نشرنا في مدونتنا عن حبري ترجمات معدلة لمواد من مدونة فايننشال هاكر ، مكرسة لأسئلة إنشاء استراتيجيات للتداول في البورصة. ناقشنا في وقت سابق
البحث عن أوجه القصور في السوق ، وإنشاء
نماذج لاستراتيجيات التداول ،
ومبادئ البرمجة الخاصة بها .
سنركز اليوم على استخدام مناهج التعلم الآلي لتحسين كفاءة أنظمة التداول.
كان أول كمبيوتر يفوز ببطولة الشطرنج العالمية هو ديب بلو. كان ذلك في عام 1996 ، ومرت عشرين سنة أخرى قبل أن يتمكن برنامج آخر ، Alpha Go ، من هزيمة أفضل لاعب في Go. كان Deep Blue نظامًا موجهًا نحو النموذج مع قواعد شطرنج مدمجة. AplhaGo هو نظام لاستخراج البيانات ، وهو شبكة عصبية عميقة ، تم تدريبها باستخدام آلاف الألعاب في Go. أي ، من أجل اتخاذ خطوة من الانتصارات على الأشخاص الذين هم أبطال في لعبة الشطرنج ، للسيطرة على أفضل اللاعبين في Go ، لم يكن من الضروري أن تكون قطعة حديد محسنة ، ولكن اختراقًا في مجال البرمجيات.
في المقالة الحالية ، سننظر في تطبيق نهج استخراج البيانات لإنشاء استراتيجيات التداول. لا تأخذ هذه الطريقة في الاعتبار آليات السوق ؛ فهي ببساطة تقوم بمسح منحنيات الأسعار ومصادر البيانات الأخرى للبحث عن الأنماط التنبؤية. لا يلزم دائمًا التعلم الآلي أو "الذكاء الاصطناعي" لهذا الغرض. على العكس من ذلك ، في كثير من الأحيان ، تعمل الأساليب الأكثر شيوعًا والأكثر ربحية لاستخراج البيانات دون أي زخرفة في شكل شبكات عصبية أو دعم لطرق المتجه.
مبادئ التعلم الآلي
يتم تغذية الخوارزمية المدربة بعينات من البيانات ، وعادة ما يتم استخراجها بطريقة أو بأخرى من أسعار الصرف التاريخية. تتكون كل عينة من المتغيرات n x1 ... xn ، والتي تسمى عادةً المتنبئات أو الوظائف أو الإشارات أو ببساطة بيانات الإدخال. يمكن لهذه التنبؤات أن تكون أسعار الأشرطة n الأخيرة على الرسم البياني للسعر أو مجموعة من قيم المؤشرات الكلاسيكية ، أو أي وظائف أخرى لمنحنى السعر (حتى في الحالات التي يتم فيها استخدام وحدات البكسل الفردية في مخطط الأسعار كمتنبئات للشبكة العصبية!). عادة ما تحتوي كل عينة أيضًا على متغير هدف معين y ، على سبيل المثال ، نتيجة المعاملة التالية بعد تحليل العينة أو حركة السعر التالية.
في الأدبيات ، غالبًا ما يشار إلى y على أنها تسمية أو هدف. في عملية التعلم ، تتعلم الخوارزمية التنبؤ بالهدف y بناءً على المتنبئات x1 ... xn. يتم تخزين ما "يتذكره" النظام في العملية في بنية بيانات تسمى نموذجًا خاصًا بخوارزمية معينة (من المهم عدم الخلط بين هذا المفهوم وبين نموذج مالي أو استراتيجية موجهة نحو النموذج). يمكن أن يكون نموذج التعلم الآلي وظائف مع قواعد التنبؤ المكتوبة باستخدام كود C الناتج عن عملية التعلم. أو قد تكون مجموعة من الأوزان المتعلقة بالشبكة العصبية:
التدريب: x1 ... xn، y => model
التنبؤ: x1 ... xn، model => y
يجب أن تحتوي المتنبئات أو الوظائف أو أي شيء تريد تسميتها على معلومات كافية لإنشاء تنبؤات حول قيمة الهدف y بدقة معينة. يجب عليهم أيضًا تلبية معيارين رسميين. أولاً ، يجب أن تكون جميع قيم التوقع في نفس النطاق ، على سبيل المثال ، -1 ... +1 (لمعظم الخوارزميات على R) أو -100 ... +100 (للخوارزميات بلغات البرمجة النصية Zorro أو TSSB). لذا قبل إرسال البيانات إلى النظام ، تحتاج إلى تطبيعها. ثانيًا ، يجب أن تكون العينات متوازنة ، بحيث يتم توزيعها بالتساوي على قيم المتغير المستهدف. أي ، يجب أن يكون لديك نفس عدد العينات التي تؤدي إلى نتيجة إيجابية ، وفقدان المجموعات. إذا لم يتم اتباع هذين المطلبين ، فلن تنجح النتائج الجيدة.
تولد خوارزميات الانحدار تنبؤات حول القيم العددية ، مثل الحجم أو علامة حركة السعر التالية. تتنبأ خوارزميات التصنيف بفئات كمية من العينات ، على سبيل المثال ، سواء كانت تسبق الربح أو خسارة الأموال. يمكن تشغيل بعض الخوارزميات ، مثل الشبكات العصبية ، أو أشجار القرار ، أو دعم أساليب المتجه في كلا الوضعين.
هناك أيضًا خوارزميات يمكنها تعلم الاستخراج من عينات الصف دون الحاجة إلى هدف ص. وهذا ما يسمى التعلم غير الخاضع للرقابة ، على عكس التعلم الخاضع للإشراف. في مكان ما بين هاتين الطريقتين يقع "التعلم المعزز" ، حيث يتدرب النظام عن طريق تشغيل المحاكاة مع وظائف محددة ويستخدم النتيجة كهدف. أتباع AlphaGo ، وهو نظام يسمى AlphaZero ، استخدم التعلم المعزز ، ولعب مليون لعبة Go مع نفسه. في التمويل ، مثل هذه الأنظمة أو المنتجات التي تستخدم التعلم غير الخاضع للرقابة نادرة للغاية. 99٪ من الأنظمة تستخدم التعلم تحت الإشراف.
أيًا كانت الإشارات التي نستخدمها للتنبؤات في التمويل ، فستحتوي في معظم الحالات على الكثير من الضوضاء وقليل من المعلومات ، بالإضافة إلى أنها ستكون غير مستقرة. لذا فإن التنبؤ المالي هو أحد أصعب المهام في التعلم الآلي. خوارزميات أكثر تعقيدًا هنا تحقق نتائج أفضل. اختيار المتنبأ أمر بالغ الأهمية لتحقيق النجاح. ليس بالضرورة أن يكون هناك الكثير منها ، لأن هذا يؤدي إلى إعادة التدريب والأعطال. لذلك ، غالبًا ما تستخدم استراتيجيات استخراج البيانات خوارزمية مختارة مسبقًا تستخرج عددًا صغيرًا من المتنبئات من مجموعة أوسع. قد يعتمد هذا الاختيار الأولي على العلاقة بين المتنبئين وأهميتها وثراء المعلومات أو ببساطة نجاح / فشل استخدام مجموعة الاختبار. يمكن العثور على تجارب عملية لاختيار الهدف ، على سبيل المثال ، على مدونة
Robot Wealth .
فيما يلي قائمة بالطرق الأكثر شيوعًا لاستخراج البيانات المستخدمة في مجال التمويل.
1. حساء المؤشرات
لا تعتمد معظم أنظمة التداول على النماذج المالية. غالبًا ما يحتاج المتداولون فقط إلى إشارات التداول التي تم إنشاؤها بواسطة مؤشرات فنية معينة ، والتي يتم تصفيتها بمؤشرات أخرى بالاشتراك مع مؤشرات فنية إضافية. عندما يسأل التاجر عن كيف يمكن أن يؤدي هذا الاختلاط في المؤشرات إلى نوع من الربح ، يجيب عادة على شيء مثل: "صدقوني ، أنا أتبادل يدي وكل شيء يعمل".
وهذا صحيح. على الأقل في بعض الأحيان. على الرغم من أن معظم هذه الأنظمة لن تجتاز
اختبار WFA (وبعضها ببساطة يختبر البيانات التاريخية) ، فإن عددًا كبيرًا بشكل مدهش من هذه الأنظمة يعمل في النهاية ويحقق ربحًا. يشارك كاتب المدونة Financial Hacker في تطوير أنظمة التداول المخصصة ، ويحكي قصة أحد العملاء الذين جربوا بشكل منهجي المؤشرات الفنية حتى وجد تركيبة تعمل مع أنواع معينة من الأصول. طريقة التجربة والخطأ هذه هي طريقة كلاسيكية لاستخراج البيانات ، للنجاح تحتاج فقط إليها ، والحظ والكثير من المال للاختبارات. ونتيجة لذلك ، يمكنك أحيانًا الاعتماد على نظام مربح.
2. أنماط الشمعدان
لا ينبغي الخلط بينه وبين أنماط الشموع الموجودة منذ مئات السنين. المعادل الحديث لهذا النهج هو التجارة على أساس تحركات الأسعار. يمكنك أيضًا تحليل المؤشرات المفتوحة والعالية والمنخفضة والإغلاق لكل شمعة في الرسم البياني. ولكنك الآن تستخدم استخراج البيانات لتحليل شموع منحنى السعر لإبراز الأنماط التي يمكن استخدامها لإنشاء توقعات حول اتجاه حركة السعر في المستقبل.
هناك حزم برامج كاملة لهذا الغرض. يبحثون عن الأنماط المربحة من حيث المعايير التي يحددها المستخدم ، ويستخدمونها لبناء وظيفة الكشف عن الأنماط. قد يبدو كل هذا شيئًا مثل هذا:
int detect(double* sig) { if(sig[1]<sig[2] && sig[4]<sig[0] && sig[0]<sig[5] && sig[5]<sig[3] && sig[10]<sig[11] && sig[11]<sig[7] && sig[7]<sig[8] && sig[8]<sig[9] && sig[9]<sig[6]) return 1; if(sig[4]<sig[1] && sig[1]<sig[2] && sig[2]<sig[5] && sig[5]<sig[3] && sig[3]<sig[0] && sig[7]<sig[8] && sig[10]<sig[6] && sig[6]<sig[11] && sig[11]<sig[9]) return 1; if(sig[1]<sig[4] && eqF(sig[4]-sig[5]) && sig[5]<sig[2] && sig[2]<sig[3] && sig[3]<sig[0] && sig[10]<sig[7] && sig[8]<sig[6] && sig[6]<sig[11] && sig[11]<sig[9]) return 1; if(sig[1]<sig[4] && sig[4]<sig[5] && sig[5]<sig[2] && sig[2]<sig[0] && sig[0]<sig[3] && sig[7]<sig[8] && sig[10]<sig[11] && sig[11]<sig[9] && sig[9]<sig[6]) return 1; if(sig[1]<sig[2] && sig[4]<sig[5] && sig[5]<sig[3] && sig[3]<sig[0] && sig[10]<sig[7] && sig[7]<sig[8] && sig[8]<sig[6] && sig[6]<sig[11] && sig[11]<sig[9]) return 1; .... return 0; }
ترجع هذه الدالة C 1 عندما تتطابق الإشارة مع أحد الأنماط ، وإلا فإنها ترجع 0. يبدو أن الرمز الطويل يشير إلى أن هذه ليست أسرع طريقة للبحث عن الأنماط. من الأفضل استخدام نهج لا تحتاج إلى تصدير وظيفة الكشف فيه ، ولكن يمكنه فرز الإشارات حسب أهميتها وفرزها. يمكن العثور
على مثال لهذا النظام
على الرابط .
يمكن التجارة بسعر العمل؟ كما في الحالة السابقة ، لا تعتمد هذه الطريقة على أي نموذج مالي عقلاني. في الوقت نفسه ، يدرك الجميع أن أحداثًا معينة في السوق حقًا يمكن أن تؤثر على المشاركين ، ونتيجة لذلك تنشأ أنماط تنبؤية قصيرة المدى. لكن عدد هذه الأنماط لا يمكن أن يكون كبيرًا إذا كنت تدرس فقط تسلسل عدة شموع متتالية على الرسم البياني. ثم ستحتاج إلى مقارنة النتيجة ببيانات الشموع ، التي ليست قريبة ، ولكن ، على العكس ، يتم تحديدها عشوائيًا على مدى فترة زمنية أطول. في هذه الحالة ، ستحصل على عدد غير محدود تقريبًا من الأنماط - وتنفصل بنجاح عن مفاهيم الواقع والعقلانية. من الصعب تخيل كيف يمكن توقع السعر المستقبلي بناءً على بعض قيمه الأسبوع الماضي. على الرغم من هذا ، يعمل العديد من التجار في هذا الاتجاه.
3. الانحدار الخطي
أساس بسيط للعديد من خوارزميات التعلم الآلي المعقدة: للتنبؤ بالمتغير المستهدف y باستخدام مجموعة خطية من المتنبئات x1 ... xn.

احتمالات - هذا هو النموذج. يتم حسابها لتقليل مجموع الانحرافات التربيعية بين قيم y الحقيقية وقيم التدريب و y المتوقعة وفقًا للصيغة:

بالنسبة للعينات التي يتم توزيعها بشكل طبيعي ، يمكن التقليل باستخدام عمليات المصفوفة ، لذلك لا يلزم التكرار. في الحالة التي تكون فيها n = 1 - مع توقع واحد x فقط ، يتم تقليل صيغة الانحدار إلى:
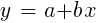
- أي قبل الانحدار الخطي البسيط ، وعندما n> 1 سيكون الانحدار الخطي متعدد المتغيرات. يتوفر الانحدار الخطي البسيط في معظم منصات التداول ، على سبيل المثال ، مؤشر
LinReg في TA-Lib. عندما يكون y = السعر و x = الوقت ، يمكن استخدامه كبديل للمتوسطات المتحركة. في منصة R ، يتم تنفيذ هذا الانحدار بواسطة دالة التسليم القياسية lm (..). يمكن تمثيله أيضًا من خلال انحدار كثير الحدود. كما في أبسط الحالات ، نستخدم هنا متغير تنبئي واحد x ، ولكن أيضًا درجاته المربعة والدرجات اللاحقة ، لذلك xn == xn:
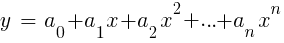
إذا كانت n = 2 أو n = 3 ، غالبًا ما يتم استخدام الانحدار متعدد الحدود للتنبؤ بمتوسط السعر التالي من الأسعار الناعمة للشرائط الأخيرة. من أجل الانحدار متعدد الحدود ، يمكن استخدام وظيفة polyfit لـ MatLab و R و Zorro والعديد من المنصات الأخرى.
4. Perceptron
غالبًا ما تسمى الشبكة العصبية مع خلية عصبية واحدة فقط. في الواقع ، إن ندسبترون هو دالة انحدار ، كما هو موضح أعلاه ، ولكن مع نتيجة ثنائية ، ونتيجة لذلك يطلق عليه
الانحدار اللوجستي . على الرغم ، بشكل عام ، هذا ليس انحدارًا ، بل خوارزمية تصنيف. على سبيل المثال ، تقوم وظيفة المشورة (PERCEPTRON ، ...) لإطار عمل Zorro بإنشاء رمز C لإرجاع 100 أو -100 اعتمادًا على ما إذا كانت النتيجة المتوقعة عتبة أم لا:
int predict(double* sig) { if(-27.99*sig[0] + 1.24*sig[1] - 3.54*sig[2] > -21.50) return 100; else return -100; }
كما ترون ، فإن مصفوفة sig تعادل الدالات xn في صيغة الانحدار ، والمعاملات هي العوامل الرقمية.
5. الشبكات العصبية
يمكن للانحدار الخطي أو اللوجستي أن يحل المشكلات الخطية فقط. في الوقت نفسه ، غالبًا ما لا تتناسب مهام التداول مع هذه الفئة. أحد الأمثلة الشهيرة هو التنبؤ بإخراج دالة XOR البسيطة. يتضمن هذا أيضًا توقع الربح من المعاملات. يمكن للشبكة العصبية الاصطناعية (ANN) حل المشاكل غير الخطية. هذه مجموعة من الإدخالات المتصلة بمجموعة من المستويات المختلفة. كل ندسبترون هو شبكة عصبية. يصبح خرجها مدخلات للخلايا العصبية الأخرى من المستوى التالي:
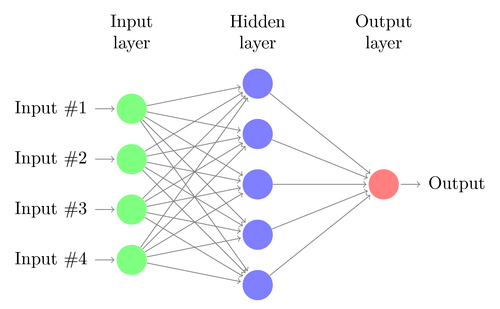
مثل ندوة ، يتم تدريب الشبكة العصبية من خلال تحديد المعاملات التي تقلل من الخطأ بين التنبؤ والهدف في العينة. وهذا يتطلب عملية تقريب ، عادة مع الانتشار الخلفي للخطأ من الإخراج إلى الإدخال مع تحسين الأوزان على طول الطريق. هذه العملية لها قيودان. أولاً ، يجب أن يكون ناتج الخلايا العصبية وظيفة قابلة للتمييز باستمرار بدلاً من عتبة بسيطة للنظير. ثانيًا ، لا ينبغي أن تكون الشبكة عميقة جدًا - فوجود عدد كبير من المستويات المخفية من الخلايا العصبية بين بيانات المدخلات والمخرجات يضر فقط. يحد هذا القيد الثاني من تعقيد المشاكل التي يمكن للشبكة العصبية القياسية حلها.
عند استخدام الشبكات العصبية للتنبؤ بالمعاملات ، سيكون لديك الكثير من المعلمات التي يمكن معالجتها ، والتي إذا تم إجراؤها بشكل غير دقيق ، يمكن أن تؤدي إلى انحياز التحديد (انحياز التحديد):
- عدد المستويات المخفية ؛
- عدد الخلايا العصبية في كل مستوى مخفي ؛
- عدد دورات الانتشار العكسي - العهود ؛
- درجة التدريب ، عرض خطوة العصر ؛
- الزخم ، عامل القصور الذاتي لتكيف الأوزان ؛
- وظيفة التنشيط.
تحاكي وظيفة التنشيط عتبة الإدراك. من أجل الانتشار الخلفي ، تحتاج إلى وظيفة قابلة للتمييز باستمرار تولد خطوة ناعمة لقيمة معينة من x. عادة ، يتم استخدام وظائف السيني أو التنح أو softmax لهذا الغرض. في بعض الأحيان يتم استخدام دالة خطية تُرجع المجموع المرجح لجميع بيانات الإدخال. في هذه الحالة ، يمكن استخدام الشبكة للانحدار ، والتنبؤ بالقيم العددية بدلاً من المخرجات الثنائية.
يتم تضمين الشبكات العصبية في تسليم الحزمة القياسية لـ R (على سبيل المثال ، nnet هي شبكة ذات مستوى مخفي واحد) ، وكذلك في العديد من الحزم الأخرى (مثل RSNNS و FCNN4R).
6. التعلم العميق
تستخدم طرق التعلم العميق الشبكات العصبية مع العديد من المستويات المخفية وآلاف الخلايا العصبية التي لا يمكن تدريبها بشكل فعال باستخدام الانتشار البسيط للظهر. في السنوات الأخيرة ، أصبحت العديد من الطرق شائعة لتدريب مثل هذه الشبكات الكبيرة. وعادة ما تتضمن التدريب المسبق للمستويات المخفية من الخلايا العصبية لزيادة فعالية التعلم الأساسي.
آلة Boltzmann المقيدة (RBM) هي خوارزمية تصنيف غير منضبط مع بنية شبكة خاصة لا توجد فيها اتصالات بين الخلايا العصبية المخفية. يستخدم Sparse Auto Encoder (SAE) بنية الشبكة المعتادة ، ولكن يقوم مسبقًا بتدريب الطبقات المخفية مسبقًا بطريقة معينة ، وإعادة إنتاج إشارات الإدخال عند مستويات الإخراج مع أقل عدد ممكن من الاتصالات النشطة. تسمح لك هذه الطرق بتنفيذ شبكات معقدة للغاية لحل مشاكل التعلم المعقدة للغاية. على سبيل المثال ، مهمة هزيمة أفضل شخص يلعب Go.
يتم تضمين شبكات التعلم العميق في حزم deepnet و darch لـ R. Deepnet تتضمن برنامج التشفير التلقائي ، ويتضمن darch جهاز Boltzmann. فيما يلي مثال على التعليمات البرمجية التي تستخدم deepnet مع ثلاثة مستويات مخفية لمعالجة إشارات التداول من خلال وظيفة neor () لإطار Zorro:
library('deepnet', quietly = T) library('caret', quietly = T) # called by Zorro for training neural.train = function(model,XY) { XY <- as.matrix(XY) X <- XY[,-ncol(XY)] # predictors Y <- XY[,ncol(XY)] # target Y <- ifelse(Y > 0,1,0) # convert -1..1 to 0..1 Models[[model]] <<- sae.dnn.train(X,Y, hidden = c(50,100,50), activationfun = "tanh", learningrate = 0.5, momentum = 0.5, learningrate_scale = 1.0, output = "sigm", sae_output = "linear", numepochs = 100, batchsize = 100, hidden_dropout = 0, visible_dropout = 0) } # called by Zorro for prediction neural.predict = function(model,X) { if(is.vector(X)) X <- t(X) # transpose horizontal vector return(nn.predict(Models[[model]],X)) } # called by Zorro for saving the models neural.save = function(name) { save(Models,file=name) # save trained models } # called by Zorro for initialization neural.init = function() { set.seed(365) Models <<- vector("list") } # quick OOS test for experimenting with the settings Test = function() { neural.init() XY <<- read.csv('C:/Project/Zorro/Data/signals0.csv',header = F) splits <- nrow(XY)*0.8 XY.tr <<- head(XY,splits) # training set XY.ts <<- tail(XY,-splits) # test set neural.train(1,XY.tr) X <<- XY.ts[,-ncol(XY.ts)] Y <<- XY.ts[,ncol(XY.ts)] Y.ob <<- ifelse(Y > 0,1,0) Y <<- neural.predict(1,X) Y.pr <<- ifelse(Y > 0.5,1,0) confusionMatrix(Y.pr,Y.ob) # display prediction accuracy }
7. دعم ناقلات
كما هو الحال مع الشبكات العصبية ، فإن طريقة ناقل الدعم هي امتداد آخر للانحدار الخطي. إذا نظرت إلى صيغة الانحدار مرة أخرى:
ثم يمكن للمرء أن يفسر الدالات xn على أنها إحداثيات فضاء n- الأبعاد. تحديد المتغير y المستهدف لقيمة ثابتة سيحدد المستوى في هذه المساحة - سيطلق عليه اللوح الزائد ، لأنه في الواقع سيكون له حجمان (حتى n-1). يفصل السطح الزائد العينات مع y> 0 عن تلك حيث y <0. يمكن حساب المعاملات a كمسار يفصل الطائرة عن أقرب العينات - متجهاتها الداعمة ، ومن هنا اسم الخوارزمية. وبالتالي ، نحصل على مصنف ثنائي مع الفصل الأمثل بين العينات الفائزة والخسارة.
المشكلة: عادة لا يمكن تقسيم هذه العينات بشكل خطي - يتم تجميعها بشكل عشوائي في مساحة وظيفية. من المستحيل رسم طائرة سلسة بين خيارات الفوز والخسارة ؛ إذا كان من الممكن القيام بذلك ، فعند حسابه ، يمكن للمرء استخدام طرق أبسط مثل التحليل التمييزي الخطي. ولكن في الحالة العامة ، يمكنك استخدام الحيلة: إضافة المزيد من الأحجام إلى المساحة. في هذه الحالة ، ستكون خوارزمية متجه الدعم قادرة على توليد المزيد من المعلمات مع الوظيفة النووية التي تجمع بين أي متنبئين - على غرار الانتقال من الانحدار البسيط إلى كثير الحدود. كلما قمت بإضافة المزيد من الأحجام ، كان من الأسهل تقسيم العينات باستخدام طائرة مفرطة. ثم يمكن تحويلها مرة أخرى إلى الفضاء الأصلي ذي الأبعاد n.
مثل الشبكات العصبية ، يمكن استخدام المتجهات المرجعية ليس فقط للتصنيف ، ولكن أيضًا للانحدار. كما أنها توفر عددًا من الخيارات للتحسين وإعادة التدريب المحتملة:
- دالة النواة - عادة ما يتم استخدام نواة RBF (دالة الأساس الشعاعي ، النواة المتماثلة) ، ولكن يمكن تحديد نوى أخرى ، على سبيل المثال ، السيني ، متعدد الحدود والخطية.
- جاما - عرض قلب RBF.
- معلمة التكلفة C ، "عقوبة" لتصنيفات عينات التدريب غير الصحيحة.
غالبًا ما يتم استخدام مكتبة libsvm ، والتي تتوفر في حزمة e1071 لـ R.
8. خوارزمية أقرب الجيران
بالمقارنة مع ANN الثقيلة و SVM ، هذه خوارزمية بسيطة وممتعة ذات خاصية فريدة: لا تحتاج إلى تدريب. ستكون العينات النموذج. يمكن استخدام هذه الخوارزمية لنظام تداول يتم تدريبه باستمرار عن طريق إضافة عينات جديدة. تحسب هذه الخوارزمية المسافات في فضاء الدالات من القيمة الحالية إلى أقرب عينات k. يتم حساب المسافة في الفراغ n-dimensional بين المجموعتين (x1 ... xn) و (y1 ... yn) بالصيغة:
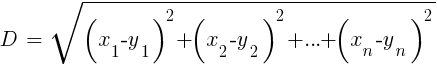
تتنبأ الخوارزمية ببساطة بالهدف من متوسط متغيرات k المستهدفة لأقرب عينات ، موزونة بمسافات رجوعها. يمكن استخدامه لكل من التصنيف والانحدار. للتنبؤ بأقرب جيران ، يمكنك استدعاء وظيفة knn في R أو كتابة رمز C بنفسك لهذا الغرض.
9. K- يعني
هذه خوارزمية تقريبية للتصنيف غير المنضبط. وهي تشبه إلى حد ما الخوارزمية السابقة. لتصنيف العينات ، تضع الخوارزمية أولاً نقاط k العشوائية في مساحة الوظيفة. ثم يعين إلى إحدى هذه النقاط جميع العينات بأقل مسافة لها. ثم تنتقل النقطة إلى منتصف هذه القيم الأقرب. يؤدي هذا إلى إنشاء ارتباطات عينة جديدة ، حيث سيكون بعضها الآن أقرب إلى نقاط أخرى. تتكرر العملية حتى تتوقف إعادة الرجوع نتيجة توقف النقاط ، أي حتى يتم حساب متوسط كل نقطة لأقرب عينات. الآن لدينا فئات عينة k ، يقع كل منها بجوار نقطة k.
يمكن أن تنتج هذه الخوارزمية البسيطة نتائج جيدة بشكل مدهش. في R ، يتم استخدام وظيفة kmeans لتنفيذها ؛ يمكن العثور
على مثال للخوارزمية
على الرابط .
10. ساذجة بايز
تستخدم هذه الخوارزمية نظرية بايزي لتصنيف عينات من الوظائف غير الرقمية (الأحداث) ، مثل أنماط الشموع المذكورة أعلاه. افترض أن الحدث X (على سبيل المثال ، المعلمة Open للشريط السابق أسفل المعلمة Open للشريط الحالي) يظهر في 80٪ من العينات الفائزة. ثم ما هو احتمال ربح العينة في وجود الحدث X فيها؟ هذا ليس 0.8 كما قد تعتقد. يتم حساب هذا الاحتمال بواسطة الصيغة:
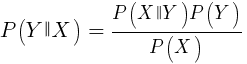
P (Y | X) هو احتمال حدوث الحدث Y (الربح) في جميع العينات التي تحتوي على الحدث X (في مثالنا ، فتح (1) <فتح (0)). وفقًا للصيغة ، يساوي احتمال حدوث الحدث X في جميع العينات الفائزة (في حالتنا 0.8) ، مضروبًا في الاحتمال Y في جميع العينات (حوالي 0.5 إذا اتبعت نصائح موازنة العينات) ومقسمة على احتمال حدوث X في جميع العينات.
إذا كنا ساذجين ونفترض أن جميع أحداث X مستقلة عن بعضها البعض ، فيمكننا حساب الاحتمال الإجمالي للفوز بالعينة ببساطة عن طريق ضرب الاحتمالات P (X | الفوز) لكل حدث X. ثم نصل إلى الصيغة التالية:
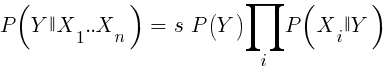
مع عامل التحجيم s. لكي تعمل الصيغة ، يجب أن يتم اختيار الوظائف بطريقة تكون مستقلة بقدر الإمكان. سيكون هذا عقبة في استخدام Bayes ساذجة للتجارة. على سبيل المثال ، حدثان إغلاق (1) <إغلاق (0) وفتح (1) <فتح (0) على الأرجح ليسا مستقلين عن بعضهما البعض. يمكن تحويل التنبؤات الرقمية إلى أحداث بتقسيم الرقم إلى نطاقات منفصلة. Naive Bayes متوفر في الحزمة e1071 لـ R.
11. أشجار القرار والانحدار
تتنبأ هذه الأشجار بنتيجة القيم العددية بناءً على سلسلة القرار بنسق نعم / لا في بنية فروع الشجرة. يمثل كل قرار وجود أو غياب الأحداث (في حالة القيم غير العددية) أو مقارنة القيم بعتبة ثابتة. تبدو دالة الشجرة النموذجية ، التي تم إنشاؤها ، على سبيل المثال ، من خلال إطار Zorro ، كما يلي:
int tree(double* sig) { if(sig[1] <= 12.938) { if(sig[0] <= 0.953) return -70; else { if(sig[2] <= 43) return 25; else { if(sig[3] <= 0.962) return -67; else return 15; } } } else { if(sig[3] <= 0.732) return -71; else { if(sig[1] > 30.61) return 27; else { if(sig[2] > 46) return 80; else return -62; } } } }
كيف يتم الحصول على مثل هذه الشجرة من مجموعة من العينات؟ يمكن أن يكون هناك عدة طرق لذلك ، بما في ذلك
إنتروبيا شانون المعلوماتية .
يمكن استخدام أشجار القرار على نطاق واسع. على سبيل المثال ، فهي مناسبة لتوليد تنبؤات أكثر دقة مما يمكن تحقيقه باستخدام الشبكات العصبية أو المتجهات المرجعية. ومع ذلك ، هذا ليس حلا عالميا. أفضل خوارزمية معروفة من هذا النوع هي C5.0 ، المتوفرة في حزمة C50 لـ R.
لمزيد من تحسين جودة التنبؤات ، يمكنك استخدام مجموعات من الأشجار - يطلق عليها غابة عشوائية. تتوفر هذه الخوارزمية في حزم R تسمى randomForest و ranger و Rborist.
الخلاصة
هناك العديد من طرق استخراج البيانات والتعلم الآلي. السؤال الحاسم هنا هو: أيهما أفضل ، أو استراتيجيات تعتمد على النموذج أو التعلم الآلي؟ ليس هناك شك في أن التعلم الآلي له عدد من المزايا. على سبيل المثال ، لا تحتاج إلى الاهتمام بالهيكل الدقيق للسوق أو الاقتصاد أو مراعاة فلسفة المشاركين في السوق أو أشياء أخرى مماثلة. يمكنك التركيز على الرياضيات البحتة. يعد التعلم الآلي طريقة أكثر أناقة وجاذبية لإنشاء أنظمة التداول. من جانبه ، كل المزايا ، باستثناء ميزة واحدة - بالإضافة إلى القصص الموجودة في منتديات المتداولين ، يصعب تتبع نجاح هذه الطريقة في التداول الحقيقي.
يتم نشر مقالات جديدة كل أسبوع تقريبًا حول التداول باستخدام التعلم الآلي. يجب أن تؤخذ هذه المواد مع قدر لا بأس به من الشك. يدعي بعض المؤلفين أن معدلات الفوز رائعة تبلغ 70٪ أو 80٪ أو حتى 85٪. ومع ذلك ، يقول عدد قليل من الناس أنه يمكنك خسارة الأموال حتى لو كانت التوقعات رابحة. عادة ما تترجم دقة 85 ٪ إلى مؤشر ربحية أعلى من 5 - إذا كان كل شيء بسيطًا جدًا ، فعندئذ سيصبح مبدعو هذا النظام أصحاب المليارات. ومع ذلك ، لسبب ما ، فإن استنساخ النتائج نفسها ببساطة عن طريق تكرار الأساليب الموضحة في المقالات يفشل.
مقارنةً بالنظم القائمة على النموذج ، هناك عدد قليل جدًا من أنظمة التعلم الآلي الناجحة. على سبيل المثال ، نادراً ما تستخدمها صناديق التحوط الناجحة. ربما في المستقبل ، عندما تصبح قوة الحوسبة أكثر سهولة ، سيتغير شيء ما ، ولكن حتى الآن تظل خوارزميات التعلم العميقة هواية مثيرة للاهتمام للمهوسين أكثر من أداة حقيقية لكسب المال في البورصة.
المواد المالية الأخرى والمتعلقة بسوق الأوراق المالية من ITI Capital :