تفوقت أجهزة الكمبيوتر على الأشخاص في الاختبار اللفظي IQ
قبل أكثر من مائة عام ، اقترح عالم النفس الألماني وليام ستيرن (وليام ستيرن) اختبارًا لتقييم ذكاء الشخص ، والذي كان يسمى اختبار الذكاء. منذ ذلك الحين ، أصبح اختبار معدل الذكاء منتشرًا إلى حد كبير باعتباره منهجية قياسية لتقييم ذكاء الأطفال عند دخولهم المدرسة ، وكذلك لتقييم المرشحين البالغين للوظائف.تحتوي اختبارات الذكاء عادة على ثلاثة أنواع من الأسئلة: 1) أسئلة حول المنطق ، حيث تحتاج إلى التعرف على نمط في سلسلة من الصور ؛ 2) أسئلة رياضية ، حيث تحتاج إلى تحديد نمط في تسلسل من الأرقام ؛ 3) المهام اللفظية على أساس المقارنات والتصنيفات ، كمرادفات ومتضادات.طور باحثون من Microsoft Research في بكين ، إلى جانب زملائهم من جامعة العلوم والتكنولوجيا الصينية ، تقنية الذكاء الاصطناعي التي يمكنها حل النوع الثالث من المشاكل المذكورة أعلاه ( مقالة علمية ).لا يمكن أبدًا أن تكون أجهزة الكمبيوتر على دراية جيدة وأن تحل المهام التي تتم صياغتها في شكل لفظي. على الأقل فعلوا ذلك أسوأ بكثير من البشر. إن تطوير Microsoft Research يغير الأشياء. تجاوز برنامجهم ، القائم على نظام التعلم العميق ، لأول مرة متوسط النتيجة التي أظهرها الناس عند حل المهام اللفظية من اختبار الذكاء.في السنوات السابقة ، استخدم العلماء تقنية استخراج البيانات لتحليل كميات كبيرة من النصوص للعثور على روابط معينة بين الكلمات. على وجه الخصوص ، تسمح لك هذه التقنية بتجميع قاموس مع مؤشرات إحصائية عن عدد المرات التي تكون فيها كلمات معينة قريبة. هذا يسمح لك بتحديد علاقة الكلمات مع بعضها البعض.ونتيجة لذلك ، يُنظر إلى كل كلمة في مثل هذا النظام على أنها متجه في مساحة معلمة متعددة الأبعاد. يمكن معالجة هذا النظام من المتجهات بالطرق الرياضية: قارنها ، أضفها ، اطرح من بعضها البعض ، مثل المتجهات العادية. على سبيل المثال ، تصبح معادلة مماثلة ممكنة: "الملك - الرجل + المرأة = الملكة".أثبت هذا النهج فعاليته. على سبيل المثال ، تستخدم Google التنقيب عن البيانات في نظام ترجمة النص التلقائي ، بمقارنة ناقلات الكلمات بلغات مختلفة.ولكن في حالة اختبارات الذكاء اللفظي ، تكون المهمة معقدة ، لأن كلمة واحدة يمكن أن يكون لها معان عديدة. يقوم مجمعو الاختبارات بذلك على وجه التحديد لتعقيد المهمة.توصلت مجموعة من الباحثين من قسم أبحاث Microsoft إلى حل لهذه المشكلة باستخدام نفس استخراج البيانات: يحدد برنامجهم الكلمات التي غالبًا ما تحدث كل كلمة في مجموعة من النصوص ، ثم يحدد المعاني المحتملة لهذه الكلمة ، بناءً على المعلومات الواردة. يتم ذلك عن طريق حساب المتجهات من الجمل الناتجة. بالنسبة للبرنامج ، يتم أولاً تجميع مصفوفة لتكرار حدوث الكلمات ، وبعد ذلك ، على أساس مجموعة النصوص (مقالات ويكيبيديا) ، لكل كلمة ، يشار إلى ناقل حدوث الكلمات الأخرى.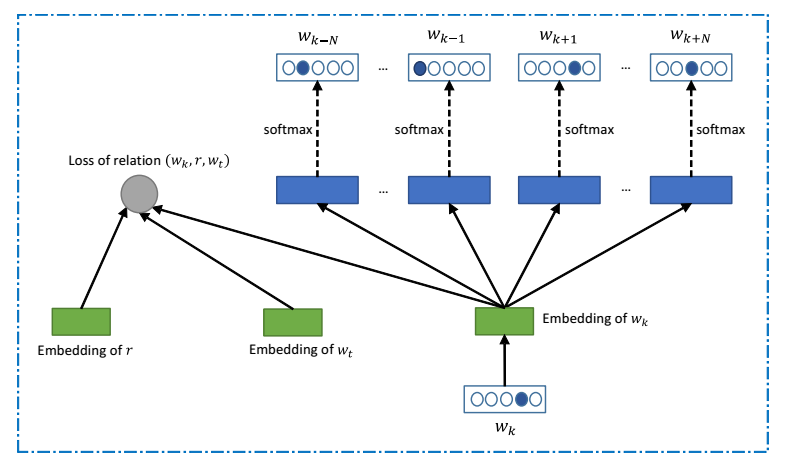 يقول العلماء أن البرنامج يظهر نتيجة أفضل من معظم الناس. تم استطلاع رأي الناس على موقع ميكانيكي ترك.
يقول العلماء أن البرنامج يظهر نتيجة أفضل من معظم الناس. تم استطلاع رأي الناس على موقع ميكانيكي ترك.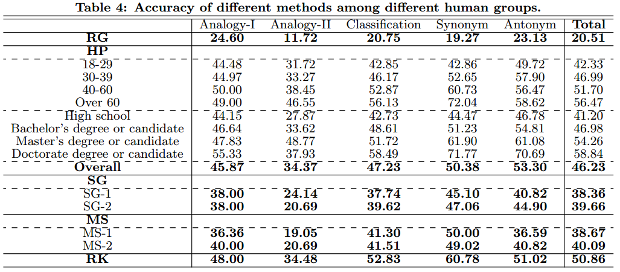 وفقًا للجدول ، تكون نتائجه تقريبًا في المنتصف بين النتائج ، والتي تُظهر متوسط النتائج بالنسبة للعزاب وحاملي درجة الماجستير.
وفقًا للجدول ، تكون نتائجه تقريبًا في المنتصف بين النتائج ، والتي تُظهر متوسط النتائج بالنسبة للعزاب وحاملي درجة الماجستير. Source: https://habr.com/ru/post/ar380839/
All Articles