 حدث ذلك أن اللغة الرئيسية للعمل مع وحدات التحكم الدقيقة هي C. يتم كتابة العديد من المشاريع الكبيرة عليها. لكن الحياة لا تقف ساكنة. لطالما كانت أدوات التطوير الحديثة قادرة على استخدام C ++ عند تطوير البرمجيات للأنظمة المدمجة. ومع ذلك ، لا يزال هذا النهج نادرًا. منذ وقت ليس ببعيد ، حاولت استخدام C ++ عند العمل على مشروع آخر. سأتحدث عن هذه التجربة في هذه المقالة.
حدث ذلك أن اللغة الرئيسية للعمل مع وحدات التحكم الدقيقة هي C. يتم كتابة العديد من المشاريع الكبيرة عليها. لكن الحياة لا تقف ساكنة. لطالما كانت أدوات التطوير الحديثة قادرة على استخدام C ++ عند تطوير البرمجيات للأنظمة المدمجة. ومع ذلك ، لا يزال هذا النهج نادرًا. منذ وقت ليس ببعيد ، حاولت استخدام C ++ عند العمل على مشروع آخر. سأتحدث عن هذه التجربة في هذه المقالة.الدخول
معظم عملي مع وحدات التحكم الدقيقة مرتبط بـ C. أولاً ، كانت متطلبات العملاء ، ثم أصبحت مجرد عادة. في الوقت نفسه ، عندما يتعلق الأمر بتطبيقات Windows ، تم استخدام C ++ هناك أولاً ، ثم C # بشكل عام.لم تكن هناك أسئلة حول C أو C ++ لفترة طويلة. حتى إصدار النسخة التالية من Keil's MDK مع دعم C ++ لـ ARM لم يزعجني كثيرًا. إذا نظرت إلى مشاريع Keil التجريبية ، فكل شيء مكتوب هناك في C. في نفس الوقت ، يتم نقل C ++ إلى مجلد منفصل مع مشروع Blinky. CMSIS و LPCOpen مكتوبة أيضًا في C. وإذا كان "الجميع" يستخدم لغة C ، فهناك بعض الأسباب.لكن الكثير قد تغير. NET Micro Framework. إذا كان أي شخص لا يعرف ، فهذا تطبيق صافي يسمح لك بكتابة تطبيقات للمتحكم الدقيق في C # في Visual Studio. يمكنك معرفة المزيد عنه فيهذه المقالات.لذلك ، تمت كتابة .Net Micro Framework باستخدام C ++. تأثرت بذلك ، قررت أن أحاول كتابة مشروع آخر في C ++. يجب أن أقول على الفور أنني لم أجد في النهاية أي حجج محددة لصالح C ++ ، ولكن هناك بعض النقاط المثيرة للاهتمام والمفيدة في هذا النهج.ما الفرق بين مشاريع C و C ++؟
أحد الاختلافات الرئيسية بين C و C ++ هو أن الثانية هي لغة موجهة للكائنات. إن التضمين المعروف والتعدد في الأشكال والميراث شائع هنا. C هي لغة إجرائية. هناك وظائف وإجراءات فقط ، وللتجميع المنطقي للكود ، يتم استخدام الوحدات (زوج من .h + .c). ولكن إذا نظرت عن كثب في كيفية استخدام C في وحدات التحكم الدقيقة ، يمكنك رؤية النهج المعتاد الموجه للكائنات.دعونا نلقي نظرة على الكود للعمل مع LEDs من مثال Keil لـ MCB1000 ( Keil_v5 \ ARM \ Boards \ Keil \ MCB1000 \ MCB11C14 \ CAN_Demo ):LED.h:#ifndef __LED_H
#define __LED_H
#define LED_NUM 8
extern void LED_init(void);
extern void LED_on (uint8_t led);
extern void LED_off (uint8_t led);
extern void LED_out (uint8_t led);
#endif
LED.c:#include "LPC11xx.h"
#include "LED.h"
const unsigned long led_mask[] = {1UL << 0, 1UL << 1, 1UL << 2, 1UL << 3,
1UL << 4, 1UL << 5, 1UL << 6, 1UL << 7 };
void LED_init (void) {
LPC_SYSCON->SYSAHBCLKCTRL |= (1UL << 6);
LPC_GPIO2->DIR |= (led_mask[0] | led_mask[1] | led_mask[2] | led_mask[3] |
led_mask[4] | led_mask[5] | led_mask[6] | led_mask[7] );
LPC_GPIO2->DATA &= ~(led_mask[0] | led_mask[1] | led_mask[2] | led_mask[3] |
led_mask[4] | led_mask[5] | led_mask[6] | led_mask[7] );
}
void LED_on (uint8_t num) {
LPC_GPIO2->DATA |= led_mask[num];
}
void LED_off (uint8_t num) {
LPC_GPIO2->DATA &= ~led_mask[num];
}
void LED_out(uint8_t value) {
int i;
for (i = 0; i < LED_NUM; i++) {
if (value & (1<<i)) {
LED_on (i);
} else {
LED_off(i);
}
}
}
إذا نظرت عن كثب ، يمكنك إعطاء قياس مع OOP. LED هو كائن يحتوي على ثابت عام واحد ومنشئ و 3 طرق عامة ومجال خاص واحد:class LED
{
private:
const unsigned long led_mask[] = {1UL << 0, 1UL << 1, 1UL << 2, 1UL << 3,
1UL << 4, 1UL << 5, 1UL << 6, 1UL << 7 };
public:
unsigned char LED_NUM=8;
public:
LED();
void on (uint8_t led);
void off (uint8_t led);
void out (uint8_t led);
}
على الرغم من حقيقة أن الرمز مكتوب بلغة C ، فإنه يستخدم نموذج برمجة الكائن. ملف .C عبارة عن كائن يسمح لك بالتغليف داخل آليات تنفيذ الطرق العامة الموضحة في ملف .h. هذا مجرد وراثة ليست هنا ، وبالتالي تعدد الأشكال أيضا.معظم التعليمات البرمجية في المشاريع التي التقيت بها مكتوبة بنفس النمط. وإذا تم استخدام نهج OOP ، فلماذا لا تستخدم لغة تدعمها بالكامل؟ في الوقت نفسه ، عند التبديل إلى C ++ ، بشكل عام ، سيتغير بناء الجملة فقط ، ولكن ليس مبادئ التطوير.تأمل في مثال آخر. لنفترض أن لدينا جهازًا يستخدم مستشعر درجة حرارة متصل عبر I2C. ولكن ظهرت مراجعة جديدة للجهاز وتم توصيل نفس المستشعر الآن بـ SPI. ماذا تفعل من الضروري دعم التنقيحات الأولى والثانية للجهاز ، مما يعني أن الرمز يجب أن يأخذ هذه التغييرات بمرونة في الاعتبار. في C ، يمكنك استخدام # تعريف مسبق لتجنب كتابة ملفين متطابقين تقريبًا. على سبيل المثال#ifdef REV1
#include “i2c.h”
#endif
#ifdef REV2
#include “spi.h”
#endif
void TEMPERATURE_init()
{
#ifdef REV1
I2C_int()
#endif
#ifdef REV2
SPI_int()
#endif
}
وهكذا دواليك.في C ++ ، يمكنك حل هذه المشكلة بشكل أكثر أناقة. إنشاء واجهةclass ITemperature
{
public:
virtual unsigned char GetValue() = 0;
}
وإجراء تنفيذينclass Temperature_I2C: public ITemperature
{
public:
virtual unsigned char GetValue();
}
class Temperature_SPI: public ITemperature
{
public:
virtual unsigned char GetValue();
}
ثم استخدم هذا أو ذاك التطبيق بناءً على المراجعة:class TemperatureGetter
{
private:
ITemperature* _temperature;
pubic:
Init(ITemperature* temperature)
{
_temperature = temperature;
}
private:
void GetTemperature()
{
_temperature->GetValue();
}
#ifdef REV1
Temperature_I2C temperature;
#endif
#ifdef REV2
Temperature_SPI temperature;
#endif
TemperatureGetter tGetter;
void main()
{
tGetter.Init(&temperature);
}
يبدو أن الاختلاف ليس كبيرًا بين كود C و C ++. يبدو الخيار الموجه للكائنات أكثر تعقيدًا. لكنه يسمح لك باتخاذ قرار أكثر مرونة.عند استخدام C ، يمكن تمييز حلين رئيسيين:- استخدم #define كما هو موضح أعلاه. هذا الخيار ليس جيدًا جدًا لأنه "يقوض" مسؤولية الوحدة. اتضح أنه مسؤول عن عدة مراجعات للمشروع. عندما يكون هناك العديد من هذه الملفات ، يصبح من الصعب جدًا الاحتفاظ بها.
- 2 , C++. “” , . , #ifdef. , , . , . , , .
استخدام تعدد الأشكال يعطي نتيجة أكثر جمالا. من ناحية ، تحل كل فئة مشكلة ذرية واضحة ، من ناحية أخرى ، فإن الشفرة ليست متناثرة وسهلة القراءة.لا يزال يتعين إجراء "التفرع" للكود في المراجعة في الحالتين الأولى والثانية ، ولكن استخدام تعدد الأشكال يجعل من السهل نقل مكان التفرع بين طبقات البرنامج ، مع عدم ازدحام الكود مع #ifdef غير ضروري.استخدام تعدد الأشكال يجعل من السهل اتخاذ قرار أكثر إثارة للاهتمام.لنفترض إصدار مراجعة جديدة ، يتم فيها تثبيت مستشعرات درجة الحرارة.يسمح لك نفس الرمز مع الحد الأدنى من التغييرات باختيار تنفيذ SPI و I2C في الوقت الفعلي ، ببساطة باستخدام طريقة Init (& temperature).المثال مبسط للغاية ، ولكن في مشروع حقيقي استخدمت نفس الأسلوب لتنفيذ نفس البروتوكول على رأس واجهتين مختلفتين لنقل البيانات المادية. هذا جعل من السهل اختيار الواجهة في إعدادات الجهاز.ومع ذلك ، مع كل ما سبق ، لا يزال الفرق بين استخدام C و C ++ كبيرًا جدًا. مزايا C ++ المتعلقة OOP ليست واضحة للغاية وهي من فئة "الهواة". لكن استخدام C ++ في الميكروكونترولر لديه مشاكل خطيرة للغاية.ما هو خطر استخدام C ++؟
الاختلاف الثاني المهم بين C و C ++ هو استخدام الذاكرة. لغة C هي في الغالب ساكنة. جميع الوظائف والإجراءات لها عناوين ثابتة ، ويتم العمل مع مجموعة فقط عند الضرورة. لغة C ++ هي لغة أكثر ديناميكية. عادة ما ينطوي استخدامه على عمل نشط مع تخصيص وتحرير الذاكرة. هذا ما هو خطير في C ++. تحتوي وحدات التحكم الدقيقة على موارد قليلة جدًا ، لذا فإن التحكم فيها أمر مهم. الاستخدام غير المنضبط لذاكرة الوصول العشوائي محفوف بالضرر الذي يلحق بالبيانات المخزنة هناك ومثل هذه "المعجزات" في عمل البرنامج ، والتي لن تبدو لأي شخص. واجه العديد من المطورين مثل هذه المشاكل.إذا نظرت عن كثب إلى الأمثلة أعلاه ، يمكن ملاحظة أن الفئات لا تحتوي على مُنشئين ومدمرين. هذا لأنه لم يتم إنشاؤها ديناميكيًا أبدًا.عند استخدام الذاكرة الديناميكية (وعند استخدام ذاكرة جديدة) ، يتم استدعاء وظيفة malloc دائمًا ، والتي تخصص العدد المطلوب من وحدات البايت من كومة الذاكرة المؤقتة. حتى إذا كنت تفكر في الأمر (على الرغم من أنه صعب للغاية) وتتحكم في استخدام الذاكرة ، فقد تواجه مشكلة التجزئة.يمكن تمثيل مجموعة كمصفوفة. على سبيل المثال ، نختار 20 بايت لها: في كل مرة يتم تخصيص الذاكرة ، يتم مسح الذاكرة بالكامل (من اليسار إلى اليمين أو من اليمين إلى اليسار - وهذا ليس مهمًا جدًا) لوجود عدد معين من وحدات البايت غير المشغولة. علاوة على ذلك ، يجب أن تقع جميع هذه البايتات في مكان قريب:
كل مرة يتم تخصيص الذاكرة ، يتم مسح الذاكرة بالكامل (من اليسار إلى اليمين أو من اليمين إلى اليسار - وهذا ليس مهمًا جدًا) لوجود عدد معين من وحدات البايت غير المشغولة. علاوة على ذلك ، يجب أن تقع جميع هذه البايتات في مكان قريب: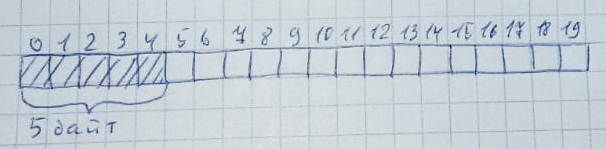 عندما لا تكون هناك حاجة للذاكرة ، تعود إلى حالتها الأصلية:يمكن أن يحدث هذا بسهولة كبيرة عند وجود وحدات بايت حرة كافية ، ولكن لا يتم ترتيبها على التوالي. اسمح بتخصيص 10 مناطق لكل منها 2 بايت:
عندما لا تكون هناك حاجة للذاكرة ، تعود إلى حالتها الأصلية:يمكن أن يحدث هذا بسهولة كبيرة عند وجود وحدات بايت حرة كافية ، ولكن لا يتم ترتيبها على التوالي. اسمح بتخصيص 10 مناطق لكل منها 2 بايت: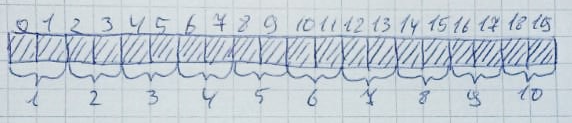 ثم سيتم تحرير مناطق 2،4،6،8،10:
ثم سيتم تحرير مناطق 2،4،6،8،10: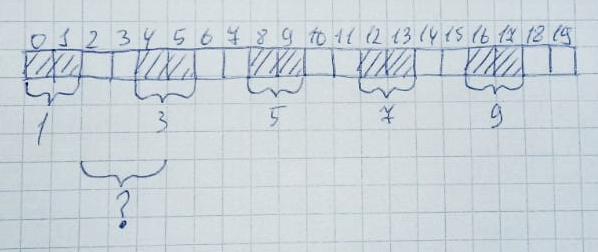 رسميًا ، يبقى نصف الكومة الكاملة (10 بايت) مجانية. ومع ذلك ، لتخصيص مساحة ذاكرة بحجم 3 بايت لا يزال لا يعمل ، لأن الصفيف لا يحتوي على 3 خلايا مجانية على التوالي. وهذا ما يسمى بتجزئة الذاكرة.والتعامل مع هذا على الأنظمة التي لا تحتوي على ذاكرة افتراضية أمر صعب للغاية. خاصة في المشاريع الكبيرة.يمكن محاكاة هذا الموقف بسهولة. فعلت هذا في Keil mVision على متحكم LPC11C24.قم بتعيين حجم كومة الذاكرة المؤقتة على 256 بايت:
رسميًا ، يبقى نصف الكومة الكاملة (10 بايت) مجانية. ومع ذلك ، لتخصيص مساحة ذاكرة بحجم 3 بايت لا يزال لا يعمل ، لأن الصفيف لا يحتوي على 3 خلايا مجانية على التوالي. وهذا ما يسمى بتجزئة الذاكرة.والتعامل مع هذا على الأنظمة التي لا تحتوي على ذاكرة افتراضية أمر صعب للغاية. خاصة في المشاريع الكبيرة.يمكن محاكاة هذا الموقف بسهولة. فعلت هذا في Keil mVision على متحكم LPC11C24.قم بتعيين حجم كومة الذاكرة المؤقتة على 256 بايت: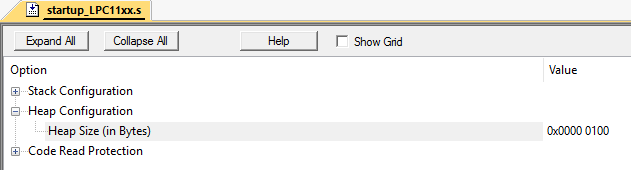 لنفترض أن لدينا فئتين:
لنفترض أن لدينا فئتين:#include <stdint.h>
class foo
{
private:
int32_t _pr1;
int32_t _pr2;
int32_t _pr3;
int32_t _pr4;
int32_t _pb1;
int32_t _pb2;
int32_t _pb3;
int32_t _pb4;
int32_t _pc1;
int32_t _pc2;
int32_t _pc3;
int32_t _pc4;
public:
foo()
{
_pr1 = 100;
_pr2 = 200;
_pr3 = 300;
_pr4 = 400;
_pb1 = 100;
_pb2 = 200;
_pb3 = 300;
_pb4 = 400;
_pc1 = 100;
_pc2 = 200;
_pc3 = 300;
_pc4 = 400;
}
~foo(){};
int32_t F1(int32_t a)
{
return _pr1*a;
};
int32_t F2(int32_t a)
{
return _pr1/a;
};
int32_t F3(int32_t a)
{
return _pr1+a;
};
int32_t F4(int32_t a)
{
return _pr1-a;
};
};
class bar
{
private:
int32_t _pr1;
int8_t _pr2;
public:
bar()
{
_pr1 = 100;
_pr2 = 10;
}
~bar() {};
int32_t F1(int32_t a)
{
return _pr2/a;
}
int16_t F2(int32_t a)
{
return _pr2*a;
}
};
كما ترى ، سوف تستهلك فئة المحامين ذاكرة أكبر من ذاكرة foo.تم وضع 14 مثيلًا لفئة الشريط في كومة الذاكرة المؤقتة ولم يعد مثيل فئة foo مناسبًا:int main(void)
{
foo *f;
bar *b[14];
b[0] = new bar();
b[1] = new bar();
b[2] = new bar();
b[3] = new bar();
b[4] = new bar();
b[5] = new bar();
b[6] = new bar();
b[7] = new bar();
b[8] = new bar();
b[9] = new bar();
b[10] = new bar();
b[11] = new bar();
b[12] = new bar();
b[13] = new bar();
f = new foo();
}
إذا قمت بإنشاء 7 مثيلات فقط من الشريط ، فسيتم إنشاء foo بشكل طبيعي:int main(void)
{
foo *f;
bar *b[14];
b[1] = new bar();
b[3] = new bar();
b[5] = new bar();
b[7] = new bar();
b[9] = new bar();
b[11] = new bar();
b[13] = new bar();
f = new foo();
}
ومع ذلك ، إذا قمت أولاً بإنشاء 14 مثيلًا للشريط ، ثم احذف 0،2،4،6،8،10 و 12 مثيلًا ، فلن تتمكن foo من تخصيص الذاكرة بسبب تجزئة الكومة:int main(void)
{
foo *f;
bar *b[14];
b[0] = new bar();
b[1] = new bar();
b[2] = new bar();
b[3] = new bar();
b[4] = new bar();
b[5] = new bar();
b[6] = new bar();
b[7] = new bar();
b[8] = new bar();
b[9] = new bar();
b[10] = new bar();
b[11] = new bar();
b[12] = new bar();
b[13] = new bar();
delete b[0];
delete b[2];
delete b[4];
delete b[6];
delete b[8];
delete b[10];
delete b[12];
f = new foo();
}
اتضح أنه لا يمكنك استخدام C ++ بالكامل ، وهذا ناقص كبير. من وجهة نظر معمارية ، فإن C ++ ، على الرغم من تفوقها على C ، غير ذات أهمية. ونتيجة لذلك ، فإن الانتقال إلى C ++ لا يحقق فوائد كبيرة (على الرغم من عدم وجود نقاط سلبية كبيرة أيضًا). وبالتالي ، نظرًا لاختلاف بسيط ، سيظل اختيار اللغة ببساطة هو التفضيل الشخصي للمطور.ولكن بالنسبة لي ، وجدت نقطة إيجابية واحدة مهمة في استخدام C ++. والحقيقة هي أنه باستخدام نهج C ++ الصحيح ، يمكن بسهولة تغطية التعليمات البرمجية لوحدات التحكم الدقيقة من خلال اختبارات الوحدة في Visual Studio.ميزة كبيرة من C ++ هي القدرة على استخدام Visual Studio.
بالنسبة لي شخصياً ، كان موضوع اختبار التعليمات البرمجية للمتحكم الدقيق دائمًا معقدًا للغاية. بطبيعة الحال ، تم التحقق من الرمز بكل طريقة ممكنة ، ولكن إنشاء نظام اختبار تلقائي كامل يتطلب دائمًا تكاليف باهظة ، حيث كان من الضروري تجميع حامل الأجهزة وكتابة برنامج ثابت خاص له. خاصة عندما يتعلق الأمر بنظام إنترنت الأشياء الموزع الذي يتكون من مئات الأجهزة.عندما بدأت كتابة مشروع في C ++ ، أردت على الفور محاولة وضع الرمز في Visual Studio واستخدام Keil mVision فقط لتصحيح الأخطاء. أولاً ، يحتوي Visual Studio على محرر تعليمات برمجية قوي ومريح للغاية ، وثانيًا ، لا يحتوي Keil mVision على تكامل ملائم مع أنظمة التحكم في الإصدار ، وفي Visual Studio يتم عمل كل ذلك تلقائيًا. ثالثًا ، كان لدي أمل في أن أتمكن من تغطية جزء على الأقل من الشفرة باختبارات الوحدة ، والتي يتم دعمها أيضًا بشكل جيد في Visual Studio. ورابعًا ، هذا ظهور Resharper C ++ - ملحق Visual Studio للعمل مع كود C ++ ، والذي بفضله يمكنك تجنب العديد من الأخطاء المحتملة مسبقًا ومراقبة نمط الشفرة.إنشاء مشروع في Visual Studio وربطه بنظام التحكم في الإصدار لم يسبب أي مشاكل. ولكن مع اختبارات الوحدة كان لا بد من العبث.كانت الفئات المستخرجة من الأجهزة (على سبيل المثال ، موزعي البروتوكول) سهلة الاختبار. لكني أردت المزيد! في مشاريعي للعمل مع الأجهزة الطرفية ، أستخدم ملفات رأس من Keil. على سبيل المثال ، بالنسبة لـ LPC11C24 يكون LPC11xx.h. تصف هذه الملفات جميع السجلات اللازمة وفقًا لمعيار CMSIS. يتم تحديد سجل معين مباشرة من خلال #define:#define LPC_I2C_BASE (LPC_APB0_BASE + 0x00000)
#define LPC_I2C ((LPC_I2C_TypeDef *) LPC_I2C_BASE )
اتضح أنه إذا تجاوزت التسجيلات بشكل صحيح وقمت بعمل جزئين ، فيمكن عندئذٍ تجميع التعليمات البرمجية التي تستخدم الأجهزة الطرفية في VisualStudio. ليس ذلك فحسب ، إذا قمت بإنشاء فئة ثابتة وتحديد حقولها كعناوين تسجيل ، فستحصل على محاكي متحكم كامل ، والذي يسمح لك باختبار العمل مع الأجهزة الطرفية بالكامل:#include <LPC11xx.h>
class LPC11C24Emulator
{
public:
static class Registers
{
public:
static LPC_ADC_TypeDef ADC;
public:
static void Init()
{
memset(&ADC, 0x00, sizeof(LPC_ADC_TypeDef));
}
};
}
#undef LPC_ADC
#define LPC_ADC ((LPC_ADC_TypeDef *) &LPC11C24Emulator::Registers::ADC)
ثم قم بذلك:#if defined ( _M_IX86 )
#include "..\Emulator\LPC11C24Emulator.h"
#else
#include <LPC11xx.h>
#endif
بهذه الطريقة ، يمكنك تجميع واختبار كل كود المشروع للمتحكم الدقيق في VisualStudio مع الحد الأدنى من التغييرات.في عملية تطوير مشروع في C ++ ، كتبت أكثر من 300 اختبار تغطي جوانب الأجهزة البحتة والرمز المستخلص من الأجهزة. علاوة على ذلك ، تم العثور على ما يقرب من 20 خطأً فادحًا إلى حد ما مقدمًا ، والتي لن يكون من السهل اكتشافها ، نظرًا لحجم المشروع بدون اختبار تلقائي.الاستنتاجات
استخدام أو عدم استخدام C ++ عند العمل مع وحدات التحكم الدقيقة هو سؤال معقد إلى حد ما. لقد أوضحت أعلاه أنه ، من ناحية ، المزايا المعمارية لـ OOP الكاملة ليست كبيرة جدًا ، وعدم القدرة على العمل بشكل كامل مع مجموعة مشكلة كبيرة إلى حد ما. بالنظر إلى هذه الجوانب ، لا يوجد فرق كبير بين C و C ++ للعمل مع وحدات التحكم الدقيقة ، وقد يكون الخيار بينهما مبررًا تمامًا من خلال التفضيلات الشخصية للمطور.ومع ذلك ، تمكنت من العثور على نقطة إيجابية كبيرة في استخدام C ++ في العمل مع Visaul Studio. هذا يسمح لك بتحسين موثوقية التطوير بشكل كبير بسبب العمل الكامل مع أنظمة التحكم في الإصدار ، واستخدام اختبارات الوحدة الكاملة (بما في ذلك اختبارات العمل مع الأجهزة الطرفية) وغيرها من مزايا Visual Studio.آمل أن تكون تجربتي مفيدة وأن تساعد شخصًا ما على زيادة فعالية عملهم.تحديث :في التعليقات على النسخة الإنجليزية من هذه المقالة أعطى روابط مفيدة حول هذا الموضوع: