ما هي الخصوصية التفاضلية
تم استخدام التقنية المعقدة للاستجابة العشوائية لأول مرة بواسطة Google لجمع إحصائيات Chrome. هل ستحذو شركة أبل حذوها؟
عن المؤلف. ماثيو جرين: خبير التشفير ، الأستاذ في جامعة جونز هوبكنز ، مؤلف مدونة أنظمة التشفيرالمنشورة في 14 يونيو 2016 بالأمس ، في عرض WWDC ، قدمت Apple عددًا من الميزات الجديدة لأمان وحماية البيانات السرية ، بما في ذلك ميزة جذبت اهتمامًا خاصًا ... الارتباك. على وجه التحديد ، أعلنت Apple عن استخدام تقنية جديدة تسمى "الخصوصية التفاضلية" ، اختصارًا باسم DP ، لتحسين حماية الخصوصية عند جمع البيانات السرية للمستخدم.بالنسبة لمعظم الناس ، تسبب هذا في سؤال غبي: "ماذا ... ؟؟؟" ، لأن القليل منهم سمع عن الخصوصية التفاضلية من قبل ، وأكثر من ذلك فهم ما يعنيه. لسوء الحظ ، لم تكن شركة Apple واضحة تمامًا عندما يتعلق الأمر بالمكونات السرية التي تعمل عليها منصتها ، لذلك نأمل أن تقرر في المستقبل نشر المزيد من المعلومات. كل ما نعرفه في الوقت الحالي موجود في دليل Apple iOS 10 Preview."بدءًا من iOS 10 ، تستخدم Apple تقنية الخصوصية التفاضلية للمساعدة في تحديد أنماط سلوك المستخدم لعدد كبير من المستخدمين دون تعريض خصوصية كل مستخدم للخطر. لإخفاء هوية الشخص ، تضيف الخصوصية التفاضلية ضوضاء رياضية إلى عينة صغيرة من قالب سلوك مستخدم فردي لمستخدم معين. نظرًا لأن المزيد من الأشخاص يظهرون نفس النمط ، تبدأ الأنماط الشائعة في الظهور التي يمكن أن تخبرنا وتحسن تجربة المستخدم الإجمالية. في iOS 10 ، ستساعد هذه التقنية في تحسين QuickType ونصائح الرموز التعبيرية ونصائح Spotlight وتلميحات البحث في Notes. "باختصار ، يبدو أن Apple تريد جمع المزيد من البيانات من هاتفك.بشكل أساسي ، يقومون بذلك من أجل تحسين خدماتهم ، وليس لجمع معلومات حول العادات والخصائص الفردية لكل مستخدم. لضمان ذلك ، تنوي Apple استخدام تقنيات إحصائية معقدة للتأكد من أن القاعدة المجمعة - نتيجة حساب الوظيفة الإحصائية بعد معالجة جميع معلوماتك - لا تمنح المشاركين الأفراد. من حيث المبدأ ، يبدو جيدًا. لكن بالطبع ، الشيطان يختبئ دائمًا في التفاصيل.على الرغم من أننا لا نمتلك هذه التفاصيل ، يبدو أن الوقت قد حان الآن للحديث على الأقل عن ماهية الخصوصية التفاضلية ، وكيف يمكن تنفيذها وماذا يمكن أن يعني لـ Apple - ولجهاز iPhone.
بالأمس ، في عرض WWDC ، قدمت Apple عددًا من الميزات الجديدة لأمان وحماية البيانات السرية ، بما في ذلك ميزة جذبت اهتمامًا خاصًا ... الارتباك. على وجه التحديد ، أعلنت Apple عن استخدام تقنية جديدة تسمى "الخصوصية التفاضلية" ، اختصارًا باسم DP ، لتحسين حماية الخصوصية عند جمع البيانات السرية للمستخدم.بالنسبة لمعظم الناس ، تسبب هذا في سؤال غبي: "ماذا ... ؟؟؟" ، لأن القليل منهم سمع عن الخصوصية التفاضلية من قبل ، وأكثر من ذلك فهم ما يعنيه. لسوء الحظ ، لم تكن شركة Apple واضحة تمامًا عندما يتعلق الأمر بالمكونات السرية التي تعمل عليها منصتها ، لذلك نأمل أن تقرر في المستقبل نشر المزيد من المعلومات. كل ما نعرفه في الوقت الحالي موجود في دليل Apple iOS 10 Preview."بدءًا من iOS 10 ، تستخدم Apple تقنية الخصوصية التفاضلية للمساعدة في تحديد أنماط سلوك المستخدم لعدد كبير من المستخدمين دون تعريض خصوصية كل مستخدم للخطر. لإخفاء هوية الشخص ، تضيف الخصوصية التفاضلية ضوضاء رياضية إلى عينة صغيرة من قالب سلوك مستخدم فردي لمستخدم معين. نظرًا لأن المزيد من الأشخاص يظهرون نفس النمط ، تبدأ الأنماط الشائعة في الظهور التي يمكن أن تخبرنا وتحسن تجربة المستخدم الإجمالية. في iOS 10 ، ستساعد هذه التقنية في تحسين QuickType ونصائح الرموز التعبيرية ونصائح Spotlight وتلميحات البحث في Notes. "باختصار ، يبدو أن Apple تريد جمع المزيد من البيانات من هاتفك.بشكل أساسي ، يقومون بذلك من أجل تحسين خدماتهم ، وليس لجمع معلومات حول العادات والخصائص الفردية لكل مستخدم. لضمان ذلك ، تنوي Apple استخدام تقنيات إحصائية معقدة للتأكد من أن القاعدة المجمعة - نتيجة حساب الوظيفة الإحصائية بعد معالجة جميع معلوماتك - لا تمنح المشاركين الأفراد. من حيث المبدأ ، يبدو جيدًا. لكن بالطبع ، الشيطان يختبئ دائمًا في التفاصيل.على الرغم من أننا لا نمتلك هذه التفاصيل ، يبدو أن الوقت قد حان الآن للحديث على الأقل عن ماهية الخصوصية التفاضلية ، وكيف يمكن تنفيذها وماذا يمكن أن يعني لـ Apple - ولجهاز iPhone.الدافع
في السنوات القليلة الماضية ، اعتاد "المستخدم العادي" على فكرة إرسال كمية كبيرة من المعلومات الشخصية من جهازه إلى الخدمات المختلفة التي يستخدمها. تظهر استطلاعات الرأي أيضا أن المواطنين بدأوا يشعرون بعدم الارتياح لهذا السبب .هذا الانزعاج منطقي إذا فكرت في تلك الشركات التي تستخدم معلوماتنا الشخصية لكسب المال منا. ومع ذلك ، في بعض الأحيان يكون هناك سبب وجيه لجمع معلومات حول إجراءات المستخدم. على سبيل المثال ، قدمت Microsoft مؤخرًا أداة يمكنها تشخيص سرطان البنكرياس من خلال تحليل استعلامات البحث في Bing. تدعم Google خدمة Google Flu Trends المعروفةللتنبؤ بانتشار الأمراض المعدية من خلال تكرار طلبات البحث في مناطق مختلفة. وبالطبع ، نستفيد جميعًا من بيانات التعهيد الجماعي التي تعمل على تحسين جودة الخدمات التي نستخدمها ، من تطبيقات الخرائط إلى التعليقات في المطاعم. لسوء الحظ ، حتى جمع البيانات لأغراض جيدة يمكن أن يكون ضارًا. على سبيل المثال ، في أواخر العقد الأول من القرن الحادي والعشرين ، أعلنت Netflix عن مسابقة لتطوير أفضل خوارزمية توصية بالأفلام الروائية الطويلة. لمساعدة المشاركين في المسابقة ، نشروا مجموعة بيانات "مجهولة المصدر" مع إحصائيات حول مشاهدات مستخدمي الأفلام ، وحذف جميع المعلومات الشخصية من هناك. لسوء الحظ ، لم يكن "إلغاء تحديد الهوية" كافيًا. في العمل العلمي الشهير Narayan و Shmatikovأوضحت أن مجموعات البيانات هذه يمكن استخدامها في تحديد هوية مستخدمين محددين - وحتى للتنبؤ بآرائهم السياسية! - ببساطة إذا كنت تعرف القليل من المعلومات الإضافية حول هؤلاء المستخدمين.مثل هذه الأشياء يجب أن تزعجنا. ليس فقط لأن الشركات التجارية تتبادل عادة المعلومات التي تم جمعها عن المستخدمين (على الرغم من قيامهم بذلك) ، ولكن لأن الاختراق يحدث ، ولأن الإحصائيات حول قاعدة البيانات التي تم جمعها يمكن أن توضح بطريقة أو بأخرى تفاصيل السجلات الفردية المحددة التي تم استخدامها لتجميع عينة مجمعة. الخصوصية التفاضلية هي مجموعة من الأدوات التي تم تصميمها لحل هذه المشكلة.ما هي الخصوصية التفاضلية؟
الخصوصية التفاضلية هي تعريف لحماية بيانات المستخدم تم اقتراحه في الأصل بواسطة Cynthia Dwork في عام 2006. تحدث تقريبا، يمكن أن يكون وصفها بإيجاز على النحو التالي:تخيل أن لديك اثنين من كافة النواحي الأخرى قواعد بيانات مماثلة، واحدة مع داخل المعلومات الخاصة بك، والآخر دون ذلك. تضمن الخصوصية التفاضلية أن يؤدي الاستعلام الإحصائي لقاعدة بيانات واحدة وثانية إلى نتيجة محددة مع نفس الاحتمال (تقريبًا).يمكن تمثيل ذلك على النحو التالي: موانئ دبي تجعل من الممكن فهم ما إذا كان لبياناتك أي تأثير ذي دلالة إحصائية على نتيجة الاستعلام. إذا لم يكن كذلك ، فيمكن إضافتها بأمان إلى قاعدة البيانات ، لأنه لن يكون هناك أي ضرر من ذلك. ضع في اعتبارك هذا المثال السخيف:تخيل أنك قمت بتنشيط جهاز iPhone الخاص بك خيار إبلاغ Apple بأنك غالبًا ما تستخدم الرموز التعبيرية  في جلسات دردشة iMessage الخاصة بك. يتكون هذا التقرير من جزء واحد من المعلومات: 1 يعني أنك تحب ، و 0 يعني أنك لا تريد . يمكن لشركة Apple تلقي هذه التقارير وإدخالها في قاعدة بيانات ضخمة. نتيجة لذلك ، تريد الشركة أن تكون قادرة على معرفة عدد المستخدمين الذين يحبون رمزًا تعبيريًا معينًا.وغني عن القول أن العملية البسيطة لتلخيص النتائج ونشرها لا تفي بتعريف DP ، لأن العملية الحسابية لجمع القيم في قاعدة بيانات تحتوي على معلوماتك ستنتج على الأرجح نتيجة مختلفة عن جمع القيم من قاعدة البيانات حيث تكون معلوماتك مفقودة. لذلك ، على الرغم من أن هذه المبالغ ستعطي القليل من المعلومات عنك ، ولكن لا يزال هناك جزء من المعلومات الشخصية يتسرب. الاستنتاج الرئيسي لدراسة الخصوصية التفاضلية هو أنه في كثير من الحالات يمكن تحقيق مبدأ DP بإضافة ضوضاء عشوائيةإلى النتيجة. على سبيل المثال ، بدلاً من مجرد الإبلاغ عن النتيجة النهائية ، يمكن للطرف الذي يقوم بالإبلاغ تنفيذ توزيع Gaussian أو Laplace ، لذلك لن تكون النتيجة دقيقة - لكنها ستخفي كل قيمة محددة في قاعدة البيانات. (هناك العديد من التقنيات الأخرى لميزات أخرى مثيرة للاهتمام ).حتى أكثر قيمة ، يمكن حساب مقدار الضوضاء المضافة دون معرفة محتويات قاعدة البيانات نفسها (أو حتى حجمها) . أي أن الحساب مع الضوضاء يمكن إجراؤه على أساس معرفة الوظيفة نفسها فقط ، والتي يتم تنفيذها ، ومستوى مقبول من تسرب البيانات.
في جلسات دردشة iMessage الخاصة بك. يتكون هذا التقرير من جزء واحد من المعلومات: 1 يعني أنك تحب ، و 0 يعني أنك لا تريد . يمكن لشركة Apple تلقي هذه التقارير وإدخالها في قاعدة بيانات ضخمة. نتيجة لذلك ، تريد الشركة أن تكون قادرة على معرفة عدد المستخدمين الذين يحبون رمزًا تعبيريًا معينًا.وغني عن القول أن العملية البسيطة لتلخيص النتائج ونشرها لا تفي بتعريف DP ، لأن العملية الحسابية لجمع القيم في قاعدة بيانات تحتوي على معلوماتك ستنتج على الأرجح نتيجة مختلفة عن جمع القيم من قاعدة البيانات حيث تكون معلوماتك مفقودة. لذلك ، على الرغم من أن هذه المبالغ ستعطي القليل من المعلومات عنك ، ولكن لا يزال هناك جزء من المعلومات الشخصية يتسرب. الاستنتاج الرئيسي لدراسة الخصوصية التفاضلية هو أنه في كثير من الحالات يمكن تحقيق مبدأ DP بإضافة ضوضاء عشوائيةإلى النتيجة. على سبيل المثال ، بدلاً من مجرد الإبلاغ عن النتيجة النهائية ، يمكن للطرف الذي يقوم بالإبلاغ تنفيذ توزيع Gaussian أو Laplace ، لذلك لن تكون النتيجة دقيقة - لكنها ستخفي كل قيمة محددة في قاعدة البيانات. (هناك العديد من التقنيات الأخرى لميزات أخرى مثيرة للاهتمام ).حتى أكثر قيمة ، يمكن حساب مقدار الضوضاء المضافة دون معرفة محتويات قاعدة البيانات نفسها (أو حتى حجمها) . أي أن الحساب مع الضوضاء يمكن إجراؤه على أساس معرفة الوظيفة نفسها فقط ، والتي يتم تنفيذها ، ومستوى مقبول من تسرب البيانات.المفاضلة بين الخصوصية والدقة
من الواضح الآن أن حساب عدد المعجبين بين المستخدمين هو مثال سيئ جدًا. في حالة DP ، من المهم أن يتم تطبيق نفس النهج العام على وظائف أكثر إثارة للاهتمام ، بما في ذلك الحسابات الإحصائية المعقدة ، مثل تلك المستخدمة في أنظمة التعلم الآلي. يمكن تطبيقه حتى إذا تم حساب العديد من الوظائف المختلفة على نفس قاعدة البيانات.ولكن هناك صيد واحد. والحقيقة هي أن حجم "تسرب المعلومات" من طلب واحد يمكن التقليل منه داخل حدود صغيرة ، ولكنه لن يكون صفراً. في كل مرة ترسل فيها استعلامًا إلى قاعدة بيانات مع بعض الوظائف ، يزداد إجمالي "التسرب" - ولا يمكن تقليله أبدًا. بمرور الوقت ، مع زيادة عدد الطلبات ، قد يبدأ التسرب في النمو.هذا هو واحد من أصعب جوانب DP. يتجلى في طريقتين رئيسيتين:- كلما كنت تنوي "سؤال" قاعدة البيانات ، كلما زاد الضجيج الذي ستضيفه لتقليل تسرب المعلومات . وهذا يعني أن DP ، في الواقع ، هو حل وسط أساسي بين دقة وحماية البيانات الشخصية ، والذي يمكن أن يؤدي إلى مشكلة كبيرة عند تدريب نماذج التعلم الآلي المعقدة.
- , . , , , — , . . .
غالبًا ما يُشار إلى إجمالي مقدار التسرب المسموح به باسم "ميزانية الخصوصية" ، ويحدد عدد الطلبات المسموح بها (ومدى دقة النتائج). الدرس الرئيسي من موانئ دبي هو أن الشيطان يختبئ في الميزانية. قم بتعيينها عالية جدًا وستسرب البيانات المهمة. قم بتعيينه منخفض جدًا ، ويمكن أن تكون نتائج الاستعلام عديمة الفائدة.الآن في بعض التطبيقات ، مثل معظم التطبيقات في أجهزة iPhone الخاصة بنا ، لن تصبح الدقة غير الكافية مشكلة معينة. لقد اعتدنا على حقيقة أن هواتفنا الذكية ترتكب أخطاء. ولكن في بعض الأحيان عندما يتم استخدام DP في التطبيقات المعقدة ، مثل تدريب نماذج التعلم الآلي ، فهذا مهم حقًا.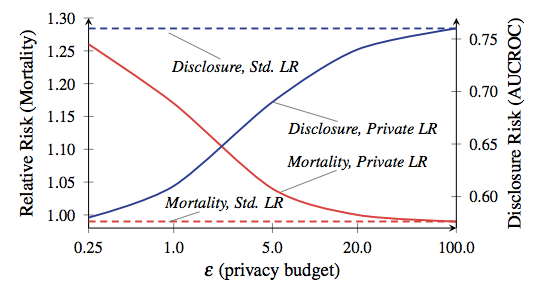 نسبة الوفيات والإفصاح ، من عمل فريدريكسون وآخرون.من عام 2014. الخط الأحمر يتوافق مع وفيات المرضى.لإعطائك مثالًا مجنونًا تمامًا عن مدى أهمية التوافق بين الخصوصية والدقة ، انظر إلى هذه الورقة العلمية لعام 2014 التي كتبها فريدريكسون وآخرون . بدأ المؤلفون بربط بيانات جرعة الدواءمنقاعدة بيانات الوارفارين المفتوحةبعلامات جينية محددة. ثم قاموا بتطبيق تقنيات التعلم الآلي لتطوير نموذج لحساب الجرعات من قاعدة البيانات - لكنهم استخدموا DP مع خيارات ميزانية الخصوصية المختلفة أثناء تدريب النموذج. ثم قاموا بتقييم مستوى تسرب المعلومات ونجاح استخدام النموذج لعلاج "المرضى" الافتراضيين.أظهرت النتائج أن دقة النموذج تعتمد بشدة على ميزانية الخصوصية التي تم وضعها أثناء التدريب. إذا كانت الميزانية مرتفعة للغاية ، فسيتم تسريب كمية كبيرة من معلومات المريض السرية من قاعدة البيانات - لكن النموذج الناتج يتخذ قرارات الجرعة التي تكون آمنة مثل الممارسة السريرية القياسية. من ناحية أخرى ، عندما يتم تخفيض الميزانية إلى مستوى يعني خصوصية مقبولة ، يميل نموذج تم تدريبه على البيانات الصاخبة إلى قتل "مرضاه".قبل أن تبدأ بالذعر ، دعني أشرح: جهاز iPhone الخاص بك لن يقتلك. لا أحد يقول أن هذا المثال يشبه عن بعد ما ستفعله Apple على الهواتف الذكية. الاستنتاج من هذه الدراسة يكمن ببساطة في حقيقة وجود حل وسط مثير للاهتمام بين الكفاءة وحماية الخصوصية في كل نظام يعتمد على DP - يعتمد هذا الحل إلى حد كبير على القرارات المحددة التي يتخذها مطورو النظام ، ومعلمات التشغيل المحددة ، وما إلى ذلك. دعونا نأمل أن تخبرنا Apple قريبًا عن هذه الخيارات.
نسبة الوفيات والإفصاح ، من عمل فريدريكسون وآخرون.من عام 2014. الخط الأحمر يتوافق مع وفيات المرضى.لإعطائك مثالًا مجنونًا تمامًا عن مدى أهمية التوافق بين الخصوصية والدقة ، انظر إلى هذه الورقة العلمية لعام 2014 التي كتبها فريدريكسون وآخرون . بدأ المؤلفون بربط بيانات جرعة الدواءمنقاعدة بيانات الوارفارين المفتوحةبعلامات جينية محددة. ثم قاموا بتطبيق تقنيات التعلم الآلي لتطوير نموذج لحساب الجرعات من قاعدة البيانات - لكنهم استخدموا DP مع خيارات ميزانية الخصوصية المختلفة أثناء تدريب النموذج. ثم قاموا بتقييم مستوى تسرب المعلومات ونجاح استخدام النموذج لعلاج "المرضى" الافتراضيين.أظهرت النتائج أن دقة النموذج تعتمد بشدة على ميزانية الخصوصية التي تم وضعها أثناء التدريب. إذا كانت الميزانية مرتفعة للغاية ، فسيتم تسريب كمية كبيرة من معلومات المريض السرية من قاعدة البيانات - لكن النموذج الناتج يتخذ قرارات الجرعة التي تكون آمنة مثل الممارسة السريرية القياسية. من ناحية أخرى ، عندما يتم تخفيض الميزانية إلى مستوى يعني خصوصية مقبولة ، يميل نموذج تم تدريبه على البيانات الصاخبة إلى قتل "مرضاه".قبل أن تبدأ بالذعر ، دعني أشرح: جهاز iPhone الخاص بك لن يقتلك. لا أحد يقول أن هذا المثال يشبه عن بعد ما ستفعله Apple على الهواتف الذكية. الاستنتاج من هذه الدراسة يكمن ببساطة في حقيقة وجود حل وسط مثير للاهتمام بين الكفاءة وحماية الخصوصية في كل نظام يعتمد على DP - يعتمد هذا الحل إلى حد كبير على القرارات المحددة التي يتخذها مطورو النظام ، ومعلمات التشغيل المحددة ، وما إلى ذلك. دعونا نأمل أن تخبرنا Apple قريبًا عن هذه الخيارات.على أي حال ، كيف تجمع البيانات؟
لقد لاحظت أنه في جميع الأمثلة المذكورة أعلاه ، افترضت أن الاستعلامات يتم إجراؤها بواسطة مشغل قاعدة بيانات موثوق به يمكنه الوصول إلى جميع البيانات الأساسية "الأولية" الأصلية. لقد اخترت هذا النموذج لأنه نسخة تقليدية من النموذج تستخدم في جميع الأدبيات تقريبًا ، وليس لأنها فكرة جيدة.في الواقع ، سيكون هناك سبب للقلق إذا نفذت Apple حقًانظامك بطريقة مماثلة. سيتطلب ذلك من Apple جمع كل المعلومات الأولية حول إجراءات المستخدم في قاعدة بيانات مركزية ضخمة ، ثم ("ثق بنا!") احسب الإحصائيات الخاصة بها بطريقة آمنة مع حماية خصوصية المستخدم. كحد أدنى ، تتيح هذه الطريقة المعلومات للحصول على الاستدعاءات القضائية ، وكذلك للمتسللين الأجانب ، وكبار المديرين الفضوليين في Apple ، وما إلى ذلك.لحسن الحظ ، هذه ليست الطريقة الوحيدة لتطبيق نظام خصوصية تفاضلي. من الناحية النظرية ، يمكن حساب الإحصائيات باستخدام تقنيات التشفير الفاخرة (مثل بروتوكول الحساب السري أو التشفير المتماثل تمامًا) لسوء الحظ ، ربما تكون هذه التقنيات غير فعالة للغاية لاستخدامها على النطاق الذي تحتاجه شركة Apple.يبدو أن اتباع نهج أكثر واعدة بكثير هو عدم جمع البيانات الأولية على الإطلاق . كان هذا النهج مؤخرًا هو أول من استخدم جميع Google لجمع الإحصاءات في متصفح Chrome . يعتمد نظامهم ، المسمى RAPPOR ، على تقنية استجابة عشوائية عمرها 50 عامًا . تعمل الاستجابة العشوائية على النحو التالي:- ( : « Bing?»), , «», — . .
- ( , «»), «» .
على مستوى بديهي ، فإن الاستجابة العشوائية تحمي خصوصية تقارير المستخدم الفردية ، لأن الإجابة "نعم" يمكن أن تعني إما "نعم ، أستخدم Bing" ، أو ببساطة نتيجة انخفاضات عشوائية للعملة. على المستوى الرسمي ، توفر الاستجابة العشوائية خصوصية متباينة ، مع ضمانات محددة يمكن تخصيصها عن طريق تعديل خصائص العملات المعدنية.يأخذ RAPPOR هذه التقنية القديمة نسبيًا ويحولها إلى شيء أكثر قوة. بدلاً من الإجابة على سؤال واحد ببساطة ، يمكن للنظام تجميع تقرير حول متجه معقد للأسئلة وحتى إرجاع إجابات معقدة ، مثل السلاسل - على سبيل المثال ، ما هي صفحتك الرئيسية في المستعرض الخاص بك. يتم تحقيق هذا الأخير بحيث يتم تمرير السلسلة لأول مرةمرشح بلوم - سلسلة من البتات التي تم إنشاؤها باستخدام وظائف التجزئة بطريقة محددة للغاية. ثم يتم خلط البتات المستقبلة بالضوضاء وجمعها ، ويتم استعادة الاستجابات باستخدام عملية فك تشفير (معقدة نوعًا ما). في حين لا يوجد دليل واضح على أن Apple تستخدم نظامًا مثل RAPPOR ، إلا أن بعض النصائح الصغيرة تشير إلى ذلك. على سبيل المثال ، يصف Craig Federighi (في الحياة التي يشبهها تمامًا في الصورة) الخصوصية المتمايزة بأنها "استخدام التجزئة والاختزال والضوضاء لتنشيط ... تدريب التعهيد الجماعي مع الحفاظ على خصوصية بيانات المستخدم الفردية تمامًا". هذا دليل ضعيف إلى حد ما على أي شيء ، على الأرجح ، ولكن وجود "التجزئة" في هذا الاقتباس يوحي على الأقل باستخدام المرشحات بأسلوب RAPPOR.تتمثل الصعوبة الرئيسية في أنظمة الاستجابة العشوائية في أنها يمكن أن تقدم بيانات حساسة إذا أجاب المستخدم على نفس السؤال عدة مرات. يحاول RAPPOR حل هذه المشكلة بعدة طرق. أحدها تحديد الجزء الثابت من المعلومات وبالتالي حساب "الاستجابة الدائمة" بدلاً من إعادة ترتيبها عشوائيًا في كل مرة. ولكن من الممكن تخيل المواقف التي لا تعمل فيها هذه الحماية. مرة أخرى ، غالبًا ما يختبئ الشيطان في التفاصيل - ما عليك سوى رؤيتها. أنا متأكد من أنه سيتم نشر العديد من الأوراق العلمية الرائعة على أي حال.
في حين لا يوجد دليل واضح على أن Apple تستخدم نظامًا مثل RAPPOR ، إلا أن بعض النصائح الصغيرة تشير إلى ذلك. على سبيل المثال ، يصف Craig Federighi (في الحياة التي يشبهها تمامًا في الصورة) الخصوصية المتمايزة بأنها "استخدام التجزئة والاختزال والضوضاء لتنشيط ... تدريب التعهيد الجماعي مع الحفاظ على خصوصية بيانات المستخدم الفردية تمامًا". هذا دليل ضعيف إلى حد ما على أي شيء ، على الأرجح ، ولكن وجود "التجزئة" في هذا الاقتباس يوحي على الأقل باستخدام المرشحات بأسلوب RAPPOR.تتمثل الصعوبة الرئيسية في أنظمة الاستجابة العشوائية في أنها يمكن أن تقدم بيانات حساسة إذا أجاب المستخدم على نفس السؤال عدة مرات. يحاول RAPPOR حل هذه المشكلة بعدة طرق. أحدها تحديد الجزء الثابت من المعلومات وبالتالي حساب "الاستجابة الدائمة" بدلاً من إعادة ترتيبها عشوائيًا في كل مرة. ولكن من الممكن تخيل المواقف التي لا تعمل فيها هذه الحماية. مرة أخرى ، غالبًا ما يختبئ الشيطان في التفاصيل - ما عليك سوى رؤيتها. أنا متأكد من أنه سيتم نشر العديد من الأوراق العلمية الرائعة على أي حال.إذن هل استخدام Apple لـ DP جيد أم سيئ؟
كعالم وأخصائي أمن المعلومات ، لدي مشاعر مختلطة حول هذا الموضوع. من ناحية ، بصفتي عالمًا ، أفهم مدى أهمية مراقبة تنفيذ التطورات العلمية المتقدمة في منتج حقيقي. وتوفر Apple منصة كبيرة جدًا لمثل هذه التجارب.من ناحية أخرى ، بصفتي متخصصًا في الأمن العملي ، من واجبي أن أبقى متشككًا - يجب على الشركة ، على أقل تقدير ، عرض رمز مهم للأمن (كما فعلت Google مع RAPPOR ) ، أو على الأقل أن تحدد صراحة ما تنفذه. إذا كانت Apple تخطط لجمع كميات هائلة من البيانات الجديدة من الأجهزة التي نعتمد عليها بشدة ، فيجب علينا حقًاتأكد من أنهم يفعلون كل شيء بشكل صحيح - ولا يصفقونهم بشدة لتنفيذ مثل هذه الأفكار الرائعة. (لقد ارتكبت بالفعل مثل هذا الخطأ مرة واحدة ، وما زلت أشعر بأنني أحمق بسبب هذا).ولكن ربما كل هذه التفاصيل عميقة للغاية. في النهاية ، يبدو بالتأكيد أن Apple تحاول بصدق أن تفعل شيئًا لحماية المعلومات السرية للمستخدمين ، ومع مراعاة البدائل ، قد يكون هذا هو الشيء الأكثر أهمية.Source: https://habr.com/ru/post/ar395313/
All Articles