تقرأ الشبكة العصبية 46.8٪ من الكلمات على الشفاه في التلفزيون ، بينما فقط 12.4٪ من الناس
 أطر البرامج الأربعة التي تمت دراسة البرنامج عليها ، بالإضافة إلى كلمة "بعد الظهر" ، التي نطق بها متحدثان مختلفانقبل أسبوعين ، تحدثوا عن شبكة LipNet العصبية ، والتي أظهرت جودة قياسية بلغت 93.4 ٪ من التعرف على الكلام البشري على الشفاه. حتى في ذلك الوقت ، كان من المفترض وجود العديد من التطبيقات لأنظمة الكمبيوتر هذه: جيل جديد من المعينات السمعية الطبية مع التعرف على الكلام ، وأنظمة المحاضرات الصامتة في الأماكن العامة ، والتعرف على المقاييس الحيوية ، وأنظمة النقل السري للمعلومات الخاصة بالتجسس ، والتعرف على الكلام عن طريق الفيديو من كاميرات المراقبة ، وما إلى ذلك. والآن ، أخبر خبراء من جامعة أكسفورد مع أحد موظفي Google DeepMind عن تطوراتهم الخاصة في هذا المجال.تم تدريب الشبكة العصبية الجديدة على النصوص التعسفية للأشخاص الذين يعملون على قناة بي بي سي التلفزيونية. ومن المثير للاهتمام ، أن التدريب تم تلقائيًا ، دون شرح الخطاب يدويًا أولاً. تعرّف النظام نفسه على الكلام ، وعلق على الفيديو ، ووجد وجوهًا في الإطار ، ثم تعلم كيفية تحديد العلاقة بين الكلمات (الأصوات) وحركة الشفاه.ونتيجة لذلك ، يتعرف هذا النظام بشكل فعال على النصوص التعسفية ، بدلاً من أمثلة من مجموعة خاصة من جمل GRID ، كما فعلت LipNet. تحتوي حالة GRID على بنية ومفردات محدودة للغاية ؛ وبالتالي ، يمكن فقط 33000 جملة. وبالتالي ، يتم تقليل عدد الخيارات بأوامر من الحجم وتبسيط الاعتراف.تتكون حالة GRID الخاصة على النحو التالي:الأمر (4) + اللون (4) + حرف الجر (4) + الحرف (25) + الرقم (10) + الظرف (4) ،حيث يتوافق الرقم مع عدد متغيرات الكلمات لكل فئة من الفئات اللفظية الست.على عكس LipNet ، يعمل تطوير DeepMind والمتخصصين من جامعة أكسفورد على تدفقات الكلام التعسفي على جودة الصورة التلفزيونية. إنه يشبه إلى حد كبير نظام حقيقي ، جاهز للاستخدام العملي.قامت منظمة العفو الدولية بتدريب 5000 ساعة من الفيديو المسجل من ستة برامج تلفزيونية لقناة BBC التلفزيونية البريطانية من يناير 2010 إلى ديسمبر 2015: هذه هي النشرات الإخبارية المنتظمة (1584 ساعة) ، والأخبار الصباحية (1997 ساعة) ، وبث الأخبار Newsnight (590 ساعة) ، World News (194 ساعات) ووقت السؤال (323 ساعة) والعالم اليوم (272 ساعة). في المجموع ، تحتوي مقاطع الفيديو على 118116 جمل من الكلام البشري المستمر.بعد ذلك ، تم فحص البرنامج على البث الذي تم بثه بين مارس وسبتمبر 2016.
أطر البرامج الأربعة التي تمت دراسة البرنامج عليها ، بالإضافة إلى كلمة "بعد الظهر" ، التي نطق بها متحدثان مختلفانقبل أسبوعين ، تحدثوا عن شبكة LipNet العصبية ، والتي أظهرت جودة قياسية بلغت 93.4 ٪ من التعرف على الكلام البشري على الشفاه. حتى في ذلك الوقت ، كان من المفترض وجود العديد من التطبيقات لأنظمة الكمبيوتر هذه: جيل جديد من المعينات السمعية الطبية مع التعرف على الكلام ، وأنظمة المحاضرات الصامتة في الأماكن العامة ، والتعرف على المقاييس الحيوية ، وأنظمة النقل السري للمعلومات الخاصة بالتجسس ، والتعرف على الكلام عن طريق الفيديو من كاميرات المراقبة ، وما إلى ذلك. والآن ، أخبر خبراء من جامعة أكسفورد مع أحد موظفي Google DeepMind عن تطوراتهم الخاصة في هذا المجال.تم تدريب الشبكة العصبية الجديدة على النصوص التعسفية للأشخاص الذين يعملون على قناة بي بي سي التلفزيونية. ومن المثير للاهتمام ، أن التدريب تم تلقائيًا ، دون شرح الخطاب يدويًا أولاً. تعرّف النظام نفسه على الكلام ، وعلق على الفيديو ، ووجد وجوهًا في الإطار ، ثم تعلم كيفية تحديد العلاقة بين الكلمات (الأصوات) وحركة الشفاه.ونتيجة لذلك ، يتعرف هذا النظام بشكل فعال على النصوص التعسفية ، بدلاً من أمثلة من مجموعة خاصة من جمل GRID ، كما فعلت LipNet. تحتوي حالة GRID على بنية ومفردات محدودة للغاية ؛ وبالتالي ، يمكن فقط 33000 جملة. وبالتالي ، يتم تقليل عدد الخيارات بأوامر من الحجم وتبسيط الاعتراف.تتكون حالة GRID الخاصة على النحو التالي:الأمر (4) + اللون (4) + حرف الجر (4) + الحرف (25) + الرقم (10) + الظرف (4) ،حيث يتوافق الرقم مع عدد متغيرات الكلمات لكل فئة من الفئات اللفظية الست.على عكس LipNet ، يعمل تطوير DeepMind والمتخصصين من جامعة أكسفورد على تدفقات الكلام التعسفي على جودة الصورة التلفزيونية. إنه يشبه إلى حد كبير نظام حقيقي ، جاهز للاستخدام العملي.قامت منظمة العفو الدولية بتدريب 5000 ساعة من الفيديو المسجل من ستة برامج تلفزيونية لقناة BBC التلفزيونية البريطانية من يناير 2010 إلى ديسمبر 2015: هذه هي النشرات الإخبارية المنتظمة (1584 ساعة) ، والأخبار الصباحية (1997 ساعة) ، وبث الأخبار Newsnight (590 ساعة) ، World News (194 ساعات) ووقت السؤال (323 ساعة) والعالم اليوم (272 ساعة). في المجموع ، تحتوي مقاطع الفيديو على 118116 جمل من الكلام البشري المستمر.بعد ذلك ، تم فحص البرنامج على البث الذي تم بثه بين مارس وسبتمبر 2016.مثال على قراءة الشفاه من شاشة التلفزيون أظهر البرنامج جودة قراءة عالية إلى حد ما. لقد أدركت بشكل صحيح حتى الجمل المعقدة للغاية ذات التركيبات النحوية غير العادية واستخدام الأسماء المناسبة. أمثلة على الجمل المعترف بها تمامًا:- الكثير من الناس الذين تورطوا في الهجمات
- CLOSE TO THE EUROPEAN COMMISSION’S MAIN BUILDING
- WEST WALES AND THE SOUTH WEST AS WELL AS WESTERN SCOTLAND
- WE KNOW THERE WILL BE HUNDREDS OF JOURNALISTS HERE AS WELL
- ACCORDING TO PROVISIONAL FIGURES FROM THE ELECTORAL COMMISSION
- THAT’S THE LOWEST FIGURE FOR EIGHT YEARS
- MANCHESTER FOOTBALL CORRESPONDENT FOR THE DAILY MIRROR
- LAYING THE GROUNDS FOR A POSSIBLE SECOND REFERENDUM
- ACCORDING TO THE LATEST FIGURES FROM THE OFFICE FOR NATIONAL STATISTICS
- IT COMES AFTER A DAMNING REPORT BY THE HEALTH WATCHDOG
تجاوزت منظمة العفو الدولية بشكل كبير فعالية عمل شخص ، خبير في قراءة الشفاه ، حاول التعرف على 200 مقطع فيديو عشوائي من أرشيف فيديو التحقق المسجل.تمكن المحترف من التعليق بدون خطأ واحد فقط على 12.4٪ من الكلمات ، بينما سجلت الذكاء الاصطناعي بشكل صحيح 46.8٪. لاحظ الباحثون أن العديد من الأخطاء يمكن أن تسمى طفيفة. على سبيل المثال ، حرف "s" المفقود في نهاية الكلمات. إذا اقتربنا من تحليل النتائج بشكل أقل صرامة ، فقد أدرك النظام في الواقع أكثر من نصف الكلمات على الهواء.مع هذه النتيجة ، فإن DeepMind متفوق بشكل كبير على جميع قراء الشفاه الآخرين ، بما في ذلك LipNet المذكور أعلاه ، والذي تم تطويره أيضًا في جامعة أكسفورد. ومع ذلك ، من السابق لأوانه الحديث عن التفوق المطلق ، لأن LipNet لم يتم تدريبه على مثل هذه المجموعة الكبيرة من البيانات.وفقًا للخبراء ، يعد DeepMind خطوة كبيرة نحو تطوير نظام قراءة الشفاه تلقائيًا بالكامل.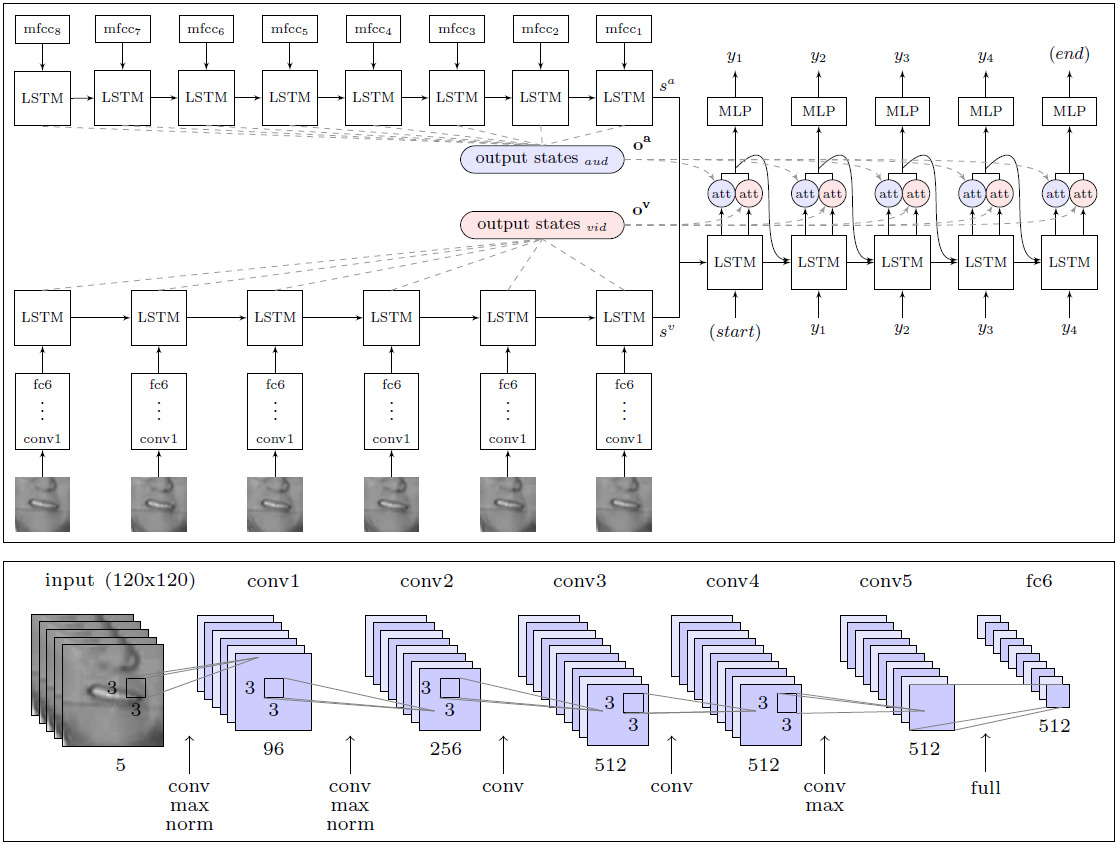 بنية وحدة WLAS (المشاهدة والاستماع والحضور والتهجئة) والشبكة العصبية التلافيفية لقراءة الشفاهتكمن الميزة العظيمة للباحثين في حقيقة أنهم قاموا بتجميع مجموعة بيانات ضخمة للتدريب واختبار النظام مع 17500 كلمة فريدة. بعد كل شيء ، ليس فقط خمس سنوات من التسجيل المستمر للبرامج التلفزيونية باللغة الإنجليزية الجيدة ، ولكن أيضًا مزامنة واضحة للفيديو والصوت (على التلفزيون غالبًا ما يكون هناك مزامنة حتى ثانية واحدة ، حتى على التلفزيون الإنجليزي الاحترافي) ، بالإضافة إلى تطوير وحدة للتعرف على الكلام ، والتي يتم فرضها على الفيديو ويستخدم في تعليم نظام قراءة الشفاه (وحدة WLAS ، انظر الرسم البياني أعلاه).في حالة أدنى تزامن ، يصبح تدريب النظام عديم الفائدة عمليا ، حيث لا يستطيع البرنامج تحديد المراسلات الصحيحة للأصوات وحركات الشفاه. بعد العمل التحضيري الشامل ، كان تدريب البرنامج تلقائيًا تمامًا - حيث قام بمعالجة كل 5000 مقطع فيديو بشكل مستقل.في السابق ، لم تكن هذه المجموعة موجودة ببساطة ، لذلك اضطر نفس مؤلفي LipNet إلى قصر أنفسهم على قاعدة GRID. إلى مطوري DeepMind ، وعدوا بنشر مجموعة بيانات في المجال العام لتدريب ذكاء اصطناعي آخر. قال زملاء من فريق تطوير LipNet بالفعل أنهم يتطلعون إلى ذلك.تم نشر العمل العلمي في المجال العام على موقع arXiv (arXiv: 1611.05358v1).إذا ظهرت أنظمة قراءة الشفاه التجارية في السوق ، فستكون حياة الناس العاديين أبسط بكثير. يمكن افتراض أن مثل هذه الأنظمة سيتم بناؤها على الفور في أجهزة التلفزيون والأجهزة المنزلية الأخرى لتحسين التحكم الصوتي والتعرف على الكلام الخالي من الأخطاء تقريبًا.
بنية وحدة WLAS (المشاهدة والاستماع والحضور والتهجئة) والشبكة العصبية التلافيفية لقراءة الشفاهتكمن الميزة العظيمة للباحثين في حقيقة أنهم قاموا بتجميع مجموعة بيانات ضخمة للتدريب واختبار النظام مع 17500 كلمة فريدة. بعد كل شيء ، ليس فقط خمس سنوات من التسجيل المستمر للبرامج التلفزيونية باللغة الإنجليزية الجيدة ، ولكن أيضًا مزامنة واضحة للفيديو والصوت (على التلفزيون غالبًا ما يكون هناك مزامنة حتى ثانية واحدة ، حتى على التلفزيون الإنجليزي الاحترافي) ، بالإضافة إلى تطوير وحدة للتعرف على الكلام ، والتي يتم فرضها على الفيديو ويستخدم في تعليم نظام قراءة الشفاه (وحدة WLAS ، انظر الرسم البياني أعلاه).في حالة أدنى تزامن ، يصبح تدريب النظام عديم الفائدة عمليا ، حيث لا يستطيع البرنامج تحديد المراسلات الصحيحة للأصوات وحركات الشفاه. بعد العمل التحضيري الشامل ، كان تدريب البرنامج تلقائيًا تمامًا - حيث قام بمعالجة كل 5000 مقطع فيديو بشكل مستقل.في السابق ، لم تكن هذه المجموعة موجودة ببساطة ، لذلك اضطر نفس مؤلفي LipNet إلى قصر أنفسهم على قاعدة GRID. إلى مطوري DeepMind ، وعدوا بنشر مجموعة بيانات في المجال العام لتدريب ذكاء اصطناعي آخر. قال زملاء من فريق تطوير LipNet بالفعل أنهم يتطلعون إلى ذلك.تم نشر العمل العلمي في المجال العام على موقع arXiv (arXiv: 1611.05358v1).إذا ظهرت أنظمة قراءة الشفاه التجارية في السوق ، فستكون حياة الناس العاديين أبسط بكثير. يمكن افتراض أن مثل هذه الأنظمة سيتم بناؤها على الفور في أجهزة التلفزيون والأجهزة المنزلية الأخرى لتحسين التحكم الصوتي والتعرف على الكلام الخالي من الأخطاء تقريبًا.Source: https://habr.com/ru/post/ar399429/
All Articles