Basado en la discusión en el chat de la
comunidad de AWS MinskRecientemente, se han librado batallas reales por la definición de DevOps y SRE.
A pesar del hecho de que en muchos aspectos las discusiones sobre este tema ya se han agotado, incluyéndome a mí, decidí llevar a la corte la comunidad habr y mi opinión sobre este tema. Para aquellos que estén interesados, bienvenidos a cat. ¡Y que todo comience de nuevo!
Antecedentes
Entonces, en la antigüedad, un equipo separado de desarrolladores de software y administradores de servidores vivía por separado. El primero escribió con éxito el código, el segundo, usando varias palabras cálidas y afectuosas dirigidas al primero, configuró los servidores, acudió periódicamente a los desarrolladores y recibió a cambio un exhaustivo "todo funciona en mi máquina". El negocio estaba esperando el software, todo estaba inactivo, se rompía periódicamente, todos estaban nerviosos. Especialmente el que pagó por todo este desastre. Gloriosa era de la lámpara. Bueno, sí, ya sabes de dónde crecen las piernas DevOps.
Prácticas de nacimiento DevOps
Luego vinieron tíos serios y dijeron que esto no es una industria, es imposible trabajar así. Y modelos de ciclo de vida arrastrados. Por ejemplo, un modelo V.
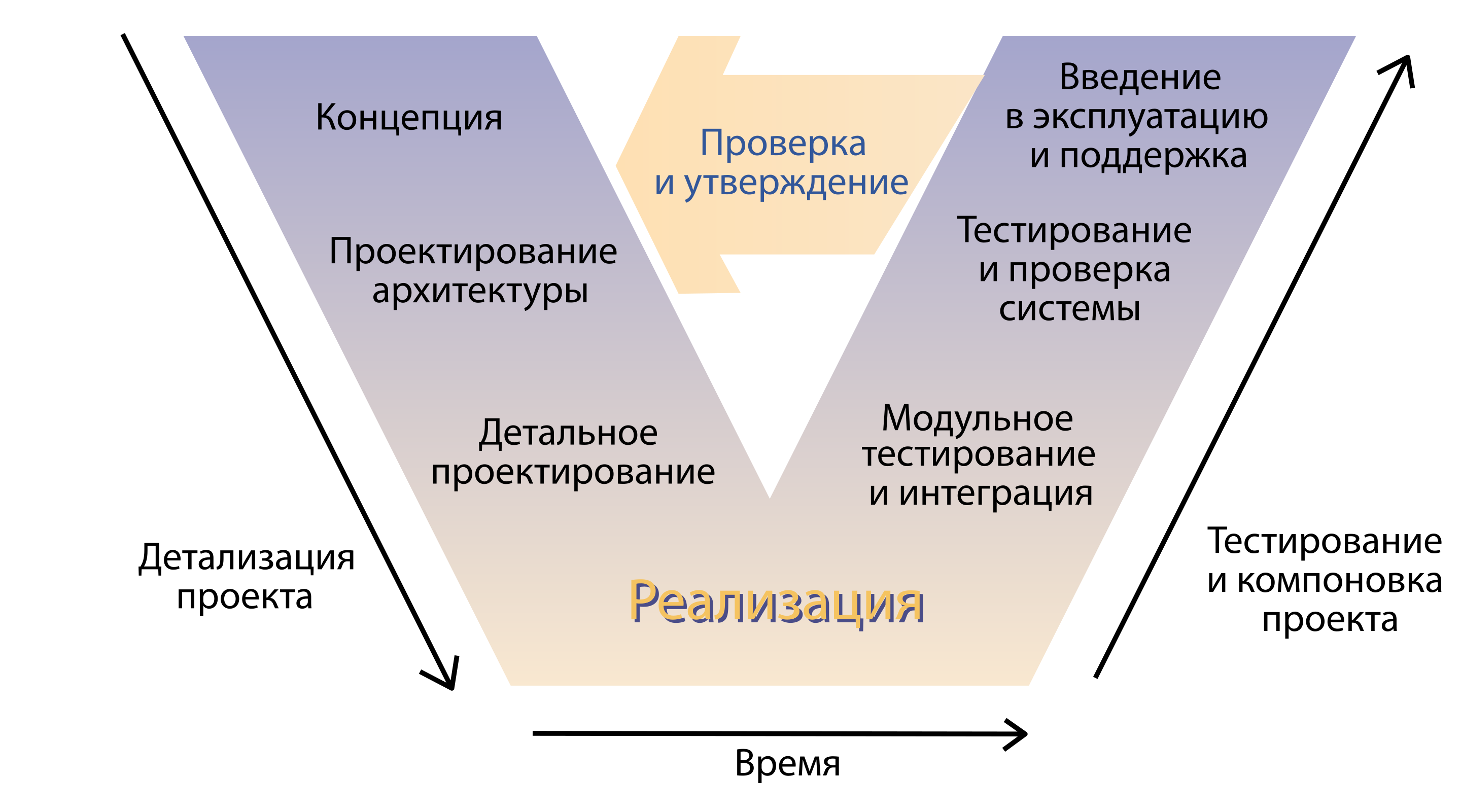
Entonces, ¿qué vemos? El negocio viene con un concepto, los arquitectos diseñan soluciones, los desarrolladores escriben código y luego fallan. Alguien de alguna manera prueba el producto, alguien de alguna manera lo entrega al usuario final, y en algún lugar a la salida de este modelo milagroso, un cliente comercial solitario se sienta y espera el clima prometido por el mar. Llegamos a la conclusión de que necesitamos métodos que permitan establecer este proceso. Y decidieron crear prácticas que los implementaran.
Digresión lírica sobre lo que es la práctica
Por práctica, me refiero a un montón de tecnología y disciplina. Un ejemplo es la práctica de describir la infraestructura con código terraform. La disciplina es cómo describir la infraestructura con código, está en la cabeza del desarrollador, y la tecnología es la propia plataforma.
Y decidieron llamarlas prácticas de DevOps, creo que significaban desde Desarrollo hasta Operaciones. Se nos ocurrieron diferentes cosas difíciles: prácticas de CI / CD, prácticas basadas en el principio de IaC, miles de ellas. Y comenzó, los desarrolladores escriben el código, los ingenieros de DevOps transforman la descripción del sistema en forma de código en sistemas operativos (sí, el código es, desafortunadamente, solo una descripción, pero no la encarnación del sistema), la entrega está girando, y así sucesivamente. Los administradores de ayer, habiendo dominado las nuevas prácticas, se volvieron a capacitar orgullosamente como ingenieros de DevOps, y todo comenzó. Y había tarde, y había mañana ... lo siento, no desde allí.
Todo de nuevo no es gracias a Dios
Solo todo se calmó, y varios "metodólogos" astutos comenzaron a escribir gruesos libros sobre prácticas de DevOps, las disputas se encendieron en silencio, quién es un ingeniero de DevOps tan notorio y que DevOps es una cultura de producción, la insatisfacción ha vuelto a madurar. De repente, la entrega de software fue una tarea absolutamente no trivial. Cada infraestructura de desarrollo tiene su propia pila, debe recopilarla en algún lugar, debe implementar el entorno en algún lugar, aquí necesita tomcat, todavía necesita una forma complicada de iniciarlo; en general, la cabeza está agrietada. Y, por extraño que parezca, el problema se debió principalmente a la organización de procesos: esta función de entrega, como un cuello de botella, comenzó a bloquear los procesos. Además, la operación (Operaciones) no se ha cancelado. No es visible en el modelo V, y existe el ciclo de vida completo a la derecha. Como resultado, es necesario apoyar de alguna manera la infraestructura, observar el monitoreo y resolver incidentes, e incluso lidiar con la entrega. Es decir sentarse con un pie tanto en desarrollo como en operación, y de repente resultó tal Desarrollo y Operaciones. Y luego hubo una exageración masiva para microservicios. Y con ellos, el desarrollo de las máquinas locales comenzó a moverse a la nube: intente depurar algo localmente, si hay docenas y cientos de microservicios, aquí la entrega constante se convierte en un medio de supervivencia. Para la "pequeña empresa modesta" todavía no importaba dónde, ¿pero aún así? ¿Qué hay de Google?
Google SRE
Google llegó, se comió los cactus más grandes y decidió: no necesitamos esto, necesitamos confiabilidad. Y la fiabilidad debe ser gestionada. Y decidí: necesitamos especialistas que gestionen la fiabilidad. Los llamó ingenieros SR y les dijo: aquí están, háganlo como siempre, bueno. Aquí tienes SLI, aquí tienes SLO, aquí tienes monitoreo. Y asomó la nariz en las operaciones. Y llamó a su "DevOps confiable" SRE. Todo parece estar bien, pero hay un truco sucio que Google podría permitirse: contratar personas que tenían las habilidades de los desarrolladores y que
cosían un poco más en casa y entendían el funcionamiento de los sistemas de trabajo como ingenieros de SR. Además, contratar a esas personas y a Google en sí tiene problemas, principalmente porque aquí compite consigo mismo, es necesario describir la lógica comercial a alguien. La entrega fue colgada por los ingenieros de lanzamiento, SR: los ingenieros administran la confiabilidad (por supuesto, no directamente, sino que influyen en la infraestructura, cambian la arquitectura, rastrean los cambios y los indicadores, tratan los incidentes). Bien, puedes
escribir libros . Pero, ¿qué pasa si no eres Google, pero la confiabilidad todavía te preocupa de alguna manera?
Desarrollando ideas de DevOps
Fue justo a tiempo para Docker, que creció de lxc, y luego varios sistemas de orquestación como Docker Swarm y Kubernetes, y los ingenieros de DevOps exhalaron: la unificación de prácticas simplificó la entrega. Simplificado hasta tal punto que incluso fue posible entregarlo a los desarrolladores: esa implementación.yaml está ahí. La contenedorización resuelve el problema. Y la madurez de los sistemas CI / CD ya está escrita en el nivel de un archivo y todo comenzó: los desarrolladores lo harán ellos mismos. Y luego comenzamos a hablar sobre cómo podemos hacer nuestro SRE, con ... sí, al menos con alguien.
SRE no está en Google
Bueno, bien, entregamos la entrega, parece que podemos exhalar, volver a los viejos tiempos, cuando los administradores observaban la carga del procesador, sintonizaban los sistemas y sorbían silenciosamente algo incomprensible de las tazas en silencio y tranquilidad ... Detente. No hicimos nada por esto (¡perdón!). De repente, resulta que en el enfoque de Google podemos tomar excelentes prácticas: no es la carga del procesador lo que importa, y no con qué frecuencia cambiamos las unidades allí o en la nube optimizamos el costo, pero las métricas comerciales son el mismo SLx notorio. Y nadie les quitó la administración de la infraestructura, y es necesario resolver incidentes, y estar de servicio periódicamente en el puesto, y en general estar en el tema de los procesos comerciales. Y chicos, comiencen a programar un poco a buen nivel, Google los ha estado esperando.
En resumen De repente, pero ya estás cansado de leer y estás ansioso por
escupir escribir al autor en el comentario sobre el artículo. DevOps como práctica de entrega, ha sido y será. Y no va a ninguna parte. SRE como un conjunto de prácticas operativas hace que esta entrega sea exitosa.