
في بداية القرن العشرين ، أعلن فيلهلم فون أوستن ، مدرب الخيول وعالم الرياضيات الألماني ، للعالم أنه علم حصانًا للعد. لسنوات ، سافر فون أوستن في جميع أنحاء ألمانيا مع عرض لهذه الظاهرة. سأل حصانه ، الملقب ب
كليفر هانز (سلالة
أورلوف تروتر ) ، لحساب نتائج المعادلات البسيطة. أجاب هانز وختم حافره. اثنان زائد اثنين؟ أربع ضربات.
لكن العلماء لم يعتقدوا أن هانز كان ذكيا كما ادعى فون أوستن. أجرى عالم النفس
كارل شتومبف تحقيقًا شاملاً أطلق عليه اسم "لجنة هانز". اكتشف أن Smart Hans لا يحل المعادلات ، ولكنه يستجيب للإشارات المرئية. استغل هانز حافته حتى حصل على الإجابة الصحيحة ، وبعد ذلك اقتحم مدربه وحشد متحمس صرخات. ثم توقف للتو. عندما لم ير ردود الفعل هذه ، واصل الطرق.
يمكن أن يتعلم علوم الكمبيوتر الكثير من هانز. تشير وتيرة التطور المتسارعة في هذا المجال إلى أن معظم الذكاء الاصطناعي الذي أنشأناه قد تدربوا بما يكفي لتقديم الإجابات الصحيحة ، لكنهم لا يفهمون المعلومات حقًا. ومن السهل أن تخدع.
سرعان ما تحولت خوارزميات التعلم الآلي إلى رعاة كلاب القطيع البشري. يربطنا البرنامج بالإنترنت ، ويراقب البريد العشوائي والمحتوى الضار في بريدنا ، وسيقود سياراتنا قريبًا. خداعهم يغير الأساس التكتوني للإنترنت ويهدد أمننا في المستقبل.
تقوم مجموعات بحثية صغيرة - من جامعة ولاية بنسلفانيا ، من Google ، من الجيش الأمريكي - بتطوير خطط للحماية من الهجمات المحتملة على الذكاء الاصطناعي. تقول النظريات التي طرحت في الدراسة إن المهاجم يمكنه تغيير ما "يراه" الروبوت. أو قم بتنشيط التعرف على الصوت على الهاتف وإجباره على الدخول إلى موقع ويب ضار باستخدام الأصوات التي ستكون ضجيجًا للشخص فقط. أو دع الفيروس يتسرب عبر جدار حماية الشبكة.
 على اليسار صورة المبنى ، على اليمين الصورة المعدلة ، والتي تتعلق الشبكة العصبية العميقة بالنعام. في المنتصف ، يتم عرض جميع التغييرات المطبقة على الصورة الأساسية.
على اليسار صورة المبنى ، على اليمين الصورة المعدلة ، والتي تتعلق الشبكة العصبية العميقة بالنعام. في المنتصف ، يتم عرض جميع التغييرات المطبقة على الصورة الأساسية.بدلاً من السيطرة على التحكم في السيارة الآلية ، تُظهر له هذه الطريقة شيئًا مثل الهلوسة - صورة غير موجودة بالفعل.
تستخدم مثل هذه الهجمات صورًا تحتوي على حيلة [أمثلة عدائية - لا يوجد مصطلح روسي ثابت ، حرفيا يتبين شيئًا مثل "أمثلة متباينة" أو "أمثلة منافسة" - تقريبًا. ترجم.]: الصور والأصوات والنص التي تبدو طبيعية بالنسبة للأشخاص ولكن يتم رؤيتها بواسطة جهاز مختلف تمامًا. التغييرات الصغيرة التي قام بها المهاجمون يمكن أن تجعل الشبكة العصبية العميقة تستخلص الاستنتاجات الخاطئة حول ما تظهره.
قال أليكس كانشيليان ، الباحث في جامعة بيركلي الذي يدرس هجمات التعلم الآلي باستخدام الصور المزيفة: "إن أي نظام يستخدم التعلم الآلي لاتخاذ قرارات ذات أهمية أمنية من المحتمل أن يكون عرضة لهذا النوع من الهجمات".
إن معرفة هذه الفروق الدقيقة في المراحل المبكرة من تطور الذكاء الاصطناعي يمنح الباحثين أداة لفهم كيفية تصحيح هذه العيوب. لقد تناول البعض هذا بالفعل ، ويقولون إن خوارزمياتهم أصبحت أكثر كفاءة بسبب هذا.
يعتمد معظم التيار الرئيسي لأبحاث الذكاء الاصطناعي على الشبكات العصبية العميقة ، والتي تعتمد بدورها على مجال أوسع لتعلم الآلة. تستخدم تقنيات وزارة الدفاع حساب التفاضل والتكامل التفاضلي والكامل لإنشاء البرامج التي يستخدمها معظمنا ، مثل مرشحات البريد العشوائي في البريد أو البحث في الإنترنت. على مدى العشرين عامًا الماضية ، بدأ الباحثون في تطبيق هذه التقنيات على فكرة جديدة ، شبكات عصبية - هياكل برامج تحاكي وظيفة الدماغ. الفكرة هي لامركزية الحسابات عبر آلاف المعادلات الصغيرة ("الخلايا العصبية") التي تستقبل البيانات وتعالجها وترسلها بشكل أكبر إلى الطبقة التالية من آلاف المعادلات الصغيرة.
يتم تدريب خوارزميات الذكاء الاصطناعي بنفس الطريقة كما في حالة MO ، والتي بدورها تنسخ عملية التعلم للشخص. يتم عرض أمثلة على أشياء مختلفة والعلامات المرتبطة بها. اعرض على الكمبيوتر (أو الطفل) صورة قطة ، قل أن القطة تبدو هكذا ، وستتعلم الخوارزمية التعرف على القطط. ولكن لهذا السبب ، سيتعين على الكمبيوتر عرض آلاف وملايين صور القطط والقطط.
اكتشف الباحثون أن هذه الأنظمة يمكن مهاجمتها ببيانات خادعة مختارة خصيصًا ، والتي أطلقوا عليها "الأمثلة العدائية".
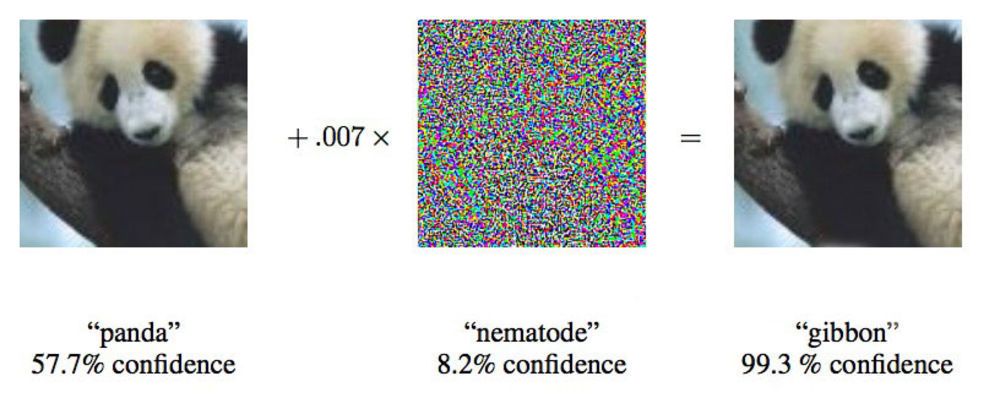 في ورقة من عام 2015 ، أظهر باحثون من Google أنه يمكن إجبار الشبكات العصبية العميقة على نسب هذه الصورة من الباندا إلى جيبونز.
في ورقة من عام 2015 ، أظهر باحثون من Google أنه يمكن إجبار الشبكات العصبية العميقة على نسب هذه الصورة من الباندا إلى جيبونز.قال إيان غودفيلو ، باحث في Google يعمل بنشاط في مثل هذه الهجمات على الشبكات العصبية: "نعرض لك صورة توضح بوضوح حافلة المدرسة ، وتجعلك تعتقد أنها نعامة".
بتغيير الصور المقدمة للشبكات العصبية بنسبة 4٪ فقط ، تمكن الباحثون من خداعهم في ارتكاب أخطاء في التصنيف في 97٪ من الحالات. حتى لو لم يعرفوا بالضبط كيف تعالج الشبكة العصبية الصور ، يمكنهم خداعها في 85 ٪ من الحالات. يسمى الشكل
الأخير من الاحتيال بدون بيانات عن بنية الشبكة "هجوم الصندوق الأسود". هذه هي الحالة الأولى الموثقة لهجوم وظيفي من هذا النوع على شبكة عصبية عميقة ، وأهميته هي أنه في هذا السيناريو تقريبًا يمكن أن تحدث الهجمات في العالم الحقيقي.
في الدراسة ، هاجم باحثون من جامعة ولاية بنسلفانيا وجوجل ومختبر أبحاث البحرية الأمريكية شبكة عصبية تصنف الصور التي يدعمها مشروع MetaMind ويعمل كأداة عبر الإنترنت للمطورين. قام الفريق ببناء وتدريب الشبكة التي تمت مهاجمتها ، لكن خوارزمية هجومهم عملت بغض النظر عن الهندسة المعمارية. باستخدام هذه الخوارزمية ، تمكنوا من خداع الشبكة العصبية للصندوق الأسود بدقة 84.24٪.
 الصف العلوي للصور والشخصيات - التعرف الصحيح على الأحرف.
الصف العلوي للصور والشخصيات - التعرف الصحيح على الأحرف.
الصف السفلي - اضطرت الشبكة إلى التعرف على العلامات بشكل خاطئ تمامًا.إن تغذية البيانات غير الدقيقة إلى الأجهزة ليست فكرة جديدة ، لكن دوج تايجار ، الأستاذ في جامعة بيركلي ، الذي يدرس التعلم الآلي لمدة 10 سنوات على النقيض من ذلك ، يقول إن تقنية الهجوم هذه تطورت من MO بسيط إلى شبكات عصبية عميقة معقدة. يستخدم المخترقون الضارون هذه التقنية على فلاتر الرسائل غير المرغوب فيها لسنوات.
يأتي بحث تايجر من
عمله لعام 2006 في هجمات من هذا النوع على شبكة مع وزارة الدفاع ، والتي
وسعها في عام 2011 بمساعدة باحثين من جامعة كاليفورنيا في بيركلي ومايكروسوفت للأبحاث. نشر فريق Google ، وهو أول من استخدم الشبكات العصبية العميقة ،
أول عمل له في عام 2014 ، بعد عامين من اكتشاف إمكانية مثل هذه الهجمات. لقد أرادوا التأكد من أن هذا لم يكن نوعًا من الشذوذ ، ولكنه احتمال حقيقي. في عام 2015 ، نشروا
عملاً آخر وصفوا فيه طريقة لحماية الشبكات وزيادة كفاءتها ، ومنذ ذلك الحين قدم إيان جودفيلو نصائح حول الأعمال العلمية الأخرى في هذا المجال ، بما
في ذلك
هجوم الصندوق الأسود .
يطلق الباحثون على الفكرة العامة حول المعلومات غير الموثوق بها "البيانات البيزنطية" ، وبفضل تقدم البحث ، فقد وصلوا إلى التعلم العميق. يأتي هذا المصطلح من "
مهمة الجنرالات البيزنطيين " المعروفة
، وهي تجربة فكرية في مجال علوم الكمبيوتر ، حيث يجب على مجموعة من الجنرالات تنسيق أفعالهم بمساعدة الرسل ، دون أن يكون لديهم الثقة بأن أحدهم خائن. لا يمكنهم الوثوق بالمعلومات الواردة من زملائهم.
يقول تايجار: "لقد تم تصميم هذه الخوارزميات للتعامل مع الضوضاء العشوائية ، ولكن ليس البيانات البيزنطية". لفهم كيفية عمل هذه الهجمات ، يقترح Goodfello تخيل شبكة عصبية في شكل رسم بياني مشتت.
تمثل كل نقطة في الرسم البياني بكسل واحد للصورة التي تتم معالجتها بواسطة الشبكة العصبية. عادة ، تحاول الشبكة رسم خط من خلال البيانات التي تناسب مجموعة جميع النقاط. من الناحية العملية ، هذا الأمر أكثر تعقيدًا بعض الشيء ، لأن وحدات البكسل المختلفة لها قيم مختلفة للشبكة. في الواقع ، هذا رسم بياني معقد متعدد الأبعاد يتم معالجته بواسطة الكمبيوتر.
ولكن في تشبيهنا البسيط لمخطط مبعثر ، يحدد شكل الخط المرسوم عبر البيانات ما تعتقد الشبكة أنها تراه. من أجل شن هجوم ناجح على هذه الأنظمة ، يحتاج الباحثون إلى تغيير جزء صغير فقط من هذه النقاط ، واتخاذ الشبكة لاتخاذ قرار غير موجود بالفعل. في مثال الحافلة التي تشبه النعامة ، تتخلل صورة الحافلة المدرسية وحدات بكسل مرتبة وفقًا للنمط المرتبط بالخصائص الفريدة لصور النعام المألوفة للشبكة. هذا كفاف غير مرئي للعين ، ولكن عندما تقوم الخوارزمية
بمعالجة البيانات وتبسيطها ، فإن نقاط البيانات المتطرفة للنعام تبدو لها خيار تصنيف مناسب. في إصدار الصندوق الأسود ، اختبر الباحثون العمل باستخدام بيانات إدخال مختلفة لتحديد كيفية رؤية الخوارزمية لأشياء معينة.
من خلال إعطاء مُصنِّف الكائن مُدخلاً مزيفًا ودراسة القرارات التي اتخذتها الآلة ، تمكن الباحثون من استعادة الخوارزمية لخداع نظام التعرف على الصور. من المحتمل أن يرى مثل هذا النظام في الأجهزة الآلية في هذه الحالة علامة "التخلي عن الطريق" بدلاً من علامة التوقف. عندما فهموا كيف تعمل الشبكة ، تمكنوا من جعل الآلة ترى أي شيء.
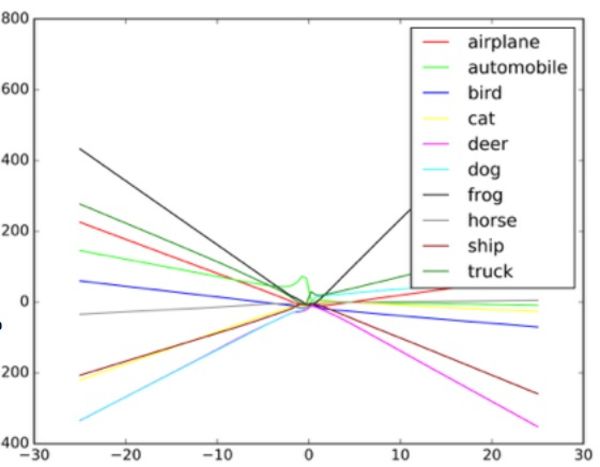 مثال على كيفية رسم مصنف الصور لخطوط مختلفة اعتمادًا على الكائنات المختلفة في الصورة. يمكن اعتبار الأمثلة المزيفة قيمًا متطرفة على الرسم البياني.
مثال على كيفية رسم مصنف الصور لخطوط مختلفة اعتمادًا على الكائنات المختلفة في الصورة. يمكن اعتبار الأمثلة المزيفة قيمًا متطرفة على الرسم البياني.يقول الباحثون أنه يمكن إدخال مثل هذا الهجوم مباشرة في نظام معالجة الصور ، وتجاوز الكاميرا ، أو يمكن تنفيذ هذه التلاعبات بعلامة حقيقية.
لكن أخصائي السلامة في جامعة كولومبيا ، أليسون بيشوب ، قال إن مثل هذه التوقعات غير واقعية وتعتمد على النظام المستخدم في السيارة الآلية. إذا تمكن المهاجمون بالفعل من الوصول إلى دفق البيانات من الكاميرا ، فيمكنهم بالفعل منحها أي مدخلات.
وتقول: "إذا تمكنوا من الوصول إلى مدخل الكاميرا ، فلن تكون هناك حاجة إلى مثل هذه الصعوبات". "يمكنك فقط أن تظهر لها علامة التوقف."
طرق الهجوم الأخرى ، إلى جانب تجاوز الكاميرا - على سبيل المثال ، رسم علامات بصرية على لافتة حقيقية ، يبدو أن المطران غير محتمل. وتشك في أن الكاميرات ذات الدقة المنخفضة المستخدمة في أجهزة الروبوت ستتمكن بشكل عام من التمييز بين التغييرات الصغيرة في اللافتة.
 يتم تصنيف الصورة البكر على اليسار على أنها حافلة مدرسية. تصحيح على اليمين - مثل النعام. في الوسط - تغييرات الصورة.
يتم تصنيف الصورة البكر على اليسار على أنها حافلة مدرسية. تصحيح على اليمين - مثل النعام. في الوسط - تغييرات الصورة.نجحت مجموعتان ، إحداهما في جامعة بيركلي والأخرى في جامعة جورجتاون ، في تطوير خوارزميات يمكنها إصدار أوامر الكلام للمساعدين الرقميين مثل Siri و Google Now ، والتي تبدو وكأنها ضوضاء غير مسموعة. بالنسبة لشخص ما ، ستبدو مثل هذه الأوامر ضجيجًا عشوائيًا ، ولكن في نفس الوقت يمكنهم إعطاء أوامر لأجهزة مثل Alexa ، لم يتوقعها صاحبها.
يقول نيكولاس كارليني ، أحد الباحثين في الهجمات الصوتية البيزنطية ، أنهم تمكنوا في اختباراتهم من تنشيط برامج التعرف على الصوت مفتوحة المصدر ، Siri و Google Now ، بدقة تزيد عن 90٪.
الضجيج هو مثل نوع من التفاوض الغريبة الخيال العلمي. هذا مزيج من الضجيج الأبيض والصوت البشري ، ولكنه ليس مثل الأمر الصوتي على الإطلاق.
وفقًا لـ Carlini ، في مثل هذا الهجوم ، يمكن إجبار أي شخص سمع ضوضاء الهاتف (في حين أنه من الضروري التخطيط لهجمات على iOS و Android بشكل منفصل) للذهاب إلى صفحة ويب تعمل أيضًا على الضوضاء ، والتي ستصيب الهواتف الموجودة في مكان قريب. أو قد تقوم هذه الصفحة بتنزيل برنامج ضار بهدوء. من الممكن أيضًا أن تفقد هذه الضوضاء في الراديو ، وسيتم إخفاؤها في الضوضاء البيضاء أو بالتوازي مع المعلومات الصوتية الأخرى.
يمكن أن تحدث مثل هذه الهجمات بسبب تدريب الجهاز على ضمان احتواء أي بيانات تقريبًا على بيانات مهمة ، بالإضافة إلى أن أحد الأشياء أكثر شيوعًا من الآخر ، كما هو موضح بواسطة Goodfello.
إن خداع الشبكة ، وإجبارها على الاعتقاد بأنها ترى شيئًا مشتركًا ، أسهل ، لأنها تعتقد أنه يجب أن ترى مثل هذه الأشياء في كثير من الأحيان. لذلك ، تمكن Goodfellow ومجموعة أخرى من جامعة وايومنج من الحصول على الشبكة لتصنيف الصور التي لم تكن موجودة على الإطلاق - فقد حددت الكائنات في الضوضاء البيضاء ، والبيكسل الأبيض والأسود بشكل عشوائي.
في دراسة Goodfellow ، تم تصنيف الضوضاء البيضاء العشوائية التي تمر عبر الشبكة على أنها حصان. من قبيل الصدفة ، يعيدنا هذا إلى قصة كليفر هانز ، وهو حصان غير موهوب رياضيًا جدًا.
يقول Goodfellow أن الشبكات العصبية ، مثل Smart Hans ، لا تتعلم في الواقع أي أفكار ، ولكنها تتعلم فقط معرفة متى تجد الفكرة الصحيحة. الفرق صغير ولكنه مهم. ويسهل نقص المعرفة الأساسية المحاولات الخبيثة لإعادة تكوين مظهر إيجاد نتائج الخوارزمية "الصحيحة" ، والتي في الواقع تبين أنها خاطئة. لفهم ماهية الشيء ، يجب على الآلة أيضًا أن تفهم ما هو ليس كذلك.
وجد Goodfello ، بعد أن درب شبكة فرز الصور على كل من الصور الطبيعية والصور المعالجة (المزيفة) ، أنه لا يستطيع فقط تقليل فعالية مثل هذه الهجمات بنسبة 90 ٪ ، ولكن أيضًا جعل الشبكة تتعامل بشكل أفضل مع المهمة الأولية.
يقول جودفيلو: "بجعل من الممكن شرح الصور المزيفة غير العادية حقًا ، يمكنك الحصول على تفسير أكثر موثوقية للمفاهيم الأساسية".
استخدمت مجموعتان من الباحثين في مجال الصوت نهجًا مشابهًا لمنهج فريق Google ، لحماية شبكاتهم العصبية من هجماتهم الخاصة من خلال التدريب المفرط. كما حققوا نجاحات مماثلة ، مما قلل من كفاءة هجومهم بأكثر من 90 ٪.
ليس من المستغرب أن هذا المجال من البحث كان مهتمًا بالجيش الأمريكي. قام مختبر أبحاث الجيش برعاية اثنين من أحدث الأعمال حول هذا الموضوع ، بما في ذلك هجوم الصندوق الأسود. وعلى الرغم من أن الوكالة تمول الأبحاث ، فإن هذا لا يعني أن التكنولوجيا ستستخدم في الحرب. وفقا لممثل القسم ، يمكن أن تمر ما يصل إلى 10 سنوات من البحث إلى التقنيات المناسبة للاستخدام من قبل جندي.
شارك أنانثرام سوامي ، الباحث في مختبر الجيش الأمريكي ، في العديد من الأعمال الحديثة التي تتناول خداع الذكاء الاصطناعي. يهتم الجيش بقضية الكشف عن البيانات الاحتيالية وإيقافها في عالمنا ، حيث لا يمكن التحقق بعناية من جميع مصادر المعلومات. يشير Swami إلى مجموعة من البيانات التي تم الحصول عليها من أجهزة استشعار عامة موجودة في الجامعات وتعمل في مشاريع مفتوحة المصدر.
"نحن لا نتحكم دائمًا في جميع البيانات. يقول سوامي: "من السهل جدًا أن يخدع خصمنا". "في بعض الحالات ، يمكن أن تكون عواقب مثل هذا الاحتيال تافهة ، بل على العكس في بعض الحالات".
ويقول أيضًا إن الجيش مهتم بالروبوتات المستقلة والدبابات والمركبات الأخرى ، لذا فإن هدف مثل هذا البحث واضح. من خلال دراسة هذه القضايا ، سيتمكن الجيش من كسب السبق في تطوير أنظمة ليست عرضة لهجمات من هذا النوع.
لكن أي مجموعة تستخدم شبكة عصبية يجب أن يكون لديها مخاوف بشأن احتمالية الهجمات باستخدام انتحال الذكاء الاصطناعي. إن التعلم الآلي والذكاء الاصطناعي في مهدهما ، ويمكن أن يكون للعيوب الأمنية عواقب وخيمة في هذا الوقت. تثق العديد من الشركات بالمعلومات الحساسة للغاية لأنظمة الذكاء الاصطناعي التي لم تنجح في اختبار الزمن. شبكاتنا العصبية لا تزال صغيرة جدًا بالنسبة لنا لمعرفة كل ما نحتاجه بشأنهم.
أدى إشراف مماثل
إلى روبوت مايكروسوفت على تويتر ، تاي ، ليصبح سريعًا عنصريًا مع ميل للإبادة الجماعية. أدى تدفق البيانات الخبيثة ووظيفة "تكرار بعدي" إلى حقيقة أن تاي انحرف بشكل كبير عن المسار المقصود. تم خداع البوت عن طريق الإدخال دون المستوى ، وهذا بمثابة مثال مناسب على التنفيذ الضعيف للتعلم الآلي.
يقول كانشيليان إنه لا يعتقد أن احتمالات مثل هذه الهجمات قد استنفدت بعد إجراء بحث ناجح من قبل فريق جوجل.
يقول كانشيليان: "في مجال أمن الكمبيوتر ، يكون المهاجمون دائمًا أمامنا". "سيكون من الخطير إلى حد ما الادعاء بأننا قد حللنا جميع مشاكل خداع الشبكات العصبية عن طريق تدريبهم المتكرر."