R es una herramienta muy poderosa para trabajar con estadísticas: desde el preprocesamiento hasta la construcción de modelos de cualquier complejidad y los gráficos correspondientes.
Una simple solicitud de Google proporcionará una gran cantidad de literatura sobre cómo "usar R fácil y rápidamente". Habrá enormes libros y numerosas notas sobre el desbordamiento de pila , que, a primera vista, parecen un depósito interminable de ejemplos, cada uno de los cuales cuenta en dos recopilará el código necesario para resolver un problema específico. Sin embargo, en realidad esto no es del todo cierto. Hay muy pocos materiales que indiquen, por ejemplo, cómo construir un programa simple "desde cero" con recetas listas para resolver las dificultades que surgirán en el curso de la solución de este problema.
Para resolver problemas prácticos, se necesitan instrucciones específicas paso a paso, no una descripción detallada de la potencia total de un paquete. Además, los ejemplos de capacitación prefabricados (los mismos iris ) a menudo son de poca utilidad, ya que se saltan inmediatamente una de las etapas más importantes del trabajo con estadísticas: la recopilación y el procesamiento preliminares de los datos en sí. ¡Pero es precisamente para este trabajo que casi una gran parte de todo el tiempo a menudo toma! Otro problema es la creación de horarios que corresponden a estándares formales, y más a menudo informales, de un determinado entorno profesional.
Mis colegas y yo regularmente necesitamos hacer más y más visualizaciones de estadísticas y modelos basados en ellos para publicar resultados científicos. Dado que los estudios se refieren a la economía, muchos de estos trabajos son similares al periodismo profesional.
En algún momento, quedó claro que para un trabajo en equipo efectivo se necesita una especie de proceso de procesamiento de estadísticas completo. Este artículo nació como una guía introductoria para colegas y una hoja de trucos para mí mismo para ejecutar este transportador. Parece que este material puede ser útil para un público más amplio.
R Gráficos sin dolor: tutorial
Ajuste básico R
Para trabajar, necesita un paquete estándar: R + RStudio . Están disponibles de forma gratuita para todas las plataformas comunes. R se instala primero, luego RStudio. Generalmente no hay problemas.
Antes de trabajar, es mejor guardar inmediatamente el nuevo script en algún lugar de su sistema de archivos e instalar inmediatamente el directorio de trabajo R en la carpeta donde está almacenado el script (Menú de sesión - Establecer directorio de trabajo - A la ubicación del archivo de origen). La última nota es importante, porque de lo contrario, no se iniciará ningún script externo o nativo después de reiniciar RStudio. Por alguna razón, RStudio no hace esto por defecto, lo que sería lógico.
Incluso en el paquete básico R hay herramientas de visualización estándar (función de trazado ) que le permiten construir muchos tipos de gráficos, pero, sin embargo, estas características claramente no son suficientes para ilustraciones completas y altamente personalizables.
La biblioteca más utilizada para gráficos en R es el paquete ggplot2 , que también utilizaremos.
También vale la pena instalar inmediatamente los paquetes readxl (para leer archivos .xls, .xlsx) y dplyr (para trabajar con matrices), escalas (para trabajar con diferentes escalas de datos), Cairo (para dibujar gráficos de ggplot a archivos). Todo esto se puede hacer con un solo comando:
install.packages("ggplot2", "readxl", "scales", "dplyr", "Cairo")
Recopilación y preparación de datos.
Lo más sorprendente es que esta etapa en cualquier literatura, ya sea un libro teórico serio sobre estadística teórica aplicada o una guía de paquetes estadísticos específicos, está dedicada a un espacio y tiempo catastróficamente pequeños. Sin embargo, según la experiencia de la investigación independiente y el liderazgo de estudiantes y colegas junior, se sabe que es en esta etapa que la mayor parte del tiempo y el esfuerzo pueden caer, por lo tanto, es muy importante salvarlos incluso cuando se resuelven problemas puramente técnicos.
Aquí hay dos preguntas:
- ¿Cómo elegir el formato de archivo correcto?
- ¿Cuál es la mejor manera de estructurar datos?
Con el formato, el dilema es simple: CSV versus Microsoft Excel (no tan importante, "nuevo" .xlsx antiguo .xls). Mucha gente piensa que CSV se beneficia de la simplicidad (de hecho, este es un archivo de texto normal en el que los valores de las columnas están separados por una coma o punto y coma) y la velocidad. Pero elijo Excel por dos razones: en primer lugar, en este archivo puede almacenar varias tablas simultáneamente en diferentes pestañas y, en segundo lugar, lo más importante es que no tiene que pensar en elegir el separador de columna y el lugar decimal correctos. Para CSV, esto a menudo tiene que escribirse manualmente en el código R y asegurarse de que el archivo de datos se guarde con la misma configuración.
La estructuración de datos es un tema más complejo, que requiere una comprensión básica de cómo deben organizarse las bases de datos. Si no entras en la teoría de las bases de datos relacionales sobre diferentes formas normales, entonces La tabla de datos debe ser redundante, es decir , contener columnas adicionales. Esto es necesario para que más adelante en el script en R pueda seleccionar de manera flexible ciertos datos para su posterior procesamiento. Por ejemplo, si queremos representar una serie temporal primitiva, debemos hacer columnas que correspondan a todas las características de agrupación posibles. Por ejemplo, si se trata de una serie de observaciones anuales sobre la población de la ciudad condicional de Severovostochinsk, necesitaremos las siguientes columnas: año (año), var (nombre del indicador), valor (valor del indicador).
Proporcionaremos cualquier dato de entrada a este estilo de presentación de información.
Ejemplo
Objetivo: construir una comparación de la dinámica de los volúmenes de cosecha en Rusia, el Distrito Federal de Siberia y el Territorio de Krasnoyarsk en 2009-2018.
Obtener datos para esta tarea es bastante simple: solo busque el indicador correspondiente en el Sistema Estadístico e Información Interdepartamental Unificado . La sutileza viene después. Puede descargar inmediatamente los datos en formato .xlsx y luego estructurarlos manualmente como se muestra arriba. Afortunadamente, algunas fuentes de información (por ejemplo, EMISS) le permiten hacer esto con las capacidades del servicio en sí, lo que simplifica enormemente el trabajo y reduce el tiempo requerido para completarlo.
Por lo tanto, para EMISS es suficiente ir al modo "Configuración" (el botón correspondiente en la esquina superior derecha de la página de datos) y mover todos los signos, excepto el "Período" de la columna "Columnas" a la columna "Filas". Resulta una tabla que está casi lista para nuestro trabajo futuro. Además, ya en Excel (o cualquier otro editor adecuado), tiene sentido llevar la estructura de la tabla a una forma similar a la presentada anteriormente y asegurarse de que la primera línea contenga solo los nombres de las variables, además, los datos en latín (en principio, R puede funcionar con encabezados en ruso) pero esto es inconveniente al escribir código). El resultado fue una tabla de este tipo (se da un fragmento en varias filas).
Ahora puede llamar a esta hoja de logging , guardar todo el libro en el archivo graphs.xlsx e ir a RStudio.
Conectamos las bibliotecas necesarias.
library(ggplot2) library(readxl) library(Cairo) library(scales) library(dplyr)
Si se está preparando una programación para una publicación en ruso, definitivamente debe configurar la configuración regional adecuada. La opción más moderna que funcionará en la mayoría de los casos es, por supuesto, la codificación UTF-8:
Sys.setlocale("LC_ALL", "ru_RU.UTF-8")
Si el sistema es antiguo (algunos Windows o Linux antiguos), entonces primero deberá comprender qué codificación se usa de manera predeterminada; esta no es una tarea tan simple, que está lejos del propósito de este artículo.
Ahora necesita cargar los datos en R.
df_logging <- read_excel("graphs.xlsx", sheet ="logging")
La opción de sheet aquí establece el nombre de la hoja dentro del libro de Excel desde el que se cargarán los datos.
Construimos la versión más simple del horario requerido.
ggplot(data=df_logging, aes(x=year, y=value)) + geom_line(aes(linetype=location))

En principio, casi "fuera de la caja" resultó ser un programa muy valioso, que es bastante adecuado para un análisis inicial del proceso en estudio, pero desde el punto de vista de una posible publicación, aún requiere un refinamiento significativo.
Primero, acerquemos el estilo gráfico a uno más académico. El paquete ggplot2 tiene varios temas básicos listos para ggplot2 . El tema de theme_classic puede ser reconocido como el más adecuado para nuestro caso. Como parte de su configuración, puede establecer inmediatamente el tamaño base de la fuente y sus auriculares. Mis preferencias personales pertenecen al moderno sistema de fuentes PT Sans, PT Serif, PT Mono . Pero, por supuesto, puedes pedir un Times o Helvetica más clásico. Además, la publicación en la que está prevista la publicación puede tener instrucciones especiales a este respecto. El punto base se determina empíricamente como 12 pt.
ggplot(data=df_logging, aes(x=year, y=value)) + geom_line(aes(linetype=location)) + theme_classic(base_family = "PT Sans", base_size = 12)
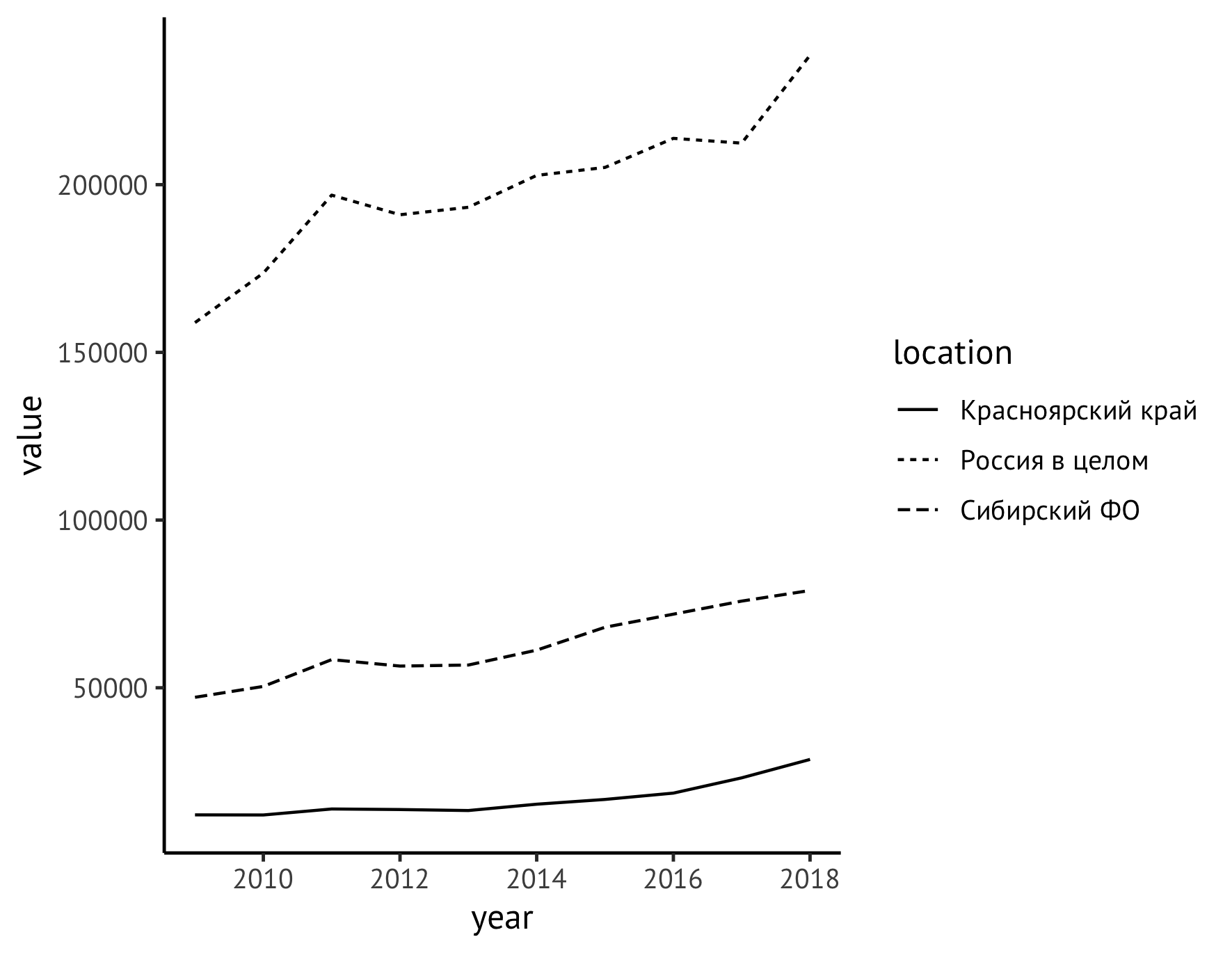
A continuación, mueva la leyenda desde el campo derecho del gráfico hacia abajo (usando la instrucción del theme ) y al mismo tiempo asigne nombres significativos a los ejes (instrucción de labs ). A lo largo del eje Y, escribimos el nombre del indicador con unidades de medida ("Volúmenes de registro, millones de metros cúbicos") y eliminamos las etiquetas a lo largo del eje X, ya que está claro que los años están marcados allí.
ggplot(data=df_logging, aes(x=year, y=value)) + geom_line(aes(linetype=location)) + theme_classic(base_family = "PT Sans", base_size = 12) + theme(legend.title = element_blank(), legend.position="bottom", legend.spacing.x = unit(0.5, "lines")) + labs(x = "", y = " , . . ", color="")

Para que las unidades de medida sean más convenientes para la percepción, nos moveremos desde mil metros cúbicos. m a millones. Para hacer esto, simplemente divida los valores entre 1000, es decir, ajuste la primera línea de nuestro código de la siguiente manera:
ggplot(data=df_logging, aes(x=year, y=value/1000))
Al mismo tiempo, debe cambiar las unidades en la inscripción:
labs(x = "", y = " , . ", color="")
E inmediatamente mejoraremos ligeramente el estilo de la imagen agregando puntos para indicar cada valor observado, para lo cual agregaremos una instrucción:
geom_point(size=2)
También puede establecer explícitamente el estilo de las líneas mismas. Es lógico hacer que el indicador para Rusia sea una línea sólida, y para el Distrito Federal de Siberia y el Territorio de Krasnoyarsk: diferentes versiones de intermitente:
scale_linetype_manual(values=c("twodash", "solid", "dotted"))
Ahora el código general y el gráfico se ven así:
ggplot(data=df_logging, aes(x=year, y=value/1000)) + geom_line(aes(linetype=location)) + geom_point(size=1) + theme_classic(base_family = "PT Sans", base_size = 12) + theme(legend.title = element_blank(), legend.position="bottom", legend.spacing.x = unit(0.5, "lines")) + scale_linetype_manual(values=c("twodash", "solid", "dotted")) + labs(x = "", y = " , . ", color="")

Queda por resolver una tarea más sustantiva: aumentar el contenido de información de nuestro horario. Ahora se puede ver que, en general, el indicador para todos los objetos de observación ha crecido, además, desde aproximadamente 2014 es más fuerte que antes. Pero sería mucho más claro si representamos directamente en el gráfico también los valores en el primer y último año y, por ejemplo, en el pico de 2011. La nueva declaración geom_text ayudará a:
geom_text(aes(label=format(value/1000, digits = 3, decimal.mark = ",")), data = subset(df_logging, year == 2009 | year == 2018 | year == 2011), check_overlap = TRUE, vjust=-0.8)
A primera vista, parece bastante complicado, y debo decir que realmente no fue tan fácil ensamblarlo. Trataré de explicar lo que está sucediendo aquí. Por sí solo, geom_text agrega etiquetas de texto al gráfico. Para esta instrucción, se necesita un conjunto de datos. Si especificamos df_logging directamente en él, obtendríamos inscripciones sobre cada punto. Esto se hace con bastante frecuencia, pero para series de tiempo bastante simples como la nuestra, este enfoque solo creará ruido visual innecesario sin proporcionarnos nueva información sobre el comportamiento del indicador observado. Por lo tanto, solo tomaremos aquellos años que son esenciales para comprender la dinámica del indicador: 2009 (comienzo de las observaciones), 2011 (pico local), 2018 (fin de las observaciones). Esto ayudará al subset estándar.
Para la visualización correcta de los números de acuerdo con la tradición de habla rusa, necesitamos una coma como separador de las partes enteras y decimales ( decimal.mark ), y para cortar el número de lugares decimales, la instrucción de dígitos. Diversos experimentos con él, incluido el uso de la función round , llevaron al hecho de que si necesitamos un decimal, debemos pasar el valor 3 a los digits .
La opción check_overlap no se necesita directamente aquí, pero puede ser útil en otros casos: es un control automático de etiquetas superpuestas. La opción vjust controla la colocación de etiquetas verticalmente. El valor se selecciona en función de las consideraciones de sabor.
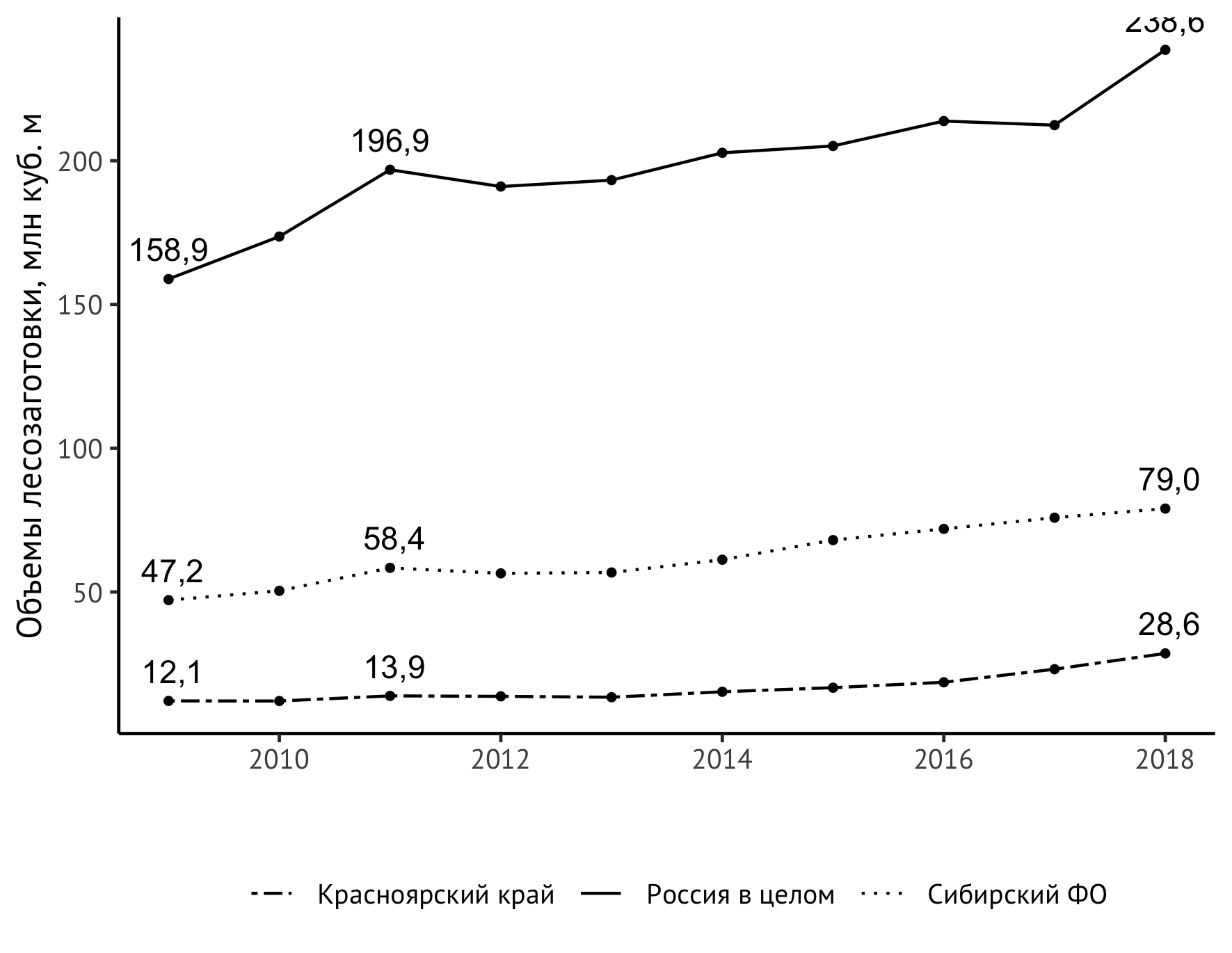
¡Ahora el calendario es realmente interesante de considerar!
Pero se descubrió un problema inesperado: el valor superior derecho está "cortado" por el tamaño vertical de la imagen. Hay varias formas de resolver este problema. Salí con un ligero estiramiento de la escala del eje vertical con un límite superior explícito de 250 millones de metros cúbicos. m:
scale_y_continuous(limits = c(0,250))
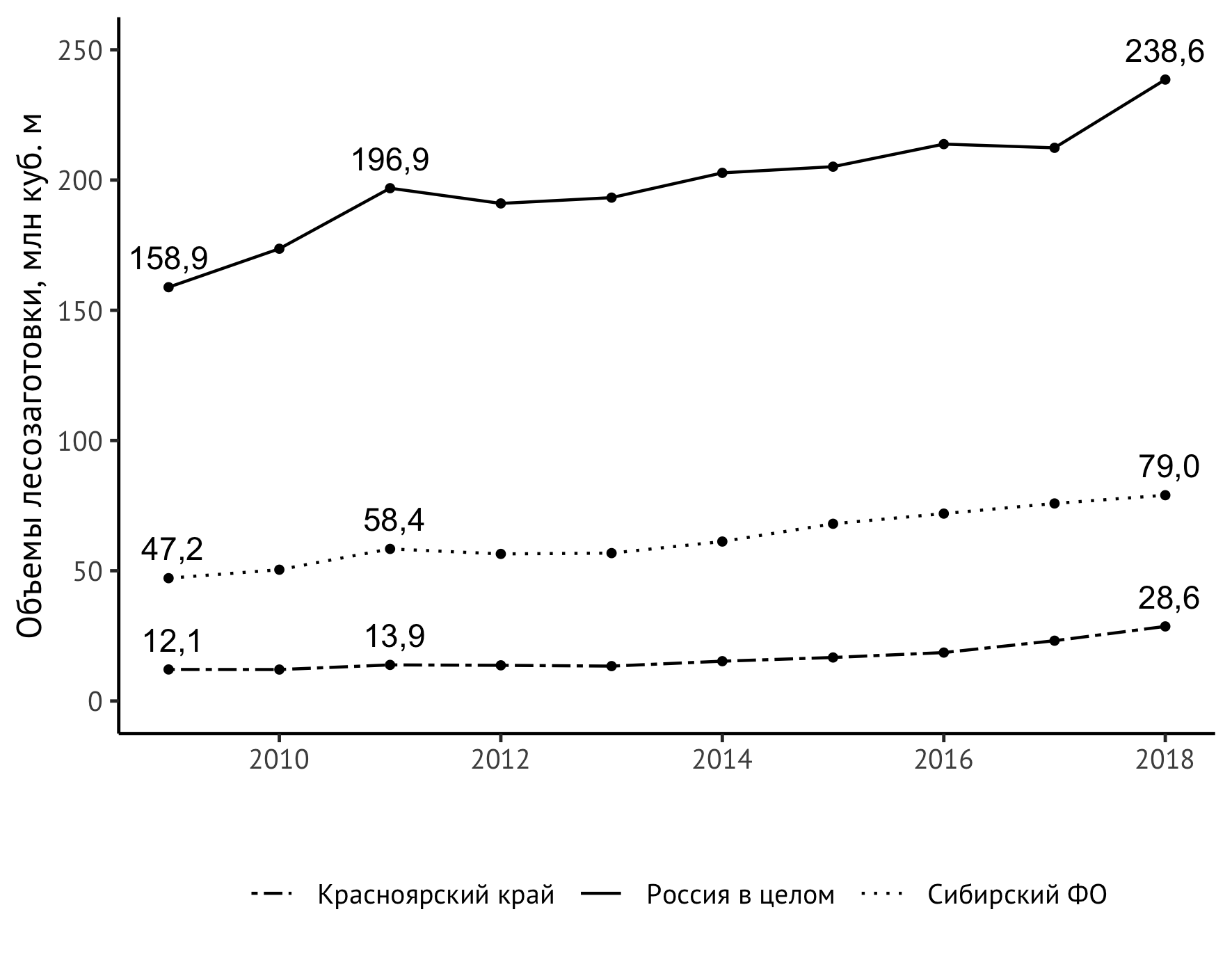
Hecho Entonces, el código final se ve así:
ggplot(data=df_logging, aes(x=year, y=value/1000)) + geom_line(aes(linetype=location)) + geom_point(size=1) + theme_classic(base_family = "PT Sans", base_size = 12) + theme(legend.title = element_blank(), legend.position="bottom", legend.spacing.x = unit(0.5, "lines")) + geom_text(aes(label=format(value/1000, digits = 3, decimal.mark = ",")), data = subset(df_logging, year == 2009 | year == 2018 | year == 2011), check_overlap = TRUE, vjust=-0.8) + geom_text(aes(label=format(value/1000, digits = 3, decimal.mark = ",")), data = subset(df_logging, year == 2009 | year == 2018 | year == 2011), check_overlap = TRUE, vjust=-0.8) + scale_linetype_manual(values=c("twodash", "solid", "dotted")) + scale_y_continuous(limits = c(0,250)) + labs(x = "", y = " , . ", color="")
La imagen resultante se incluye en la monografía: Modernización estructural como factor para aumentar la competitividad de la región (en el ejemplo del Territorio de Krasnoyarsk) / ed. Shishatsky N.G. - Novosibirsk: IEOPP SB RAS, 2020 (en prensa).
Exportar
El complemento de visualización de gráficos integrado en RStudio le permite exportar imágenes en varios formatos sin comandos adicionales, con solo unos pocos clics. El problema es que para tareas prácticas este servicio es prácticamente inútil. Al guardar en formatos ráster (.jpg, .png), la resolución se establece en muy baja de forma predeterminada, por lo que cuando importe una imagen, por ejemplo, en Word, se verá borrosa. Con los vectores .eps o .pdf, la situación es francamente peor: el guardado se produce con errores que no permiten abrir el archivo o se guarda sin la posibilidad de utilizar inscripciones en ruso.
La solución es usar la función ggplot paquete ggplot .
Si la salida requiere un archivo ráster regular, por ejemplo, del formato .png, todo es bastante simple:
ggsave("logging.png", width=709, height=549, units="px")
La geometría ( width y height opciones) y las unidades de medida ( units ) se pueden omitir, pero de manera predeterminada la imagen se exportará al cuadrado, lo cual no es conveniente. Por lo tanto, es mejor obtener su propia proporción y el tamaño requerido y establecer estos parámetros manualmente, como se hace en la línea de código anterior.
Para el uso posterior de la imagen en publicaciones en papel, es razonable exportar la imagen en formatos vectoriales, de modo que más adelante en el diseño existe la posibilidad de cambiar libremente la geometría de la imagen. Muchas revistas prefieren el formato .eps; también es conveniente usarlo para exportar a Word. Necesitaremos el controlador Cairo ya instalado y conectado:
ggsave(filename = "export.eps", width=15, height=11.6, units="cm", device = cairo_ps)
Los archivos se guardarán en el directorio actual donde se encuentra el script R.
Que mas leer
La literatura sobre gráficos en R es bastante. Aquí hay algunos ejemplos, el primero de los cuales es el autor del paquete ggplot:
Probablemente el mejor y más detallado libro sobre gráficos en ruso en ruso es el libro de Timofei Samsonov. Visualización y análisis de datos geográficos en lenguaje R. Esta es una excelente guía detallada de muchos problemas comunes y específicos que se pueden resolver con R.
También puede recomendar un libro en ruso sobre R en general:
Shitikov V.K., Mastitsky S.E.Clasificación, regresión, algoritmos de minería de datos con R. 2017 .
Un ejemplo interesante y motivador es una presentación poderosa sobre el uso de ggplot2 en la preparación de dibujos para el influyente periódico Financial Times .