
يبدأ يومنا بعبارة "صباح الخير!". خلال النهار نتحدث مع الزملاء والأقارب والأصدقاء وحتى الغرباء الذين يسألون عن الاتجاهات إلى أقرب مترو. نتحدث حتى عندما لا يوجد أحد حولنا من أجل فهم أفضل لمنطقنا. كل هذا هو حديثنا - هدية لا تضاهى حقًا مع العديد من الاحتمالات الأخرى لجسم الإنسان. يسمح لنا الكلام بإنشاء روابط اجتماعية ، والتعبير عن الأفكار والعواطف ، والتعبير عن أنفسنا ، على سبيل المثال ، في الأغاني.
وهكذا ، ظهرت السيارات الذكية في حياة الناس. يحاول الشخص ، بدافع الفضول ، أو متعطشًا لإنجازات جديدة ، تعليم الآلة للتحدث. ولكن لكي تتكلم ، تحتاج إلى الاستماع والاستماع. في الوقت الحاضر ، من الصعب أن تفاجأ ببرنامج (على سبيل المثال Siri) يمكنه التعرف على الكلام ، والعثور على مطعم على الخريطة ، والاتصال بأمي ، وحتى إخباره بنكتة. إنها تدرك الكثير ، ليس كلها ، بالطبع ، ولكن الكثير. ولكن لم يكن الأمر كذلك دائمًا ، بطبيعة الحال. قبل عقود ، كان ذلك من أجل السعادة ، عندما تمكنت الآلة من فهم ما لا يقل عن اثنتي عشرة كلمة.
اليوم سنغوص في تاريخ كيف تمكنت البشرية من التحدث مع الآلة ، والتي كانت بمثابة اختراقات عبر القرون في هذا المجال بمثابة قوة دفع لتطوير تقنية التعرف على الكلام. كما ننظر إلى كيفية إدراك الأجهزة الحديثة لأصواتنا ومعالجتها. دعنا نذهب.
أصول التعرف على الكلام
ما هو الكلام؟ تقريبا ، هذا الصوت. لذا ، من أجل التعرف على الكلام ، تحتاج أولاً إلى التعرف على الصوت وتسجيله.
الآن لدينا أجهزة iPod ، ومشغلات MP3 ، قبل أن يكون هناك مسجلات الأشرطة ، حتى في وقت سابق من gramophones و gramophones. هذه كلها أجهزة لتشغيل الأصوات. ولكن من كان سلفهم جميعًا؟
 توماس إديسون مع اختراعه. 1878 سنة
توماس إديسون مع اختراعه. 1878 سنةكانت الفونوغراف. في 29 نوفمبر 1877 ، أظهر المخترع الكبير توماس إديسون ابتكاره الجديد القادر على تسجيل الأصوات وإعادة إنتاجها. لقد كان اختراقا أثار الاهتمام الحيوي للمجتمع.
مبدأ الفونوغراف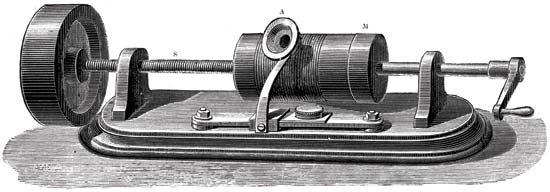
كانت الأجزاء الرئيسية لآلية التسجيل الصوتي عبارة عن أسطوانة مغطاة بالرقائق وإبرة قطع. تحركت الإبرة على طول أسطوانة تدور. وتم التقاط الاهتزازات الميكانيكية باستخدام غشاء الميكروفون. ونتيجة لذلك ، تركت الإبرة علامات على الرقاقة. نتيجة لذلك ، تلقينا اسطوانة بسجل. لإعادة إنتاجها ، تم استخدام الأسطوانة نفسها في البداية كما هو الحال عند التسجيل. لكن الرقاقة كانت هشة للغاية وتآكلت بسرعة ، لأن السجلات لم تدم طويلاً. ثم بدأوا في تطبيق الشمع الذي يغطي الاسطوانة. من أجل إطالة وجود السجلات ، بدأوا في النسخ باستخدام الطلاء الكهربائي. من خلال استخدام مواد أكثر صعوبة ، استمرت النسخ لفترة أطول.
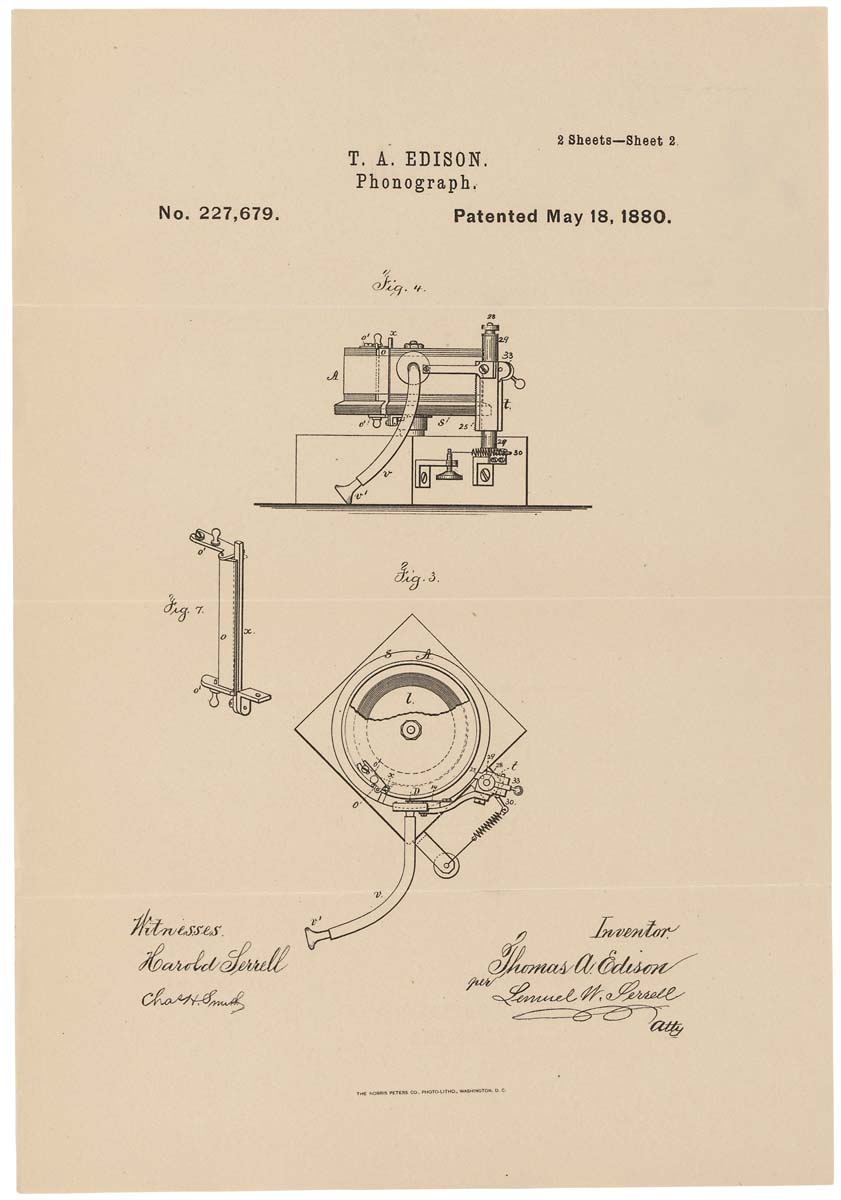 رسم تخطيطي لفونوغراف على براءة اختراع. 1880 ، 18 مايو
رسم تخطيطي لفونوغراف على براءة اختراع. 1880 ، 18 مايوبالنظر إلى العوائق المذكورة أعلاه ، الفونوغراف ، على الرغم من أنها كانت آلة مثيرة للاهتمام ، لكنها لم تنجرف بعيداً عن الرفوف. فقط مع ظهور الفونوغراف على القرص - المعروف باسم الحاكي - جاء الاعتراف العام. سمحت الجدة بعمل تسجيلات أطول (يمكن للفونوغراف الأول أن يسجل بضع دقائق فقط) ، والتي خدمت لفترة طويلة. وتم تجهيز الحاكي نفسه بمكبر صوت زاد من حجم التشغيل.
تصور توماس إديسون في الأصل الفونوغراف كجهاز لتسجيل المحادثات الهاتفية ، مثل مسجلات الصوت الحديثة. ومع ذلك ، اكتسب ابتكاره شعبية كبيرة في استنساخ الأعمال الموسيقية. وقد خدم كبداية لتشكيل صناعة التسجيل.
الكلام "الجهاز"
تشتهر شركة Bell Labs باختراعاتها في مجال الاتصالات. أحد هذه الاختراعات كان Voder.
في عام 1928 ، بدأ Homer Dudley في العمل على مشفر صوتي ، وهو جهاز قادر على تجميع الكلام. سنتحدث عنه في وقت لاحق. الآن سننظر في الجزء الخاص به - vader.
 رسم تخطيطي لفادر
رسم تخطيطي لفادركان المبدأ الأساسي للادر هو تقسيم الكلام البشري إلى مكونات صوتية. كانت الآلة معقدة للغاية ، ولا يمكن تشغيلها إلا من قبل عامل مدرب.
قام فيدر بتقليد آثار المسالك الصوتية البشرية. كان هناك صوتان رئيسيان يمكن للمستخدم اختيارهما من معصمه. تم استخدام دواسات القدم للتحكم في مولد التذبذبات المتقطعة (صوت الطنين) ، مما أدى إلى إنشاء أصوات متحركة وأصوات أنفية. خلق أنبوب تصريف الغاز (الهسهسة) الأشقاء (الحروف الساكنة الاحتكاكية). مرت جميع هذه الأصوات من خلال أحد المرشحات العشرة التي تم اختيارها بالمفاتيح. كانت هناك أيضًا مفاتيح خاصة للأصوات مثل "p" أو "d" ، وللحرفين "j" في كلمة "jaw" و "ch" في كلمة "cheese".
يوضح هذا المقتطف الصغير من عرض vader بوضوح مبدأ تشغيله وإجراءات المشغليمكن للمشغل إنتاج خطاب يمكن التعرف عليه بشكل صحيح فقط بعد عدة أشهر من التدريب والتدريب الصعب.
لأول مرة ، تم عرض الناقل في معرض في نيويورك عام 1939.
التوفير من خلال تركيب الكلام
الآن فكر في أحد المبرمجين ، والذي كان جزء منه هو السائق المذكور أعلاه.
 أحد موديلات المبرمج: HY-2 (1961)
أحد موديلات المبرمج: HY-2 (1961)كان القصد في الأصل من المبرمج حفظ موارد التردد للوصلات اللاسلكية عند إرسال الرسائل الصوتية. بدلاً من الصوت نفسه ، تم إرسال قيم معلماته المحددة ، والتي تمت معالجتها بواسطة مُركِّب الكلام في الإخراج.
كان أساس المبرمج ثلاث خصائص رئيسية:
- مولد الضجيج (الأصوات الساكنة) ؛
- مولد النغمات (حروف العلة) ؛
- مرشحات رسمية (إعادة صياغة الخصائص الفردية للمتكلم).
على الرغم من الغرض الجاد ، جذب المشغل انتباه الموسيقيين الإلكترونيين. إن تحويل إشارة المصدر وتشغيلها على جهاز آخر جعل من الممكن تحقيق مجموعة متنوعة من التأثيرات ، مثل تأثير غناء آلة موسيقية "بصوت بشري".
آلة العد
في عام 1952 ، لم تكن التقنيات متطورة كما هي الآن. لكن هذا لم يمنع العلماء المتحمسين من تحديد مهام مستحيلة لأنفسهم ، حسب الكثيرين. أيها السادة ستيفن بلاشك (S. Balashek) ورالون بيدولف (R. Biddulph) و K.Kh. قرر ديفيس (KH Davis) تعليم الآلة لفهم الكلام. بعد هذه الفكرة ، ظهرت سيارة أودري. كانت قدراتها محدودة للغاية - كان بإمكانها فقط التعرف على الأرقام من 0 إلى 9. لكن هذا كان كافياً بالفعل للإعلان بأمان عن اختراق في تكنولوجيا الكمبيوتر.
 أودري مع أحد مبدعيه (وفقًا للإنترنت ، صحح لي إذا لم يكن كذلك)
أودري مع أحد مبدعيه (وفقًا للإنترنت ، صحح لي إذا لم يكن كذلك)على الرغم من قدراته الصغيرة ، لم تستطع أودري التفاخر بنفس الأبعاد. كانت "فتاة" كبيرة نوعًا ما - كانت خزانة التتابع بارتفاع مترين تقريبًا ، وجميع العناصر احتلت غرفة صغيرة. وهو ليس مفاجئًا لأجهزة الكمبيوتر في ذلك الوقت.
كان لإجراء التفاعل بين العامل وأودري أيضًا بعض الشروط. قال عامل الهاتف الكلمات (الأرقام ، في هذه الحالة) في هاتف هاتف عادي ، تأكد من تحمل وقفة 350 مللي ثانية بين كل كلمة. قبلت أودري المعلومات وترجمتها إلى تنسيق إلكتروني وشغلت لمبة ضوء معينة تتوافق مع رقم معين. ناهيك عن حقيقة أنه لا يمكن لكل مشغل الحصول على إجابة دقيقة. لتحقيق الدقة 97٪ ، يجب أن يكون عامل الهاتف الشخص الذي كان يمارس "الثرثرة" مع Audrey لفترة طويلة. وبعبارة أخرى ، فهمت أودري فقط منشئيها.
حتى مع مراعاة جميع أوجه القصور في أودري ، والتي لا ترتبط بأخطاء التصميم ، ولكن مع قيود التكنولوجيا في تلك الأوقات ، أصبحت النجمة الأولى في أفق الآلات التي تفهم الصوت البشري.
المستقبل في صندوق الأحذية
في عام 1961 ، تم تطوير جهاز معجزة جديد في Shoebox في مختبر IBM Advanced Systems Development - وهو Shoebox ، والذي يمكنه التعرف على 16 كلمة (باللغة الإنجليزية فقط) وأرقام من 0 إلى 9. مؤلف هذا الكمبيوتر كان William C. Dersch.
 Shoebox من IBM
Shoebox من IBMيتوافق الاسم غير المعتاد مع مظهر الآلة ، وكان الحجم والشكل مثل صندوق الأحذية. الشيء الوحيد الذي لفت نظري هو الميكروفون ، الذي كان متصلاً بفلاتر الصوت الثلاثة اللازمة للتعرف على الأصوات العالية والمتوسطة والمنخفضة. تم توصيل المرشحات بجهاز فك ترميز منطقي (دائرة منطق الترانزستور الثنائي) وآلية تبديل الضوء.
جلب العامل الميكروفون إلى فمه ونطق كلمة (على سبيل المثال ، رقم 7). قامت الآلة بتحويل البيانات الصوتية إلى إشارات إلكترونية. وكانت نتيجة الفهم إدراج مصباح كهربائي يحمل توقيع "7". بالإضافة إلى فهم الكلمات الفردية ، يمكن لـ Shoebox فهم المشكلات الحسابية البسيطة (مثل 5 + 6 أو 7-3) وإعطاء الإجابة الصحيحة.
تم تقديم Shoebox بواسطة منشئه في عام 1962 في معرض سياتل العالمي.
محادثة هاتفية مع السيارة
في عام 1971 ، قررت شركة IBM ، المعروفة بحبها للاختراعات والتقنيات المبتكرة ، تطبيق ميزة التعرف على الكلام. سمح نظام التعرف التلقائي على المكالمات للمهندس الموجود في أي مكان في الولايات المتحدة بالاتصال بجهاز كمبيوتر في رالي ، نورث كارولينا. يمكن للمتصل طرح سؤال وتلقي إجابة صوتية عليه. كان تفرد هذا النظام في فهم الأصوات العديدة ، نظرًا لنغميتها ، وتركيزها ، وحجم الكلام ، وما إلى ذلك.
ارتفاع Harpy عالية
أعلن مكتب مشاريع البحث المتقدم بوزارة الدفاع (DARPA اختصارًا) عن إطلاق برنامج تطوير التعرف على الكلام والبحث في عام 1971 يهدف إلى إنشاء آلة يمكنها التعرف على 1000 كلمة. مشروع جريء بالنظر إلى نجاحات سلفه بعشرات الكلمات. لكن ليس هناك حد لحيلة الإنسان. وفي عام 1976 ، أظهرت جامعة كارنيجي ميلون Harpy ، قادرة على التعرف على 1011 كلمة.
مظاهرة فيديو هاربيلقد طورت الجامعة بالفعل أنظمة التعرف على الكلام - Hearsay-1 و Dragon. تم استخدامها كأساس لتنفيذ Harpy.
في Hearsay-1 ، يتم تمثيل المعرفة (أي قاموس آلي) في شكل إجراءات ، وفي Dragon - في شكل شبكة ماركوف مع انتقال احتمالي مسبق. في Harpy ، تقرر استخدام أحدث طراز ، ولكن بدون هذا التحول.
في هذا الفيديو ، تم وصف مبدأ التشغيل بمزيد من التفصيل.
ببساطة ، يمكنك تصوير شبكة - سلسلة من الكلمات ومجموعاتها ، بالإضافة إلى أصوات بكلمة واحدة ، لكي يفهم الجهاز النطق المختلف للكلمة نفسها.
فهم Harpy 5 مشغلين ، بما في ذلك ثلاثة رجال وامرأتين. تحدث عن قدرات الحوسبة أكبر لهذا الجهاز. كانت دقة التعرف على الكلام حوالي 95٪.
Tangora بواسطة IBM
في أوائل الثمانينيات ، قررت شركة IBM تطوير نظام قادر على التعرف على أكثر من 20000 كلمة بحلول منتصف العقد. لذلك ولدت Tangora ، في العمل الذي تم استخدام نماذج ماركوف المخفية. على الرغم من المفردات المثيرة للإعجاب إلى حد ما ، لم يتطلب النظام أكثر من 20 دقيقة من التعاون مع العامل الجديد (الشخص المتحدث) من أجل تعلم كيفية التعرف على خطابه.
دمية حية
في عام 1987 ، أصدرت شركة لعبة Worlds of Wonder لعبة جديدة مبتكرة - دمية ناطقة باسم Julie. كانت الميزة الأكثر إثارة للإعجاب في اللعبة الدنماركية هي القدرة على تدريبها على التعرف على خطاب المالك. يمكن جولي التحدث بشكل جيد. بالإضافة إلى ذلك ، تم تجهيز الدمية بالعديد من أجهزة الاستشعار ، والتي بفضلها تفاعلت عندما تم التقاطها أو دغدغتها أو نقلها من غرفة مظلمة إلى غرفة مشرقة.
عوالم العجائب التجارية جولي تعرض ملامحهاكانت عيناها وشفتيها متحركتين ، مما خلق صورة أكثر حيوية. بالإضافة إلى الدمية نفسها ، كان من الممكن شراء كتاب يتم فيه صنع الصور والكلمات على شكل ملصقات خاصة. إذا حملت الدمى بأصابعك فوقها ، فسوف تسمع ما تشعر به عند لمسه. كان Doll Julie أول جهاز مزود بوظيفة التعرف على الكلام ، والتي كانت متاحة لأي شخص.
برنامج الإملاء الأول

في عام 1990 ، أصدرت Dragon Systems أول برنامج كمبيوتر شخصي يعتمد على التعرف على الكلام - DragonDictate. عمل البرنامج بشكل حصري على Windows. كان على المستخدم إجراء فترات توقف صغيرة بين كل كلمة حتى يتمكن البرنامج من تحليلها. في المستقبل ، ظهر إصدار أكثر مثالية يسمح لك بالتحدث بشكل مستمر - Dragon NaturallySpeaking (إنه متاح الآن ، بينما توقف DragonDictate الأصلي عن التحديث منذ Windows 98). على الرغم من "البطء" ، اكتسبت DragonDictate شعبية كبيرة بين مستخدمي الكمبيوتر ، خاصة بين الأشخاص ذوي الإعاقة.
أبو الهول غير المصري
أصبحت جامعة كارنيجي ميلون ، التي "أضاءت" بالفعل في وقت سابق ، مهد نظام آخر مهم للتعرف على الكلام تاريخياً - Sphinx 2.
 خالق أبو الهول Xuedong هوانغ
خالق أبو الهول Xuedong هوانغكان المؤلف المباشر للنظام هو Xuedong Huang. تميز أبو الهول 2 عن سلفه بسرعته. ركز النظام على التعرف على الكلام في الوقت الحقيقي للبرامج التي تستخدم لغة منطوقة (كل يوم). من بين سمات Sphinx 2: تشكيل الفرضية ، والتبديل الديناميكي بين النماذج اللغوية ، واكتشاف المعادلات ، وما إلى ذلك.
تم استخدام رمز أبو الهول 2 في العديد من المنتجات التجارية. وفي عام 2000 ، نشر Kevin Lenzo ، على موقع SourceForge ، كود المصدر للنظام للعرض العام. يمكن لأولئك الذين يرغبون في دراسة الكود المصدري لأبو الهول 2 وتنويعاته الأخرى اتباع
الرابط .
الاملاء الطبي
في عام 1996 ، أطلقت شركة آي بي إم MedSpeak ، أول منتج تجاري مع التعرف على الكلام. كان من المفترض استخدام هذا البرنامج في الأطباء لتجميع السجلات الطبية. على سبيل المثال ، عبرت أخصائي الأشعة بفحص صور المريض عن تعليقاتها ، والتي ترجمها نظام MedSpeak إلى نص.
قبل الانتقال إلى أشهر ممثلي البرامج مع التعرف على الكلام ، دعنا نلقي نظرة سريعة وبإيجاز على بعض الأحداث التاريخية الأخرى المتعلقة بهذه التقنية.
غارة تاريخية
- 2002 - تقوم Microsoft بدمج التعرف على الكلام في جميع منتجات Office الخاصة بها ؛
- 2006 - بدأت وكالة الأمن القومي الأمريكية في استخدام برامج التعرف على الكلام لتحديد الكلمات الأساسية المحددة في سجلات المحادثات ؛
- 2007 (30 يناير) - أصدرت Microsoft Windows Vista - أول نظام تشغيل مع التعرف على الكلام ؛
- 2007 - تقدم Google GOOG-411 - نظام إعادة توجيه الهاتف (يقوم شخص بالاتصال برقم ويقول المنظمة أو الشخص الذي يحتاجه والنظام الذي يربطهم). عمل النظام داخل الولايات المتحدة وكندا ؛
- 2008 (14 نوفمبر) - أطلقت Google البحث الصوتي على أجهزة iPhone المحمولة. كان هذا أول استخدام لتكنولوجيا التعرف على الكلام في الهواتف المحمولة.
والآن نأتي إلى الفترة الزمنية التي صادف فيها الكثير من الأشخاص تقنية التعرف على الكلام.
السيدات لا يتشاجرون
في 4 أكتوبر 2011 ، أعلنت شركة Apple عن Siri ، حيث يتفكك تشفير الاسم الذي تتحدث عنه - واجهة تفسير الكلام والتعرف عليه (أي واجهة التفسير والتعرف على الكلام).

إن تاريخ تطوير Siri طويل جدًا (في الواقع ، لديه 40 عامًا من العمل) ومثير للاهتمام. حقيقة وجودها ووظائفها الواسعة هي العمل المشترك للعديد من الشركات والجامعات. ومع ذلك ، لن نركز على هذا المنتج ، لأن المقالة ليست حول Siri ، ولكن حول التعرف على الكلام بشكل عام.
لم ترغب Microsoft في رعاية الظهر ، لأنها أعلنت في عام 2014 (2 أبريل) عن مساعدها الرقمي الافتراضي Cortana.

تتشابه وظائف Cortana مع منافستها Siri ، باستثناء نظام أكثر مرونة لتحديد الوصول إلى المعلومات.
مناظرة حول Cortana أو Siri. من الأفضل "؟ أجريت منذ ظهورها في السوق. بشكل عام ، والصراع بين مستخدمي iOS و Android. لكن هذا جيد. المنتجات المنافسة ، في محاولة لتبدو أفضل من منافسيها ، ستوفر المزيد والمزيد من الفرص الجديدة ، وتطوير واستخدام تقنيات وتقنيات أكثر تقدمًا في نفس مجال التعرف على الكلام. وجود ممثل واحد فقط في أي مجال من مجالات التكنولوجيا الاستهلاكية ، ليست هناك حاجة للحديث عن تطورها السريع.
فيديو مضحك قليلاً للمحادثة بين سيري وكورتانا (من الواضح أنه بني ، ولكن ليس أقل مرحًا). انتباه!: في هذا الفيديو هناك تجديف.
محادثة مع السيارات. كيف يفهموننا؟
كما ذكرت سابقًا ، الكلام تقريبًا سليم. وما هو صوت السيارة؟ هذه هي التغييرات (التقلبات) في ضغط الهواء ، أي موجات صوتية. لكي يتمكن الجهاز (الكمبيوتر أو الهاتف) من التعرف على الكلام ، يجب عليك أولاً قراءة هذه الاهتزازات. يجب أن يكون تردد القياس على الأقل 8000 مرة في الثانية (والأفضل - 44100 مرة في الثانية). إذا تم تنفيذ القياسات مع انقطاعات زمنية كبيرة ، فسوف نحصل على صوت غير دقيق ، مما يعني الكلام غير المقروء. يشار إلى العملية الموضحة أعلاه بالرقمنة 8 كيلو هرتز أو 44.1 كيلو هرتز.
عندما يتم جمع البيانات حول اهتزازات الموجات الصوتية ، يجب فرزها. نظرًا لأننا في كومة الذاكرة المؤقتة لدينا كلًا من أصوات الكلام والأصوات الثانوية (ضوضاء الجهاز وورقة السرقة وصوت جهاز كمبيوتر يعمل ، وما إلى ذلك). يسمح لنا إجراء العمليات الرياضية بالقضاء على كلامنا بدقة ، والذي يحتاج إلى الاعتراف.
التالي هو تحليل الموجة الصوتية المختارة - الكلام. لأنه يتكون من العديد من المكونات المنفصلة التي تشكل أصواتًا معينة (على سبيل المثال ، "ah" أو "ee"). يسمح لك إبراز هذه الميزات وتحويلها إلى مكافئات عددية بتحديد كلمات معينة.
تتكون اللغة الإنجليزية ، على سبيل المثال ، من أكثر من 40 صوتًا (44 ، على وجه الدقة ، ووفقًا لبعض النظريات هناك أكثر من 100) ، أي أصوات الكلام. تحددها الآلة جميعًا ، لأنه في عملية تطويرها ، تم إجراء اختبارات التدريب ، حيث نطق أشخاص مختلفون بنفس الكلمات والعبارات. لذلك يمكن للآلة تحديد أوجه التشابه والاختلاف وتشكيل خوارزمية لتحديد الأصوات. يجدر النظر في حقيقة أن كيفية تأثر "المظهر" السليم لا يتأثر فقط بالشخص (أو بالأحرى ، نطقه ، لهجته ، جرس الصوت ، إلخ) ، ولكن أيضًا بمزيج من الأصوات المختلفة في كلمة واحدة. على سبيل المثال ، "t" في "sTar" و "t" في "ciTy" لتبدو السيارة مختلفة تمامًا.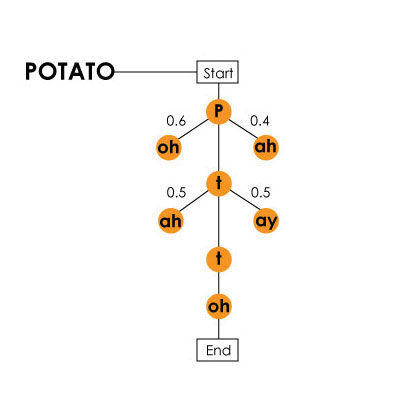 نموذج ماركوف باستخدام كلمة "بطاطس" (كارتل) كمثال / موجود في الفيديو حول نظام هاربيعلاوة على ذلك ، يجب على الكمبيوتر ، باتباع نماذج تشكيل التسلسل اللفظي ، تحديد المكان الذي يستحق فيه فصل الكلمات. على سبيل المثال ، هناك عبارة "hang ten" لا يمكن للكمبيوتر تقسيمها بهذه الطريقة - "hey، ngten" ، لأنه لا يمكنه العثور على تطابقات في قاعدة بياناته مع "ngten".لكي لا يعطي الكمبيوتر هراء بدلاً من العبارة المذكورة ، يحتاج إلى فهم الكلمات التي تذهب بعدها. لهذا ، لا يتم استخدام قاعدة المعرفة فقط لتحديد العبارات المكونة (الكلمات) ، ولكن أيضًا خوارزمية فرضية جزئية تحدد بها الآلة ما إذا كانت الكلمة رقم 2 مناسبة بالاقتران مع الكلمة رقم 1. عبارة "ماذا تحب القطط على الفطور؟" يمكن أن يسمع باسم "ضوء الغاز أربعة طوب واسع؟". براد ، صحيح. لمنع مثل هذه الأخطاء ، هناك حاجة إلى الخوارزمية الموصوفة أعلاه. يمكن أن تأخذ أيضًا في الاعتبار إمكانية الجمع بين الكلمات التي ، وفقًا لمنطق الآلة ، لا ينبغي دمجها. لكن هذا التحسين في نموذج خوارزمية الفرضية يتطلب المزيد من القوة.بعد الانتهاء من جميع هذه الإجراءات الحسابية والإحصائية والقياسية المعقدة ، يعطي الكمبيوتر المستخدم النتيجة. كل جمال هذه التقنية ، أو بالأحرى هذه التقنية في هذه المرحلة من تطورها ، تكمن في السرعة المذهلة للنظام.
نموذج ماركوف باستخدام كلمة "بطاطس" (كارتل) كمثال / موجود في الفيديو حول نظام هاربيعلاوة على ذلك ، يجب على الكمبيوتر ، باتباع نماذج تشكيل التسلسل اللفظي ، تحديد المكان الذي يستحق فيه فصل الكلمات. على سبيل المثال ، هناك عبارة "hang ten" لا يمكن للكمبيوتر تقسيمها بهذه الطريقة - "hey، ngten" ، لأنه لا يمكنه العثور على تطابقات في قاعدة بياناته مع "ngten".لكي لا يعطي الكمبيوتر هراء بدلاً من العبارة المذكورة ، يحتاج إلى فهم الكلمات التي تذهب بعدها. لهذا ، لا يتم استخدام قاعدة المعرفة فقط لتحديد العبارات المكونة (الكلمات) ، ولكن أيضًا خوارزمية فرضية جزئية تحدد بها الآلة ما إذا كانت الكلمة رقم 2 مناسبة بالاقتران مع الكلمة رقم 1. عبارة "ماذا تحب القطط على الفطور؟" يمكن أن يسمع باسم "ضوء الغاز أربعة طوب واسع؟". براد ، صحيح. لمنع مثل هذه الأخطاء ، هناك حاجة إلى الخوارزمية الموصوفة أعلاه. يمكن أن تأخذ أيضًا في الاعتبار إمكانية الجمع بين الكلمات التي ، وفقًا لمنطق الآلة ، لا ينبغي دمجها. لكن هذا التحسين في نموذج خوارزمية الفرضية يتطلب المزيد من القوة.بعد الانتهاء من جميع هذه الإجراءات الحسابية والإحصائية والقياسية المعقدة ، يعطي الكمبيوتر المستخدم النتيجة. كل جمال هذه التقنية ، أو بالأحرى هذه التقنية في هذه المرحلة من تطورها ، تكمن في السرعة المذهلة للنظام.الخاتمة
كما نرى ، بدأت هذه التكنولوجيا الحديثة والمذهلة رحلتها منذ فترة طويلة. مرة أخرى في القرن قبل الماضي. إذا كان شخص ما سيقول في تلك الأيام أنه في المستقبل سيكون من الممكن التحدث مع الهاتف (ناهيك عن حقيقة أنه لاسلكي) ، فلن يصدقه أحد. ومن المحتمل أن يُعالج صاحب هذه البيانات بالقوة في المستشفى المناسب. ولكن الآن أصبحت هذه التكنولوجيا شائعة مثل الهواتف الذكية وأجهزة الكمبيوتر المحمولة والإنترنت وأكثر من ذلك بكثير. قد لا تتذكر الأجيال القادمة أنه ذات مرة ، لا تستطيع الآلات التحدث إلى شخص.كإعلان. اسرع للاستفادة من العرض المثير في العام الجديد واحصل على خصم 25 ٪ على الدفعة الأولى عند الطلب لمدة 3 أو 6 أشهر!
هذه ليست مجرد خوادم افتراضية! هذه هي VPS (KVM) ذات محركات أقراص مخصصة ، والتي لا يمكن أن تكون أسوأ من الخوادم المخصصة ، وفي معظم الحالات - أفضل! لقد جعلنا VPS (KVM) بمحركات مخصصة في هولندا والولايات المتحدة الأمريكية (تكوينات من VPS (KVM) - E5-2650v4 (6 نوى) / 10 جيجابايت DDR4 / 240 جيجابايت SSD أو 4 تيرابايت HDD / 1 جيجابت في الثانية 10 تيرابايت بسعر منخفض بشكل فريد - من 29 دولارًا في الشهر ، تتوفر خيارات مع RAID1 و RAID10) ، لا تفوت فرصة تقديم طلب لنوع جديد من الخادم الافتراضي ، حيث تنتمي جميع الموارد إليك ، كما هو الحال في خادم مخصص ، والسعر أقل بكثير ، مع أجهزة أكثر إنتاجية!كيفية بناء البنية التحتية للمبنى. الطبقة باستخدام خوادم Dell R730xd E5-2650 v4 بتكلفة 9000 يورو مقابل سنت واحد؟ ديل R730xd أرخص مرتين؟ فقط معنا2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV من 249 دولارًا في هولندا والولايات المتحدة!