في 28 مايو ، في مؤتمر
RootConf 2018 ، الذي عقد كجزء من
مهرجان RIT ++ 2018 ، في قسم "التسجيل والمراقبة" ، تم تسليم تقرير "المراقبة و Kubernetes". يخبر عن تجربة مراقبة الإعداد مع Prometheus ، التي تم الحصول عليها من قبل Flant نتيجة لتشغيل عشرات مشاريع Kubernetes في الإنتاج.

بالتقليد ، يسعدنا أن نقدم
فيديو مع تقرير (حوالي ساعة ،
أكثر إفادة بكثير من المقالة) والضغط الرئيسي في شكل نص. دعنا نذهب!
ما هو الرصد؟
هناك العديد من أنظمة المراقبة:

يبدو أن أخذ واحد منهم وتثبيته - هذا كل شيء ، تم إغلاق السؤال. لكن الممارسة تظهر أن الأمر ليس كذلك. وهنا السبب:
- يظهر عداد السرعة السرعة . إذا قمنا بقياس السرعة مرة واحدة في الدقيقة بواسطة عداد السرعة ، فإن متوسط السرعة ، الذي نحسبه على أساس هذه البيانات ، لن يتزامن مع بيانات عداد المسافات. وإذا كان هذا واضحًا في حالة السيارة ، فعندما يتعلق الأمر بالعديد من المؤشرات للخادم ، فإننا غالبًا ما ننسى ذلك.
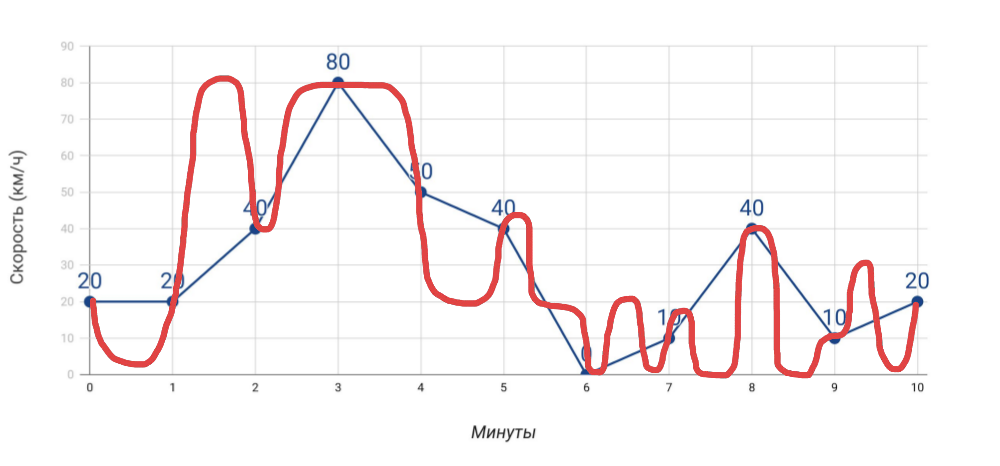
ما نقيس وكيف سافرنا فعلا - المزيد من القياسات . كلما حصلنا على مؤشرات مختلفة ، كلما كان تشخيص المشكلات أكثر دقة ... ولكن بشرط أن تكون هذه مؤشرات مفيدة حقًا ، وليس فقط كل ما تمكنت من جمعه.
- التنبيهات . لا يوجد شيء معقد في إرسال التنبيهات. ومع ذلك ، هناك مشكلتان نموذجيتان: أ) تحدث الإنذارات الكاذبة في كثير من الأحيان بحيث نتوقف عن الاستجابة لأي تنبيهات ، ب) تأتي التنبيهات في وقت متأخر جدًا (كل شيء قد انفجر بالفعل). وتحقيق في رصد أن هذه المشاكل لم تنشأ هو فن حقيقي!
المراقبة عبارة عن فطيرة مكونة من ثلاث طبقات ، ولكل منها أهمية حاسمة:
- بادئ ذي بدء ، هذا نظام يتيح لك استباق الحوادث ، والإبلاغ عن الحوادث (إذا لم يكن بالإمكان منعها) وإجراء تشخيص سريع للمشاكل.
- ما هو المطلوب لهذا؟ بيانات دقيقة ، ومخططات مفيدة (انظر إليها وافهم مكان المشكلة) ، والتنبيهات ذات الصلة (تصل في الوقت المناسب وتحتوي على معلومات واضحة).
- ولكي يعمل كل هذا ، هناك حاجة إلى نظام مراقبة .
إن الإعداد الصحيح لنظام مراقبة يعمل حقًا ليس مهمة سهلة ، حيث يتطلب اتباع نهج مدروس للتنفيذ حتى بدون Kubernetes. لكن ماذا يحدث بمظهره؟
Kubernetes رصد التفاصيل
رقم 1. أكبر وأسرع
تتغير Kubernetes كثيرًا لأن البنية التحتية تزداد حجمًا وأسرع. إذا كان في وقت سابق ، مع خوادم الحديد العادية ، كان عددهم محدودًا جدًا ، وكانت عملية الإضافة طويلة جدًا (استغرقت أيامًا أو أسابيع) ، ثم مع الأجهزة الافتراضية ، زاد عدد الكيانات بشكل كبير ، وتم تقليل وقت إدخالها في المعركة إلى ثوانٍ.
مع Kubernetes ، زاد عدد الكيانات بترتيب من الحجم ، وإضافتها مؤتمتة بالكامل (إدارة التكوين ضرورية ، لأنه بدون وصف لا يمكن إنشاء جراب جديد ببساطة) ، أصبحت البنية التحتية بأكملها ديناميكية للغاية (على سبيل المثال ، يتم حذف القرون وإطلاقها في كل مرة يتم إنشاؤها مرة أخرى).
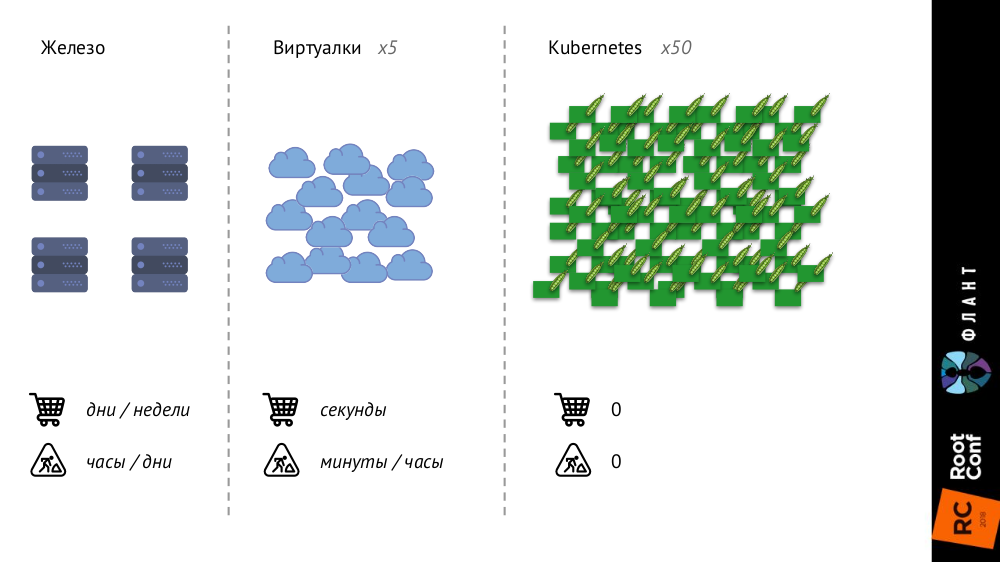
ماذا تغير ذلك؟
- من حيث المبدأ ، نتوقف عن النظر في القرون أو الحاويات الفردية - نحن الآن مهتمون فقط بمجموعات من الأشياء .
- يصبح Service Discovery إلزاميًا تمامًا ، لأن "السرعات" أصبحت بالفعل ، من حيث المبدأ ، لا يمكننا بدء / حذف الكيانات الجديدة يدويًا ، كما كان من قبل ، عندما تم شراء خوادم جديدة.
- كمية البيانات تنمو بشكل ملحوظ . إذا تم جمع المقاييس السابقة من الخوادم أو الأجهزة الافتراضية ، الآن من القرون ، فإن عددها أكبر بكثير.
- التغيير الأكثر إثارة للاهتمام الذي أسميه " تدفق البيانات الوصفية " وسأخبرك المزيد عنه.
سأبدأ بهذه المقارنة:
- عندما ترسل طفلك إلى روضة الأطفال ، سيتم إعطاؤه صندوقًا شخصيًا ، يتم تخصيصه له في العام المقبل (أو أكثر) والذي يشار إليه باسمه.
- عندما تأتي إلى حوض السباحة ، لا يتم توقيع الخزانة الخاصة بك ويتم إصدارها لك لـ "جلسة" واحدة.
لذا
تعتقد أنظمة المراقبة الكلاسيكية أنها روضة أطفال وليست بركة: فهي تفترض أن كائن المراقبة جاء إليهم إلى الأبد أو لفترة طويلة ، ومنحهم الخزائن وفقًا لذلك. لكن الحقائق في Kubernetes مختلفة: جاء جراب إلى التجمع (أي تم إنشاؤه) ، سبح فيه (حتى نشر جديد) وترك (تم تدميره) - كل هذا يحدث بسرعة وبشكل منتظم. وبالتالي ، يجب أن يفهم نظام المراقبة أن الأشياء التي يراقبها تعيش حياة قصيرة ، ويجب أن تكون قادرة على نسيانها تمامًا في الوقت المناسب.
رقم 2. الواقع الموازي موجود
نقطة أخرى مهمة - مع ظهور Kubernetes ، لدينا في الوقت نفسه "حقيقتان":
- عالم Kubernetes حيث توجد مساحات أسماء وانتشار وقرون وحاويات. هذا عالم معقد ، لكنه منطقي ومنظم.
- العالم "المادي" ، الذي يتكون من العديد من الحاويات (حرفيا - أكوام) على كل عقدة.
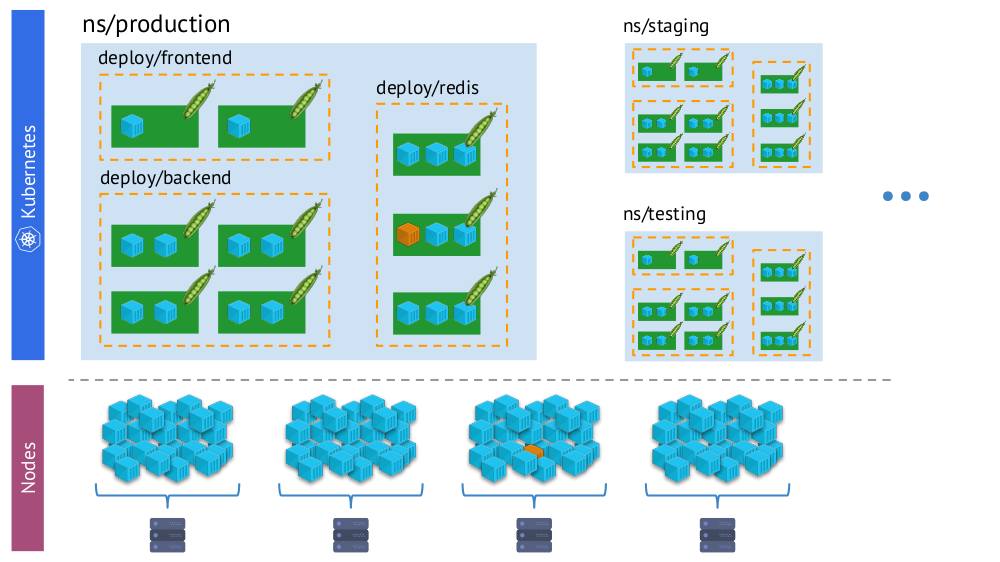 نفس الحاوية في Kubernetes "الواقع الافتراضي" (أعلاه) والعالم المادي للعقد (أدناه)
نفس الحاوية في Kubernetes "الواقع الافتراضي" (أعلاه) والعالم المادي للعقد (أدناه)وفي عملية المراقبة ، نحتاج إلى
مقارنة العالم المادي للحاويات باستمرار
بواقع Kubernetes . على سبيل المثال ، عندما ننظر إلى بعض مساحة الاسم ، نريد أن نعرف مكان وجود جميع حاوياتها (أو حاويات أحد مداخنها). بدون هذا ، لن تكون التنبيهات مرئية ومريحة للاستخدام - لأنه من المهم بالنسبة لنا أن نفهم الأشياء التي يبلغون عنها.
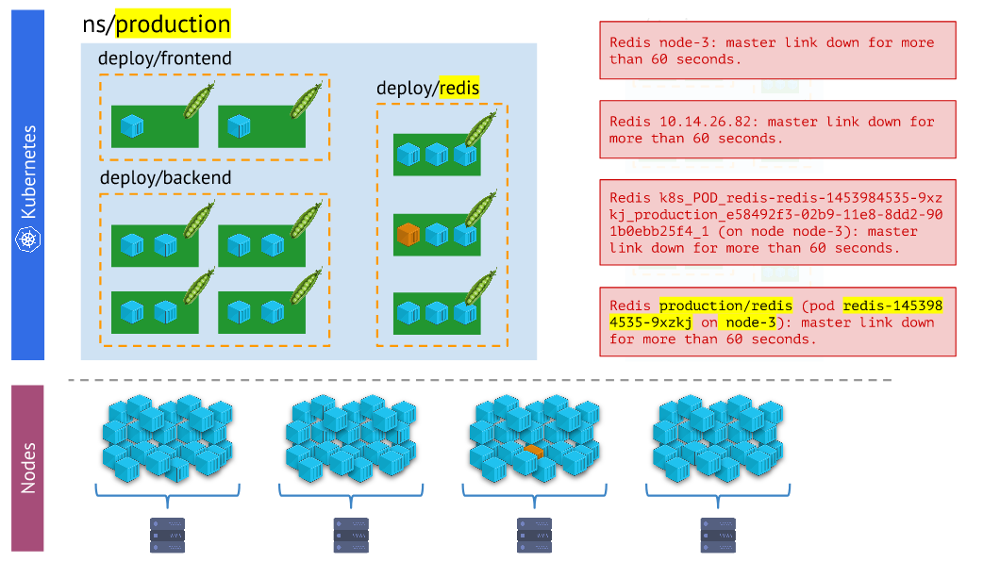 أنواع مختلفة من التنبيهات - هذا الأخير أكثر بصرية وملاءمة في العمل من البقيةالاستنتاجات
أنواع مختلفة من التنبيهات - هذا الأخير أكثر بصرية وملاءمة في العمل من البقيةالاستنتاجات هنا هي:
- يجب أن يستخدم نظام المراقبة بدائل Kubernetes المدمجة.
- هناك أكثر من حقيقة: في كثير من الأحيان لا تحدث المشاكل في الموقد ، ولكن مع عقدة معينة ، ونحن بحاجة إلى فهم مستمر لنوع "الواقع" الذي هم فيه.
- في إحدى المجموعات ، كقاعدة عامة ، هناك العديد من البيئات (إلى جانب الإنتاج) ، مما يعني أنه يجب أخذ ذلك في الاعتبار (على سبيل المثال ، عدم تلقي تنبيهات في الليل حول المشاكل في dev).
لذا ، لدينا ثلاثة شروط ضرورية لكي يعمل كل شيء:
- نحن نفهم جيدًا ما هو الرصد.
- نحن نعرف عن ميزاته ، والتي تظهر مع Kubernetes.
- نعتمد بروميثيوس.
وهكذا ، للعمل حقًا ، يبقى فقط بذل
الكثير من الجهد
حقًا ! بالمناسبة ، لماذا بالضبط بروميثيوس؟ ..
بروميثيوس
هناك طريقتان للإجابة عن السؤال حول اختيار بروميثيوس:
- تعرف على من وما يستخدم بشكل عام لمراقبة Kubernetes.
- النظر في مزاياها التقنية.
أولاً ، استخدمت بيانات المسح من The New Stack (من
كتاب حالة دولة Kubernetes Ecosystem الإلكترونية) ، والذي بموجبه يعتبر Prometheus أكثر شيوعًا على الأقل من الحلول الأخرى (كل من Open Source و SaaS) ، وإذا نظرت ، فإنه يتمتع بميزة إحصائية من خمسة أضعاف .
الآن دعونا نرى كيف يعمل Prometheus ، بالتوازي مع كيفية دمج قدراتها مع Kubernetes وحل التحديات ذات الصلة.
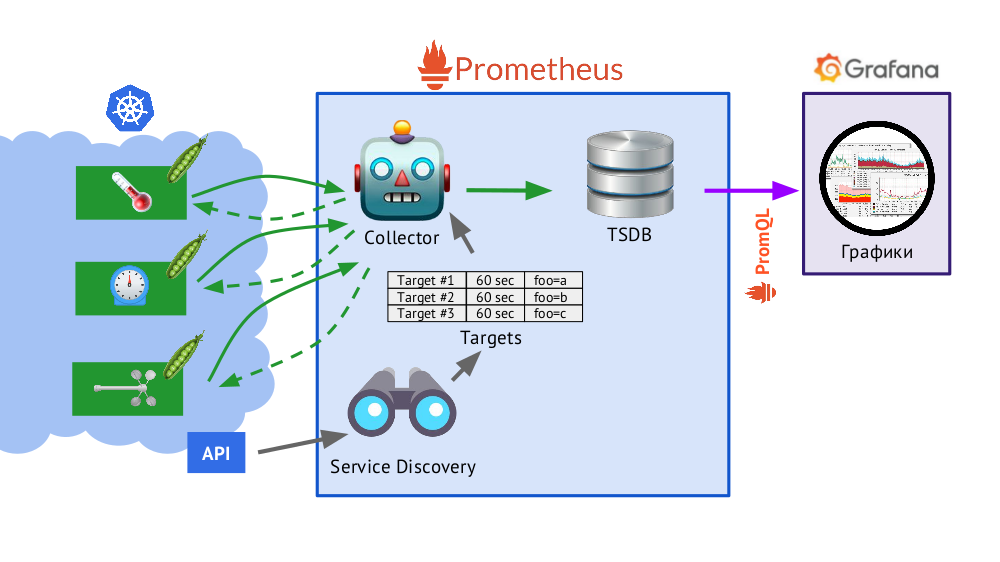
كيف يتم بناء بروميثيوس؟
يتم كتابة Prometheus في Go ويتم توزيعه كملف ثنائي واحد ، حيث يتم تضمين كل شيء فيه. الخوارزمية الأساسية لتشغيلها هي كما يلي:

- يقوم المُجمع بقراءة جدول الأهداف ، أي قائمة بالأشياء المراد مراقبتها ووتيرة الاقتراع (افتراضيًا - 60 ثانية).
- بعد ذلك ، يرسل المجمّع طلب HTTP إلى كل منصة تحتاجها ويتلقى استجابة بمجموعة من المقاييس - يمكن أن يكون هناك مائة أو ألف أو عشرة آلاف ... لكل مقياس اسم وقيمة وتسميات .
- يتم تخزين الاستجابة المستلمة في قاعدة بيانات TSDB ، حيث يتم إضافة الطابع الزمني لاستلامها وتسميات الكائن الذي تم أخذها منه إلى بيانات القياس المستلمة.
باختصار حول TSDBTSDB - قاعدة بيانات السلاسل الزمنية (DB للسلسلة الزمنية) على Go ، والتي تسمح لك بتخزين البيانات لعدد محدد من الأيام وتقوم بذلك بكفاءة عالية (في الحجم والذاكرة والإدخال / الإخراج). يتم تخزين البيانات محليًا فقط ، بدون تجميع وتكرار ، وهو زائد (يعمل ببساطة ومضمون) وناقص (لا يوجد مقياس أفقي للتخزين) ، ولكن في حالة تقسيم Prometheus بشكل جيد ، يتم الاتحاد - المزيد حول هذا لاحقًا.
- تم تقديم Service Discovery في المخطط ، وهو عبارة عن محرك لاكتشاف الخدمات مدمج في Prometheus يسمح لك بتلقي البيانات "من الصندوق" (عبر واجهة برمجة تطبيقات Kubernetes) لإنشاء جدول أهداف.
كيف يبدو هذا الجدول؟ لكل إدخال ، يقوم بتخزين عنوان URL المستخدم للحصول على المقاييس ، وتكرار المكالمات والعلامات.
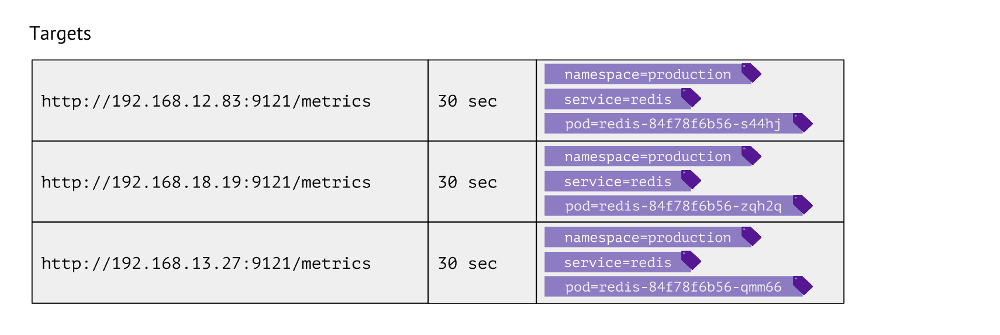
تُستخدم التسميات للتجاور بين عوالم Kubernetes المادية. على سبيل المثال ، للعثور على pod مع Redis ، نحتاج إلى الحصول على مساحة اسم القيم والخدمة (تُستخدم بدلاً من النشر بسبب الميزات التقنية لحالة معينة) و pod الفعلي. وفقًا لذلك ، يتم تخزين هذه التسميات الثلاثة في إدخالات جدول الأهداف لمقاييس Redis.
يتم تكوين هذه الإدخالات في الجدول على أساس
scrape_configs Prometheus الذي يتم فيه وصف كائنات المراقبة: في قسم
scrape_configs ،
scrape_configs تعريف
scrape_configs ، والتي تشير من خلال أي تصنيفات للبحث عن الكائنات المراد مراقبتها ، وكيفية تصفيتها ، وأي التصنيفات يتم تسجيلها.
ما هي البيانات التي تجمعها Kubernetes؟
- أولاً ، إن المعالج في Kubernetes معقد للغاية - ومن الأهمية بمكان مراقبة حالة تشغيله (kube-apiserver ، kube-controller-manager ، kube-Scheduler ، kube-etcd3 ...) ، ومع ربط العقدة العنقودية.
- ثانيًا ، من المهم معرفة ما يجري داخل Kubernetes ، وللقيام بذلك نحصل على بيانات من:
- kubelet - يعمل مكون Kubernetes هذا على كل عقدة في الكتلة (ويتصل بمعالج K8s) ؛ يتم تضمين citations فيه (جميع المقاييس بالحاويات) ، كما يخزن معلومات حول الأحجام المستمرة المتصلة ؛
- مقاييس kube-state- metres - في الأساس ، هذا هو Prometheus Exporter for Kubernetes API (يسمح لك بالحصول على معلومات حول الأشياء المخزنة في Kubernetes: القرون ، الخدمات ، عمليات النشر ، إلخ ؛ على سبيل المثال ، لن نتعرف بدونها الحاوية أو حالة الموقد) ؛
- node-exporter - يوفر معلومات حول العقدة نفسها ، والمقاييس الأساسية لنظام Linux (وحدة المعالجة المركزية ، وأقراص القرص ، و meminfo ، وما إلى ذلك ).
- فيما يلي مكونات Kubernetes ، مثل kube-dns و kube-prometheus-operator و kube-prometheus و ingress-nginx-controller وغيرها.
- الفئة التالية من الكائنات التي يجب مراقبتها هي في الواقع البرنامج الذي تم إطلاقه في Kubernetes. هذه خدمات خادم نموذجية مثل nginx و php-fpm و Redis و MongoDB و RabbitMQ ... ونحن نفعل ذلك بأنفسنا بحيث عندما نضيف بعض التصنيفات إلى الخدمة ، يبدأ تلقائيًا في جمع البيانات اللازمة ، مما يؤدي إلى إنشاء لوحة المعلومات الحالية في Grafana.
- أخيرًا ، فئة كل شيء آخر مخصصة . تسمح لك أدوات Prometheus بأتمتة جمع المقاييس التعسفية (على سبيل المثال ، عدد الطلبات) عن طريق إضافة تصنيف
prometheus-custom-target إلى وصف الخدمة.

الرسوم البيانية
يتم استخدام البيانات المستلمة
(الموضحة أعلاه) لإرسال تنبيهات وإنشاء مخططات. نرسم الرسوم البيانية باستخدام
Grafana . وهناك "تفاصيل" مهمة هنا هي
PromQL ، لغة الاستعلام Prometheus التي تتكامل تمامًا مع Grafana.
إنه بسيط للغاية ومناسب لمعظم المهام
(ولكن ، على سبيل المثال ، الانضمام إلى الانضمام إليه غير مريح بالفعل ، ولكن لا يزال عليك ذلك) . تسمح لك PromQL بحل جميع المهام الضرورية: حدد المقاييس اللازمة بسرعة ، وقارن القيم ، وقم بإجراء العمليات الحسابية عليها ، وقم بالتجميع ، والعمل مع فترات زمنية وأكثر من ذلك بكثير. على سبيل المثال:

بالإضافة إلى ذلك ، يحتوي Prometheus على
مقيِّم يمكنه ، باستخدام نفس PromQL ، الوصول إلى TSDB بالتردد المحدد. لماذا هذا؟ مثال: ابدأ في إرسال التنبيهات في الحالات التي نواجه فيها ، وفقًا للمقاييس المتاحة ، خطأ 500 على خادم الويب خلال الدقائق الخمس الماضية. بالإضافة إلى التسميات التي كانت موجودة في الطلب ، يضيف Evaluator تصنيفات إضافية إلى البيانات للتنبيهات (أثناء
تكويننا ) ، وبعد ذلك يتم إرسالها بتنسيق JSON إلى مكون Prometheus آخر -
Alertmanager .
يرسل Prometheus بشكل دوري (مرة كل 30 ثانية) تنبيهات إلى Alertmanager ، مما يؤدي إلى إلغاء تكرارها (بعد تلقي التنبيه الأول ، سيتم إرساله ، ولن يتم إرسال التنبيهات التالية مرة أخرى).
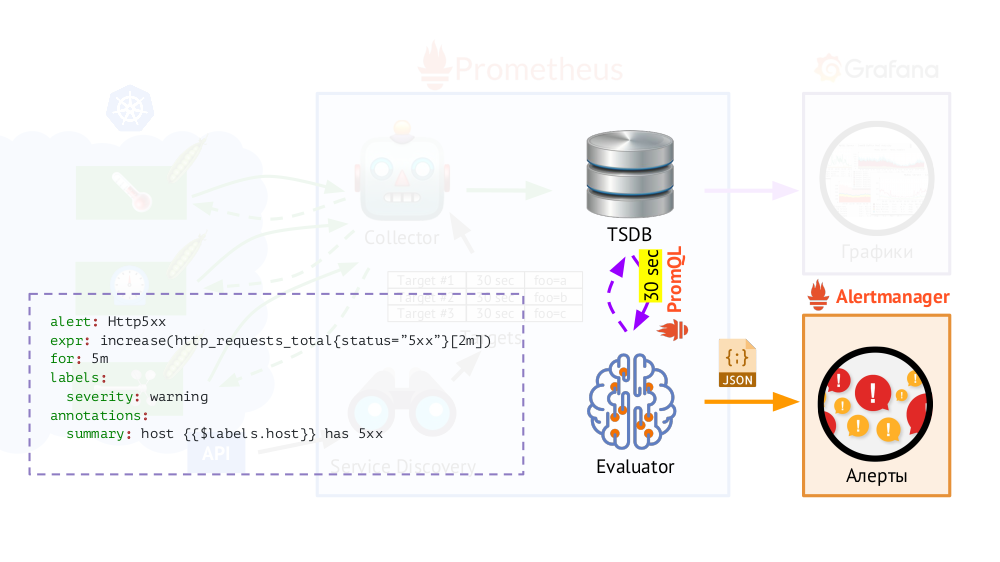 ملاحظة : لا نستخدم Alertmanager في المنزل ، ولكن نرسل البيانات من Prometheus مباشرة إلى نظامنا ، والتي يعمل معها الحاضرون ، ولكن هذا لا يهم في المخطط العام.
ملاحظة : لا نستخدم Alertmanager في المنزل ، ولكن نرسل البيانات من Prometheus مباشرة إلى نظامنا ، والتي يعمل معها الحاضرون ، ولكن هذا لا يهم في المخطط العام.بروميثيوس في Kubernetes: الصورة الكبيرة
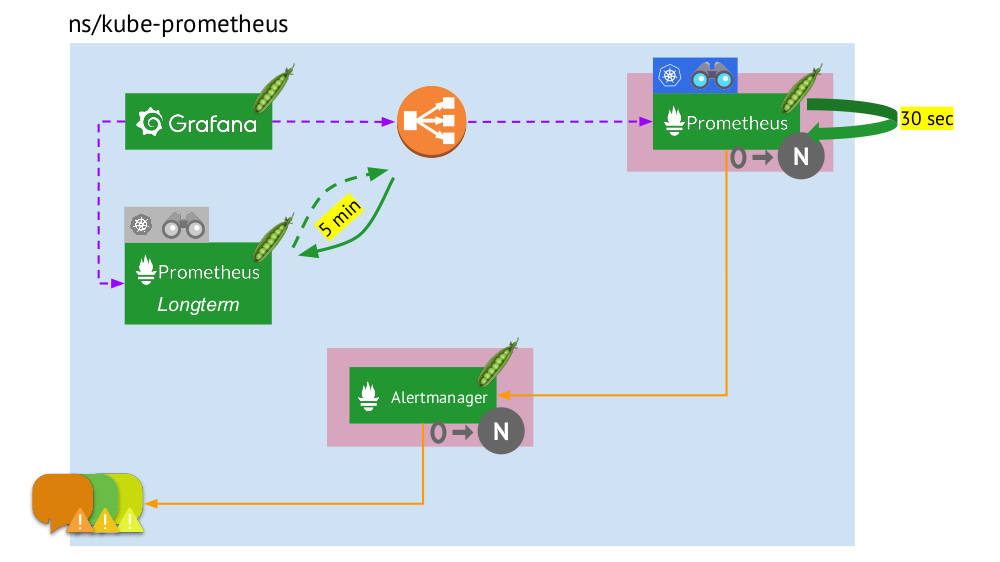
دعنا نرى الآن كيف تعمل حزمة بروميثيوس بالكامل داخل Kubernetes:
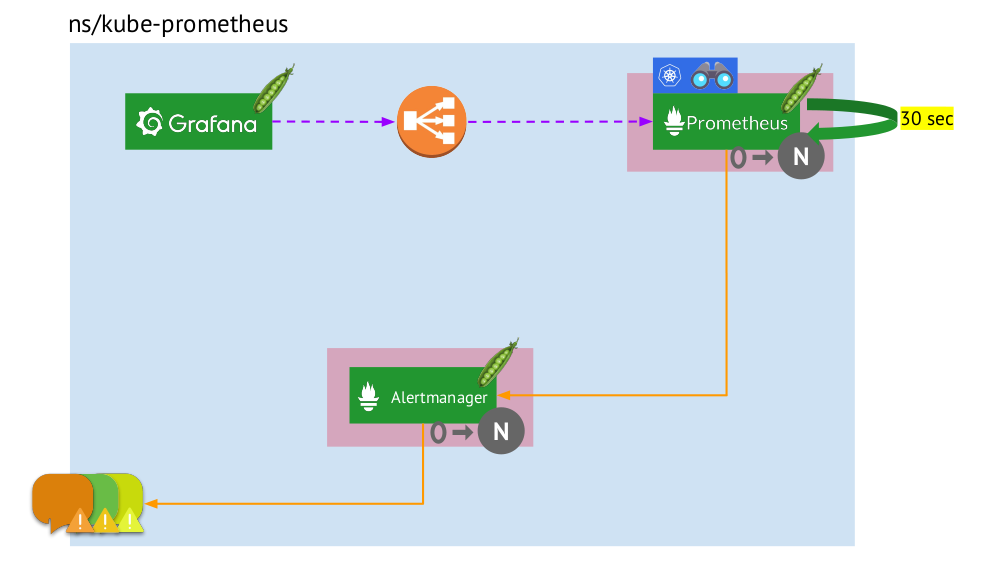
- تمتلك Kubernetes مساحة اسم خاصة بها لـ Prometheus (لدينا
kube-prometheus في الرسم التوضيحي) . - تستضيف مساحة الاسم هذه الكبسولة مع تثبيت Prometheus ، الذي يجمع كل 30 ثانية المقاييس من جميع الأهداف التي تم تلقيها من خلال Service Discovery في المجموعة.
- يحتوي أيضًا على جراب مع Alertmanager ، والذي يتلقى بيانات من Prometheus ويرسل تنبيهات (إلى البريد و Slack و PagerDuty و WeChat ودمج الطرف الثالث وما إلى ذلك ) .
- تواجه بروميثيوس موازنة تحميل - خدمة منتظمة في Kubernetes - وتصل Grafana إلى Prometheus من خلاله. لضمان التسامح مع الخطأ ، يستخدم Prometheus عدة قرون مع تثبيتات Prometheus ، كل منها يجمع كل البيانات ويخزنها في TSDB الخاص به. من خلال الموازن ، ضربت جرافانا أحدهم.
- يتم التحكم في عدد القرون التي تحتوي على Prometheus من خلال إعداد StatefulSet - عادةً لا ننشئ أكثر من قرنين ، ولكن يمكنك زيادة هذا العدد. بنفس الطريقة ، يتم نشر Alertmanager من خلال StatefulSet ، لتسامح مع الخطأ الذي يتطلبه 3 قرون على الأقل بالفعل (حيث يتطلب النصاب القانوني لاتخاذ قرارات بشأن إرسال التنبيهات).
ما المفقود هنا؟ ..
اتحاد بروميثيوس
عندما يتم جمع البيانات كل 30 (أو 60) ثانية ، ينتهي مكان تخزينها بسرعة كبيرة ، والأسوأ من ذلك ، يتطلب الكثير من موارد الحوسبة (عند استقبال ومعالجة مثل هذا العدد الكبير من النقاط من TSDB). لكننا نريد تخزين المعلومات ولدينا القدرة على تنزيل المعلومات
لفترات زمنية كبيرة و e . كيف تحقق ذلك؟
يكفي إضافة
تثبيت آخر لـ Prometheus (نسميه على
المدى الطويل ) إلى المخطط العام ، حيث يتم تعطيل Service Discovery ، وفي جدول الهدف يوجد السجل الثابت الوحيد المؤدي إلى Prometheus
الرئيسي (
الرئيسي ).
هذا ممكن بفضل الاتحاد : يسمح لك Prometheus بإرجاع أحدث القيم لجميع المقاييس في استعلام واحد. وبالتالي ، لا يزال التثبيت الأول لـ Prometheus يعمل (يصل كل 60 أو ، على سبيل المثال ، 30 ثانية) إلى جميع الأهداف في مجموعة Kubernetes ، والثاني - مرة واحدة كل 5 دقائق ، يتلقى البيانات من الأول ويخزنه ليتمكن من مشاهدة البيانات لفترة طويلة ( ولكن بدون تفاصيل عميقة).
 لا يحتاج تثبيت Prometheus الثاني إلى خدمة اكتشاف الخدمة ، وسيتكون جدول الأهداف من سطر واحد
لا يحتاج تثبيت Prometheus الثاني إلى خدمة اكتشاف الخدمة ، وسيتكون جدول الأهداف من سطر واحد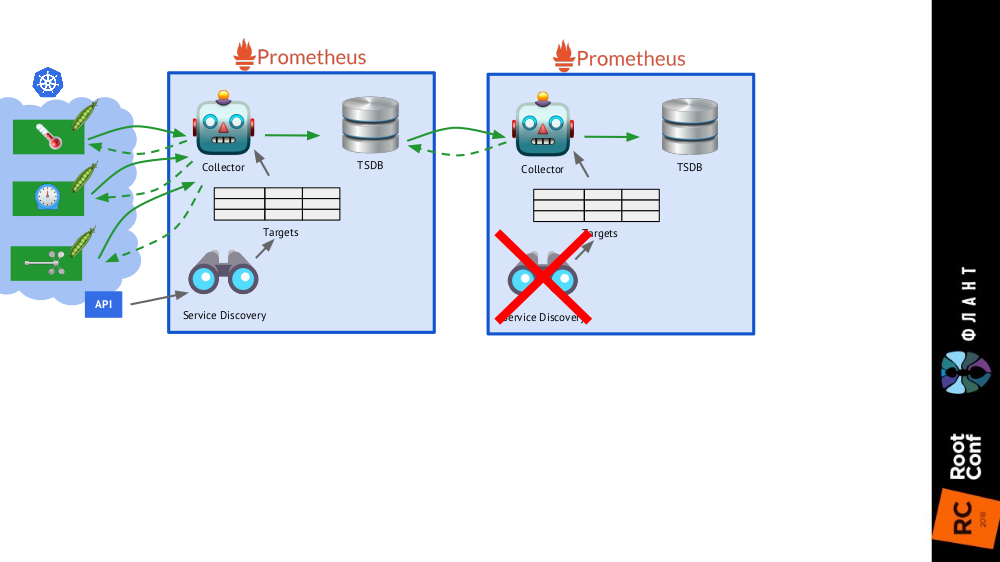 الصورة الكاملة مع تركيبات بروميثيوس من نوعين: رئيسي (علوي) وطويل المدى
الصورة الكاملة مع تركيبات بروميثيوس من نوعين: رئيسي (علوي) وطويل المدىاللمسة الأخيرة هي
ربط Grafana بكل من تثبيتات Prometheus وإنشاء لوحات تحكم بطريقة خاصة بحيث يمكنك التبديل بين مصادر البيانات (
الرئيسية أو
طويلة المدى ). للقيام بذلك ، باستخدام محرك القالب ، استبدل المتغير
$prometheus بدلاً من مصدر البيانات في جميع اللوحات.
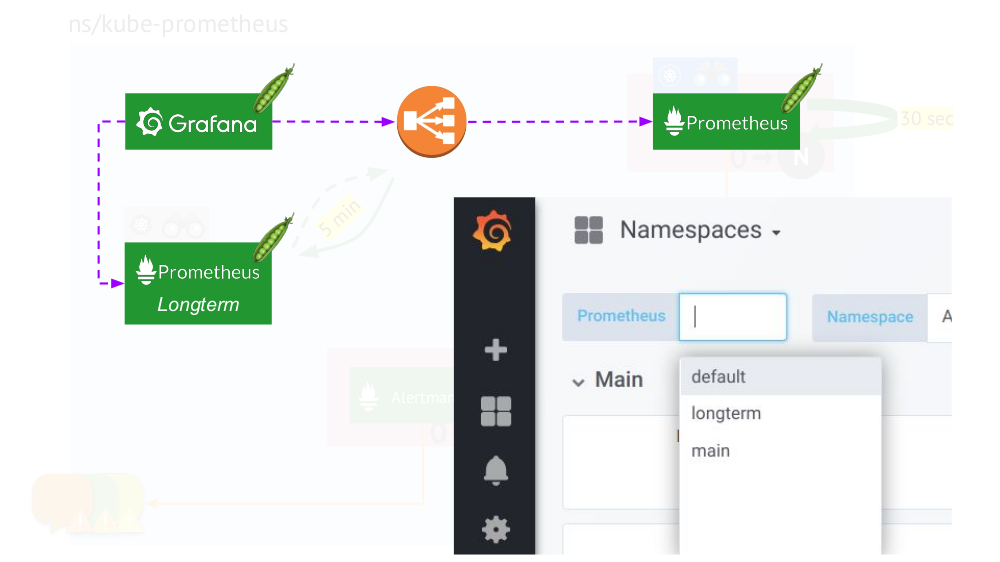
ما هو المهم الآخر في الرسوم البيانية؟
هناك نقطتان رئيسيتان يجب مراعاتهما عند تنظيم الجداول هما دعم بدائية Kubernetes والقدرة على الانتقال بسرعة من الصورة العامة (أو "عرض" أقل) إلى خدمة معينة والعكس صحيح.
تم بالفعل ذكر دعم البدائيين (مساحات الأسماء ، القرون ، وما إلى ذلك) - وهذا شرط ضروري من حيث المبدأ للعمل المريح في حقائق Kubernetes. وإليك مثال عن التوغل:
- ننظر إلى الرسوم البيانية لاستهلاك الموارد من خلال ثلاثة مشاريع (أي ثلاثة مساحات أسماء) - نرى أن الجزء الرئيسي من وحدة المعالجة المركزية (أو الذاكرة ، أو الشبكة ، ...) يقع على المشروع أ.
- نحن ننظر إلى نفس الرسوم البيانية ، ولكن بالفعل لخدمات المشروع أ: أي منهم يستهلك معظم وحدة المعالجة المركزية؟
- ننتقل إلى الرسوم البيانية للخدمة المطلوبة: أي جراب "يقع اللوم"؟
- ننتقل إلى الرسوم البيانية للجراب المطلوب: أي حاوية يجب إلقاء اللوم عليها؟ هذا هو الهدف المنشود!
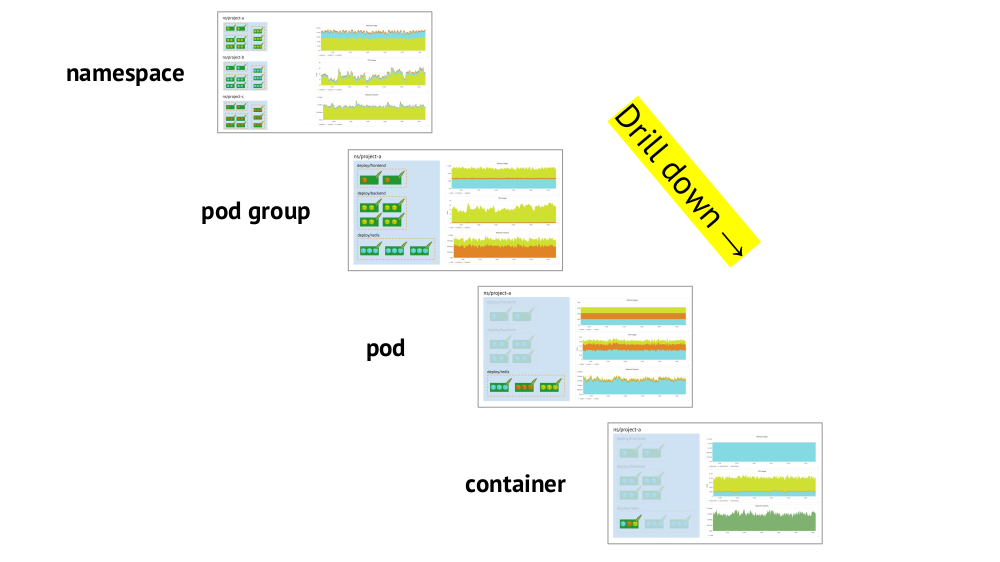
الملخص
- حدد لنفسك بدقة ما هو الرصد. (دع "الفطيرة ثلاثية الطبقات" بمثابة تذكير بهذا ... وكذلك حقيقة أن الخبز بكفاءة ليس بالأمر السهل حتى بدون Kubernetes!)
- تذكر أن Kubernetes تضيف تفاصيل إلزامية: تجميع الهدف ، واكتشاف الخدمة ، وكميات كبيرة من البيانات ، وتدفق البيانات الوصفية. علاوة على ذلك:
- نعم ، تم حل بعضها بطريقة سحرية ("خارج الصندوق") في بروميثيوس ؛
- ومع ذلك ، لا يزال هناك جزء آخر يجب مراقبته بشكل مستقل ومدروس.
وتذكر أن
المحتوى أكثر أهمية من النظام ، أي تعد المخططات والتنبيهات الصحيحة أساسية ، وليست بروميثيوس (أو أي برامج أخرى مماثلة) على هذا النحو.

مقاطع فيديو وشرائح
فيديو من العرض (حوالي ساعة):
عرض التقرير:
ملاحظة
تقارير أخرى على مدونتنا:
قد تكون مهتمًا أيضًا بالمطبوعات التالية: