هل لدى AlphaGo فرصة في المباراة ضد Lee Sedol: آراء وتصنيفات اللاعبين المحترفين في ال
ستقام مباراة Google go-pro 9th و Google AI في مارس
 لا يوجد جهاز كمبيوتر قادر على التغلب على لاعب محترف في لعبة الطاولة الآسيوية. الشيء هو عن ميزات اللعبة: هناك العديد من المواقف ، ومن الصعب وصف الحدس البشري خوارزمية. كان لدى العالم وجهات نظر مماثلة حتى 27 يناير. قبل بضعة أيام ، نشرت Google بيانات بحثية من قسم DeepMind . يتحدث عن نظام AlphaGo ، الذي تمكن في أكتوبر من العام الماضي من التغلب على اللاعب الثاني المحترف Dan Fan في 5 من أصل خمس مباريات.ومع ذلك ، كان لدى اللاعبين المحترفين والمعارف من go أسئلة حول جودة اللعبة. هوى بطل ثلاث مرات ، ولكنه بطل أوروبي ، حيث مستوى اللعبة ليس مرتفعا للغاية. ليس فقط خيار اللاعب لإثبات قوة AlphaGo هو الذي يثير الأسئلة ، ولكن أيضًا بعض التحركات في الألعاب.
لا يوجد جهاز كمبيوتر قادر على التغلب على لاعب محترف في لعبة الطاولة الآسيوية. الشيء هو عن ميزات اللعبة: هناك العديد من المواقف ، ومن الصعب وصف الحدس البشري خوارزمية. كان لدى العالم وجهات نظر مماثلة حتى 27 يناير. قبل بضعة أيام ، نشرت Google بيانات بحثية من قسم DeepMind . يتحدث عن نظام AlphaGo ، الذي تمكن في أكتوبر من العام الماضي من التغلب على اللاعب الثاني المحترف Dan Fan في 5 من أصل خمس مباريات.ومع ذلك ، كان لدى اللاعبين المحترفين والمعارف من go أسئلة حول جودة اللعبة. هوى بطل ثلاث مرات ، ولكنه بطل أوروبي ، حيث مستوى اللعبة ليس مرتفعا للغاية. ليس فقط خيار اللاعب لإثبات قوة AlphaGo هو الذي يثير الأسئلة ، ولكن أيضًا بعض التحركات في الألعاب.خوارزمية
لطالما اعتبرت Guo لعبة تدريب يصعب فيها الذكاء الاصطناعي بسبب مساحة البحث الضخمة وتعقيد اختيار التحركات. ينتمي Go إلى فئة الألعاب بمعلومات مثالية ، أي أن اللاعبين على دراية بجميع التحركات التي قام بها اللاعبون الآخرون سابقًا. يتضمن اللعبة نتيجة حل مشكلة البحث حساب القيمة المثلى من وظيفة في شجرة البحث التي تحتوي على حوالي ب د من التحركات المحتملة. هنا b هو عدد الحركات الصحيحة في كل مركز ، و d هو طول اللعبة. بالنسبة للشطرنج ، هذه القيم هي b ≈ 35 و d ≈ 80 ، ولا يمكن البحث الكامل. لذلك ، يتم تقييم مواقف الأرقام ، ثم يؤخذ التقييم في الاعتبار في البحث. في عام 1996 ، ولأول مرة ، فاز جهاز كمبيوتر بالشطرنج ضد بطل ، ومنذ عام 2005 ، لم يتمكن أي بطل من التغلب على جهاز كمبيوتر.بالنسبة لـ go b ≈ 250 ، d ≈ 150. المواضع المحتملة للحجارة على لوحة قياسية أكثر من googol (10 100 ) مرات أكثر من الشطرنج. عدد المواضع الممكنة أكبر من الذرات في الكون. ومما يعقد الموقف أنه من الصعب التنبؤ بقيمة الدول بسبب تعقيد اللعبة. لاعبان يضعان الحجارة بلونين على لوح بحجم معين ، المجال القياسي 19 × 19 خط. تختلف القواعد في التفاصيل ، لكن الهدف الرئيسي للعبة بسيط: أنت بحاجة إلى تحجيم مساحة أكبر على اللوح بأحجار من لونك من خصمك.يمكن للبرامج الحالية أن تلعب على مستوى الهواة. يستخدمون البحث في شجرة مونت كارلو لتقييم قيمة كل حالة في شجرة البحث. تتضمن البرامج أيضًا سياسات تتنبأ بتحركات اللاعبين الأقوياء.في الآونة الأخيرة ، تمكنت الشبكات العصبية التلافيفية العميقة من تحقيق نتائج جيدة في التعرف على الوجوه وتصنيف الصور. في Google ، تعلمت منظمة العفو الدولية لعب 49 لعبة Atari قديمة بمفردها . في AlphaGo ، تفسر الشبكات العصبية المماثلة موضع الأحجار على اللوحة ، مما يساعد على تقييم واختيار الحركات. في Google ، اتبع الباحثون النهج التالي: استخدموا شبكات القيمة وشبكات السياسة. ثم يتم تدريب هذه الشبكات العصبية العميقة على مجموعة من الأطراف ، وعلى لعبة ضد نسخهم. البحث جديد أيضًا ، ويجمع بين طريقة مونت كارلو وشبكات السياسة والقيمة. مخطط وهيكلة تدريب الشبكات العصبية.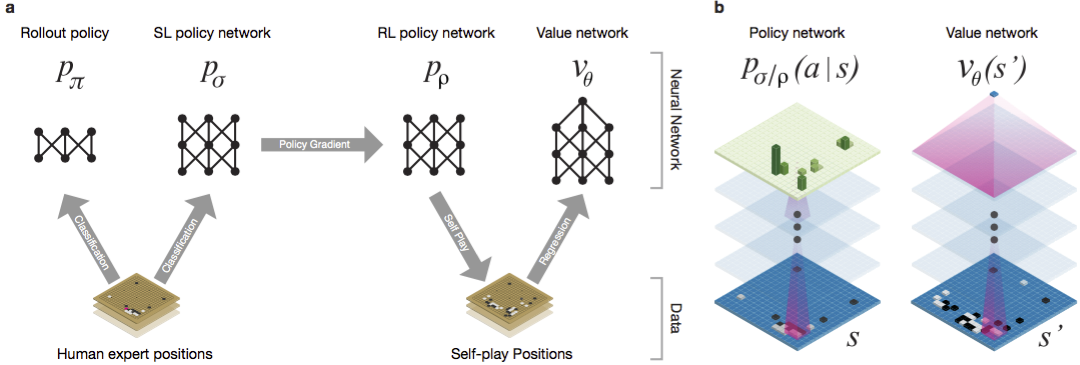 تم تدريب الشبكات العصبية في عدة مراحل من التعلم الآلي. في البداية ، تم تنفيذ التدريب المسيطر عليه لشبكة السياسة بشكل مباشر باستخدام تحركات اللاعبين البشريين. شبكة سياسة أخرى تم تعزيز التعلم. الثاني لعب مع الأول وحسنه بحيث تحولت السياسة إلى فوز ، وليس فقط توقعات التحركات. وأخيرًا ، تم إجراء التدريب ، مدعومًا بشبكة قيمة تتنبأ بالفائز في الألعاب التي تلعبها شبكات السياسات. والنتيجة النهائية هي AlphaGo ، وهي مزيج من طريقة مونت كارلو وشبكات السياسة والقيمة. تم تحقيق نتيجة التنبؤ الصحيح للخطوة التالية في 57 ٪ من الحالات. قبل AlphaGo ، كانت أفضل نتيجة 44٪ .تم استخدام 160 ألف لعبة مع 29.4 مليون موقع من خادم KGS كمدخل للتدريب. تم أخذ حفلات اللاعبين من السادس إلى التاسع. تم تخصيص مليون وظيفة للاختبارات ، وتم إجراء التدريب نفسه لـ 28.4 مليون وظيفة. قوة ودقة سياسات وقيم الشبكات.
لكي تعمل الخوارزميات ، فإنها تتطلب العديد من الطلبات من حيث حجم الحوسبة أكبر من البحث التقليدي. AlphaGo هو برنامج غير متزامن متعدد الخيوط يقوم بالمحاكاة على نوى المعالج المركزي ويقوم بتشغيل شبكات السياسات والقيم على شرائح الفيديو. تبدو النسخة النهائية مثل تطبيق 40 خيطًا يعمل على 48 معالجًا (ربما يعني نواة منفصلة أو حتى خيوط) و 8 مسرعات رسومات. تم أيضًا إنشاء نسخة موزعة من AlphaGo ، والتي تستخدم العديد من الأجهزة و 40 تيارات بحث و 1202 نوى و 176 مسرعات فيديو.
تم تدريب الشبكات العصبية في عدة مراحل من التعلم الآلي. في البداية ، تم تنفيذ التدريب المسيطر عليه لشبكة السياسة بشكل مباشر باستخدام تحركات اللاعبين البشريين. شبكة سياسة أخرى تم تعزيز التعلم. الثاني لعب مع الأول وحسنه بحيث تحولت السياسة إلى فوز ، وليس فقط توقعات التحركات. وأخيرًا ، تم إجراء التدريب ، مدعومًا بشبكة قيمة تتنبأ بالفائز في الألعاب التي تلعبها شبكات السياسات. والنتيجة النهائية هي AlphaGo ، وهي مزيج من طريقة مونت كارلو وشبكات السياسة والقيمة. تم تحقيق نتيجة التنبؤ الصحيح للخطوة التالية في 57 ٪ من الحالات. قبل AlphaGo ، كانت أفضل نتيجة 44٪ .تم استخدام 160 ألف لعبة مع 29.4 مليون موقع من خادم KGS كمدخل للتدريب. تم أخذ حفلات اللاعبين من السادس إلى التاسع. تم تخصيص مليون وظيفة للاختبارات ، وتم إجراء التدريب نفسه لـ 28.4 مليون وظيفة. قوة ودقة سياسات وقيم الشبكات.
لكي تعمل الخوارزميات ، فإنها تتطلب العديد من الطلبات من حيث حجم الحوسبة أكبر من البحث التقليدي. AlphaGo هو برنامج غير متزامن متعدد الخيوط يقوم بالمحاكاة على نوى المعالج المركزي ويقوم بتشغيل شبكات السياسات والقيم على شرائح الفيديو. تبدو النسخة النهائية مثل تطبيق 40 خيطًا يعمل على 48 معالجًا (ربما يعني نواة منفصلة أو حتى خيوط) و 8 مسرعات رسومات. تم أيضًا إنشاء نسخة موزعة من AlphaGo ، والتي تستخدم العديد من الأجهزة و 40 تيارات بحث و 1202 نوى و 176 مسرعات فيديو.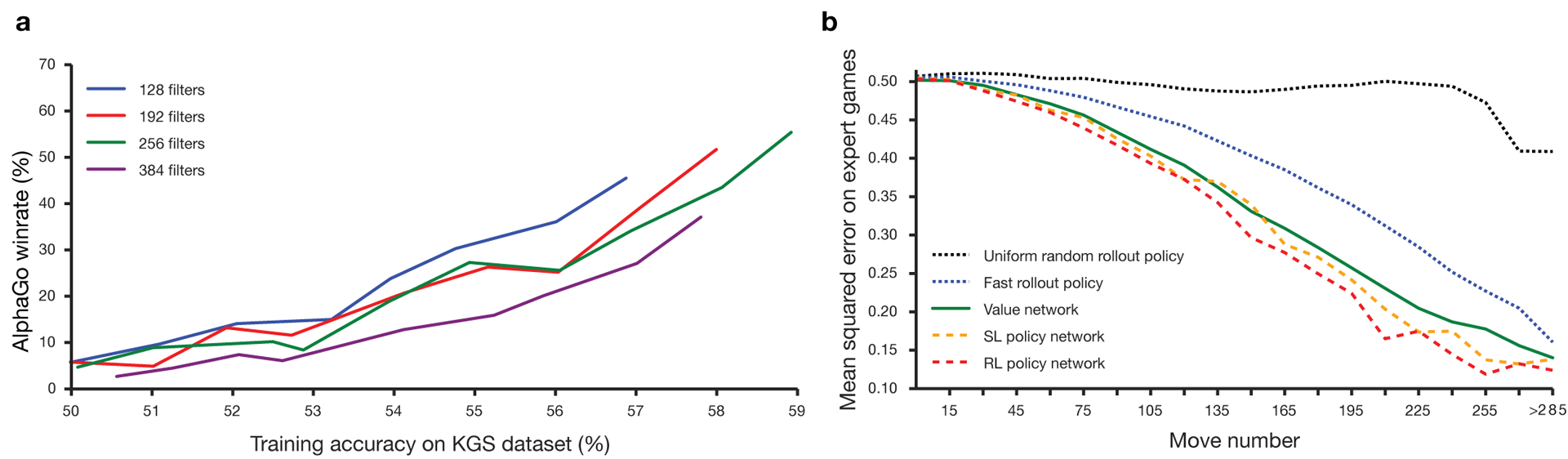 يمكن العثور على
تقرير DeepMind الكامل في المستند . ابحث عن مونت كارلو في AlphaGo.
لتقييم قدرات AlphaGo ، تم إجراء المطابقات الداخلية مقابل إصدارات أخرى من البرنامج ، بالإضافة إلى منتجات أخرى مماثلة. بما في ذلك المقارنة التي أجريت مع برامج تجارية شعبية مثل Crazy Stone و Zen ، وأقوى المشاريع مفتوحة المصدر Pachi و Fuego. تعتمد جميعها على خوارزميات مونت كارلو عالية الأداء. ولكن أيضا مقارنة AlphaGo مع غير كارلو GnuGo. أعطيت البرامج 5 ثوان لكل خطوة. تم إجراء مقارنة لكل من AlphaGo يعمل على جهاز واحد والنسخة الموزعة من الخوارزمية.
يمكن العثور على
تقرير DeepMind الكامل في المستند . ابحث عن مونت كارلو في AlphaGo.
لتقييم قدرات AlphaGo ، تم إجراء المطابقات الداخلية مقابل إصدارات أخرى من البرنامج ، بالإضافة إلى منتجات أخرى مماثلة. بما في ذلك المقارنة التي أجريت مع برامج تجارية شعبية مثل Crazy Stone و Zen ، وأقوى المشاريع مفتوحة المصدر Pachi و Fuego. تعتمد جميعها على خوارزميات مونت كارلو عالية الأداء. ولكن أيضا مقارنة AlphaGo مع غير كارلو GnuGo. أعطيت البرامج 5 ثوان لكل خطوة. تم إجراء مقارنة لكل من AlphaGo يعمل على جهاز واحد والنسخة الموزعة من الخوارزمية.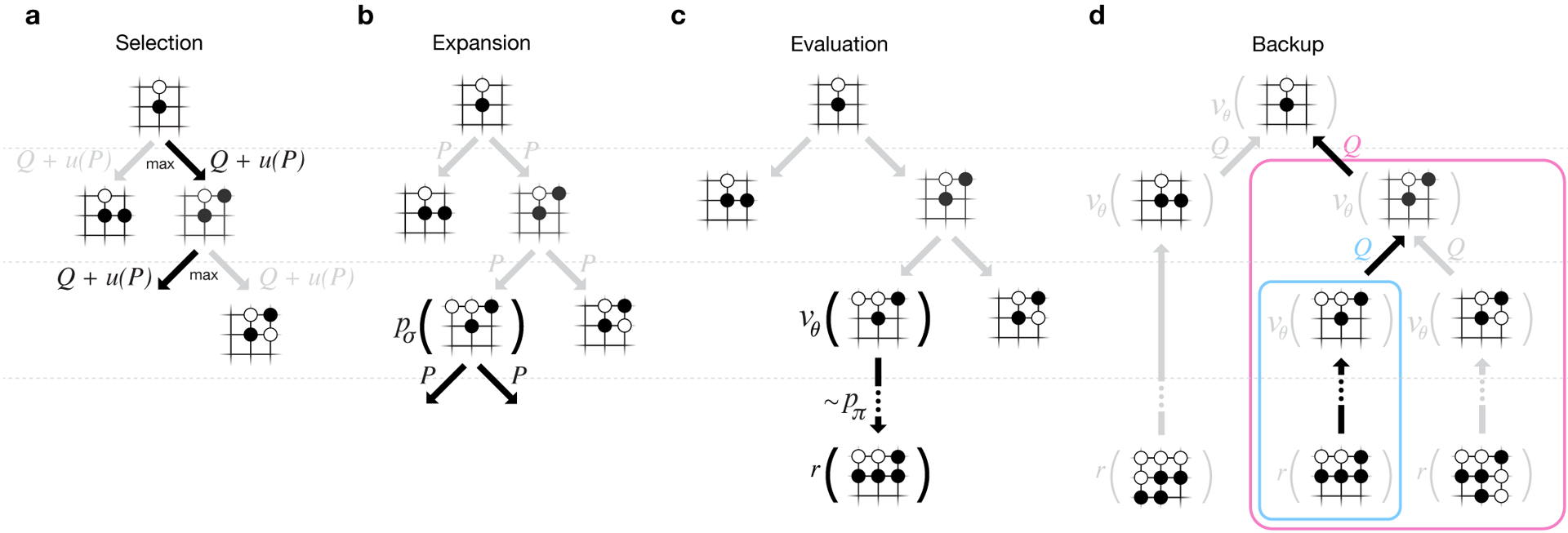 وفقا للمطورين ، أظهرت النتائج أن AlphaGo أقوى بكثير من أي برامج سابقة. فاز AlphaGo بـ 494 من 495 مباراة ، وهو 99.8٪ من المباريات ضد منتجات أخرى مماثلة. تسمح قواعد Go بإعاقة ، إعاقة: يمكن وضع ما يصل إلى 9 أحجار سوداء في الميدان قبل تحركات اللون الأبيض. ولكن حتى مع 4 أحجار للمعوقات ، فازت آلة AlphaGo المفردة بنسبة 77٪ و 86٪ و 99٪ من الوقت ضد Crazy Stone و Zen و Pachi على التوالي. كانت النسخة الموزعة من AlphaGo أقوى بشكل ملحوظ: في 77 ٪ من الألعاب ، هزمت نسخة الجهاز الواحد وفي 100 ٪ من الألعاب - جميع البرامج الأخرى. AlphaGo مقابل البرامج الأخرى.
وفقا للمطورين ، أظهرت النتائج أن AlphaGo أقوى بكثير من أي برامج سابقة. فاز AlphaGo بـ 494 من 495 مباراة ، وهو 99.8٪ من المباريات ضد منتجات أخرى مماثلة. تسمح قواعد Go بإعاقة ، إعاقة: يمكن وضع ما يصل إلى 9 أحجار سوداء في الميدان قبل تحركات اللون الأبيض. ولكن حتى مع 4 أحجار للمعوقات ، فازت آلة AlphaGo المفردة بنسبة 77٪ و 86٪ و 99٪ من الوقت ضد Crazy Stone و Zen و Pachi على التوالي. كانت النسخة الموزعة من AlphaGo أقوى بشكل ملحوظ: في 77 ٪ من الألعاب ، هزمت نسخة الجهاز الواحد وفي 100 ٪ من الألعاب - جميع البرامج الأخرى. AlphaGo مقابل البرامج الأخرى.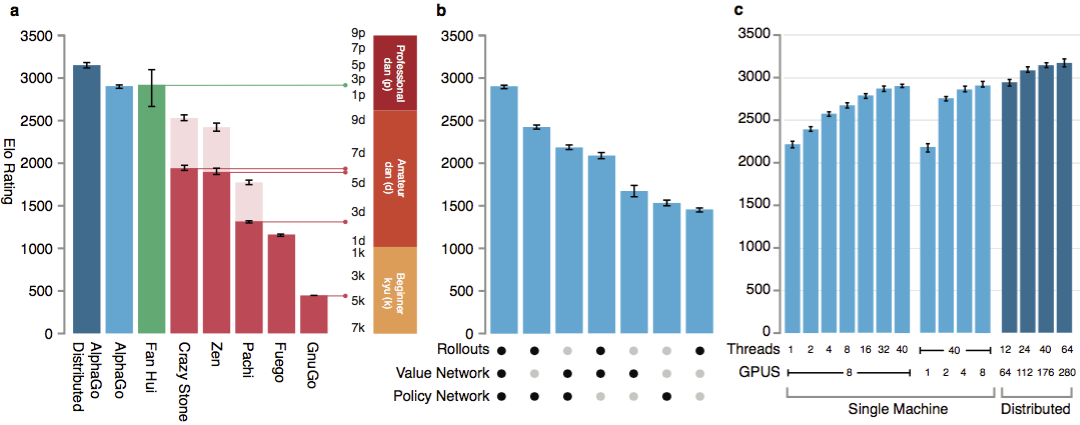 أخيرًا ، تمت مقارنة المنتج الذي تم إنشاؤه مع شخص. حارب اللاعب المحترف 2 dan ضد النسخة الموزعة من AlphaGo ، Fan Hui ، الفائز ببطولة Go الأوروبية في 2013 و 2014 و 2015. أقيمت الألعاب بمشاركة قاض من الاتحاد البريطاني ومحرر مجلة Nature. عقدت 5 مباريات في الفترة من 5 إلى 9 أكتوبر 2015. جميعهم فازوا بخوارزمية تطوير Google DeepMind. كانت هذه الألعاب هي التي أدت إلى التصريح بأن الكمبيوتر كان أول من تمكن من التغلب على لاعب محترف. بالإضافة إلى 5 أحزاب رسمية ، عقدت 5 أحزاب غير رسمية لم تحتسب. فاز فان اثنان منهم.متاح تسجيل يتحرك خمس مباريات ، عرض في القطعة على شبكة الإنترنت ، و أشرطة الفيديو على يوتيوب .
أخيرًا ، تمت مقارنة المنتج الذي تم إنشاؤه مع شخص. حارب اللاعب المحترف 2 dan ضد النسخة الموزعة من AlphaGo ، Fan Hui ، الفائز ببطولة Go الأوروبية في 2013 و 2014 و 2015. أقيمت الألعاب بمشاركة قاض من الاتحاد البريطاني ومحرر مجلة Nature. عقدت 5 مباريات في الفترة من 5 إلى 9 أكتوبر 2015. جميعهم فازوا بخوارزمية تطوير Google DeepMind. كانت هذه الألعاب هي التي أدت إلى التصريح بأن الكمبيوتر كان أول من تمكن من التغلب على لاعب محترف. بالإضافة إلى 5 أحزاب رسمية ، عقدت 5 أحزاب غير رسمية لم تحتسب. فاز فان اثنان منهم.متاح تسجيل يتحرك خمس مباريات ، عرض في القطعة على شبكة الإنترنت ، و أشرطة الفيديو على يوتيوب .نقد من لاعبين محترفين
يتم التشكيك في اختيار لاعب محترف ولعبة البطل الضعيفة. القواعد المختارة غير واضحة أيضًا: ساعة لكل لعبة بدلاً من عدة ساعات من الألعاب الجادة. ومع ذلك ، تم اختيار التنسيق من قبل هوي نفسه. في مارس ، سيلعب AlphaGo ضد Lee Sedola. هل تستطيع الخوارزمية التغلب على المحترف الكوري للدان التاسع ، الذي يعتبر أحد أفضل اللاعبين في العالم؟ على المحك مليون دولار. إذا فاز شخص ما ، سيتلقى لي سيدول ذلك ؛ إذا فازت الخوارزمية ، فسيذهب إلى مؤسسة خيرية.يقول الباحثون أنه خلال معركة أكتوبر مع البشر ، اعتبر نظام AlphaGo مواقع أقل بآلاف المرات من Deep Blue خلال مباراة تاريخية مع Kasparov. بدلاً من ذلك ، استخدم البرنامج شبكة من السياسات لخيارات أكثر ذكاءً وشبكة من القيم لقياس المواقف بدقة أكبر. ويقول الباحثون إن هذا النهج ربما يكون أقرب إلى طريقة لعب الناس. بالإضافة إلى ذلك ، تمت برمجة نظام الدرجات Deep Blue يدويًا ، بينما تم تدريب شبكات AlphaGo العصبية مباشرة من الألعاب باستخدام خوارزميات عالمية للتعلم تحت الإشراف والتعلم المعزز. سيحاول Lee Sedoll يده ضد AlphaGo في مارس. لدى اللاعبين المحترفين وجهات نظر مختلفة. يبدو للبعض أن Google اختارت على وجه التحديد عدم وجود لاعب قوي للغاية ، فمن المؤكد أن سيدول سيخسر في مارس المقبل.يعتقد كيم مينجوانج (دان التاسع) أحد أقوى اللاعبين المحترفين الناطقين بالإنجليزية أن Fan Hui لم يلعب بكامل قوته. في الدقيقة 51 من الفيديو ، أعطى مثالًا ملموسًا من الدفعة الثانية. يقول كيم إن المروحة ربما لعبت على حد سواء مع واحدة أضعف لاختبار قوة الكمبيوتر. اعترف Mengwan أن AlphaGo برنامج قوي بشكل مثير للصدمة ، ولكن من غير المحتمل أن يهزم Lee Sedol.وقال حكم المباراة توبي مانينغ لصحيفة Go Journal البريطانية عن المباراة. حلل جميع المباريات الخمس وسلط الضوء على بعض النقاط. ارتكب AlphaGo أخطاء في المباريات الثانية والثالثة والرابعة ، لكن Fan لم يستخدمها. أجاب بطل أوروبا ثلاث مرات مع نفسه. تنتهي المقالة في المجلة بتقييم إيجابي عام من قبل AlphaGo: البرنامج قوي ، ولكن ليس من الواضح كم.أيضا ، عند إعداد المواد ، تلقيت تعليقات من المهنيين الروس وأذهب إلى العشاق. ألكسندر داينرشتاين (قازان) ، ثالث دان (محترف) ، بطل أوروبا سبع مرات:
لدى اللاعبين المحترفين وجهات نظر مختلفة. يبدو للبعض أن Google اختارت على وجه التحديد عدم وجود لاعب قوي للغاية ، فمن المؤكد أن سيدول سيخسر في مارس المقبل.يعتقد كيم مينجوانج (دان التاسع) أحد أقوى اللاعبين المحترفين الناطقين بالإنجليزية أن Fan Hui لم يلعب بكامل قوته. في الدقيقة 51 من الفيديو ، أعطى مثالًا ملموسًا من الدفعة الثانية. يقول كيم إن المروحة ربما لعبت على حد سواء مع واحدة أضعف لاختبار قوة الكمبيوتر. اعترف Mengwan أن AlphaGo برنامج قوي بشكل مثير للصدمة ، ولكن من غير المحتمل أن يهزم Lee Sedol.وقال حكم المباراة توبي مانينغ لصحيفة Go Journal البريطانية عن المباراة. حلل جميع المباريات الخمس وسلط الضوء على بعض النقاط. ارتكب AlphaGo أخطاء في المباريات الثانية والثالثة والرابعة ، لكن Fan لم يستخدمها. أجاب بطل أوروبا ثلاث مرات مع نفسه. تنتهي المقالة في المجلة بتقييم إيجابي عام من قبل AlphaGo: البرنامج قوي ، ولكن ليس من الواضح كم.أيضا ، عند إعداد المواد ، تلقيت تعليقات من المهنيين الروس وأذهب إلى العشاق. ألكسندر داينرشتاين (قازان) ، ثالث دان (محترف) ، بطل أوروبا سبع مرات:Deep Blue . , , , . Google . .
4-4 ( -, starpoint ). . : 3-3, 3-4, 5-3, , , , . , . .
, , . . – , . , - . . 20-30 , , , , . , . , . .
, - 2016 (EGC) ، في إطاره تقام بطولة برامج الكمبيوتر دائمًا. دعا الاتحاد الروسي لـ Go إلى جميع البرامج القوية للمشاركة في البطولة. إذا قبلوا الدعوة ، فربما يكون في هذه البطولة لأول مرة تشغيل برامج Google و Facebook فيما بينهم. هذا الأخير ، على عكس منافسه ، يسير في طريق صادق. يلعب بوت DarkForest آلاف الألعاب على خادم KGS . الإصدار الأقرب يقترب من الدان السادس على الخادم. هذا مستوى جيد جدا. Fan Hui واللاعبون من مستواه - هذا هو حوالي dan الثامن على الخادم (من أصل تسعة ممكن). الفرق هو حوالي إثنين من العوائق الحجرية. مع مثل هذا الاختلاف ، يمكن للبرنامج أحيانًا أن يهزم شخصًا ما. إذا كانت على قدم المساواة ، ثم في دفعة واحدة من عشرة.
مكسيم بودولياك (سانت بطرسبرغ) ، نائب رئيس اتحاد غو الروسي:, , , , , , , , . , Google : , . , . : , , , . , : , . Google . , . ? ?
ألكسندر كرينوف (موسكو) ، عاشق اللعبة يذهب:بسبب نشاطي المهني ، أعرف الوضع جيدًا "من الجانب الآخر".
في عام 2012 ، حدثت قفزة نوعية في التعلم الآلي بشكل عام. وصلت كمية البيانات للتدريب ومستوى الخوارزميات وقوة التدريب إلى مستوى بدأت الشبكات العصبية الاصطناعية (التي تم تطويرها كمبدأ لفترة طويلة) في إعطاء نتائج رائعة.
الفرق الأساسي بين التدريب على الشبكات العصبية هو أنها لا تحتاج إلى إدخال عوامل الإدخال (في حالة الذهاب ، اشرح ، على سبيل المثال ، الأشكال الجيدة). في الحد ، حتى القواعد لا يمكن شرحها لهم. الشيء الرئيسي هو إعطاء عدد كبير من الأمثلة الإيجابية (حركات الجانب الفائز) والسلبية (حركات الجانب الخاسر). وستتعلم الشبكة نفسها.
, , . . : , , ( ) , .
, .
, , , . . . . , , .
ما يقوله لي سيدول نفسه
يتنافس اللاعبون المحترفون ليس على لقب العالم ، ولكن على الألقاب. يتم تحديد الاعتراف ووضع الماجستير من خلال عدد الألقاب التي تمكن من الحصول عليها خلال العام. لي سيدول هو واحد من أقوى خمسة لاعبين في العالم ، وسيضطر في مارس من هذا العام إلى القتال مع نظام AlphaGo. ويتوقعالبطل الكوري نفسه أنه سيفوز بنتيجة 4-1 أو 5-0. ولكن بعد 2-3 سنوات ، ستريد Google الانتقام ، ثم ستكون اللعبة ذات الإصدار المحدث من AlphaGo أكثر إثارة للاهتمام ، كما يقول Lee.
إن مهمة إنشاء مثل هذه الخوارزمية تطرح أسئلة جديدة حول ماهية التعلم والتفكير. كما يذكر م. إيميليانوف ، المستوى الثالث من المهارة (دبوس) من الأعلى وفقًا للتصنيف الصيني القديم يسمى "الوضوح الكامل". يشير مثل هذا المستوى من اللعبة إلى أن القرارات يتم اتخاذها بشكل حدسي ، مع خيارات قليلة أو معدومة. قال أحد أقوى أساتذة القرن العشرين ، Guo Seigen ، أنه بدا له أنه كان سيفوز ضد "إله الذهاب" بأخذ اثنين أو ثلاثة أحجار إعاقة. يعتقد Seigan أنه قد وصل إلى حد فهم اللعبة تقريبًا. هل يمكن للشبكة العصبية تحقيق ذلك؟ ربما الحدس البشري هو خوارزمية وضعتها الطبيعة؟يشكر المؤلف ألكسندر داينرشتاين وعامة الجمهور على التعليقات والمساعدة في المنشور.Source: https://habr.com/ru/post/ar389825/
All Articles