MongoDB की सबसे अधिक प्रचारित सुविधाओं में से एक लचीलापन है। मैं स्वयं बार-बार मोंगबॉब के बारे में अनगिनत बातचीत में इस पर जोर देता हूं। हालाँकि, लचीलापन एक दोधारी तलवार है: अधिक लचीलेपन का तात्पर्य डेटा मॉडलिंग समाधानों की व्यापक पसंद से है। हालाँकि, मुझे वह लचीलापन पसंद है जो MongoDB प्रदान करता है, आपको डेटा मॉडल विकसित करने से पहले बस कुछ सिफारिशों को ध्यान में रखना होगा।
इस लेख में, हम देखेंगे कि इन सूचियों पर आने वाले लोगों के बारे में मेलिंग सूचियों और डेटा वाली संरचना को कैसे मॉडल किया जाए।
निम्नलिखित आवश्यकताएं हैं:
- एक व्यक्ति के एक या अधिक ई-मेल पते हो सकते हैं;
- एक व्यक्ति किसी भी मेलिंग सूची में हो सकता है;
- कोई भी व्यक्ति किसी भी मेलिंग सूची के लिए कोई भी नाम चुन सकता है।
"कोई एम्बेड नहीं" रणनीति
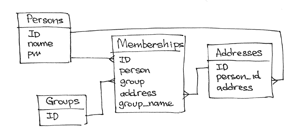
आइए देखें कि हमारा डेटा मॉडल कैसा दिखेगा यदि कोई डेटा कहीं भी एम्बेडेड नहीं है।
हमारे पास उपयोगकर्ता नाम और पासवर्ड वाले ग्राहक हैं:
{ _id: PERSON_ID, name: " ", pw: " " }
हमारे पास
एड्रेस्रेस पतों का एक संग्रह है जिसमें प्रत्येक दस्तावेज़ में एक ई-मेल पता और एक विशिष्ट ग्राहक के लिए बाध्यकारी है:
{ _id: ADDRESS_ID, person: PERSON_ID, address: "vpupkin@gmail.com" }
हमारे पास
समूह हैं , जिनमें से प्रत्येक में केवल समूह के पहचानकर्ता शामिल हैं (यह, निश्चित रूप से, अन्य डेटा हो सकते हैं, लेकिन हम इस क्षण को विशेष रूप से सदस्यता पर ध्यान केंद्रित करने के लिए छोड़ देते हैं)
{ _id: GROUP_ID }
अंत में, हमारे पास
सदस्यता सदस्यता का संग्रह है। प्रत्येक सदस्यता समूह में लोगों को एकजुट करती है, इसके अलावा, इसमें वह नाम शामिल है जिसे व्यक्ति ने इस समूह के लिए चुना था, और उस ई-मेल पते का लिंक जिसे वह इस समूह में समाचार पत्र प्राप्त करने के लिए उपयोग करना चाहता है:
{ _id: MEMBERSHIP_ID, person: PERSON_ID, group: GROUP_ID, address: ADDRESS_ID, group_name: "" }
यह डेटा मॉडल स्पष्ट, विकसित करने में आसान और बनाए रखने में आसान है। हमने एक मॉडल बनाया है जो रिलेशनल डेटाबेस में उपयोग करने के लिए सुविधाजनक है। उसी समय, हमने मोंगोबीडी के दस्तावेज़-उन्मुख दृष्टिकोण को ध्यान में नहीं रखा। आइए देखें कि हमें क्या करना है, उदाहरण के लिए, एक समूह के सभी सदस्यों के ई-मेल पते, एक ज्ञात ई-मेल पता और इस समूह का नाम:
- पते के संग्रह में, प्रसिद्ध ई-मेल द्वारा, हम
PERSON_ID पाते हैं; - सदस्यता संग्रह में, प्राप्त
PERSON_ID और समूह के सुप्रसिद्ध नाम से, हम GROUP_ID पाते हैं; - पुन: सदस्यता संग्रह में, प्राप्त
GROUP_ID द्वारा हम इस समूह की सदस्यता की सूची प्राप्त करते हैं; - और अंत में,
ADDRESS_ID द्वारा पते के संग्रह से, प्राप्त सूची से प्रत्येक सदस्यता के माध्यम से, हमें ई-मेल पते की एक सूची मिलती है।
थोड़ा जटिल है, है ना?
ऑल-इन-वन रणनीति
अब उस स्थिति पर विचार करें जब सभी डेटा एक दस्तावेज़ में एम्बेडेड हो। ऐसा करने के लिए, हम सभी समूह सदस्यताएँ लेंगे और उन्हें समूह मॉडल में एम्बेड करेंगे। साथ ही, प्रत्येक सब्सक्रिप्शन में हम सब्सक्राइबर और उसके ई-मेल पते के बारे में डेटा एम्बेड करेंगे:
{ _id: GROUP_ID, memberships: [{ address: "vpupkin@gmail.com", name: " ", pw: " ", person_addresses: ["vpupkin@gmail.com", "vpupkin@mail.ru", ...], group_name: "" }, ...] }
सभी कनेक्टेड डेटा को एक दस्तावेज़ में एम्बेड करने की बात यह है कि अब कुछ डेटा क्वेरी करना बहुत आसान है। लेख के पिछले भाग से अनुरोध काफी सरल हो जाता है (याद रखें, हमें इस समूह के शेष सदस्यों के ई-मेल पते का पता लगाने के लिए एक ज्ञात ई-मेल पता और समूह का नाम होना चाहिए):
- समूह संग्रह में हमें वह समूह मिलता है जिसमें सदस्यता होती है, जिसमें
person_addresses उस समूह के नाम से मेल खाता है जिसे हम जानते हैं और person_addresses सरणी में वह ईमेल होता है जिसे हम जानते हैं; - हम शेष ई-मेल पते निकालने के लिए प्राप्त दस्तावेज़ का विश्लेषण करेंगे।
बहुत आसान है। लेकिन क्या होगा अगर सब्सक्राइबर नाम या पासवर्ड बदलना चाहता है? हमें प्रत्येक समूह के प्रत्येक अंतर्निहित सदस्यता में उसका नाम या पासवर्ड बदलना होगा, जिसमें यह सदस्य एक सदस्य है। यह
person_addresses सरणी से एक मौजूदा ई-मेल पता हटाने या जोड़ने के लिए भी लागू होता है। इस तरह के क्षण हमें इस मॉडल की विशिष्ट प्रकृति के बारे में बताते हैं: यह विशिष्ट प्रश्नों के लिए अच्छी तरह से अनुकूल है (क्योंकि सभी आवश्यक डेटा पहले से ही अंदर है, जैसे कि पूर्व-जुड़ाव), लेकिन यह रखरखाव के मामले में दीर्घकालिक रूप से बुरे सपने बन सकते हैं।
आंशिक एम्बेड रणनीति
जिस दृष्टिकोण की मैं सबसे अधिक सलाह देता हूं, वह है बिना एम्बेड किए डेटा मॉडल के बारे में सोचना शुरू करना। एक बार जब आपके पास एक मसौदा मॉडल होता है, तो आप उन मामलों को उजागर करना शुरू कर सकते हैं जहां एम्बेडिंग समझ में आता है। यह आमतौर पर एक-से-कई संबंध हैं।
उदाहरण के लिए,
पते के संग्रह के कई ई-मेल पते एक सब्सक्राइबर के होते हैं (वे सब्सक्रिप्शन मॉडल में भी भाग लेते हैं) और आमतौर पर इतने बार नहीं बदलते हैं। इसलिए, हम उन्हें एक सरणी में जोड़ देंगे और हमारे मॉडल में एक सब्सक्राइबर जोड़ देंगे, जिससे यह मानसिक मॉडल के समान हो जाएगा।
प्रत्येक सब्सक्रिप्शन एक विशिष्ट सब्सक्राइबर और एक विशिष्ट समूह से जुड़ा होता है, इसलिए आप सबस्क्राइबर के मॉडल और समूह के मॉडल दोनों में सब्सक्रिप्शन एम्बेड कर सकते हैं। ऐसे मामलों में, डेटा एक्सेस मॉडल और एम्बेडेड डेटा के आकार के बारे में सोचना महत्वपूर्ण है। हम उम्मीद करते हैं कि लोग 1000 से अधिक विभिन्न समूहों से न्यूज़लेटर की सदस्यता लेने की संभावना नहीं रखते हैं, और एक समूह, बदले में, 1000 से अधिक ग्राहकों को प्राप्त करने की संभावना नहीं है। इस मामले में, संख्याएं हमें कुछ भी उपयोगी नहीं बताती हैं। हालांकि, हमारे डेटा एक्सेस मॉडल, इसके विपरीत, हमें बताता है कि जब आप इसे प्रदर्शित करते हैं, तो आपको किसी विशेष व्यक्ति की सभी सदस्यताएं देखने की आवश्यकता होती है। अनुरोध को सरल बनाने के लिए, हम सब्सक्राइबर मॉडल में सब्सक्रिप्शन एम्बेड करेंगे। लाभ यह है कि सब्सक्राइबर के ई-मेल पते की सूची सब्सक्राइबर के मॉडल में है, और सब्सक्रिप्शन में इस सूची के किसी एक पते का उपयोग किया जाता है, और अगर हमें ई-मेल पते को बदलने या हटाने की आवश्यकता है, तो यह एक ही स्थान पर किया जा सकता है।
अब हमारा डेटा मॉडल इस तरह दिखता है:
{ _id: PERSON_ID, name: " ", pw: " ", addresses: ["vpupkin@gmail.com", "vpupkin@mail.ru", ...], memberships: [{ address: "vpupkin@gmail.com", group_name: "", group: GROUP_ID }, ...] }
यह सबस्क्राइबर मॉडल है, इसके अलावा समूह का मॉडल भी है, जो "बिना एम्बेड किए" रणनीति के विवरण में वर्णित एक के समान है।
ऊपर हमने जिस क्वेरी की चर्चा की है, वह अब इस तरह दिखाई देगी:
- लोगों के संग्रह में हम सब्सक्राइबर को वांछित ई-मेल पते के साथ पाते हैं, जिसमें से सब्सक्राइबर्स में वांछित नाम के साथ एक सब्सक्रिप्शन है;
- पाया सदस्यता के
GROUP_ID उपयोग करते हुए, हम इस समूह के अन्य लोगों को लोगों के संग्रह में पाएंगे और उनके ई-मेल पते सीधे सदस्यता से लेंगे।
यह अभी भी लगभग उतना ही सरल है जब सब कुछ एम्बेडेड है, लेकिन अब हमारा डेटा मॉडल बहुत साफ है और बनाए रखना आसान है। आशा है कि यह लेख आपके लिए उपयोगी रहा होगा।
एक अनुवादक से: सामान्य तौर पर, यह एक नि: शुल्क अनुवाद है और विशुद्ध रूप से व्यक्तिगत उद्देश्यों के लिए किया गया था, इसलिए सभी कानों में थप्पड़, कृपया, पीएम में। मैं एक आरक्षण भी करता हूं कि कुछ अवधारणाओं को व्यक्तिपरक कारणों से प्रतिस्थापित किया जाता है, कुछ बिंदुओं को छोड़ दिया जाता है, क्योंकि उन्होंने सार को समझाने में महत्वपूर्ण भूमिका नहीं निभाई है। किसी भी स्थिति में, कृपया मूल को देखें।