مجرد التفكير ، ما هي قوة الحوسبة الإجمالية لجميع الهواتف الذكية في العالم؟ هذا مورد حاسوبي ضخم يمكنه حتى محاكاة عمل الدماغ البشري. لا يمكن لمثل هذا المورد أن يكون خاملاً ، حيث يحرق بغباء كيلوات من الطاقة بغباء في غرف الدردشة وموجزات وسائل التواصل الاجتماعي. إذا أعطيت موارد الحوسبة هذه لمنظمة العفو الدولية الموزعة في العالم ، بل وزودتها ببيانات من الهواتف الذكية للمستخدم - للتدريب - فإن مثل هذا النظام يمكن أن يحقق قفزة كمية في هذا المجال.
تتطلب طرق التعلم الآلي القياسية جمع مجموعة البيانات الخاصة بتدريب النموذج ("الأساسي") في مكان واحد - على كمبيوتر واحد أو خادم أو في مركز بيانات واحد أو سحابة واحدة. من هنا يتم أخذه بواسطة نموذج تم تدريبه على هذه البيانات. في حالة وجود مجموعة من أجهزة الكمبيوتر في مركز البيانات ، يتم استخدام
طريقة Stochastic Gradient Descent (SGD) - خوارزمية تحسين تعمل باستمرار في أجزاء من مجموعة بيانات موزعة بشكل متجانس عبر الخوادم في السحابة.
تقوم Google و Apple و Facebook و Microsoft وغيرها من لاعبي الذكاء الاصطناعي بذلك منذ فترة طويلة: يجمعون البيانات - السرية أحيانًا - من أجهزة كمبيوتر المستخدمين والهواتف الذكية في وحدة تخزين آمنة واحدة (من المفترض) يتم تدريب شبكاتهم العصبية عليها.
اقترح علماء من Google Research الآن إضافة مثيرة للاهتمام إلى طريقة التعلم الآلي القياسية هذه. اقترحوا نهجًا مبتكرًا يسمى Federated Learning. يسمح لجميع الأجهزة التي تشارك في التعلم الآلي بمشاركة نموذج واحد للتنبؤ ، ولكن
ليس لمشاركة البيانات الأولية لتدريب النموذج !
ربما يقلل هذا النهج غير المعتاد من فعالية التعلم الآلي (على الرغم من أن هذا ليس حقيقة) ، ولكنه يقلل بشكل كبير من تكاليف Google للحفاظ على مراكز البيانات. لماذا تستثمر الشركة مبالغ ضخمة من الأموال في معداتها إذا كان لديها مليارات من أجهزة Android في جميع أنحاء العالم يمكنها مشاركة الحمل؟ يمكن للمستخدمين أن يكونوا سعداء بمثل هذا الحمل ، لأنهم بذلك يساعدون في تقديم خدمات أفضل يستخدمونها هم أنفسهم. وهم يحمون بياناتهم السرية دون إرسالها إلى مركز البيانات.
تؤكد Google أنه في هذه الحالة لا يقتصر الأمر على أن النموذج المدرب بالفعل يتم تنفيذه مباشرة على جهاز المستخدم ، كما هو الحال مع
Mobile Vision API وخدمات
الرد الذكي على الجهاز . لا ، إنه
تدريب نموذجي يتم على الأجهزة النهائية.
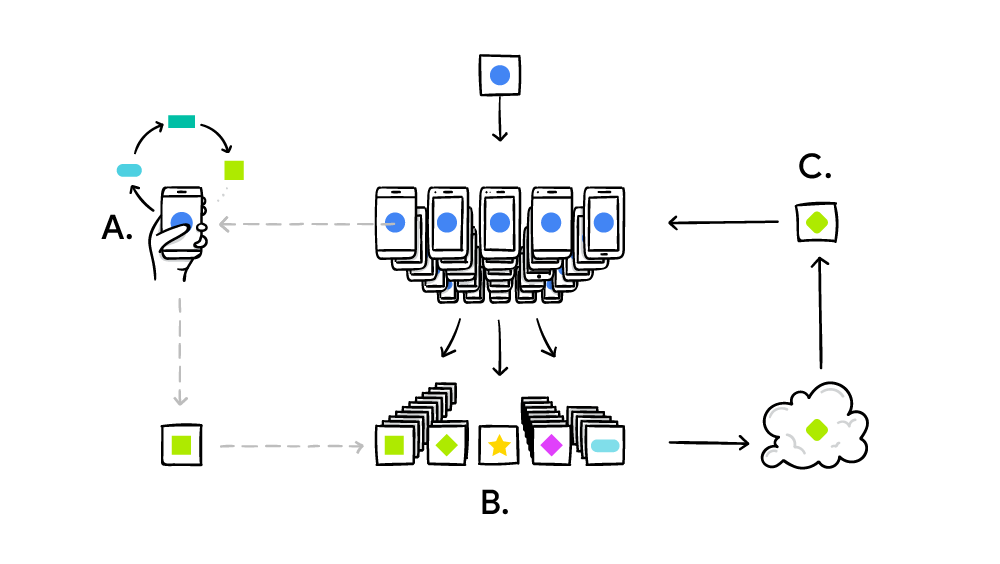
يعمل نظام التعلم الفدرالي وفقًا للمبدأ القياسي للحوسبة الموزعة مثل SETI @ Home ، عندما يحل ملايين أجهزة الكمبيوتر مشكلة معقدة واحدة كبيرة. في حالة SETI @ Home ، كان البحث عن حالات شاذة في الإشارة اللاسلكية من الفضاء عبر الطيف بأكمله. وفي حالة التعلم الآلي المتحد ، تعمل Google على إتقان نموذج واحد مشترك من الذكاء الاصطناعي الضعيف (حتى الآن). من الناحية العملية ، يتم تنفيذ الدورة التدريبية على النحو التالي:
- الهاتف الذكي يقوم بتنزيل النموذج الحالي ؛
- بمساعدة النسخة المصغرة TensorFlow ، ينفذ دورة تدريبية على البيانات الفريدة لمستخدم معين ؛
- يحسن النموذج ؛
- يحسب الفرق بين نماذج المصدر المحسنة ، ويجمع التصحيح باستخدام بروتوكول التشفير التجميع الآمن ، والذي يسمح بفك تشفير البيانات فقط إذا كان هناك مئات أو آلاف التصحيحات من مستخدمين آخرين ؛
- يرسل التصحيح إلى الخادم المركزي ؛
- يتم حساب متوسط التصحيح المعتمد فورًا مع آلاف التصحيحات الواردة من المشاركين الآخرين في التجربة باستخدام خوارزمية المتوسط الموحدة ؛
- إصدار نسخة جديدة من النموذج ؛
- يتم إرسال نموذج محسن إلى المشاركين في التجربة.
يشبه المتوسط المتحد إلى حد كبير طريقة التدرج العشوائي المذكورة أعلاه ، هنا فقط لا تتم الحسابات الأولية على الخوادم في السحابة ، ولكن على ملايين الهواتف الذكية عن بعد. الإنجاز الرئيسي للمتوسط المتحد هو حركة أقل مع العملاء من 10 إلى 100 مرة مقارنة بحركة المرور مع الخوادم باستخدام طريقة التدرج العشوائي. تم تحقيق التحسين بسبب
الضغط عالي الجودة للتحديثات التي يتم إرسالها من الهواتف الذكية إلى الخادم. حسنًا ، زائد هنا هو بروتوكول تشفير التجميع الآمن.
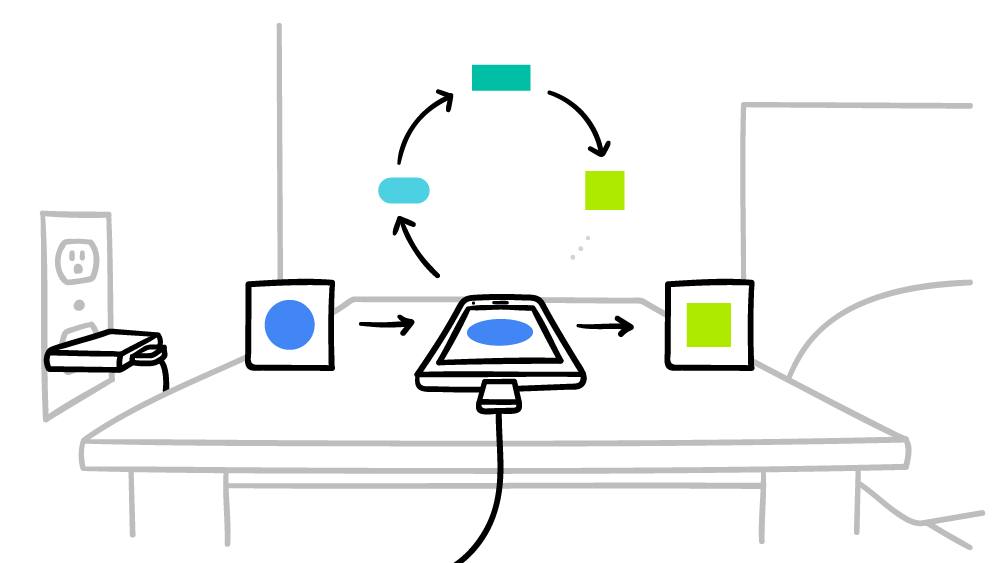
تتعهد Google بأن الهاتف الذكي لن يجري سوى حسابات لنظام الذكاء الاصطناعي العالمي الموزع في أوقات التعطل ، بحيث لا يؤثر ذلك على الأداء بأي شكل من الأشكال. علاوة على ذلك ، يمكنك ضبط وقت التشغيل فقط عندما يكون الهاتف الذكي متصلاً بالتيار الكهربائي. وبالتالي ، لن تؤثر هذه الحسابات على عمر البطارية. يتم اختبار التعلم الآلي
المتحد حاليًا على المطالبات السياقية على لوحة مفاتيح Google -
Gboard على Android .
تم وصف خوارزمية حساب المتوسط المتحد بمزيد من التفصيل في الورقة العلمية
التعلم الفعال للتواصل للشبكات العميقة من البيانات اللامركزية ، والتي تم نشرها في 17 فبراير 2016 في arXiv.org (arXiv: 1602.05629).