Hola Habr! Les presento la traducción del artículo "Visualizando un modelo de traducción automática neuronal (Mecánica de modelos Seq2seq con atención)" por Jay Alammar.
Los modelos de secuencia a secuencia (seq2seq) son modelos de aprendizaje profundo que han logrado un gran éxito en tareas como traducción automática, resumen de texto, anotación de imágenes, etc. Por ejemplo, a fines de 2016, se incorporó un modelo similar en Google Translate. Las bases de los modelos seq2seq se establecieron en 2014 con el lanzamiento de dos artículos: Sutskever et al., 2014 , Cho et al., 2014 .
Para comprender lo suficiente y luego usar estos modelos, primero deben aclararse algunos conceptos. Las visualizaciones propuestas en este artículo serán un buen complemento para los artículos mencionados anteriormente.
El modelo de secuencia a secuencia es un modelo que acepta una secuencia de entrada de elementos (palabras, letras, atributos de imagen, etc.) y devuelve otra secuencia de elementos. El modelo entrenado funciona de la siguiente manera:
En la traducción automática neuronal, una secuencia de elementos es una colección de palabras que se procesan a su vez. La conclusión también es un conjunto de palabras:
Echa un vistazo debajo del capó
Debajo del capó, el modelo tiene un codificador y decodificador.
El codificador procesa cada elemento de la secuencia de entrada, traduce la información recibida en un vector llamado contexto. Después de procesar toda la secuencia de entrada, el codificador envía el contexto al decodificador, que luego comienza a generar la secuencia de salida elemento por elemento.
Lo mismo sucede con la traducción automática.
Para la traducción automática, el contexto es un vector (una matriz de números), y el codificador y el decodificador, a su vez, son redes neuronales recurrentes (consulte la introducción a RNN: una introducción amigable a las redes neuronales recurrentes ).

El contexto es un vector de números de coma flotante. Además en el artículo, los vectores se visualizarán en color para que el color más claro corresponda a celdas con valores grandes.
Al entrenar el modelo, puede establecer el tamaño del vector de contexto: el número de neuronas ocultas (unidades ocultas) en el codificador RNN. Los datos de visualización muestran un vector de 4 dimensiones, pero en aplicaciones reales el vector de contexto tendrá una dimensión del orden de 256, 512 o 1024.
Por defecto, en cada intervalo de tiempo, RNN recibe dos elementos para la entrada: el elemento de entrada en sí (en el caso de un codificador, una palabra de la oración original) y el estado oculto. La palabra, sin embargo, debe estar representada por un vector. Para convertir una palabra en un vector, recurren a una serie de algoritmos llamados incrustaciones de palabras. Las incrustaciones traducen palabras en espacios vectoriales que contienen información semántica y semántica sobre ellas (por ejemplo, "rey" - "hombre" + "mujer" = "reina" ).
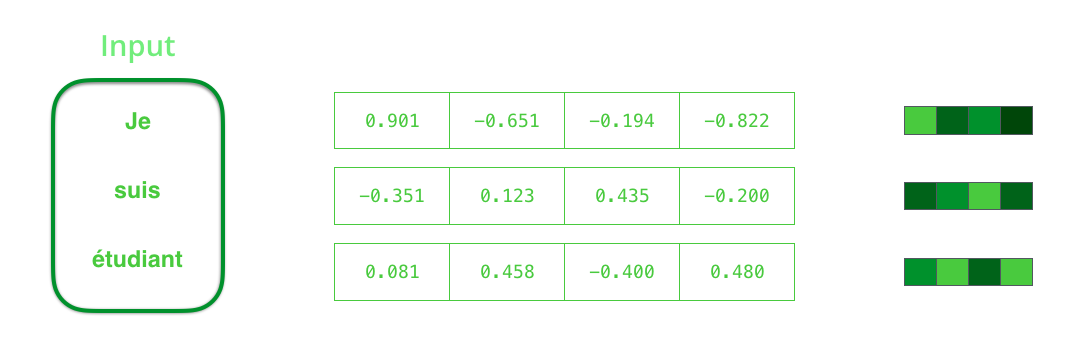
Antes de procesar palabras, debe convertirlas en vectores. Esta transformación se lleva a cabo utilizando el algoritmo de inclusión de palabras. Puede utilizar incrustaciones pre-entrenadas y entretejidas en su conjunto de datos. 200-300 - dimensión típica del vector de incrustación; Este artículo utiliza la dimensión 4 por simplicidad.
Ahora que nos hemos familiarizado con nuestros principales vectores / tensores, recordemos el mecanismo de RNN y creemos visualizaciones para describirlo:
En el siguiente paso, RNN toma el segundo vector de entrada y el estado latente # 1 para formar la salida en este intervalo de tiempo. Más adelante en el artículo, se usa una animación similar para describir vectores dentro de un modelo de traducción automática neuronal.
En la siguiente visualización, cada cuadro describe el procesamiento de entradas por un codificador y la generación de salidas por un decodificador en un intervalo de tiempo. Dado que tanto el codificador como el decodificador son RNN, en cada intervalo de tiempo, la red neuronal está ocupada procesando y actualizando sus estados ocultos en función de las entradas actuales y anteriores. En este caso, el último de los estados ocultos del codificador es el contexto mismo que se transmite al decodificador.
El decodificador también contiene estados ocultos que transfiere de un intervalo de tiempo a otro. (Esto no está en la visualización, representando solo las partes principales del modelo).
Ahora pasamos a otro tipo de visualización de modelos de secuencia a secuencia. Esta animación ayudará a comprender los gráficos estáticos que describen estos modelos, los llamados una vista desenrollada, donde en lugar de mostrar un decodificador, mostramos una copia para cada intervalo de tiempo. Entonces podemos mirar los elementos de entrada y salida en cada intervalo de tiempo.
¡Presta atención!
El vector de contexto es un cuello de botella para este tipo de modelo, lo que les dificulta lidiar con oraciones largas. La solución fue propuesta en artículos de Bahdanau et al., 2014 y Luong et al., 2015 , que presentaron una técnica llamada mecanismo de atención. Este mecanismo mejora significativamente la calidad de los sistemas de traducción automática, permitiendo que los modelos se concentren en las partes relevantes de las secuencias de entrada.
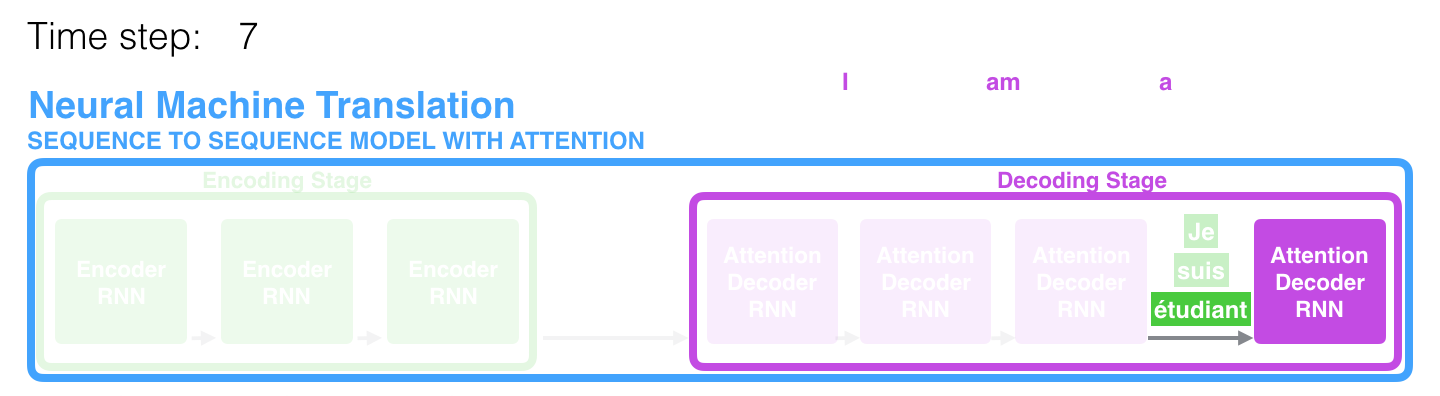
En el séptimo período de tiempo, el mecanismo de atención permite al decodificador enfocarse en la palabra étudiant (estudiante en francés) antes de generar una traducción al inglés. Esta capacidad de amplificar la señal de la parte relevante de la secuencia de entrada permite que los modelos basados en el mecanismo de atención obtengan un mejor resultado en comparación con otros modelos.
Cuando se considera un modelo con un mecanismo de atención a un alto nivel de abstracción, se pueden distinguir dos diferencias principales del modelo clásico de secuencia a secuencia.
En primer lugar, el codificador transfiere significativamente más datos al decodificador: en lugar de transmitir solo el último estado oculto después de la etapa de codificación, el codificador le envía todos sus estados ocultos:
En segundo lugar, el decodificador pasa por un paso adicional antes de generar la salida. Para enfocarse en aquellas partes de la secuencia de entrada que son relevantes para el lapso de tiempo correspondiente, el decodificador hace lo siguiente:
- Examina un conjunto de estados latentes recibidos de un codificador: cada uno de los estados latentes se correlaciona mejor con una de las palabras en la secuencia de entrada;
- Asigna una determinada evaluación a cada estado latente (omita por ahora cómo ocurre el procedimiento de estimación);
- Multiplica cada estado oculto por una función de evaluación convertida por softmax, resaltando así los estados ocultos con una calificación grande y relegando los estados ocultos con uno pequeño al fondo.
Este "ejercicio de calificación" se realiza en el decodificador en cada intervalo de tiempo.
Entonces, resumiendo todo lo anterior, consideramos el proceso del modelo con el mecanismo de atención:
- En el decodificador, el RNN recibe la incorporación <END> del token y el estado oculto inicial.
- El RNN procesa el elemento de entrada, genera la salida y un nuevo vector de estado oculto (h4). La salida se descarta.
- El mecanismo de atención utiliza los estados ocultos del codificador y el vector h4 para calcular el vector de contexto (C4) en un intervalo de tiempo dado.
- Los vectores h4 y C4 se concatenan en un solo vector.
- Este vector se pasa a través de una red neuronal de alimentación directa (FFN), entrenada junto con el modelo.
- La salida de la red FFN indica la palabra de salida en un intervalo de tiempo dado.
- El algoritmo se repite para el siguiente intervalo de tiempo.
Otra forma de ver en qué parte de la oración original se enfoca el modelo en cada etapa del decodificador:
Tenga en cuenta que el modelo no solo conecta sin pensar la primera palabra en la entrada con la primera palabra en la salida. Ella realmente entendió durante el proceso de capacitación cómo unir las palabras en este par de idiomas considerado (en nuestro caso, francés e inglés). Un ejemplo de la precisión con que puede funcionar este mecanismo se puede encontrar en los artículos sobre el mecanismo de atención mencionados anteriormente.

Si cree que está listo para aprender cómo aplicar este modelo, consulte el manual de Traducción Neural Automática (seq2seq) en TensorFlow.
Los autores