
En RIT 2019, nuestro colega Alexander Korotkov hizo un
informe sobre la automatización del desarrollo en el CIAN: para simplificar la vida y el trabajo, utilizamos nuestra propia plataforma Integro. Supervisa el ciclo de vida de las tareas, elimina las operaciones de rutina de los desarrolladores y reduce significativamente la cantidad de errores en la producción. En esta publicación, complementaremos el informe de Alexander y le diremos cómo pasamos de simples guiones a combinar productos de código abierto a través de nuestra propia plataforma y lo que hace un equipo de automatización independiente.
Nivel cero
"No hay un nivel cero, no lo sé"
Shifu master de la película "Kung Fu Panda"La automatización en CIAN comenzó 14 años después de la fundación de la empresa. Luego había 35 personas en el equipo de desarrollo. Difícil de creer, ¿verdad? Por supuesto, la automatización existía de alguna forma, pero un área separada de integración continua y entrega de código comenzó a tomar forma en 2015.
En ese momento, teníamos un gran monolito de Python, C # y PHP implementado en servidores Linux / Windows. Para el despliegue de este monstruo, teníamos un conjunto de scripts que ejecutamos manualmente. También hubo un conjunto de monolitos, que causó dolor y sufrimiento debido a conflictos al fusionar ramas, editar defectos y reconstruir "con un conjunto diferente de tareas en la compilación". El proceso simplificado se veía así:

Esto no nos convenía, y queríamos construir un proceso de construcción e implementación repetible, automatizado y controlado. Para hacer esto, necesitábamos un sistema CI / CD, y elegimos entre la versión gratuita de Teamcity y la gratuita Jenkins, ya que trabajamos con ellos y ambos nos convenían para un conjunto de funciones. Elegimos Teamcity como un producto más reciente. Entonces no utilizamos la arquitectura de microservicios y no contamos con una gran cantidad de tareas y proyectos.
Llegamos a la idea de nuestro propio sistema.
La implementación de Teamcity eliminó solo una parte del trabajo manual: todavía existía la creación de Pull Request, la promoción de tareas por estado en Jira, la selección de tareas para liberar. Teamcity ya no podría hacer frente a esto. Era necesario elegir el camino de una mayor automatización. Consideramos opciones para trabajar con scripts en Teamcity o cambiar a sistemas de automatización de terceros. Pero al final, decidimos que necesitábamos la máxima flexibilidad que solo nuestra propia solución brinda. Entonces apareció la primera versión del sistema de automatización interno llamado Integro.
Teamcity se dedica a la automatización en el nivel inicial de los procesos de ensamblaje e implementación, e Integro se ha centrado en la automatización de alto nivel de los procesos de desarrollo. Era necesario combinar trabajo con tareas en Jira con el procesamiento del código fuente asociado en Bitbucket. En esta etapa, Integro comenzó a tener sus propios flujos de trabajo para trabajar con tareas de varios tipos.
Debido al aumento de la automatización en los procesos comerciales, la cantidad de proyectos y ejecuciones en Teamcity ha aumentado. Entonces surgió un nuevo problema: faltaba una instancia gratuita de Teamcity (3 agentes y 100 proyectos), agregamos otra instancia (3 agentes más y 100 proyectos), luego otra. Como resultado, obtuvimos un sistema de varios grupos, que era difícil de administrar:
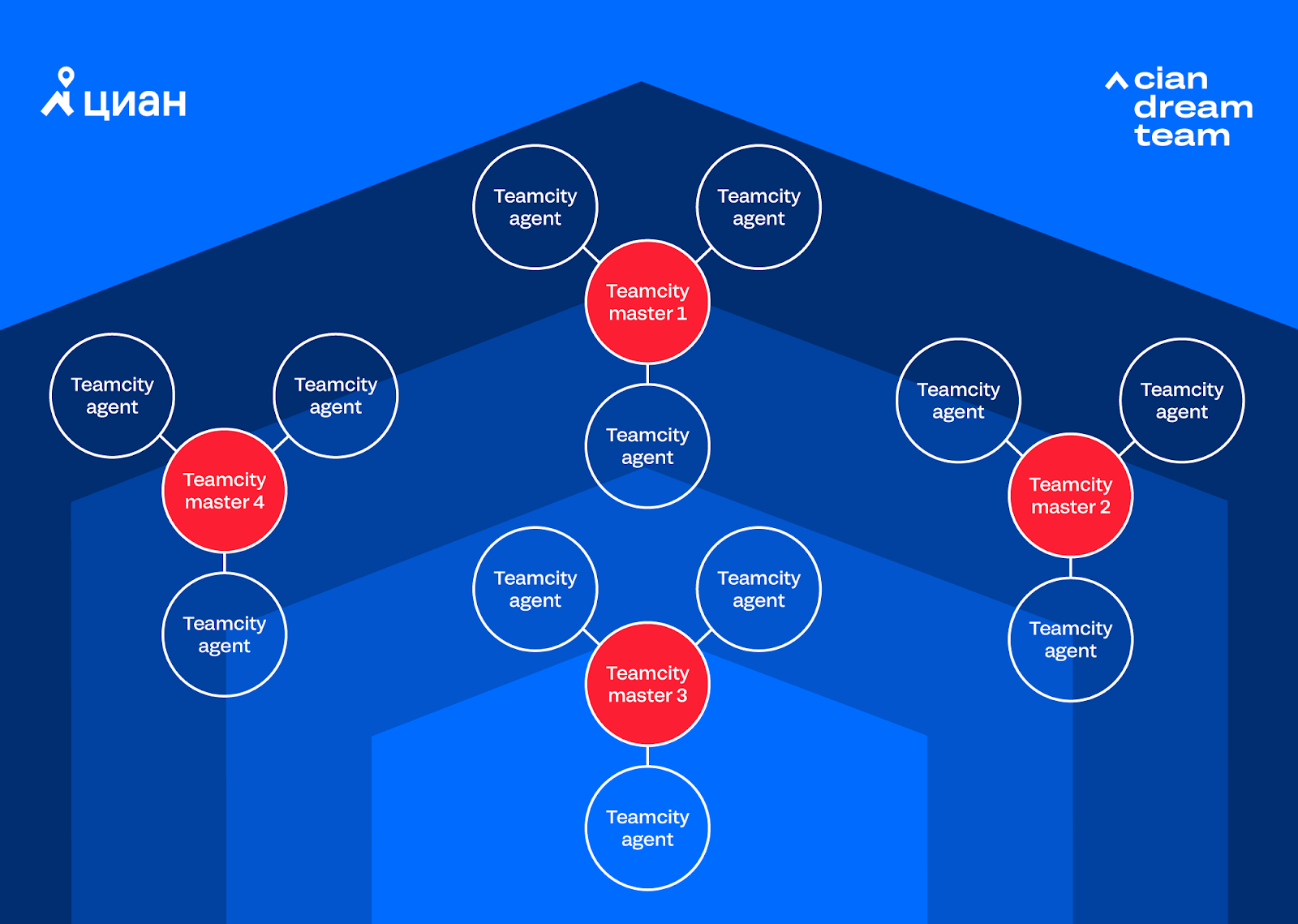
Cuando surgió la pregunta sobre la 4 instancia, nos dimos cuenta de que ya no podíamos vivir así, ya que los costos totales de soportar 4 instancias ya no se ajustan a ningún marco. Se planteó la cuestión de comprar un Teamcity pagado u optar por un Jenkins gratis. Realizamos cálculos sobre instancias y planes de automatización y decidimos que viviríamos de Jenkins. Después de un par de semanas, nos cambiamos a Jenkins y nos deshicimos de la parte del dolor de cabeza asociada con el soporte de múltiples instancias de Teamcity. Por lo tanto, pudimos concentrarnos en desarrollar Integro y completar Jenkins por nosotros mismos.
Con el crecimiento de la automatización básica (en forma de creación automática de solicitudes de extracción, recopilación y publicación de cobertura de código y otras verificaciones), hubo un fuerte deseo de rechazar las liberaciones manuales tanto como sea posible y dar este trabajo a los robots. Además, la compañía comenzó a pasar a microservicios, que requerían lanzamientos frecuentes, y por separado el uno del otro. Así que gradualmente llegamos a las versiones automáticas de nuestros microservicios (por ahora, estamos lanzando el monolito manualmente debido a la complejidad del proceso). Pero, como suele suceder, ha surgido una nueva complejidad.
Prueba automatizada
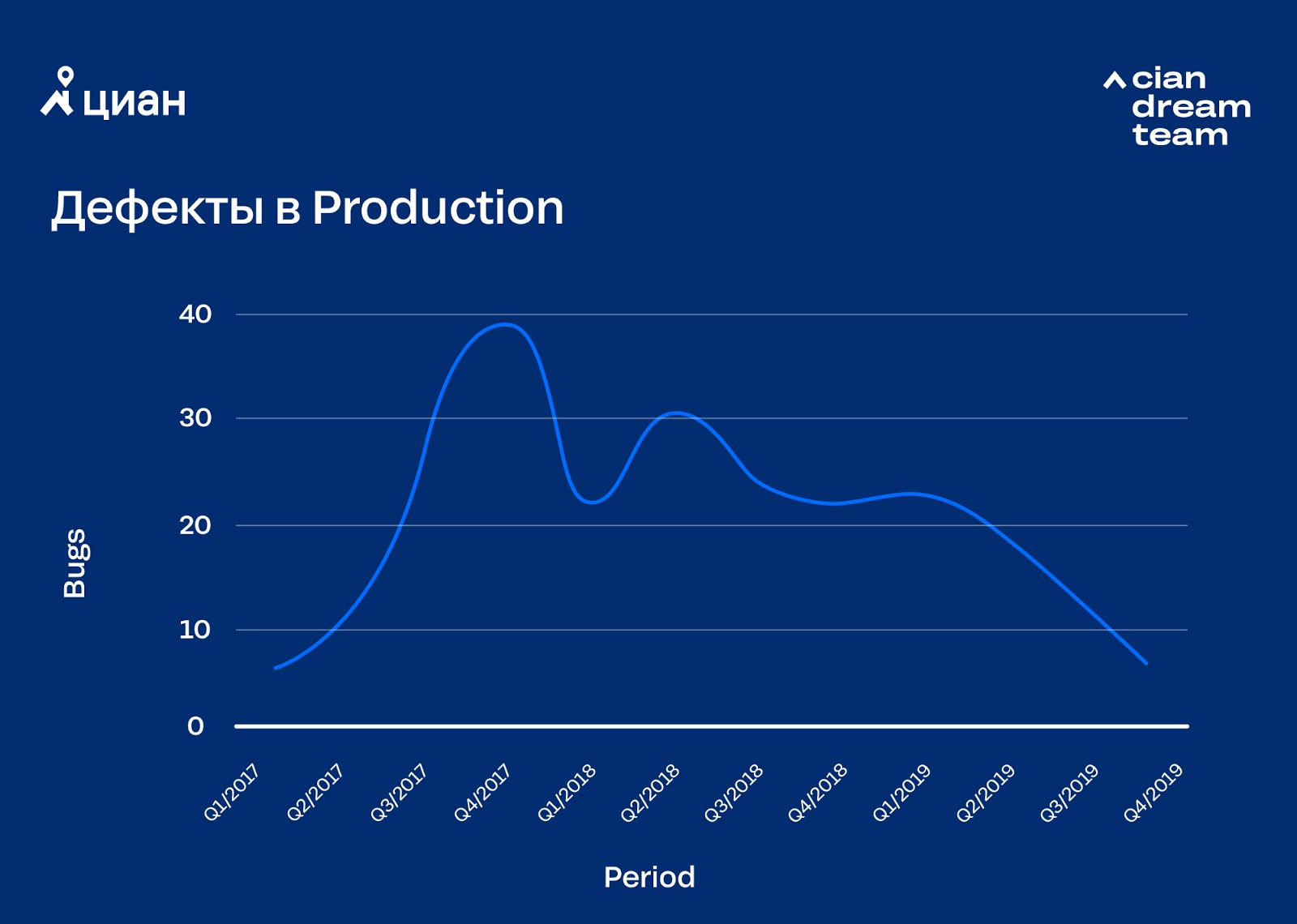
Debido a la automatización de las versiones, los procesos de desarrollo se han acelerado, en parte debido a la omisión de algunas etapas de las pruebas. Y esto condujo a una pérdida temporal de calidad. Suena cursi, pero junto con la aceleración de los lanzamientos, fue necesario cambiar la metodología de desarrollo del producto. Era necesario pensar en la automatización de pruebas, la inculcación de responsabilidad personal (aquí estamos hablando de "aceptar ideas en la cabeza", no multas monetarias) del desarrollador por el código liberado y los errores en él, así como sobre la decisión de emitir / no emitir la tarea a través de un despliegue automático.
Al eliminar los problemas de calidad, llegamos a dos decisiones importantes: comenzamos a realizar pruebas canarias e implementamos el monitoreo automático del fondo del error con una respuesta automática a su exceso. La primera solución hizo posible encontrar errores obvios antes de que el código entrara completamente en producción, la segunda redujo el tiempo de respuesta a problemas en la producción. Los errores, por supuesto, ocurren, pero gastamos la mayor parte de nuestro tiempo y energía no en la corrección, sino en la minimización.
Equipo de automatización
Ahora tenemos un personal de 130 desarrolladores y seguimos
creciendo . El equipo para la integración continua y la entrega de código (en adelante, el equipo de Implementación e Integración o DI) está formado por 7 personas y trabaja en 2 direcciones: desarrollo de la plataforma de automatización Integro y DevOps.
DevOps es responsable del entorno Dev / Beta del sitio web de CIAN, el entorno Integro, ayuda a los desarrolladores a resolver problemas y desarrolla nuevos enfoques para entornos de escala. La línea de negocios de Integro se ocupa tanto de Integro como de servicios relacionados, por ejemplo, complementos para Jenkins, Jira, Confluence, y también desarrolla utilidades y aplicaciones auxiliares para equipos de desarrollo.
El equipo de DI trabaja en conjunto con el equipo de Plataforma, que desarrolla arquitecturas, bibliotecas y enfoques de desarrollo dentro de la empresa. Al mismo tiempo, cualquier desarrollador dentro de CIAN puede contribuir a la automatización, por ejemplo, hacer microautomatización a las necesidades del equipo o compartir una idea genial de cómo hacer que la automatización sea aún mejor.
Automatización de hojaldre en cian
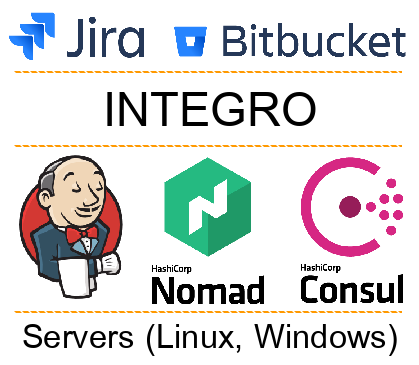
Todos los sistemas involucrados en la automatización se pueden dividir en varias capas:
- Sistemas externos (Jira, Bitbucket, etc.). Los equipos de desarrollo trabajan con ellos.
- Plataforma Integro. Muy a menudo, los desarrolladores no trabajan directamente con él, pero es ella quien apoya el trabajo de toda la automatización.
- Servicios de entrega, orquestación y descubrimiento (por ejemplo, Jeknins, Consul, Nomad). Con su ayuda, implementamos el código en los servidores y brindamos los servicios entre nosotros.
- Capa física (servidor, sistema operativo, software relacionado). En este nivel, nuestro código funciona. Puede ser un servidor físico o uno virtual (LXC, KVM, Docker).
En base a este concepto, dividimos las áreas de responsabilidad dentro del equipo de DI. Los primeros dos niveles están en el área de responsabilidad del área de desarrollo de Integro, y los dos últimos niveles ya están en el área de responsabilidad de DevOps. Esta separación le permite concentrarse en las tareas y no interfiere con la interacción, porque estamos uno al lado del otro e intercambiamos constantemente conocimientos y experiencias.
Integro
Centrémonos en Integro y comencemos con la pila de tecnología:
- CentOs 7
- Docker + Nomad + Consul + Vault
- Java 11 (el antiguo monolito Integro permanecerá en Java 8)
- Spring Boot 2.X + Spring Cloud Config
- PostgreSql 11
- Rabbitmq
- Apache se enciende
- Camunda (incrustada)
- Grafana + Grafito + Prometeo + Jaeger + ELK
- Interfaz de usuario web: React (CSR) + MobX
- SSO: Keycloak
Nos adherimos al principio del desarrollo de microservicios, aunque tenemos un legado en forma de monolito de la versión anterior de Integro. Cada microservicio gira en su contenedor acoplable, los servicios se comunican entre sí a través de solicitudes HTTP y mensajes RabbitMQ. Los microservicios se encuentran entre sí a través de Consul y le ejecutan una solicitud, pasando la autorización a través de SSO (Keycloak, OAuth 2 / OpenID Connect).

Como un ejemplo real, considere la interacción con Jenkins, que consta de los siguientes pasos:
- El microservicio de gestión del flujo de trabajo (en lo sucesivo denominado microservicio Flow) quiere ejecutar el ensamblaje en Jenkins. Para hacer esto, encuentra a través de la integración del microservicio Consul IP: PORT con Jenkins (en adelante, microservicio Jenkins) y le envía una solicitud asíncrona para iniciar el ensamblaje en Jenkins.
- El microservicio de Jenkins, al recibir la solicitud, genera y devuelve la ID del trabajo, por lo que será posible identificar el resultado del trabajo. Junto con esto, comienza la compilación en Jenkins a través de una llamada a la API REST.
- Jenkins construye y, cuando termina, envía un webhook con los resultados al microservicio de Jenkins.
- Un microservicio de Jenkins, después de haber recibido un webhook, genera un mensaje sobre la finalización del procesamiento de la solicitud y le adjunta los resultados de la ejecución. El mensaje generado se envía a la cola RabbitMQ.
- A través de RabbitMQ, el mensaje publicado llega al microservicio Flow, que aprende sobre el resultado del procesamiento de su tarea al hacer coincidir el ID del trabajo de la solicitud y el mensaje recibido.
Ahora tenemos unos 30 microservicios que se pueden dividir en varios grupos:
- Gestión de configuraciones.
- Informar e interactuar con los usuarios (mensajería instantánea, correo).
- Trabajar con código fuente.
- Integración con herramientas de implementación (jenkins, nómada, cónsul, etc.).
- Monitoreo (lanzamientos, errores, etc.).
- Utilidades web (IU para gestionar entornos de prueba, recopilar estadísticas, etc.).
- Integración con rastreadores de tareas y sistemas similares.
- Administre el flujo de trabajo para diferentes tareas.
Tareas de flujo de trabajo
Integro automatiza actividades relacionadas con el ciclo de vida de la tarea. Simplificado por el ciclo de vida de la tarea, nos referimos al flujo de trabajo de una tarea en Jira. En nuestros procesos de desarrollo, existen varias variaciones del flujo de trabajo según el proyecto, el tipo de tarea y las opciones seleccionadas en una tarea en particular.
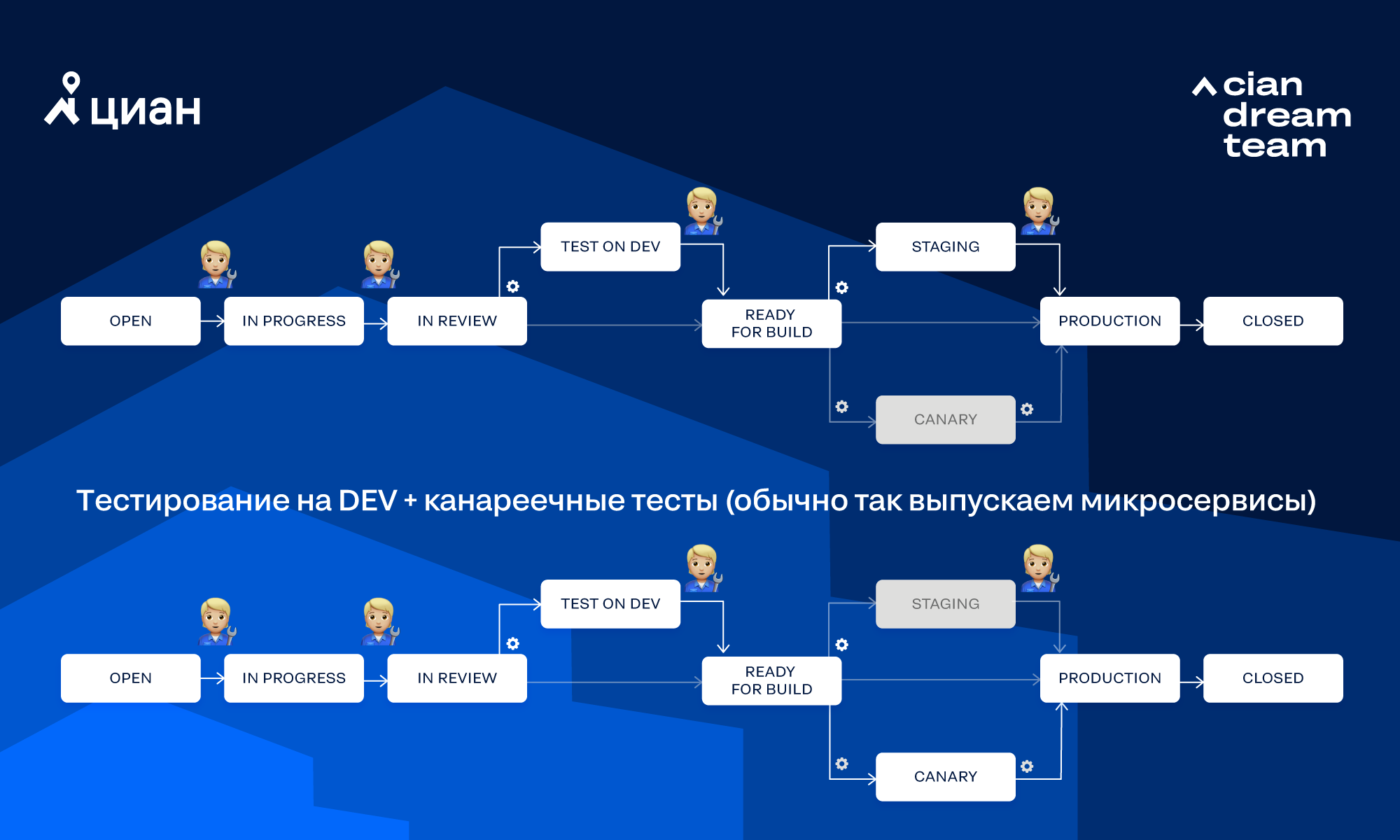
Considere el flujo de trabajo que usamos con mayor frecuencia:
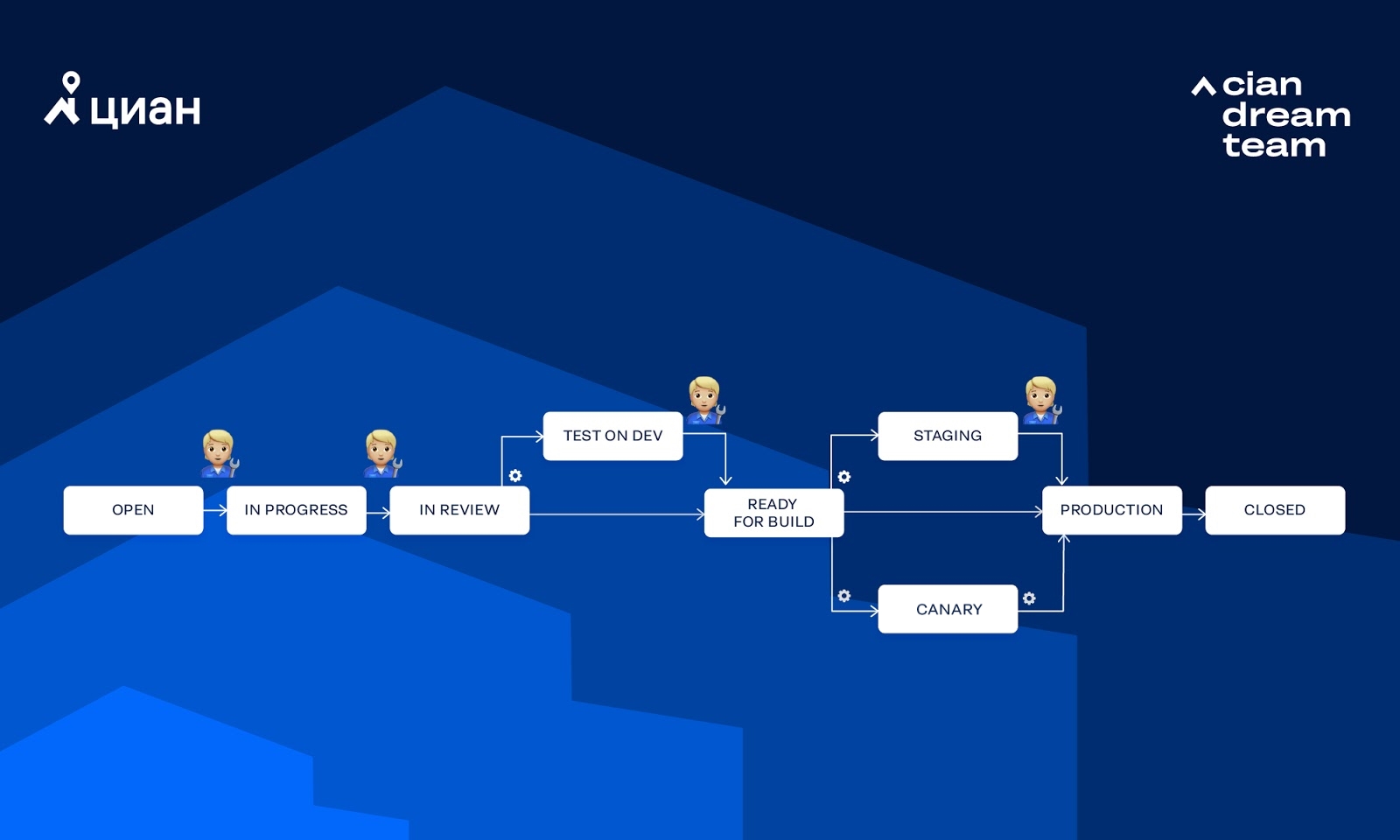
En el diagrama, el engranaje indica que Integro llama a la transición automáticamente, mientras que la figura humana significa que la persona llama manualmente a la transición. Veamos algunas formas en que una tarea puede pasar por este flujo de trabajo.
Pruebas completamente manuales para DEV + BETA sin pruebas canarias (generalmente lanzamos un monolito):
Puede haber otras combinaciones de transición. A veces, el camino que tomará la tarea se puede seleccionar a través de las opciones en Jira.
Movimiento de tareas
Tenga en cuenta los pasos básicos que se realizan al mover la tarea en el flujo de trabajo "Pruebas para pruebas canarias DEV +":
1. El desarrollador o PM crea la tarea.
2. El desarrollador toma la tarea para trabajar. Al finalizar, lo transfiere al estado IN REVIEW.
3. Jira envía Webhook hacia el microservicio de Jira (es responsable de la integración con Jira).
4. El microservicio Jira envía una solicitud al servicio Flow (es responsable de los flujos de trabajo internos en los que se realiza el trabajo) para iniciar el flujo de trabajo.
5. Dentro del servicio Flow:
- Se asignan los revisores para la tarea (Users-microservice que sabe todo sobre los usuarios + Jira-microservice).
- A través del microservicio de origen (sabe sobre repositorios y ramas, pero no funciona con el código en sí), busca repositorios en los que haya una rama de nuestra tarea (para simplificar la búsqueda, el nombre de la rama coincide con el número de tarea en Jira). Muy a menudo, la tarea tiene solo una rama en un repositorio, esto simplifica la gestión de la cola en el despliegue y reduce la conectividad entre los repositorios.
- Para cada rama encontrada, se realiza la siguiente secuencia de acciones:
i) Alimentando la rama maestra (microservicio Git para trabajar con código).
ii) El desarrollador bloquea los cambios de la rama (microservicio de Bitbucket).
iii) Se crea una solicitud de extracción en esta rama (microservicio de Bitbucket).
iv) Se envía un mensaje sobre la nueva Solicitud de extracción a los chats del desarrollador (notifique al microservicio para trabajar con notificaciones).
v) Crear, probar e implementar tareas en DEV (microservicio de Jenkins para trabajar con Jenkins).
vi) Si todos los párrafos anteriores se han completado con éxito, Integro coloca su Aprobar en la Solicitud de extracción (microservicio Bitbucket). - Integro espera una aprobación de solicitud de extracción de los revisores designados.
- Tan pronto como se hayan recibido todas las aprobaciones necesarias (incluidas las pruebas automatizadas que se hayan superado con éxito), Integro transfiere la tarea al estado Prueba en desarrollo (microservicio Jira).
6. Los probadores prueban la tarea. Si no hay problemas, transfieren la tarea al estado Listo para compilar.
7. Integro "ve" que la tarea está lista para su lanzamiento y lanza su implementación en modo canario (microservicio Jenkins). La preparación para la liberación está determinada por un conjunto de reglas. Por ejemplo, una tarea en el estado correcto, no hay bloqueos en otras tareas, ahora no hay cálculos activos de este microservicio, etc.
8. La tarea se transfiere al estado de Canarias (Jira-microservice).
9. Jenkins comienza a través de Nomad un despliegue de tareas en modo canario (generalmente 1-3 instancias) y notifica al servicio de supervisión de lanzamiento (microservicio DeployWatch) del cálculo.
10. DeployWatch-microservice recopila errores de fondo y responde si es necesario. Si se supera el error de fondo (la tasa de fondo se calcula automáticamente), los desarrolladores reciben una notificación a través del microservicio Notificar. Si después de 5 minutos el desarrollador no respondió (hizo clic en Revertir o en Suspensión), se inicia la reversión automática de las instancias canarias. Si no se supera el fondo, entonces el desarrollador debe iniciar manualmente la implementación de la tarea en Producción (presionando el botón en la IU). Si dentro de los 60 minutos el desarrollador no inició una implementación en Producción, las instancias canarias también se eliminarán por razones de seguridad.
11. Después de iniciar la implementación en Producción:
- La tarea se transfiere al estado de Producción (microservicio Jira).
- El microservicio de Jenkins inicia el proceso de implementación y notifica la implementación del microservicio DeployWatch.
- DeployWatch-microservice verifica que todos los contenedores se actualizaron en Producción (hubo casos en que no todos se actualizaron).
- Se envía una notificación sobre los resultados de la implementación a Producción a través del microservicio Notificar.
12. Los desarrolladores tendrán 30 minutos para comenzar la reversión de la tarea con Producción en caso de detectar un comportamiento incorrecto del microservicio. Después de este tiempo, la tarea se vertirá automáticamente en el maestro (Git-microservice).
13. Después de una fusión exitosa en master, el estado de la tarea cambiará a Cerrado (microservicio Jira).
El esquema no pretende ser completamente detallado (en realidad, hay aún más pasos), pero le permite evaluar el grado de integración en los procesos. No consideramos que este esquema sea ideal y mejoramos los procesos de seguimiento automático de lanzamientos y despliegues.
Que sigue
Tenemos grandes planes para el desarrollo de la automatización, por ejemplo, el rechazo de las operaciones manuales durante los lanzamientos de monolitos, la mejora de la supervisión durante la implementación automática, la mejora de la interacción con los desarrolladores.
Pero por ahora, detengámonos en este lugar. Cubrimos superficialmente muchos temas en la revisión de automatización, algunos no los tocaron en absoluto, por lo que estaremos encantados de responder preguntas. Estamos a la espera de sugerencias sobre qué cubrir en detalle, escriba en los comentarios.