مرحبا يا هبر! أخيرًا ، انتظرنا جزءًا آخر من سلسلة المواد من خريج
أخصائي البيانات الضخمة وبرامج
التعلم العميق ، سيريل دانيلوك ، حول استخدام Mask R-CNN ، الشبكات العصبية الشائعة حاليًا ، كجزء من نظام لتصنيف الصور ، وهي تقييم جودة الطبق المحضر باستخدام مجموعة بيانات من أجهزة الاستشعار.
بعد فحص مجموعة بيانات اللعبة التي تتكون من صور لإشارات الطرق في
المقالة السابقة ، يمكننا الآن المضي قدمًا في حل المشكلة التي واجهتها في الحياة الواقعية:
"هل من الممكن تنفيذ خوارزمية التعلم العميق ، والتي يمكن أن تميز الأطباق عالية الجودة عن الأطباق السيئة في وقت واحد صور؟ " . باختصار ، أرادت الشركة ما يلي:
ما يمثله النشاط التجاري عندما يفكر في التعلم الآلي:هذا مثال على مشكلة تم طرحها بشكل غير صحيح: في هذه الحالة من المستحيل تحديد ما إذا كان الحل موجودًا ، سواء كان فريدًا ومستقرًا. علاوة على ذلك ، فإن بيان المشكلة نفسها غامض للغاية ، ناهيك عن تنفيذ حلها. بالطبع ، هذه المقالة ليست مكرسة لفعالية الاتصالات أو إدارة المشاريع ، ولكن من المهم أن نلاحظ:
لا تأخذ على الإطلاق المشاريع التي لا يتم فيها تحديد النتيجة النهائية وتسجيلها في بيان العمل. تتمثل إحدى الطرق الأكثر موثوقية للتعامل مع مثل هذه الشكوك في بناء نموذج أولي أولاً ، ثم باستخدام المعارف الجديدة ، هيكلة بقية المهمة. هذا ما فعلناه.
بيان المشكلة
في نموذجي الأولي ، ركزت على طبق واحد من القائمة - عجة - وبنيت خط أنابيب قابل للتحجيم ، والذي يحدد "جودة" العجة عند الإخراج. يمكن وصف ذلك بمزيد من التفصيل على النحو التالي:
- نوع المشكلة: تصنيف متعدد الفئات مع 6 فئات جودة منفصلة: جيدة (جيدة) ، صفار مكسور (مع صفار منتشر) ، محمص ( مفرط النضج ) ، اثنان_بيض (بيضتان) ، أربعة_بيض (أربع بيضات) ، قطع في غير مكانها (مع قطع متناثرة على لوحة) .
- مجموعة البيانات: 351 صورة تم جمعها يدويًا للعجّات المختلفة. عينات التدريب / التحقق / الاختبار: 139/32/180 صورة مختلطة.
- تصنيفات الفصل: كل صورة تتوافق مع تصنيف فصل يتوافق مع التقييم الذاتي لجودة العجة.
- متري: إنتروبيا مقطعية.
- الحد الأدنى من معرفة المجال: يجب أن تبدو العجة "عالية الجودة" على هذا النحو: فهي تتكون من ثلاث بيضات ، وكمية صغيرة من لحم الخنزير المقدد ، وورقة بقدونس في المركز ، لا تحتوي على صفار صفراء وقطع مطبوخة بشكل مفرط. أيضًا ، يجب أن تبدو التركيبة الشاملة "جيدة" ، أي أن القطع لا يجب أن تكون مبعثرة في جميع أنحاء الطبق.
- معيار الإنجاز: أفضل قيمة للانتروبيا في عينة الاختبار بين جميع ما يمكن بعد أسبوعين من تطوير النموذج الأولي.
- طريقة التصور النهائي: t-SNE على مساحة البيانات ذات البعد الأصغر.
 إدخال الصور
إدخال الصورالهدف الرئيسي من خط الأنابيب هو تعلم الجمع بين عدة أنواع من الإشارات (على سبيل المثال ، صور من زوايا مختلفة ، خريطة حرارية ، وما إلى ذلك) ، بعد تلقي تمثيل مضغوط مسبقًا لكل منها وتمرير هذه الميزات من خلال مصنف الشبكة العصبية للتنبؤ النهائي. لذا ، يمكننا تحقيق نموذجنا الأولي وجعله قابلاً للتطبيق عمليًا في المزيد من العمل. فيما يلي بعض الإشارات المستخدمة في النموذج الأولي:
- أقنعة المكونات الرئيسية (Mask R-CNN): Signal No. 1 .
- عدد المكونات الرئيسية في الإطار ، الإشارة رقم 2 .
- لوحة RGB ذات عجة بدون خلفية. من أجل البساطة ، قررت عدم إضافتها إلى النموذج حتى الآن ، على الرغم من أنها الإشارة الأكثر وضوحًا: في المستقبل ، يمكنك تدريب الشبكة العصبية التلافيفية للتصنيف باستخدام بعض وظائف فقدان ثلاثية كافية ، وحساب تضمين الصور وقطع المسافة L2 عن التيار صور مثالية. لسوء الحظ ، لم تتح لي الفرصة لاختبار هذه الفرضية ، حيث تتكون عينة الاختبار من 139 كائنًا فقط.
نظرة عامة على خط الأنابيب
ألاحظ أنه سيتعين علي تخطي العديد من الخطوات المهمة ، مثل تحليل البيانات الاستكشافية ، وبناء مصنف أساسي ووضع العلامات النشطة (مصطلحي المقترح ، والذي يعني التعليق التوضيحي شبه التلقائي للكائنات ، المستوحى من
الفيديو التوضيحي المضلع Polygon-RNN ) لـ Mask R-CNN (المزيد عن هذا في المنشورات التالية).
ألق نظرة على خط الأنابيب بالكامل بشكل عام:
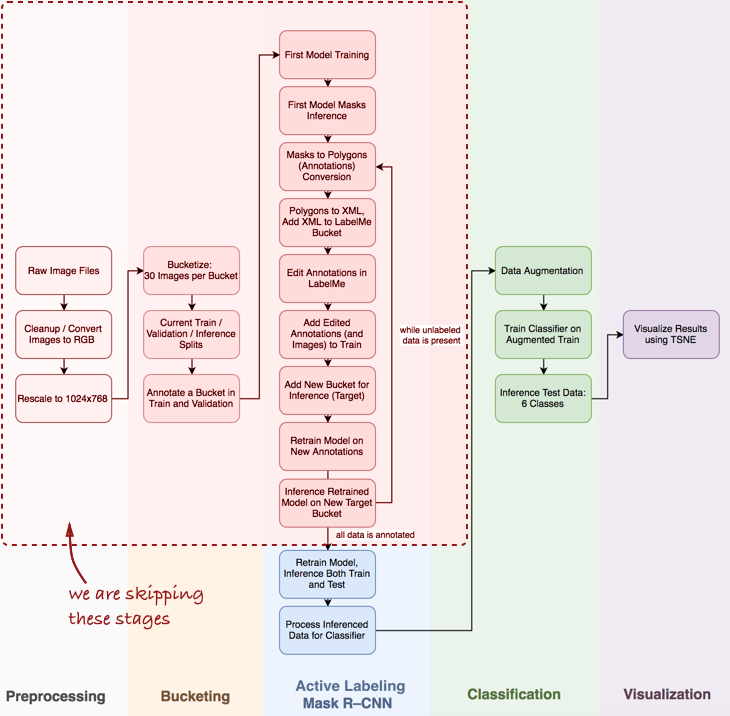 في هذه المقالة ، نحن مهتمون بمراحل Mask R-CNN والتصنيف ضمن خط الأنابيب.
في هذه المقالة ، نحن مهتمون بمراحل Mask R-CNN والتصنيف ضمن خط الأنابيب.بعد ذلك ، سننظر في ثلاث مراحل: 1) استخدام Mask R-CNN لبناء أقنعة مكونات العجة ؛ 2) مصنف ConvNet استنادًا إلى Keras ؛ 3) تصور النتائج باستخدام t-SNE.
المرحلة 1: قناع R-CNN وأقنعة البناء
كان قناع R-CNN (MRCNN) مؤخرًا في ذروة الشعبية. بدءًا من
مقالة Facebook الأصلية وانتهاءً بـ
Data Science Bowl 2018 في Kaggle ، أثبت Mask R-CNN نفسه على أنه بنية قوية لتجزئة المثال (على سبيل المثال ، ليس فقط تقسيم صورة بكسل تلو الآخر ، ولكن أيضًا فصل العديد من الكائنات التي تنتمي إلى نفس الفئة ) بالإضافة إلى ذلك ، من دواعي سروري العمل على
تنفيذ MRCNN من Matterport في Keras. الشفرة منظمة بشكل جيد ، ولديها وثائق جيدة ، وتعمل فور إخراجها من العلبة ، وإن كان ذلك أبطأ من المتوقع.
من الناحية العملية ، خاصة عند تطوير نموذج أولي ، من المهم أن يكون لديك شبكة عصبية تلافيفية مدربة مسبقًا. في معظم الحالات ، تكون مجموعة البيانات التي تم وضع علامة عليها لعالم البيانات محدودة جدًا أو لا تكون على الإطلاق ، بينما تتطلب ConvNet الكثير من البيانات التي تم وضع علامات عليها لتحقيق التقارب (على سبيل المثال ، تحتوي مجموعة بيانات ImageNet على 1.2 مليون صورة ذات علامات). هنا يأتي
التعلم عن طريق الإنقاذ: يمكننا إصلاح وزن الطبقات التلافيفية وإعادة التدريب فقط على المصنف. يعد تثبيت الطبقات التلافيفية أمرًا مهمًا لمجموعات البيانات الصغيرة ، حيث تمنع هذه التقنية إعادة التدريب.
إليكم ما حصلت عليه بعد الحقبة الأولى من إعادة التدريب:
 نتيجة تجزئة الكائن: التعرف على جميع المكونات الرئيسية
نتيجة تجزئة الكائن: التعرف على جميع المكونات الرئيسيةفي المرحلة التالية من خط الأنابيب (معالجة
البيانات المستنبطة للمُصنف ) ، من الضروري قطع جزء الصورة الذي يحتوي على اللوحة واستخراج القناع الثنائي الأبعاد لكل مكون على هذه اللوحة:
 صورة مقطوعة مع مكونات رئيسية في شكل أقنعة ثنائية.
صورة مقطوعة مع مكونات رئيسية في شكل أقنعة ثنائية.يتم بعد ذلك دمج هذه الأقنعة الثنائية في صورة ذات 8 قنوات (حيث حددت 8 فئات أقنعة لـ MRCNN) ، ونحصل على
الإشارة رقم 1 :
 الإشارة رقم 1 : صورة 8 قنوات تتكون من أقنعة ثنائية. بالألوان لتحسين التصور.
الإشارة رقم 1 : صورة 8 قنوات تتكون من أقنعة ثنائية. بالألوان لتحسين التصور.للحصول على
الإشارة رقم 2 ، قمت بحساب عدد المرات التي تم فيها العثور على كل مكون في محصول اللوحة وحصلت على مجموعة من ناقلات الميزات ، كل منها يتوافق مع محصوله.
المرحلة 2: مصنف ConvNet في Keras
تم تنفيذ مصنف CNN من الصفر باستخدام Keras. كنت أرغب في الجمع بين عدة إشارات (
الإشارة رقم 1 والإشارة رقم 2 ، بالإضافة إلى إمكانية إضافة البيانات في المستقبل) والسماح للشبكات العصبية باستخدامها لوضع توقعات بشأن جودة الطبق. العمارة المعروضة أدناه تجريبية وبعيدة عن المثالية:

بضع كلمات حول هندسة المصنف:
- الوحدة التلافيفية متعددة المستويات : اخترت في البداية مرشح 5x5 للطبقات التلافيفية ، لكن هذا أدى فقط إلى نتيجة مرضية. تم تحقيق التحسينات من خلال تطبيق AveragePooling2D على عدة طبقات مع مرشحات مختلفة: 3x3 ، 5x5 ، 7x7 ، 11x11. تمت إضافة طبقة تلافيفية إضافية 1x1 أمام كل طبقة لتقليل البعد. هذا المكون يشبه إلى حد ما وحدة Inception ، على الرغم من أنني لم أخطط لبناء شبكة عميقة جدًا.
- فلاتر أكبر : استخدمت فلاتر أكبر ، لأنها تساعد على استخراج علامات أكبر بسهولة من الصورة المدخلة (والتي هي في الأساس طبقة تنشيط مع 8 فلاتر - يمكن اعتبار قناع كل مكون كمرشح منفصل).
- الجمع بين الإشارات : في عملي الساذج ، تم استخدام طبقة واحدة فقط تربط مجموعتين من السمات: الأقنعة الثنائية المعالجة ( الإشارة رقم 1 ) والمكونات المحسوبة ( الإشارة رقم 2 ). ومع ذلك ، على الرغم من بساطتها ، فإن إضافة الإشارة رقم 2 جعلت من الممكن تقليل مقياس الإنتروبيا المتقاطع من 0.8 إلى [0.7 ، 0.72] .
- Logits : من حيث TensorFlow ، logit عبارة عن طبقة يتم فيها تطبيق tf.nn.softmax_cross_entropy_with_logits لحساب خسارة الدفعة .
المرحلة 3: تصور النتائج باستخدام t-SNE
لتصور نتائج المصنف على بيانات الاختبار ، استخدمت t-SNE - خوارزمية تسمح لك بنقل البيانات المصدر إلى مساحة ذات أبعاد أقل (لفهم مبدأ الخوارزمية ، أوصي بقراءة
المقالة الأصلية ، وهي غنية بالمعلومات ومكتوبة بشكل جيد).
قبل التخيل ، التقطت صورًا للاختبار ، واستخرجت طبقة المنطق من المصنف وطبقت خوارزمية t-SNE على مجموعة البيانات هذه. على الرغم من أنني لم أجرب قيمًا مختلفة لمعلمة الحيرة ، فإن النتيجة لا تزال تبدو جيدة جدًا:
 نتيجة t-SNE على بيانات الاختبار مع توقعات المصنف
نتيجة t-SNE على بيانات الاختبار مع توقعات المصنفبالطبع ، هذا النهج غير كامل ، لكنه يعمل. قد تكون هناك بعض التحسينات الممكنة:
- المزيد من البيانات. تتطلب شبكات الالتفاف الكثير من البيانات ، ولم يكن لدي سوى 139 صورة للتدريب. تقنيات مثل تكبير البيانات تعمل بشكل جيد (استخدمت D4 أو تكبير ثنائي متماثل ، مما أدى إلى أكثر من ألفي صورة) ، ولكن لا يزال الحصول على بيانات أكثر واقعية أمرًا بالغ الأهمية.
- وظيفة خسارة أكثر ملاءمة. من أجل البساطة ، استخدمت الإنتروبيا القاطعة ، وهو أمر جيد لأنه يعمل مباشرة خارج الصندوق. سيكون الخيار الأفضل هو استخدام وظيفة الخسارة ، والتي تأخذ في الاعتبار الاختلاف داخل الفئات ، على سبيل المثال ، وظيفة الخسارة الثلاثية (انظر مقالة FaceNet ).
- تحسين هندسة المصنف. المصنف الحالي هو في الأساس نموذج أولي ، الغرض الوحيد منه هو بناء أقنعة ثنائية ودمج عدة مجموعات من الميزات لتشكيل خط أنابيب واحد.
- تحسين تخطيط الصورة. لقد كنت قذرًا جدًا عند ترميز الصور يدويًا: قام المصنف بهذه المهمة أفضل مني في اثني عشر صورة اختبار.
الخلاصة يجب أن يتم الاعتراف أخيرًا بأن الشركة ليس لديها بيانات ، ولا تفسيرات ، ولا حتى مهمة أكثر وضوحًا تحتاج إلى حل. وهذا أمر جيد (بخلاف ذلك ، لماذا يحتاجون إليك؟) ، لأن عملك هو استخدام أدوات متنوعة ومعالجات متعددة النواة ونماذج مدربة مسبقًا وخليط من الخبرة الفنية والتجارية لخلق قيمة إضافية في الشركة.
ابدأ بشكل صغير: يمكن إنشاء نموذج أولي يعمل من عدة كتل ألعاب من التعليمات البرمجية ، وسيزيد بشكل كبير من إنتاجية المزيد من المحادثات مع إدارة الشركة. هذا هو عمل عالم البيانات - لتقديم مناهج وأفكار تجارية جديدة.
يبدأ 20 سبتمبر 2018
"Big Data Specialist 9.0" ، حيث ستتعلم ، من بين أمور أخرى ، كيفية تصور البيانات وفهم منطق العمل وراء هذه المهمة أو تلك ، مما سيساعد على تقديم نتائج عملك بشكل أكثر فعالية إلى الزملاء والإدارة.