تحياتي للمجتمع المتميز!
التكرار هي أم التعلم ، وفهم التحليل هو مهارة مفيدة جدًا لأي مبرمج ، لذلك أريد أن أطرح هذا الموضوع مرة أخرى وأتحدث هذه المرة عن التحليل باستخدام طريقة النسب العودية (LL) ، دون أي شكليات (يمكنك دائمًا استخدامها لاحقًا أعود).
كما يكتب د. ستروغوف العظيم ، "الفهم هو التبسيط". لذلك ، من أجل فهم مفهوم التحليل باستخدام طريقة الهبوط العودية (ويعرف أيضًا باسم LL-parsing) ، نقوم بتبسيط المهمة قدر الإمكان ونكتب محللًا بتنسيق يشبه تنسيق JSON يدويًا ، ولكن أبسط (إذا أردت ، يمكنك بعد ذلك توسيعه إلى محلل JSON الكامل إذا تريد ممارسة). دعونا نكتبها ، مع الأخذ في الاعتبار فكرة
قطع الخيط .
في الكتب الكلاسيكية ودورات تصميم المترجم ، يبدأون عادةً بشرح موضوع التحليل والتفسير ، مع تسليط الضوء على عدة مراحل:
- التحليل المعجمي: تقسيم النص المصدر إلى مجموعة من السلاسل الفرعية (الرموز المميزة أو الرموز المميزة)
- التحليل: بناء شجرة التحليل من مجموعة من الرموز المميزة
- التفسير (أو الترجمة): اجتياز الشجرة الناتجة بالترتيب المطلوب (المباشر أو العكسي) وتنفيذ بعض إجراءات التفسير أو إنشاء التعليمات البرمجية في بعض خطوات هذا الاجتياز
ليس كذلكلأنه في عملية التحليل نحصل بالفعل على سلسلة من الخطوات ، وهي سلسلة من الزيارات إلى عقد الشجرة ، قد لا تكون الشجرة نفسها في شكل صريح موجودة على الإطلاق ، لكننا لن نتعمق بعد. بالنسبة لأولئك الذين يريدون التعمق ، هناك روابط في النهاية.
الآن أريد استخدام نهج مختلف قليلاً لهذا المفهوم نفسه (تحليل LL) وإظهار كيف يمكنك بناء محلل LL بناءً على فكرة قطع سلسلة: يتم قطع الأجزاء من السلسلة الأصلية أثناء التحليل ، وتصبح أصغر ، ثم يتم تحليلها كشف بقية الخط. ونتيجة لذلك ، نصل إلى نفس مفهوم السلالة العودية ، ولكن بطريقة مختلفة قليلاً عما يتم عادة. ربما يكون هذا المسار أكثر ملاءمة لفهم جوهر الفكرة. وإذا لم يكن الأمر كذلك ، فلا تزال فرصة للنظر إلى نزول تعاودي من زاوية مختلفة.
لنبدأ بمهمة أبسط: هناك خط مع المحددات ، وأريد أن أكتب تكرارًا فوق قيمه. شيء مثل:
String names = "ivanov;petrov;sidorov"; for (String name in names) { echo("Hello, " + name); }
كيف يمكن القيام بذلك؟ الطريقة القياسية هي تحويل السلسلة المحددة إلى مصفوفة أو قائمة باستخدام String.split (في Java) ، أو names.split ("،") (في جافا سكريبت) ، والتكرار من خلال المصفوفة بالفعل. ولكن دعونا نتخيل أننا لا نريد أو لا يمكننا استخدام التحويل إلى مصفوفة (على سبيل المثال ، حسنًا ، فجأة إذا قمنا بالبرمجة بلغة برمجة AVAJ ++ ، حيث لا توجد بنية بيانات "صفيف"). لا يزال بإمكانك مسح السلسلة وتتبع المحددات ، لكنني لن أستخدم هذه الطريقة أيضًا ، لأنها تجعل رمز حلقة التكرار مرهقًا ، والأهم من ذلك ، أنها تتعارض مع المفهوم الذي أريد إظهاره. لذلك ، سوف نتعامل مع سلسلة محددة بنفس الطريقة المتعلقة بالقوائم في البرمجة الوظيفية. وهناك دائمًا ما يحددون رأس الوظائف (احصل على العنصر الأول من القائمة) والذيل (احصل على بقية القائمة). بدءًا من اللهجات الأولى من Lisp ، حيث تم استدعاء هذه الوظائف بشكل فظيع وغير بديهي تمامًا: car و cdr (السيارة = محتوى سجل العنوان ، cdr = محتوى التناقص. أساطير القديمة عميقة ، نعم ، eheheh.).
خطنا هو خط محدد. قم بتمييز الفواصل باللون الأرجواني:
وقم بتمييز عناصر القائمة باللون الأصفر:

نفترض أن خطنا قابل للتغيير (يمكن تغييره) ونكتب دالة:
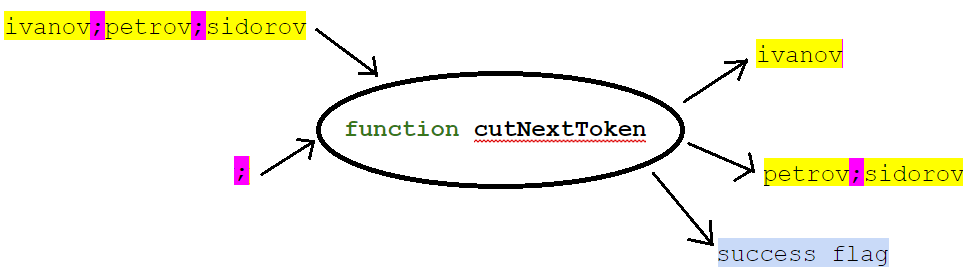
توقيعها ، على سبيل المثال ، قد يكون:
public boolean cutNextToken(StringBuilder svList, String separator, StringBuilder token)
عند إدخال الوظيفة ، نعطي قائمة (في شكل سلسلة مع فواصل) ، وفي الواقع ، قيمة الفاصل. عند الإخراج ، تقوم الدالة بإرجاع العنصر الأول من القائمة (مقطع السطر إلى الفاصل الأول) ، وبقية القائمة وعلامة ما إذا تم إرجاع العنصر الأول. في هذه الحالة ، يتم وضع بقية القائمة في نفس المتغير حيث كانت القائمة الأصلية.
ونتيجة لذلك ، أتيحت لنا الفرصة لكتابة مثل هذا:
StringBuilder names = new StringBuilder("ivanov;petrov;sidorov"); StringBuilder name = new StringBuilder(); while(cutNextToken(names, ";", name)) { System.out.println(name); }
المخرجات كما هو متوقع:
إيفانوف
بتروف
سيدوروف
فعلنا دون تحويل إلى ArrayList ، لكننا أفسدنا متغير الأسماء ، والآن يحتوي على سلسلة فارغة. لا يبدو مفيدًا جدًا حتى الآن ، كما لو قاموا بتغيير المخرز للصابون. ولكن دعنا نذهب أبعد من ذلك. هناك سنرى لماذا كان ذلك ضروريا وإلى أين سيقودنا.
الآن دعنا نحلل شيئًا أكثر إثارة للاهتمام: قائمة أزواج القيمة الرئيسية. هذه أيضًا مهمة شائعة جدًا.
StringBuilder pairs = new StringBuilder("name=ivan;surname=ivanov;middlename=ivanovich"); StringBuilder pair = new StringBuilder(); while (cutNextToken(pairs, ";", pair)) { StringBuilder paramName = new StringBuilder(); StringBuilder paramValue = new StringBuilder(); cutNextToken(pair, "=", paramName); cutNextToken(pair, "=", paramValue); System.out.println("param with name \"" + paramName + "\" has value of \"" + paramValue + "\""); }
الخلاصة:
param with name "name" has value of "ivan" param with name "surname" has value of "ivanov" param with name "middlename" has value of "ivanovich"
متوقع أيضا. ويمكن تحقيق الشيء نفسه مع String.split ، دون قطع الخطوط.
ولكن دعنا نقول أننا أردنا الآن تعقيد تنسيقنا والانتقال من قيمة مفتاح ثابتة إلى تنسيق معقد يذكرنا بـ JSON. نريد الآن قراءة شيء مثل هذا:
{'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'}}
ما تقسيم الفاصل؟ إذا كانت فاصلة ، فسيكون لدينا الخط في أحد الرموز
'birthdate':{'year':'1984'
من الواضح أنه ليس ما نحتاج إليه. لذلك ، يجب أن ننتبه إلى بنية الخط الذي نريد تحليله.
يبدأ بقوس مجعد وينتهي بقوس مجعد (مقترن به ، وهو أمر مهم). داخل هذه الأقواس توجد قائمة "مفتاح" أزواج: "قيمة" ، يتم فصل كل زوج من الزوج التالي بفاصلة. يتم فصل المفتاح والقيمة بعلامة النقطتين. المفتاح عبارة عن سلسلة من الحروف داخل الفواصل العليا. يمكن أن تكون القيمة عبارة عن سلسلة من الأحرف محاطة بفواصل عليا ، أو يمكن أن تكون نفس البنية ، تبدأ وتنتهي بأقواس متعرجة مقترنة. نسمي مثل هذا الهيكل كلمة "كائن" ، كما هو معتاد أن نسميها في JSON.
لقد قمنا للتو بوصف غير رسمي لقواعد تنسيق JSON الشبيه. عادة ، يتم وصف القواعد النحوية بشكل عكسي ، في شكل رسمي ، ويتم استخدام تدوين BNF أو أشكاله المختلفة لكتابتها. ولكن الآن يمكنني الاستغناء عنها ، وسنرى فقط كيف يمكنك "قطع" هذا الخط بحيث يمكن تحليله وفقًا لقواعد هذا النحو.
في الواقع ، يبدأ "جسمنا" بقوس مجعد افتتاحي وينتهي بزوج يغلقه. ماذا يمكن أن تفعل وظيفة تحليل مثل هذا التنسيق؟ على الأرجح ، ما يلي:
- تحقق من أن السلسلة التي تم تمريرها تبدأ مع قوس فتح
- تحقق من أن السلسلة التي تم تمريرها تنتهي بزوج من أقواس الإغلاق
- إذا كان كلا الشرطين صحيحًا ، فقم بقطع بين قوسي الفتح والإغلاق ، وما يتبقى ، انتقل إلى الوظيفة التي تحلل قائمة "مفتاح" الأزواج: "القيمة"
يرجى ملاحظة: ظهرت الكلمتان "وظيفة تحليل هذا التنسيق" و "وظيفة تحليل قائمة الأزواج" مفتاح ":" القيمة "". لدينا ميزتان! هذه هي الوظائف نفسها التي يطلق عليها في الوصف الكلاسيكي لخوارزمية الهبوط العودية "وظائف التحليل للرموز غير النثرية" ، والتي تنص على أنه "لكل رمز غير نمطي ، يتم إنشاء وظيفة التحليل الخاصة به". وهو في الواقع يوزعها. يمكننا تسميتها ، على سبيل المثال ، parseJsonObject و parseJsonPairList.
نحتاج الآن أيضًا إلى الانتباه إلى أن لدينا مفهوم "قوس مزدوج" بالإضافة إلى مفهوم "فاصل". إذا قمت بقطع خط إلى الفاصل التالي (نقطتان بين مفتاح وقيمة ، فاصلة بين أزواج "المفتاح: القيمة") ، كانت وظيفة cutNextToken كافية بالنسبة لنا ، والآن يمكننا استخدام ليس فقط سلسلة ، ولكن أيضًا كائن ، نحتاج وظيفة "قطع إلى الزوج التالي من الأقواس". شيء من هذا القبيل:

تقوم هذه الوظيفة بقطع جزء من الخط من قوس الفتح إلى الزوج الذي يغلقه ، مع مراعاة الأقواس ، إن وجدت. بالطبع ، لا يمكنك أن تقتصر على الأقواس ، ولكن استخدم وظيفة مماثلة لقطع هياكل مختلفة للكتل التي يمكن أن تتداخل: كتل المشغل تبدأ .. نهاية ، إذا ... نهاية ، إلى ... نهاية وما شابه.
لنرسم بيانيًا ما سيحدث للسلسلة. اللون الفيروزي - هذا يعني أننا نقوم بمسح الخط للأمام إلى الرمز المميز باللون الفيروزي لتحديد ما يجب علينا القيام به بعد ذلك. البنفسج هو "ما يجب قطعه ، هذا عندما نقطع الأجزاء المظللة في البنفسج من الخط ، ونستمر في تحليل ما تبقى منه.

للمقارنة ، خرج البرنامج (نص البرنامج موجود في الملحق) الذي يوزع هذا السطر:
شرح تحليل هيكل يشبه JSON
ok, about to parse JSON object {'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'}} ok, about to parse pair list 'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'name' found VALUE of type STRING:'ivan' ok, about to parse pair list 'surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'surname' found VALUE of type STRING:'ivanov' ok, about to parse pair list 'birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'birthdate' found VALUE of type OBJECT:{'year':'1984','month':'october','day':'06'} ok, about to parse JSON object {'year':'1984','month':'october','day':'06'} ok, about to parse pair list 'year':'1984','month':'october','day':'06' found KEY: 'year' found VALUE of type STRING:'1984' ok, about to parse pair list 'month':'october','day':'06' found KEY: 'month' found VALUE of type STRING:'october' ok, about to parse pair list 'day':'06' found KEY: 'day' found VALUE of type STRING:'06'
في أي وقت ، نعرف ما نتوقع العثور عليه في خط الإدخال الخاص بنا. إذا أدخلنا دالة parseJsonObject ، فإننا نتوقع أن يتم تمرير الكائن إلينا هناك ، ويمكننا التحقق من ذلك من خلال وجود قوسي الفتح والإغلاق في البداية وفي النهاية. إذا أدخلنا وظيفة parseJsonPairList ، فإننا نتوقع قائمة من أزواج "المفتاح: القيمة" هناك ، وبعد "إيقاف تشغيل" المفتاح (قبل فاصل ":") ، نتوقع أن الشيء التالي الذي "نطرده" هو القيمة. يمكننا أن ننظر إلى الحرف الأول للقيمة ، ونرسم استنتاجًا حول نوعه (إذا كانت الفاصلة العليا ، عندئذ تكون القيمة من النوع "سلسلة" ، إذا كان قوس الفتح المجعد هو القيمة من النوع "كائن").
وبالتالي ، بقطع الأجزاء من السلسلة ، يمكننا تحليلها بطريقة التحليل من أعلى إلى أسفل (النزول العودي). وعندما يمكننا التحليل ، يمكننا تحليل التنسيق الذي نحتاجه. أو ابتكار تنسيق خاص بك مناسب لنا وقم بتفكيكه. أو ابتكر لغة خاصة بالمجال (DSL) لمنطقتنا الخاصة وقم بتصميم مترجم فوري لها. ولإنشاءها بشكل صحيح ، دون اتخاذ قرارات معذبة بشأن regexp أو آلات الحالة الذاتية الصنع التي تنشأ للمبرمجين الذين يحاولون حل بعض المشكلات التي تتطلب التحليل ، لكنهم لا يمتلكون المواد تمامًا.
هنا. تهانينا للجميع في الصيف القادم وأتمنى لكم التوفيق والحب والمحللين الوظيفيين :)
لمزيد من القراءة:
أيديولوجي: زوجان من مقالات طويلة ولكن تستحق القراءة من قبل ستيف Yeegge:
غذاء مبرمج غنيزوجان من الاقتباسات من هناك:
إما أن تتعلم المترجمين وتبدأ في كتابة DSL الخاصة بك ، أو تحصل على لغة أفضل
تحليل المرحلة الأولى الكبيرة من خط أنابيب التجميع
مشكلة بينوكيواقتباس من هناك:
اكتب القوالب ، وتضييق ووسع التحويلات ، ووظائف الصديق لتجاوز حماية الفئة القياسية ، وحشو اللغات المصغرة في سلاسل وتحليلها يدويًا ، وهناك عشرات الطرق لتجاوز أنظمة الكتابة في Java و C ++ ، ويستخدمها المبرمجون طوال الوقت ، لأنهم (لا يعرفون سوى القليل) أنهم يحاولون بالفعل إنشاء برامج ، وليس أجهزة.
التقنية: مقالتان حول تحليل الفرق بين نهج LL و LR:
إلغاء LL و LR تحليل الغموضLL و LR في السياق: لماذا أدوات التحليل صعبةوأعمق في الموضوع: كيفية كتابة مترجم Lisp في C ++
مترجم Lisp في 90 سطرًا من C ++التطبيق. رمز المثال (جافا) الذي ينفذ المحلل الموصوف في المقالة: package demoll; public class DemoLL { public boolean cutNextToken(StringBuilder svList, String separator, StringBuilder token) { String s = svList.toString(); if (s.trim().isEmpty()){ return false; } int sepIndex = s.indexOf(separator); if (sepIndex == -1) {