في أوائل نوفمبر 2017 ، أكملت شركة كوالكوم داتا سنتر تكنولوجيز (QDT) العمل على طفلها الجديد - معالج يعتمد على تقنية 10 نانومتر - Centriq 2400. ما المستقبل الذي ينتظر الصناعة وفقًا لمبدعي هذا الابتكار؟ ما هي فوائد الحصول على خوادم ولماذا يعتبر Centriq 2400 فريدًا جدًا؟ اقرأ المزيد عن هذا وأكثر.
في 8 نوفمبر ، تم عقد مؤتمر صحفي لـ QDT في سان خوسيه (كاليفورنيا) ، حيث تم الإعلان رسميًا عن بدء تسليم المعالج الجديد. قال أناند تشاندراسيخر ، نائب الرئيس الأول والمدير التنفيذي:
يعد عرض اليوم إنجازًا هامًا وتوجًا لأكثر من 4 سنوات من التصميم الدؤوب وتطوير ودعم النظام ... لقد أنشأنا معالج الخادم الأكثر تقدمًا في العالم ، والذي يوفر أداءً عاليًا مقترنًا بمستوى عالٍ من كفاءة الطاقة ، مما يسمح لعملائنا بخفض تكاليفهم بشكل كبير.
بالإضافة إلى الفخر غير المقنع في منتجهم ، لا يخجل ممثلو الشركة من إعلان أن معالج Centriq 2400 يتفوق بشكل كبير على المنتجات المنافسة ، على سبيل المثال Intel Xeon Platinum 8180. وفقًا لحساباتهم ، مقابل كل دولار يتم إنفاقه (وتكلفة المعالج 1995 دولارًا) ، سيحصل المستخدم على أداء في 4 مرات. وعند إعادة حساب الأداء بمقدار 1 واط - بنسبة 45٪ أكثر. البيانات الغامقة ، على أي حال ، كثير من ممثلي مختلف الشركات المهتمة بالمنتج الجديد يسعدهم سماعها.
المواصفات الفنية لـ Qualcomm Centriq 2400
بنية وحدة المعالجة المركزية:- حتى 48 نواة 64 بت مع ذروة تردد 2.6 جيجا هرتز ؛
- التوافق مع Armv8
- AArch64 فقط ؛
- Armv8 FP / SIMD ؛
- تمديد CRC و Armv8 Crypto ؛
ذاكرة التخزين المؤقت لوحدة المعالجة المركزية:- 64 كيلو بايت من ذاكرة التخزين المؤقت للتعليمات (تعليمات) L1 و 24 Kb من ذاكرة التخزين المؤقت أحادية الدورة L0 ؛
- ذاكرة تخزين بيانات 32 كيلوبايت L1 ؛
- 512 كيلوبايت من إجمالي ذاكرة التخزين المؤقت L2 لكل نوى 2 ؛
- 60 ميغابايت من ذاكرة التخزين المؤقت L3 المشتركة ؛
- تصفية مرشح طلبات L2 ؛
- جودة الخدمة ؛
حيث ، L (L1 ، L2 ، L3 ، L0) هو المستوى ، أي L0 هو المستوى صفر.التكنولوجيا:- تقنية 10nm FinFET من سامسونج ؛
عرض نطاق الذاكرة:- 6 قنوات لتوصيل وحدات ذاكرة DDR4 ؛
- حتى 2667 طن متري / ثانية لكل اتصال ؛
- 128 جيجابايت / ثانية - الحد الأقصى لإجمالي عرض النطاق الترددي ؛
- ضغط النطاق الترددي المدمج
سعة الذاكرة:- 768 جيجابايت = 128 جيجابايت × 6 اتصالات ؛
نوع الذاكرة:- اتصالات DDR4 64 بت مع 8 بت ECC ؛
- RDIMM و LRDIMM ؛
الواجهة المدعومة:- GPIO
- I²C ؛
- SPI
- 8 نطاقات SATA Gen 3 ؛
- 32 واجهة PCIe Gen3 مع إمكانية توصيل ما يصل إلى 6 وحدات تحكم PCIe ؛
بالإضافة إلى الخصائص المذكورة أعلاه ، تجدر الإشارة إلى أن هذا المعالج يحتوي على 18 مليار ترانزستور على كل شريحة. وجميع النوى متصلة بواسطة ناقل حلقي ثنائي الاتجاه. عند الحمل الأقصى ، يستهلك Centriq 2400 فقط 120 واط.
التركيز الأساسي للمعالج الجديد لا يزال الحلول السحابية. وفقًا لممثلي الشركة ، سيسمح لك Centriq 2400 بإنشاء أنظمة خادم تتميز بالأداء العالي والكفاءة وقابلية التوسع.
هذا لا يمكن أن يفشل في جذب العديد من الشركات ، والتقنيات السحابية التي تكاد تكون أساس أنشطتها. حضر العرض: Alibaba و LinkedIn و Cloudflare و American Megatrends Inc. و Arm و Cadence Design Systems و Canonical و Chelsio Communications و Excelero و Hewlett Packard Enterprise و Illumina و MariaDB و Mellanox و Microsoft Azure و MongoDB و Netronome و Packet و Red Hat ScyllaDB ، 6WIND ، Samsung ، Solarflare ، Smartcore ، SUSE ، Synopsys ، Uber ، Xilinx. القائمة مثيرة للإعجاب للغاية ، مما يشير إلى زيادة الاهتمام بهذا المنتج.
في الوقت الحالي ، يكتسب معالج Qualcomm Centriq 2400 قوة دفع فقط ، سواء في الانتشار أو الشعبية. وهذا ، بطبيعة الحال ، سيؤدي إلى ظهور شيء جديد ، مشابه أو حتى أكثر إنتاجية ، من منافسي QDT.
ولكن لا يؤمن الجميع بشكل أعمى ببرودة العناصر الجديدة. إذا كان أولئك الذين يعتقدون أن إجراء الاختبارات والتحليل المقارن للعديد من المعالجات سيسمح لك بمشاهدة نتائج إرشادية أكثر بكثير من كلمات مروجي Centriq 2400.
أجرت Cloudflare تحليلاً مقارنًا لثلاث منصات: Grantley (Intel) و Purley (Intel) و Centriq (Qualcomm).
سيتم أدناه عرض الرسوم البيانية لهذا التحليل واستنتاجات مؤلفها -
فلاد كراسنوف . (
أصل هذا التحليل على مدونة Cloudflare )
تشفير المفتاح العام
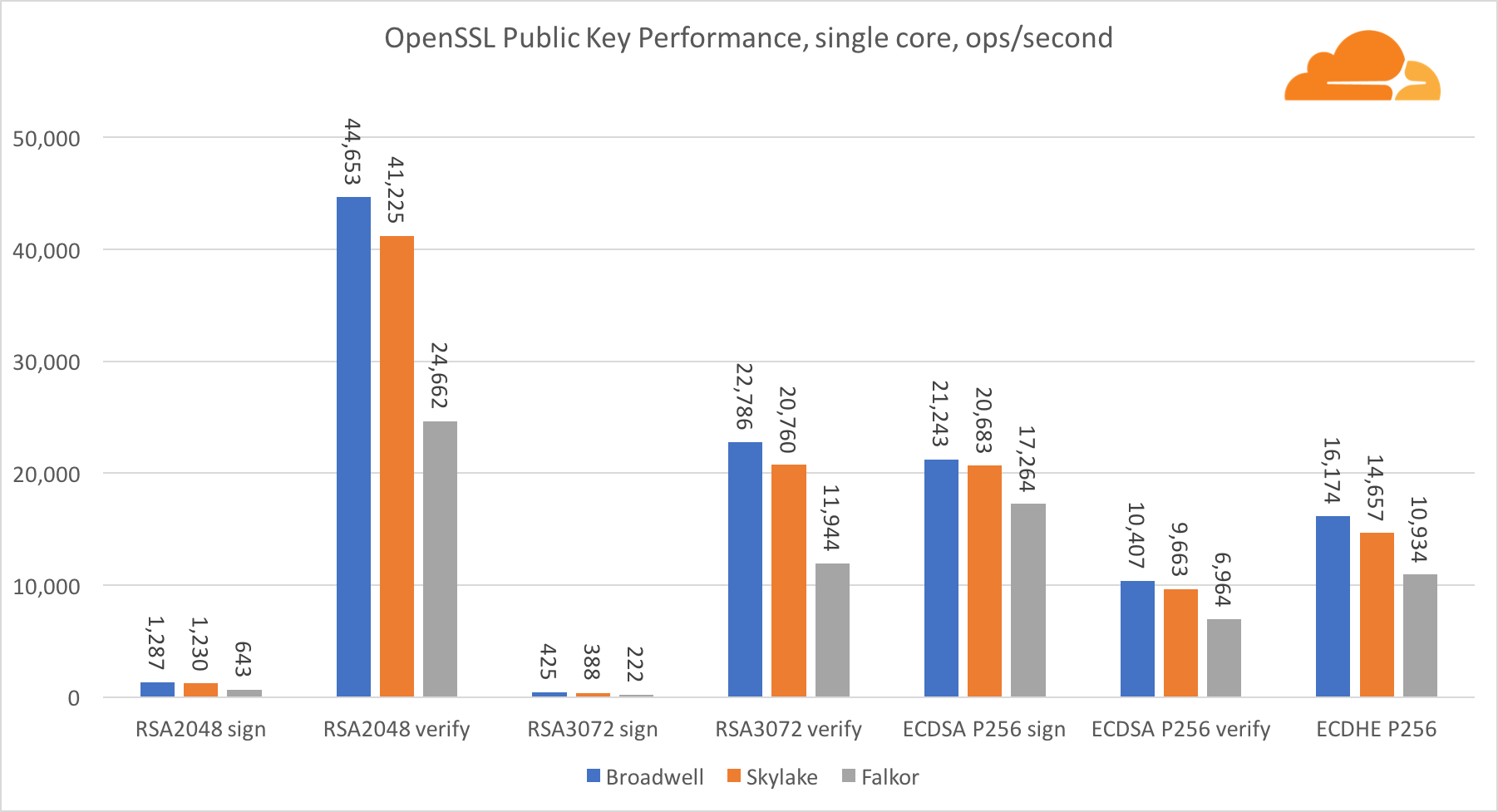
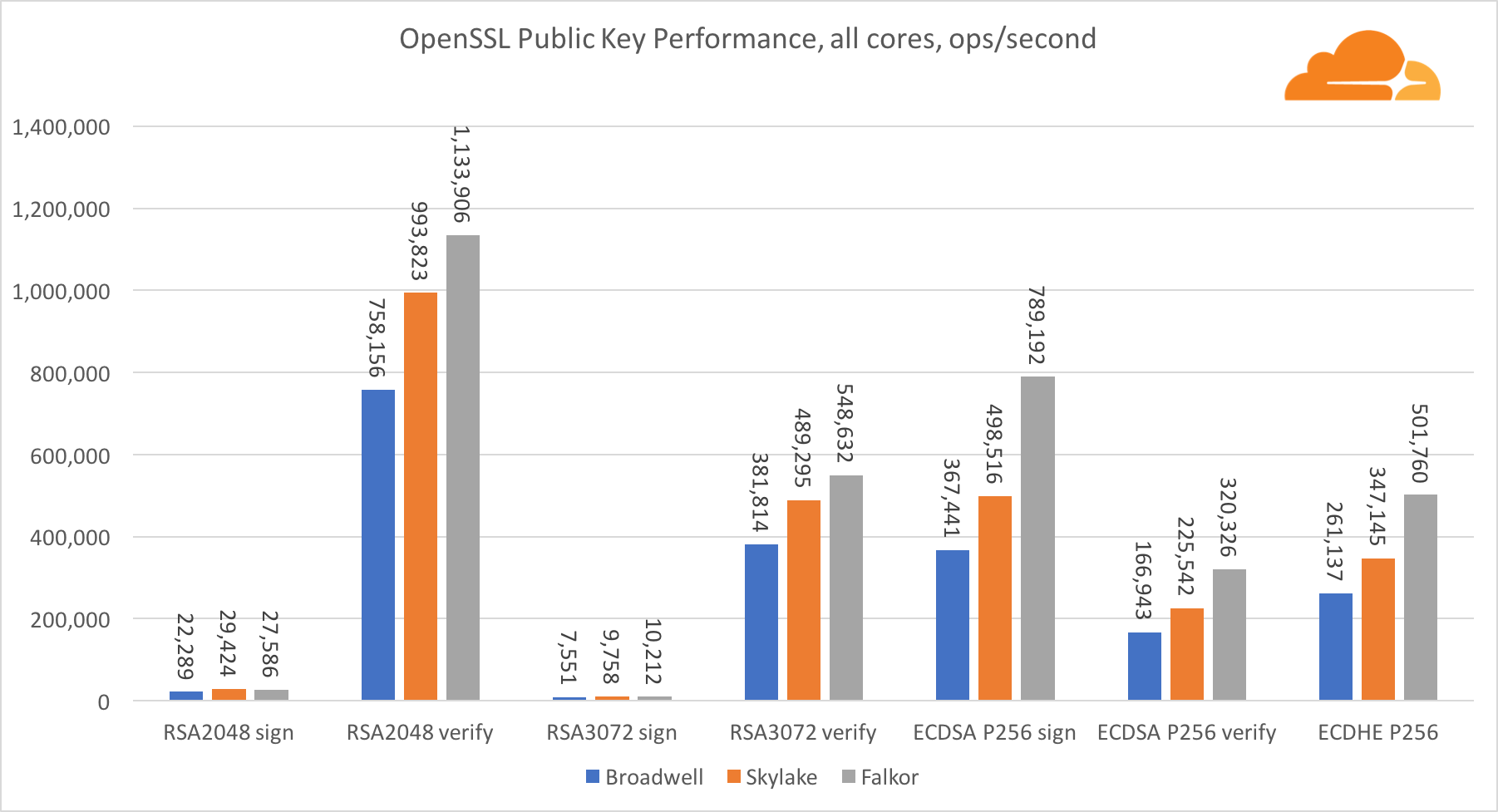
تشفير المفتاح العام هو أنقى أداء لـ ALU (جهاز المنطق الحسابي). من المثير للاهتمام ، ولكن ليس من المستغرب ، أنه في معيار أساسي واحد ، فإن نواة Broadwell أسرع من Skylake ، وكلاهما أسرع من Falkor. هذا لأن برودويل تعمل على تردد أعلى ، على الرغم من أنه من حيث الهندسة المعمارية ، فهي ليست أقل شأنا بكثير من Skylake.
فالكور أدنى من الآخرين في هذا الاختبار. أولاً ، تم تشغيل وضع turbo في أحد المعايير الأساسية ، مما يعني أن معالجات Intel تعمل بتردد أعلى. بالإضافة إلى ذلك ، قدمت Intel تعليمات خاصة في Broadwell لتسريع معالجة الأعداد الكبيرة: ADCX و ADOX. ينفذون عمليتين إضافيتين إضافيتين للحمل في كل دورة ، بينما يمكن لـ ARM القيام بواحدة فقط. وبالمثل ، لا تحتوي مجموعة تعليمات ARMv8 على أمر واحد لإجراء الضرب 64 بت ؛ بدلاً من ذلك ، يتم استخدام زوج من تعليمات MUL و UMULH.
ومع ذلك ، على مستوى SoC ، يفوز Falkor. إنه أبطأ قليلاً من Skylake من حيث RSA2048 ، وفقط لأن RSA2048 ليس لديه تطبيق محسن لـ ARM. أداء ECDSA مرتفع بشكل مثير للسخرية. يمكن لرقاقة Centriq واحدة تلبية احتياجات أي شركة في العالم تقريبًا باستخدام ECDSA.
من المثير للاهتمام أيضًا أن نرى أن Skylake تتخطى برودويل بنسبة 30 ٪ ، على الرغم من أنها فقدت نواة واحدة في الاختبار ولديها 20 ٪ فقط من النوى أكثر من برودويل. يمكن تفسير ذلك من خلال وضع توربو أكثر كفاءة وتحسين الترابط.
التشفير المتماثل
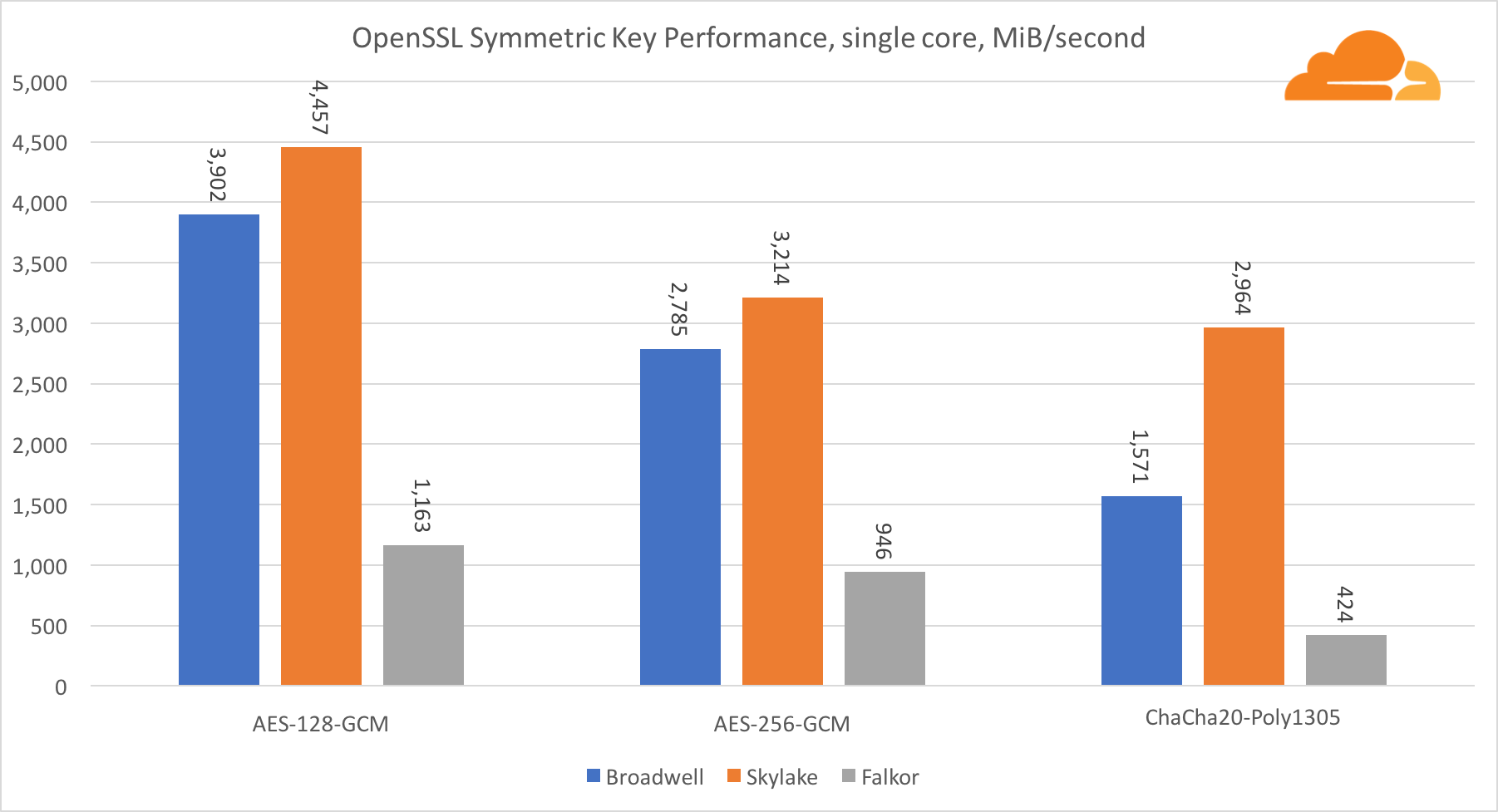
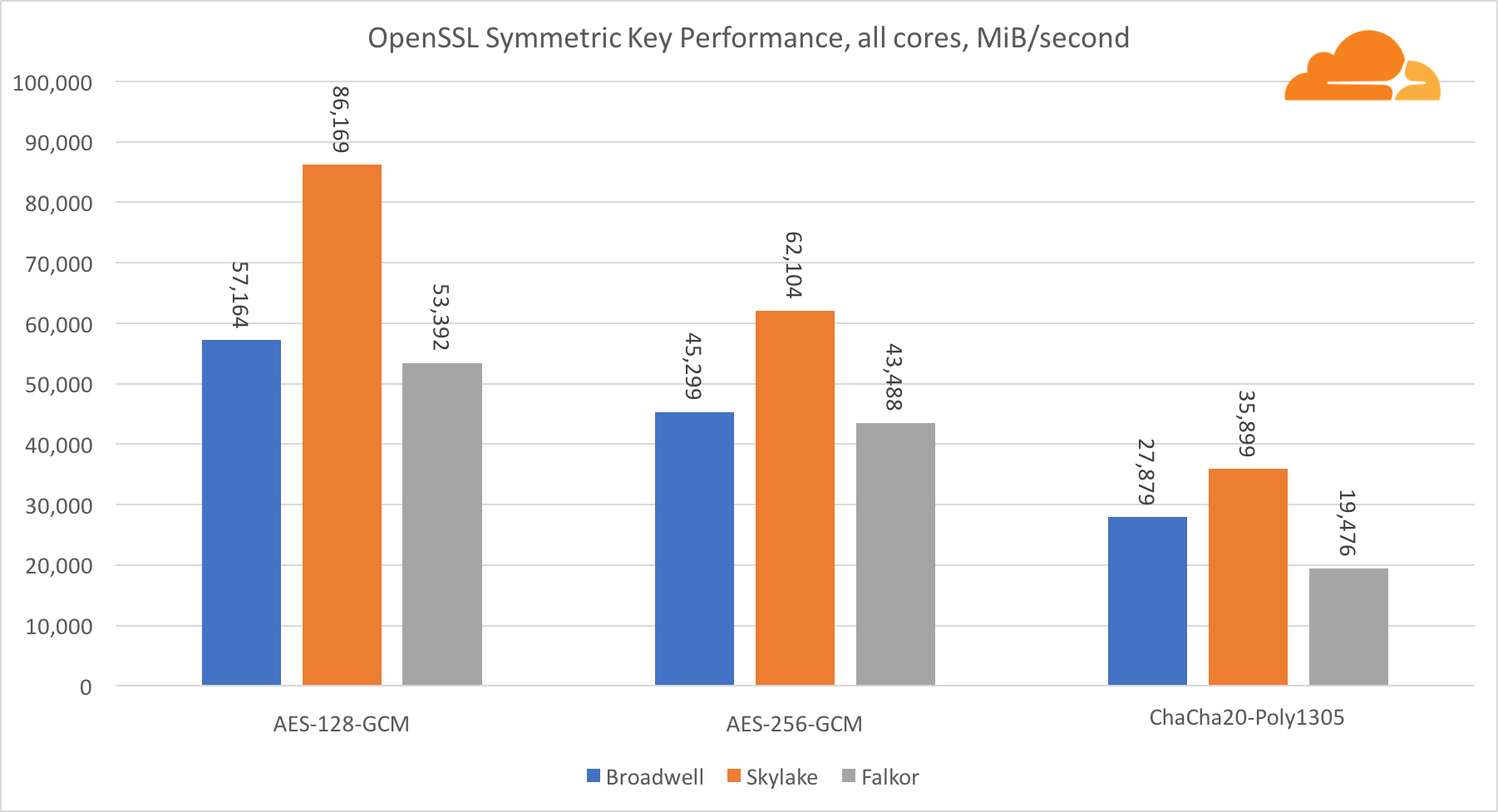
أداء نوى Intel في التشفير المتماثل هو ببساطة ممتاز.
يستخدم AES-GCM مجموعة من التعليمات الخاصة بالأجهزة لتسريع AES و CLMUL. قدمت Intel هذه التعليمات لأول مرة في عام 2010 ، باستخدام معالج Westmere ومع كل جيل ، حسنت من أدائها. قدم ARM مؤخرًا مجموعة من التعليمات المتشابهة مع مجموعة تعليمات 64 بت كإضافة اختيارية. لحسن الحظ ، قام كل مورد معدات أعرفه بتنفيذها. من المرجح جدًا أن تعمل كوالكوم على تحسين أداء تعليمات التشفير في الأجيال القادمة.
ChaCha20-Poly1305 هي خوارزمية أكثر عمومية تم تصميمها بطريقة للاستفادة بشكل أفضل من وحدات SIMD العريضة. كوالكوم لديها فقط NEON SIMD 128 بت ، برودويل 256 بت AVX2 ، و Skylake 512 بت AVX-512. هذا يفسر لماذا Skylake مع هذا الهامش غادر في الصدارة في تقييم العمل مع جوهر واحد. في اختبار جميع النوى ، تم تقليل فجوة Skylake عن البقية في نفس الوقت ، حيث يجب أن تقلل من تردد الساعة عند أداء أحمال عمل AVX-512. عند تشغيل AVX-512 على جميع النوى ، ينخفض تردد القاعدة إلى 1.4 جيجا هرتز. ضع ذلك في الاعتبار إذا قمت بخلط AVX-512 والرموز الأخرى.
الاستنتاج فيما يتعلق بالتشفير المتماثل هو أنه على الرغم من أن Skylake تتقدم ، فقد أظهر برودويل وفالكور نتائج جيدة للغاية ، حيث كان أداءهما عاليًا للحالات الحقيقية ، نظرًا لأن RSA من جانبنا تستهلك وقت معالج أكثر من جميع خوارزميات التشفير الأخرى مجتمعة .
ضغط (ضغط)
الاختبار التالي الذي أردت القيام به هو الضغط. لسببين. أولاً ، يعد هذا عبء عمل مهمًا ، لأنه كلما كان الضغط أفضل ، قل عدد الفجوات في القدرة ، وهذا يسمح بتسليم المحتوى بشكل أسرع إلى العميل. ثانياً ، هذا عبء عمل خطأ في التنبؤ بفرع عالي التردد يتطلب الكثير.
من الواضح أن الاختبار الأول سيكون مكتبة زليب الشعبية. في Cloudflare ، نستخدم إصدارًا محسنًا من المكتبة المحسنة لمعالجات Intel 64 بت ، وعلى الرغم من أنه مكتوب بشكل أساسي في لغة C ، فإنه يستخدم بعض الميزات المضمنة الخاصة بـ Intel. سيكون من غير العدل مقارنة هذه النسخة المحسنة مع zlib الأصلي. ولكن لا داعي للقلق ، فقد بذلت القليل من الجهد وقمت بتعديل المكتبة بحيث تعمل على بنية ARMv8 ، باستخدام خصائص NEON و CRC32. علاوة على ذلك ، فإن سرعته أعلى مرتين من الأصل ، لبعض الملفات.
الاختبار الثاني هو مكتبة بروتلي الجديدة ، مكتوبة بلغة C وتسمح باستخدام شروط متساوية لجميع المنصات.
تم إجراء جميع الاختبارات على HTML blog.cloudflare.com ، في الذاكرة ، على غرار كيفية قيام NGINX بضغط الدفق. ما لم يكن الإصدار المحدد من ملف HTML هو 29329 بايت ، وهو مؤشر جيد ، لأنه يتوافق مع حجم معظم الملفات التي نقوم بضغطها. اختبار الضغط المتوازي هو الضغط المتوازي لعدة ملفات في نفس الوقت ، والضغط المفرد هو ضغط ملف واحد في عدة تدفقات ، على غرار كيفية عمل NGINX.
gzip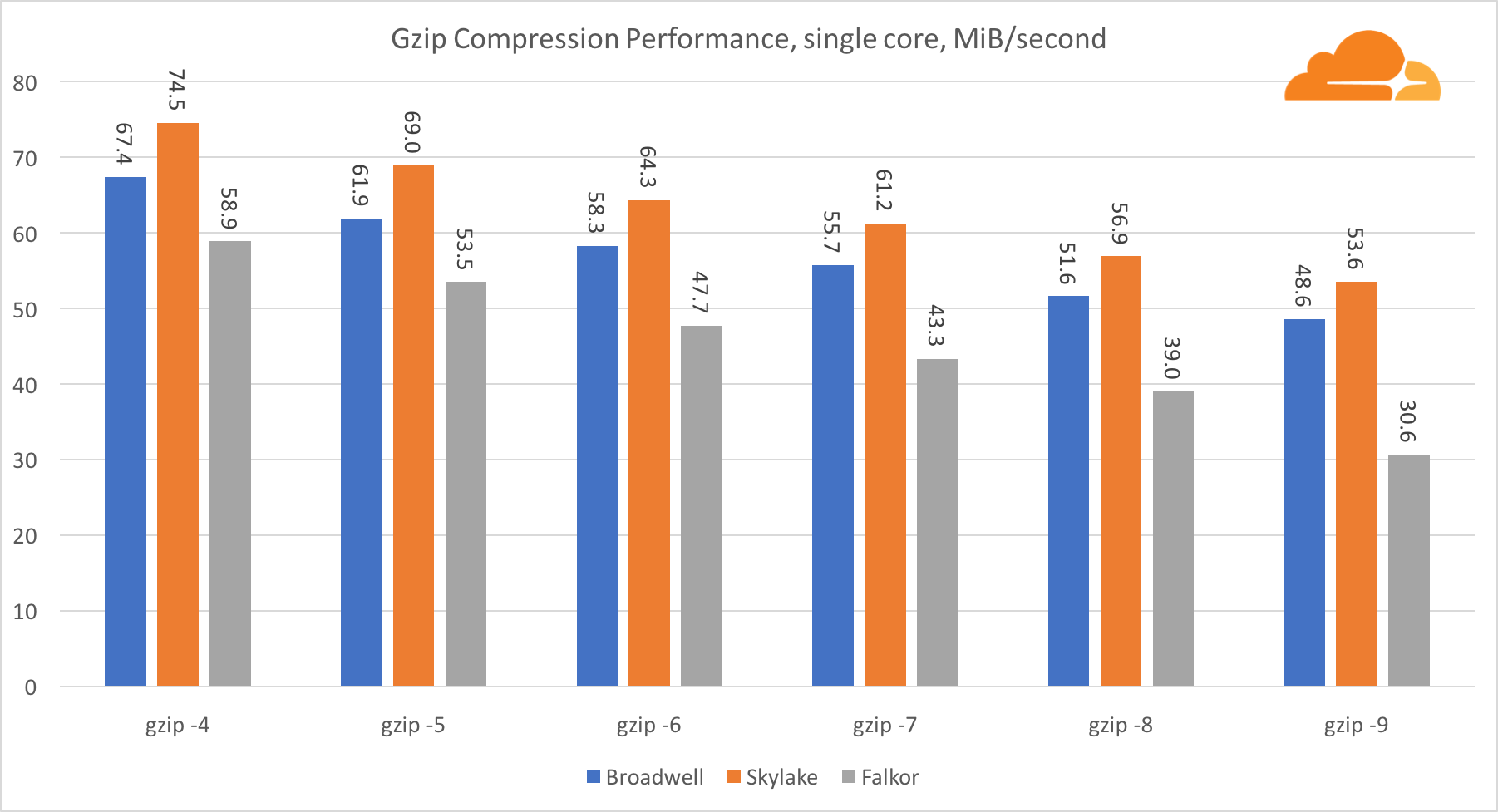
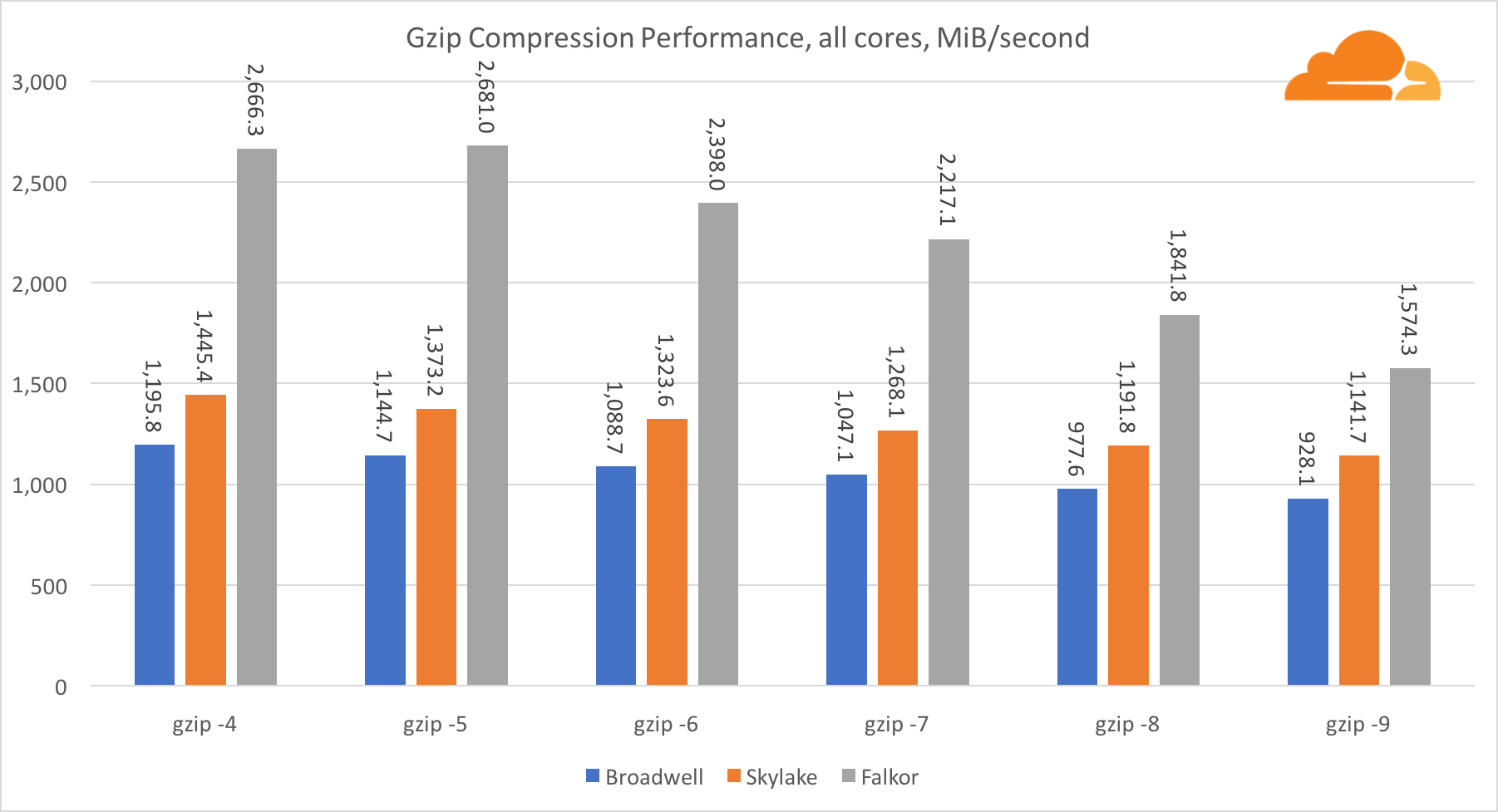
باستخدام gzip على مستوى النواة الواحدة ، تفوز Skylake بلا شك. مع تردد أقل من برودويل ، تستفيد Skylake من التعرض الأقل لسوء فهم الفرع. جوهر Falkor ليست بعيدة. على مستوى النظام ، أداء Falkor أفضل بكثير مع المزيد من النوى. لاحظ كيف أن gzip يتغير بشكل جيد عبر نوى متعددة.
بروتليمع وجود brotli على قلب واحد ، فإن الوضع مشابه للوضع السابق. Skylake هو الأسرع ، لكن Falkor ليس ببعيد. وعلى مستوى 9 ، فالكور أسرع. يشبه معيار 4 Brotli إلى حد كبير مستوى gzip 5 ، بينما لا يزال الضغط الفعلي أفضل (8010B مقابل 8187B).
عند الضغط على نوى متعددة ، يصبح الوضع مربكًا بعض الشيء. بالنسبة للمستويات 4 و 5 و 6 ، يتدرج البروتلي بشكل جيد للغاية. في المستويين 7 و 8 ، يبدأ في الانخفاض بشكل مثمر على القلب ، ويغرق في الأسفل عند المستوى 9 ، حيث نحصل على إنتاجية أقل 3 مرات من جميع النوى مقارنة بواحد.
في رأيي ، هذا يرجع إلى حقيقة أنه مع كل مستوى ، يبدأ brotli في استهلاك المزيد من الذاكرة وتعطل ذاكرة التخزين المؤقت. بدأت المؤشرات في التعافي بالفعل عند المستويين 10 و 11.
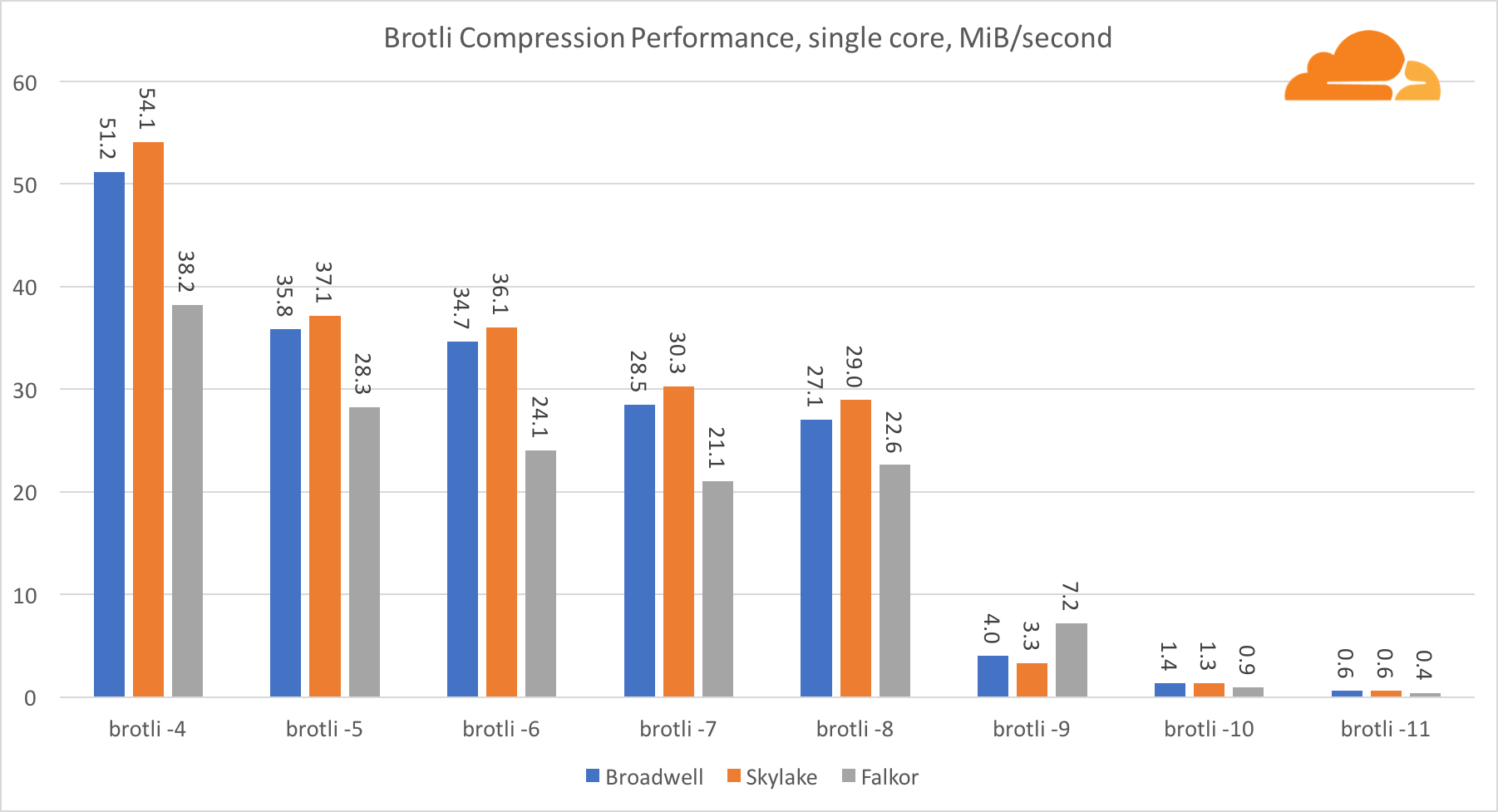
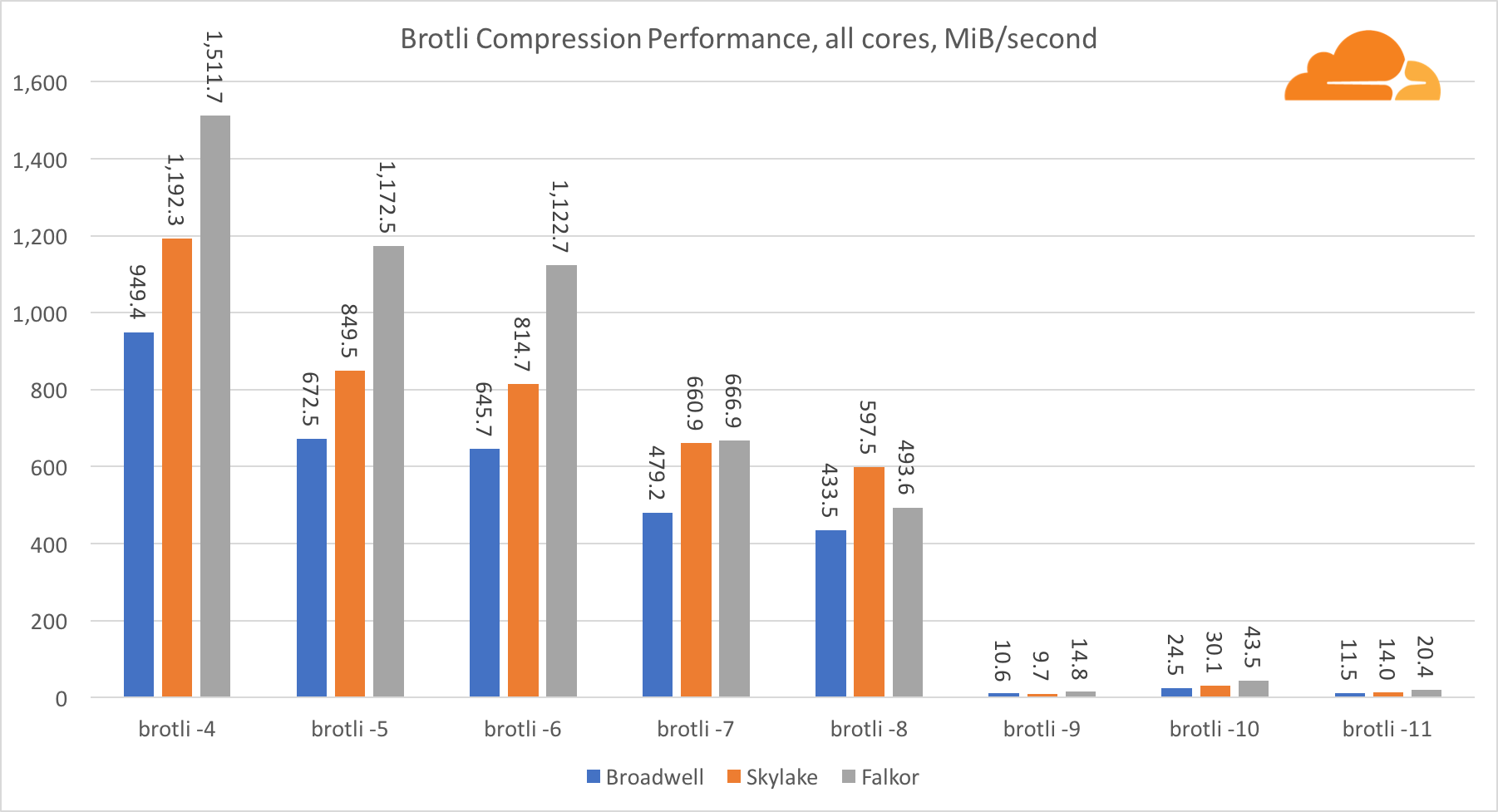
في الختام ، فاز Falkor ، بالنظر إلى أن الضغط الديناميكي لن يتجاوز المستوى 7.
جولانج
الجولانج هي لغة أخرى مهمة جدًا لـ Cloudflare. كما أنها واحدة من اللغات الأولى التي تدعم ARMv8 ، لذا يمكنك توقع أداء جيد. لقد استخدمت بعض الاختبارات المضمنة ، ولكن قمت بتعديلها لعدة غوروتينات.
اذهب التشفيرأود أن أبدأ باختبارات أداء التشفير. بفضل OpenSSL ، لدينا بيانات مصدر ممتازة ، وسيكون من المثير للاهتمام معرفة مدى جودة مكتبة Go.
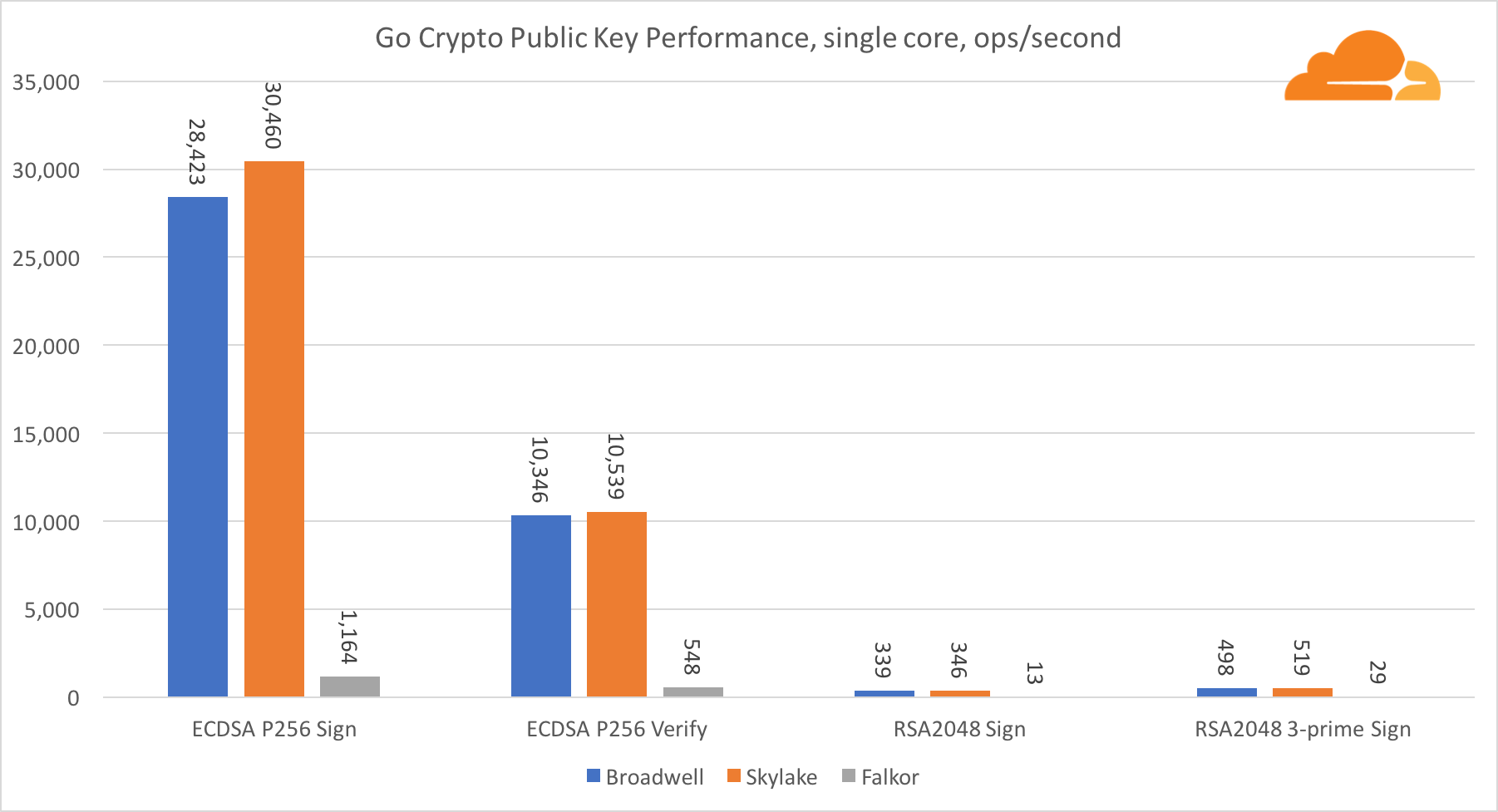
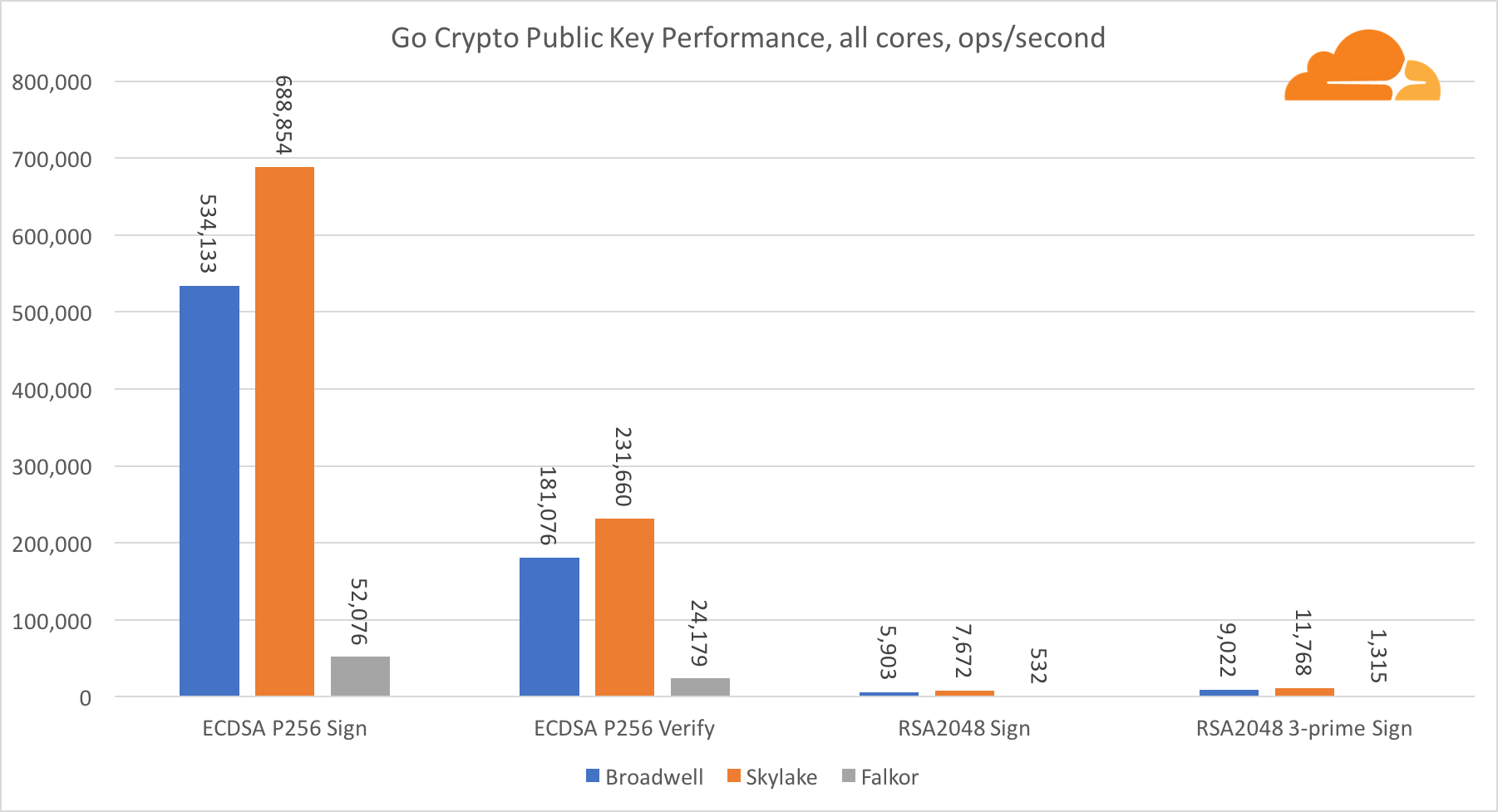
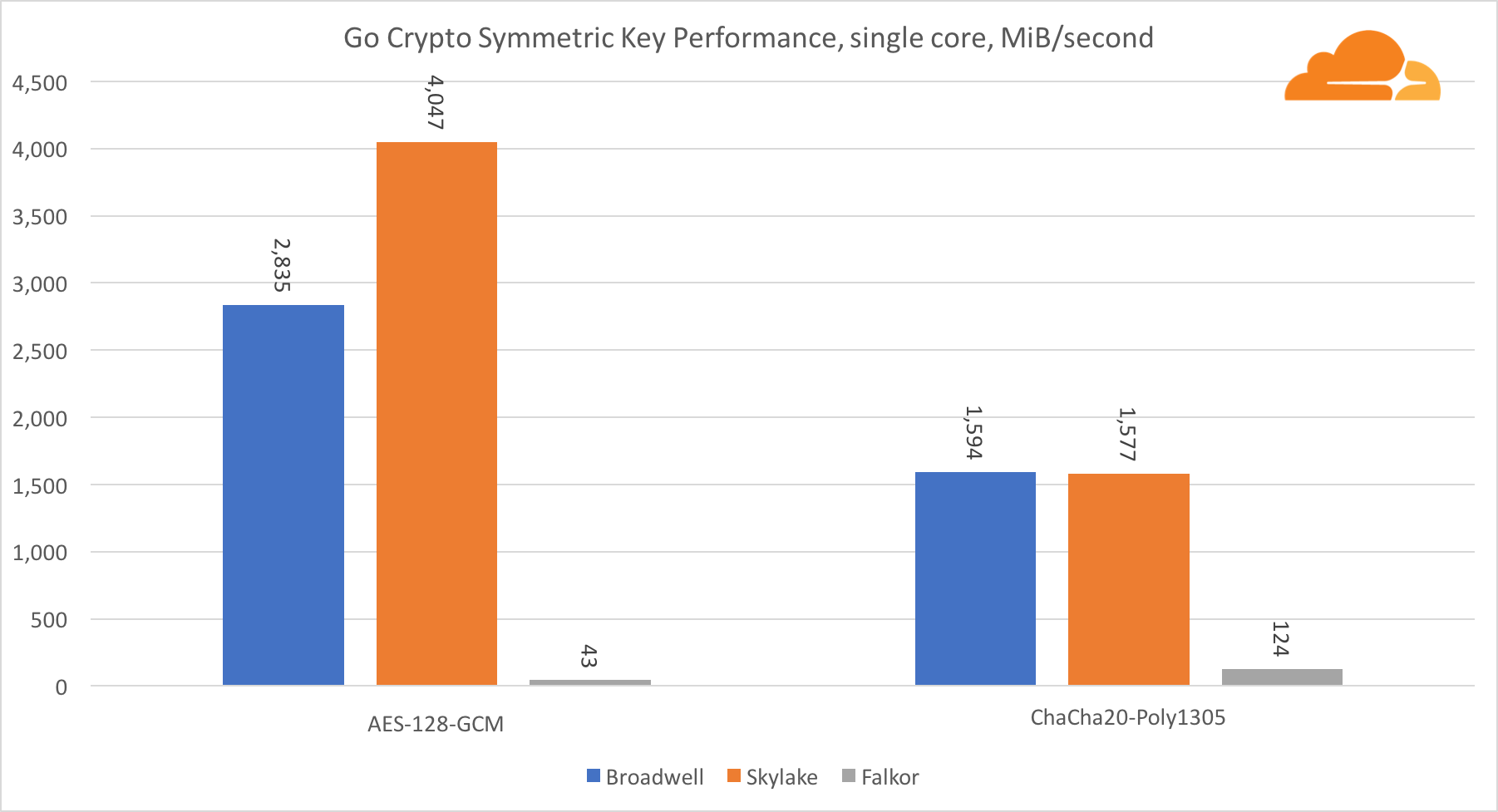
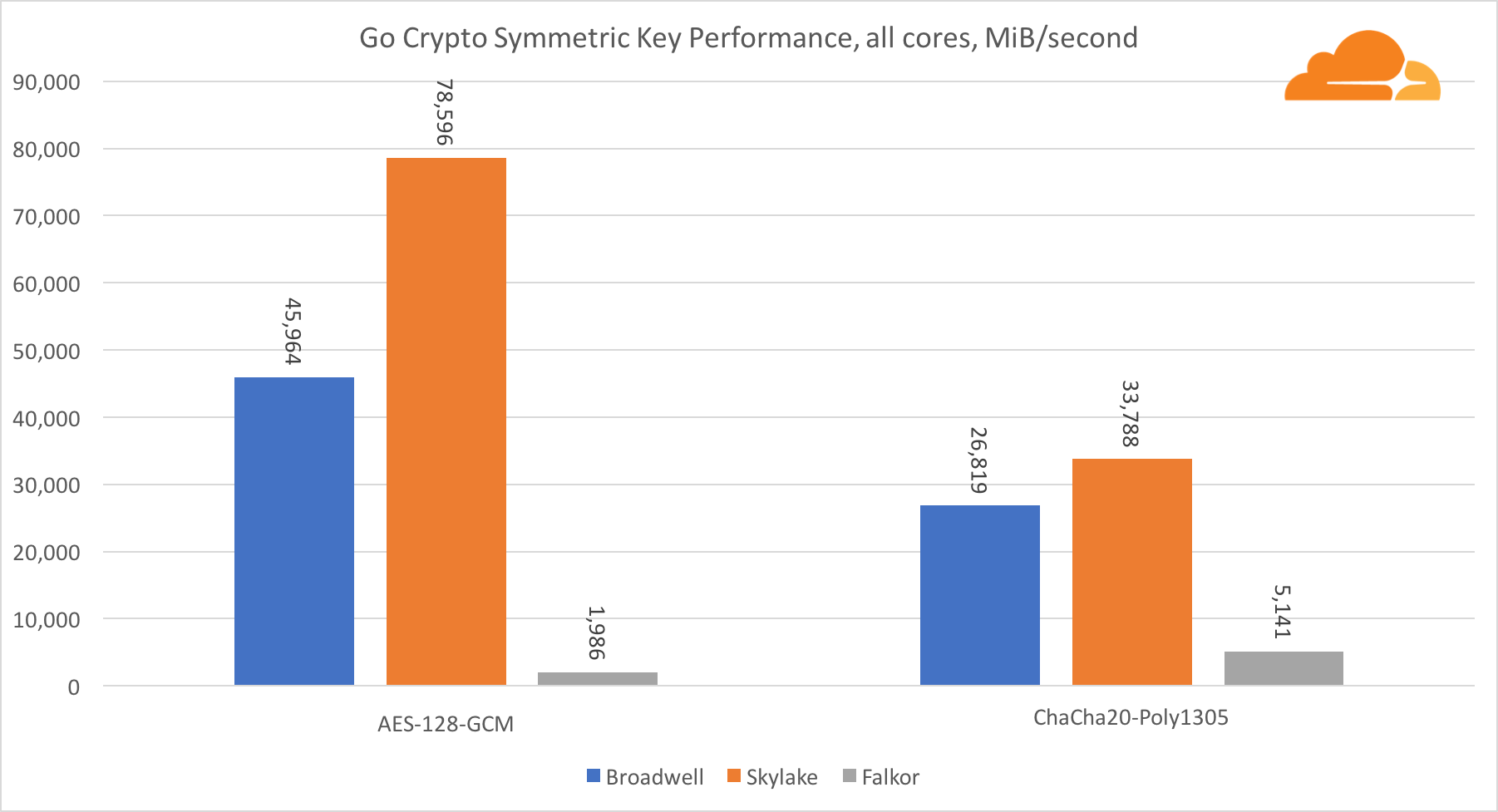
فيما يتعلق بـ Go crypto ، فإن ARM و Intel ليسوا حتى في نفس فئة الوزن. يحتوي Go على كود تجميع محسن للغاية لـ ECDSA و AES-GCM و Chacha20-Poly1305 على Intel. هناك أيضًا وظائف رياضية محسنة تستخدم في حسابات RSA. ARMv8 ليس لديه كل هذا ، مما يضعه في وضع غير مؤاتٍ للغاية.
ومع ذلك ، يمكن تقليل الفجوة بجهد قليل نسبيًا ، ونحن نعلم أنه مع التحسين المناسب ، يمكن أن يكون الأداء على قدم المساواة مع OpenSSL. حتى التغييرات الطفيفة للغاية ، مثل تنفيذ وظيفة addMulVVW في التجميع ، تؤدي إلى زيادة بأكثر من عشرة أضعاف في أداء RSA ، مما يضع Falkor (بنتيجة 8009) فوق كل من Broadwell و Skylake.
تجدر الإشارة إلى شيء واحد أكثر إثارة للاهتمام - على Skylake ، يعمل رمز Go Chacha20-Poly1305 الذي يستخدم AVX2 بنفس الطريقة التي يعمل بها رمز OpenSSL AVX512. مرة أخرى ، هذا يرجع إلى حقيقة أن AVX2 يعمل على ترددات أعلى للساعة.
اذهب gzipالآن دعونا نلقي نظرة على أداء gzip's Go. هناك أيضًا دليل رائع لتعليمات برمجية محسنة جيدًا ، ويمكننا مقارنته بـ Go. في حالة مكتبة gzip ، لا توجد تحسينات محددة لـ Intel.
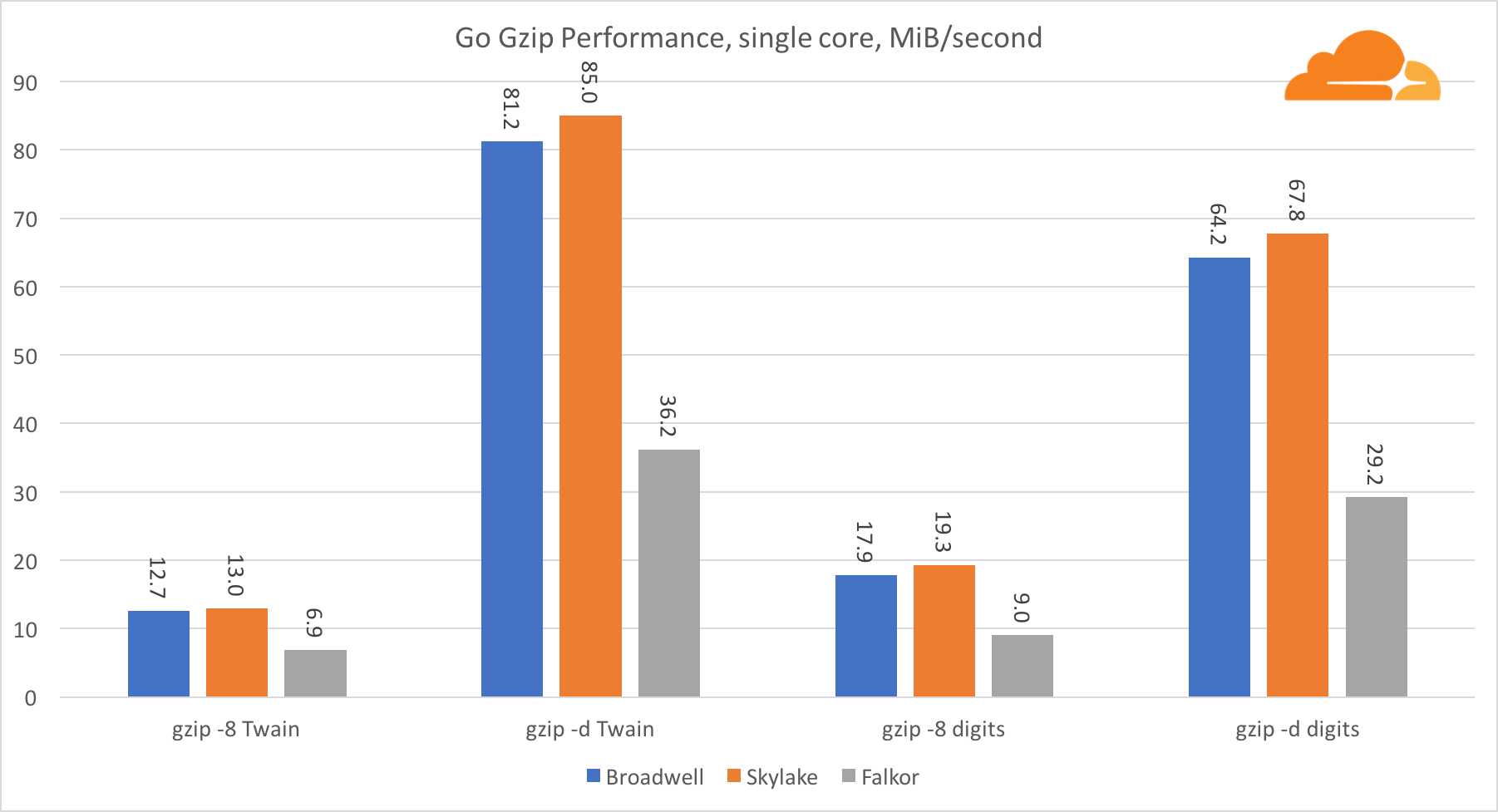

أداء Gzip جيد جدًا. الأداء على نواة واحدة Falkor متخلف بشكل كبير وراء كل من معالجات Intel ، ولكن على مستوى النظام ، تمكن من التغلب على Broadwell ويقع أسفل Skylake. نظرًا لأننا نعرف بالفعل أن Falkor يتفوق على المعالجين الآخرين عند تشغيل C. يمكن أن يعني هذا شيئًا واحدًا فقط - لا تزال خلفية Go for ARMv8 غير نهائية مقارنة بـ gcc.
اذهب regexpيستخدم Regexp على نطاق واسع في مجموعة متنوعة من المهام ، لأن أدائه مهم للغاية أيضًا. لقد أجريت اختبارات مضمنة على تيارات 32 كيلوبايت.
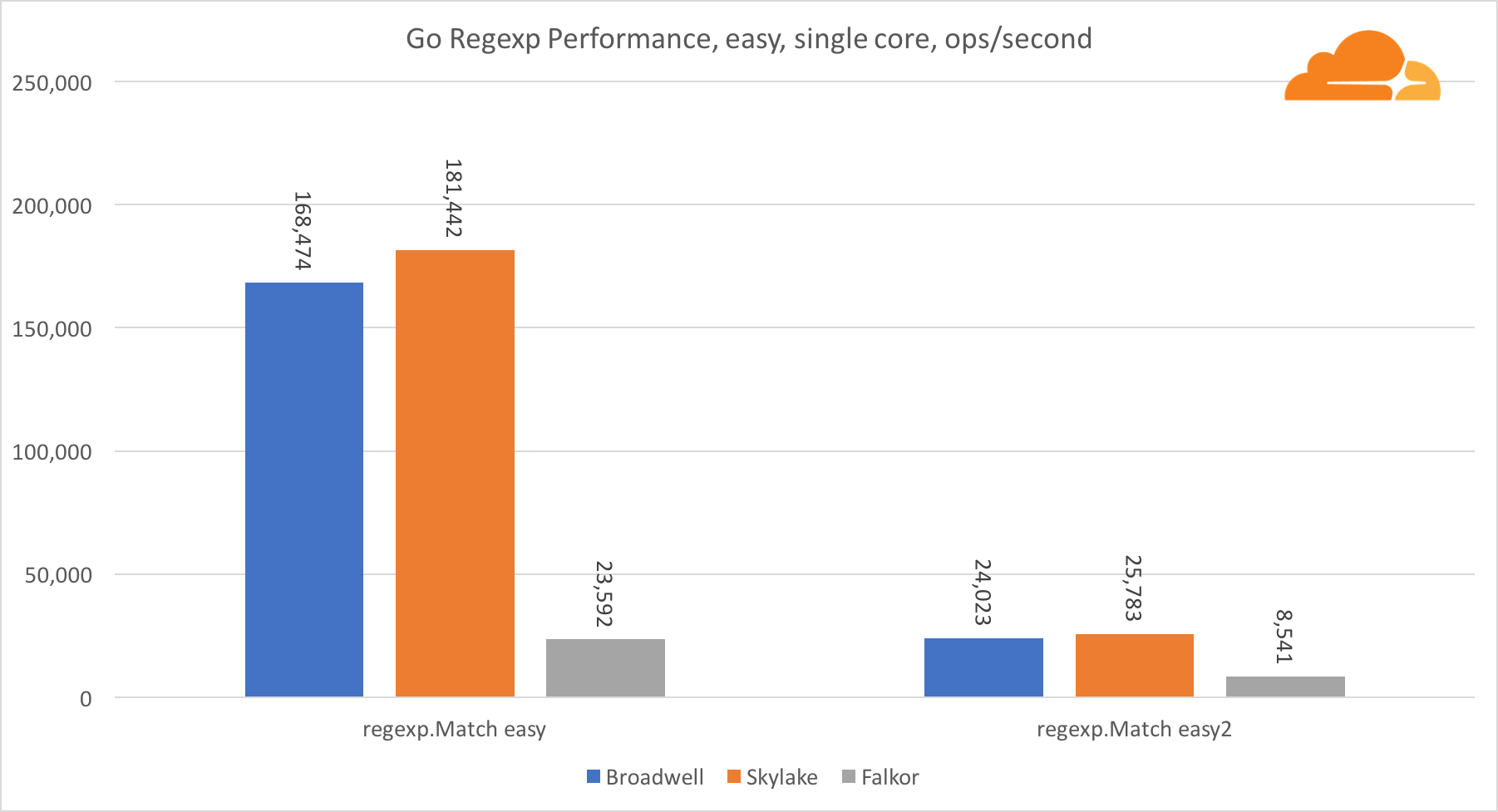
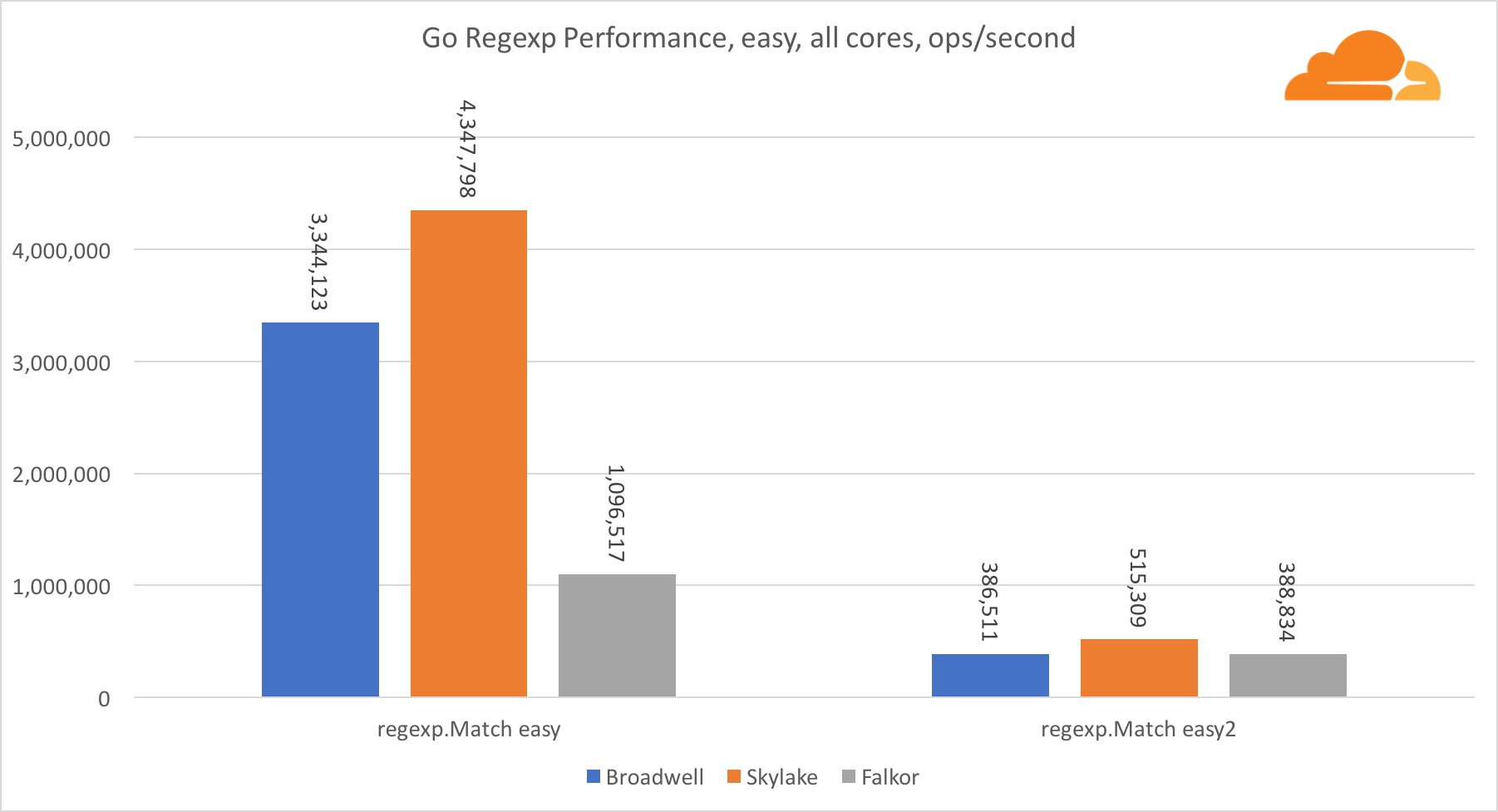
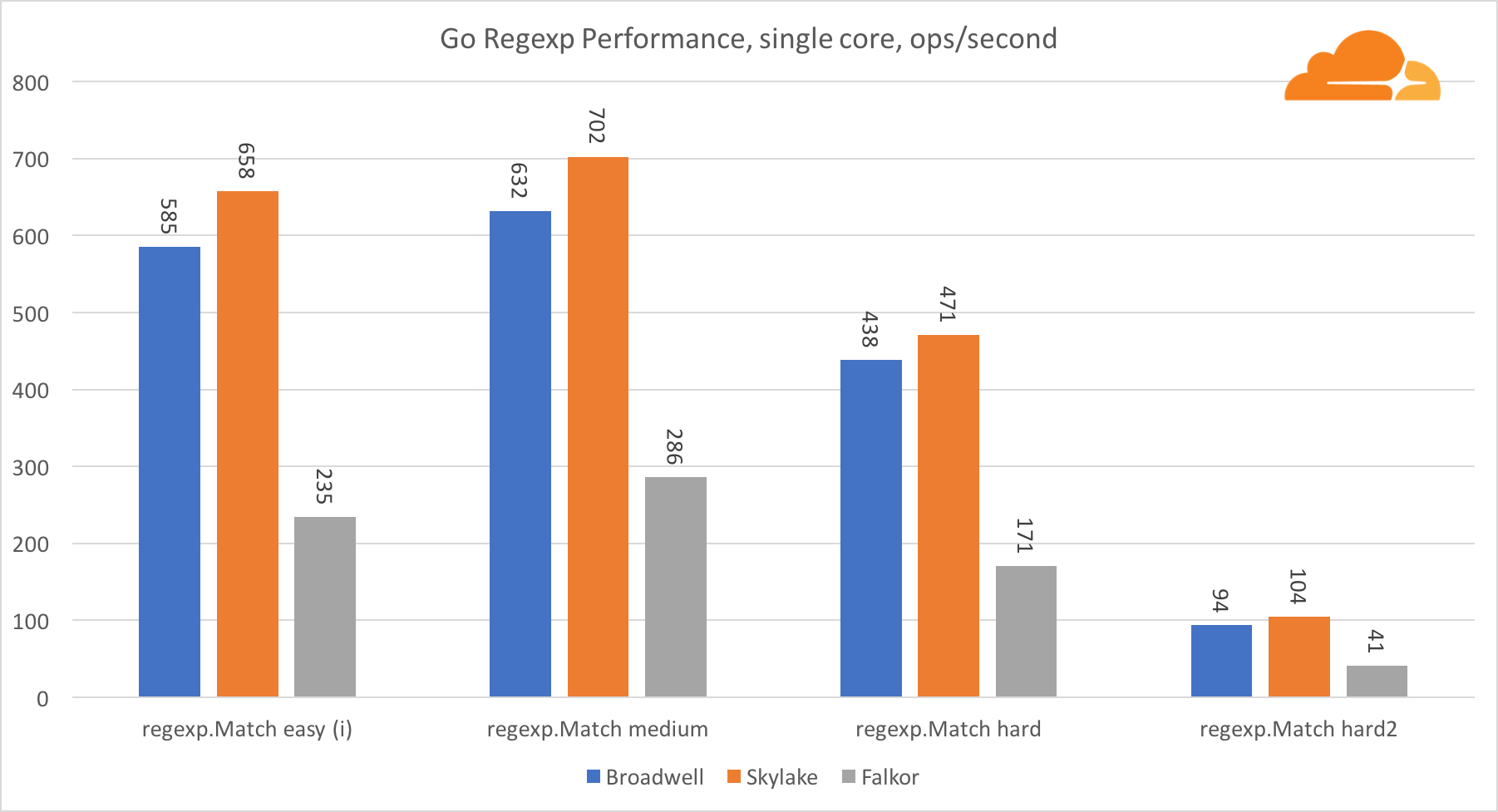
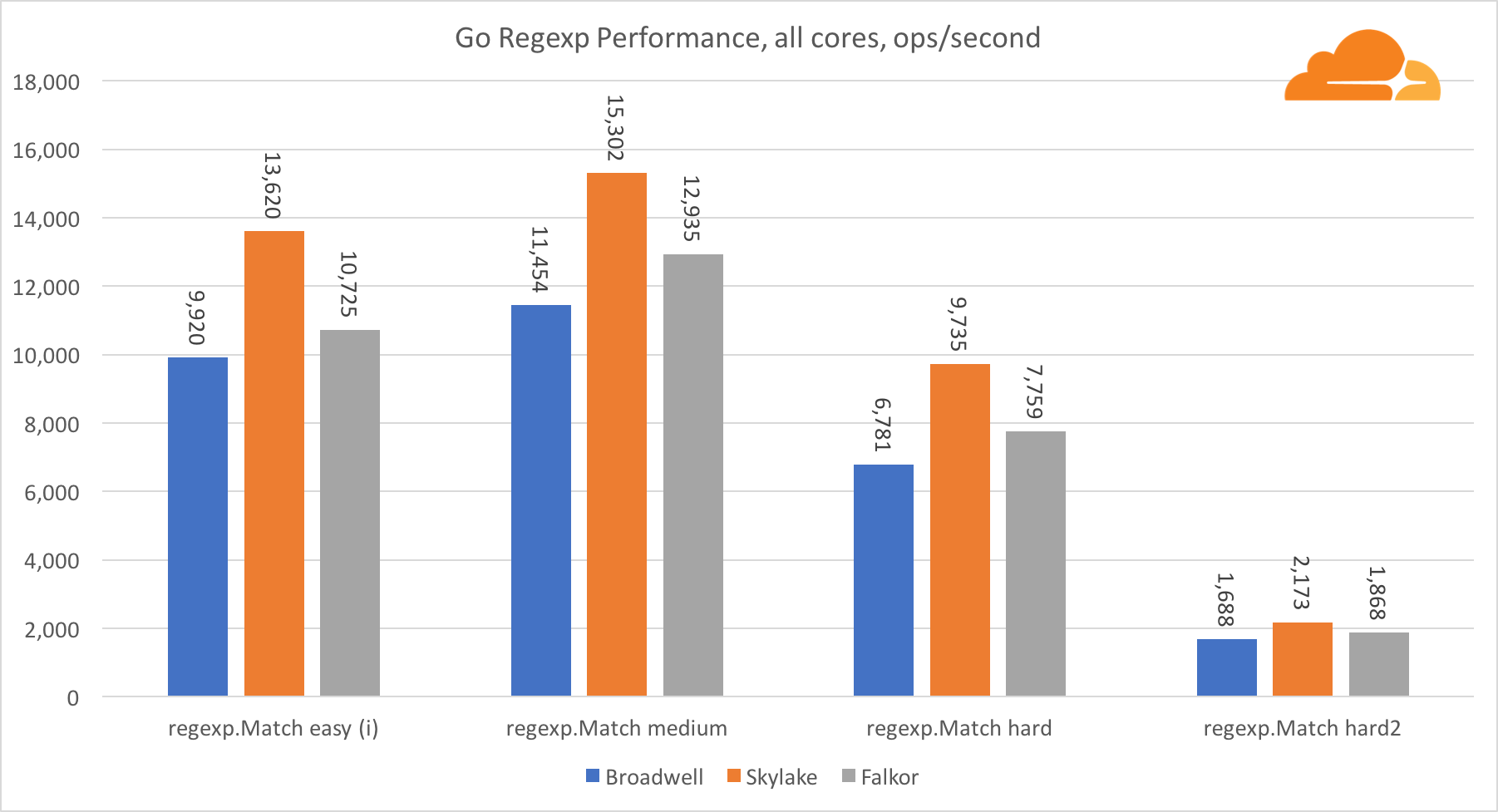
على Falkor ، أداء Go regexp ليس جيدًا جدًا. يحتل المركز الثاني في الاختبارات المتوسطة والمعقدة ، وذلك بفضل عدد أكبر من النوى ، ولكن مع ذلك ، Skylake أسرع بكثير.
تظهر نظرة فاحصة على العملية أنه يتم إنفاق الكثير من الوقت على وظيفة البايت. تحتوي هذه الوظيفة على تطبيق مجمع لـ amd64 (runtime.indexbytebody) ، ولكن التطبيق الرئيسي لـ Go. خلال اختبارات الوزن الخفيف ، أمضى regexp وقتًا أطول في هذه الميزة ، وهو ما يفسر الفجوة الأوسع.
اذهب سلاسلمكتبة مهمة أخرى لخادم الويب هي سلاسل Go. اختبرت فقط فئة Replacer الرئيسية.
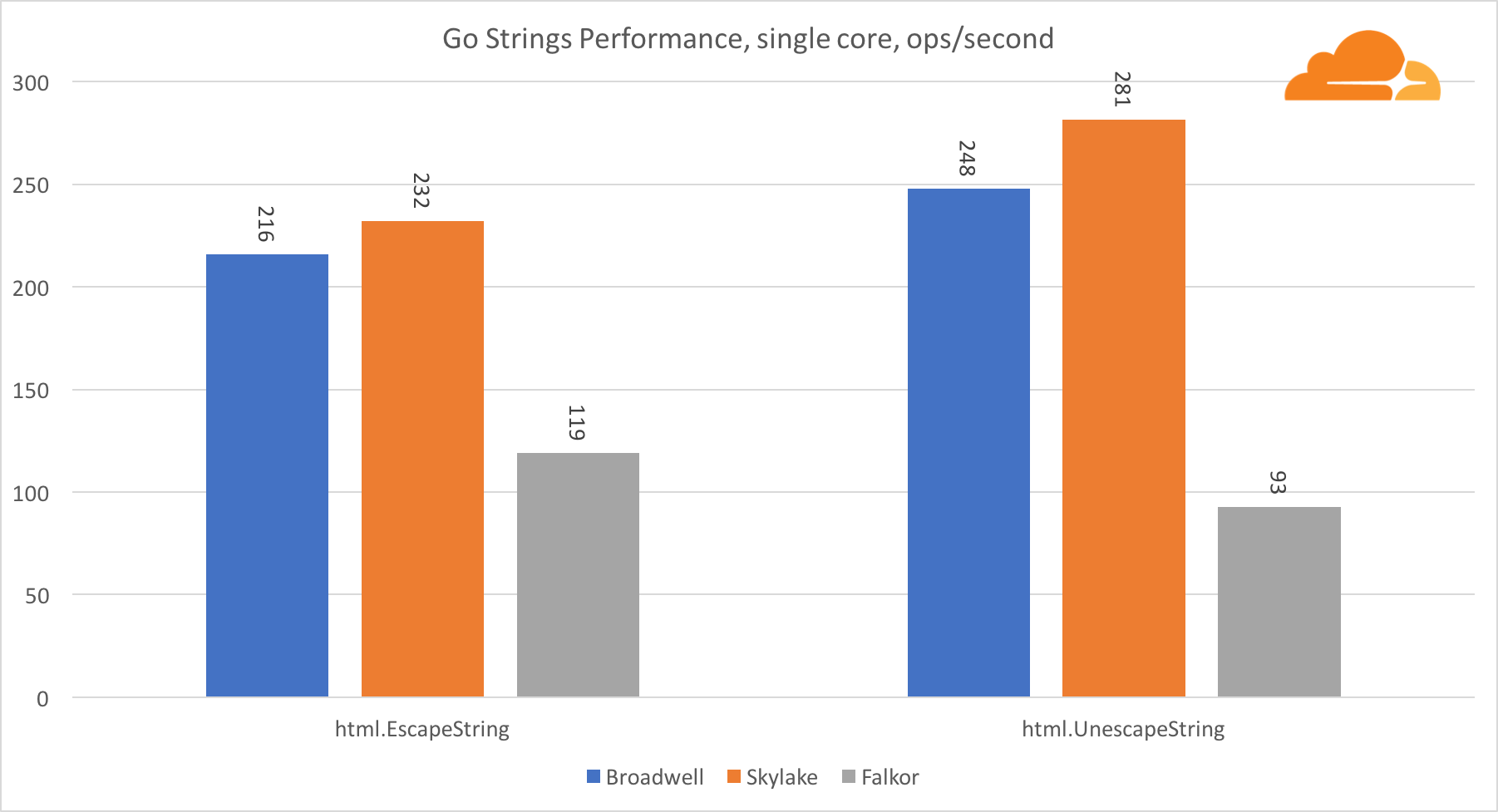
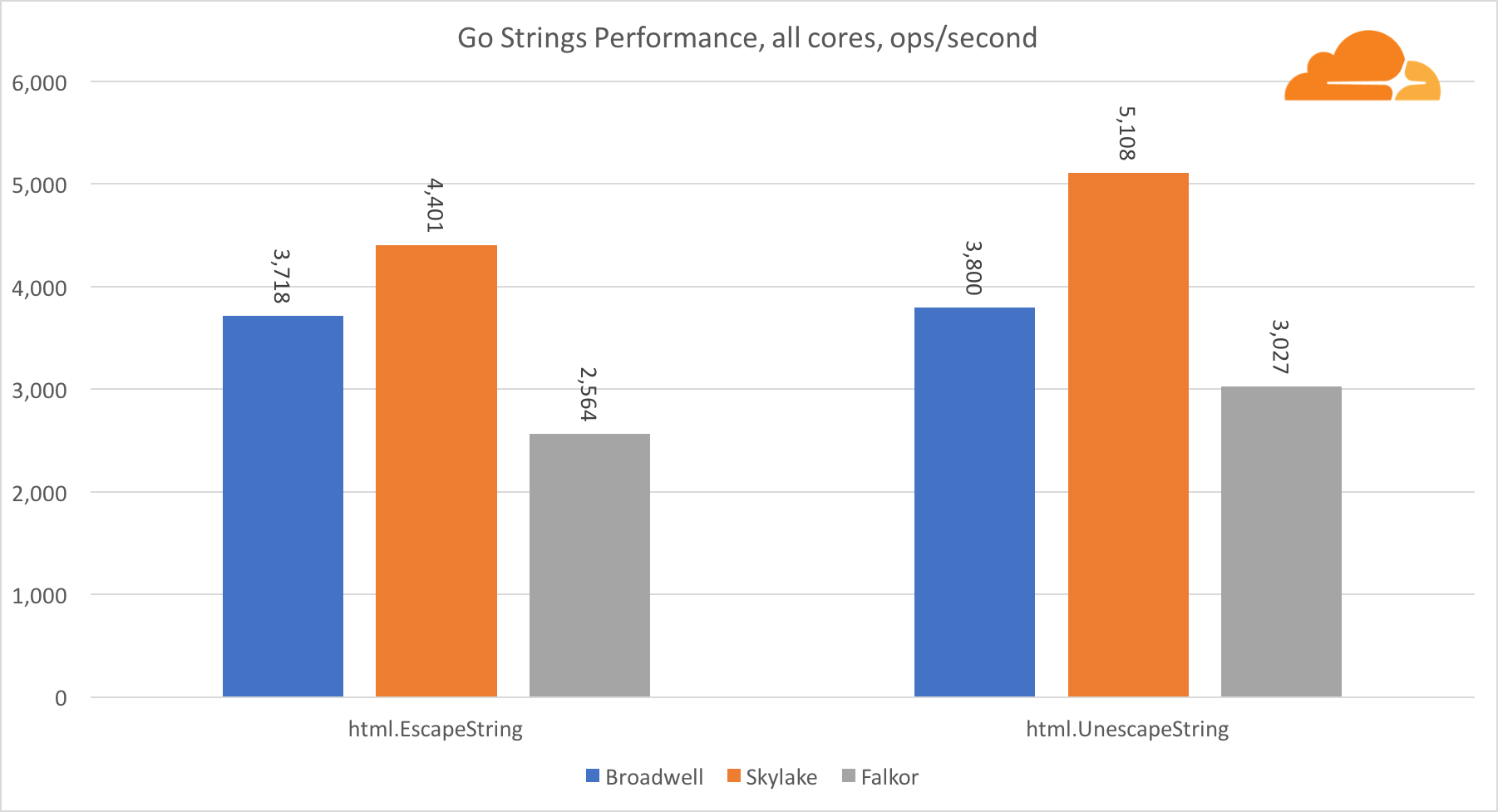
في هذا الاختبار ، يتخلف Falkor مرة أخرى ، حتى وراء Broadwell. نظرة فاحصة تكشف عن إقامة طويلة في وظيفة runtime.memmove. هل تعلم ماذا؟ لديها كود تجميع محسن بشكل مثالي لـ amd64 يستخدم AVX2 ، ولكن فقط أبسط مجمع يقوم بنسخ 8 بايت في المرة الواحدة. من خلال تغيير 3 أسطر في هذا الرمز واستخدام تعليمات LDP / STP (تحميل الزوج / تخزين الزوج) ، يمكنك نسخ 16 بايت في المرة الواحدة ، مما أدى إلى زيادة أداء memmove بنسبة 30٪ ، مما يؤدي بدوره إلى تسريع EscapeString و UnescapeString بنسبة 20٪. وهذا مجرد غيض من فيض.
اذهب الخلاصةالذهاب الدعم على aarch64 أمر مخيب للآمال جدا. يسعدني أن أعلن أن كل شيء تم تجميعه وعمله بشكل لا تشوبه شائبة ، ولكن من ناحية الأداء يمكن أن يكون أفضل. يحصل المرء على الانطباع بأن معظم الجهد تم إنفاقه على الواجهة الخلفية للمترجم ، وأن المكتبة لم تمس تقريبا. هناك العديد من التحسينات ذات المستوى المنخفض ، على سبيل المثال إصلاح addMulVVW الذي استغرق 20 دقيقة. تنوي كوالكوم وموردي ARMv8 الآخرين إنفاق موارد فنية كبيرة لتصحيح الوضع ، ولكن يمكن لأي شخص المساهمة فعليًا في Go. لذلك ، إذا كنت تريد ترك بصمتك في التاريخ ، فقد حان الوقت.
لواجيت
لوا هو الغراء الذي يجمع Cloudflare معًا.
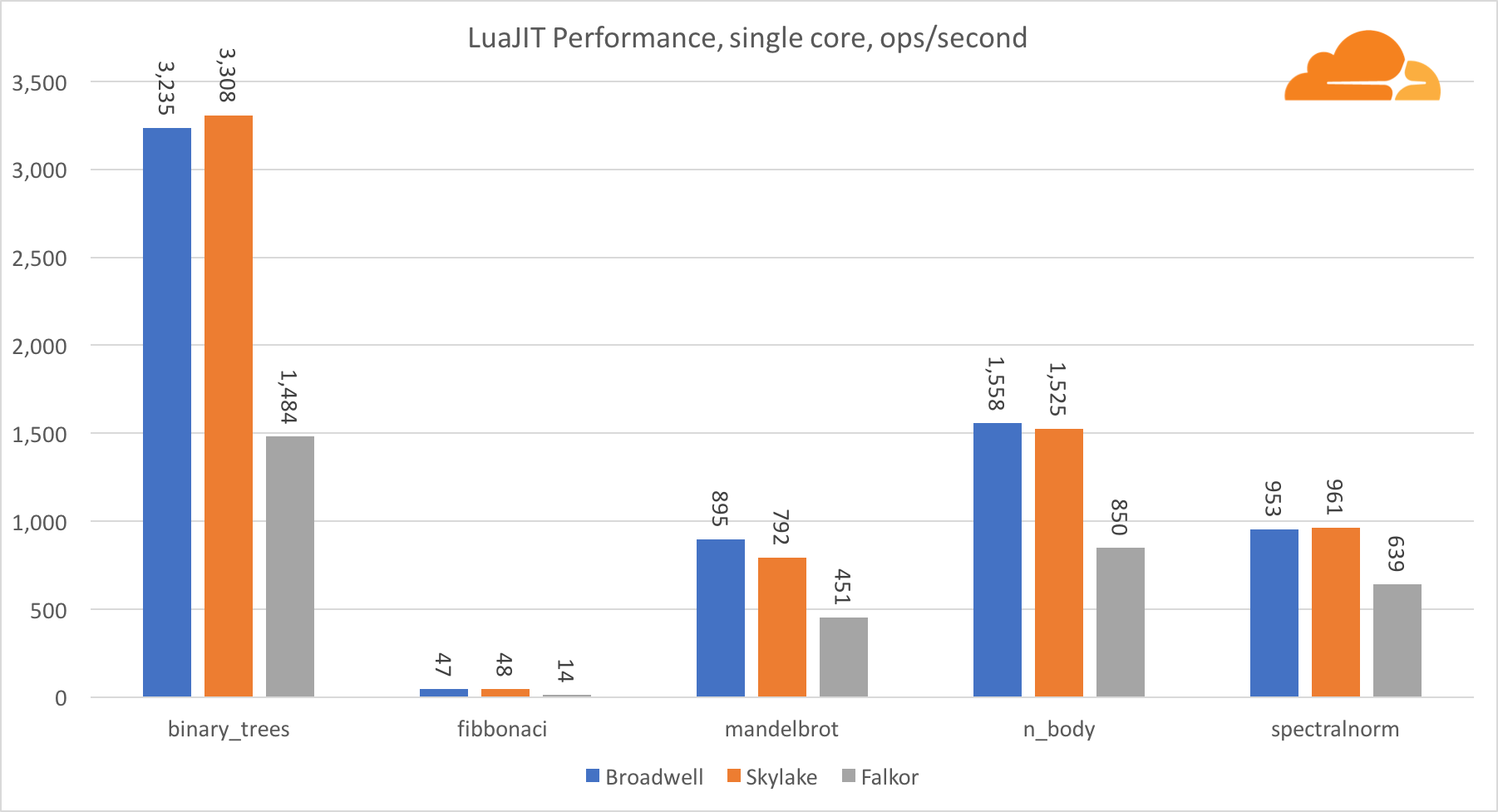
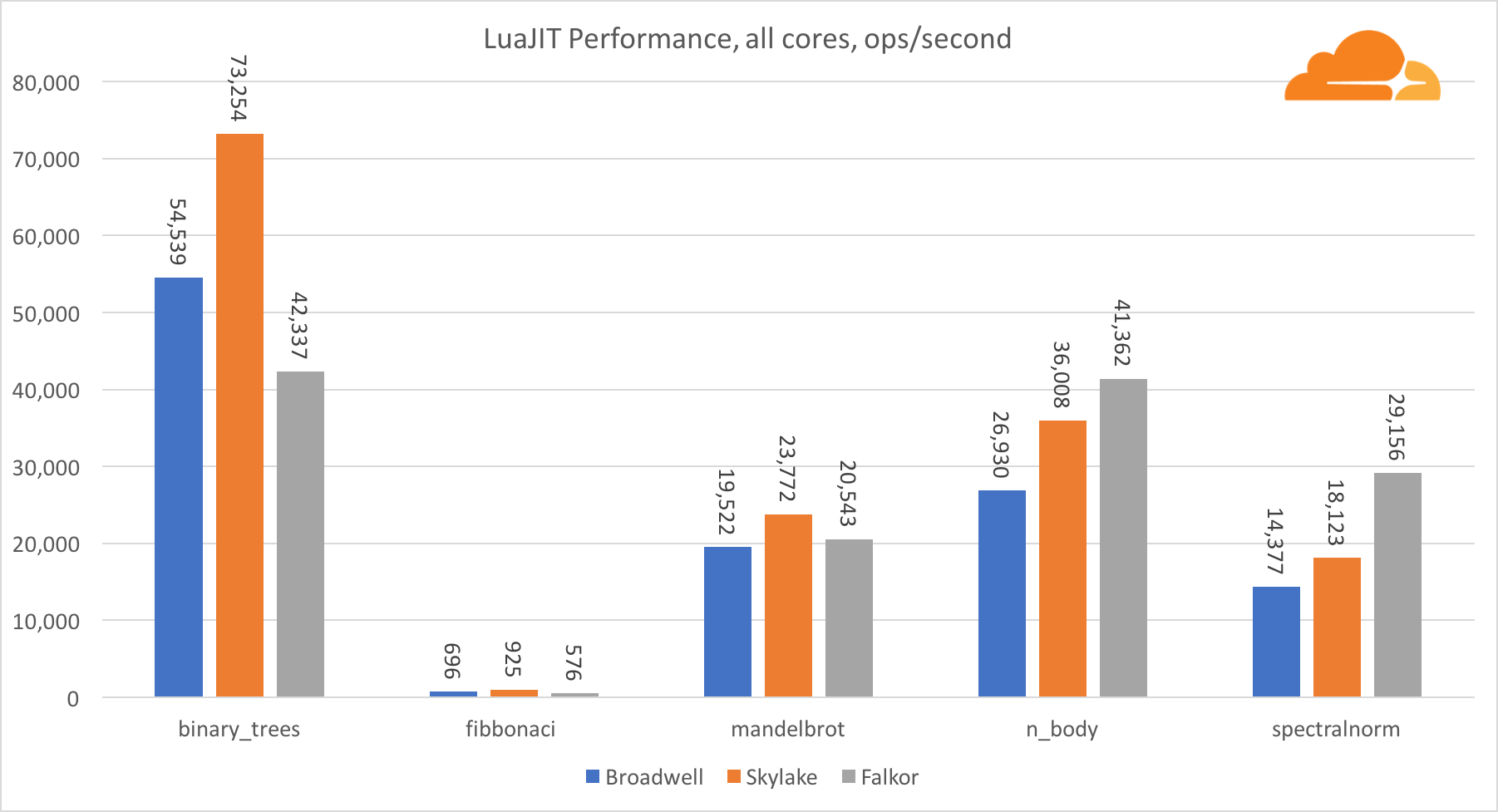
باستثناء اختبار binary_trees ، فإن أداء LuaJIT على ARM تنافسي للغاية. يفوز باثنين من الاختبارات ، والثالث يذهب الأنف مع المنافسين.
تجدر الإشارة إلى أن اختبار binary_trees مهم للغاية ، لأنه يتضمن العديد من دورات تخصيص الذاكرة وجمع القمامة. يتطلب دراسة أكثر دقة في المستقبل.
Nginx
كحمل عمل NGINX ، قررت إنشاء واحد يشبه الخادم الفعلي.
لقد هيأت خادمًا يخدم ملف HTML المستخدم في اختبار gzip عبر https باستخدام مجموعة التشفير ECDHE-ECDSA-AES128-GCM-SHA256.
كما أنه يستخدم LuaJIT لإعادة توجيه الطلب الوارد وإزالة جميع فواصل الأسطر والمسافات الإضافية من ملف HTML عند إضافة طابع زمني. ثم يتم ضغط HTML باستخدام brotli 5.
تم تكوين كل خادم للعمل مع العديد من المستخدمين مثل المعالجات الافتراضية. 40 لـ Broadwell ، 48 لـ Skylake و 46 لـ Falkor.
كعميل لهذا الاختبار ، استخدمت برنامج يا يعمل على 3 خوادم برودويل.
في نفس وقت الاختبار ، أخذنا قراءات الطاقة من كتل BMC المقابلة لكل خادم.
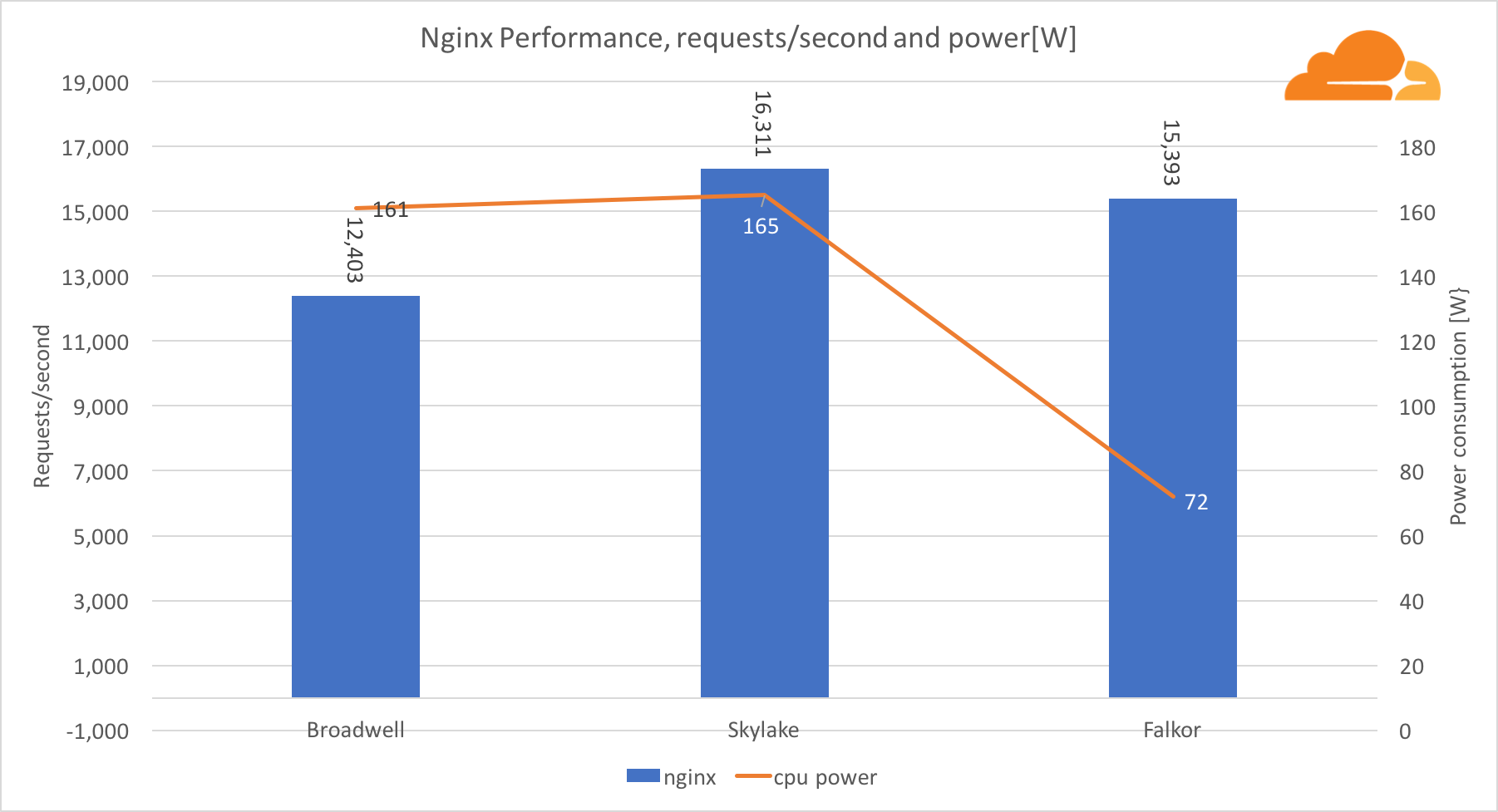
مع عبء العمل ، تعامل NGINX Falkor تقريبًا مع نفس عدد الطلبات مثل خادم Skylake ، وكان كلاهما متقدمًا بشكل كبير على Broadwell. تظهر قراءات الطاقة المأخوذة من BMC أن هذا حدث عندما تم استهلاك الطاقة بنصف كمية استهلاك المعالجات الأخرى. هذا يعني أن Falkor تمكن من الحصول على 214 طلبًا / W ، Skylake - 99 طلبًا / W و Broadwell - 77 طلبًا / W.
لقد فوجئت بأن Skylake و Broadwell يستهلكان نفس الكمية من الطاقة ، نظرًا لأنه يتم إنتاجهما بنفس الطريقة ، وأن Skylake لديها المزيد من النوى.
إن استهلاك الطاقة المنخفض في فالكور ليس مفاجئًا ، لأن معالجات كوالكوم معروفة بكفاءتها العالية في الطاقة ، مما سمح لها باحتلال مكانة مهيمنة في سوق معالجات الأجهزة المحمولة.
الخلاصة
لقد أعجبتني عينة فالكور حقًا. يعد هذا تحسنًا كبيرًا مقارنة بالمحاولات السابقة على الخوادم القائمة على ARM. بالطبع ، بمقارنة النواة بالنواة ، فإن Intel Skylake أفضل بكثير ، ولكن إذا نظرنا إلى مستوى النظام ، يصبح الأداء جذابًا للغاية.
ستحتوي نسخة الإنتاج من Centriq SoC على 48 نواة Falkor تعمل بترددات تصل إلى 2.6 جيجا هرتز ، مما يعطي زيادة محتملة في الأداء بنسبة 8٪.
من الواضح أن Skylake التي نختبرها ليست رائدة مثل Platinum مع 28 نواة ، ولكن هذه النوى الـ 28 تكلف الكثير وتستهلك 200 واط ، بينما نحاول تحسين التكاليف وزيادة الأداء بمقدار 1 واط.
في الوقت الحالي ، أنا قلق للغاية بشأن الأداء الضعيف للغة Go ، ولكن هذا سيتغير بمجرد أن تحتل الخوادم القائمة على ARM مكانتها في السوق.
الأداء C و LuaJIT تنافسي للغاية ، وفي كثير من الحالات أفضل من Skylake. في جميع الاختبارات تقريبًا ، أثبت Falkor أنه بديل جدير بـ Broadwell.
أكبر ميزة ل Falkor في الوقت الحالي هو انخفاض استهلاك الطاقة. على الرغم من أن TDP هو 120W ، خلال اختباراتي لم يتجاوز هذا الرقم أبدًا 89W (لاختبارات الذهاب). للمقارنة ، تجاوزت Skylake و Broadwell 160W ، في حين أن TDP الخاص بهم هو 170W.
كإعلان. هذه ليست مجرد خوادم افتراضية! هذه هي VPS (KVM) ذات محركات أقراص مخصصة ، والتي لا يمكن أن تكون أسوأ من الخوادم المخصصة ، وفي معظم الحالات - أفضل!
لقد جعلنا VPS (KVM) بمحركات مخصصة في هولندا والولايات المتحدة الأمريكية (تكوينات من VPS (KVM) - E5-2650v4 (6 نوى) / 10 جيجابايت DDR4 / 240 جيجابايت SSD أو 4 تيرابايت HDD / 1 جيجابت في الثانية 10 تيرابايت بسعر منخفض بشكل فريد - من 29 دولارًا في الشهر ، تتوفر خيارات مع RAID1 و RAID10) ، لا تفوت فرصة تقديم طلب لنوع جديد من الخادم الافتراضي ، حيث تنتمي جميع الموارد إليك ، كما هو الحال في خادم مخصص ، والسعر أقل بكثير ، مع أجهزة أكثر إنتاجية!
كيفية بناء البنية التحتية للمبنى. الطبقة باستخدام خوادم Dell R730xd E5-2650 v4 بتكلفة 9000 يورو مقابل سنت واحد؟ ديل R730xd أرخص مرتين؟ فقط لدينا
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV من 249 دولارًا في هولندا والولايات المتحدة!