NeurIPS (
Neural Information Processing Systems ) es la conferencia más grande del mundo sobre aprendizaje automático e inteligencia artificial y el evento principal en el mundo del aprendizaje profundo.
En la nueva década, ¿dominaremos los ingenieros de DS también la biología, la lingüística y la psicología? Lo diremos en nuestra revisión.

Este año, la conferencia reunió a más de 13,500 personas de 80 países en Vancouver (Canadá). Este no es el primer año que Sberbank ha representado a Rusia en la conferencia: el equipo de DS habló sobre la introducción de ML en los procesos bancarios, la competencia de ML y las capacidades de la plataforma Sberbank DS. ¿Cuáles fueron las principales tendencias de 2019 en la comunidad de ML? Los participantes en la conferencia cuentan:
Andrey Chertok y
Tatyana Shavrina .
Este año, se aceptaron más de 1400 artículos en NeurIPS: algoritmos, nuevos modelos y nuevas aplicaciones para nuevos datos.
Enlace a todos los materialesContenido:
- Tendencias
- Interpretabilidad del modelo
- Multidisciplinariedad
- Razonamiento
- RL
- Gan
- Charlas invitadas clave
- "Inteligencia social", Blaise Aguera y Arcas (Google)
- "Ciencia de datos verídicos", Bin Yu (Berkeley)
- "Modelado del comportamiento humano con aprendizaje automático: oportunidades y desafíos", Nuria M Oliver, Albert Ali Salah
- "Del sistema 1 al sistema 2 Aprendizaje profundo", Yoshua Bengio
Tendencias 2019
1. Interpretabilidad del modelo y la nueva metodología de MLEl tema principal de la conferencia es la interpretación y la prueba de por qué obtenemos estos o esos resultados. Puede hablar durante mucho tiempo sobre la importancia filosófica de interpretar la "caja negra", pero hubo más métodos reales y desarrollos técnicos en esta área.
La metodología de reproducibilidad de los modelos y la extracción de conocimiento de ellos es un nuevo conjunto de herramientas de la ciencia. Los modelos pueden servir como una herramienta para adquirir nuevos conocimientos y probarlos, y todas las etapas de preprocesamiento, capacitación y aplicación del modelo deben ser reproducibles.
Una proporción importante de publicaciones se dedica no a crear modelos y herramientas, sino a problemas para garantizar la seguridad, la transparencia y la verificabilidad de los resultados. En particular, apareció una transmisión separada sobre los ataques al modelo (ataques adversos), y se consideran las opciones tanto para los ataques al entrenamiento como a los ataques a las aplicaciones.
Artículos:
- Veridical Data Science es un artículo destacado sobre metodología de verificación de modelos. Incluye una visión general de las herramientas modernas para interpretar modelos, en particular, el uso de la atención y la obtención de importancia de características debido a la "destilación" de la red neuronal por modelos lineales.
- Esto se ve así: Aprendizaje profundo para el reconocimiento de imágenes interpretables Chaofan Chen, Oscar Li, Daniel Tao, Alina Barnett, Cynthia Rudin, Jonathan K. Su
- Un punto de referencia para los métodos de interpretación en redes neuronales profundas Sara Hooker, Dumitru Erhan, Pieter-Jan Kindermans, Been Kim
- Hacia el aprendizaje de refuerzo interpretable usando la atención Agentes aumentados Alexander Mott, Daniel Zoran, Mike Chrzanowski, Daan Wierstra, Danilo Jiménez Rezende
- Una medida de importancia de la característica MDI debiatada para bosques aleatorios Xiao Li, Yu Wang, Sumanta Basu, Karl Kumbier, Bin Yu
- Extracción de conocimiento sin datos observables Jaemin Yoo, Minyong Cho, Taebum Kim, U Kang
- Un paso hacia la cuantificación Investigación de aprendizaje automático independientemente reproducible Edward Raff
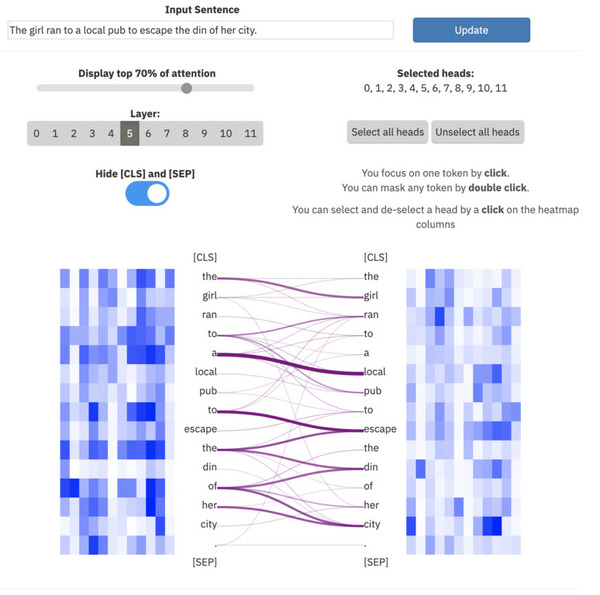 ExBert.net muestra la interpretación del modelo para tareas de procesamiento de texto
ExBert.net muestra la interpretación del modelo para tareas de procesamiento de texto
2. MultidisciplinariedadCon el fin de garantizar una verificación confiable y desarrollar mecanismos para probar y reponer el conocimiento, se necesitan especialistas de campos relacionados, que simultáneamente tengan competencias en ML y en el campo temático (medicina, lingüística, neurobiología, educación, etc.). De particular interés es la presencia más significativa de trabajos y presentaciones sobre neurociencias y ciencias cognitivas: hay un acercamiento de especialistas e ideas prestadas.
Además de este acercamiento, se planea la multidisciplinariedad en el procesamiento conjunto de información de varias fuentes: texto y fotos, texto y juegos, bases de datos de gráficos + texto y fotos.
Artículos:
 Dos modelos, un estratega y un intérprete, basados en RL y PNL juegan una estrategia en línea3. Razonamiento
Dos modelos, un estratega y un intérprete, basados en RL y PNL juegan una estrategia en línea3. RazonamientoFortalecimiento de la inteligencia artificial: un movimiento hacia sistemas de autoaprendizaje, "consciente", razonamiento y discusión (razonamiento). En particular, se desarrolla la inferencia causal y el razonamiento de sentido común. Parte de los informes está dedicado al metaaprendizaje (cómo aprender a aprender) y la combinación de tecnologías DL con lógica de primer y segundo orden: el término Inteligencia Artificial General (AGI) se convierte en un término común en los discursos de los oradores.
Artículos:
- Aprendizaje gráfico heterogéneo para el razonamiento de sentido común visual Weijiang Yu, Jingwen Zhou, Weihao Yu, Xiaodan Liang, Nong Xiao
- Bridging Machine Learning y razonamiento lógico mediante el aprendizaje abductivo Wang-Zhou Dai, Qiuling Xu, Yang Yu, Zhi-Hua Zhou
- Aprendiendo implícitamente a razonar en la lógica de primer orden Vaishak Belle, Brendan Juba
- PHYRE: un nuevo punto de referencia para el razonamiento físico Anton Bakhtin, Laurens van der Maaten, Justin Johnson, Laura Gustafson, Ross Girshick
- Incrustación cuántica del conocimiento para el razonamiento Dinesh Garg, Shajith Ikbal, Santosh K. Srivastava, Harit Vishwakarma, Hima Karanam, L Venkata Subramaniam
4.aprendizaje de refuerzoLa mayor parte del trabajo continúa desarrollando las áreas tradicionales de RL - DOTA2, Starcraft, combinando arquitecturas con visión por computadora, PNL, bases de datos gráficas.
Un día separado de la conferencia se dedicó al taller de RL, que presentó la arquitectura del Modelo Optimista de Actor Crítico, superando a todos los anteriores, en particular el Crítico de Actor Suave.
Artículos:
 Los jugadores de StarCraft luchan contra Alphastar (DeepMind)5. GAN
Los jugadores de StarCraft luchan contra Alphastar (DeepMind)5. GANLas redes generativas siguen siendo el foco de atención: muchas obras utilizan GAN de vainilla para pruebas matemáticas, y también las aplican en versiones nuevas e inusuales (modelos generativos gráficos, trabajo con series, aplicación para causar y afectar relaciones en datos, etc.).
Artículos:
Dado que el trabajo se ha llevado a más de
1.400 a continuación, hablaremos sobre las actuaciones más importantes.
Charlas invitadas
"Inteligencia social", Blaise Aguera y Arcas (Google)
EnlaceDiapositivas y videosEl informe está dedicado a la metodología general de aprendizaje automático y las perspectivas que están cambiando la industria en este momento: ¿a qué encrucijada nos enfrentamos? ¿Cómo funciona el cerebro y la evolución, y por qué usamos tan poco que ya sabemos bien sobre el desarrollo de los sistemas naturales?
El desarrollo industrial de ML coincide en gran medida con los hitos del desarrollo de Google, que publica su investigación sobre NeurIPS de año en año:
- 1997 - lanzamiento de capacidades de búsqueda, primeros servidores, pequeña potencia informática
- 2010 - Jeff Dean lanza el proyecto Google Brain, un boom de redes neuronales desde el principio
- 2015: implementación industrial de redes neuronales, reconocimiento rápido de rostros directamente en el dispositivo local, procesadores de bajo nivel mejorados por la informática tensorial (TPU). Google lanza Coral ai, un análogo de raspberry pi, una mini computadora para introducir redes neuronales en instalaciones experimentales
- 2017 - Google comienza el desarrollo de entrenamiento descentralizado y combina los resultados del entrenamiento de redes neuronales desde diferentes dispositivos en un solo modelo - en Android
Hoy, toda una industria se preocupa por la seguridad de los datos, combinando y reproduciendo resultados de aprendizaje en dispositivos locales.
Aprendizaje federado : dirección de
aprendizaje automático en la que los modelos individuales estudian de forma independiente y luego se combinan en un solo modelo (sin centralizar los datos de origen), ajustados por eventos raros, anomalías, personalización, etc. Todos los dispositivos Android son esencialmente una sola supercomputadora informática para Google.
Los modelos generativos basados en el aprendizaje federado son un área prometedora futura, según Google, que se encuentra "en las primeras etapas de crecimiento exponencial". Los GAN, según el profesor, pueden aprender a reproducir el comportamiento de masas de las poblaciones de organismos vivos, utilizando algoritmos de pensamiento.
Usando dos arquitecturas GAN simples como ejemplo, se muestra que en ellas la búsqueda de la ruta de optimización vaga en un círculo, lo que significa que la optimización no ocurre como tal. Además, estos modelos modelan con mucho éxito los experimentos que los biólogos realizan en poblaciones bacterianas, obligándolos a aprender nuevas estrategias de comportamiento en busca de alimento. Podemos concluir que la vida funciona de manera diferente a la función de optimización.
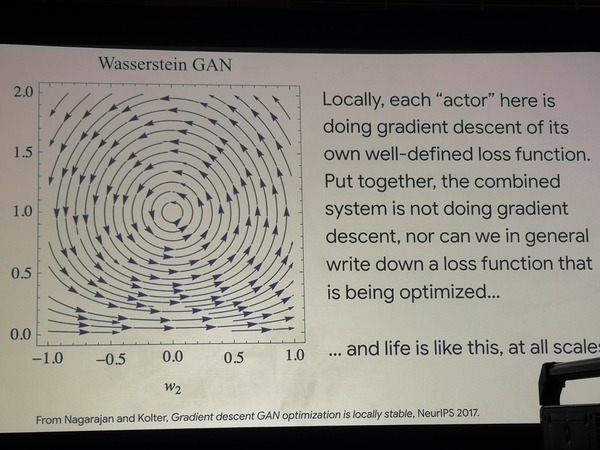 Optimización de GAN errante
Optimización de GAN erranteTodo lo que hacemos en el marco del aprendizaje automático ahora es tareas estrechas y extremadamente formalizadas, mientras que estos formalismos están poco generalizados y no corresponden a nuestro conocimiento del tema en áreas como la neurofisiología y la biología.
Lo que realmente vale la pena tomar prestado del campo de la neurofisiología en el futuro cercano es la nueva arquitectura de las neuronas y una pequeña revisión de los mecanismos de propagación del error.
El cerebro humano en sí no aprende a usar una red neuronal:
- No tiene introductorios primarios aleatorios, incluidos los establecidos a través de los sentidos y en la infancia.
- Él tiene las direcciones establecidas de desarrollo instintivo (el deseo de aprender un idioma desde una postura erguida infantil)
Aprender el cerebro individual es una tarea de bajo nivel, quizás deberíamos considerar las "colonias" de los individuos que cambian rápidamente, transmitiéndose conocimientos entre sí para reproducir los mecanismos de la evolución grupal.
¿Qué podemos tomar en los algoritmos de ML en este momento?
- Aplicar modelos de linaje celular que brinden capacitación para la población, pero la corta vida del individuo ("cerebro individual")
- Pocos aprendizajes en algunos ejemplos
- Estructuras neuronales más complejas, funciones de activación ligeramente diferentes.
- Transmitir el "genoma" a las generaciones futuras: algoritmo de propagación inversa
- Tan pronto como conectemos neurofisiología y redes neuronales, aprenderemos cómo construir un cerebro multifuncional a partir de muchos componentes.
Desde este punto de vista, la práctica de las soluciones SOTA es perjudicial y debe revisarse para desarrollar tareas comunes (puntos de referencia).
"Ciencia de datos verídicos", Bin Yu (Berkeley)
Videos y diapositivasEl informe está dedicado al problema de la interpretación de los modelos de aprendizaje automático y la metodología de su verificación y verificación directa. Cualquier modelo ML capacitado puede ser percibido como una fuente de conocimiento que debe extraerse de él.
En muchas áreas, especialmente en medicina, la aplicación del modelo es imposible sin extraer este conocimiento oculto e interpretar los resultados del modelo; de lo contrario, no estaremos seguros de que los resultados serán estables, no aleatorios, confiables y no matarán al paciente. Toda la dirección de la metodología de trabajo se desarrolla dentro del paradigma de aprendizaje profundo y va más allá de sus límites: la ciencia de datos verídica. Que es esto
Queremos lograr la calidad de las publicaciones científicas y la reproducibilidad de los modelos para que sean:
- predecible
- computable
- estable
Estos tres principios forman la base de la nueva metodología. ¿Cómo se pueden probar los modelos ML con estos criterios? La forma más fácil es construir modelos inmediatamente interpretables (regresiones, árboles de decisión). Sin embargo, queremos obtener las ventajas inmediatas del aprendizaje profundo.
Varias formas existentes de tratar el problema:
- interpretar el modelo;
- Utilice métodos basados en la atención.
- use conjuntos de algoritmos para el entrenamiento y asegúrese de que los modelos lineales interpretables aprendan a predecir las mismas respuestas que una red neuronal, interpretando las características de un modelo lineal;
- Cambiar y aumentar los datos de entrenamiento. Esto incluye la adición de ruido, interferencia y aumento de datos;
- cualquier método que asegure que los resultados del modelo no sean aleatorios y no dependan de pequeñas interferencias no deseadas (ataques adversos);
- interpretar el modelo post factum después del entrenamiento;
- estudiar pesos de signos de varias maneras;
- Estudiar las probabilidades de todas las hipótesis, la distribución de clases.
 Ataque adversarial a un cerdo
Ataque adversarial a un cerdoLos errores de modelado son caros para todos: un ejemplo vívido: el trabajo de Reinhart y Rogov "
Crecimiento en tiempos de deuda " influyó en las políticas económicas de muchos países europeos y los obligó a seguir una política de ahorro, ¡pero la verificación cruzada cuidadosa de los datos y su procesamiento años después mostraron el resultado opuesto!
Cualquier tecnología ML tiene su propio ciclo de vida de implementación a implementación. La tarea de la nueva metodología es verificar tres principios básicos en cada etapa de la vida del modelo.
Resumen:
- Se están desarrollando varios proyectos para ayudar a que el modelo ML sea más confiable. Esto es, por ejemplo, deeptune (enlace a: github.com/ChrisCummins/paper-end2end-dl );
- Para un mayor desarrollo de la metodología, es necesario mejorar significativamente la calidad de las publicaciones en el campo de ML;
- El aprendizaje automático necesita líderes con capacitación multidisciplinaria y experiencia en los campos técnicos y humanitarios.
"Modelado del comportamiento humano con aprendizaje automático: oportunidades y desafíos" Nuria M Oliver, Albert Ali Salah
Conferencia sobre modelado del comportamiento humano, sus fundamentos tecnológicos y perspectivas de aplicación.
El modelado del comportamiento humano se puede dividir en:
- comportamiento individual
- comportamiento de grupos pequeños
- comportamiento masivo
Cada uno de estos tipos se puede modelar usando ML, pero con información y características de entrada completamente diferentes. Cada tipo también tiene sus propios problemas éticos por los que pasa cada proyecto:
- comportamiento individual: robo de identidad, falsificación profunda;
- el comportamiento de grupos de personas: desanonimización, obtención de información sobre movimientos, llamadas telefónicas, etc.
Comportamiento individualEn mayor medida, el tema de la visión por computadora: reconocimiento de las emociones humanas, sus reacciones. Es posible solo en contexto, en el tiempo o con una escala relativa de su propia variabilidad de emociones. En la diapositiva está el reconocimiento de las emociones de Mona Lisa usando el contexto del espectro emocional de las mujeres mediterráneas. Resultado: una sonrisa de alegría, pero con desprecio y asco. La razón es más probable en la forma técnica de determinar la emoción "neutral".
Comportamiento en grupos pequeñosHasta ahora, lo peor está modelado debido a la falta de información. Las obras de 2018-2019 se mostraron como ejemplo. en docenas de personas X docenas de videos (cf. conjuntos de datos de imágenes 100k ++). Para la mejor simulación dentro de esta tarea, se requiere información multimodal, preferiblemente desde sensores hasta un telealtímetro, termómetro, grabación de micrófono, etc.
Comportamiento masivoEl área más desarrollada, ya que el cliente es las Naciones Unidas y muchos estados. Cámaras de vigilancia al aire libre, datos de torres telefónicas (facturación, SMS, llamadas, datos sobre el movimiento entre las fronteras de los estados), todo esto da una idea muy confiable del movimiento de los flujos de personas, de las inestabilidades sociales. Posibles aplicaciones de la tecnología: optimización de operaciones de rescate, asistencia y evacuación oportuna de la población en caso de emergencia. Hasta ahora, los modelos utilizados están en su mayoría mal interpretados: se trata de varios LSTM y redes convolucionales. Hubo un breve comentario de que la ONU está presionando por una nueva ley que obligue a las empresas europeas a compartir los datos anónimos necesarios para cualquier investigación.
"Del sistema 1 al sistema 2 Aprendizaje profundo", Yoshua Bengio
DiapositivasEn una conferencia de Joshua, el aprendizaje profundo de Benjio se encuentra con la neurociencia en el nivel de fijación de objetivos.
Benjio identifica dos tipos principales de tareas según la metodología del premio Nobel Daniel Kahneman (el libro "
Piensa despacio, resuelve rápido ")
tipo 1 - Sistema 1, las acciones inconscientes que hacemos "en la máquina" (el cerebro antiguo): conducir un automóvil en lugares familiares, caminar, reconocer rostros.
tipo 2 - Sistema 2, acciones conscientes (corteza cerebral), fijación de objetivos, análisis, pensamiento, tareas compuestas.
Hasta ahora, la inteligencia artificial alcanza alturas suficientes solo en tareas del primer tipo, mientras que nuestra tarea es llevarla al segundo, habiendo aprendido cómo realizar operaciones multidisciplinarias y operar con habilidades cognitivas lógicas de alto nivel.
Para lograr este objetivo, se propone:
- utilizar la atención como mecanismo clave para modelar el pensamiento en tareas de PNL
- utilice el metaaprendizaje y el aprendizaje de representación para modelar mejor los signos que afectan la conciencia y su localización, y en función de ellos, cambie a operar con conceptos de nivel superior.
En lugar de la conclusión, dejamos la entrada de la charla invitada: Benjio es uno de los muchos científicos que están tratando de expandir el campo de ML más allá de los problemas de optimización, SOTA y nuevas arquitecturas.
La pregunta sigue abierta en qué medida la combinación de los problemas de la conciencia, la influencia del lenguaje en el pensamiento, la neurobiología y los algoritmos es lo que nos espera en el futuro y nos permitirá pasar a máquinas que "piensan" como las personas.
Gracias