Para Hadoop y Greenplum, existe la oportunidad de preparar SaaS. Y si Khadup es algo bien conocido, entonces Greenplum (es la base del producto ArenadataDB, que se discutirá más adelante) es interesante, pero ya menos "de oído".
Arenadata DB es un DBMS distribuido basado en el código abierto Greenplum. Al igual que otras soluciones MPP (procesamiento de datos en paralelo), para sistemas masivamente paralelos, la arquitectura de la nube está lejos de ser óptima. Esto puede reducir el rendimiento hasta en un 30% (generalmente menos). Pero, sin embargo, este problema puede ser nivelado (lo cual se discutirá más adelante). Además, vale la pena comprar dicho servicio desde la nube, a menudo es conveniente y rentable en comparación con la implementación de su propio clúster.
En las instalaciones se indica claramente en las guías, pero ahora muchas personas se dan cuenta de la escala de la conveniencia de la nube. Todos entienden que habrá algún tipo de degradación del rendimiento, pero sigue siendo tan súper conveniente y rápida que ya hay proyectos en los que esto se sacrifica en algunas etapas, como probar hipótesis.
Si tiene un almacén de datos de más de 1 TB y sistemas transaccionales, no su perfil de carga, a continuación encontrará una historia sobre lo que se puede hacer como una opción. ¿Por qué 1 TB? A partir de este volumen, el uso de MPP es más eficiente en términos de relación rendimiento / costo en comparación con los DBMS clásicos.
Cuando usar
Cuando el DBMS clásico de un solo nodo por arquitectura no es adecuado para sus volúmenes. Un caso común es un nuevo almacén de datos con una capacidad de más de 1 TB. MPP DBMS ahora está en tendencia, y Greenplum es uno de los mejores en el mercado para tareas modernas. Especialmente considerando su apertura. También hay un montón de sistemas patentados con muchas características listas para usar: Terradata, Sap Khan, Exadata, Vertika. Por lo tanto, si no puede permitirse el lujo de las piñas y el urogallo, tome la ciruela.
El segundo caso es cuando tiene un almacén de datos existente en algo universal como Oracle o Post-Congress, pero los usuarios se quejan regularmente de informes lentos. Y cuando hay nuevas tareas como Big Data: cuando los usuarios quieren todos los datos de inmediato, no pueden predecir qué harán con ellos. Hay muchas situaciones en las que una empresa operativa necesita informes relevantes solo un día, y no tienen tiempo para pagar en un día. Es decir, básicamente no se necesitan datos. En este caso, también es conveniente tomar bases de datos MPP e intentar con SaaS en la nube.
El tercer caso es cuando alguien sigue la moda de Khadup y resuelve las tareas estándar de procesamiento de datos estructurados por lotes, pero el clúster no está bien ensamblado. A menudo vemos que la tecnología se aplica un poco e incluso nada como debería. Por ejemplo, no necesita construir una base de datos relacional en Khadup. Sin embargo, si su Hadoup repentinamente no tiene procesamiento en tiempo real o se suponía que debía hacerlo, pero el administrador y el desarrollador huyeron con horror, entonces también puede mirar hacia Greenplum en la nube: el soporte será muy simple mientras se mantiene la capacidad de procesar grandes cantidades de datos.
¿Por qué pocas personas lo intentan?
Cualquier MPP DBMS requiere mucha capacidad. Eso es mucho hierro. De hecho, las personas tienen miedo de intentar el nivel de prueba de concepto simplemente por el precio de entrada. No pueden hacer esto físicamente. Una de las ideas principales de nuestro SaaS es darle la oportunidad de jugar con todo esto sin comprar un grupo de hierro.
Y regularmente nos encontramos con clientes que dicen que no queremos acompañar, operar, etc. de manera independiente. Y me gustaría externalizar. Este es un sistema analítico, y la mayoría de las veces es crítico para el negocio, pero no crítico para la misión. Muchos en Occidente están subcontratando; también hemos comenzado recientemente.
¿Qué es lo mejor que se puede hacer en MPP?
Clásico almacén de datos corporativos: para todas las fuentes de datos, obtienes datos incrementales y luego las ventanas se crean para los usuarios. Los usuarios que se encuentran por encima de estos escaparates crean sus informes. "Todos los días quiero ver cómo van las cosas en los negocios", eso es todo.
Algunas palabras más sobre la solución en la nube
Solía ser que las infraestructuras de este tipo estaban mal diseñadas para las nubes. Pero en realidad, más y más clientes están entrando en las nubes. El trabajo requiere un alto rendimiento, ya que gira en torno a muchas consultas analíticas grandes que consumen muchas CPU, requieren mucha memoria y tienen altas demandas en los discos y la infraestructura de red. Como resultado, cuando los clientes implementan DBMS distribuidos en la nube, pueden encontrar varios problemas.
El primero es el bajo rendimiento de la red. Como todo esto sucede en la nube en un entorno virtual, puede haber muchas máquinas en un hipervisor. Las máquinas virtuales pueden estar dispersas en diferentes hipervisores. Además, en algunos momentos pueden estar dispersos en diferentes centros de datos, los supervisores pueden girar sobre ellos virtualmente. Y debido a esto, la red sufre mucho. Al procesar mil millones de registros en una tabla, digamos 10 servidores, e impulsa estos datos entre todos los servidores. Una subespecie funciona dentro, e incluso dentro de un servidor, muchas de estas subespecies funcionan. Puede haber 10-20, y ahora todos comienzan a conducir datos a través de la red durante la ejecución de la solicitud. La red está cayendo como los cultivos de invierno. ¿Qué conclusión se puede sacar de esto? Utilice nubes de gran ancho de banda, como la nube CROC, que proporciona 56 GB en Infiniband.
El segundo problema es que los firewalls y las protecciones DDoS se ven muy sesgados. Astillado, decidido. Antes de usar, le recomendamos que programe una hora adicional para verificar dos veces todas las configuraciones.
Aún imperceptible migración en vivo y actualización. Para arrastrar una máquina a otro hipervisor, y luego de regreso, no necesita perder paquetes. Es necesario chamanizar con la configuración al final. Por ejemplo, casi inmediatamente subimos para aumentar el portapapeles. MTU elevado a 9,000 jumboframe.
Por supuesto, unidades que tienen HDD. Realmente no les gusta tal registro, especialmente cuando estos son sectores muy, muy aleatorios en la cola con el resto de las solicitudes. Decidimos dividir el almacenamiento en segmentos: uno es solo para Greenplum, el otro es compartido. Esto es necesario para situaciones en las que una docena de clientes están implementando instalaciones de Greenplum en paralelo. MPP utiliza el subsistema de disco en la mayor medida posible, los servicios en la nube se interconectan con el almacenamiento y el rendimiento allí es casi el mismo que el del canal. Si todos los clientes de la nube no calculan MPP, puede obtener una ganancia muy significativa. La distribución eficiente de energía en tales cargas funciona muy bien.
Y debido a su propia arquitectura, Greenplum en la nube funciona mejor en eficiencia que Redshift, BigQuery y Snowflake.
Aspecto de la implementación:
Así:
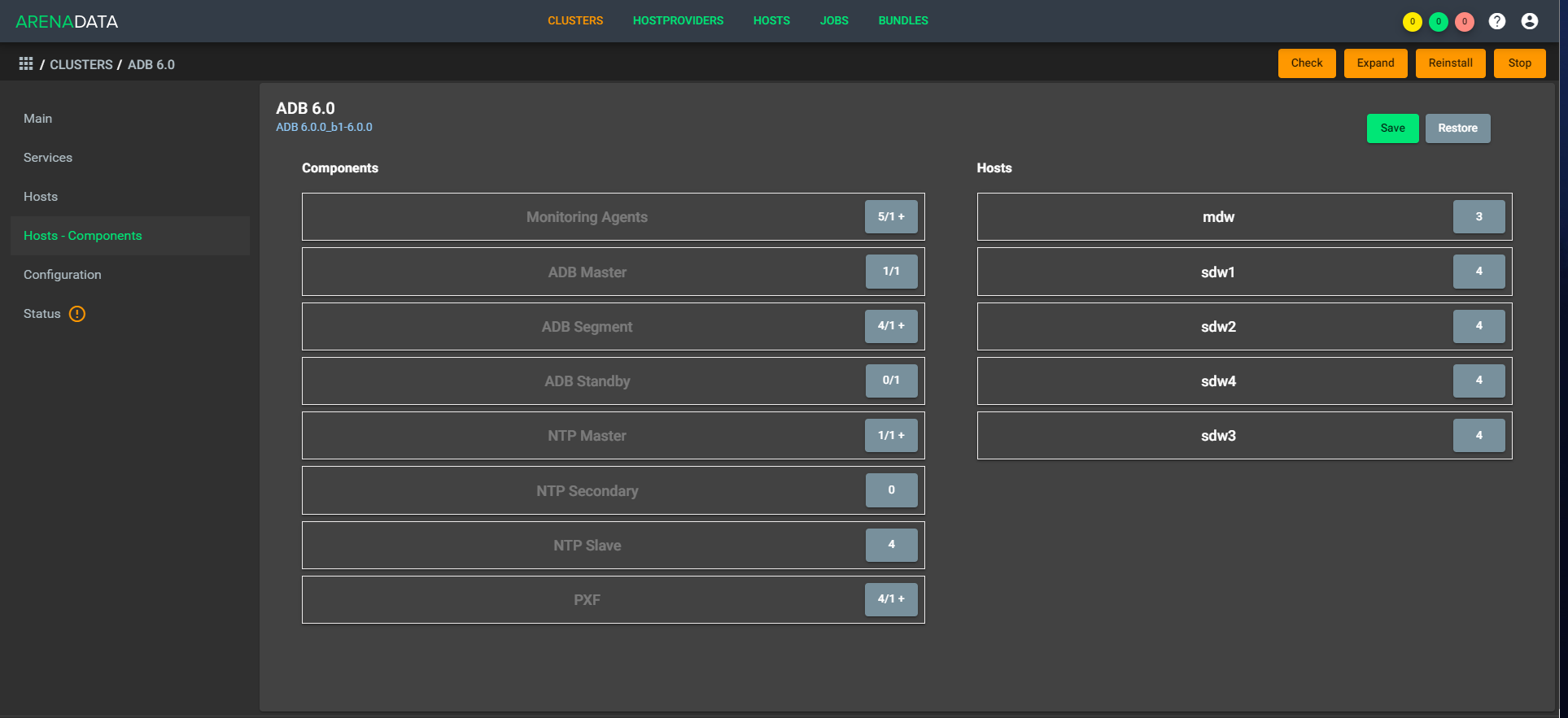
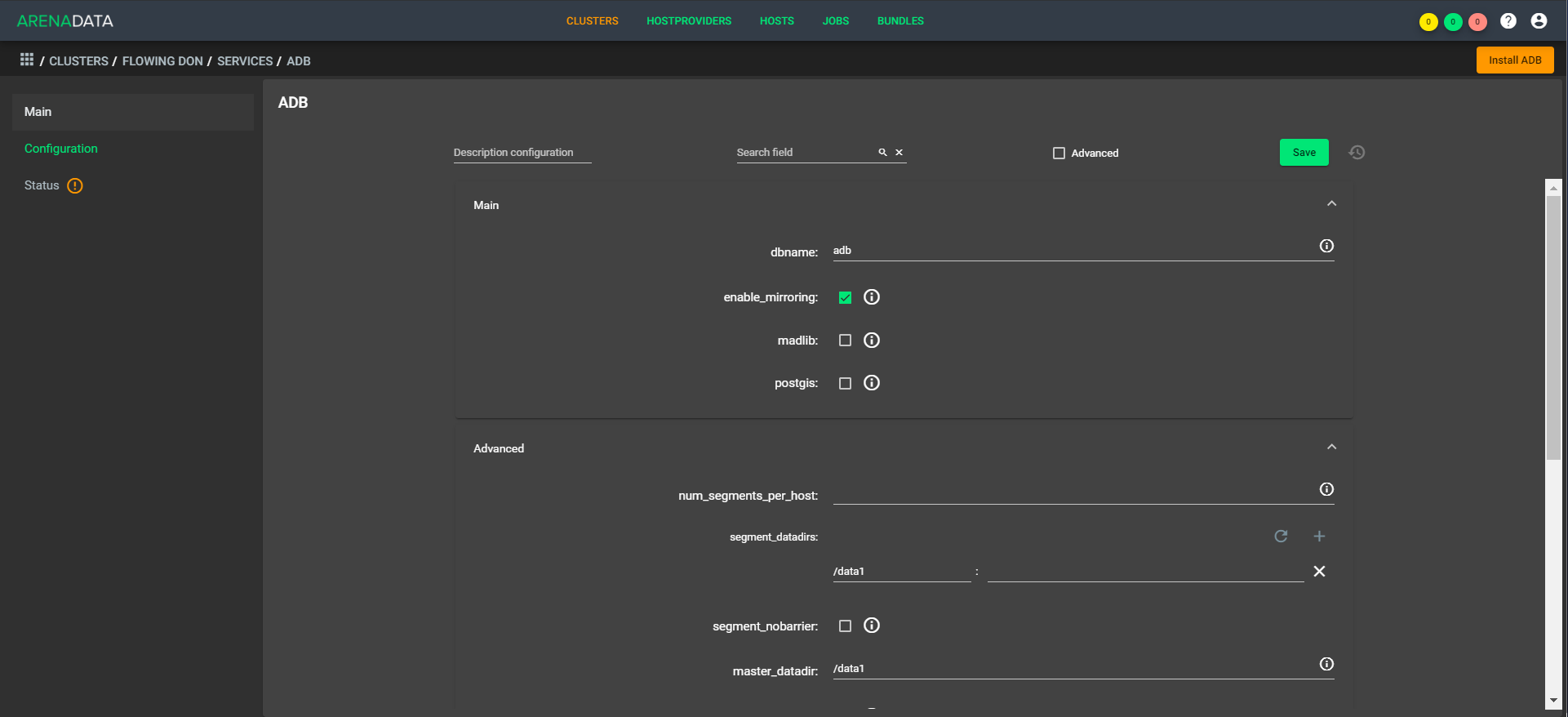
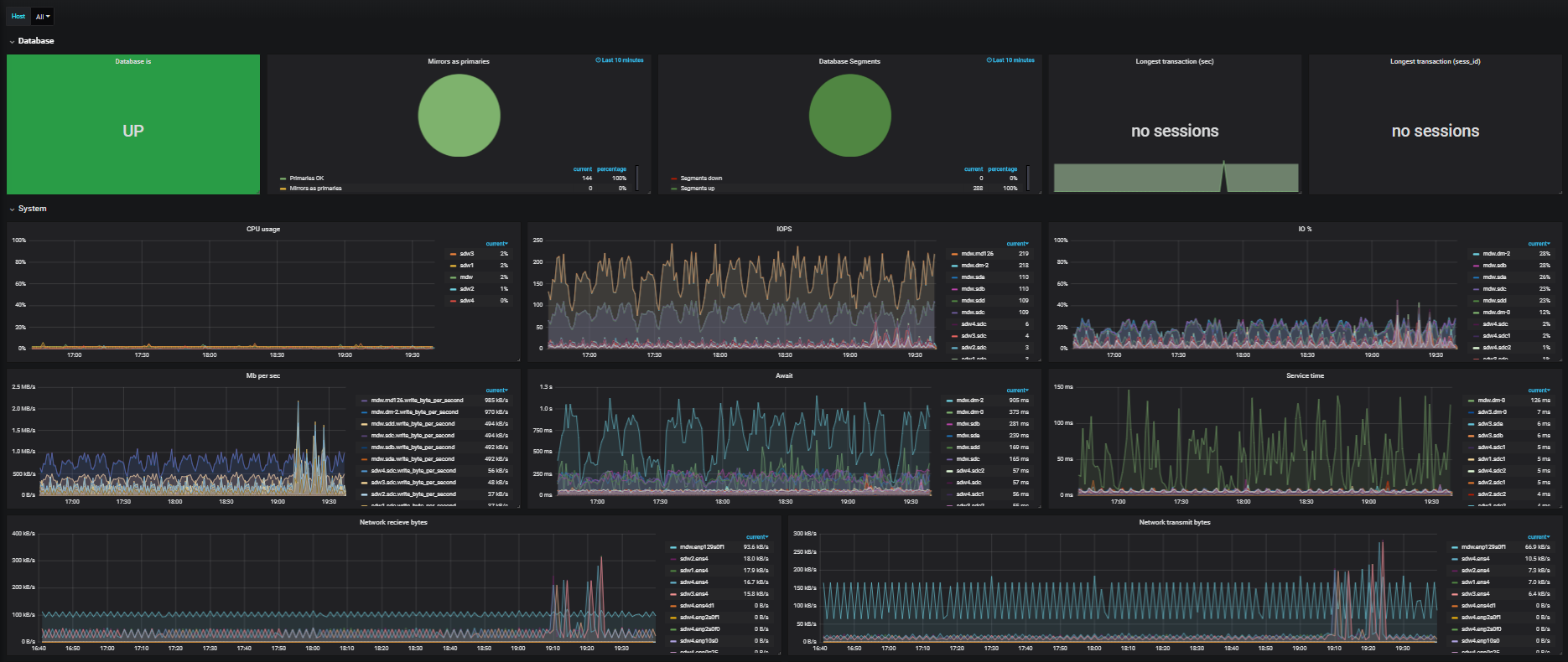
La arquitectura es "transpirable", es decir, puede implementar rápidamente un factor simple en la configuración. Como ejemplo, en la tarde tenemos cinco CPU, y en la noche tenemos 1,000 controladores en aumento y diez CPU funcionando. En este caso, no necesita equilibrar los datos, ya que se encuentran dentro de la misma tienda. Hay una extensión disponible de fábrica, la compresión rápida aún debe completarse un poco.
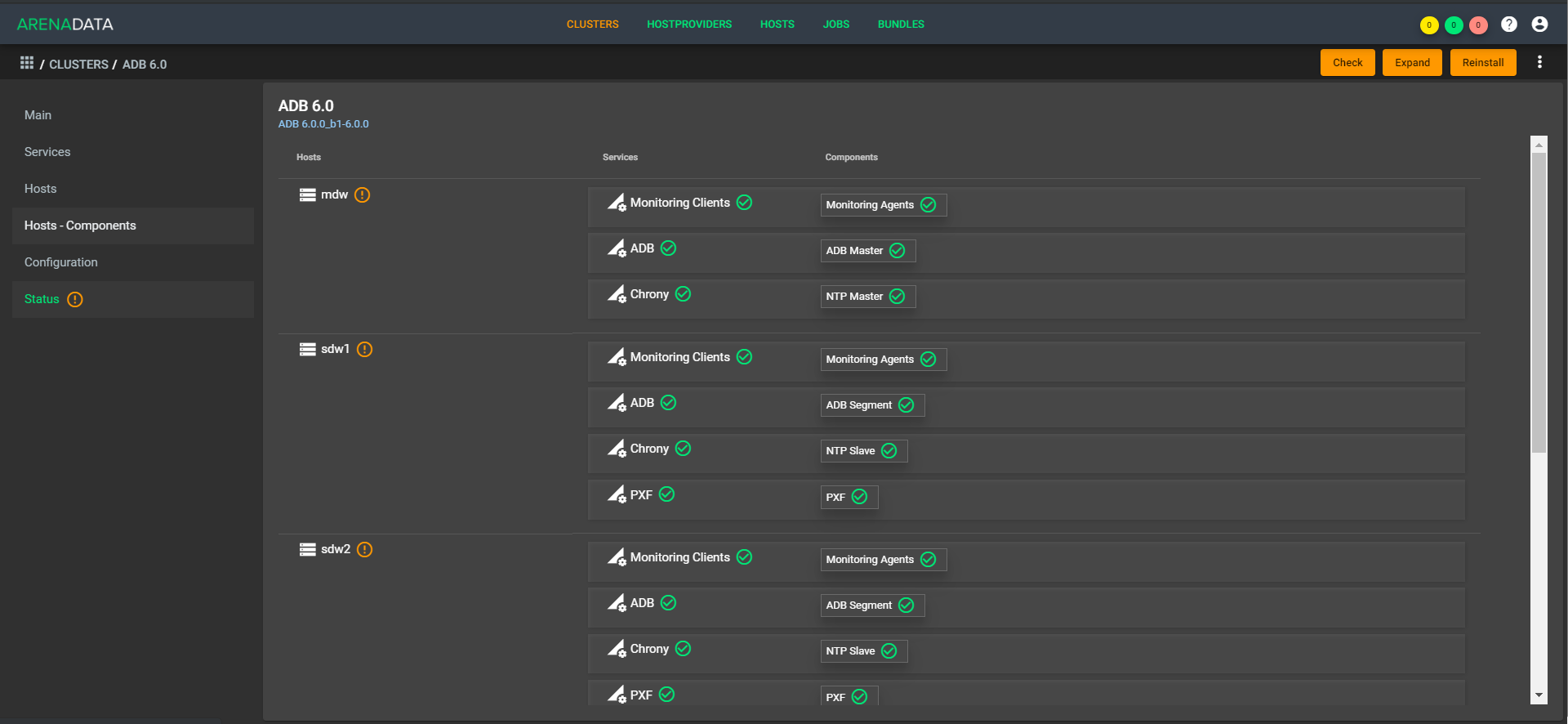
Ahora para el cliente hay un único punto de gestión. Llega a un lugar, lanza una solicitud allí como: "Implemente un plan de clúster para mí en tales máquinas", y nuestro soporte implementa las máquinas en la nube (con nosotros o con el cliente), coloca a Greenplum allí, inicia, configura y realiza todos los ajustes. Lo mismo ocurre con el monitoreo, la gestión, la actualización. A medida que avanza la automatización, esto dejará soporte en los botones de su cuenta.
Primero entendimos la conveniencia de tal enfoque en proyectos internos, y luego comenzamos a proporcionar SaaS a los clientes. Tenemos una profunda integración con S3: esto le permite usar Greenplum como un sistema con capas separadas para computación y almacenamiento, o usar S3 para copias de seguridad, y Greenplum como núcleo en QCD en la nube. Existe una implementación flexible de entornos para empresas que utilizan la API CROC y la API ADCM.