AlphaGo vs Lee Sedola: نتائج وعشرات من اللاعبين المحترفين في ال
 أمس ، أقيمت المباراة الخامسة الأخيرة لمباراة الذهاب في سيول في فندق فور سيزونز. تم تغطية كل واحد منهم بكثافة على Geektimes لمدة أسبوع كامل. فاز شخص ما في السلسلة ، ولكن من غير المرجح أن يكون مثل هذا الزائر مهتمًا بموقع باللغة الروسية حول التكنولوجيا العالية والعلوم ، إن لم يكن لواحد من الحقائق.لعبت من قبل لي سيدول ، صاحب دان المهنية التاسعة ، واحدة من أفضل أساتذة الذهاب في العالم. كان خصمه هو نظام AlphaGo للكمبيوتر ، تم تطويره بواسطة Google DeepMind. قبل بداية المباراة ، كان يعتقد أنه لا يوجد منتج قادر على التغلب على سيد رفيع المستوى. لكن منظمة العفو الدولية فازت 4-1.السرعة التي يذهب بها شحذ AlphaGo مثيرة للاهتمام. حتى أكتوبر الماضي ، كان نظام مباراة التظاهر يغذي اللاعب أضعف بكثير. بعد خمسة أشهر ، تدور حول واحدة من الأفضل. يبدو أننا وصلنا إلى عام 1997 في لعبة الشطرنج ، عندما فاز الكمبيوتر لأول مرة على البطل الحاكم في المباراة. منذ تلك اللحظة ، حسنت برامج الشطرنج مهاراتهم إلى هذا المستوى بحيث لم يعد الشخص قادرًا على التغلب عليهم في الظروف العادية.هل هذا يتطلع إلى؟ هل يجب أن أخاف من قوة الذكاء الاصطناعي؟ تمكنت من الحصول على التعليقات والأجوبة التي قدمها نائب رئيس الاتحاد الروسي ورئيس الاتحاد الرياضي في سانت بطرسبرغ مكسيم بودولياك ، واللاعبين المحترفين في العمل والعديد من الأبطال الأوروبيين إيليا شيكشين (أول دان محترف) وألكسندر داينرشتاين (المحترف الثالث).
أمس ، أقيمت المباراة الخامسة الأخيرة لمباراة الذهاب في سيول في فندق فور سيزونز. تم تغطية كل واحد منهم بكثافة على Geektimes لمدة أسبوع كامل. فاز شخص ما في السلسلة ، ولكن من غير المرجح أن يكون مثل هذا الزائر مهتمًا بموقع باللغة الروسية حول التكنولوجيا العالية والعلوم ، إن لم يكن لواحد من الحقائق.لعبت من قبل لي سيدول ، صاحب دان المهنية التاسعة ، واحدة من أفضل أساتذة الذهاب في العالم. كان خصمه هو نظام AlphaGo للكمبيوتر ، تم تطويره بواسطة Google DeepMind. قبل بداية المباراة ، كان يعتقد أنه لا يوجد منتج قادر على التغلب على سيد رفيع المستوى. لكن منظمة العفو الدولية فازت 4-1.السرعة التي يذهب بها شحذ AlphaGo مثيرة للاهتمام. حتى أكتوبر الماضي ، كان نظام مباراة التظاهر يغذي اللاعب أضعف بكثير. بعد خمسة أشهر ، تدور حول واحدة من الأفضل. يبدو أننا وصلنا إلى عام 1997 في لعبة الشطرنج ، عندما فاز الكمبيوتر لأول مرة على البطل الحاكم في المباراة. منذ تلك اللحظة ، حسنت برامج الشطرنج مهاراتهم إلى هذا المستوى بحيث لم يعد الشخص قادرًا على التغلب عليهم في الظروف العادية.هل هذا يتطلع إلى؟ هل يجب أن أخاف من قوة الذكاء الاصطناعي؟ تمكنت من الحصول على التعليقات والأجوبة التي قدمها نائب رئيس الاتحاد الروسي ورئيس الاتحاد الرياضي في سانت بطرسبرغ مكسيم بودولياك ، واللاعبين المحترفين في العمل والعديد من الأبطال الأوروبيين إيليا شيكشين (أول دان محترف) وألكسندر داينرشتاين (المحترف الثالث).تذهب الصعوبات
يمكن مقارنة هذا الانتصار بمباراة تاريخية أخرى. في عام 1997 ، هزم الكمبيوتر العملاق Deep Blue لأول مرة في العالم بطل العالم في الشطرنج. خسارة كاسباروف لم تكن آخر هزيمة للناس. في السنوات اللاحقة ، وصل شطرنج الكمبيوتر إلى نقطة لا يمكن حتى لأقوى لاعبي الشطرنج التغلب عليهم في الظروف العادية.Go (baduk، weiqi) هي لعبة لوحية نشأت في الصين القديمة واكتسبت شعبية كبيرة في كوريا الجنوبية والصين واليابان. اليوم ، يذهب حوالي 60 مليون شخص للعب . يضع اللاعبون الحجارة بلونين على لوح بحجم معين. الهدف هو تحجيم منطقة أكبر من الخصم على اللوح.يقول رئيس الاتحاد الدولي للشطرنج ، ليس بدون متعة ، أن مصير الشطرنج ينتظر الآن ويذهب.من وجهة نظر إنشاء الذكاء الاصطناعي ، مع البساطة الخارجية ، يكون الأمر أكثر صعوبة من الشطرنج - googol (10 100 ) مرات ، لتكون أكثر دقة. إنها عدة مرات أكثر موضعًا ممكنًا للأحجار على لوح قياسي 19 × 19 من الشطرنج. قبل ظهور AlphaGo ، كان يعتقد أنه حتى الآن يتم تشغيل أي برامج على مستوى الهواة ، وحتى مستوى الماجستير ، فهي عقد آخر.حجم اللوح بعيد عن العقبة الوحيدة. العديد من الخوارزميات التي تم استخدامها للشطرنج لا تنطبق. عدد التحركات أكبر من الشطرنج. تبدأ اللعبة بـ 55 حركة ممكنة ، وسرعان ما تحتاج إلى النظر في جميع النقاط الـ 361 تقريبًا على اللوحة. بعض التحركات أكثر شيوعًا ، وبعضها تقريبًا لا يستخدم أبدًا. التحركات الأولية للحزب - fuseki - تبدأ بسرعة في الذهاب إلى شيء أصلي. في الشطرنج ، تتم إزالة القطع من اللوح ، فيتم إضافتها (على الرغم من إمكانية إزالتها عن طريق التقاط الأحجار). ويستثنى من ذلك إنشاء قاعدة لنهايات الحفلات. لا تتوافق الأنظمة الحالية بشكل سيء مع نهاية اللعبة ، بما في ذلك هذا بسبب القتال المشترك.أنظمة تشغيل الكمبيوتر موجودة بالفعل. في معظم الأحيان ، تقوم هذه المنتجات بتقييم التحركات باستخدام البحث الشجري أو طريقة مونت كارلو ، وتوظيف أنظمة الخبراء مع قاعدة بيانات من التحركات الجيدة ، ومطابقة الأنماط والتعلم الآلي. قد تظهر منتجات مثل Crazy Stone أو Zen أو GnuGo نتائج جيدة ، ولكنها لا تزال تخسر أمام المحترفين.في عام 1989 ، لم يكن جالوت قادرًا على التغلب على دان السادس للهواة بعائق ضخم من 17 حجرًا. قبل AlphaGo ، كان الفوز بأربع أحجار إعاقة يعتبر أعلى إنجاز . هذا العام كانوا ينتظرون انخفاضًا إلى 3 أحجار إعاقة. ولكن فجأة ظهر نظام تفوق على الأبطال على قدم المساواة.قوى الأطراف
AlphaGo
 العمر: أقل من 2 سنةالبلد: المملكة المتحدةدان ؟في عام 2014 ، اشترت Google شركة DeepMind ، وهي شركة ذكاء اصطناعي مقرها المملكة المتحدة. كان DeepMind في الماضي هو الذي جذب الانتباه من خلال إنشاء ذكاء اصطناعي DQN ، الذي تعلم بشكل مستقل لعب 49 لعبة Atari قديمة . عند وصف منتج شركة أخرى - AlphaGo - يمكنك أيضًا استخدام كلمة "بنفسك".يتكون نظام الكمبيوتر هذا بشكل مبسط من مزيج من طريقة مونتي كارلو والشبكات العصبية السياسية وشبكات القيمة. تم تدريب الشبكات العصبية في عدة مراحل من التعلم الآلي بمساعدة 160 ألف لعبة من 28.4 مليون وظيفة من خادم KGS للاعبين من السادس إلى التاسع. تم تخصيص مليون وظيفة أخرى للاختبارات. في البداية ، تم تنفيذ التدريب الخاضع للسيطرة لشبكة السياسة مباشرةً باستخدام تحركات اللاعبين البشريين. شبكة سياسة أخرى تم تعزيز التعلم. والثاني لعب مع الأول وحسنه بحيث تحولت السياسة للفوز ، وليس فقط توقعات التحركات. وأخيرًا ، تم إجراء التدريب ، مدعومًا بشبكة من القيم التي تتوقع الفائز في الألعاب التي تلعبها شبكات السياسة. تم تحقيق نتيجة التنبؤ الصحيح للخطوة التالية في 57 ٪ من الحالات.قبل AlphaGo ، أفضل نتيجةتمثل 44٪.تم النظر في المكونات الفنية بمزيد من التفصيل في كل من "Giktayms" و "Habr " .تمت مقارنة AlphaGo ببرامج أخرى - دائمًا ما تتفوق على أي منافسين - وكلاعب بشري. تحقيقا لهذه الغاية ، بمشاركة قاض من الاتحاد البريطاني للغو ، نظمت مباراة ضد بطل أوروبا ثلاث مرات وحامل دان الثاني فان هوي. خسر هوى جميع المباريات الخمس.
العمر: أقل من 2 سنةالبلد: المملكة المتحدةدان ؟في عام 2014 ، اشترت Google شركة DeepMind ، وهي شركة ذكاء اصطناعي مقرها المملكة المتحدة. كان DeepMind في الماضي هو الذي جذب الانتباه من خلال إنشاء ذكاء اصطناعي DQN ، الذي تعلم بشكل مستقل لعب 49 لعبة Atari قديمة . عند وصف منتج شركة أخرى - AlphaGo - يمكنك أيضًا استخدام كلمة "بنفسك".يتكون نظام الكمبيوتر هذا بشكل مبسط من مزيج من طريقة مونتي كارلو والشبكات العصبية السياسية وشبكات القيمة. تم تدريب الشبكات العصبية في عدة مراحل من التعلم الآلي بمساعدة 160 ألف لعبة من 28.4 مليون وظيفة من خادم KGS للاعبين من السادس إلى التاسع. تم تخصيص مليون وظيفة أخرى للاختبارات. في البداية ، تم تنفيذ التدريب الخاضع للسيطرة لشبكة السياسة مباشرةً باستخدام تحركات اللاعبين البشريين. شبكة سياسة أخرى تم تعزيز التعلم. والثاني لعب مع الأول وحسنه بحيث تحولت السياسة للفوز ، وليس فقط توقعات التحركات. وأخيرًا ، تم إجراء التدريب ، مدعومًا بشبكة من القيم التي تتوقع الفائز في الألعاب التي تلعبها شبكات السياسة. تم تحقيق نتيجة التنبؤ الصحيح للخطوة التالية في 57 ٪ من الحالات.قبل AlphaGo ، أفضل نتيجةتمثل 44٪.تم النظر في المكونات الفنية بمزيد من التفصيل في كل من "Giktayms" و "Habr " .تمت مقارنة AlphaGo ببرامج أخرى - دائمًا ما تتفوق على أي منافسين - وكلاعب بشري. تحقيقا لهذه الغاية ، بمشاركة قاض من الاتحاد البريطاني للغو ، نظمت مباراة ضد بطل أوروبا ثلاث مرات وحامل دان الثاني فان هوي. خسر هوى جميع المباريات الخمس.لي سيدول
 العمر: 33 سنةالبلد: كوريا الجنوبيةدان: 9 محترفمشارك آخر في المباراة هو لاعب الذهاب المحترف لي سيدول. حصل سيدول على أول عمل احترافي له في عام 1996 عن عمر يناهز 13 عامًا. سيدول لديه 18 لقبا دوليا ، وهو واحد من أقوى خمسة لاعبين في العالم.فاز AlphaGo على بطل أوروبا ، حيث انخفض المستوى. في الوقت نفسه ، ارتكب كل من البرنامج وهوي أخطاء. ليس من المستغرب أن Sedoll قبل التحدي بسرعة ووافق على اللعب ضد AlphaGo. قال لي إنه سيفوز بسهولة بنتيجة 4: 1 أو 5: 0. وقال سيدول إنه في غضون عامين أو ثلاثة أعوام ، ستريد Google الانتقام ، وبعد ذلك سيكون اللعب أكثر إثارة للاهتمام.
العمر: 33 سنةالبلد: كوريا الجنوبيةدان: 9 محترفمشارك آخر في المباراة هو لاعب الذهاب المحترف لي سيدول. حصل سيدول على أول عمل احترافي له في عام 1996 عن عمر يناهز 13 عامًا. سيدول لديه 18 لقبا دوليا ، وهو واحد من أقوى خمسة لاعبين في العالم.فاز AlphaGo على بطل أوروبا ، حيث انخفض المستوى. في الوقت نفسه ، ارتكب كل من البرنامج وهوي أخطاء. ليس من المستغرب أن Sedoll قبل التحدي بسرعة ووافق على اللعب ضد AlphaGo. قال لي إنه سيفوز بسهولة بنتيجة 4: 1 أو 5: 0. وقال سيدول إنه في غضون عامين أو ثلاثة أعوام ، ستريد Google الانتقام ، وبعد ذلك سيكون اللعب أكثر إثارة للاهتمام.مسار الأحداث
في الفترة من 9 مارس إلى 15 مارس ، أقيمت مباراة من 5 مباريات في فندق فورسيزون في سيول وفقًا للقواعد الصينية ، حيث يبلغ مقدار التعويض الأبيض عن الخطوة الأولى للسود (كومي) 7.5 نقاط. الفائز في المباراة حصل على مكافأة قدرها مليون دولار. إذا فازت منظمة العفو الدولية ، يذهب صندوق الجائزة للأعمال الخيرية: اليونيسف ، اذهب إلى منظمات التنمية وغيرها.كان الاهتمام بالألعاب كبيرا. أجبرت الاحتياجات التقنية Google على مد خط ألياف ضوئية في الفندق. لم يرسل عملاق البحث 1920 معالجًا و 280 مسرعات فيديو تم إطلاق AI عليها إلى كوريا . بدلا من ذلك نظم اتصال مع ملقمات في مكان ما في السحاب من Google منصة في الغرب الأوسط. تم ترتيب الأحجار على متن AlphaGo بواسطة المصور Aja Huan (الدان السادس للهواة).لم يحضر المباراة رئيس القسم ديميس حسبس فحسب ، بل حضر أيضًا الرئيس التنفيذي السابق لشركة Google إريك شميدت ، بالإضافة إلى أحد المهندسين الرئيسيين للشركة ، جيف دين. Go هي لعبة شعبية في كوريا. وصلت المباراة دون عناء إلى الصفحات الأولى من الصحف الكورية ، وحضرها أعضاء البرلمان الكوري. تم بث الألعاب باللغات الكورية واليابانية والصينية والإنجليزية. في اللغة الإنجليزية وحدها ، شاهد ما معدله 80،000 شخص عمليات البث على YouTube.9 مارس ، الأربعاء. لعبة واحدة
 الصورة من قبل DeepMind الشريك المؤسس مصطفى سليمانالأسود: Lee SedolWhite: AlphaGoالنتيجة: اعترف Lee Sedol بالهزيمةMoves: 186Movesالبث الكاململخص اللعبة باللغة الإنجليزيةتعليقات الاتحاد الروسي انتقلإلى Geektimesفي الساعة الواحدة بالتوقيت المحلي ، بدأت اللعبة الأولى. لعب الأسود الواجبات المنزلية ، وفي سبع حركات كانت المجموعات تتجاوز أي قاعدة. أظهر الرجل ذو الشعر الرمادي أسلوبه النموذجي وهاجمه . لكن AlphaGo لم يتراجع - بدأ النظام في التقدم بعد حوالي 12 حجرًا.كما قال المعلقون ، لعب AlphaGo مثل الإنسان: بحث النظام عن مجموعات حجارة ضعيفة وخلقها لاتخاذ خطوات قوية. على الرغم من أن منظمة العفو الدولية ارتكبت بعض الأخطاء ، كان لدى بلاك أسباب خطيرة للقلق. في الدقائق العشرين الأخيرة من المباراة ، طور AlphaGo ميزة. انتهت المباراة لمدة 3.5 ساعة مع اعتراف سيد دان التاسع بالهزيمة.كما قال Sedoll في وقت لاحق ، قام AlphaGo بخطوة واحدة غير عادية لم يكن ليقوم بها أي إنسان. ممثل فريق من الناس لم يتوقع مثل هذه المباراة. لعب النظام أقوى بشكل ملحوظ من ضد البطل الأوروبي. كما قال رئيس DeepMind Hassabis ، لا يتعلق الأمر حتى بقوة الحوسبة - إنهم تقريبًا متشابهونكما في المباراة ضد هوى. على مدار الأشهر الخمسة الماضية ، لعبت AlphaGo ضد نفسها واستخدمت تدريبات التعزيز لتحسين مهاراتها الخاصة. جاءت القوة المتزايدة كمفاجأة.هل تحسنت قوة اللعبة وأسلوبها بعد المباراة مع Fan Hui في أكتوبر 2015؟ يتفق المعلقون الثلاثة على أن هناك تغييرات كبيرة. تقول إيليا شيكشين أن البرنامج زاد المهارة بشكل ملحوظ من أكتوبر من مستوى لعبة البطل الأوروبي إلى مستوى بطل العالم:
الصورة من قبل DeepMind الشريك المؤسس مصطفى سليمانالأسود: Lee SedolWhite: AlphaGoالنتيجة: اعترف Lee Sedol بالهزيمةMoves: 186Movesالبث الكاململخص اللعبة باللغة الإنجليزيةتعليقات الاتحاد الروسي انتقلإلى Geektimesفي الساعة الواحدة بالتوقيت المحلي ، بدأت اللعبة الأولى. لعب الأسود الواجبات المنزلية ، وفي سبع حركات كانت المجموعات تتجاوز أي قاعدة. أظهر الرجل ذو الشعر الرمادي أسلوبه النموذجي وهاجمه . لكن AlphaGo لم يتراجع - بدأ النظام في التقدم بعد حوالي 12 حجرًا.كما قال المعلقون ، لعب AlphaGo مثل الإنسان: بحث النظام عن مجموعات حجارة ضعيفة وخلقها لاتخاذ خطوات قوية. على الرغم من أن منظمة العفو الدولية ارتكبت بعض الأخطاء ، كان لدى بلاك أسباب خطيرة للقلق. في الدقائق العشرين الأخيرة من المباراة ، طور AlphaGo ميزة. انتهت المباراة لمدة 3.5 ساعة مع اعتراف سيد دان التاسع بالهزيمة.كما قال Sedoll في وقت لاحق ، قام AlphaGo بخطوة واحدة غير عادية لم يكن ليقوم بها أي إنسان. ممثل فريق من الناس لم يتوقع مثل هذه المباراة. لعب النظام أقوى بشكل ملحوظ من ضد البطل الأوروبي. كما قال رئيس DeepMind Hassabis ، لا يتعلق الأمر حتى بقوة الحوسبة - إنهم تقريبًا متشابهونكما في المباراة ضد هوى. على مدار الأشهر الخمسة الماضية ، لعبت AlphaGo ضد نفسها واستخدمت تدريبات التعزيز لتحسين مهاراتها الخاصة. جاءت القوة المتزايدة كمفاجأة.هل تحسنت قوة اللعبة وأسلوبها بعد المباراة مع Fan Hui في أكتوبر 2015؟ يتفق المعلقون الثلاثة على أن هناك تغييرات كبيرة. تقول إيليا شيكشين أن البرنامج زاد المهارة بشكل ملحوظ من أكتوبر من مستوى لعبة البطل الأوروبي إلى مستوى بطل العالم:"يجب أن أقول أن هذا فرق كبير. تركت الألعاب المنشورة للبرنامج ضد Fan Hui شكوكًا كبيرة في أن AlfaGo يمكن أن يهزم Li Sedol. لكن خلال الأشهر القليلة الماضية ، نجح البرنامج في تحقيق قفزة كبيرة ".
"لم يكن Lee Sedoll يعرف من كان يلعب معه. وحقيقة أنه في الدفعة الأولى حاول استفزاز البرنامج لخطأ بمساعدة التحركات الأولى غير القياسية هو دليل على ذلك. بدلاً من محاولة العثور على نقاط ضعف في البرنامج ، يجب أن يلعب لعبته العادية. في هذه الحالة ، لن يكون واضحا من سيفوز ".
لاحظ ألكسندر داينرشتاين لعبة نسختين مختلفتين من البرنامج. الإصدار الذي لعب مع Fan ارتكب المزيد من الأخطاء بشكل ملحوظ.10 مارس ، الخميس. المباراة الثانية
 الصورة من قبل DeepMind الشريك المؤسس مصطفى سليمانالأسود: AlphaGoWhite: Lee Sedolالنتيجة: اعترف Lee Sedol بالهزيمةMoves: 211Movesالترجمة الكاملةملخص اللعبة باللغة الإنجليزيةالتعليقات من الاتحاد الروسي انتقلإلى Geektimesبعد المباراة الأولى ، اعترف Sedol بأنه صُدم ، لكنه ظل متفائلًا : يعتقد أن فتح الحركات سيجعل من الممكن تحقيق فرص أكبر للنصر. جعلت المباراة الثانية نتيجة المباراة أكثر توقعاً.لعب نظام AlphaGo باللون الأسود ، أي أنه ذهب أولاً. قامت منظمة العفو الدولية بخطوات عدوانية. كانت البداية غير عادية. لم يستطع المعلقون تحديد ما إذا كان جيدًا أم سيئًا. لعبت الأبيض بشكل أكثر تحفظا.لم يتم تكوين الشبكات العصبية للحد الأقصى من النقاط. يبحث البرنامج عن التحركات التي ستحقق النصر. هذا ما يوضحه باحث DeepMind Thor Grapel لقرارات غريبة. بين هذه الخطوة ، والتي ستعطي فوزًا بميزة 80٪ ، وأخرى ، والتي ستسمح لك بالفوز باحتمالية بنسبة 99 في المائة مع ميزة 1.5 نقطة ، سيختار AlphaGo الأخير. في بعض الأحيان يفقد النظام النقاط ، لكنه يحسن فرص الفوز فقط. هل هذا يعني أن التحركات الضعيفة هي علامة على ثقة السيارة في النصر ؟في المباراة الأولى ، كان لا يزال لدى Sedol وقت على ساعته. هذه المرة استنفدها ، لذلك كان على الشخص أن يقضي دقيقة واحدة فقط. في النهاية ، استهلك AlphaGo وقته أيضًا ، لذلك تسارعت سرعة تبادل الحركات إلى الحد الأقصى. ولكن ليس لفترة طويلة - اعترف الأبيض بالهزيمة. كما قال ، كان رئيس DeepMind Hassabis AlphaGo متأكد من النصر لا يزال في مكان ما من منتصف اللعبة.هل يمكن لـ DeepMind أن يأخذ في الاعتبار خصائص لاعب معين ويضع ميزاته المميزة في الذكاء الاصطناعي؟ يقول مكسيم بودولياك أن القدرات التقنية كانت:
الصورة من قبل DeepMind الشريك المؤسس مصطفى سليمانالأسود: AlphaGoWhite: Lee Sedolالنتيجة: اعترف Lee Sedol بالهزيمةMoves: 211Movesالترجمة الكاملةملخص اللعبة باللغة الإنجليزيةالتعليقات من الاتحاد الروسي انتقلإلى Geektimesبعد المباراة الأولى ، اعترف Sedol بأنه صُدم ، لكنه ظل متفائلًا : يعتقد أن فتح الحركات سيجعل من الممكن تحقيق فرص أكبر للنصر. جعلت المباراة الثانية نتيجة المباراة أكثر توقعاً.لعب نظام AlphaGo باللون الأسود ، أي أنه ذهب أولاً. قامت منظمة العفو الدولية بخطوات عدوانية. كانت البداية غير عادية. لم يستطع المعلقون تحديد ما إذا كان جيدًا أم سيئًا. لعبت الأبيض بشكل أكثر تحفظا.لم يتم تكوين الشبكات العصبية للحد الأقصى من النقاط. يبحث البرنامج عن التحركات التي ستحقق النصر. هذا ما يوضحه باحث DeepMind Thor Grapel لقرارات غريبة. بين هذه الخطوة ، والتي ستعطي فوزًا بميزة 80٪ ، وأخرى ، والتي ستسمح لك بالفوز باحتمالية بنسبة 99 في المائة مع ميزة 1.5 نقطة ، سيختار AlphaGo الأخير. في بعض الأحيان يفقد النظام النقاط ، لكنه يحسن فرص الفوز فقط. هل هذا يعني أن التحركات الضعيفة هي علامة على ثقة السيارة في النصر ؟في المباراة الأولى ، كان لا يزال لدى Sedol وقت على ساعته. هذه المرة استنفدها ، لذلك كان على الشخص أن يقضي دقيقة واحدة فقط. في النهاية ، استهلك AlphaGo وقته أيضًا ، لذلك تسارعت سرعة تبادل الحركات إلى الحد الأقصى. ولكن ليس لفترة طويلة - اعترف الأبيض بالهزيمة. كما قال ، كان رئيس DeepMind Hassabis AlphaGo متأكد من النصر لا يزال في مكان ما من منتصف اللعبة.هل يمكن لـ DeepMind أن يأخذ في الاعتبار خصائص لاعب معين ويضع ميزاته المميزة في الذكاء الاصطناعي؟ يقول مكسيم بودولياك أن القدرات التقنية كانت:"نظرًا لأن قاعدة الألعاب الاحترافية موجودة في المجال العام ، فسيكون من المستغرب إذا لم يتم استخدامها في إعداد AlphaGo. وبالتالي ، يمكننا أن نتوقع أن البرنامج يحتوي على ملف تعريف مفصل لجميع اللاعبين المحترفين ، نظرًا لأن بنائه لا يختلف من حيث المبدأ عن إنشاء ملف تعريف لتفضيلات المستخدم. وفي هذا جوجل قوي ".
تم التعبير عن وجهة نظر مماثلة من قبل إيليا شيكشين:"أنا متأكد من أن جميع ألعاب الحفلات المتاحة للجمهور في Lee Sedol (أكثر من 1000) تم تحميلها عليها. إن معرفة هذه الألعاب وإمكانية إعادة إنتاجها في أي وقت يمكن أن تعطي ميزة للبرنامج ، في حين أن Li Sedol كان بإمكانه فقط دراسة الألعاب ضد Fan Hui قبل المباراة ، حيث كان AlphaGo أقل بكثير. "
ومع ذلك ، يقول DeepMind أن AlphaGo لم تتم إعادة تكوينه خصيصًا لـ Lee Sedola. نعم ، ويصعب إجراء تغييرات كبيرة على الشبكة العصبية من خلال إدارة عدة مئات من الحفلات.السبت 12 مارس. اللعبة الثالثة
 من اليسار إلى اليمين: مؤسس DeepMind Demis Hassabis ، مالك دان المحترف التاسع لي سيدول ، المؤسس المشارك لشركة Google ، سيرجي برين.السود: Lee SedolWhite: AlphaGoالنتيجة: Lee Sedol هزيمة معترف بهاالتحركات: 176Turnsترجمة كاملةملخص اللعبة باللغة الإنجليزيةتعليقات الاتحاد الروسي انتقلإلى Geektimesالفرصة لتقرير نتيجة المباراة بالفعل في هذه اللعبة جذبت الانتباه إلى اللعبة. سافر سيرجي برين المؤسس المشارك لشركة Google إلى سيول بدون مضخة وزار اللعبة. كان من الواضح أن النصر كان دليلاً على قوة التكنولوجيا التي تدعم خدمات عملاق البحث. من التفضيلات الإعلانية إلى الهواتف الآلية التي يمكن أن تتحرك بشكل مستقل ، تعتمد جميع خدمات Google تقريبًا إلى درجة أو أخرى على الأنظمة التي تحتوي على عناصر الذكاء الاصطناعي.كما هو الحال في اللعبة الأولى ، أصبح Sedol أسود ، أي الأول. أيضا ، يمكن أن تعزى تجربة طرفين إلى عدد من اللحظات المواتية للشخص. الإشاعة المطالبات التي Sedol وفريق من الخبراء قضى الليل في البحث عن نقاط الضعف AlphaGo. يوافق ألكسندر داينرشتاين على ما يلي:
من اليسار إلى اليمين: مؤسس DeepMind Demis Hassabis ، مالك دان المحترف التاسع لي سيدول ، المؤسس المشارك لشركة Google ، سيرجي برين.السود: Lee SedolWhite: AlphaGoالنتيجة: Lee Sedol هزيمة معترف بهاالتحركات: 176Turnsترجمة كاملةملخص اللعبة باللغة الإنجليزيةتعليقات الاتحاد الروسي انتقلإلى Geektimesالفرصة لتقرير نتيجة المباراة بالفعل في هذه اللعبة جذبت الانتباه إلى اللعبة. سافر سيرجي برين المؤسس المشارك لشركة Google إلى سيول بدون مضخة وزار اللعبة. كان من الواضح أن النصر كان دليلاً على قوة التكنولوجيا التي تدعم خدمات عملاق البحث. من التفضيلات الإعلانية إلى الهواتف الآلية التي يمكن أن تتحرك بشكل مستقل ، تعتمد جميع خدمات Google تقريبًا إلى درجة أو أخرى على الأنظمة التي تحتوي على عناصر الذكاء الاصطناعي.كما هو الحال في اللعبة الأولى ، أصبح Sedol أسود ، أي الأول. أيضا ، يمكن أن تعزى تجربة طرفين إلى عدد من اللحظات المواتية للشخص. الإشاعة المطالبات التي Sedol وفريق من الخبراء قضى الليل في البحث عن نقاط الضعف AlphaGo. يوافق ألكسندر داينرشتاين على ما يلي:« , , – . , . , . , . , – .»
في الواقع ، في المباراة الثالثة ، كانت تحركات بلاك الأولى عدوانية. وفقًا لمعلقي المباراة ، في أول مباراتين ، حاول Sedol أسلوبًا مختلفًا عن أسلوبه المعتاد ، محاولًا الضغط على نقاط الضعف في النظام. في المباراة الثالثة ، أظهر أسلوبه النموذجي مع بداية جيدة وكو قوي في النهاية. على الرغم من وجود خطأ ، أظهر AlphaGo القدرة على العمل مع القتال المشترك - عادة ما تتعامل أنظمة الكمبيوتر بشكل سيئ مع هذا. في المباريات السابقة ، لم تكن هناك فرصة لإثبات هذه المهارة.حدد الحزب الحاسم القيمة التاريخية لما حدث. كان هذا ثالث فوز لـ AlphaGo في مباراة من خمس مباريات. هذا يعني أن نظام الكمبيوتر قد أظهر بالفعل التفوق. كانت مباراتان لاحقتان لإظهار عمقهما.الأحد 13 مارس. اللعبة الرابعة
 إذن AlphaGo يعترف بالهزيمةأسود: AlphaGoWhite: Lee Sedolالنتيجة: AlphaGo اعترف بهزيمةيتحرك: 180تحركاتترجمة كاملةملخص اللعبة باللغة الإنجليزيةتعليقاتنشرتها "Russian Federation go" Post on Geektimesبعد الهزيمة الثالثة لرجل ، كان أحد مواضيع المؤتمر الصحفي هو السؤال ما إذا كان لدى AlphaGo نقاط ضعف. ذكر الرجل ذو الشعر الرمادي كيف شعر به. اعتذر للأمة الكورية ومجتمع go go للنتيجة.اختار Sedoll استراتيجية أماسي ، حيث استولى على المنطقة المحيطة بالمحيط ، وليس المركز. كانت تحركات وايت الافتتاحية هي نفسها في المباراة الثانية. سمح الأبيض للأسود بالقبض على المركز ، مع التركيز على الحواف والزوايا. كما في الألعاب السابقة ، نفد الوقت قبل Sedol من قبل خصمه ، مما يعني دقيقة واحدة فقط لكل حركة.اتضح أن تحرك وايت 78 كان عظيما لدرجة أن المعلقين وصفوه بأنه تسوجي ، البعض أطلق عليه "يد الله". ربما وجد Sedol بالفعل نقطة ضعف في نظام الكمبيوتر. أجاب AlphaGo بشكل ضعيف. وفقا لرئيس DeepMind ، Demis Hassabis ، في الخطوة 79 ، ارتكب النظام خطأ ، معتبرا أن فرصة الفوز كانت 70 ٪. لكنها فهمت ذلك فقط في الخطوة 87. بعد ذلك ، اختلط الذكاء الاصطناعي.بدأ AlphaGo في القيام بحركات ضعيفة وصعبة. يعترف النظام بالهزيمة عندما تنخفض احتمالات الفوز إلى ما دون 20 بالمائة. حول هذا ، تذكر مهندس جوجل ديفيد سيلفر خلال استراحة ، والتي استغرقت لي سيدول. هذا ضروري للحفاظ على ثقافة اللعبة - إن الاستمرار في وضع غير مؤكد بشكل واضح سيكون غير محترم للخصم. ورفضت الفضة التعليق على سلسلة من تحركات النظام غير الواضحة. استمرت اللعبة ، ولا يزال سيدول مجبرا على العمل في ظل ظروف ضيق الوقت. ارتكبت منظمة العفو الدولية خطأ آخر ، وهزمت في وقت لاحق. كانت نتيجة المواجهة لمدة 4.5 ساعات أول انتصار لرجل في هذه المباراة.وقال سيدول إنه لم يهنئ كثيراً بهذا الفوز فقط. و ذكر أن السيارة ليست قوية حتى عندما يذهب الأسود.
إذن AlphaGo يعترف بالهزيمةأسود: AlphaGoWhite: Lee Sedolالنتيجة: AlphaGo اعترف بهزيمةيتحرك: 180تحركاتترجمة كاملةملخص اللعبة باللغة الإنجليزيةتعليقاتنشرتها "Russian Federation go" Post on Geektimesبعد الهزيمة الثالثة لرجل ، كان أحد مواضيع المؤتمر الصحفي هو السؤال ما إذا كان لدى AlphaGo نقاط ضعف. ذكر الرجل ذو الشعر الرمادي كيف شعر به. اعتذر للأمة الكورية ومجتمع go go للنتيجة.اختار Sedoll استراتيجية أماسي ، حيث استولى على المنطقة المحيطة بالمحيط ، وليس المركز. كانت تحركات وايت الافتتاحية هي نفسها في المباراة الثانية. سمح الأبيض للأسود بالقبض على المركز ، مع التركيز على الحواف والزوايا. كما في الألعاب السابقة ، نفد الوقت قبل Sedol من قبل خصمه ، مما يعني دقيقة واحدة فقط لكل حركة.اتضح أن تحرك وايت 78 كان عظيما لدرجة أن المعلقين وصفوه بأنه تسوجي ، البعض أطلق عليه "يد الله". ربما وجد Sedol بالفعل نقطة ضعف في نظام الكمبيوتر. أجاب AlphaGo بشكل ضعيف. وفقا لرئيس DeepMind ، Demis Hassabis ، في الخطوة 79 ، ارتكب النظام خطأ ، معتبرا أن فرصة الفوز كانت 70 ٪. لكنها فهمت ذلك فقط في الخطوة 87. بعد ذلك ، اختلط الذكاء الاصطناعي.بدأ AlphaGo في القيام بحركات ضعيفة وصعبة. يعترف النظام بالهزيمة عندما تنخفض احتمالات الفوز إلى ما دون 20 بالمائة. حول هذا ، تذكر مهندس جوجل ديفيد سيلفر خلال استراحة ، والتي استغرقت لي سيدول. هذا ضروري للحفاظ على ثقافة اللعبة - إن الاستمرار في وضع غير مؤكد بشكل واضح سيكون غير محترم للخصم. ورفضت الفضة التعليق على سلسلة من تحركات النظام غير الواضحة. استمرت اللعبة ، ولا يزال سيدول مجبرا على العمل في ظل ظروف ضيق الوقت. ارتكبت منظمة العفو الدولية خطأ آخر ، وهزمت في وقت لاحق. كانت نتيجة المواجهة لمدة 4.5 ساعات أول انتصار لرجل في هذه المباراة.وقال سيدول إنه لم يهنئ كثيراً بهذا الفوز فقط. و ذكر أن السيارة ليست قوية حتى عندما يذهب الأسود.15 مارس الثلاثاء. المباراة الخامسة
 غرفة التحكم AlphaGo ، مصطفى سليمانبلاكس: Lee SedolWhite: AlphaGoالنتيجة: اعترف Lee Sedol بالهزيمةMoves: 280Moves ملخصالبث الكاملللعبة باللغة الإنجليزيةتعليقات الاتحاد الروسي goPost على GeektimesBlack بدأ بأسلوب مشابه للعبة الأولى. ثم حاول Sedol وضع علامة على المنطقة في الزوايا العلوية اليمنى واليسرى - وهي استراتيجية استخدمها بنجاح في المباراة الرابعة. تولى AlphaGo المركز. من 48 إلى 58 ، ذهب الرجل والسيارة متدفقا. لكن AlphaGo لم ير tesuji من السود ، وانفجر لي إلى الأمام.نظرًا لخطأ بسيط ، زاد AlphaGo من موقفه قليلاً. نتيجة لمعركة طويلة ، نفد الوقت من كلا اللاعبين ، أي أنه كان عليهم مرة أخرى وضع كل حجر في أقل من دقيقة. خرجت اللعبة في أنف عميق ، وكانت اللوحة ممتلئة بالكامل بالحجارة. تمكن الأبيض من استعادة الميزة. عند تقييم الموقف ، أدرك سيدول أنه كان يخسر. بعد خمس ساعات ، اعترف بالهزيمة.
غرفة التحكم AlphaGo ، مصطفى سليمانبلاكس: Lee SedolWhite: AlphaGoالنتيجة: اعترف Lee Sedol بالهزيمةMoves: 280Moves ملخصالبث الكاملللعبة باللغة الإنجليزيةتعليقات الاتحاد الروسي goPost على GeektimesBlack بدأ بأسلوب مشابه للعبة الأولى. ثم حاول Sedol وضع علامة على المنطقة في الزوايا العلوية اليمنى واليسرى - وهي استراتيجية استخدمها بنجاح في المباراة الرابعة. تولى AlphaGo المركز. من 48 إلى 58 ، ذهب الرجل والسيارة متدفقا. لكن AlphaGo لم ير tesuji من السود ، وانفجر لي إلى الأمام.نظرًا لخطأ بسيط ، زاد AlphaGo من موقفه قليلاً. نتيجة لمعركة طويلة ، نفد الوقت من كلا اللاعبين ، أي أنه كان عليهم مرة أخرى وضع كل حجر في أقل من دقيقة. خرجت اللعبة في أنف عميق ، وكانت اللوحة ممتلئة بالكامل بالحجارة. تمكن الأبيض من استعادة الميزة. عند تقييم الموقف ، أدرك سيدول أنه كان يخسر. بعد خمس ساعات ، اعترف بالهزيمة.الأسئلة
ماذا تعني المباراة لي سيدولا؟
كانت نتيجة المباراة مفاجئة - هزيمة أحد أفضل اللاعبين البشريين ، والانتصار المفاجئ لأحد أنظمة الكمبيوتر الجديدة. بدلًا من مليون ، ستحصل سيدول على 170 ألف دولار: 150 ألفًا مقابل المشاركة و 20 ألفًا لانتصار واحد.قضية منفصلة هي لماذا خسر Sedol. كما تقول إيليا شيكشين ، لم يكن مستعدًا نفسيًا:تمكنت AlfaGo من هزيمة Lee Sedola. ومع ذلك ، هذا لا يعني أن البرنامج يلعب أقوى. أعتقد أن مستواهم هو نفسه تقريبا. كان الأمر فقط أن Lee Sedol لم يكن مستعدًا نفسيًا لمحاربة البرنامج في الأقساط الأولى ، حيث كان مفاجأة كبيرة بالنسبة له أن البرنامج يمكن أن يحاربه على قدم المساواة.
ألكسندر داينرشتاين:أعترف أنني لم أتوقع مثل هذا الموقف. مثل معظم المحترفين ، كان على يقين من أن Lee Sedol سيفوز بسهولة. لكننا رأينا أخطاء البرنامج. أعتقد أن السؤال لا يزال مفتوحًا. لي سيدول ، حتى في كوريا ، ليس الأول في التصنيف. أعتقد أن المهنيين الآخرين من مستواه لديهم فرصة للفوز ، خاصة إذا رأينا مجموعة مختارة من الألعاب التي يلعبها البرنامج ، والتي يمكننا من خلالها البحث عن نقاط ضعفها في اللعبة
ماذا تعني مباراة AlphaGo؟
من أجل الانتصار على Lee Sedol ، أعطت رابطة بادوك الكورية النظام رسميًا احترافيًا تاسعًا. هذا يعني أنها تعتبر لاعبة من المستوى الأعلى.لي سيدول ليس أقوى لاعب على وجه الأرض ، فهناك لاعبون آخرون. على سبيل المثال ، يدعي مالك دان المحترف التاسع ، Ke Jie ، أنه مع احتمال 60 ٪ يمكنه التغلب على AlphaGo. موقع العودة التقييمات يتلقى هو حقا أعلى في التصنيف العالمي. تم تحدي AlphaGo أيضًا من قبل السيد الصيني في دان المحترف التاسع ، Gu Li. هناك شائعات عن طلبات اللعب ضد إياما يوتا. أثناء اختيار AI للخصم ، قام معيد التوجيه بحساب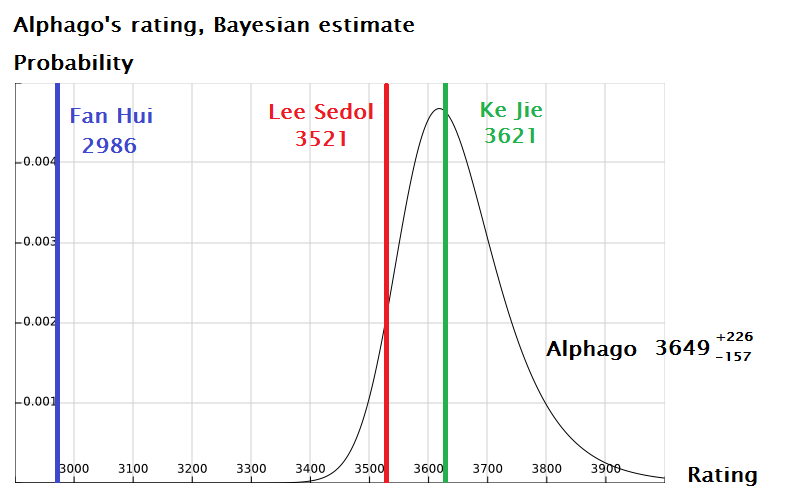 أن AlphaGo قد يكون أعلى من أفضل الأشخاص في الترتيب. وفقًا لتقديراته بواسطة نظرية بايز ، فإن تصنيف AlphaGo هو 3649 ، في حين أن جي لديه 3621 ، أقل.ومع ذلك ، فإن الإدلاء بأي تصريحات حول قوة النظام في وقت مبكر ، إذا كان ذلك ممكنا على الإطلاق. يتم نشر عدد قليل فقط من الألعاب ، والقوة الحقيقية للنظام غير واضحة. وهل هناك أي نقطة في نقاط التصنيف إذا تمكن النظام من العثور على نقطة ضعف؟ وفقا لألكسندر داينرشتاين ، سيكون البرنامج مثيرًا للاهتمام للتحقق في المباراة ضد Takemia Masaki ، صاحب الدرجة التاسعة الاحترافية:
أن AlphaGo قد يكون أعلى من أفضل الأشخاص في الترتيب. وفقًا لتقديراته بواسطة نظرية بايز ، فإن تصنيف AlphaGo هو 3649 ، في حين أن جي لديه 3621 ، أقل.ومع ذلك ، فإن الإدلاء بأي تصريحات حول قوة النظام في وقت مبكر ، إذا كان ذلك ممكنا على الإطلاق. يتم نشر عدد قليل فقط من الألعاب ، والقوة الحقيقية للنظام غير واضحة. وهل هناك أي نقطة في نقاط التصنيف إذا تمكن النظام من العثور على نقطة ضعف؟ وفقا لألكسندر داينرشتاين ، سيكون البرنامج مثيرًا للاهتمام للتحقق في المباراة ضد Takemia Masaki ، صاحب الدرجة التاسعة الاحترافية:"لقد كان أحد أقوى الأساتذة في العالم في أوائل التسعينات. لاحظنا أن البرنامج يفضل اللعبة على المركز للتأثير. حصل لي سيدول في جميع الأطراف على نقاط في الزوايا. ومن المعروف أن Takemia-sensi مغرم جدًا بلعب المركز وليس على الإطلاق "جشعًا" في بداية اللعبة. ليس من الواضح كيف سيتصرف البرنامج ضد مثل هذا الأسلوب غير المعتاد في اللعب ".
يمكن للمرء أن يتوقع تحركات أصلية وغير متوقعة من نظام كمبيوتر لم يخطر ببال أحد أبدًا. كما يقول مكسيم بودولياك ، رأى في AlphaGo يتحرك التحركات الطبيعية القابلة للتفسير للاعب قوي بشكل استثنائي:"كما يقول أحد الكتب ، تتدفق حفلة مثل تيار من جانب الجبل ، بشكل طبيعي وقوي. B.102 بدت مثيرة للإعجاب ومثيرة للإعجاب في الدفعة الأولى. لكن هذه ليست خطوة "إلهية".
يدعي دينرشتاين أن بعض تحركات AlphaGo لم ينظر فيها الناس:« , , 9 (), . C, , 5 % . 95 – , . , .
Google?
لقد أثبت عملاق الإنترنت مرة أخرى أن لديه بعضًا من أفضل التقنيات في العالم. كان قسم Google هذا أول من تمكن من حل مهمة أخرى لعلوم الكمبيوتر. في DeepMind يرون التطبيقات النفعية لأفضل ممارساتهم: هذه هي خدمات توصية التسوق أو تحليل البيانات الطبية.ولكن يمكنك الهروب من المشاريع التجارية وما زلت تحلم بالذهاب. لا يهم إذا بدأت أجهزة الكمبيوتر في اللعب بشكل أفضل من البشر أم لا. يمكنك تعيين منتج واحد على آخر ومشاهدة المعركة بين شركتين للتصنيع. وهم: يقوم Facebook بإنشاء روبوت غامق للغابات ، والذي يلعب حتى الآن أضعف ولم يشارك بعد في المباريات الرسمية ضد لاعبين محترفين. يجب أن تتنافس الغابة المظلمة هذا الشهر في بطولة العالم للكمبيوترفي اليابان. ستلعب أفضل برامج البطولة ضد Koichi Kobayashi.هل سيشاهد أحد معركة فيسبوك مع جوجل على لوحة 19 × 19؟ بالمناسبة ، من السهل تخيل المواجهة والعداء الشخصي. في يناير ، تحدث زوكربيرج عن نظامه في نفس يوم Google. وإذا كان لدى Facebook أخبار تطوير فقط ، فإن DeepMind تفاخر بالفعل بفوزه على البطل.مكسيم بودولياك:بالكاد. سيكون هذا تقريبًا مثل النظر في كيفية رسم البرنامج للفركتلات أو البقع الملونة على شاشة التوقف. لا أحد مهتم بالتعداد الميكانيكي للخيارات ؛ لا يوجد شيء استثنائي في هذا. لكن حقيقة أن الشخص يمكنه القيام بذلك هي ظاهرة.
ألكسندر داينرشتاين:بالنسبة للاعبي الشطرنج ، تم عقد مثل هذه المباريات لفترة طويلة ولا تسبب الكثير من الاهتمام. أنا شخصياً أحب أن أشاهد دورة برنامج يعلق عليها شخص. بالمناسبة ، لن يكون من المثير للاهتمام مشاهدة بطولة أفضل للمحترفين مع تعليقات AlphaGo.
ايليا شيكشين:أعتقد أن التطابق بين برامج الكمبيوتر يمكن أن يثير اهتمام الناس. وقد تم بالفعل بث مباريات مماثلة وجمع عدة مئات من المتفرجين. مستوى الشخص في العمل لا يزال بعيدًا عن الكمال. هناك مجال للنمو والتطور.
ماذا تعني المباراة للذهاب؟
يمكن للمرء أن ينظر بشكل مختلف إلى هزيمة أذكى الناس الذين استوعبوا آلاف السنين من الخبرة ، وانتصار قطعة حديد بلا روح بقطع من السيليكون في الداخل ، وإطلاق برنامج لم يكن منذ عامين. في مجتمع محبي اللعبة ، شخص ما سلبي بشكل واضح. يرى آخرون أن AlphaGo يساعد في الترويج. لكنه لن يفوز إلا إذا كان لديه شخص يتنافس معه ويتعلم منه ، تلاحظ إيليا شيكشين:"لعب البرنامج بجدارة وفاز بجدارة. هل يمكن أن تنتهي هذه المباراة بشكل مختلف؟ لا أعتقد ذلك. أنا متأكد من أن Lee Sedol اكتشف الكثير لنفسه في هذه الألعاب الخمس. الآن يجب أن يكون مستعدًا لمحاربة AlfaGo ، ولكن للأسف ، فات الأوان. حصل Go-world على منافس خطير في شخص هذا البرنامج.
ولكن ليس فقط لي سيدول قام بالاكتشافات. اكتشف الملايين من الأشخاص الذين شاهدوا هذه المباراة شيئًا جديدًا. شخص ما لديه إمكانات هائلة من التكنولوجيا والذكاء الاصطناعي ، شخص ما وجد شيئًا جديدًا في اللعبة وينظر إليه الآن بشكل مختلف ، حسنًا ، بالنسبة لشخص ما ، كانت لعبة go نفسها هي الوحي.
أنا شخصياً يسعدني جداً أن أرى أن لعبتي المفضلة هذه الأيام أصبحت مركز اهتمام العالم كله. أعتقد أنه مع كل شيء الآن سيكون كل شيء أفضل فقط. "
ألكسندر داينرشتاين:"أشك في أن الجوائز المالية في الدول الآسيوية قد تنخفض ، لكن بالنسبة لبقية العالم ، فإن الإيجابيات من الإعلان عن المباراة ، وكانت ضخمة ، يجب أن تفوقها. أتوقع تدفق لاعبين جدد إلى Go ، وينبغي أن نكون سعداء بذلك فقط. لقد سمع الكثير عن هذه اللعبة لأول مرة ".
من الممكن أيضًا حل المشكلات التي لا يواجهها الأشخاص:"إن عالم الذهاب مستاء بالتأكيد ، ولكن مع ظهور البرنامج ، يمكننا أن نتعلم الكثير من الأشياء المثيرة للاهتمام. على سبيل المثال ، في Go هناك لغز اخترع في عام 1713 من قبل السيد الياباني الشهير Dosetsu Inseki. يذهب الحساب مائتي خطوة إلى الأمام. تم نشر كتب كاملة عليها ، ولكن لا يمكن لأحد حلها. هناك حلول جميلة ، لكنها تختلف عن المهمة التي أعلن عنها المؤلف في الأصل. أخيرًا ، سنكتشف ما إذا كان لهذه المشكلة حل. أو ربما كان دوسيتسو مخطئا؟ "
إذا أصبحت أنظمة الطاقة AlphaGo هي القاعدة ، فسيكون من السهل الغش واستخدام حركات مثل هذا النظام. حتى الآن ، تعرض البطل للضرب من قبل مجموعة حوسبة ضخمة. من المستحيل جسديا جره معه. اليوم ، القوة الحاسوبية للهاتف الذكي كافية لوضع أي شخص على شفرات الكتف في لعبة الشطرنج. لم يحدث هذا على الفور ، ولكن يجب أن نتوقع حدوث شيء مماثل في المستقبل القريب. في يوم من الأيام ، ستناسب إمكانية الاحتيال في جيبك حتى في غياب الاتصالات اللاسلكية. وفقًا لـ Dienstein ، أصبحت الأجهزة الإلكترونية في بطولات go الآن مريحة:« . . , ( ). , , . . , , , .»
?
تم إنشاء الخوارزمية على مدار الأشهر ، وتم تدريبه على اللعب في حفلات بشرية ، ثم وصل بشكل مستقل إلى أعلى مستوى. هذا هو واحد من أفضل العروض المرئية لقوة وسرعة الذكاء الاصطناعي.وفقًا لإيليا شيكشين ، فقد صُدم بالسرعة التي تعلم بها النظام اللعب:"في فترة زمنية قصيرة ، تعلم البرنامج اللعب على أعلى مستوى. "كنت مهتما بملاحظة كيف يتصرف البرنامج عندما يفوز ومتى يخسر."
ماذا تعني المباراة لنا جميعا؟
هو AlphaGo الذكاء الاصطناعي؟لقد تعلم النظام كيفية اللعب في حفلات الناس. لقد شهدت الشبكات العصبية الاصطناعية العديد من الألعاب التي لم يلعبها أي شخص في حياته كلها. ثم ، في الألعاب ضد نفسه ، جلب النظام المهارة إلى مستوى يجلب النصر على أفضل الناس. هذا ليس هو الحال مع Deep Blue ، عندما تم تعيين خوارزمية بحث الحل يدويًا بالكامل.لا يختلف هذا كثيرًا عن كيفية تعلمنا للكلام. يكتسب الأطفال بطريقة ما القدرة على تكرار الكلمات ، ووضع الكلمات في جمل ، ثم التعبير عن أفكارهم في أجزاء. هذا يستغرق سنوات من التدريب ، وهذا ممكن فقط في بعض النقاط في الحياة ، عندما يكون الدماغ أكثر عرضة للإصابة. كيف يختلف AlphaGo عن الشخص الذي تعلم التحدث ، ثم صقل المهارة قبل كتابة الأدب؟يمكنك أن تنظر داخل المشروع وتكون محبطًا للغاية: هناك خوارزميات يمكن تفسيرها وفهمها. ولكن في الوقت نفسه ، يحقق AlphaGo هدفه بشكل مثالي. هذه هي المشكلة: يجب أن يكون الذكاء الاصطناعي في نظر المتشككين غير قابل للتفسير وقادر على فعل كل شيء وكره الإنسانية. إن إتمام مهمة بسيطة يثير عبء حساب الخيارات.لكن مسألة جوهر المصطلحات ليست مثيرة للاهتمام. ما هو أكثر إثارة للخوف هو الفكر بأن لعبة AlphaGo تلعب بشكل أفضل من جميع منشئيها ، وحتى الأشخاص الذين علمتهم أطرافها الشبكات العصبية.هل سيدمرنا الذكاء الاصطناعي؟تخضع ل تأثير الذكاء الاصطناعيفي بعض الأحيان تتطلب البرامج أن تكون على علم بها. هذا هو بالضبط ما لا تضعه منظمة العفو الدولية. لقد هزمت شركة IBM Watson الناس في لعبة Jeopardy الفكرية ، لكنها لا تعرف عنها. لا يتسرع في الرغبة في اللعب بعد. لا يفرح بالنصر. حتى أنه لا يفهم أنه فاز. ليس لديه وعي.إن AIs ليست صورًا أساسية في شكل مصباح أحمر HAL9000 أو SkyNet شرير. الذكاء الاصطناعي ليس لديه وعي. هذا مجرد برنامج كمبيوتر "ذكي" بما يكفي لأداء المهام التي تتطلب عادة مشاركة التحليل البشري. هذه ليست آلة قتل بدم بارد.على سبيل المثال ، يوجد اليوم العديد من المقالات والدراسات العلمية. من المستحيل جسديًا قراءة كل شيء. نحن بحاجة إلى نظام يمكنه قراءة وتنظيم هذه المصفوفات الوحشية من المعلومات. وسيكون لهذا النظام ذكاء اصطناعي.لكن هذا الذكاء الاصطناعي لن يقتل الناس. بدلا من ذلك ، سوف تشغل وظائفهم.هل ستتركنا منظمة العفو الدولية بدون عمل؟يمكن للذكاء الاصطناعي زيادة كفاءة العمل بشكل ملحوظ. هذا ما يجب أن يكون مصدر قلق.في فجر الحضارة ، كان الجميع يشاركون في إنتاج الغذاء ، لكن ذلك لم يكن كافياً. اليوم ، لا يوجد أحد تقريبًا منخرط في الزراعة ، ولكن هناك الكثير من الطعام. الجواب على هذا اللغز هو في إنتاجية العمل وكفاءة الأداة.نظام الترجمة الذي لا يتطلب سوى التدقيق اللغوي ومقارنة المصطلحات يمكن أن يجعل الحياة أسهل للمترجم. هل يعني هذا أن نصف المترجمين يخاطرون بفقدان وظائفهم؟سيؤدي تحليل بسيط للنص إلى تسليط الضوء على عبارة ساخنة في المقالة ، ثم نشر عبارة مماثلة مع رابط إلى الأصل عبر واجهة برمجة التطبيقات للشبكات الاجتماعية. هل هذا يعني أن صفوف SMMs ستصبح أرق؟ الإجابة على متطلبات رفع الحد الأدنى للأجور للصرافين.
ستنقل أسطول من الشاحنات غير المأهولة بشكل مستقل بين المدن ، وسيجلس السائق أحيانًا خلف عجلة القيادة لوقوف السيارة. ماذا تفعل بالكتلة الضخمة من سائقي الشاحنات المحررين؟ من خلال تحليل دفق الفيديو لبث مباراة رياضية ، يمكن للروبوت إنشاء مقال إخباري لن يختلف بأي شكل عن ذلك الذي كتبه شخص. أين يوجد في هذا السيناريو المزيد من الوظائف للصحفيين؟يقوم النظام الخبير بتقييم الوثيقة القانونية واتخاذ قرار بشأنها. ماذا تفعل مع الجيش الذي تم إخلاؤه من صغار الموظفين في مكاتب المحاماة؟ولا حتى فقدان الوظائف ، لكن شخصيتها خطيرة. بادئ ذي بدء ، سوف تبدأ الوظائف البسيطة منخفضة الأجر بالاختفاء. أولئك الذين هم في مثل هذه المواقف هم الأكثر ضعفا من الناحية الاقتصادية.هل يمكننا التكيف مع التغيرات الاجتماعية العميقة التي لن تحدث حتى في الثورة ، ولكن في ومضة حادة؟ من سيستفيد من الذكاء الاصطناعي: فقط أولئك الذين يمتلكون مثل هذا النظام؟ هل هذا يعني زيادة أخرى في عدم المساواة الاجتماعية؟هذه هي الأسئلة التي يجب أن تخيف ذوبان الشتاء القادم لمنظمة العفو الدولية. لا ينبغي أن يكون هذا رهاب بدائي للقتلة الميكانيكية القديرة. وستبقى أنباء انتفاضة السيارات عناوين الصحف " قتل الروبوت رجلاً ". التكنولوجيا هي مجرد أداة. خطر على الناس خلق أشخاص آخرين.AlphaGo هو رسول آخر لمستقبل التغيير الغامض هذا. لكن هذا الذكاء الاصطناعي ليس تهديدًا بالذهاب ، إذا كان فقط لأن اللعبة بفضله أصبحت أكثر شعبية فقط. لا يمكن للاعب آخر أن يفعل أسوأ من ذلك ، حيث يشاهد الملايين مبارياته.
من خلال تحليل دفق الفيديو لبث مباراة رياضية ، يمكن للروبوت إنشاء مقال إخباري لن يختلف بأي شكل عن ذلك الذي كتبه شخص. أين يوجد في هذا السيناريو المزيد من الوظائف للصحفيين؟يقوم النظام الخبير بتقييم الوثيقة القانونية واتخاذ قرار بشأنها. ماذا تفعل مع الجيش الذي تم إخلاؤه من صغار الموظفين في مكاتب المحاماة؟ولا حتى فقدان الوظائف ، لكن شخصيتها خطيرة. بادئ ذي بدء ، سوف تبدأ الوظائف البسيطة منخفضة الأجر بالاختفاء. أولئك الذين هم في مثل هذه المواقف هم الأكثر ضعفا من الناحية الاقتصادية.هل يمكننا التكيف مع التغيرات الاجتماعية العميقة التي لن تحدث حتى في الثورة ، ولكن في ومضة حادة؟ من سيستفيد من الذكاء الاصطناعي: فقط أولئك الذين يمتلكون مثل هذا النظام؟ هل هذا يعني زيادة أخرى في عدم المساواة الاجتماعية؟هذه هي الأسئلة التي يجب أن تخيف ذوبان الشتاء القادم لمنظمة العفو الدولية. لا ينبغي أن يكون هذا رهاب بدائي للقتلة الميكانيكية القديرة. وستبقى أنباء انتفاضة السيارات عناوين الصحف " قتل الروبوت رجلاً ". التكنولوجيا هي مجرد أداة. خطر على الناس خلق أشخاص آخرين.AlphaGo هو رسول آخر لمستقبل التغيير الغامض هذا. لكن هذا الذكاء الاصطناعي ليس تهديدًا بالذهاب ، إذا كان فقط لأن اللعبة بفضله أصبحت أكثر شعبية فقط. لا يمكن للاعب آخر أن يفعل أسوأ من ذلك ، حيث يشاهد الملايين مبارياته.Source: https://habr.com/ru/post/ar391747/
All Articles