 يمكنك أتمتة الكثير ، ولكن ليس كلها. ولكن مع ذلك ، بمساعدة الأتمتة ، يمكنك تبسيط حياتك بشكل كبير ، مما يجعلها أكثر راحة ، وفي بعض الحالات أكثر أمانًا. يعني حماية نفسك من الرؤساء. قرر أحد مطوري الشبكات العصبية إنشاء نظام ، عندما اقترب المدير ، قلل على الفور من "النوافذ غير الملائمة" ، مما أخفيها عن الأنظار.بالنسبة للمستخدم ، تبدو إجراءات النظام شفافة تمامًا ، لأن الشبكة العصبية بعد اكتشاف رئيس يقترب يعطي إخطارًا مقابلًا. وعندها فقط يقلل من النوافذ ، ويحذر آخر. يعمل النظام نفسه على حقيقة أنه بمساعدة كاميرا الويب العادية ذات الجودة العالية ، فإنه يلتقط وجوه الأشخاص الذين يقتربون من سطح المكتب ، وعندما يتم تحديد الرؤساء ، فإنه يزيل كل شيء بسرعة من شاشة الكمبيوتر ، بعيدًا عن الخطيئة. في التطوير ، تم استخدام مكتبة Keras ، مما سهل المهمة. كيف يعمل كل ذلك؟نعم ، لا شيء معقد بشكل خاص ، المطور لم يتلق أي مشاكل خاصة في تنفيذ النظام. بالمناسبة ، كان أحد الشروط عند إنشاء مثل هذا النظام هو تعليم الشبكة العصبية للتعرف على وجه الرئيس من 5-7 أمتار ، حتى لا تقلق بشأن قدرة الرئيس على رؤية كل شيء من مسافة قريبة. ليس هناك الكثير من الوقت لتحديد الرئيس - فقط حوالي 4-5 ثواني.بالطبع ، لا يوجد شيء جيد في العمل خارج العمل. هذا المثال هو مجرد نظام عمل ، تم إجراؤه ، بدلاً من ذلك من أجل المتعة ، وليس بسبب بعض المشاكل الحقيقية من قبل السلطات.
يمكنك أتمتة الكثير ، ولكن ليس كلها. ولكن مع ذلك ، بمساعدة الأتمتة ، يمكنك تبسيط حياتك بشكل كبير ، مما يجعلها أكثر راحة ، وفي بعض الحالات أكثر أمانًا. يعني حماية نفسك من الرؤساء. قرر أحد مطوري الشبكات العصبية إنشاء نظام ، عندما اقترب المدير ، قلل على الفور من "النوافذ غير الملائمة" ، مما أخفيها عن الأنظار.بالنسبة للمستخدم ، تبدو إجراءات النظام شفافة تمامًا ، لأن الشبكة العصبية بعد اكتشاف رئيس يقترب يعطي إخطارًا مقابلًا. وعندها فقط يقلل من النوافذ ، ويحذر آخر. يعمل النظام نفسه على حقيقة أنه بمساعدة كاميرا الويب العادية ذات الجودة العالية ، فإنه يلتقط وجوه الأشخاص الذين يقتربون من سطح المكتب ، وعندما يتم تحديد الرؤساء ، فإنه يزيل كل شيء بسرعة من شاشة الكمبيوتر ، بعيدًا عن الخطيئة. في التطوير ، تم استخدام مكتبة Keras ، مما سهل المهمة. كيف يعمل كل ذلك؟نعم ، لا شيء معقد بشكل خاص ، المطور لم يتلق أي مشاكل خاصة في تنفيذ النظام. بالمناسبة ، كان أحد الشروط عند إنشاء مثل هذا النظام هو تعليم الشبكة العصبية للتعرف على وجه الرئيس من 5-7 أمتار ، حتى لا تقلق بشأن قدرة الرئيس على رؤية كل شيء من مسافة قريبة. ليس هناك الكثير من الوقت لتحديد الرئيس - فقط حوالي 4-5 ثواني.بالطبع ، لا يوجد شيء جيد في العمل خارج العمل. هذا المثال هو مجرد نظام عمل ، تم إجراؤه ، بدلاً من ذلك من أجل المتعة ، وليس بسبب بعض المشاكل الحقيقية من قبل السلطات.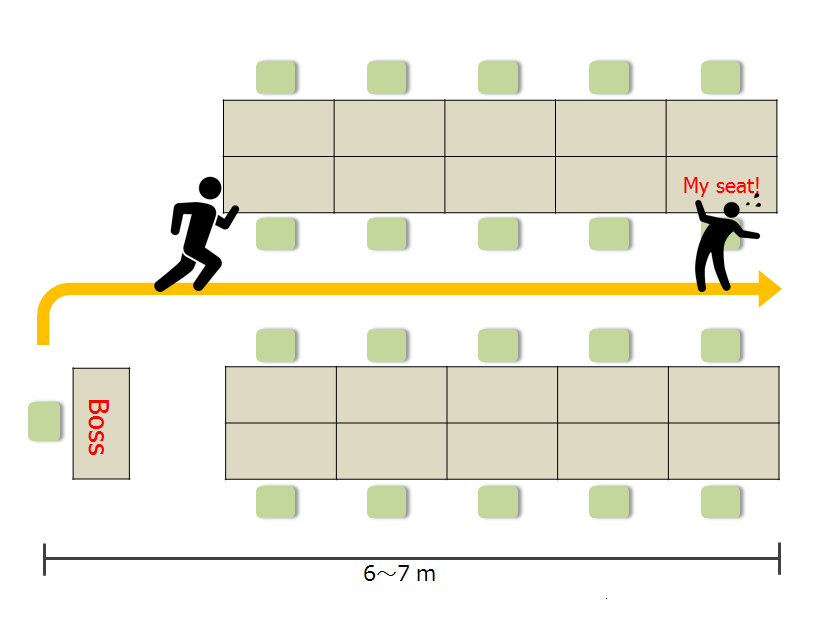 لذا ، قرر المطور تصوير كل ما يحدث حوله باستمرار ، من أجل ملاحظة الرئيس في الوقت المحدد. نظام الكشف يسمى مستشعر بوس.
لذا ، قرر المطور تصوير كل ما يحدث حوله باستمرار ، من أجل ملاحظة الرئيس في الوقت المحدد. نظام الكشف يسمى مستشعر بوس.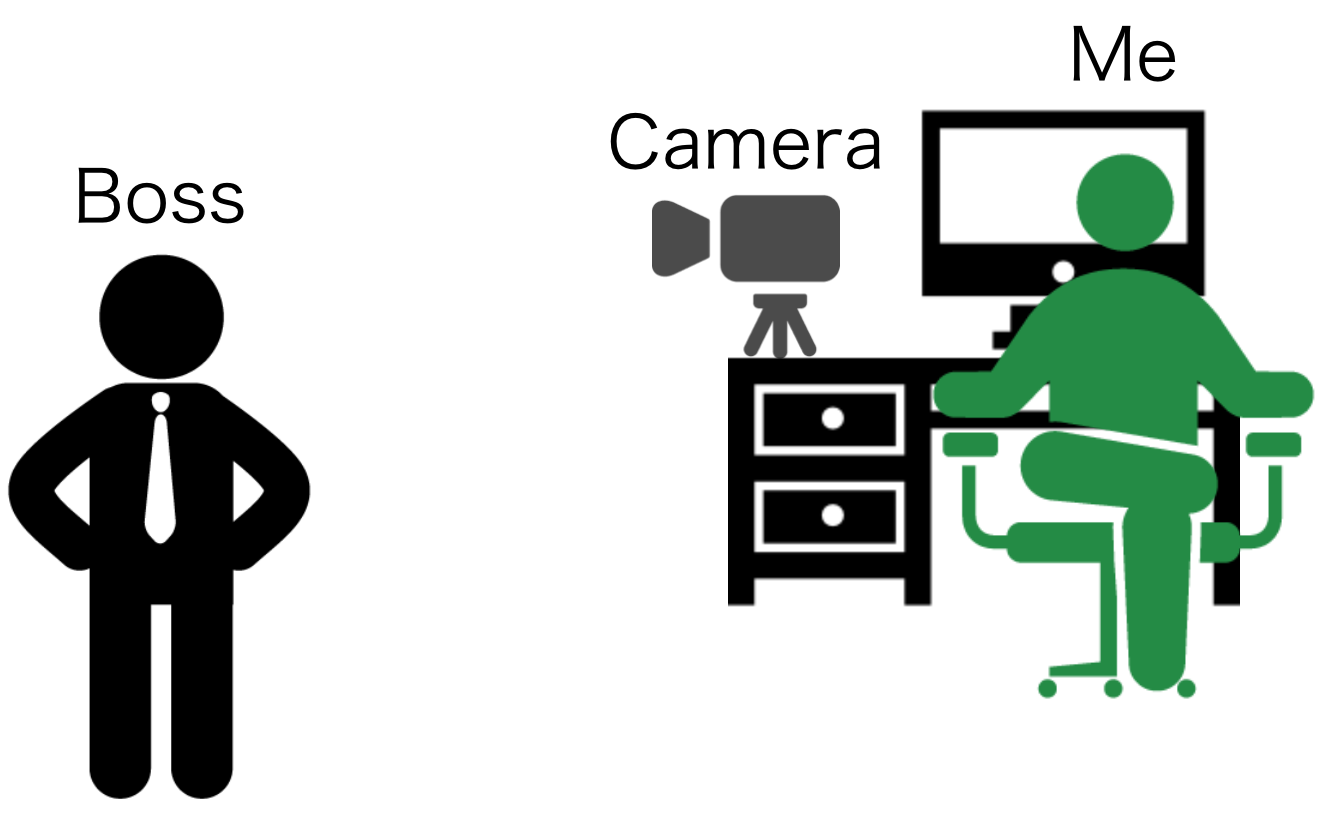 النظام بسيط:أي بالمعنى الحرفي للكلمة ، تحتاج إلى: الحصول على صور للوجه ، والتعرف على ، وتبديل الشاشات ، مما يسمح لك بإخفاء النوافذ المفتوحة من أحد أجهزة الكمبيوتر المكتبية.قرر المطور عدم التفلسف بشكل مؤذ ، ولكن استخدام كاميرا Buffalo BSW20KM11BK القياسية.
النظام بسيط:أي بالمعنى الحرفي للكلمة ، تحتاج إلى: الحصول على صور للوجه ، والتعرف على ، وتبديل الشاشات ، مما يسمح لك بإخفاء النوافذ المفتوحة من أحد أجهزة الكمبيوتر المكتبية.قرر المطور عدم التفلسف بشكل مؤذ ، ولكن استخدام كاميرا Buffalo BSW20KM11BK القياسية. بالطبع ، يمكنك إنشاء صورة بنفسك باستخدام البرنامج. ولكن من الأفضل الوثوق بالنظام - استمر العمل عليه لفترة طويلة ، بالإضافة إلى ذلك ، يعمل النظام بدقة تامة. فيما يتعلق بالحصول على الصور ، يقدم المطور الجميع للتعرف على المصدر .بالنسبة للتدريب ، كل شيء بسيط نسبيًا هنا - توجد أنظمة مماثلة لبعض الوقت. لتحقيق الهدف ، تحتاج إلى تنفيذ ثلاث خطوات:
بالطبع ، يمكنك إنشاء صورة بنفسك باستخدام البرنامج. ولكن من الأفضل الوثوق بالنظام - استمر العمل عليه لفترة طويلة ، بالإضافة إلى ذلك ، يعمل النظام بدقة تامة. فيما يتعلق بالحصول على الصور ، يقدم المطور الجميع للتعرف على المصدر .بالنسبة للتدريب ، كل شيء بسيط نسبيًا هنا - توجد أنظمة مماثلة لبعض الوقت. لتحقيق الهدف ، تحتاج إلى تنفيذ ثلاث خطوات:- جمع الصور ؛
- صور ما قبل المعالجة ؛
- إنشاء نظام التعلم الذاتي.
تنفيذ الأفكار
جمع الصور. من أجل أن يكون للشبكات العصبية شيء لتتدرب عليه ، استخدم مبدعو النظام آلاف الصور. يمكن أخذها ، سواء من المجموعات الخاصة ، أو من حزم أخرى من المستخدمين الآخرين. للدراسة الذاتية للنظام ، تحتاج إلى عدد كبير من اللقطات. قرروا أن يأخذوا من:- صورة جوجل
- مجموعات صور الفيسبوك
- ملفات الفيديو الأساسية.
في البداية ، تلقى المطور آلاف الصور ذات الوجوه المختلفة ، لكن نظامه لم يكن قادرًا على التعلم الذاتي بناءً على الصور. تم استخدام مكتبة ImageMagick لاستخراج الوجوه من عدد كبير من الصور الفوتوغرافية .والنتيجة هي قاعدة البيانات هذه لوجوه الموظفين والمدير نفسه: إذا كنت تريد التعرف على وجه الشخص ، فمن الأفضل تجربة واجهة برمجة تطبيقات الويب ، للحصول على صورة - أداة مثل Computer Vision API في Cognitive Services. قرر المطور أن يسير بطريقته الخاصة. كان للشبكة العصبية التي أنشأها بنية معينة:
إذا كنت تريد التعرف على وجه الشخص ، فمن الأفضل تجربة واجهة برمجة تطبيقات الويب ، للحصول على صورة - أداة مثل Computer Vision API في Cognitive Services. قرر المطور أن يسير بطريقته الخاصة. كان للشبكة العصبية التي أنشأها بنية معينة:هيكل البرنامج____________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
====================================================================================================
convolution2d_1 (Convolution2D) (None, 32, 64, 64) 896 convolution2d_input_1[0][0]
____________________________________________________________________________________________________
activation_1 (Activation) (None, 32, 64, 64) 0 convolution2d_1[0][0]
____________________________________________________________________________________________________
convolution2d_2 (Convolution2D) (None, 32, 62, 62) 9248 activation_1[0][0]
____________________________________________________________________________________________________
activation_2 (Activation) (None, 32, 62, 62) 0 convolution2d_2[0][0]
____________________________________________________________________________________________________
maxpooling2d_1 (MaxPooling2D) (None, 32, 31, 31) 0 activation_2[0][0]
____________________________________________________________________________________________________
dropout_1 (Dropout) (None, 32, 31, 31) 0 maxpooling2d_1[0][0]
____________________________________________________________________________________________________
convolution2d_3 (Convolution2D) (None, 64, 31, 31) 18496 dropout_1[0][0]
____________________________________________________________________________________________________
activation_3 (Activation) (None, 64, 31, 31) 0 convolution2d_3[0][0]
____________________________________________________________________________________________________
convolution2d_4 (Convolution2D) (None, 64, 29, 29) 36928 activation_3[0][0]
____________________________________________________________________________________________________
activation_4 (Activation) (None, 64, 29, 29) 0 convolution2d_4[0][0]
____________________________________________________________________________________________________
maxpooling2d_2 (MaxPooling2D) (None, 64, 14, 14) 0 activation_4[0][0]
____________________________________________________________________________________________________
dropout_2 (Dropout) (None, 64, 14, 14) 0 maxpooling2d_2[0][0]
____________________________________________________________________________________________________
flatten_1 (Flatten) (None, 12544) 0 dropout_2[0][0]
____________________________________________________________________________________________________
dense_1 (Dense) (None, 512) 6423040 flatten_1[0][0]
____________________________________________________________________________________________________
activation_5 (Activation) (None, 512) 0 dense_1[0][0]
____________________________________________________________________________________________________
dropout_3 (Dropout) (None, 512) 0 activation_5[0][0]
____________________________________________________________________________________________________
dense_2 (Dense) (None, 2) 1026 dropout_3[0][0]
____________________________________________________________________________________________________
activation_6 (Activation) (None, 2) 0 dense_2[0][0]
====================================================================================================
Total params: 6489634
يمكن العثور على الرمز هنا . يقول المطور أن النظام بدأ يتعرف على الرئيس بشكل لا لبس فيه عندما يظهر بالقرب من الكاميرا.حسنًا ، تحتاج الآن إلى وضع تعليمات واضحة حول هذه النقطة ، إذا ظهر الشيف بعد ذلك. الآن كل شيء جاهز ، وقد تم اختبار التكنولوجيا عدة مرات. يمكنك الآن بدء تشغيل النظام ، وجعله يستجيب للمدرب.بعد الاختبار ، تبين أن كل شيء قابل للتطبيق. على بعد أمتار قليلة من الكاميرا ، ظل المدير ينابيع وهادئة. أخذ النظام جميع الصور اللازمة ، وأجرى تحليلاً وتمكن من تحديد رئيس المطور بشكل صحيح. أظهر الاختبار شيئًا واحدًا - كل شيء يعمل.يمكن العثور على الكود المصدر لهذا النظام على هذا الرابط .حدد نظام تحديد الهوية أولاً أن هناك رئيسًا حقًا ، ثم تمكنت من التعرف على الصورة و ... نعم ، قلل جميع النوافذ. في الوقت الحالي ، يستخدم اكتشاف الوجه OpenCV. ربما سيحسن Dlib دقة التعرف.هناك بالطبع مشروعات أكثر جدية ، حيث يعدون ، على سبيل المثال ، أنظمة الرؤية الآلية التي تعلم ألعاب الكمبيوتر . أصبحت الشبكات العصبية أكثر شيوعًا - يعمل معها مطورو السيارات والعلماء ومبدعو الأنظمة الآلية وغيرهم من المتخصصين.
الآن كل شيء جاهز ، وقد تم اختبار التكنولوجيا عدة مرات. يمكنك الآن بدء تشغيل النظام ، وجعله يستجيب للمدرب.بعد الاختبار ، تبين أن كل شيء قابل للتطبيق. على بعد أمتار قليلة من الكاميرا ، ظل المدير ينابيع وهادئة. أخذ النظام جميع الصور اللازمة ، وأجرى تحليلاً وتمكن من تحديد رئيس المطور بشكل صحيح. أظهر الاختبار شيئًا واحدًا - كل شيء يعمل.يمكن العثور على الكود المصدر لهذا النظام على هذا الرابط .حدد نظام تحديد الهوية أولاً أن هناك رئيسًا حقًا ، ثم تمكنت من التعرف على الصورة و ... نعم ، قلل جميع النوافذ. في الوقت الحالي ، يستخدم اكتشاف الوجه OpenCV. ربما سيحسن Dlib دقة التعرف.هناك بالطبع مشروعات أكثر جدية ، حيث يعدون ، على سبيل المثال ، أنظمة الرؤية الآلية التي تعلم ألعاب الكمبيوتر . أصبحت الشبكات العصبية أكثر شيوعًا - يعمل معها مطورو السيارات والعلماء ومبدعو الأنظمة الآلية وغيرهم من المتخصصين.