
قبل أربع سنوات ، أدركت Google الإمكانات الحقيقية لاستخدام الشبكات العصبية في تطبيقاتها. ثم بدأت في تقديمها في كل مكان - في ترجمة النصوص والبحث الصوتي مع التعرف على الكلام وما إلى ذلك. ولكن أصبح من الواضح على الفور أن استخدام الشبكات العصبية يزيد الحمل بشكل كبير على خوادم Google. بشكل تقريبي ، إذا أجرى الجميع بحثًا صوتيًا على Android (أو نص إملاء مع التعرف على الكلام) لمدة ثلاث دقائق فقط في اليوم ، فسيتعين على Google مضاعفة عدد مراكز البيانات (!) فقط حتى تتمكن الشبكات العصبية من معالجة مثل هذه الكمية من حركة الصوت.
شيء ما يجب القيام به - ووجدت Google حلاً. في عام 2015 ، قامت بتطوير هندسة الأجهزة الخاصة بها للتعلم الآلي (وحدة معالجة Tensor ، TPU) ، وهي أسرع حتى 70 مرة من وحدات معالجة الرسومات ووحدات المعالجة المركزية التقليدية من حيث الأداء وما يصل إلى 196 مرة من حيث عدد الحسابات لكل واط. تشير وحدات معالجة الرسومات / وحدات المعالجة المركزية التقليدية إلى معالجات الأغراض العامة Xeon E5 v3 (Haswell) و Nvidia Tesla K80.
تم وصف هندسة TPU لأول مرة هذا الأسبوع في
ورقة علمية (pdf) سيتم تقديمها في الندوة الدولية الرابعة والأربعين حول معماريات الكمبيوتر (ISCA) ، 26 يونيو 2017 في تورنتو. شرح أحد المؤلفين الرائدين لأكثر من 70 مؤلفًا لهذا العمل العلمي ،
وهو مهندس متميز نورمان جوبي ، المعروف باسم أحد مبدعي معالج MIPS ، في
مقابلة مع
The Next Platform ، في كلماته الخاصة ميزات بنية TPU الفريدة ، والتي هي في الواقع ASIC متخصصة ، أي. دارة متكاملة لأغراض خاصة.
على عكس FPGAs التقليدية أو ASICs عالية التخصص ، تتم برمجة وحدات TPU بنفس طريقة وحدة معالجة الرسومات أو وحدة المعالجة المركزية ؛ وهي ليست معدات ضيقة النطاق لشبكة عصبية واحدة. يقول نورمان يوبي أن TPU تدعم تعليمات CISC لأنواع مختلفة من الشبكات العصبية: الشبكات العصبية التلافيفية ، ونماذج LSTM ، والنماذج الكبيرة والمتصلة بالكامل. بحيث تظل قابلة للبرمجة ، تستخدم المصفوفة فقط كبدائية بدائية ، وليس بدائية متجهية أو متدرجة.
تؤكد Google أنه بينما يقوم المطورون الآخرون بتحسين شرائحهم الدقيقة للشبكات العصبية التلافيفية ، فإن هذه الشبكات العصبية توفر 5٪ فقط من الحمل في مراكز بيانات Google. تستخدم غالبية تطبيقات Google
مفهوم Rumelhart متعدد الطبقات ، لذلك كان من المهم جدًا إنشاء بنية أكثر شمولية لم يتم "صقلها" فقط للشبكات العصبية التلافيفية.
 أحد عناصر الهندسة المعمارية هو محرك دفق البيانات الانقباضي ، صفيف 256 × 256 ، الذي يتلقى تنشيط (الأوزان) من الخلايا العصبية على اليسار ، ثم كل شيء يتغير خطوة بخطوة ، مضروبًا في الأوزان في الخلية. اتضح أن المصفوفة الانقباضية تنفذ 65536 حسابات لكل دورة. هذه العمارة مثالية للشبكات العصبية.
أحد عناصر الهندسة المعمارية هو محرك دفق البيانات الانقباضي ، صفيف 256 × 256 ، الذي يتلقى تنشيط (الأوزان) من الخلايا العصبية على اليسار ، ثم كل شيء يتغير خطوة بخطوة ، مضروبًا في الأوزان في الخلية. اتضح أن المصفوفة الانقباضية تنفذ 65536 حسابات لكل دورة. هذه العمارة مثالية للشبكات العصبية.وفقًا لـ Uppy ، فإن بنية TPUs تشبه إلى حد كبير معالج وحدة FPU أكثر من وحدة معالجة الرسومات العادية ، على الرغم من أن العديد من المصفوفات للتكاثر لا تخزن أي برامج في حد ذاتها ، فإنها ببساطة تنفذ التعليمات الواردة من المضيف.
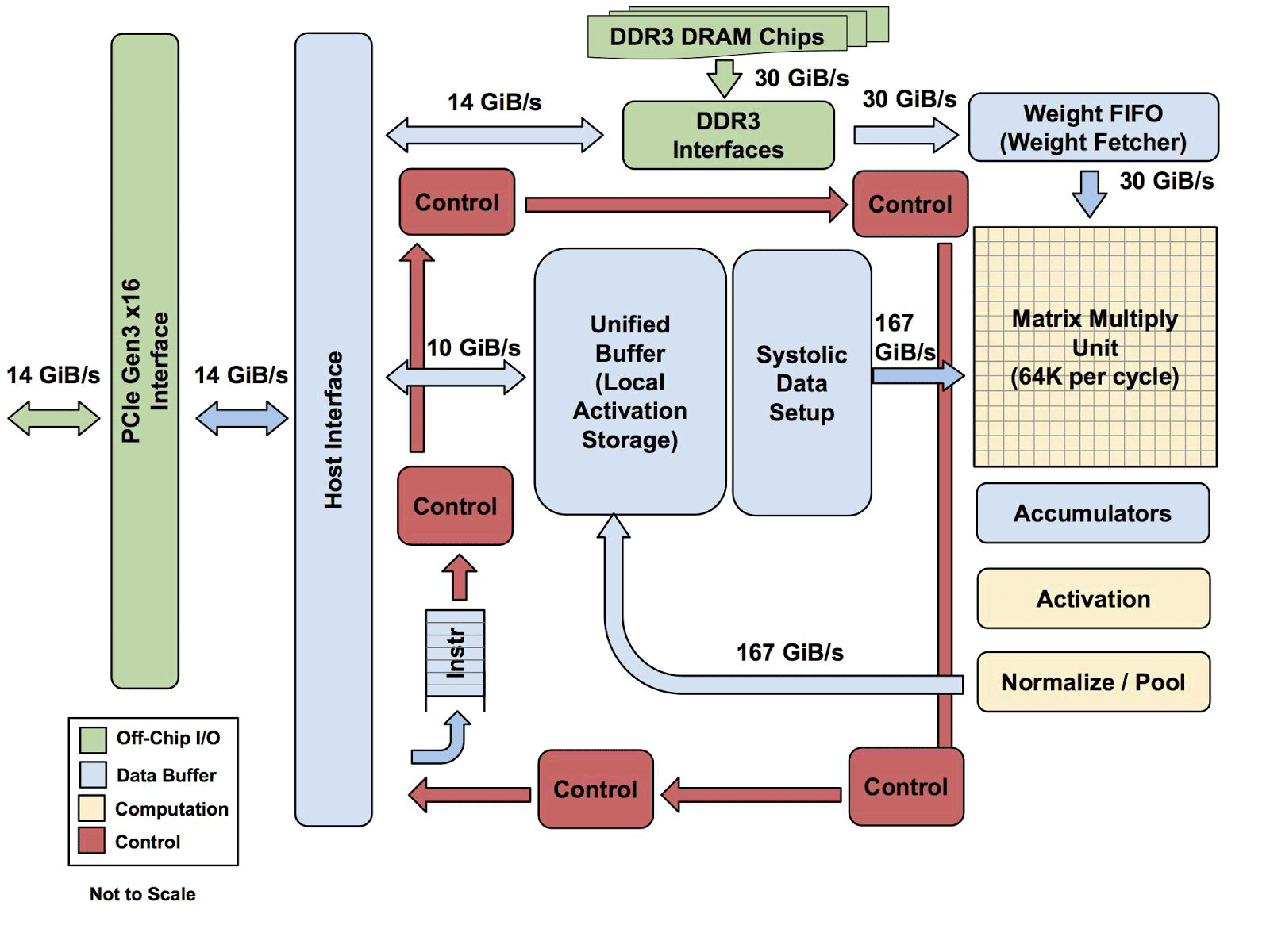 جميع معماريات TPU باستثناء ذاكرة DDR3. يتم إرسال التعليمات من المضيف (يسار) إلى قائمة الانتظار. بعد ذلك ، يمكن لمنطق التحكم ، بناءً على التعليمات ، تشغيل كل واحد منهم بشكل متكرر
جميع معماريات TPU باستثناء ذاكرة DDR3. يتم إرسال التعليمات من المضيف (يسار) إلى قائمة الانتظار. بعد ذلك ، يمكن لمنطق التحكم ، بناءً على التعليمات ، تشغيل كل واحد منهم بشكل متكررولا يُعرف بعد مدى قابلية هذه العمارة للتطوير. يقول Yuppy أنه في نظام مع هذا النوع من المضيف سيكون هناك دائمًا نوع من الاختناق.
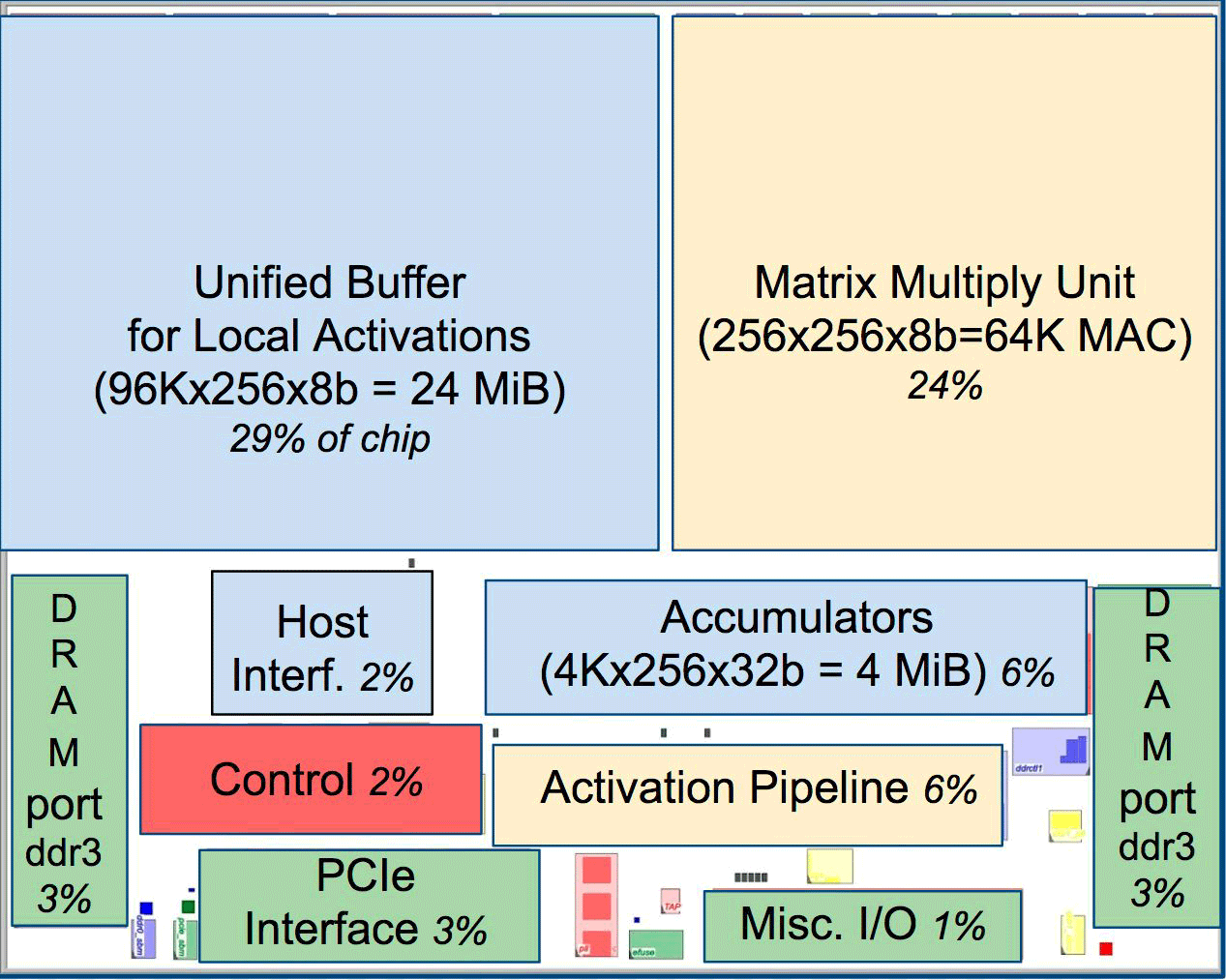
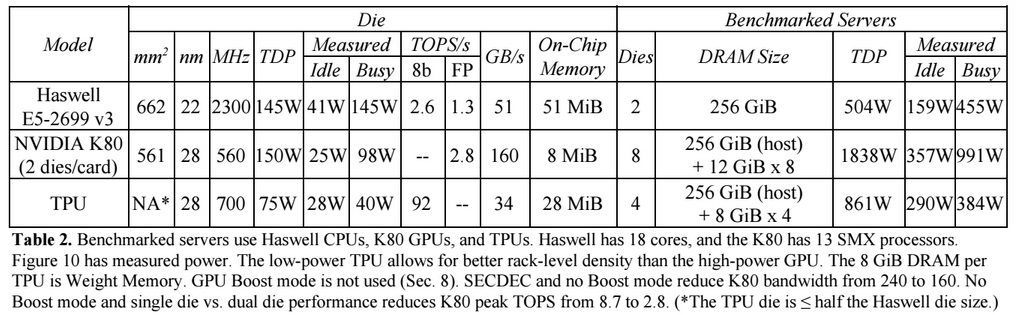
مقارنةً بوحدات المعالجة المركزية ووحدات معالجة الرسومات التقليدية ، تتفوق بنية أجهزة Google على أدائها بعشرة أضعاف. على سبيل المثال ، معالج Haswell Xeon E5-2699 v3 مع 18 نواة بتردد ساعة يبلغ 2.3 جيجاهرتز مع نقطة عائمة 64 بت ينفذ 1.3 تيرا في الثانية (TOPS) ويظهر معدل نقل بيانات يبلغ 51 جيجابايت / ثانية. في هذه الحالة ، تستهلك الشريحة نفسها 145 واط ، والنظام بأكمله عليها بذاكرة 256 جيجابايت - 455 واط.
للمقارنة ، تُظهر TPU على عمليات 8 بت مع 256 جيجا بايت من الذاكرة الخارجية و 32 جيجا بايت من الذاكرة الخاصة بها سرعة نقل تبلغ 34 جيجا بايت / ثانية ، ولكن البطاقة تؤدي 92 TOPS ، أي ما يقرب من 71 مرة أكثر من معالج Haswell. استهلاك طاقة الخادم على TPU 384 واط.
يقارن الرسم البياني التالي الأداء النسبي لكل واط خادم مع GPU (عمود أزرق) ، خادم على TPU (أحمر) نسبة إلى خادم على وحدة المعالجة المركزية. كما يقارن الأداء النسبي لكل واط من الخادم مع TPU بالنسبة للخادم الموجود على GPU (باللون البرتقالي) والإصدار المحسن من TPU بالنسبة للخادم على وحدة المعالجة المركزية (باللون الأخضر) والخادم على GPU (باللون الأرجواني).

تجدر الإشارة إلى أن Google أجرت مقارنات في اختبارات التطبيقات على TensorFlow مع الإصدار القديم النسبي من Haswell Xeon ، بينما في الإصدار الأحدث من Broadwell Xeon E5 v4 ، زاد عدد التعليمات لكل دورة بنسبة 5٪ بسبب التحسينات المعمارية ، وفي إصدار Skylake Xeon E5 v5 ، وهو أمر متوقع في الصيف ، قد يزيد عدد التعليمات لكل دورة بنسبة 9-10٪ أخرى. ومع زيادة عدد النوى من 18 إلى 28 في Skylake ، يمكن أن يتحسن الأداء العام لمعالجات Intel في اختبارات Google بنسبة 80٪. ولكن مع ذلك ، سيكون هناك اختلاف كبير في الأداء مع TPU. في نسخة الاختبار مع النقطة العائمة 32 بت ، يتم تقليل الفرق بين وحدات المعالجة المركزية ووحدات المعالجة المركزية إلى 3.5 مرة تقريبًا. لكن معظم النماذج تصل إلى 8 بت بشكل مثالي.
تفكر Google في كيفية استخدام وحدات معالجة الرسوميات و FPGAs و ASICs في مراكز البيانات منذ عام 2006 ، لكنها لم تعثر عليها حتى وقت قريب ، عندما قدمت التعلم الآلي لعدد من المهام العملية ، وبدأ الحمل على هذه الشبكات العصبية ينمو مع مليارات الطلبات من المستخدمين. الآن ليس أمام الشركة خيار سوى الابتعاد عن وحدات المعالجة المركزية التقليدية.
لا تخطط الشركة لبيع معالجاتها إلى أي شخص ، لكنها تأمل في أن يسمح العمل العلمي مع ASIC 2015 للآخرين بتحسين الهيكل وإنشاء إصدارات محسنة من ASIC "التي سترفع مستوى أعلى." ربما تعمل Google نفسها بالفعل على إصدار جديد من ASIC.