
Recientemente, leí un libro sobre las matemáticas y la belleza de las personas y pensé en lo que hace una década, la idea de cómo entender qué belleza humana era bastante primitiva. El razonamiento sobre qué rostro se considera hermoso desde el punto de vista de las matemáticas se redujo al hecho de que debe ser simétrico. Además, desde el Renacimiento, ha habido intentos de describir caras hermosas usando las relaciones entre distancias en algunos puntos de la cara y mostrar, por ejemplo, que las caras hermosas tienen algún tipo de relación cercana a la proporción dorada. Ideas similares sobre la ubicación de puntos ahora se utilizan como uno de los métodos para identificar caras (búsqueda de puntos de referencia de caras). Sin embargo, la experiencia muestra que si no limita el conjunto de características a la posición de puntos específicos en la cara, puede lograr mejores resultados en una serie de tareas,
incluida la determinación de la edad, el sexo o incluso
la orientación sexual . Ya es evidente aquí que la cuestión de la ética de publicar los resultados de tales estudios puede ser grave.
El tema de la belleza de las personas y su evaluación también puede ser éticamente controvertido. Al desarrollar la aplicación, muchos de mis amigos se negaron a usar sus fotos para las pruebas, o simplemente no querían saber el resultado (es curioso que la mayoría de las niñas se negaron a conocer los resultados). Además, el objetivo de automatizar la evaluación de la belleza puede generar interesantes preguntas filosóficas. ¿En qué medida el concepto de belleza está determinado por la cultura? ¿Qué tan cierto es "La belleza en el ojo del espectador"? ¿Es posible resaltar signos objetivos de belleza?
Para responder estas preguntas, debe estudiar las estadísticas sobre las calificaciones de algunas personas por parte de otras. Traté de diseñar y entrenar un modelo de red neuronal que evaluara la belleza, así como ejecutarlo en un teléfono Android.
Parte 0. Tubería
Para entender cómo se relacionan los siguientes pasos entre sí, dibujé un diagrama del proyecto:
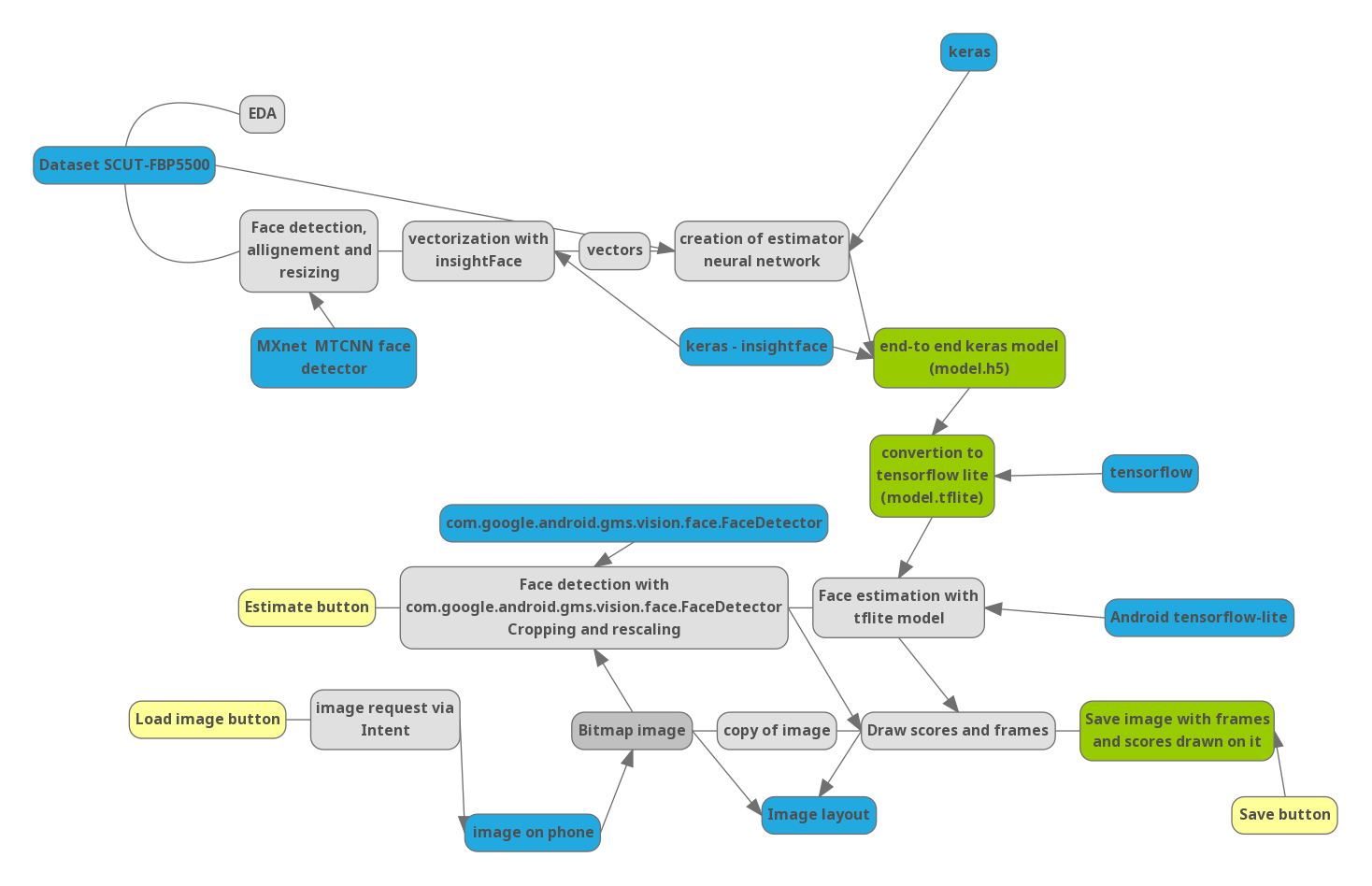
Azul: bibliotecas importantes y datos externos. Amarillo: controles en la aplicación.
Parte 1. Python
Dado que la evaluación de la belleza es un tema bastante delicado, no hay muchos conjuntos de datos en el dominio público que contengan fotos con una evaluación (estoy seguro de que los servicios de citas en línea como Tinder tienen conjuntos de estadísticas mucho más grandes). Encontré
una base de datos compilada en una de las universidades de China, que contiene 5500 fotografías, cada una evaluada por 7 evaluadores de estudiantes chinos. De las 5.500 fotografías, 2.000 son hombres asiáticos (AM), 2000 son mujeres asiáticas (AF) y 750 hombres europioides (CM) y mujeres (CF) cada uno.
Leamos los datos usando el módulo de pandas Python y echemos un vistazo rápido a los datos. Distribución estimada para diferentes géneros y razas:
import pandas as pd import matplotlib.pyplot as plt ratingDS=pd.read_excel('../input/faces-scut/scut-fbp5500_v2/SCUT-FBP5500_v2/All_Ratings.xlsx') Answer=ratingDS.groupby('Filename').mean()['Rating'] ratingDS['race']=ratingDS['Filename'].apply(lambda x:x[:2]) fig, ax = plt.subplots(2, 2, sharex='col') for i, race in enumerate(['CF','CM','AF','AM']): sbp=ax[i%2,i//2] ratingDS[ratingDS['race']==race].groupby('Filename')['Rating'].mean().hist(alpha=0.5, bins=20,label=race,grid=False,rwidth=0.9,ax=sbp) sbp.set_title(race)
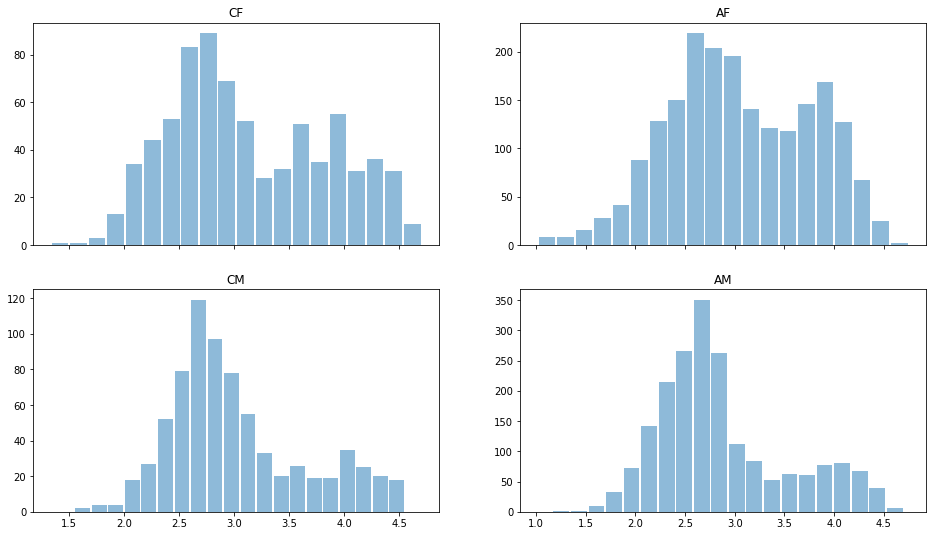
Se puede ver que, en general, los hombres se consideran menos hermosos que las mujeres, la distribución es bimodal: hay esos. que se consideran bellas y "promedio". Casi no hay calificaciones bajas, por lo que los datos podrían volver a formalizarse. Pero dejémoslos por ahora.
Veamos la desviación estándar en las estimaciones:
ratingDS.groupby('Filename')['Rating'].std().mean()
Es 0,64, lo que significa que la diferencia en las evaluaciones de diferentes evaluadores es inferior a 1 punto de 5, lo que indica unanimidad en las evaluaciones de belleza. Se puede decir razonablemente que "la belleza NO está en el ojo del espectador". Al promediar, puede usar de manera confiable los datos para entrenar el modelo y no preocuparse por la imposibilidad fundamental de la evaluación programática.
Sin embargo, a pesar del pequeño valor de la desviación estándar de la estimación, la opinión de algunos evaluadores puede ser muy diferente de la "ordinaria". Construyamos la distribución de la diferencia entre la estimación y la mediana:
R2=ratingDS.join(ratingDS.groupby('Filename')['Rating'].median(), on='Filename', how='inner',rsuffix =' median') R2['ratingdiff']=(R2['Rating median']-R2['Rating']).astype(int) print(set(R2['ratingdiff'])) R2['ratingdiff'].hist(label='difference of raings',bins=[-3.5,-2.5,-1.5,-0.5,0.5,1.5,2.5,3.5,4.5],grid=False,rwidth=0.5)
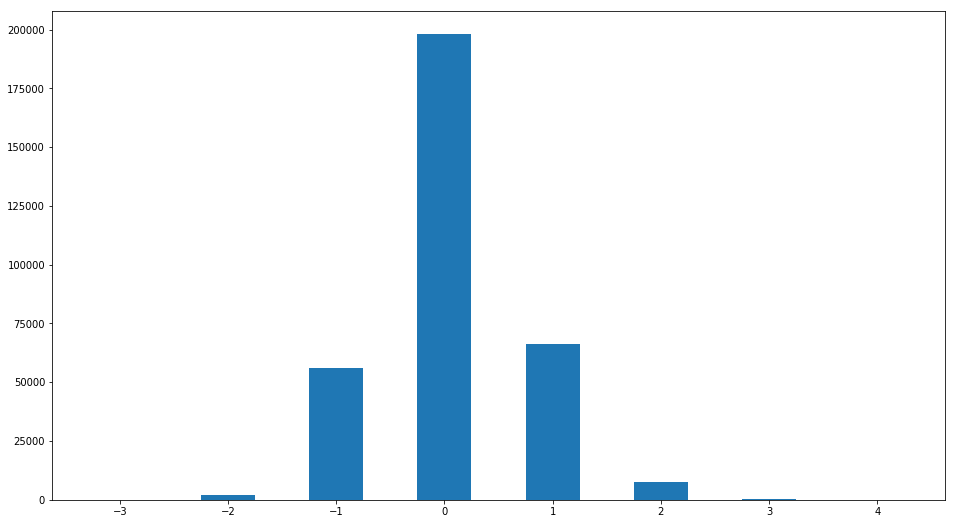
Se encuentra un patrón interesante. Personas cuyo puntaje difiere de la mediana en más de 1 punto
len(R2[R2['ratingdiff'].abs()>1])/len(R2)
0.02943333333333333332
Menos del 3%. Es decir, la sorprendente unanimidad se confirma nuevamente en materia de evaluación de la belleza.
Cree una tabla con las calificaciones promedio necesarias
Answer=ratingDS.groupby('Filename').mean()['Rating']
Nuestra base de datos es pequeña; Además, todas las fotos contienen principalmente imágenes de cara completa, y me gustaría un resultado confiable para cualquier posición de la cara. Para resolver problemas con una pequeña cantidad de datos, a menudo se utiliza la técnica de transferencia de aprendizaje: el uso de modelos pre-entrenados para tareas similares y su modificación. Cerca de mi tarea está la tarea de reconocimiento facial. Por lo general, se resuelve en una forma de tres etapas.
1. Hay una detección de rostros en la imagen y su escala.
2. Usando una red neuronal convolucional, la imagen de la cara se convierte en un vector de características, y las propiedades de tal transformación son tales que la transformación es invariante con respecto a la rotación de la cara y el cambio en el peinado. manifestaciones de emociones y cualquier imagen temporal. Aprender una red de este tipo es una tarea interesante en sí misma, que se puede escribir durante mucho tiempo. Además, constantemente aparecen nuevos desarrollos para mejorar esta conversión para mejorar el seguimiento de masa y los algoritmos de identificación. Optimizan tanto la arquitectura de la red como el método de entrenamiento (por ejemplo, pérdida de triplete-pérdida de superficie-arco).
3. Comparación del vector de características con los almacenados en la base de datos.
Para nuestra tarea, utilicé soluciones preparadas de 1-2 puntos. La tarea de detectar rostros generalmente se resuelve de muchas maneras, además, casi cualquier dispositivo móvil tiene detectores de rostros (en Android son parte del paquete de servicios estándar de Google Play), que se utilizan para enfocarse en los rostros al fotografiar. En cuanto a la traducción de personas en forma vectorial, hay un punto sutil no obvio. El hecho es que los signos. extraídos para resolver el problema de reconocimiento: son característicos de una persona, pero pueden no correlacionarse con la belleza en absoluto. Por otra parte. Debido a las peculiaridades de las redes neuronales convolucionales, estos signos son principalmente locales, y en general esto puede causar muchos problemas (ataque de un solo píxel). Sin embargo, descubrí que los resultados dependen en gran medida de la dimensión del vector, y si 128 signos no son suficientes para determinar la belleza, 512 es suficiente. En base a esto, se eligió una
red insightFace pre-entrenada basada en Reset . También usaremos keras como marco para el aprendizaje automático.
Puede encontrar un código detallado para descargar modelos previamente entrenados
aquí. model=LResNet100E_IR()
El detector
facial mtcnn se utilizó como detector facial para el preprocesamiento
. detector = MtcnnDetector(model_folder=mtcnn_path, ctx=ctx, num_worker=1, accurate_landmark = True, threshold=det_threshold)
Alinee, recorte y vectorice imágenes del conjunto de datos:
imgpath='../input/faces-scut/scut-fbp5500_v2/SCUT-FBP5500_v2/Images/'
Prepararemos los datos dividiéndolos en vectores de capacitación (90% de ellos, estudiaremos sobre ellos) y validación (verificaremos el trabajo del modelo en ellos). Normalizamos los datos a un rango de 0-1.
X=np.stack(facevecs)[:,0,:] Y=(Answer[:])/5 Indicies=np.arange(len(Answer)) X,Y,Indicies=sklearn.utils.shuffle(X,Y,Indicies) Xtrain=X[:int(len(facevecs)*0.9)] Ytrain=Y[:int(len(facevecs)*0.9)] Indtrain=Indicies[:int(len(facevecs)*0.9)] Xval=X[int(len(facevecs)*0.9):] Yval=Y[int(len(facevecs)*0.9):] Indval=Indicies[int(len(facevecs)*0.9):]
Ahora pasemos al modelo. describiendo la belleza.
def Createheadmodel(): inp=keras.layers.Input((512,)) x=keras.layers.Dense(32,activation='elu')(inp) x=keras.layers.Dropout(0.1)(x) out=keras.layers.Dense(1,activation='hard_sigmoid',use_bias=False,kernel_initializer=keras.initializers.Ones())(x) model=keras.models.Model(input=inp,output=out) model.layers[-1].trainable=False model.compile(optimizer=keras.optimizers.Adam(lr=0.0001), loss='mse') return model modelhead=Createheadmodel()
Este modelo es una red neuronal completamente conectada de una sola capa con 32 neuronas y 512 nodos de entrada, una de las arquitecturas más simples, que, sin embargo, está bien entrenada:
hist=modelhead.fit(Xtrain,Ytrain, epochs=4000, batch_size=5000, validation_data=(Xval,Yval) )
4950/4950 [===============================] - 0s 3us / paso - pérdida: 0.0069 - val_loss: 0.0071
Construyamos curvas de aprendizaje.
plt.plot(hist.history['loss'][100:], label='loss') plt.plot(hist.history['val_loss'][100:],label='validation_loss') plt.legend(bbox_to_anchor=(0.95, 0.95), loc='upper right', borderaxespad=0.)
Vemos que la pérdida (desviación cuadrática media) es 0.0071 en los datos de validación, por lo tanto, la desviación estándar = 0.084 o 0.42 puntos en una escala de cinco puntos, que es menor que la propagación en las estimaciones dadas por las personas (0.6 puntos). Nuestro modelo esta funcionando.
Para visualizar cómo funciona el modelo, puede usar el diagrama de dispersión: para cada foto de los datos de validación, construimos un punto donde una de las coordenadas corresponde a la calificación nominal promedio y la segunda a la calificación pronosticada promedio:
Answer2=Answer.to_frame()[:5500] Answer2['ans']=0 Answer2['race']=Answer2.index Answer2['race']=Answer2['race'].apply(lambda x: x[:2]) Answer2['ans']=modelhead.predict(np.stack(facevecs)[:,0,:])*5 xy=np.array(Answer2.iloc[Indval][['ans','Rating']]) plt.scatter(xy[:,1],xy[:,0])

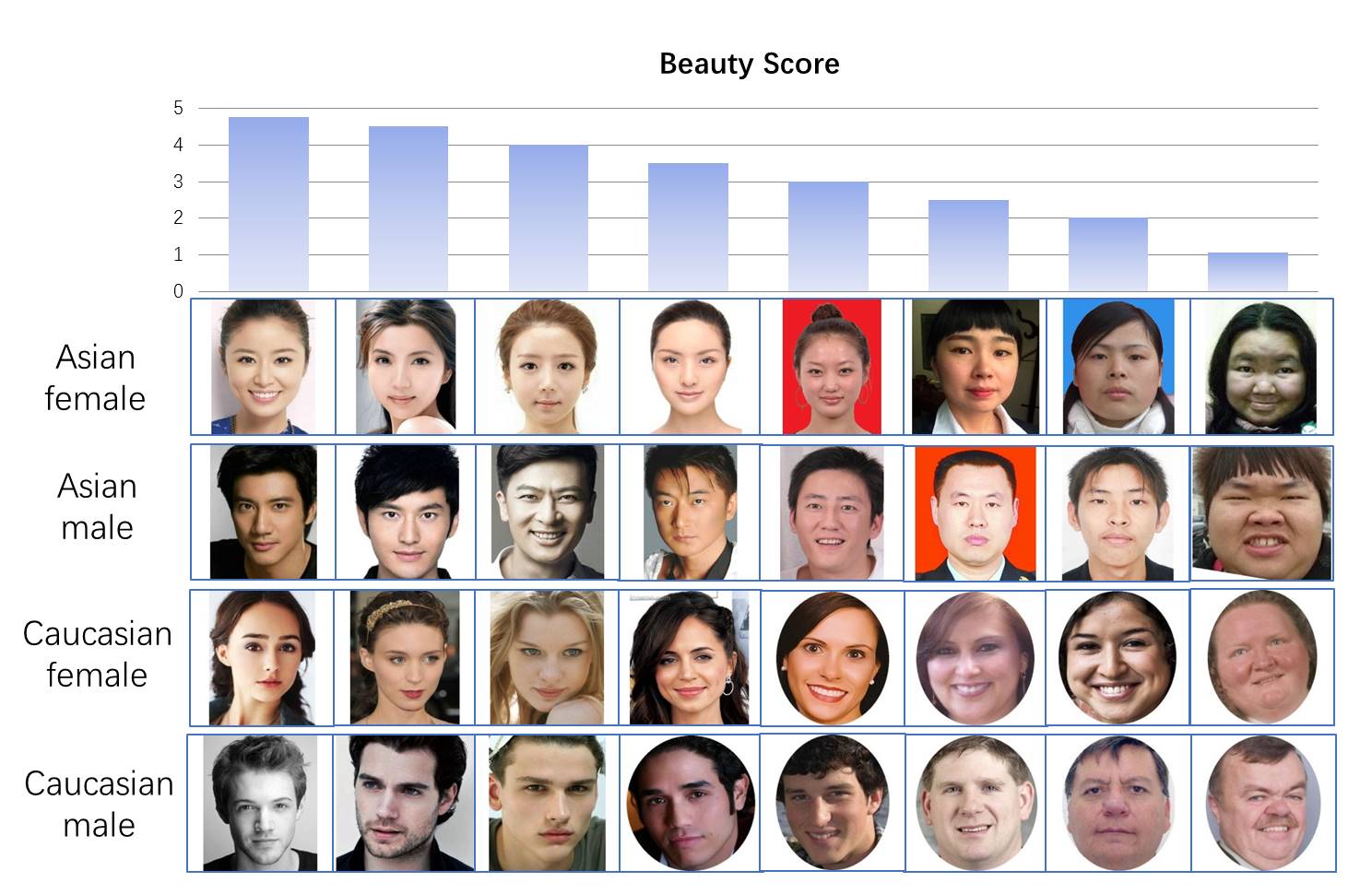
Eje Y - valores predichos por el modelo, eje X - valores promedio de las estimaciones de las personas. Vemos una alta correlación (el diagrama se alarga a lo largo de la diagonal). También puede consultar nuestros resultados visualmente: tome las caras de cada una de las categorías con calificaciones pronosticadas del 1 al 5
import matplotlib.image as mpimg f, axarr = plt.subplots(4,5,figsize=(10, 10)) for i, race in enumerate(['AF','CF', "AM", 'CM']): for rating in range(1,6):

Vemos que el resultado de ordenar por belleza parece razonable.
Ahora crearemos un modelo completo en el que enviaremos una cara a la entrada, en la salida obtendremos una calificación de 0 a 1 y la convertiremos al formato tflite adecuado para el teléfono
import tensorflow as tf finmodel=Model(input=model.input, output=modelhead(model.output)) finmodel.save('finmodel.h5') converter = tf.lite.TFLiteConverter.from_keras_model_file('finmodel.h5') converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE] tflite_quant_model = converter.convert() open ("modelquant.tflite" , "wb").write(tflite_quant_model) from IPython.display import FileLink FileLink(r'modelquant.tflite')
Este modelo recibe una imagen de una cara con un tamaño de 112 * 112 * 3 en la entrada, y en la salida da un solo número de 0 a 1, lo que significa la belleza de la cara (aunque debemos recordar que en el conjunto de datos las calificaciones no variaron de 0 a 5, sino de 1 a 5).
Parte 2. JAVA
Intentemos escribir una aplicación simple para un teléfono Android. El lenguaje Java es nuevo para mí, y nunca he estado involucrado en el desarrollo de Android, por lo tanto, el proyecto no utiliza la optimización del trabajo, no utiliza el control de flujo y otras cosas que requieren mucho trabajo para un principiante. Dado que el código de Java es bastante engorroso, aquí daré solo las piezas más importantes para que el programa funcione. El código completo de la aplicación está disponible
aquí . La aplicación abre una foto, detecta y evalúa una cara usando una red previamente guardada y muestra el resultado:

Desde el punto de vista del desarrollo, las siguientes funciones son importantes.
1. La función de cargar la red neuronal desde el archivo model.tflite en la carpeta de activos en el objeto de intérprete
import org.tensorflow.lite.Interpreter; Interpreter interpreter; try { interpreter=new Interpreter(loadModelFile(MainActivity.this)); Log.e("TIME", "Interpreter_started "); } catch (IOException e) { e.printStackTrace(); Log.e("TIME", "Interpreter NOT started "); } private MappedByteBuffer loadModelFile(Activity activity) throws IOException { AssetFileDescriptor fileDescriptor = activity.getAssets().openFd("model.tflite"); FileInputStream inputStream = new FileInputStream(fileDescriptor.getFileDescriptor()); FileChannel fileChannel = inputStream.getChannel(); long startOffset = fileDescriptor.getStartOffset(); long declaredLength = fileDescriptor.getDeclaredLength(); return fileChannel.map(FileChannel.MapMode.READ_ONLY, startOffset, declaredLength); }
2. Detectando caras usando el módulo FaceDetector, que es parte del paquete estándar de la biblioteca de google, usando una red neuronal y mostrando los resultados.
import com.google.android.gms.vision.face.Face; import com.google.android.gms.vision.face.FaceDetector; private void detectFace(){
Si desea jugar con la calificación en su teléfono, puede descargar la
aplicación desde el mercado GooglePlay .