Veremos cómo funciona Zabbix con la base de datos TimescaleDB como back-end. Mostramos cómo comenzar desde cero y cómo migrar con PostgreSQL. También ofrecemos pruebas de rendimiento comparativas de las dos configuraciones.

HighLoad ++ Siberia 2019. Tomsk Hall. 24 de junio, 16:00. Resúmenes y
presentación . La próxima conferencia HighLoad ++ se llevará a cabo los días 6 y 7 de abril de 2020 en San Petersburgo. Detalles y entradas
aquí .
Andrey Gushchin (en adelante ,
AG): - Soy un ingeniero de soporte técnico de ZABBIX (en adelante, Zabbix), un entrenador. He trabajado en soporte técnico durante más de 6 años y me he enfrentado directamente con el rendimiento. Hoy hablaré sobre el rendimiento que TimescaleDB puede ofrecer en comparación con el PostgreSQL 10. También, una parte introductoria sobre cómo funciona.
Retos clave del rendimiento: de la recopilación a la limpieza de datos
Para empezar, hay ciertos desafíos de rendimiento que enfrenta todo sistema de monitoreo. El primer desafío de rendimiento es la rápida recopilación y procesamiento de datos.

Un buen sistema de monitoreo debe recibir de manera oportuna y oportuna todos los datos, procesarlos de acuerdo con expresiones desencadenantes, es decir, procesarlos de acuerdo con algunos criterios (en diferentes sistemas es diferente) y guardarlos en la base de datos para usar estos datos en el futuro.

El segundo desafío de rendimiento es mantener la historia. Almacene en la base de datos con frecuencia y tenga acceso rápido y conveniente a estas métricas que se recopilaron durante un período de tiempo. Lo más importante es que es conveniente obtener estos datos, usarlos en informes, gráficos, disparadores, en algunos valores de umbral, para alertas, etc.

El tercer desafío de rendimiento es aclarar la historia, es decir, cuando su día es tal que no necesita almacenar ninguna métrica detallada que se haya recopilado durante 5 años (incluso meses o dos meses). Algunos nodos de red se han eliminado, o algunos hosts, las métricas ya no son necesarias porque ya están desactualizadas y ya no se recopilan. Todo esto debe limpiarse para que su base de datos no crezca a un tamaño grande. En general, borrar el historial suele ser una prueba seria para el almacenamiento; muy a menudo afecta el rendimiento.
¿Cómo resolver los problemas de almacenamiento en caché?
Ahora hablaré específicamente sobre el Zabbix. En Zabbix, la primera y la segunda llamada se resuelven mediante el almacenamiento en caché.

Recopilación y procesamiento de datos: utilizamos RAM para almacenar todos estos datos. Ahora estos datos se discutirán con más detalle.
También en el lado de la base de datos hay un cierto almacenamiento en caché para las muestras principales: para gráficos, otras cosas.
Almacenamiento en caché en el lado del servidor Zabbix: tenemos ConfigurationCache, ValueCache, HistoryCache, TrendsCache. Que es esto

ConfigurationCache es el caché principal en el que almacenamos métricas, hosts, elementos de datos, disparadores; todo lo que necesita para procesar el preprocesamiento, recopilar datos, de qué hosts recopilar, con qué frecuencia. Todo esto se almacena en ConfigurationCache, para no ir a la base de datos, para no crear solicitudes innecesarias. Después de que se inicia el servidor, actualizamos este caché (crear) y lo actualizamos periódicamente (según la configuración).
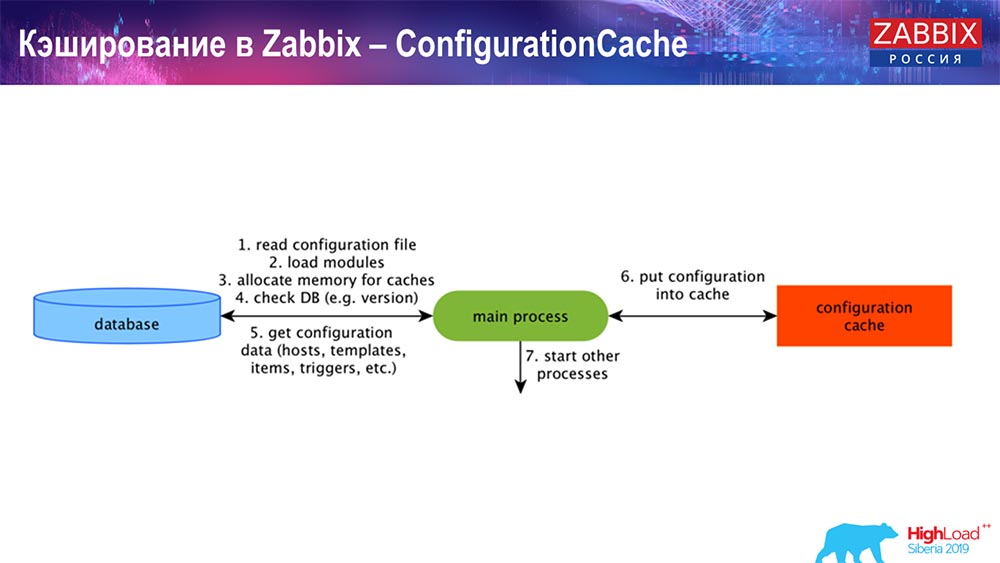
Almacenamiento en caché en Zabbix. Recogida de datos
Aquí el esquema es bastante grande:

Los principales en el esquema son estos coleccionistas:
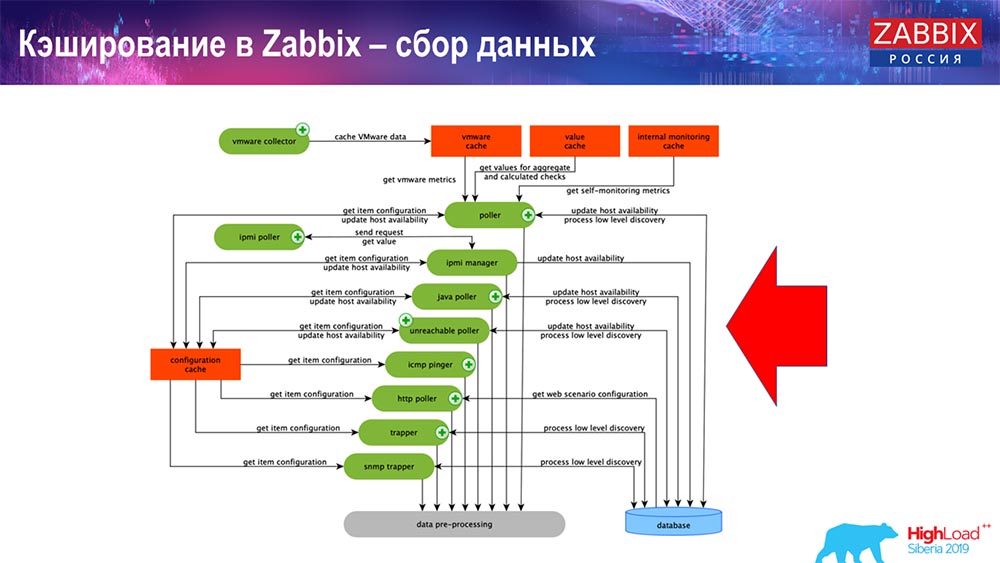
Estos son los procesos de ensamblaje en sí, varios "encuestadores" responsables de los diferentes tipos de ensamblajes. Recopilan datos a través de icmp, ipmi, de acuerdo con diferentes protocolos y los transfieren al preprocesamiento.
Historial de preprocesamiento
Además, si hemos calculado elementos de datos (quién sabe Zabbix - sabe), es decir, elementos de datos agregados calculados, los tomamos directamente de ValueCache. Sobre cómo se llena, lo contaré más tarde. Todos estos recopiladores usan ConfigurationCache para obtener sus trabajos y luego pasarlos al preprocesamiento.
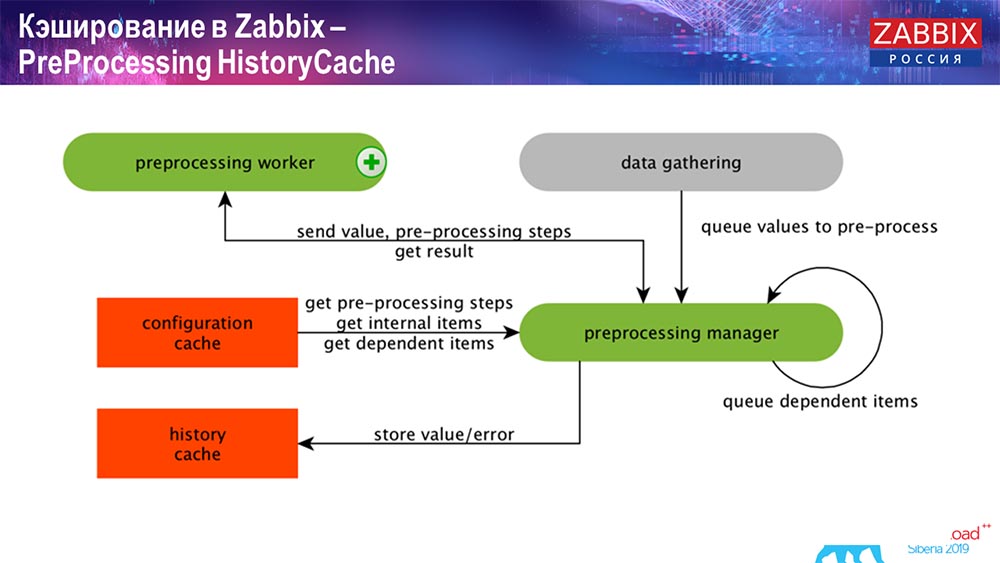
El preprocesamiento también utiliza ConfigurationCache para obtener pasos de preprocesamiento; procesa estos datos de varias maneras. A partir de la versión 4.2, la enviamos al proxy. Esto es muy conveniente, porque el preprocesamiento en sí mismo es una operación bastante difícil. Y si tiene un "Zabbix" muy grande, con una gran cantidad de elementos de datos y una alta frecuencia de recolección, esto facilita enormemente el trabajo.
En consecuencia, después de que procesamos estos datos de alguna manera utilizando el preprocesamiento, los guardamos en HistoryCache para procesarlos más. Esto finaliza la recopilación de datos. Pasamos al proceso principal.
Operación de sincronizador de historia
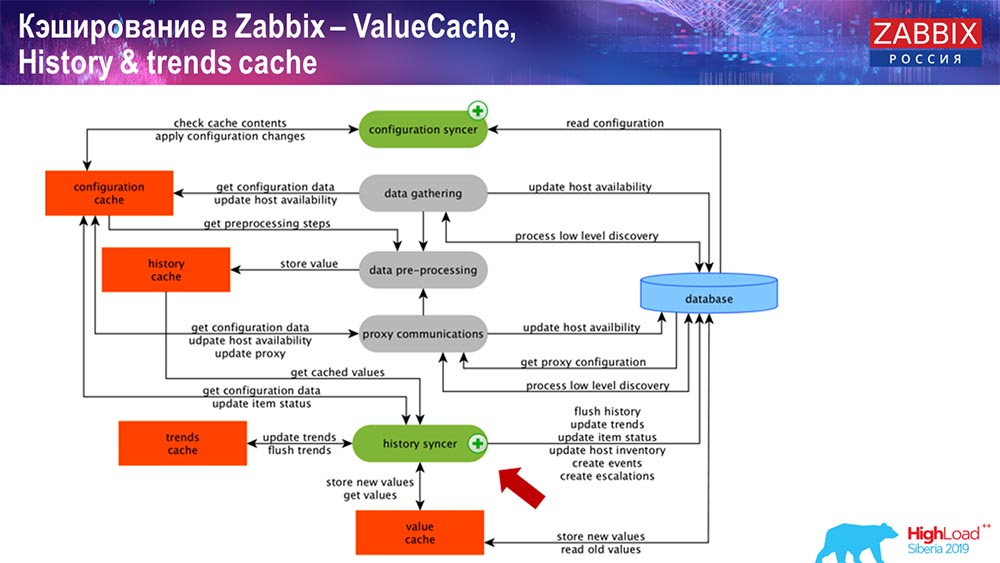
El proceso principal en Zabbix (ya que es una arquitectura monolítica) es History Syncer. Este es el proceso principal que se ocupa específicamente del procesamiento atómico de cada elemento de datos, es decir, de cada valor:
- viene el valor (lo toma de HistoryCache);
- verifica en Sincronizador de configuración: ¿hay algún desencadenante para el cálculo?
si es así, crea eventos, crea una escalada para crear una alerta, si es necesario por configuración; - desencadenantes de registros para procesamiento posterior, agregación; si agrega en la última hora, etc., este valor recuerda ValueCache, para no ir a la tabla de historial; Por lo tanto, ValueCache se llena con los datos necesarios que son necesarios para calcular desencadenantes, elementos calculados, etc.
- entonces History Syncer escribe todos los datos en la base de datos;
- la base de datos los escribe en el disco; aquí es donde termina el proceso de procesamiento.
Bases de datos Almacenamiento en caché
En el lado de la base de datos, cuando desea ver gráficos o algún tipo de informe de eventos, hay varios cachés. Pero como parte de este informe, no hablaré sobre ellos.
Para MySQL, hay Innodb_buffer_pool, un montón de cachés diferentes que también se pueden configurar.
Pero estos son los principales:
- shared_buffers;
- eficaz_caché_tamaño;
- shared_pool.

He citado para todas las bases de datos que hay ciertas memorias caché que le permiten mantener en la memoria los datos que a menudo se necesitan para las consultas. Allí tienen sus propias tecnologías para esto.
Sobre el rendimiento de la base de datos
En consecuencia, existe un entorno competitivo, es decir, el servidor Zabbix recopila datos y los registra. Al reiniciar, también lee del historial para llenar ValueCache y así sucesivamente. Aquí puede tener scripts e informes que utilizan la API de Zabbix, que se basa en la interfaz web. "Zabbiks" -API está incluido en la base de datos y recibe los datos necesarios para obtener gráficos, informes o alguna lista de eventos, problemas recientes.

También una solución de visualización muy popular es Grafana, que utilizan nuestros usuarios. Capaz de ingresar directamente a través de "Zabbiks" -API, y a través de la base de datos. También crea una cierta competencia para obtener datos: se necesita un ajuste más fino y mejor de la base de datos para corresponder a la entrega rápida de resultados y pruebas.

Claro historial. Zabbix tiene ama de llaves
El tercer desafío utilizado por Zabbix es aclarar la historia con Housekeeper. Hauskiper cumple con todas las configuraciones, es decir, en nuestros elementos de datos se indica cuánto almacenar (en días), cuánto almacenar las tendencias, la dinámica de los cambios.
No hablé de TrendCache, que calculamos sobre la marcha: los datos llegan, los agregamos en una hora (básicamente estos son números en la última hora), la cantidad es promedio / mínimo y la escribimos una vez por hora en la tabla de cambios en la dinámica (Tendencias) . Hauskiper se inicia y elimina datos de la base de datos utilizando selecciones regulares, lo que no siempre es efectivo.
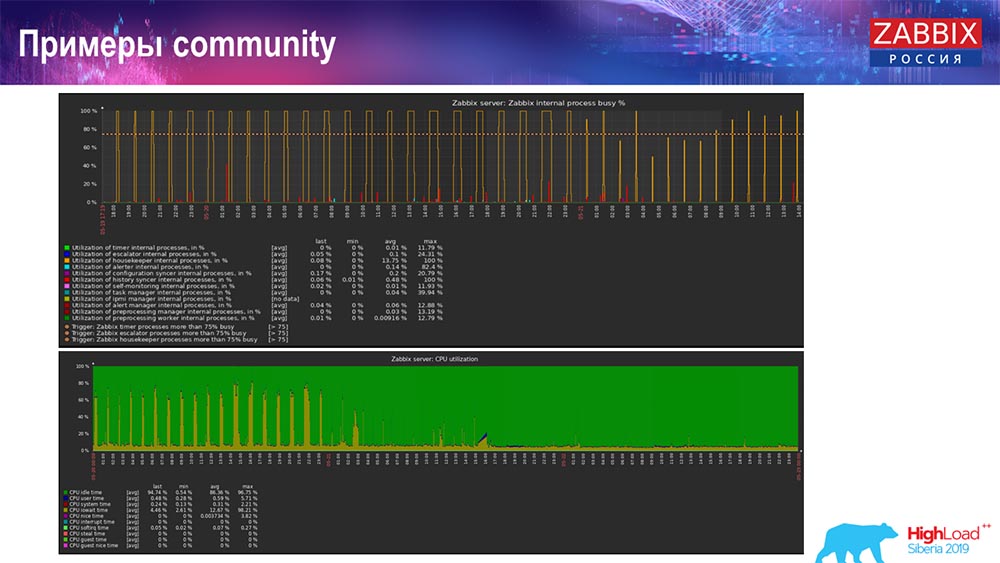
¿Cómo entender que es ineficiente? Puede ver la siguiente imagen en los gráficos de rendimiento de los procesos internos:
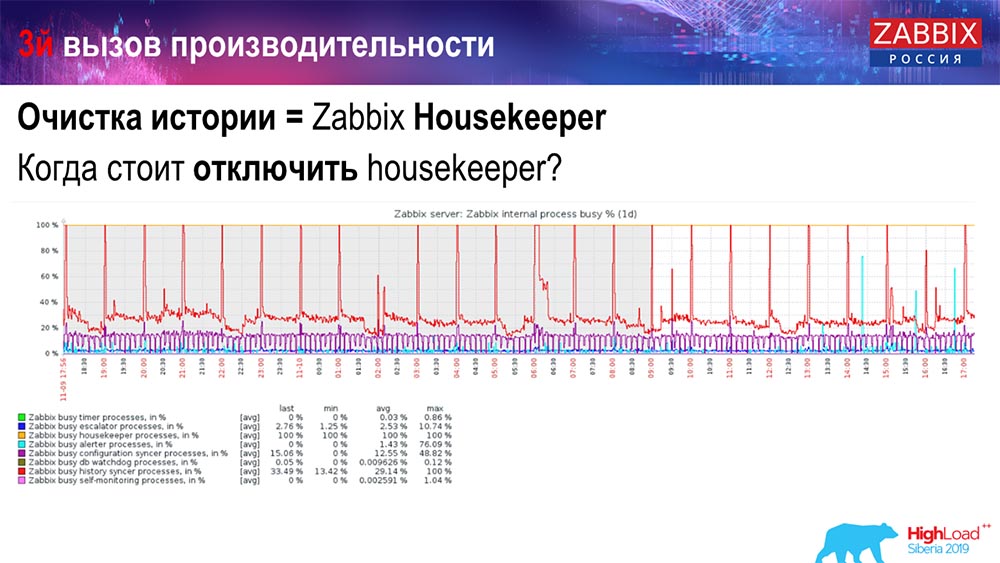
Su sincerizador de historia está constantemente ocupado (gráfico rojo). Y la tabla "roja" que va arriba. Este es el Hauskiper, que comienza y espera a la base de datos cuando elimina todas las líneas que especificó.
Tome alguna ID de artículo: debe eliminar los últimos 5 mil; Por supuesto, por índices. Pero, por lo general, el conjunto de datos es lo suficientemente grande: la base de datos todavía lee esto del disco y lo eleva a la memoria caché, y esta es una operación muy costosa para la base de datos. Dependiendo de su tamaño, esto puede conducir a ciertos problemas de rendimiento.
Puede deshabilitar Hauskiper de una manera simple: tenemos una interfaz web familiar para todos. Configurando en Administración general (configuraciones para "Ama de llaves") deshabilitamos la limpieza interna para el historial interno y las tendencias. En consecuencia, Hauskiper ya no controla esto:

¿Qué puedo hacer a continuación? Se desconectó, sus horarios se nivelaron ... ¿Qué problemas pueden ir más allá en este caso? Que puede ayudar
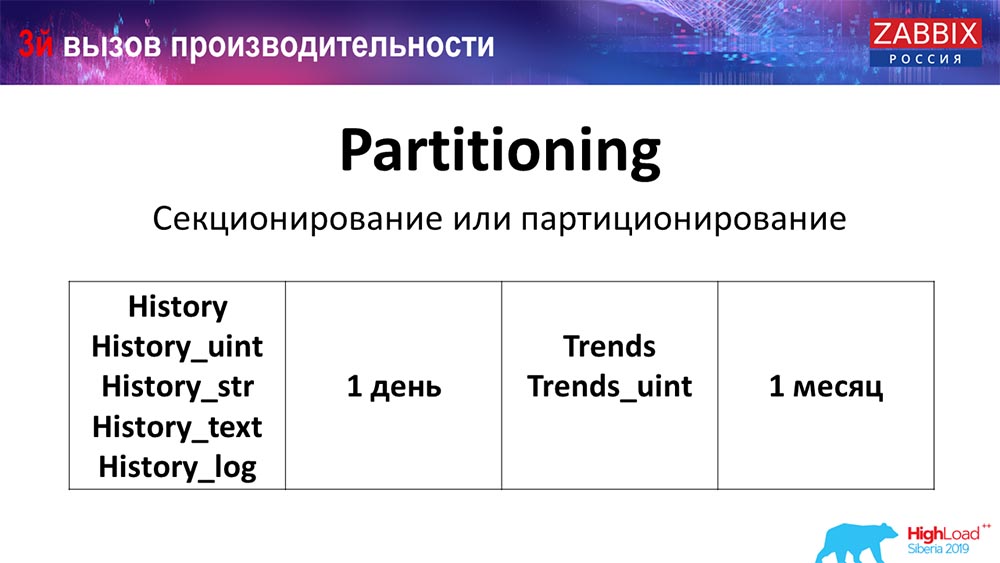
Particionamiento (particionamiento)
Esto generalmente se configura en cada base de datos relacional que he enumerado de manera diferente. MySQL tiene su propia tecnología. Pero en general son muy similares cuando se trata de PostgreSQL 10 y MySQL. Por supuesto, hay muchas diferencias internas en cómo se implementa todo y cómo afecta todo el rendimiento. Pero en general, la creación de una nueva partición a menudo también conduce a ciertos problemas.

Dependiendo de su configuración (la cantidad de datos que crea en un día), generalmente establecen el mínimo: 1 día / partición, y para las tendencias, la dinámica de los cambios: 1 mes / nueva partición. Esto puede cambiar si tiene una configuración muy grande.
Digamos de inmediato sobre el tamaño de la configuración: hasta 5 mil valores nuevos por segundo (denominados nvps); esto se considerará una pequeña "configuración". Promedio: de 5 a 25 mil valores por segundo. Todo lo que está arriba ya son instalaciones grandes y muy grandes que requieren una configuración muy cuidadosa de la base de datos.
En instalaciones muy grandes, 1 día, esto puede no ser óptimo. Personalmente, vi en particiones MySQL de 40 gigabytes por día (y puede haber más). Esta es una gran cantidad de datos, lo que puede generar algunos problemas. Necesita ser reducido.
¿Por qué particionar?
Lo que el particionamiento ofrece, creo que todos lo saben, es el particionamiento de tablas. A menudo, estos son archivos separados en el disco y solicitudes de extensión. Él selecciona de manera más óptima una partición, si esta es parte de la partición habitual.
Para Zabbix, en particular, se usa por rango, por rango, es decir, usamos una marca de tiempo (el número es ordinario, el tiempo desde el comienzo de la era). Usted especifica el comienzo del día / final del día, y esta es una partición. En consecuencia, si está solicitando datos hace dos días, todo esto se selecciona de la base de datos más rápido, ya que solo necesita cargar un archivo en la caché y emitir (en lugar de una tabla grande).

Muchas bases de datos también aceleran la inserción (inserción en una sola tabla secundaria). Si bien hablo de manera abstracta, pero también es posible. Partitoning a menudo ayuda.
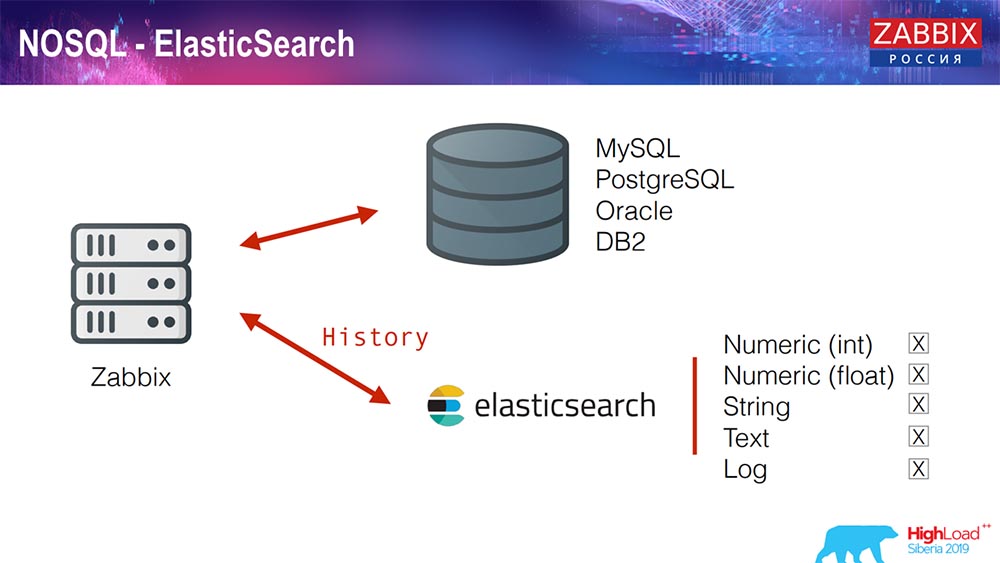
Elasticsearch para NoSQL
Recientemente, en 3.4, implementamos una solución para NoSQL. Se agregó la capacidad de escribir en Elasticsearch. Puede escribir algunos tipos separados: elija, ya sea escribir números o algunos signos; tenemos texto de cadena, puede escribir registros en Elasticsearch ... En consecuencia, la interfaz web también accederá a Elasticsearch. Esto funciona bien en algunos casos, pero por el momento se puede usar.
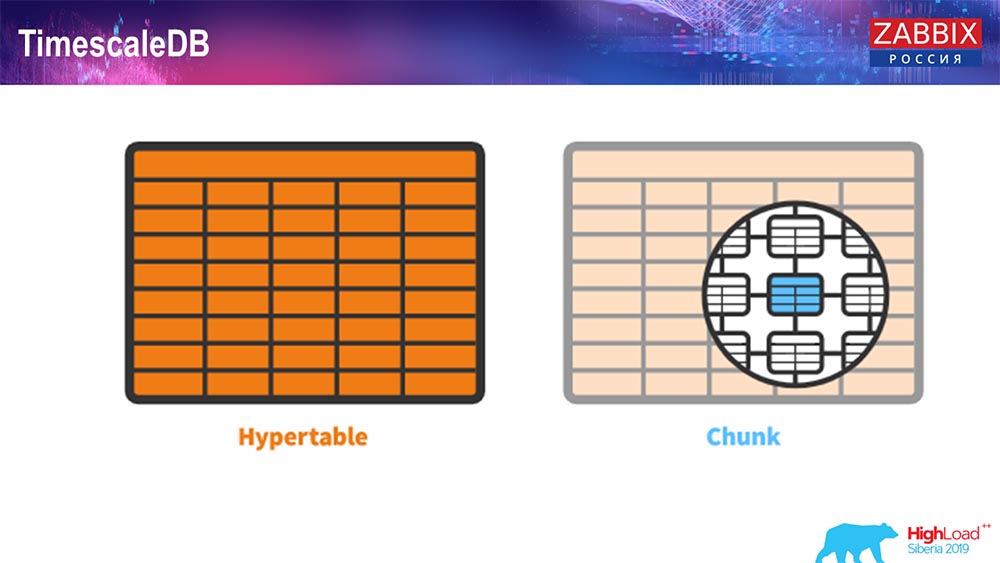
TimescaleDB. Hipertables
Para 4.4.2, notamos una cosa como TimescaleDB. Que es esto Esta es una extensión para Postgres, es decir, tiene una interfaz nativa de PostgreSQL. Además, esta extensión le permite trabajar con datos de series de tiempo de manera mucho más eficiente y tener particiones automáticas. Cómo se ve:

Esto es hipertable: existe tal concepto en Timescale. Esta es la hipertable que creas y contiene fragmentos. Los fragmentos son particiones, estas son tablas secundarias, si no me equivoco. Es realmente efectivo.
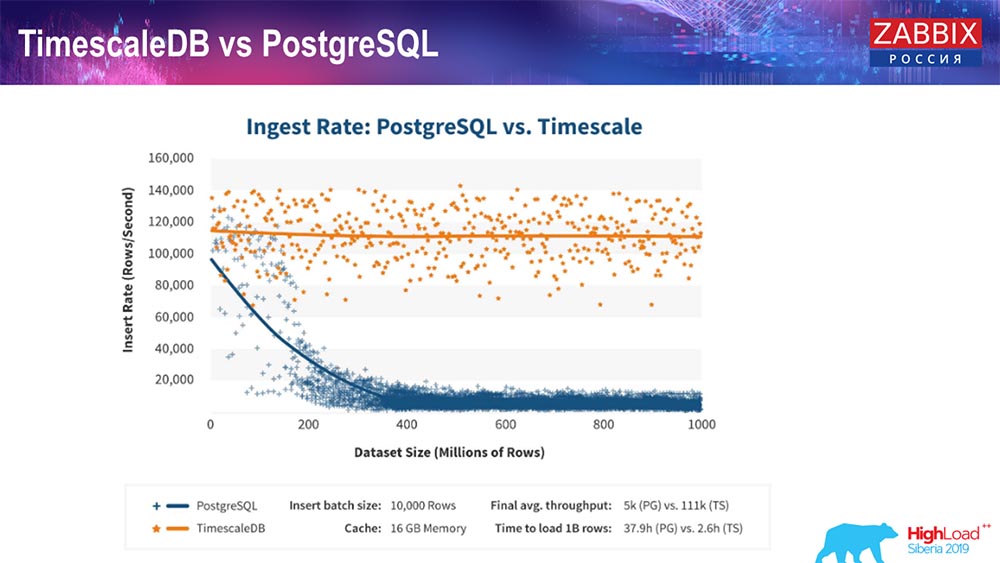
TimescaleDB y PostgreSQL
Como aseguran los fabricantes de TimescaleDB, utilizan un algoritmo de procesamiento de solicitudes más correcto, en particular insert'ov, que le permite tener un rendimiento aproximadamente constante con un tamaño creciente de la inserción del conjunto de datos. Es decir, después de 200 millones de líneas de "Postgres", la habitual comienza a ceder mucho y pierde el rendimiento literalmente a cero, mientras que "Timescale" le permite insertar inserciones de la manera más eficiente posible con cualquier cantidad de datos.
¿Cómo instalar TimescaleDB? ¡Todo es simple!
Lo tiene en la documentación, se describe: se puede entregar desde paquetes para cualquier ... Depende de los paquetes oficiales de Postgres. Se puede compilar manualmente. Sucedió que tuve que compilar para la base de datos.
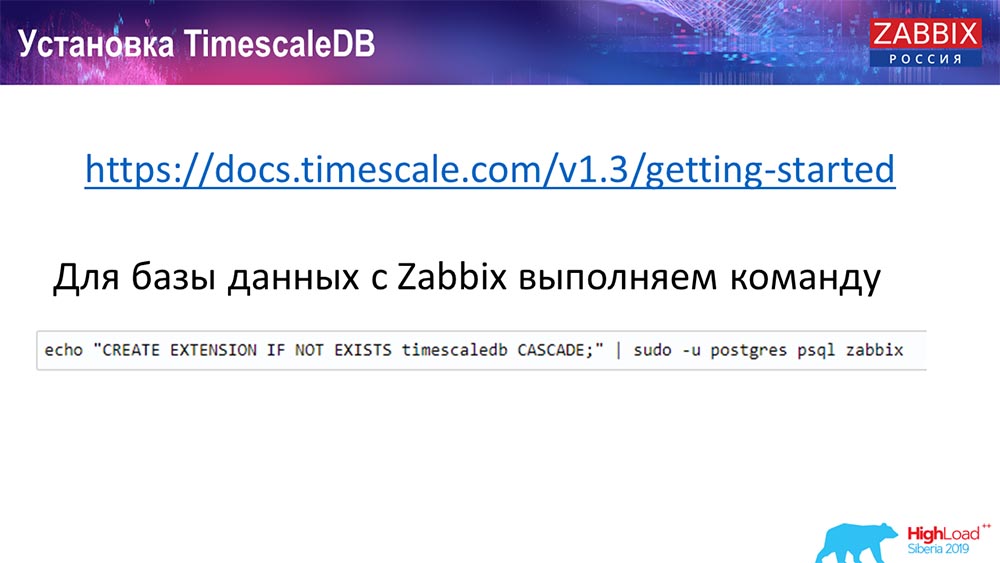
En Zabbix, solo activamos la extensión. Creo que aquellos que usaron Extención en Postgres ... Simplemente active Extención, créelo para la base de datos Zabbix que usa.
Y el último paso ...
TimescaleDB. Tablas de historial de migración
Necesitas crear un hipertable. Hay una función especial para esto: crear hipertables. En él, el primer parámetro indica la tabla que se necesita en esta base de datos (para la cual necesita crear una hipertable).

El campo por el que desea crear, y chunk_time_interval (este es el intervalo de fragmentos (particiones que se utilizarán). 86,400 es un día.
Parámetro migrate_data: si inserta en verdadero, esto transfiere todos los datos actuales a fragmentos previamente creados.
Yo mismo utilicé migrate_data: lleva una cantidad de tiempo decente, dependiendo del tamaño de su base de datos. Tenía más de un terabyte: la creación tardó más de una hora. En algunos casos, durante las pruebas, eliminé los datos históricos para el texto (history_text) y la cadena (history_str), para no transferirlos, no eran realmente interesantes para mí.
Y hacemos la última actualización en nuestra db_extention: establecemos timescaledb para que la base de datos y, en particular, nuestro Zabbix entiendan qué es db_extention. Lo activa y utiliza la sintaxis correcta y las consultas de la base de datos, utilizando esas "características" que son necesarias para TimescaleDB.
Configuración del servidor
Usé dos servidores. El primer servidor es una máquina virtual lo suficientemente pequeña, 20 procesadores, 16 gigabytes de RAM. Configure Postgres 10.8 en él:

El sistema operativo era Debian, el sistema de archivos era xfs. Realicé configuraciones mínimas para usar esta base de datos en particular, menos lo que usará Zabbix. En la misma máquina había un servidor Zabbix, PostgreSQL y agentes de carga.

Usé 50 agentes activos que usan LoadableModule para generar rápidamente varios resultados. Generaron líneas, números, etc. Estorbé la base de datos con muchos datos. Inicialmente, la configuración contenía 5 mil elementos de datos por host, y aproximadamente cada elemento de datos contenía un disparador, por lo que era una configuración real. A veces, incluso se necesita más de un disparador para usar.

Regulé el intervalo de actualización, la carga en sí misma, de modo que no solo usé 50 agentes (agregué más), sino que también usé elementos de datos dinámicos y reduje el intervalo de actualización a 4 segundos.
Prueba de rendimiento. PostgreSQL: 36 mil NVP
El primer lanzamiento, la primera configuración que tuve en PostreSQL 10 puro en este hardware (35 mil valores por segundo). En general, como puede ver en la pantalla, la inserción de datos toma fracciones de segundo: todo está bien y es rápido, SSD (200 gigabytes). Lo único es que 20 GB se llenan rápidamente.
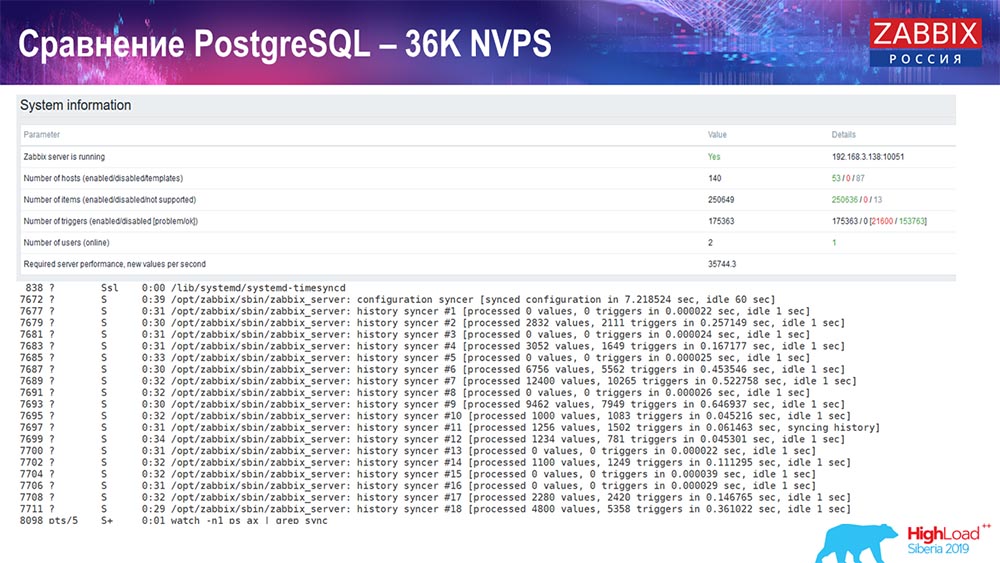
Habrá muchos más gráficos de este tipo. Este es el panel de rendimiento estándar del servidor Zabbix.
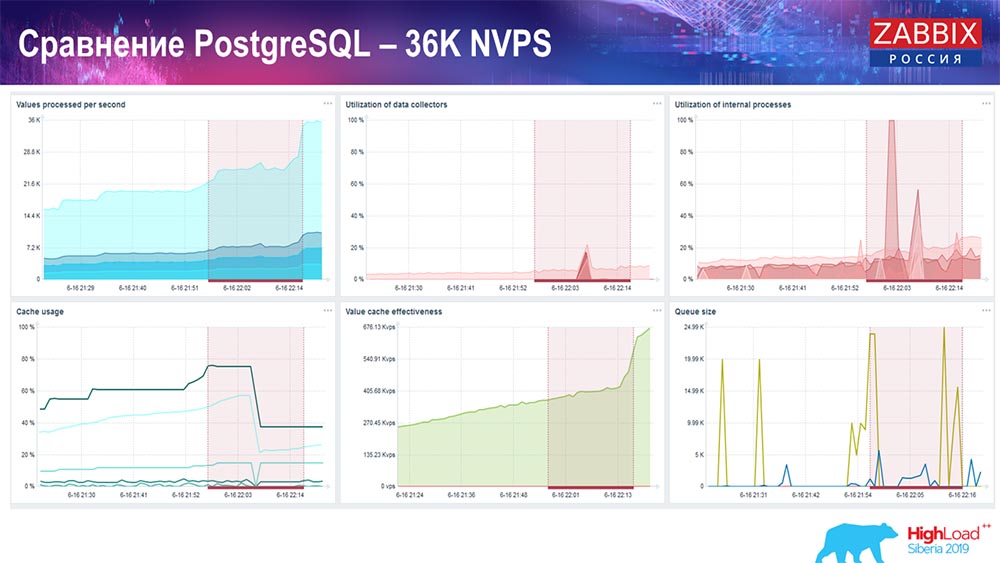
El primer gráfico es el número de valores por segundo (azul, arriba a la izquierda), 35 mil valores en este caso. Este (centro de carga) es la carga de los procesos de ensamblaje, y esto (arriba a la derecha) es la carga de los procesos internos: historiadores y ama de llaves, que ha estado funcionando aquí durante un tiempo suficiente.
Este gráfico (centro inferior) muestra el uso de ValueCache: cuántos hits de ValueCache para desencadenantes (varios miles de valores por segundo). Otro gráfico importante es el cuarto (abajo a la izquierda), que muestra el uso de HistoryCache, del que hablé, que es un búfer antes de insertarlo en la base de datos.
Prueba de rendimiento. PostgreSQL: 50 mil NVP
Luego, aumenté la carga a 50 mil valores por segundo en el mismo hardware. Al cargar con Hauskiper, se registraron 10 mil valores en 2-3 segundos con el cálculo. Que, de hecho, se muestra en la siguiente captura de pantalla:
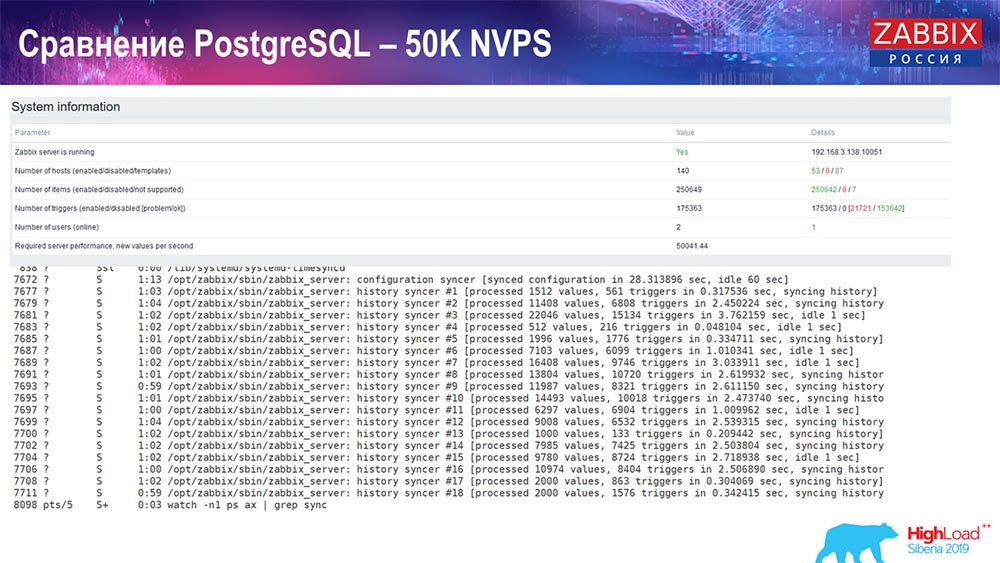
Hauskiper ya está comenzando a interferir con el trabajo, pero en general la carga de los cazadores de historiadores sigue siendo del 60% (tercer gráfico, arriba a la derecha). HistoryCache ya durante el trabajo de "Hauskiper" comienza a llenar activamente (abajo a la izquierda). Era aproximadamente medio gigabyte, lleno al 20%.
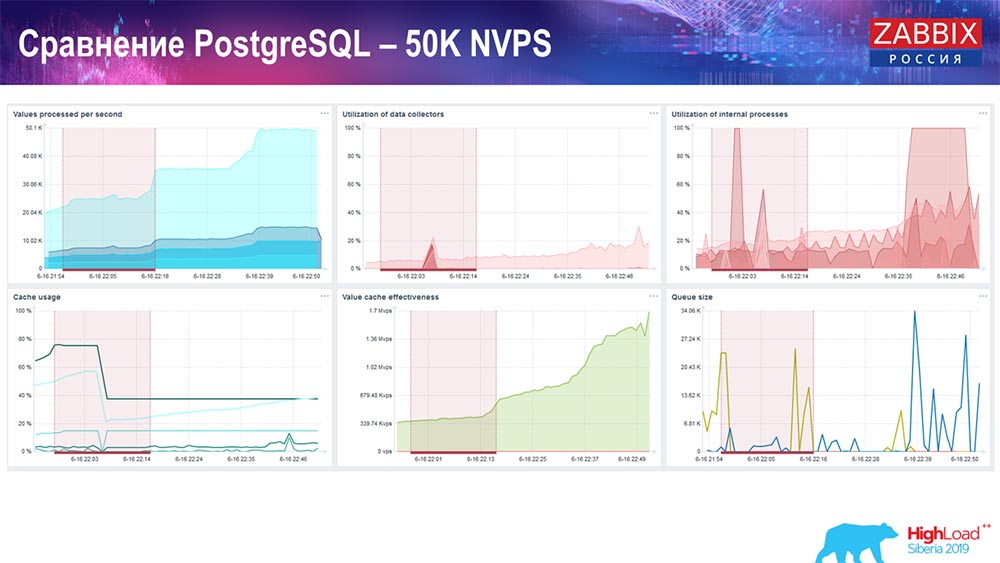
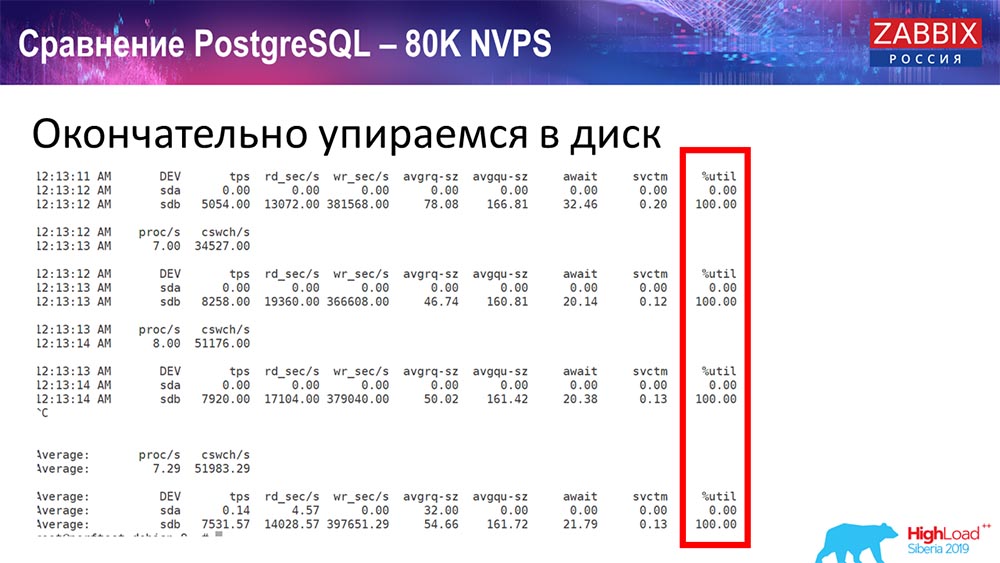
Prueba de rendimiento. PostgreSQL: 80 mil NVP
Aumentó aún más a 80 mil valores por segundo:
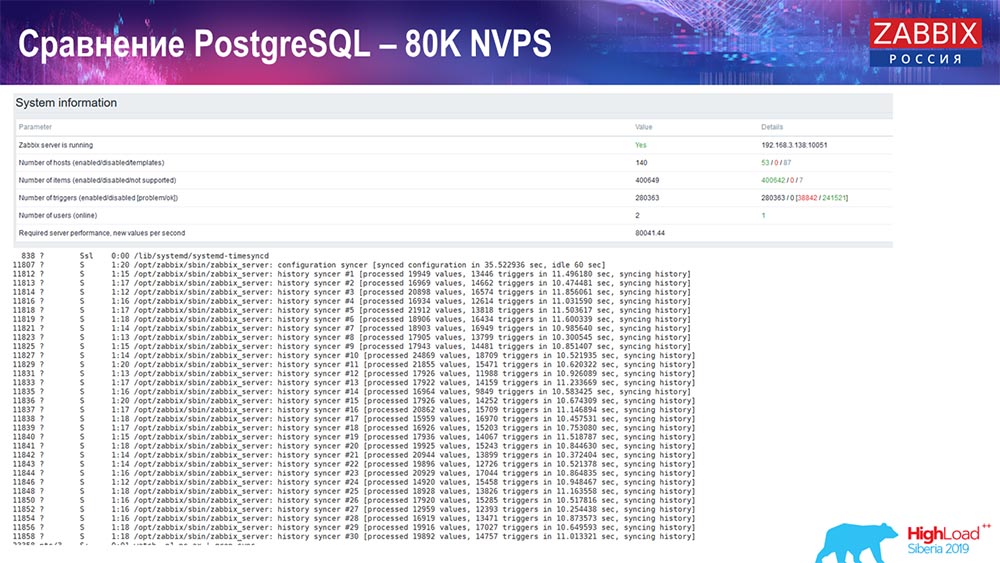
Eran aproximadamente 400 mil elementos de datos, 280 mil disparadores. El inserto, como puede ver, para la carga de hundidores históricos (había 30 de ellos) ya era bastante alto. Además, aumenté varios parámetros: hundidores de historial, caché ... En este hardware, la carga de hundidores de historial comenzó a aumentar al máximo, casi "en el estante"; en consecuencia, HistoryCache pasó a una carga muy alta:
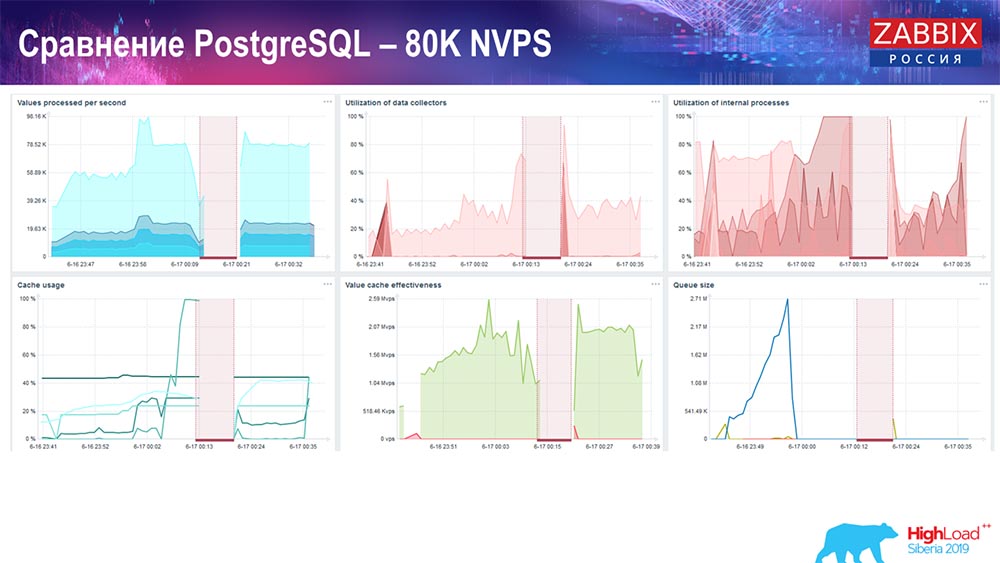
Todo este tiempo observé todos los parámetros del sistema (cómo se usa el procesador, RAM) y descubrí que la utilización del disco era máxima: logré la capacidad máxima de este disco en este hardware, en esta máquina virtual. "Postgres" comenzó a tal intensidad para volcar datos de manera bastante activa, y el disco ya no tenía tiempo para escribir, leer ...
Tomé otro servidor que ya tenía 48 procesadores con 128 gigabytes de RAM:
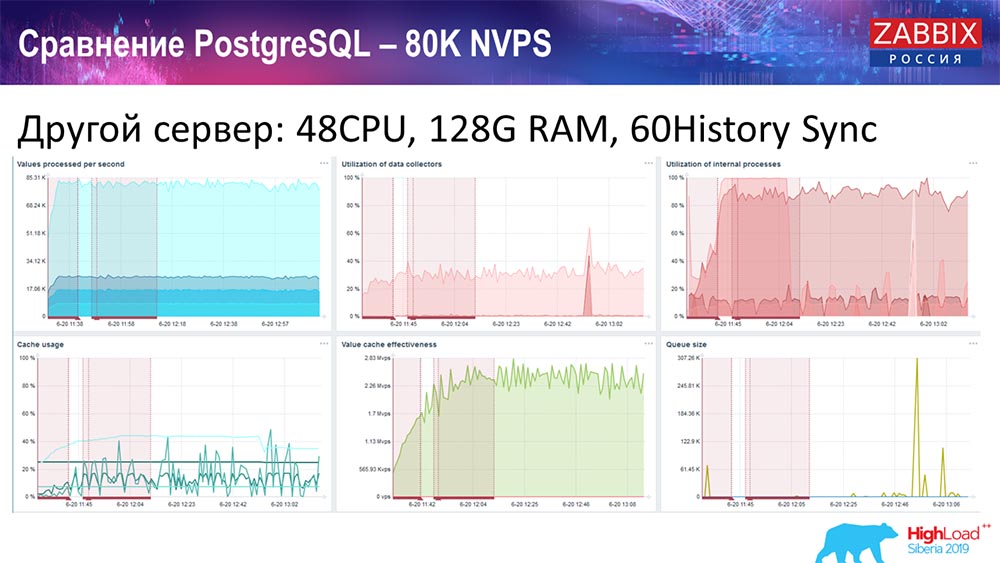
Además, lo "empañé": instalé History Syncer (60 piezas) y logré un rendimiento aceptable. De hecho, no estamos "en el estante", pero este es probablemente el límite de productividad, donde ya es necesario hacer algo al respecto.
Prueba de rendimiento. TimescaleDB: 80 mil NVP
Mi tarea principal era usar TimescaleDB. La falla es visible en cada gráfico:
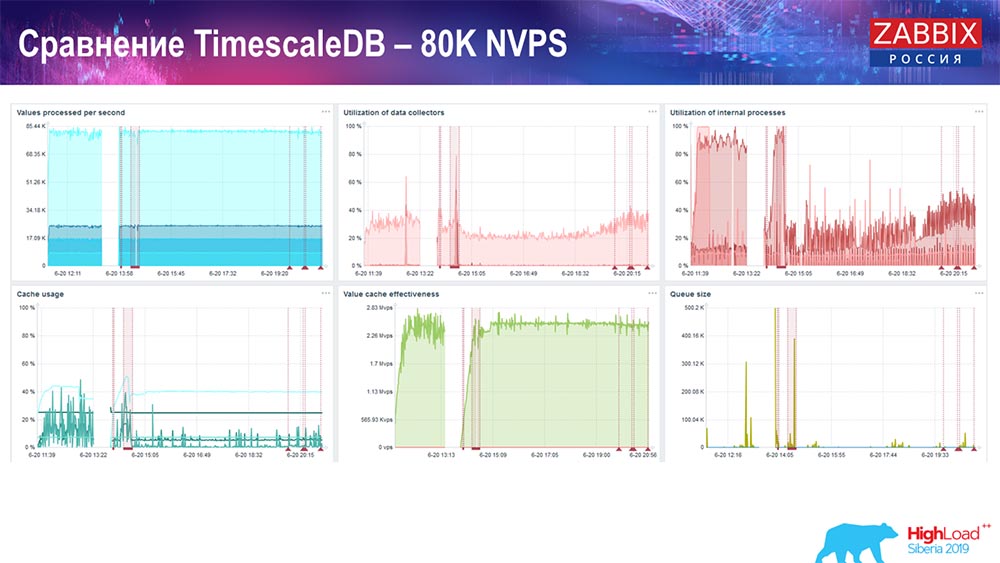
Estas caídas son solo migración de datos. Después de eso, en el servidor "Zabbix", el perfil de carga de los hundidores de la historia, como puede ver, ha cambiado mucho. 3 HistoryCache – , . , 80 – rate (, «»). setup, .
PostgreSQL: 120 NVPs
125 :

:
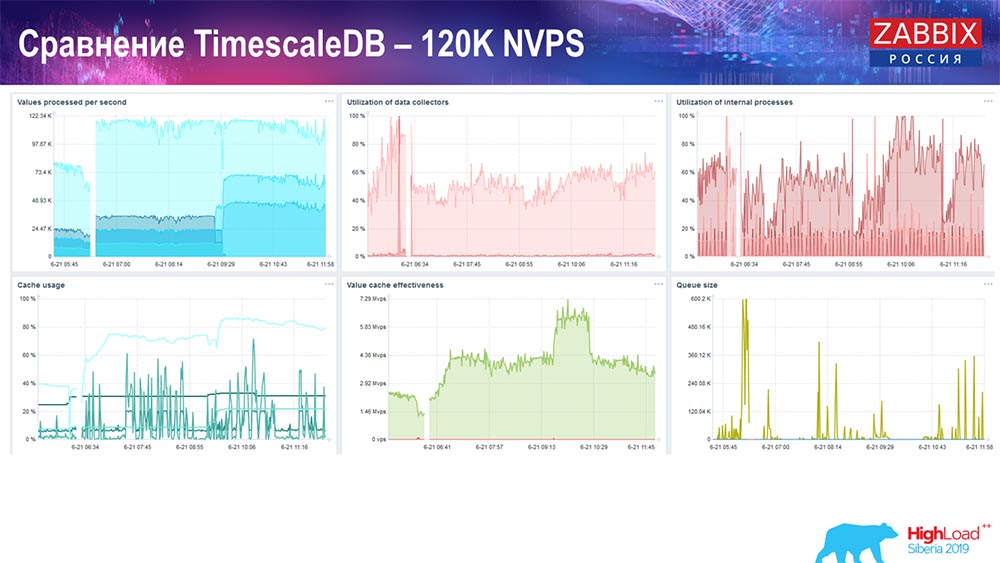
setup, . 1,5 , . , TimescaleDB, , MySQL.
, , . ! – TimescaleDB. : 120 .
«» :
TimescaleDB io.weight ; TimescaleDB. , ( SSD)!
- setup', , TimescaleDB, , . , .
: Conference – , Summit – . – «», , IRC. - – , .
( – ): – TimescaleDB , , , , «» «»? - , -, «», «», «» , ?
 :
: – , , : «» TimescaleDB. , , , «» . , ( TimescaleDB), , ! , , .
«»: - . , . setup'. MySQL… setup' .
: – , community, «»:
. «» TimescaleDB?
: – – . TimescaleDB , - . . .
: – – «».
( ): – , delete, – , , . «», , . , , big data: «!»
«» , . , select' , – « !» ( ). Eso es todo! , .
: – SQL. , «» , – - . , , , , – Clickhouse, , - -?.. Kafka – ! - ?
: – . «» 3.4: , , ; - . . - , , «». , , , NoSQL- (, «») .
: – , , ?
: – , «» – , , . , - , , , .
: – , , «», ?
: – . , , , «» , . . : . – , – Grafana -.
:- Es decir, estamos hablando de una lucha igualitaria, y no de la gran ventaja de estas bases de datos rápidas.AG: Creo que cuando integremos, habrá pruebas más precisas.A: - ¿ A dónde se fue el viejo RRD? ¿Qué te hizo cambiar a bases de datos SQL? Inicialmente, en RRD, se recopilaron todas las métricas.AG: - En el RRD "Zabbix", tal vez estaba en una versión muy antigua. Siempre ha habido bases de datos SQL, un enfoque clásico. El enfoque clásico es MySQL, PostgreSQL (ya existen desde hace mucho tiempo). Tenemos una interfaz común para las bases de datos SQL y RRD, casi nunca las usamos.
Un poco de publicidad :)
Gracias por quedarte con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes? Apóyenos haciendo un pedido o recomendando a sus amigos
VPS basado en la nube para desarrolladores desde $ 4.99 , un
análogo único de servidores de nivel básico que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2697 v3 (6 núcleos) 10GB DDR4 480GB SSD 1Gbps desde $ 19 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).
Dell R730xd 2 veces más barato en el centro de datos Equinix Tier IV en Amsterdam? ¡Solo tenemos
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV desde $ 199 en los Países Bajos! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - ¡desde $ 99! Lea sobre
Cómo construir un edificio de infraestructura. clase utilizando servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo?