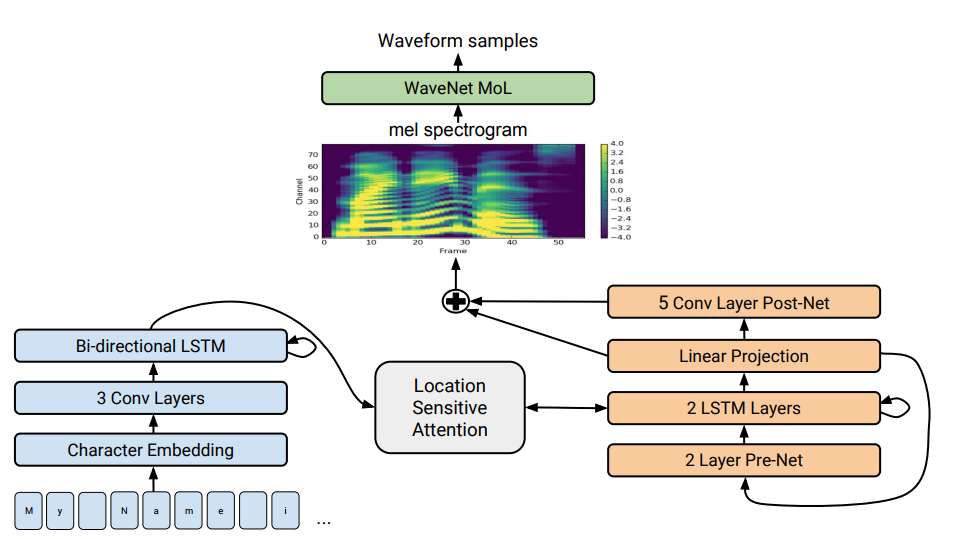
 بنية Tacotron 2. في الجزء السفلي من الرسم التوضيحي ، يتم عرض نماذج العرض إلى العرض التي تترجم سلسلة من الحروف إلى سلسلة من السمات في مساحة 80-الأبعاد. للحصول على وصف تقني انظر مقالة علمية.
بنية Tacotron 2. في الجزء السفلي من الرسم التوضيحي ، يتم عرض نماذج العرض إلى العرض التي تترجم سلسلة من الحروف إلى سلسلة من السمات في مساحة 80-الأبعاد. للحصول على وصف تقني انظر مقالة علمية.يعتبر توليف الكلام - التكاثر المصطنع لخطاب الإنسان من النص - تقليديا أحد مكونات الذكاء الاصطناعي. في السابق ، كان يمكن رؤية مثل هذه الأنظمة فقط في أفلام الخيال العلمي ، ولكنها الآن تعمل حرفياً في كل هاتف ذكي: هذه هي Siri و Alice وما شابه ذلك. لكنها ليست عبارات واقعية للغاية: صوت جامد ، يتم فصل الكلمات عن بعضها البعض.
قامت Google
بتطوير مُركب الكلام المتقدم من الجيل التالي. يطلق عليه Tacotron 2 ويقوم على شبكة عصبية. لإثبات قدراتها ، نشرت الشركة
أمثلة على التوليف . في أسفل الصفحة مع أمثلة ، يمكنك إجراء اختبار ومحاولة تحديد مكان تسليم النص بواسطة مُركِّب الكلام ومكان الشخص. يكاد يكون من المستحيل تحديد الفرق.
على الرغم من عقود من البحث ، لا يزال توليف الكلام مهمة ملحة للمجتمع العلمي. على مدى السنوات الماضية ، سادت تقنيات مختلفة في هذا المجال: تم اعتبار التوليف المتسلسل مع اختيار الأجزاء الأكثر تقدمًا مؤخرًا - عملية الجمع بين أجزاء صوتية صغيرة مسجلة مسبقًا ، بالإضافة إلى تجميع الكلام المعياري الإحصائي ، حيث يقوم المشفر بتجميع مسارات النطق السلسة. الطريقة الثانية حلت العديد من مشاكل التوليف المتسلسل مع القطع الأثرية على الحدود بين الشظايا. ومع ذلك ، في كلتا الحالتين ، بدا الصوت المركب ضبابيًا وغير طبيعي مقارنة بخطاب الإنسان.
ثم جاء محرك الصوت WaveNet (نموذج مولّد لأشكال الموجة في المجال الزمني) ، والذي كان لأول مرة قادرًا على إظهار جودة صوت مماثلة للإنسان. يتم استخدامه الآن في نظام تركيب الكلام
Deep Voice 3 .
في وقت سابق من عام 2017 ، قدمت Google
بنية Tacotron من عرض إلى عرض. يولد أطياف الاتساع من سلسلة من الشخصيات. يبسط Tacotron ناقل محرك الصوت التقليدي. هنا ، يتم إنشاء الميزات اللغوية والصوتية من خلال شبكة عصبية واحدة مدربة فقط على البيانات. تعني عبارة "جملة إلى جملة" أن الشبكة العصبية تنشئ توازناً بين سلسلة من الحروف وسلسلة من السمات لترميز الصوت. يتم إنشاء اللافتات في مطياف صوتي 80-الأبعاد بإطارات تبلغ 12.5 مللي ثانية.
تتعلم الشبكة العصبية ليس فقط نطق الكلمات ، ولكن أيضًا خصائص الصوت المحددة ، مثل الحجم والسرعة والتجويد.
ثم يتم توليد الموجات الصوتية مباشرة باستخدام خوارزمية Griffin-Lim (لتقدير الطور) وتحويل فورييه العكسي قصير المدى. كما لاحظ المؤلفون ، كان هذا حلاً مؤقتًا لإثبات قدرات الشبكة العصبية. في الواقع ، يخلق محرك WaveNet وما شابه صوتًا أفضل من خوارزمية Griffin-Lim ، وبدون قطع أثرية.
في نظام Tacotron 2 المعدل ، لا يزال المتخصصون من Google يربطون برنامج WaveNet vocoder بالشبكة العصبية. وهكذا ، تنشئ الشبكة العصبية مخططات طيفية ، ومن ثم تقوم نسخة معدلة من WaveNet بتوليد صوت عند 24 كيلو هرتز.
تتعلم الشبكة العصبية بشكل مستقل (من طرف إلى طرف) على صوت صوت بشري ، مصحوبًا بنص. ثم تقرأ الشبكة العصبية المدربة جيدًا النصوص بطريقة تجعل من المستحيل تقريبًا التمييز بين صوت الكلام البشري ، كما يمكن رؤيته في
الأمثلة الحقيقية .
لاحظ الباحثون أن نظام Deep Voice 3 يستخدم نهجًا مشابهًا ، ولكن لا يزال لا يمكن مقارنة جودة تركيبه مع الكلام البشري. ولكن يمكن لـ Tacotron 2 ، راجع نتائج اختبار متوسط درجة الرأي (MOS) في الجدول.
هناك مُركِّب كلام آخر يعمل أيضًا على شبكة عصبية - هذا هو
Char2Wav ، ولكن له بنية مختلفة تمامًا.
يقول العلماء أنه بشكل عام ، تعمل الشبكة العصبية بشكل جيد ، ولكن لا تزال تواجه صعوبة في نطق بعض الكلمات المعقدة (مثل
decorum أو
merlot ). وأحيانًا ينتج ضوضاء غريبة بشكل عشوائي - يتم الآن توضيح أسباب ذلك. بالإضافة إلى ذلك ، النظام غير قادر على العمل في الوقت الحقيقي ، ولم يتمكن المؤلفون بعد من التحكم في المحرك ، أي تعيين التجويد المطلوب له ، على سبيل المثال ، صوت سعيد أو حزين. يكتبون أن كل من هذه المشاكل مثيرة للاهتمام في حد ذاتها.
تم
نشر المقالة العلمية في 16 ديسمبر 2017 على موقع ما قبل الطباعة arXiv.org (arXiv: 1712.05884v1).