Hace mucho tiempo, en la lejana galaxia solar, incluso antes de que se convirtiera en parte del universo Rostelecom, surgió un pequeño producto webProxy que no solo necesitaba filtrar el tráfico de red, sino también generar estadísticas sobre él con su almacenamiento posterior. En ese momento, las bases de datos de columnas no eran tan populares como lo son ahora. El único análogo adecuado era la base de datos paga de HP Vertica. Cómo en la galaxia solar resolvieron este problema y a qué llegaron finalmente, lo diremos debajo del corte.

Primero, decidimos crear nuestra propia base de datos. Como resultado, se escribió en OCaml con almacenamiento binario de columnas (las representaciones de texto se comprimieron a través de lz4) y su propio lenguaje de consulta bastante flexible sobre expresiones S. El particionamiento se realizó por día.
Solicitar ejemplo:

No era la opción más conveniente y rápida, sino ampliable y personalizable.
Pasó el tiempo, al igual que la necesidad de acelerar la construcción de estadísticas e informes de tráfico. Por lo tanto, comenzamos a considerar otras opciones:
- postgres puros;
- Postgres + cstore_fdw;
- Clickhouse;
- Elástico
Comparación de Postgres vs Elastic
En la primera etapa, comparamos Elastic y Postgres + cstore. Postgres se consideró más de cerca, porque ya se usaba en el sistema y había experiencia disponible para trabajar con él.
Elastic también se utilizó activamente en la empresa. A pesar del "atractivo" de la búsqueda de texto completo y su velocidad, Elastic tuvo que abandonarse debido al demasiado volumen ocupado por los datos en el disco. En términos de velocidad, Elastic ganó en consultas simples aproximadamente 3 veces, por ejemplo, en la consulta "TOP 20 sitios en una semana". Y en los más complejos, hasta 9 veces: "Los 20 mejores sitios para el tráfico por mes".
Sin embargo, fue mejor que su propia base, que tardó minutos en hacerlo versus 5-6 segundos en Elastic y 15-55 segundos en Postgres.
Comparación entre Postgres y Clickhouse
Datos de origen
Con https://github.com/wizardjedi/clickhouse-test tomamos contenedores con Postgres y Clickhouse. Estos contenedores fueron diseñados para crear tablas.
Vista de tabla para Postgres:

La clave primaria tuvo que ser eliminada, ya que la tabla externa en Postgres no permite esto.
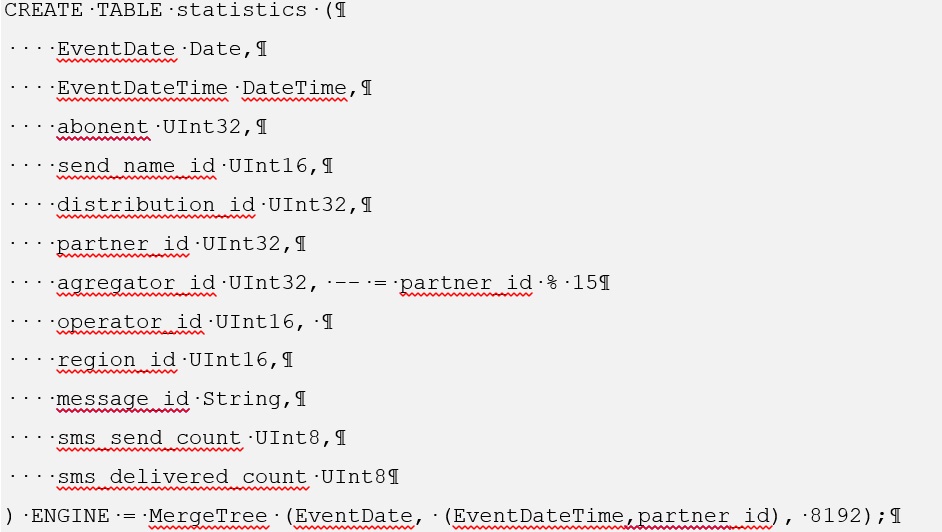
Para Clickhouse, la creación de dicha tabla es la siguiente:
Para familiarizarse con el proceso de instalación de cstore para Postgres, vaya a https://github.com/citusdata/cstore_fdw .
Además, al instalar cstore, debe instalar el paquete postgresql-server-dev-XY
Al comparar el rendimiento, se utilizaron los siguientes tamaños de datos (en megabytes):

Los datos de origen son solo una consulta sql que enumera todas las tuplas, es decir datos en bruto
Durante la ejecución de las consultas, especialmente las pesadas, además de los datos, se midieron los tamaños de la base de datos.
Se reveló que para Clickhouse definitivamente no aumentaron.

Parámetros del sistema de computación
Fabricante: Intel
Línea: Core i5
Modelo: 8250U
Frecuencia de reloj: 1.60 GHz por núcleo
Corazones: 4
RAM: 16 GB
SSD: 256 GB
Cargando datos en una base de datos
Para tal volumen de datos en Clickhouse, se cargaron bastante rápido: 1 hora y 40 minutos (esto es por 600 millones de tuplas).
Al principio, planeamos descargar todo en un archivo, pero se mostró el error "bad_alloc". Aparentemente, debido a la incapacidad de Clickhouse para asignar memoria. No se encontró solución. Por lo tanto, 600 millones de tuplas se dividieron en 30 archivos de 20 millones cada uno. En este caso, cada archivo se descargó un poco más de 3 minutos.
Con Postgres, las cosas fueron más complicadas, pero solo al principio. La descarga de archivos sql sin formato que contienen el comando INSERT INTO <table_name> (atributos) VALUES tuples lleva mucho tiempo. Por lo tanto, todo se convirtió a formato csv y se ejecutó el comando COPY <table_name> FROM WITH CSV.
Vale la pena señalar que primero cargamos los datos en una tabla Postgres normal, desde donde los copiamos a una tabla extranjera, que es controlada por cstore. Como resultado, cargar Postgres desde un archivo csv también tomó un poco menos de dos horas.
Comparación de rendimiento
La comparación de rendimiento de Postgres y Clickhouse se muestra en la tabla a continuación. Pero sin crear índices y cambiar los parámetros de la base de datos. En algún momento, la memoria en el disco casi se agotó y, por lo tanto, se hizo necesario eliminar una tabla normal sin comprimir de Postgres. En este momento, solo las tablas están disponibles en Clickhouse y Postgres cstore.
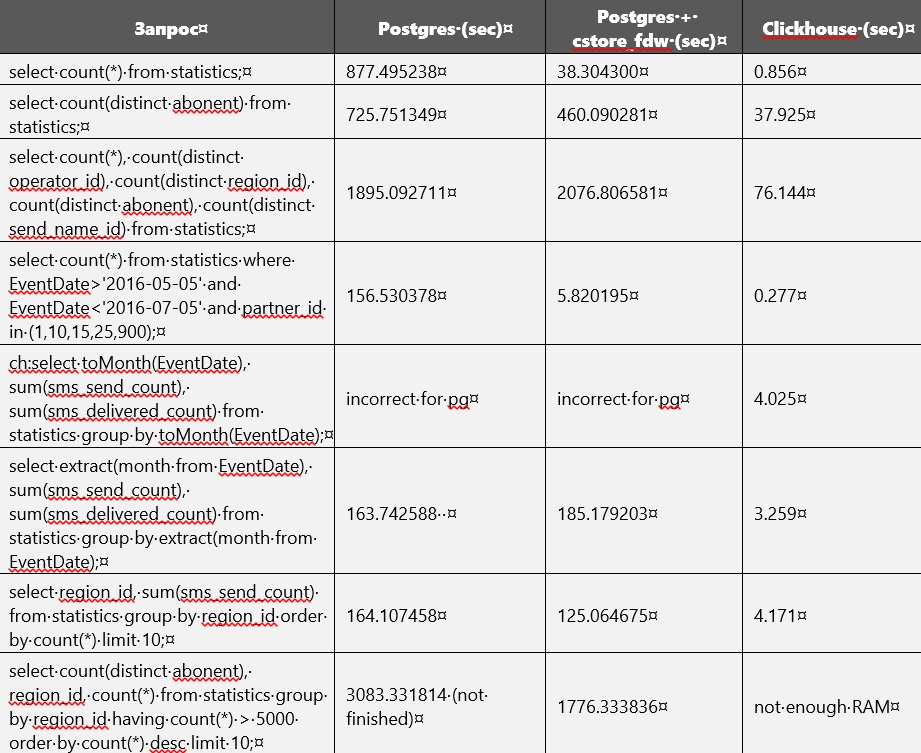
Aparentemente, cstore se enfoca en el primer atributo especificado al crearlo. En otras palabras, él ordena todos los datos por él. Esto se puede notar fácilmente, ya que las consultas relacionadas con EventDate fueron más rápidas de ejecutar en cstore que en Postgres.
Al ejecutar consultas, Postgres a veces tomaba hasta 27 GB en una unidad externa para archivos temporales.
Clickhouse ocupa mucha RAM.
En el archivo de configuración /etc/clickhouse/users.xml, se especificaron <max_memory_usage> 12000000000 </max_memory_usage> y <max_bytes_before_external_sort> 1000000000 </max_btes_before_external_sort>.
Para algunas consultas, la RAM no era suficiente, por lo que tuvimos que aumentarla. Después de eso, el procesamiento de las solicitudes continuó, pero en la última solicitud aún se interrumpió. Había varios parámetros más disponibles para limitar el consumo de memoria https://clickhouse.yandex/docs/ru/query_language/queries/ .
Dio la casualidad de que agregamos un poco más de datos a Clickhouse: 695_640_000 tuplas en lugar de 600_000_000, pero eso no le impidió ganar.
En cstore_fdw, puede configurar varios parámetros https://github.com/citusdata/cstore_fdw/issues/174 , https://github.com/citusdata/cstore_fdw , que afectan el rendimiento.
Particionamiento
En cuanto a la partición, también está en Clickhouse https://github.com/yandex/ClickHouse/blob/master/docs/ru/table_engines/custom_partition_key.md , https://clickhouse.yandex/docs/ru/table_engines/custom_partitions_key / , y en Postgres (versiones 10 y 11). Un ejemplo de particionamiento en clickhouse se puede encontrar en https://github.com/yandex/ClickHouse/blob/master/dbms/tests/queries/0_stateless/00502_custom_partitions_local.sql y https://github.com/yandex/ClickHouse/issues/1513 .
El uso de particionamiento en Postgres es posible siempre que cstore solo funcione con tablas foráneas, ya que necesita crear un servidor para él y no puede especificar el servidor para tablas normales. Una tabla extranjera no se puede dividir en particiones; en sí misma puede actuar como una partición. Por lo tanto, solo hay una forma posible de utilizar el particionamiento: cree una tabla primaria normal, puede adjuntarle tablas externas en forma de particiones, que ya funcionan en cstore_fdw.
En Clickhouse, la partición funciona de forma inmediata.
Conclusión
Como resultado, decidimos usar Clickhouse, porque es inteligente: siempre es al menos 10 veces más rápido que los análogos. En los servidores de memoria, generalmente hay más de 32 Gb, 64 y 128, por lo que las consultas en tablas de alrededor de 50 Gb funcionarán correctamente. Si la tabla es muy grande, es decir, particionar o ajustar los parámetros del servidor clickhouse ayudará.