Zabbix es un popular sistema de monitoreo abierto utilizado por una gran cantidad de empresas. Hablaré sobre la experiencia de crear un clúster de monitoreo.
En el informe, menciono brevemente los cambios realizados anteriormente (parches), que amplían significativamente las capacidades del sistema y preparan la base para el clúster (cargando el historial a "Clickhouse", sondeo asíncrono). Y consideraré en detalle los problemas que surgieron durante la agrupación del sistema: resolución de conflictos de identidad en la base de datos, un poco sobre el teorema CAP y el monitoreo con bases de datos distribuidas, sobre los matices de Zabbix trabajando en modo de clúster: copia de seguridad y coordinación de servidores y servidores proxy, sobre "monitoreo de dominios" y una nueva apariencia en la arquitectura del sistema.
Hablaré brevemente sobre cómo iniciar un clúster en casa, dónde obtener las fuentes y qué otras adicionales. la configuración será necesaria para el clúster.

HighLoad ++ Siberia 2019. Tomsk Hall. 24 de junio, 5 p.m. Resúmenes y
presentación . La próxima conferencia HighLoad ++ se llevará a cabo los días 6 y 7 de abril de 2020 en San Petersburgo. Detalles y entradas
aquí .
Mikhaili Makurov (en adelante, MM): - Trabajo para una empresa proveedora. El proveedor se llama Intersvyaz, trabaja en la ciudad de Chelyabinsk. Tenemos aproximadamente 1,5 millones de personas. Y para que el proveedor trabaje, hay una gran infraestructura. Tenemos alrededor de 70 mil equipos: interruptores, dispositivos IoT ... - mucho de todo lo que necesita ser monitoreado. Específicamente, este informe trata sobre el uso de Zabbix, sobre la construcción de un clúster basado en Zabbix para el monitoreo de la infraestructura.
Tengo 12 años en el proveedor. Ahora no estoy haciendo nada técnico, se trata más de administrar personas. Y esto (material técnico) es en realidad mi hobby. Desarrollaré este tema un poco.
Problemas de monitoreo
Creo que tengo suerte. Hace aproximadamente un año y medio, terminé en un proyecto que sonaba así: "Necesitamos resolver algunos problemas con nuestro monitoreo". Heredé una zona de responsabilidad (monitoreo), que consistía en un grupo de servidores, específicamente de 21 servidores:

Había 4 servidores potentes y 15 servidores proxy: todo era hardware. Hubo algunas quejas sobre este monitoreo. La primera es que fue mucho. No tenemos un solo servidor con el proveedor que ocupe tanto espacio. Esto es dinero, electricidad ... De hecho, este no es un gran problema.

El gran problema era que el monitoreo no se mantenía al día con lo mucho que queríamos de él. Para aquellos que no han usado Zabbix de manera activa, este es un tablero que muestra la tardanza en los cheques:

La mayoría de nuestros cheques estaban en la zona roja. Corrieron más de 10 minutos más lento de lo que queríamos, es decir, llegaron 10 minutos tarde. No fue muy agradable, pero aún era posible vivir más o menos. El mayor problema fue este:

Era un sistema de monitoreo de una red en funcionamiento. Cuando se realizó el trabajo planificado, un segmento de miles se cayó en cinco interruptores. Junto con estos interruptores, el interruptor y la supervisión quedaron en el olvido. Cuando todo fue restaurado, dos horas más tarde y la supervisión fue restaurada. Fue dolorosamente desagradable, y esta frase debería estar en cada informe:

"¡Debemos hacer algo con este proyecto!"
Y aquí contaré dos historias. Luego intentamos ir simultáneamente de dos maneras. Tenemos un grupo de integración: eligió la forma de construir un sistema modular (hubo un informe muy bueno de Avito a Highload en noviembre del año pasado en Moscú; hablaron sobre esto):

Zabbix = personas + API + eficiencia
Los chicos de pequeñas piezas comenzaron a construir un sistema. Y con varios entusiastas, seguí trabajando en Zabbix. Había razones para eso. Cuales son las razones?
- En primer lugar, hay una API genial. Y cuando tiene 60-70 mil elementos de monitoreo, está claro que todo esto funciona solo automáticamente: no puede agregar tantas manos sin errores.
- Personal Hay turnos de monitoreo en servicio que se encuentran 24/7. Estos no son especialistas de TI, son personas de servicio. Le mostramos al "Grafan" algunos otros sistemas, es difícil para ellos. Hay administradores que están acostumbrados a la diversidad, la conveniencia de monitorear en el propio Zabbix: plantillas, detección automática, ¡y eso es genial!
- Zabbix puede ser efectivo.
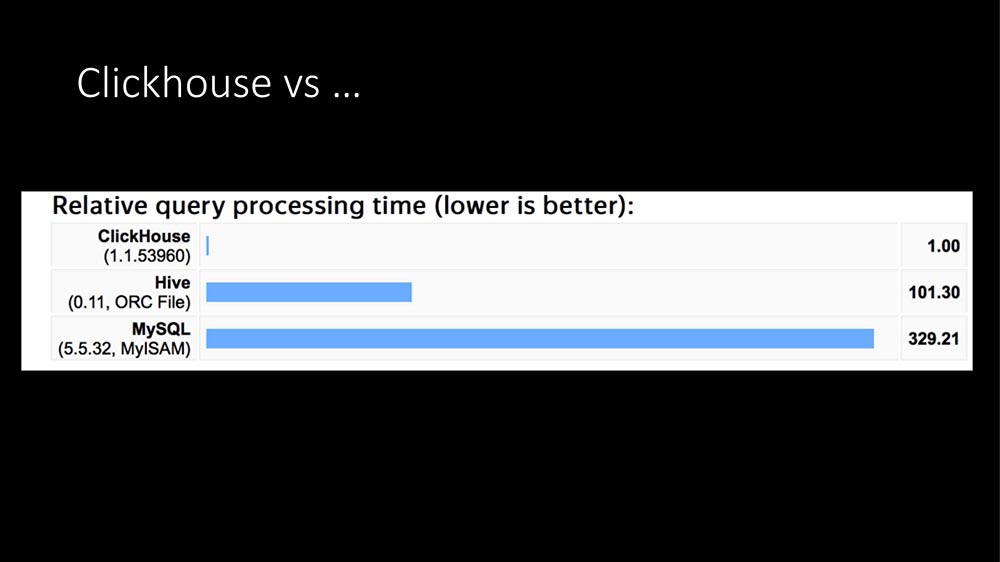
¿La base de datos SQL se ralentiza? Una respuesta - Clickhouse
La primera razón era obvia. Luego trabajamos en MySQL, y encontramos alrededor de 6-7 mil métricas por segundo, vimos constantes retrasos en los discos.

Hoy ya ha sonado 100 veces: la única respuesta es Clickhouse:
En la estructura de las consultas, la mayor parte de las consultas (nuestro perfil en unas pocas horas) son registros de métricas. Escribir métricas en una base de datos SQL es extremadamente costoso. Aquí apareció TimeScaleDB ... Luego tuvimos un "Clickhouse" en funcionamiento durante aproximadamente un año para otras tareas (hacemos grandes datos, tenemos una gran aplicación; en general, un proveedor ahora es un negocio de TI completo).
Después de mirar hermosos gráficos de Internet (que "Clickhouse" es cientos de veces más rápido, que necesita muy poco espacio) y tener experiencia actual, escribimos nuestro módulo HistoryStorage para "Zabbix" para que pueda guardar los datos de "Clickhouse" directamente (es decir, no desde la exportación de archivos, sino directamente sobre la marcha).

Además, escribimos un módulo para el "frente". Todos estos hermosos gráficos en el panel de administración de Zabbix se pueden construir desde Clickhouse. Está claro que la API también funciona.
El efecto es aproximadamente el mismo: el servidor SQL como entidad dedicada no se volvió completamente, es decir, la carga cayó a cero. Lo que es más notable, ya teníamos un clúster dedicado "Clickhouse": cuando dimos toda nuestra carga allí, aumentó de 6 a 10 mil métricas. Los muchachos que administran dijeron: "Pero no vemos algo que haya sucedido. ¡No!
Cómo expandimos Clickhouse
Diré aún más: para las pruebas, intentamos cargar hasta 140-150 mil métricas por segundo (ya no pudimos exprimirnos de Zabbix, luego diré por qué), y Clickhouse tampoco ve esta carga. Es decir, es muy cómodo, carga fresca. En general, existe tal módulo.
Además, lo expandimos un poco:

En nuestra versión, puede desactivar los nanosegundos. Probablemente lo sepas: Zabbix escribe segundos y nanosegundos en dos campos. En los campos "Clickhouse" en los que la variabilidad es muy grande, ocupe mucho espacio.
Por cierto, sobre el lugar. Una métrica en Clickhouse (ahora tenemos aproximadamente 700 mil millones de métricas registradas) ocupa 2.9 bytes. Según la documentación de Zabbix, una métrica en las bases de datos SQL toma de 40 a 100 bytes. Apagar los nanosegundos ahorra otro 40%, es decir, aproximadamente 1,5 bytes por métrica. Es decir, "Clickhouse" es muy efectivo en términos de ubicación.
A pedido de nuestros muchachos que se dedican al aprendizaje automático, hicimos una opción para poder escribir el host y el nombre de la métrica. Dado que la variabilidad de los datos es grande, esto no ocupa mucho espacio adicional, a pesar de que los datos de texto pueden ser significativos (aún no se han verificado con pruebas largas).
Además, hicimos dos adiciones, ya que desarrollamos Zabbix y a menudo tuvimos que sacarlo. Una adición muy interesante: al principio, ya que "Clickhouse" le permite leer millones de registros, podemos llenar el caché del historial. Al principio, nos demoramos 30-40 segundos adicionales, pero recibimos un servicio lanzado de inmediato con un caché calentado.
En los casos en que es más fácil recolectar de la infraestructura, todavía existe esa opción: prohibir la lectura del caché por algún tiempo. Es mejor trabajar rápidamente durante 5 minutos, sin contar los desencadenantes, y luego el caché se llenará; si no lo hace, comienza el estancamiento de los hundidores de la historia.
En general, hay un módulo "Clickhouse". Se puede usar.
Eficiencia de sondeo
A pesar del hecho de que luego resolvimos los problemas con la base, los frenos y el problema con quince proxies aún permanecían. Estaban conectados con esto:

Esta es la principal tubería de procesamiento de datos en Zabbix. Hay una etapa de recopilación de datos, hay un preprocesamiento y hay sincerizadores históricos que hacen todo el trabajo (cálculo de disparadores, alertas, historial de guardado). El cuello de botella del caché resultó ser:

¿Por qué el sondeo es lento? Porque los subprocesos que realizan las solicitudes van a la cola en la configuración de la memoria caché para las métricas de la unidad y la bloquean. Hay otros lugares, pero no son tan estrechos. Por ejemplo, hay un preprocesamiento en sí mismo y hay Historial de caché. En nuestro SQL, obtuvimos las siguientes restricciones:

Quizás esto se deba al hecho de que en nuestro caso, la base es de aproximadamente 5 millones de métricas, que eliminamos. Con todas las optimizaciones que hicimos, pudimos obtener 70 mil métricas en el cuello de botella (en la caché de configuración), pero solo en el caso cuando las procesamos en masa.
¿Qué es el procesamiento a granel? Poller va a la caché de configuración y toma la tarea no para una métrica, sino para 4 u 8 mil. Al mismo tiempo, obtiene otra oportunidad maravillosa: ahora puede hacer encuestas de forma asincrónica, porque obtuvo 4 mil métricas ... ¿Por qué lo hacen una tras otra? ¡Puedes preguntar todo de inmediato!
¡El sondeo asincrónico es más eficiente que el proxy!
Para los tipos principales que usa el proveedor, estos son SNMP y AGENT, reescribimos el sondeo a modo asíncrono, y de manera agregada esto aumentó la velocidad de 100 a 200 veces. Teníamos 15 proxies, los dividimos en 150, se habían ido por completo. Como resultado, todo se convirtió en dos bancos, que son necesarios solo para la reserva:

Banco uniprocesador (un Xeon 1280 cuesta). Este es el momento de dle:

Alrededor del 60% es gratuito, pero este timbre del 60% al 40% se ejecuta en secuencias de comandos periódicas en la máquina (secuencias de comandos externas). Se pueden optimizar hasta que se creen problemas.
La escala es algo como esto:

Estos son 62 mil hosts, aproximadamente 5 millones de métricas. Nuestra necesidad actual es de aproximadamente 20 mil métricas por segundo.
Bueno, como todo? Resolvimos los problemas de rendimiento, la historia se expandió, el sondeo es increíble. ¿Se resolvió el problema? En realidad no ... Todo sería demasiado simple.
Jugué un truco en el gráfico anterior (no todos se muestran):

Hay dos problemas Quiero decir: "Tontos, caminos". Hay un factor humano, hay equipos.
Un servidor todavía no es suficiente. En aproximadamente un año de funcionamiento, ha habido dos casos con problemas de hardware: una unidad SSD y algo más. La mayoría de los problemas son el factor humano cuando las personas hacen algún tipo de prueba. En nuestra empresa, Zabbix se utiliza como un servicio: todos los departamentos pueden escribir algo propio allí.
Me gustaría ampliar Me gustaría no depender de una lata. Quería que pudiéramos seguir siendo más fuertes. Y me gustaría escalar de acuerdo con el principio de escalamiento horizontal. Incluso no hay nada que discutir aquí: crecer, aumentar la capacidad de una lata, ha sido irrelevante durante 20 años.

El clúster solicitó ...
En algún lugar de diciembre, apareció la primera versión. Una unidad de clúster atómico es lo que se procesa en un host separado. El anfitrión ha sido seleccionado.

El hecho es que en Zabbix hay conexiones bastante fuertes entre los elementos que pueden estar en el mismo host, es decir, los disparadores se pueden conectar, se pueden procesar juntos en el preprocesamiento. Pero entre los hosts la conectividad no es tan alta, por lo que es normal usar este clúster entre los nodos del clúster; habrá mucho tráfico allí. La tarea principal de los clústeres es acordar entre ellos quién participa en qué hosts.
Me gustaría superar nuestro límite máximo de 60-70 mil métricas, porque el apetito viene con la comida. Tenemos personas que se dedican a QoE ... Calidad de experiencia: un análisis de cómo funciona Internet para los suscriptores en función de las métricas de tránsito, es decir, usted suministra todas las métricas TCP a 1,5 millones de personas, vertiéndolas en el monitoreo: hay muchos datos.
Y quería fiabilidad. Lo quería si algo sucedía ... El oficial de turno llamó y dijo: "Tenemos problemas con el servidor", lo apagó, lo resolveremos mañana.
Primer grupo
La primera versión se implementó en base a etcd:

Etcd es un almacenamiento distribuido de valor clave utilizado en muchos proyectos progresivos (hasta donde yo entiendo, en Kubernetes). Todo estuvo genial. Etcd proporciona herramientas muy interesantes, por ejemplo, resuelve el problema de elegir el servidor principal. Pero tal problema ...
Teníamos un clásico "Zabbix" de tres enlaces: "web" - la base - el servidor mismo. Y agregamos "Clickhouse" allí, y ahora también agregamos etcd. Los administradores comenzaron a rascarse detrás de sus cabezas: hay demasiadas dependencias aquí, probablemente no será confiable. En el proceso de desarrollo, una cosa más se hizo evidente: en el propio Zabbix ya existe una forma integrada de comunicación entre servidores, solo se usa entre el servidor y el proxy, el llamado proceso de sondeo proxy:

Es bastante bueno para la comunicación entre servidores con cambios mínimos. Esto permitió que etcd no se usara (al menos temporalmente), simplificaría enormemente el código y, lo más importante, trabajaría en el código que ha sido verificado (parece que este código tiene 5 o 7 años).
¿Cómo se coordinan los servidores en un clúster?
La coordinación se realiza por tipo, como el protocolo IGP. Para que los servidores tengan prioridad (ahora diré por qué esto es necesario) y para evitar conflictos en la base de datos SQL al escribir registros, a cada servidor se le asigna un identificador (hasta ahora de forma manual): este es un número del 0 al 63 (63 - es solo una constante, tal vez más):

El servidor con el identificador máximo se convierte en el "maestro". Cuando lanzamos nuestros primeros grupos de prueba, lo primero que dijeron nuestros administradores fue: “¡Guau! Y vamos a ponerlos en diferentes sitios. ¡Bien, genial! ”(Volveremos a esto). Y cuando alguien ha distribuido clústeres, será posible controlar cómo se redistribuye la topología: dónde irá el papel del "maestro" en caso de una caída en el servidor principal "Zabbix":

En este caso, así:

Pisar
En el Zabbix original, esto se hace así: el servidor mismo es responsable de generar índices de incremento automático. Para evitar que muchas instancias pisen los talones de la otra (para no crear registros con los mismos índices), se usa la operación de pasos: "Zabbix" con el identificador "1" generará múltiplos de uno: 1, 11, 21; con el identificador "7" - 7, 17, 27 (con matices).
Manejamos con modificadores.

¿Cómo interactúan los servidores entre sí?
Este es el legado de los paquetes Hello de IGP cada 5 segundos. Entonces los servidores saben que tienen vecinos. Por lo tanto, el "maestro" sabe que hay vecinos cercanos, y sobre la base de esto, el "maestro" decide qué hosts se pueden distribuir a qué servidores.

En consecuencia, hay una configuración. Según la memoria anterior, lo llamo topología. Una topología es esencialmente una lista de servidores y hosts que les pertenecen.
El protocolo es simple: este es JSON:

Este es también el legado del proxy Zabbix y la comunicación del servidor Zabbix. En general, no tiene sentido usar otra cosa. Lo único es que en el caso de Zabbix hay 4 bytes (ZBXD), pero este no es el punto.
En el paquete de saludo, el identificador del servidor se transmite: cuando el servidor envía el paquete, dice su identificador y su versión de la topología, de esta manera los servidores descubren rápidamente que hay una nueva versión de la topología y se actualizan muy rápidamente.
En realidad, la topología en sí misma es solo un árbol, una lista de servidores. Para cada servidor, una lista de hosts que admite:

Y entonces surge un problema interesante.
Existe una frase tan mágica: monitorear dominios
Cual es el punto? En el clásico Zabbix, todo era simple: una actitud inequívoca: este proxy es monitoreado por este proxy, este proxy proporciona datos al servidor. Si el proxy no se ha instalado (o no es necesario), este servidor supervisa todos los hosts:

Cuando tenemos muchos servidores, ¿qué hacer? Además, puede haber un problema con el hecho de que tenemos servidores distribuidos geográficamente, y el servidor en alguna oficina que trabaja lentamente en Kemerovo comenzará a tratar de monitorear toda la infraestructura de Novosibirsk.

No queremos esto. Queremos tener algún tipo de mecanismo para que no todos los servidores, pero los que seleccionamos (posiblemente basados en la geografía) puedan monitorear un host en particular. Al mismo tiempo, queremos gestionar esto, y queremos que sea simple. Para esto, se inventó la idea de monitorear dominios. De hecho, estos son grupos simples, simplemente ya hay grupos en el registro.
Y cuando hice esto, los chicos de la operación hablaron conmigo: me dijeron: “Los grupos nos confunden mucho. Siempre empezamos a pensar en grupos normales ". Por lo tanto, este nombre: monitoreo de dominios.
Los hosts se relacionan inequívocamente: un host - un dominio:

El dominio del host puede incluir cualquier número de servidores. Los servidores pueden estar en cualquier número de dominios. Esto es algo muy flexible. Para expandir la flexibilidad y romper completamente el cerebro, también hay un dominio predeterminado:

Los servidores que son miembros del dominio predeterminado son monitoreados por todos los hosts que no tienen servidores activos o que no tienen un dominio de monitoreo.
Esto solo nos permite vincular topológicamente los hosts a algunos servidores y controlar cómo se distribuyen los hosts en caso de que un servidor se caiga:

El siguiente problema que encontramos ...
Cluster: Piensa diferente
Cuando tenemos muchos servidores, hay nuevas oportunidades para construir un clúster, para construir una topología. Este es un clásico cuando tenemos algún tipo de sitio central y hay sitios remotos; o, por ejemplo, un proxy donde se delega la carga:

En el caso del clúster Zabbix, se puede implementar de dos maneras. Puede seguir el camino clásico: simplemente duplique la infraestructura. En el centro, tenemos dos servidores que forman un clúster, pueden reorganizar los hosts o asumir la carga si el vecino se cae. En consecuencia, puede aumentar los servidores proxy adicionales en los mismos servidores; obtenemos una doble reserva:

Puede usar las nuevas "características" y hacer esto:

Lo principal es no ir a una situación en la que un servidor geográficamente remoto esté monitoreando una infraestructura grande en otro lugar. Esto es más un problema de administración (lo llamo negocio) porque es un problema de configuración.
Clúster: cerebro dividido y punto de vista
, :
- split brain;
- point of view ( ).
. Split brain – , . , - – ? , , ( ).
point of view : , , , . . , RTT , .
:

, . , , . , – . , , , .
SQL-
, , , . . , , … . .
-, , , - – . , Galera MySQL.
PostgreSQL. «» : , , – . «», , .
?
, :


– . :
- - (Logs), . problems, events events recovery. , – , .
- 15 (State). – ( – – «» ). . , ; – …
- - (Configuration update).
«. «», SQL-:

-, :

. -, , … – , 2 ! : « , ». - , , .
. , :

, . SQL- . , SQL-. ( - ), «» ( ). …
.
, , «» . . , ?

«»- (. . «» daemon). ( ): ( 1 63, «») ( , ).
ServerIP IP-. , , IP- . - , proxy poller, trapper hello-, proxy poller .
. , , « »:

:

, default. . – , IP-, , ( ). «» – default.
-, .
- .
- , : « , ». .
- - , .
- , hello-time, : « »; .
- .
, , , . 30-40 . , , , .
, . - : « , !» -!

– : - , - , , GitLab, CI/CD, . , , – .
, , – 4.0.9 (4.2 ). Roadmap – -. -, «»; , RPM'.

( ) «» «»-. . , . – : , - … ? !.. «», .
SQL- , , . History Storage.
Referencias
5 . .
-, , , , . . -.

, ? ! , , , . - - , . , , . , :

. «»- , .
- , , , .
- «» : , Configuration Cache, .
- , , . , , .
- - , . , , . 200 , – .
Nota: ¡el proxy pasivo aún no es compatible!Quité el código. Esto se debe al hecho de que es difícil para las personas crear otro mecanismo, cuyo servidor seguirá siendo responsable de este proxy.Los proxies activos mismos van a los servidores. Hay una opción de servidor para esto (proxy estándar). El proxy modificado tiene la opción Servidores: ¿Y qué hace un servidor modificado? Mantiene una conexión KPI con todos los servidores especificados para ello; pide configuración, envía datos al primer servidor disponible de la lista. Esto resuelve el problema. Suponga que si tiene un proxy configurado en el servidor Zabbix y el servidor Zabbix se ha caído, hay otro en el clúster para no quedarse sin proxy; entonces el proxy simplemente se conecta a otro.
¿Y qué hace un servidor modificado? Mantiene una conexión KPI con todos los servidores especificados para ello; pide configuración, envía datos al primer servidor disponible de la lista. Esto resuelve el problema. Suponga que si tiene un proxy configurado en el servidor Zabbix y el servidor Zabbix se ha caído, hay otro en el clúster para no quedarse sin proxy; entonces el proxy simplemente se conecta a otro.Preguntas
Pregunta de la audiencia (en adelante - A): - Me gustaría aclarar cómo están sucediendo las cosas entre los servidores. ¿Con qué protocolo se comunican? ¿Hay algún tipo de seguridad? Porque no es muy "seguro" llevar la comunicación entre servidores a Internet ... ¿Cómo va esto?
MM: - Creo que este es un candidato para la mejor pregunta, ¡hasta el punto! De hecho, cuando cambiamos a la comunicación estándar, los servidores para su comunicación entre servidores heredaron todas esas características de protocolo de comunicación que existen entre el servidor y el proxy. Aclararé: hay cifrado, compresión de datos. Por favor, de la misma manera, todo se configura a través de la web, ya que está configurado de forma estándar para el servidor y el proxy; Todo funcionará.
R: - ¿Cómo trabaja Hauskiper para usted en el caso de Clickhouse?
MM: - En el "Zabbix" estándar no hay una interfaz del "Ama de llaves" a la Interfaz de historial, es decir, la Interfaz de historial no admite la rotación de datos (ElasticSearch, por ejemplo, no es compatible). Tal vez en 4.2 es (no miré), pero hasta ahora en 4.0.9.
¡Hazlo fácil! El nuevo "Clickhouse" tiene una partición. Me gustaría hacerlo desactivando particiones obsoletas. Está claro que no habrá rotación a nivel de elementos individuales, pero hay un truco en Zabbix: puede especificar valores globales (por ejemplo, almacenar el historial completo durante no más de 90 días): puede borrar todos los elementos, todo el historial de estos valores globales. . ¡Y se hará! Hay más sobre este tema en Gitlab.
Queremos hacer el derecho arquitectónico: expandir la interfaz de la historia, para que básicamente sea ... En general, no quiero dejar deuda técnica, pero se hará. Debido a que es necesario, más "Clickhouse" comenzó a apoyar.
A: - ¿Cómo te sientes acerca de esto? Resulta que usted está haciendo una gran cantidad de trabajo sin proveedores.
MM: - Probablemente no lo puse muy correctamente. Este es mi hobby! Realmente no soy un especialista técnico, soy un gerente. En mi tiempo libre practico.
R: - Pensé que estabas haciendo esto como parte de tu negocio principal ...
MM: - Los negocios me dan un lugar genial para probar. De hecho, lo recomiendo: alivia el cerebro. En algún lugar de la "cosa" administrativa diría esto, cuando puedes cambiar de problemas humanos a estos. ¡Están tan bien resueltos! Estos son problemas técnicos. ¡Usted programó, y funciona de la manera que programó! Es una pena que la gente no deba hacer eso.
R: - ¿Escribe a "Clickhouse" a través de algún proxy o directamente?
MM: - Directamente. De hecho, la interfaz de historial alterada, que se utiliza para el "Elastix", también se hereda. Se utiliza la url, es decir, a través de la interfaz http "Zabbiks" envía "Clickhouse". Lo que es genial, Zabbix agrega cuando hay una gran corriente de historia, miles de métricas en un paquete, y esto cae muy bien en Clickhouse.
A: - De hecho, ¿escribe bachi para él?
MM: Sí. Una consulta SQL ejecutada por la url generalmente contiene mil métricas. Administradores "Clickhouse" simplemente feliz.
Presentador: - Este es el final del programa en esta sala. Hay un programa nocturno organizado y hay algo que solo tú puedes hacer. Y le sugiero, mientras se comuniquen entre sí, que piensen en las cosas interesantes que pueden ... Cuando se cuentan sus casos, lo más probable es que de esto puedan hablar. Al conversar entre ellos, pueden encontrar solo un resumen: el comité del programa aceptará su solicitud, la considerará y ayudará a hacer una buena historia. ¿Quizás tenga algún tipo de historia sobre trabajar con el comité del programa?
MM: - En realidad, se dan muchos comentarios. Tuve mucha suerte: una persona del comité del programa vive en mi Chelyabinsk, y Highload es la única conferencia que trabaja tan estrechamente con los oradores. Nunca he visto algo así en ningún otro lado. ¡Es muy beneficioso! Diferentes etapas: los chicos miran el video, hacen comentarios en las diapositivas; realmente sucede en el tema (ortografía, errores tipográficos). Muy guay! Lo recomiendo Pruébalo tú mismo!
Un poco de publicidad :)
Gracias por quedarte con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes? Apóyenos haciendo un pedido o recomendando a sus amigos
VPS basado en la nube para desarrolladores desde $ 4.99 , un
análogo único de servidores de nivel básico que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2697 v3 (6 núcleos) 10GB DDR4 480GB SSD 1Gbps desde $ 19 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).
Dell R730xd 2 veces más barato en el centro de datos Equinix Tier IV en Amsterdam? ¡Solo tenemos
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV desde $ 199 en los Países Bajos! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - ¡desde $ 99! Lea sobre
Cómo construir un edificio de infraestructura. clase utilizando servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo?