
اليوم ، يعد الرسم البياني أحد أكثر الطرق المقبولة لوصف النماذج التي تم إنشاؤها في نظام التعلم الآلي. تتكون هذه الرسوم البيانية الحسابية من رؤوس عصبية متصلة بحواف متشابكة تصف الروابط بين القمم.
على عكس معالج الرسومات المركزية أو المتجهية ، يتيح لك IPU - وهو نوع جديد من المعالج مصمم للتعلم الآلي ، إنشاء مثل هذه الرسوم البيانية. يعد الكمبيوتر المصمم لإدارة الرسم البياني جهازًا مثاليًا لنماذج الرسم البياني الحسابي التي تم إنشاؤها كجزء من التعلم الآلي.
واحدة من أسهل الطرق لوصف آلية عمل الذكاء الآلي هي تصورها. أنشأ فريق تطوير Graphcore مجموعة من هذه الصور المعروضة على IPU. كان الأساس هو برنامج Poplar ، الذي يتصور عمل الذكاء الاصطناعي. اكتشف باحثون من هذه الشركة أيضًا لماذا تتطلب الشبكات العميقة الكثير من الذاكرة ، وما هي الحلول الموجودة.
يتضمن Poplar مترجمًا رسوميًا تم إنشاؤه من الصفر لترجمة العمليات القياسية المستخدمة كجزء من التعلم الآلي إلى رمز تطبيق محسن للغاية لوحدات معالجة البرامج. يسمح لك بجمع هذه الرسوم البيانية معًا على نفس المبدأ الذي يتم تجميع شبكات POPNN فيه. تحتوي المكتبة على مجموعة من الأنواع المختلفة من القمم للبدائيين المعممين.
الرسوم البيانية هي النموذج الذي تستند إليه جميع البرامج. في Poplar ، تسمح لك الرسوم البيانية بتعريف عملية الحساب ، حيث تقوم القمم بالعمليات والحواف تصف العلاقة بينهما. على سبيل المثال ، إذا كنت ترغب في إضافة رقمين معًا ، يمكنك تحديد قمة مع إدخالين (الأرقام التي ترغب في إضافتها) ، وبعض الحسابات (وظيفة إضافة رقمين) والمخرجات (النتيجة).
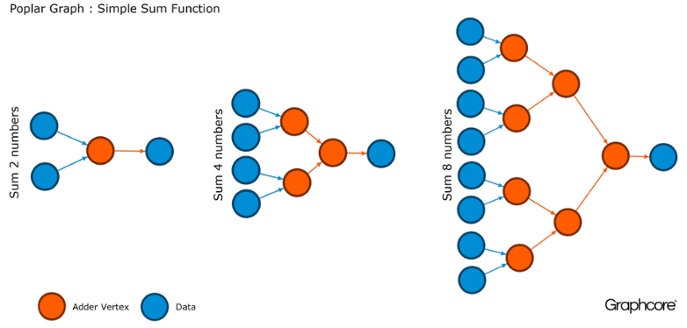
عادة ، تكون عمليات قمة الرأس أكثر تعقيدًا بكثير من المثال الموضح أعلاه. غالبًا ما يتم تعريفها بواسطة برامج صغيرة تسمى codelets (أسماء الرموز). تجريد الرسم جذاب لأنه لا يضع أي افتراضات حول بنية الحسابات ويقسم الحساب إلى مكونات يمكن لمعالج IPU استخدامها للعمل.
يستخدم Poplar هذا التجريد البسيط لإنشاء رسوم بيانية كبيرة جدًا يتم تمثيلها كصور. يعني الإنشاء البرمجي للرسم البياني أنه يمكننا تكييفه مع الحسابات المحددة اللازمة لضمان الاستخدام الأكثر فعالية لموارد الاتحاد البرلماني الدولي.
يترجم المترجم العمليات القياسية المستخدمة في أنظمة التعلم الآلي إلى رمز تطبيق محسن للغاية لوحدات معالجة البرامج. يقوم مترجم الرسم البياني بإنشاء صورة وسيطة للرسم البياني الحسابي الذي يتم نشره على واحد أو أكثر من أجهزة IPU. يمكن للمترجم عرض هذا الرسم البياني الحسابي ، لذلك يعرض التطبيق المكتوب على مستوى بنية الشبكة العصبية صورة للرسم البياني الحسابي الذي يعمل على IPU.
 الرسم البياني للتعلم AlexNet دورة كاملة للأمام والخلف
الرسم البياني للتعلم AlexNet دورة كاملة للأمام والخلفقام مترجم الرسم البياني Poplar بتحويل وصف
AlexNet إلى رسم بياني
حاسوبي يحتوي على 18.7 مليون رأس و 115.8 مليون حافة. إن التكتل المرئي بوضوح هو نتيجة لاتصال قوي بين العمليات في كل طبقة من طبقات الشبكة مع اتصال أسهل بين المستويات.
مثال آخر هو شبكة بسيطة ذات اتصال كامل ، تم تدريبها في
MNIST - مجموعة بيانات بسيطة لرؤية الكمبيوتر ، وهي نوع من "Hello، world" في التعلم الآلي. تساعد شبكة بسيطة لاستكشاف مجموعة البيانات هذه على فهم الرسوم البيانية التي تتحكم فيها تطبيقات Poplar. من خلال دمج مكتبات الرسوم البيانية مع بيئات مثل TensorFlow ، توفر الشركة إحدى أسهل الطرق لاستخدام وحدات IPU في تطبيقات التعلم الآلي.
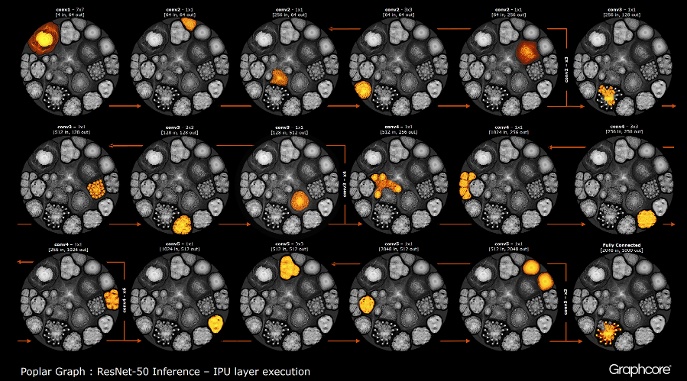
بعد بناء الرسم البياني باستخدام المترجم ، يجب تنفيذه. هذا ممكن باستخدام محرك الرسوم البيانية. باستخدام ResNet-50 كمثال ، يتم توضيح عملها.
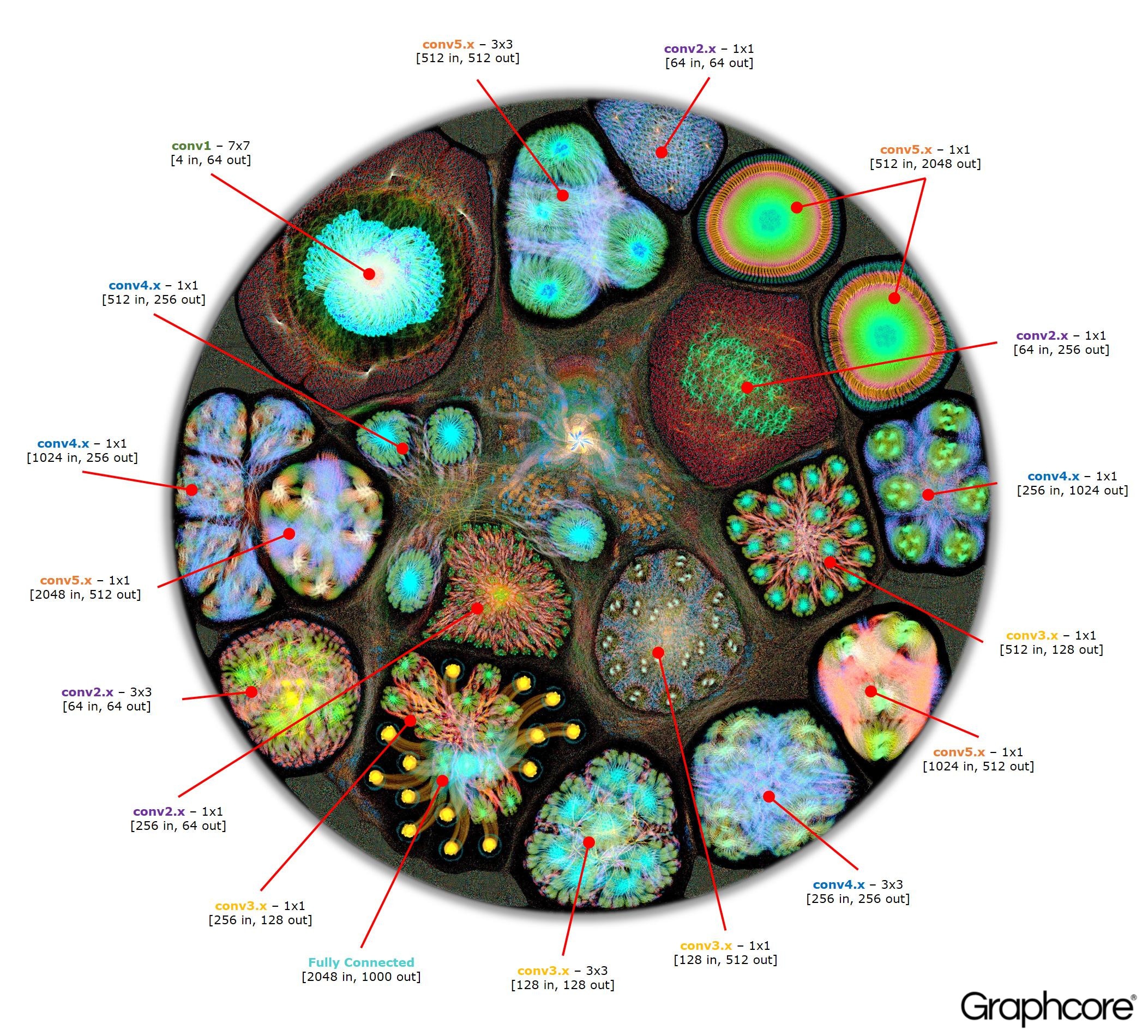
 العد ResNet-50
العد ResNet-50تتيح لك بنية ResNet-50 إنشاء شبكات عميقة من تكرار الأقسام. يحتاج المعالج إلى تحديد هذه الأقسام مرة واحدة فقط وإعادة الاتصال بها. على سبيل المثال ، يتم تنفيذ كتلة مستوى conv4 ست مرات ، ولكن يتم تطبيقها مرة واحدة فقط على الرسم البياني. توضح الصورة أيضًا مجموعة متنوعة من أشكال الطبقات التلافيفية ، حيث أن لكل منها رسمًا بيانيًا يتم إنشاؤه وفقًا للشكل الطبيعي للحساب.
يقوم المحرك بإنشاء والتحكم في تنفيذ نموذج التعلم الآلي باستخدام رسم بياني تم إنشاؤه بواسطة المترجم. بمجرد نشره ، يراقب Graph Engine ويستجيب لوحدات IPU أو الأجهزة التي تستخدمها التطبيقات.
يظهر Image ResNet-50 النموذج بأكمله. في هذا المستوى ، من الصعب التمييز بين القمم الفردية ، لذا يجدر النظر إلى الصور المكبرة. فيما يلي بعض الأمثلة للأقسام داخل طبقات الشبكة العصبية.


لماذا تحتاج الشبكات العميقة إلى الكثير من الذاكرة؟
تعد الكميات الكبيرة من الذاكرة المشغولة واحدة من أكبر مشكلات الشبكات العصبية العميقة. يحاول الباحثون التعامل مع النطاق الترددي المحدود لأجهزة DRAM ، والتي يجب أن تستخدمها الأنظمة الحديثة لتخزين عدد كبير من الأوزان والتنشيط في شبكة عصبية عميقة.
تم تطوير البنيات باستخدام رقائق المعالج المصممة للمعالجة التسلسلية وتحسين الذاكرة العشوائية للذاكرة عالية الكثافة. الواجهة بين الجهازين هي عنق الزجاجة الذي يقدم قيود النطاق الترددي ويضيف عبئا كبيرا لاستهلاك الطاقة.
على الرغم من أننا ما زلنا لا نمتلك صورة كاملة للدماغ البشري وكيف يعمل ، فمن الواضح بشكل عام أنه لا يوجد مرفق تخزين كبير منفصل للذاكرة. ويعتقد أن وظيفة الذاكرة طويلة المدى وقصيرة المدى في دماغ الإنسان جزء لا يتجزأ من بنية الخلايا العصبية + المشابك. حتى الكائنات الحية البسيطة مثل
الديدان ذات البنية العصبية للدماغ ، والتي تتكون من ما يزيد قليلاً عن 300 خلية عصبية ،
لديها درجة من وظيفة الذاكرة.
يعد بناء الذاكرة في المعالجات التقليدية إحدى الطرق للتغلب على اختناقات الذاكرة من خلال فتح نطاق ترددي ضخم مع استهلاك طاقة أقل بكثير. ومع ذلك ، تعد الذاكرة الموجودة على الشريحة أمرًا باهظًا وغير مصمم لكميات كبيرة جدًا من الذاكرة ، والتي ترتبط بالمعالجات المركزية والرسومات المستخدمة حاليًا لإعداد الشبكات العصبية العميقة ونشرها.
لذلك ، من المفيد إلقاء نظرة على كيفية استخدام الذاكرة اليوم في وحدات المعالجة المركزية وأنظمة التعلم العميق على مسرعات الرسومات والسؤال عن نفسك: لماذا يحتاجون إلى مثل هذه أجهزة تخزين الذاكرة الكبيرة عندما يعمل الدماغ البشري بشكل جيد بدونها؟
تحتاج الشبكات العصبية إلى ذاكرة لتخزين بيانات الإدخال ومعلمات الوزن ووظائف التنشيط ، حيث يتم توزيع الإدخال عبر الشبكة. في التدريب ، يجب الحفاظ على التنشيط عند الإدخال حتى يمكن استخدامه لحساب أخطاء التدرجات عند الإخراج.
على سبيل المثال ، تحتوي شبكة ResNet المكونة من 50 طبقة على حوالي 26 مليون معلمة ترجيح وتحسب 16 مليون تنشيط أمامي. إذا كنت تستخدم رقم فاصلة عائمة 32 بت لتخزين كل وزن وتنشيط ، فإن هذا سيتطلب حوالي 168 ميغابايت من المساحة. باستخدام قيمة دقة أقل لتخزين هذه المقاييس والتنشيطات ، يمكننا تخفيض متطلبات التخزين هذه إلى النصف أو حتى أربعة أضعاف.
تنشأ مشكلة خطيرة في الذاكرة من حقيقة أن وحدات معالجة الرسومات تعتمد على البيانات الممثلة كناقلات كثيفة. لذلك ، يمكنهم استخدام دفق تعليمي واحد (SIMD) لتحقيق حوسبة عالية الكثافة. يستخدم المعالج المركزي كتل متجهة مماثلة للحوسبة عالية الأداء.
في GPUs ، يكون المشبك بعرض 1024 بت ، لذا يستخدمون بيانات النقطة العائمة 32 بت ، لذلك غالبًا ما يقومون بتقسيمها إلى دفعة صغيرة متوازية من 32 عينة لإنشاء ناقلات بيانات 1024 بت. يزيد هذا النهج لتنظيم موازاة المتجهات من عدد التنشيطات 32 مرة والحاجة إلى التخزين المحلي بسعة تزيد عن 2 جيجابايت.
وحدات معالجة الرسوميات (GPUs) والآلات الأخرى المصممة لجبر المصفوفة تخضع أيضًا لحمل الذاكرة من الأوزان أو تنشيط الشبكة العصبية. لا يمكن لوحدات معالجة الرسومات أداء تلافيف صغيرة بكفاءة تُستخدم في الشبكات العصبية العميقة. لذلك ، يتم استخدام تحويل يسمى "الرجوع إلى إصدار أقدم" لتحويل هذه اللفات إلى مضاعفات مصفوفة مصفوفة (GEMMs) ، والتي يمكن لمسرعات الرسومات التعامل معها بشكل فعال.
مطلوب ذاكرة إضافية أيضًا لتخزين بيانات الإدخال وقيم الوقت وإرشادات البرنامج. أظهر قياس استخدام الذاكرة عند تدريب ResNet-50 على وحدة معالجة رسومات عالية الأداء أنها تتطلب أكثر من 7.5 جيجابايت من الذاكرة العشوائية المحلية.
ربما يقرر شخص ما أن الدقة الأقل يمكن أن تقلل من حجم الذاكرة المطلوبة ، ولكن هذا ليس هو الحال. عندما تقوم بتبديل قيم البيانات إلى نصف الدقة للأوزان والتنشيطات ، فإنك تملأ نصف عرض المتجه فقط في بطاقة SIMD ، وتنفق نصف موارد الحوسبة المتاحة. للتعويض عن ذلك ، عند التبديل من الدقة الكاملة إلى نصف الدقة على وحدة معالجة الرسومات ، سيتعين عليك مضاعفة حجم الدفعة المصغرة لإحداث توازي بيانات كافٍ لاستخدام جميع الحسابات المتاحة. وبالتالي ، لا يزال الانتقال إلى مقاييس الدقة والتنشيط الأقل على وحدة معالجة الرسومات يتطلب أكثر من 7.5 جيجابايت من الذاكرة الديناميكية مع وصول مجاني.
مع وجود الكثير من البيانات ليتم تخزينها ، من المستحيل ببساطة احتواء كل هذا في GPU. في كل طبقة من الشبكة العصبية التلافيفية ، من الضروري حفظ حالة DRAM الخارجية ، وتحميل طبقة الشبكة التالية ثم تحميل البيانات في النظام. ونتيجة لذلك ، تعاني واجهة الذاكرة الخارجية ، التي كانت محدودة بالفعل من عرض النطاق الترددي للذاكرة ، من العبء الإضافي المتمثل في إعادة تحميل الرصيد باستمرار ، بالإضافة إلى حفظ واستعادة وظائف التنشيط. هذا يبطئ وقت التدريب بشكل ملحوظ ويزيد من استهلاك الطاقة بشكل ملحوظ.
هناك العديد من الحلول لهذه المشكلة. أولاً ، يمكن تنفيذ عمليات مثل وظائف التنشيط "على الفور" ، مما يسمح لك بالكتابة فوق الإدخال مباشرة إلى الإخراج. وبالتالي ، يمكن إعادة استخدام الذاكرة الموجودة. ثانيًا ، يمكن الحصول على فرصة إعادة استخدام الذاكرة من خلال تحليل اعتماد البيانات بين العمليات على الشبكة وتوزيع نفس الذاكرة للعمليات التي لا تستخدمها في الوقت الحالي.
النهج الثاني فعال بشكل خاص عندما يمكن تحليل الشبكة العصبية بأكملها في مرحلة التجميع من أجل إنشاء ذاكرة مخصصة ثابتة ، حيث يتم تقليل تكاليف إدارة الذاكرة إلى الصفر تقريبًا. اتضح أن مجموعة من هذه الأساليب تقلل من استخدام الذاكرة للشبكة العصبية مرتين إلى ثلاث مرات.
تم اكتشاف نهج ثالث مهم مؤخرًا بواسطة فريق Baidu Deep Speech. قاموا بتطبيق طرق مختلفة لتوفير الذاكرة للحصول على انخفاض 16 ضعفًا في استهلاك الذاكرة من خلال وظائف التنشيط ، مما سمح لهم بتدريب الشبكات مع 100 طبقة. في السابق ، وبنفس المقدار من الذاكرة ، كان بإمكانهم تدريب شبكات من تسع طبقات.
إن الجمع بين الذاكرة وموارد المعالجة في جهاز واحد له إمكانات كبيرة لزيادة إنتاجية وكفاءة الشبكات العصبية التلافيفية ، بالإضافة إلى أشكال أخرى من التعلم الآلي. يمكنك إجراء حل وسط بين الذاكرة وموارد الحوسبة من أجل تحقيق التوازن بين قدرات وأداء النظام.
يمكن اعتبار الشبكات العصبية ونماذج المعرفة في طرق التعلم الآلي الأخرى رسومًا بيانية رياضية. في هذه الرسوم البيانية ، تتركز كمية كبيرة من التوازي. لا يعتمد المعالج الموازي المصمم لاستخدام التزامن في الرسوم البيانية على مجموعة صغيرة ويمكن أن يقلل بشكل كبير من كمية التخزين المحلي المطلوب.
وقد أظهرت نتائج البحث الحديثة أن كل هذه الأساليب يمكن أن تحسن بشكل كبير من أداء الشبكات العصبية. تحتوي الرسومات الحديثة ووحدات المعالجة المركزية على ذاكرة داخلية محدودة للغاية ، في المجمل فقط عدد قليل من الميغابايت. توفر بنيات المعالج الجديدة المصممة خصيصًا للتعلم الآلي التوازن بين الذاكرة والحوسبة على الشريحة ، مما يوفر زيادة كبيرة في الأداء والكفاءة مقارنة بوحدات المعالجة المركزية الحديثة ومسرعات الرسومات.