خطوة أخرى في التعلم الذاتي من الآلة
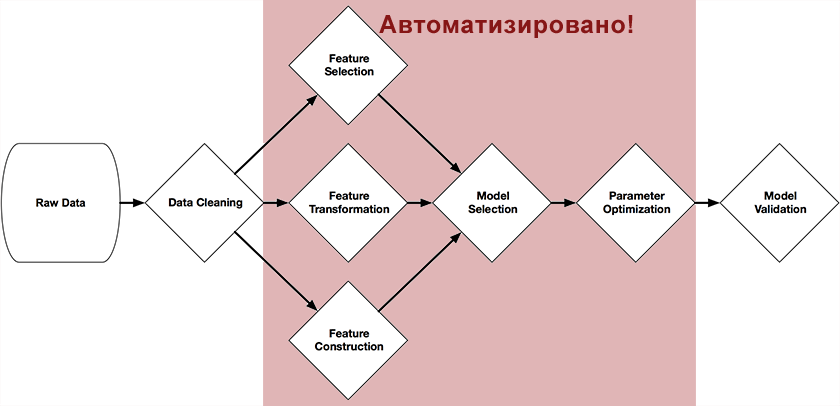 بالطبع ، هناك العديد من نماذج التعلم الذاتي في علوم البيانات ، ولكن هل هي حقًا؟ في الواقع ، لا: يوجد الآن في التعلم الآلي موقف يلعب فيه العامل البشري دورًا حاسمًا في بناء نماذج فعالة.يعد Data Data الآن نوعًا من اندماج العلم والحدس ، لأنه لا توجد معرفة رسمية لكيفية التنبؤ بشكل صحيح بالتنبؤات ، أي نموذج للاختيار من بين العشرات من الموجودة ، وكيفية تكوين العديد من المعلمات في هذا النموذج. يصعب إضفاء الطابع الرسمي على كل هذا ، وبالتالي ينشأ موقف متناقض - يتطلب التعلم الآلي عاملاً بشريًا .إنه الشخص الذي يحتاج إلى بناء سلسلة التعلم ، وضبط المعلمات التي يمكنها بسهولة تحويل أفضل نموذج إلى عديم الفائدة على الإطلاق. قد يستغرق بناء هذه السلسلة ، التي تحول البيانات الأولية إلى نموذج تنبؤي ، عدة أسابيع ، اعتمادًا على تعقيد المهمة ، وغالبًا ما يتم ذلك ببساطة عن طريق التجربة والخطأ.هذا عيب خطير ، وبالتالي نشأت الفكرة: هل يمكن للتعلم الآلي - تثقيف نفسك بنفس الطريقة التي يفعلها الشخص؟ تم إنشاء مثل هذا النظام ، ومن المدهش أن هذه الأخبار لم تصل بعد إلى المجتمع الحرفي!
بالطبع ، هناك العديد من نماذج التعلم الذاتي في علوم البيانات ، ولكن هل هي حقًا؟ في الواقع ، لا: يوجد الآن في التعلم الآلي موقف يلعب فيه العامل البشري دورًا حاسمًا في بناء نماذج فعالة.يعد Data Data الآن نوعًا من اندماج العلم والحدس ، لأنه لا توجد معرفة رسمية لكيفية التنبؤ بشكل صحيح بالتنبؤات ، أي نموذج للاختيار من بين العشرات من الموجودة ، وكيفية تكوين العديد من المعلمات في هذا النموذج. يصعب إضفاء الطابع الرسمي على كل هذا ، وبالتالي ينشأ موقف متناقض - يتطلب التعلم الآلي عاملاً بشريًا .إنه الشخص الذي يحتاج إلى بناء سلسلة التعلم ، وضبط المعلمات التي يمكنها بسهولة تحويل أفضل نموذج إلى عديم الفائدة على الإطلاق. قد يستغرق بناء هذه السلسلة ، التي تحول البيانات الأولية إلى نموذج تنبؤي ، عدة أسابيع ، اعتمادًا على تعقيد المهمة ، وغالبًا ما يتم ذلك ببساطة عن طريق التجربة والخطأ.هذا عيب خطير ، وبالتالي نشأت الفكرة: هل يمكن للتعلم الآلي - تثقيف نفسك بنفس الطريقة التي يفعلها الشخص؟ تم إنشاء مثل هذا النظام ، ومن المدهش أن هذه الأخبار لم تصل بعد إلى المجتمع الحرفي!TROT (أداة تحسين خطوط الأنابيب المرتكزة على الأشجار)
راندي أولسون ، طالب دراسات عليا في مختبر علم الوراثة الحاسوبية (جامعة بنسلفانيا) ، طور أداة تحسين خطوط الأنابيب المستندة إلى الأشجار كجزء من مشروع تخرجه .يتم وضع هذا النظام كمساعد علوم البيانات. إنها تعمل على أتمتة الجزء الأكثر إرهاقًا في التعلم الآلي والدراسة والاختيار من بين آلاف سلاسل البناء الممكنة تمامًا السلسلة الأنسب لمعالجة بياناتك.تمت كتابة النظام في Python باستخدام مكتبة التعلم المعرفية ، ومن خلال الخوارزميات الجينية تبني بشكل مستقل سلسلة كاملة من إعداد النموذج والبناء. يعرض الشكل في بداية هذه المقالة تلك الأجزاء من السلسلة التي يمكن أتمتتها بمساعدتها: المعالجة المسبقة واختيار التنبئات ، واختيار النماذج ، وتحسين معلماتها.الفكرة بسيطة للغاية - خوارزمية جينية .هذه خوارزمية للعثور على السلسلة التي نحتاجها عن طريق الانتقاء العشوائي ، باستخدام آليات مماثلة للانتقاء الطبيعي في الطبيعة. وهي مكتوبة بتفاصيل كافية عنها على ويكيبيديا أو على حبر أو في كتاب "أنظمة التعلم الذاتي"(أوصي للمهتمين بهذا الموضوع أن توجد شبكة في شكل إلكتروني).كدالة للاختيار (وظيفة اللياقة البدنية) ، يتم استخدام دقة التنبؤ في عينة الاختبار ، حيث أن كائن السكان عبارة عن طرق scikit ومعلماتها.النتائج
يقدم المؤلف مثالًا بسيطًا على كيفية استخدام TPOT لحل المشكلة المرجعية لتصنيف الأرقام المكتوبة بخط اليد من مجموعة MNISTfrom tpot import TPOT
from sklearn.datasets import load_digits
from sklearn.cross_validation import train_test_split
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, train_size=0.75)
tpot = TPOT(generations=5, verbosity=2)
tpot.fit(X_train, y_train)
print( tpot.score(X_train, y_train, X_test, y_test) )
tpot.export('tpot_exported_pipeline.py')
عند تشغيل الكود ، بعد دقيقتين ، يمكن لـ TPOT الحصول على سلسلة بناء النموذج ، التي تصل دقتها إلى 98٪. سيحدث هذا عندما يكتشف TPOT أن مصنّف Random Forest يعمل بشكل مثالي على بيانات MNIST.ومع ذلك ، نظرًا لأن هذه العملية احتمالية ، فمن المستحسن تعيين معلمة random_state للنتائج القابلة للتكرار - على سبيل المثال ، لخمسة أجيال ، لم أجد سوى سلسلة ذات SVC و KNeighboursClassifier. أعطىاختبار النظام على مشكلة كلاسيكية أخرى ، قزحية فيشر ، دقة 97٪ على مدى 10 أجيال.المستقبل
Trot هو مشروع مفتوح المصدر نشأ منذ شهر (وهو عمومًا عمر الطفل لهذه الأنظمة) ويتطور الآن بنشاط. على موقع المشروع على الإنترنت ، يشجع المؤلف مجتمع علماء البيانات على الانضمام إلى تطوير نظام تتوفر شفرته على github (https://github.com/rhiever/tpot)بالطبع ، النظام الآن بعيد جدًا عن المثالية ، لكن فكرة هذا النظام تبدو منطقية للغاية - أتمتة كاملة العملية الكاملة للتعلم الآلي. وإذا تطورت الفكرة ، فربما تظهر الأنظمة قريبًا حيث يُطلب من الشخص فقط تنزيل البيانات والحصول على نتيجة. ثم يطرح سؤال آخر: هل هناك حاجة إلى أي شخص على الإطلاق لبناء نماذج التعلم الذاتي؟