 تم النشر بواسطة إيجور ماسترنايا ، مطور أول ، قائد مجتمع DataArt Java
تم النشر بواسطة إيجور ماسترنايا ، مطور أول ، قائد مجتمع DataArt Javaفي الفترة من 18 إلى 19 مايو ، تم عقد JEEonf في كييف ، وهو أحد الأحداث الأكثر توقعًا لمجتمع جافا بأكمله في أوروبا الشرقية. شراكة DataArt مع المؤتمر. تحدث المتحدثون من جميع أنحاء العالم على أربع مراحل: فولكر سيمونيس ، ممثل SAP في
JCP ومساهم OpenJDK ، يورغن هولر ، كبير المهندسين المحوري ، والد إطار الربيع المحبوب ، كلاوس إيبسن ، مبتكر Apache Camel ، و Hugh McKee ، المبشر في Lightbend.
كان الجدول مشغولاً للغاية: في يومين أكثر من 50 عرضًا ، 45 دقيقة لكل منهما. استراحة 10 دقائق - وركض إلى تقرير جديد. سيستغرق الأمر وقتًا طويلاً لمشاهدة جميع مقاطع الفيديو عند ظهورها على الشبكة. لذلك ، سأصف بإيجاز التقارير التي وجدتها الأكثر إثارة للاهتمام والتي زرتها شخصيا.
15 سنة من الربيع
افتتح المؤتمر يورغن هولر. تحدث عن تاريخ إطار الربيع لمدة 15 عامًا (!) ، من تكوينات XML "المفضلة" في الإصدار 0.9 إلى Spring WebFlux التفاعلي ، الذي انبثق من المشاريع البحثية المتأثرة بالبيان
التفاعلي . تحدث يورجن عن التعايش بين Spring MVC و Spring WebFlux في Spring WEB ، وأوضح لماذا قرروا عدم دمجهم في واحد. والحقيقة هي أن التجريد الرئيسي لـ Spring MVC هو Servlet API 3.0 وحظر IO ، بينما يستخدم Spring WebFlux تجريد التدفقات التفاعلية و IO غير المحجوبة. يمكنك تشغيل خدمتك على SpringWebFlux على أي خادم يدعم IO غير المحظور: Netty ، الإصدارات الجديدة من Tomcat (> 8.5) ، Jetty. لا يختلف إنشاء وحدات تحكم WebFlux التفاعلية كثيرًا عن إنشائها باستخدام Spring MVC ، ولكن لا تزال هناك اختلافات. معالجة طلب مستخدم ، لا يعالج جهاز التحكم التفاعلي ذلك بالمعنى المعتاد ، ولكنه ينشئ خط أنابيب لمعالجة الطلب. يستدعي Dispatcher طريقة التحكم ، التي تنشئ خط أنابيب وتعطيه على الفور كتيار ناشر. يتم عرض دفق الناشر في Spring Reactive Spring كملخصين: Flux / Mono. يقوم Flux بإرجاع دفق من الكائنات ، بينما يقوم Mono دائمًا بإرجاع كائن واحد.
ذكر Jürgen أيضًا راحة استخدام نمط Java 8 عند العمل مع Spring 5.0 ووعد بمرشح إصدار Spring 5.1 في يوليو 2018 وإصدار في سبتمبر ، والذي سيدعم Java 11 والعمل على الضبط الدقيق لميزات Spring 5.0 الجديدة
تكامل Python / Java
كان هناك الكثير من التقارير ، وكان من الصعب اختيار الأكثر إثارة للاهتمام في الفتحة التالية. كانت الأوصاف مثيرة للاهتمام بنفس القدر ، لذلك وثقت بغرائزي وقررت الاستماع إلى تاماس روزمان ، نائب رئيس BlackRock من المجر. ولكن سيكون من الأفضل إذا استمعت مرة أخرى حول مصادر الأحداث و CQRS. بناءً على الوصف ، تعمل الشركة في Data Science لصندوق استثماري كبير. كان الغرض من التقرير هو إظهار كيفية إنشاء نظام مستقر وقابل للتوسيع وملائم أيضًا لمحللي البيانات مع Python وللمطورين Java في النظام الرئيسي. ومع ذلك ، بدا لي شك في أن النظام الذي تم إنشاؤه تبين أنه مناسب حقًا. لتكوين صداقات مع Python و Java ، توصل المهندسون في BlackRock إلى فكرة بدء مترجم Python كعملية من تطبيق Java. لقد توصلوا إلى هذا لعدة أسباب:
- Jython (Python on JVM) لم يكن مناسبًا نظرًا لقاعدة الرموز القديمة 2.7 مقابل CPython 3.6.
- اعتبروا خيار إعادة كتابة منطق علوم البيانات في جافا عملية طويلة جدًا.
- قررت Apache Spark عدم أخذها ، لأنه ، كما أوضح المتحدث ، لا يمكنك مزج أعباء العمل المكتوبة بلغة Java و Python. على الرغم من أنه ليس من الواضح لماذا UDF و UDFA لا تناسب [ 2 ]. أيضًا ، لم يكن Spark مناسبًا ، لأن لديهم بالفعل نوعًا من إطار العمل ، ولم يرغبوا حقًا في تقديم إطار عمل جديد. وكما اتضح ، فإنهم لا يملكون بيانات كبيرة أيضًا ، وتعود جميع المعالجة إلى إحصاءات ملفات 100 ميغابايت المثيرة للشفقة.
تم تنظيم الاتصال من Java مع عملية Python باستخدام ملفات الذاكرة المعينة (يتم استخدام ملف واحد كملف بيانات إدخال) والأوامر (الملف الثاني هو ناتج عملية Python). وبالتالي ، كان التواصل شيئًا على شكل:
جافا: calcExr | 1 + javaFunc (sqrt (36))
Python: 1 + javaFunct | 6
جافا: 1 + نجاح | 64
بايثون: النجاح | 65
المشاكل الرئيسية لهذا التكامل ، دعا تاماس النفقات العامة أثناء التسلسل وإلغاء تسلسل معلمات الإدخال / الإخراج.

تطبيق Java 10 CDS
بعد عرض تقديمي حول تعقيدات تشغيل Python ، أردت حقًا الاستماع إلى شيء تقني عميق من عالم جافا. لذلك ذهبت إلى تقرير فولكر سيمونيس ، حيث تحدث عن ميزة مشاركة بيانات فئة التطبيق من
Java 10+ . في العالم الحديث المبني على الخدمات المصغرة في Docker ، تعمل القدرة على مشاركة Java Codecache و Metaspace على تسريع إطلاق التطبيق وتوفير الذاكرة. تظهر الصورة نتائج إطلاق الطماطم المرسومة مع أرشيف مشترك / مشترك لفئات Tomcat. كما ترى ، بالنسبة للعملية الثانية ، تم وضع علامة على بعض الصفحات في الذاكرة بالفعل على أنها Shared_clean - مما يعني أن العملية الحالية وعملية واحدة على الأقل (العملية الثانية قيد التشغيل) تشير إليهما.

يمكن العثور على تفاصيل حول كيفية اللعب باستخدام CDS في OpenJDK 10 على:
CDS للتطبيق . بالإضافة إلى تقسيم فئات التطبيق بين العمليات ، فمن المخطط في المستقبل مشاركة السلاسل
المتدربة في
JEP-250 .
القيود الرئيسية ل AppCDS:
لا يعمل مع فصول حتى 1.5.
- لا يمكنك استخدام الفصول التي تم تحميلها من الملفات (فقط. أرشيفات jar).
- لا يمكن استخدام الفئات المعدلة بواسطة أداة تحميل الفصول.
- يمكن إعادة استخدام الفصول التي تم تحميلها بواسطة لوادر متعددة الفئات مرة واحدة فقط.
- لا يعمل إعادة كتابة كود البايت ، مما قد يؤدي إلى انخفاض في الأداء يصل إلى 2٪. JDK-8074345

خط أنابيب معالجة اللغة الطبيعية مع Apache Spark
تم تقديم التقرير حول البرمجة اللغوية العصبية و Apache Spark من قبل Vitaliy Kotlyarenko - مهندس من Grammarly. أظهر فيتالي كيف أن النموذج النحوي NLP-Jobs على Apache Zeppelin. ومن الأمثلة على ذلك إنشاء خط أنابيب بسيط للنمذجة المواضيعية بناءً على خوارزمية
LDA لأرشيف الإنترنت
للزحف المشترك . تم استخدام نتائج نمذجة الموضوعات لتصفية المواقع ذات المحتوى غير المناسب كمثال على وظيفة الرقابة الأبوية. لإنشاء خط الأنابيب ، استخدمنا مخطوطات Terraform ومجموعة
AWS EMR Spark ، والتي تسمح لك بنشر Spark Cluster مع YARN في Amazon. من الناحية التخطيطية ، يبدو خط الأنابيب كما يلي:
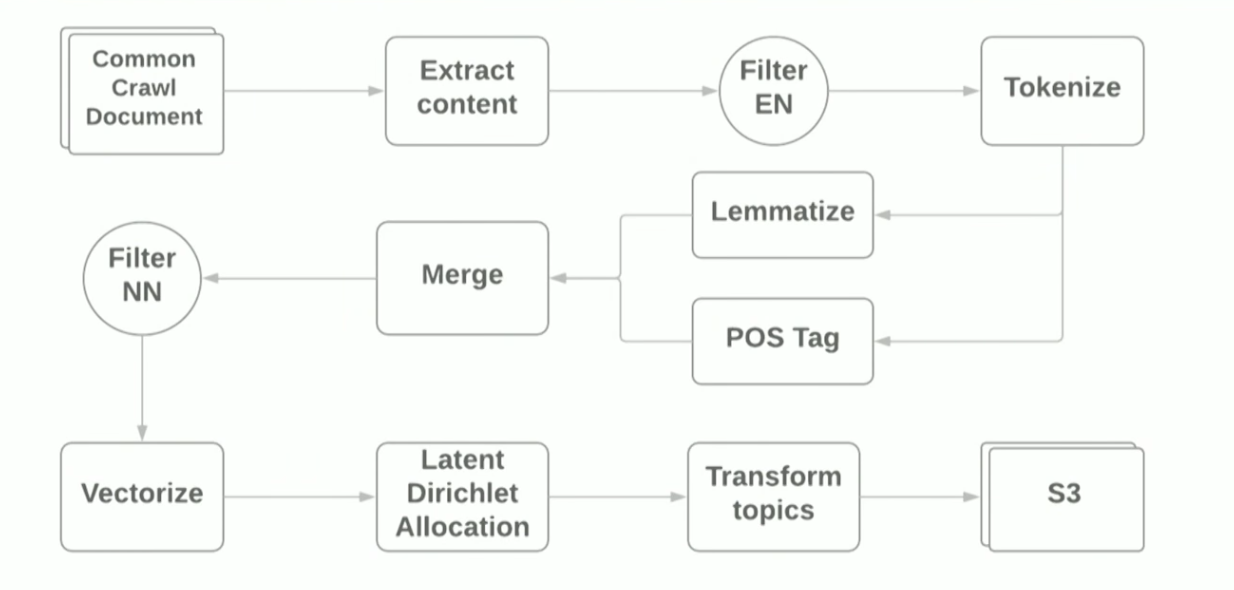
كان الغرض من التقرير هو إظهار أن استخدام الأطر الحديثة لعمل نموذج أولي لمهام ML أمر بسيط للغاية ، ومع ذلك ، باستخدام المكتبات القياسية ، لا تزال تواجه صعوبات. على سبيل المثال:
- في الخطوة الأولى من قراءة ملفات WARC باستخدام مكتبة HadoopInputFormat ، تعطلت IllegalStateExceptions أحيانًا بسبب رؤوس الملفات غير الصحيحة ، وكان يجب إعادة كتابة المكتبة وتخطي الملفات غير الصحيحة.
- تصادمت التبعيات على الجوافة - مكتبة تعريف اللغة - مع التبعيات التي يسحبها سبارك على نفسه. ساعدت Java 8 ، والتي كان من الممكن من خلالها إلقاء التبعيات على الجوافة في المكتبة المستخدمة.
خلال العرض التوضيحي ، قمنا بمراقبة تنفيذ المهمة باستخدام واجهة مستخدم Spark القياسية ونظام المراقبة الفرعي
Ganglia ، والذي يتوفر تلقائيًا عند نشره إلى AWS EMR. ركز المؤلف على الخريطة الحرارية توزيع تحميل الخادم ، والتي توضح توزيع الحمل بين العقد في المجموعة ، وقدم نصائح عامة حول تحسين عمل Spark Job: زيادة عدد الأقسام ، وتحسين تسلسل البيانات ، وتحليل سجلات GC. يمكنك قراءة المزيد حول تحسين وظائف Spark
هنا . يمكن العثور على الملفات المصدر للعرض التوضيحي في
github لمؤلف التقرير.
Graal و Truffle و SubstrateVM وغيرها من الامتيازات: ما هي هذه الأشياء ولماذا تحتاجها
أكثر ما كان متوقعًا بالنسبة لي كان تقريرًا من Oleg Chirukhin من JUG.ru. أخبر كيفية تحسين الشفرة النهائية باستخدام الكأس. ما هي الكأس؟ Grail هي علامة تجارية لـ
Oracle Labs ، والتي تجمع بين مترجم JIT (في الوقت المناسب) ، وإطار كتابة لغات DSL - Truffle - و JVM الخاص (
SubstrateVM ) - آلة افتراضية عالمية
مغلقة يمكنك الكتابة عنها في JavaScript ، روبي ، بيثون ، جافا ، سكالا. ركز التقرير على مترجم JIT واختباره في الإنتاج.
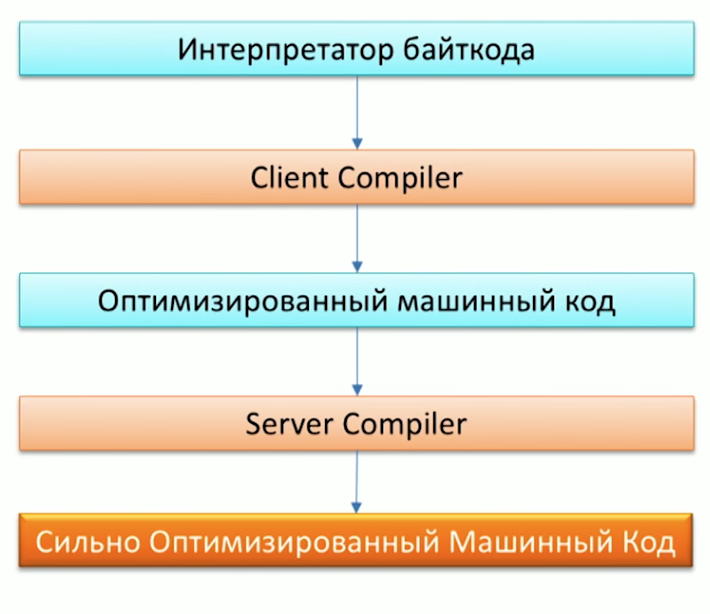
أولاً ، تذكر عملية تنفيذ التعليمات البرمجية بواسطة جهاز Java ولاحظ أن Java لديها بالفعل مترجمين: C1 (مترجم برنامج العميل) و C2 (خادم مترجم). يمكن استخدام الكأس كمترجم C2.
عندما سُئل لماذا نحتاج إلى مترجم آخر ، أجاب أحد موظفي Oracle Labs ، الدكتور كريس سيتون ، جيدًا في المقالة
فهم كيفية عمل Graal . باختصار ، الفكرة الأصلية لمشروع Graal ، بالإضافة إلى مشروع
Metropolis ، هي إعادة كتابة أجزاء من كود JVM المكتوب بلغة C ++ في Java. هذا سيجعل من الممكن في المستقبل تكملة الكود بسهولة. على سبيل المثال ، أحد التحسينات - P
artial Escape Analysis - موجود بالفعل في Grail ، ولكن ليس في Hotspot -
لأن توسيع كود Grail أسهل بكثير من كود C2 .
هذا يبدو رائعا ، ولكن كيف ستعمل في الممارسة العملية في مشروعي ، تسأل؟ الكأس مناسبة للمشاريع:
- مما يفرز الكثير ، مما يخلق الكثير من الأشياء الصغيرة.
- مكتوب بأسلوب Java 8 ، مع مجموعة من التدفقات ولامداس.
- باستخدام لغات مختلفة: Ruby، Java، R.
واحدة من الأولى في الإنتاج ، بدأ استخدام الكأس على تويتر. يمكنك قراءة المزيد عن هذا في مقابلة مع كريستيان تالنجر ، المنشورة على حبري (
مقابلة 1 و
مقابلة 2 ). هناك ، يشرح أنه من خلال استبدال C2 بـ Graal ، بدأ Twitter في توفير حوالي 8 ٪ من استخدام وحدة المعالجة المركزية ، وهو أمر جيد جدًا بالنظر إلى حجم المؤسسة.
في المؤتمر ، تمكنا أيضًا من التحقق من سرعة Graal من خلال إطلاق أحد معايير Scala بموجبه -
Scala DaCapo . ونتيجة لذلك ، في Graal ، تم تمرير المعيار في ~ 7000 مللي ثانية ، وعلى JVM عادي في ~ 14000 مللي ثانية! لماذا حدث هذا ، يمكنك أن ترى من خلال النظر في اختبارات gclog. عدد فشل التخصيص عند استخدام Graal أقل بكثير من Hotspot. ومع ذلك ، لا يزال لا يمكنك القول أن Grail سيكون الحل لمشاكل الأداء في تطبيق Java الخاص بك. أظهر أوليغ أيضًا قصة فشل في تقريره ، قارن بين عمل
Apache Ignite تحت الكأس وبدونه - لم يكن هناك تغيير ملحوظ في الأداء.

تصميم الخدمات الدقيقة المتسامحة
تم قراءة تقرير آخر عن بنية الخدمات الصغيرة الآمنة من الفشل بواسطة Orkhan Gasimov من AppsFlyer. قدم أنماط تصميم شعبية لبناء التطبيقات الموزعة. قد نعرف الكثير منهم جيدًا ، لكن التجول واستدعاء كل منهم لن يضر على الإطلاق.
المشاكل الرئيسية لتسامح الأخطاء مع الخدمات التي يتم استدعاء الأنماط الموصوفة في التقرير للقتال هي: الشبكة ، أحمال الذروة ، آليات RPC للتواصل بين الخدمات.
لحل مشاكل الشبكة ، عندما تكون إحدى الخدمات غير متاحة ، نحتاج إلى القدرة على استبدالها بسرعة بأخرى من نفس الخدمة. من الناحية العملية ، يمكن تحقيق ذلك من خلال عدة مثيلات للخدمة نفسها ووصف المسارات البديلة لهذه المثيلات ، وهو نمط
اكتشاف الخدمة . الانخراط في خدمات
ضربات القلب وتسجيل الخدمات الجديدة ستكون نسخة منفصلة - سجل الخدمة. من المعتاد استخدام
Zookeeper أو
القنصل المعروفين
كسجل الخدمة. وهو بدوره له طبيعة موزعة ودعم لتحمل الأخطاء.
بعد حل مشاكل الشبكة ، ننتقل إلى مشكلة ذروة الأحمال عندما تكون بعض الخدمات تحت التحميل ومعالجة الطلبات بشكل أبطأ بكثير من الوضع العادي. لحلها ، يمكنك استخدام نمط
التحجيم التلقائي . لن يتولى فقط مهمة توسيع نطاق الخدمات المحملة تلقائيًا فحسب ، بل سيتوقف أيضًا عن الحالات بعد فترة الذروة.
كان الفصل الأخير من تقرير المؤلف وصفاً للمشاكل المحتملة للاتصال الداخلي بين الخدمات RPC. يولي أوراهان اهتمامًا خاصًا لرسالة "لا يجب على المستخدم انتظار رسالة خطأ لفترة طويلة." قد ينشأ مثل هذا الموقف إذا تمت معالجة طلبه بواسطة سلسلة الخدمة وكانت المشكلة في نهاية السلسلة: وفقًا لذلك ، يمكن للمستخدم الانتظار حتى تتم معالجة الطلب من قبل كل من الخدمات في السلسلة وفقط في المرحلة الأخيرة يتلقى خطأ. الأسوأ من ذلك كله ، إذا كانت الخدمة النهائية محملة بشكل زائد ، وبعد انتظار طويل ، سيتلقى العميل خطأ HTTP لا معنى له: 500.
لمكافحة مثل هذه المواقف ، يمكنك استخدام
Timeout s ، ومع ذلك ، يمكن أن تظل الطلبات التي لا يزال من الممكن معالجتها بشكل صحيح تقع في المهلة. للقيام بذلك ، يمكن أن يكون منطق المهلة معقدًا ويمكن إضافة قيمة عتبة خاصة لعدد أخطاء الخدمة لكل فاصل زمني. عندما يتجاوز عدد الأخطاء قيمة العتبة ، نتفهم أن الخدمة قيد التحميل ونعتبرها غير متاحة ، مما يمنحها الوقت اللازم للتعامل مع المهام الحالية. يصف هذا النهج نمط
قواطع الدائرة . يمكنك أيضًا استخدام CircuitBreaker.html "> Circuit Beaker كمقياس إضافي للمراقبة ، والذي سيسمح لك بالاستجابة بسرعة للمشكلات المحتملة وتحديد بوضوح سلاسل الخدمة التي تواجهها. للقيام بذلك ، يجب أن يتم تغليف كل مكالمة خدمة في Circuit Breaker.
في التقرير أيضًا ، أشار المؤلف إلى نمط
التكرار N-Modular ، المصمم لـ "معالجة الطلبات بشكل أسرع إن أمكن" ، وقدم مثالًا رائعًا على استخدامه للتحقق من عنوان العميل. تم إرسال الطلب في نظامهم من خلال ذاكرة التخزين المؤقت للعناوين على الفور إلى العديد من موفري الخريطة الجغرافية ، ونتيجة لذلك فاز أسرع رد.
بالإضافة إلى الأنماط الموصوفة ، تم ذكر ما يلي:
- نمط المسار السريع ، الذي يمكن تطبيقه ، على سبيل المثال ، عند تخزين نتائج الاستعلام في ذاكرة التخزين المؤقت. ثم الوصول إلى ذاكرة التخزين المؤقت هو المسار السريع.
- نمط خطأ Kernel - نمط من عالم Akka ينطوي على تقسيم مهمة إلى مهام فرعية وتفويض مهام فرعية إلى الجهات الفاعلة في المصب. بهذه الطريقة ، يتم تحقيق مرونة معالجة أخطاء تنفيذ المهام الفرعية.
- Instance Healer ، الذي يفترض وجود خدمة خاصة - مشرف يدير خدمات أخرى ويستجيب للتغيرات في حالتها. على سبيل المثال ، في حالة وجود أخطاء في الخدمة ، يمكن للمشرف إعادة تشغيل خدمة المشكلة.

مصادر الأحداث المجمعة و CQRS مع Akka و Java
التقرير الأخير الذي أود أن أوجه انتباهكم إليه تمت قراءته من قبل أحد الإنجيليين والمهندسين المعماريين Light Hend Hugh McKee. Lightbend (المعروف سابقًا باسم Typesafe) هو شيء يشبه Oracle ، ولكن بالنسبة للغة Scala. كما تعمل الشركة بنشاط على تطوير إطار
Akka.io. في تقرير ، تحدث هيو عن تنفيذ نهج
CQRS (أوامر مسؤولية استعلام الأوامر /
SEGREGATION )
المشهور في إطار عمل Akka. من الناحية التخطيطية ، تبدو بنية نظام CQRS كما يلي:
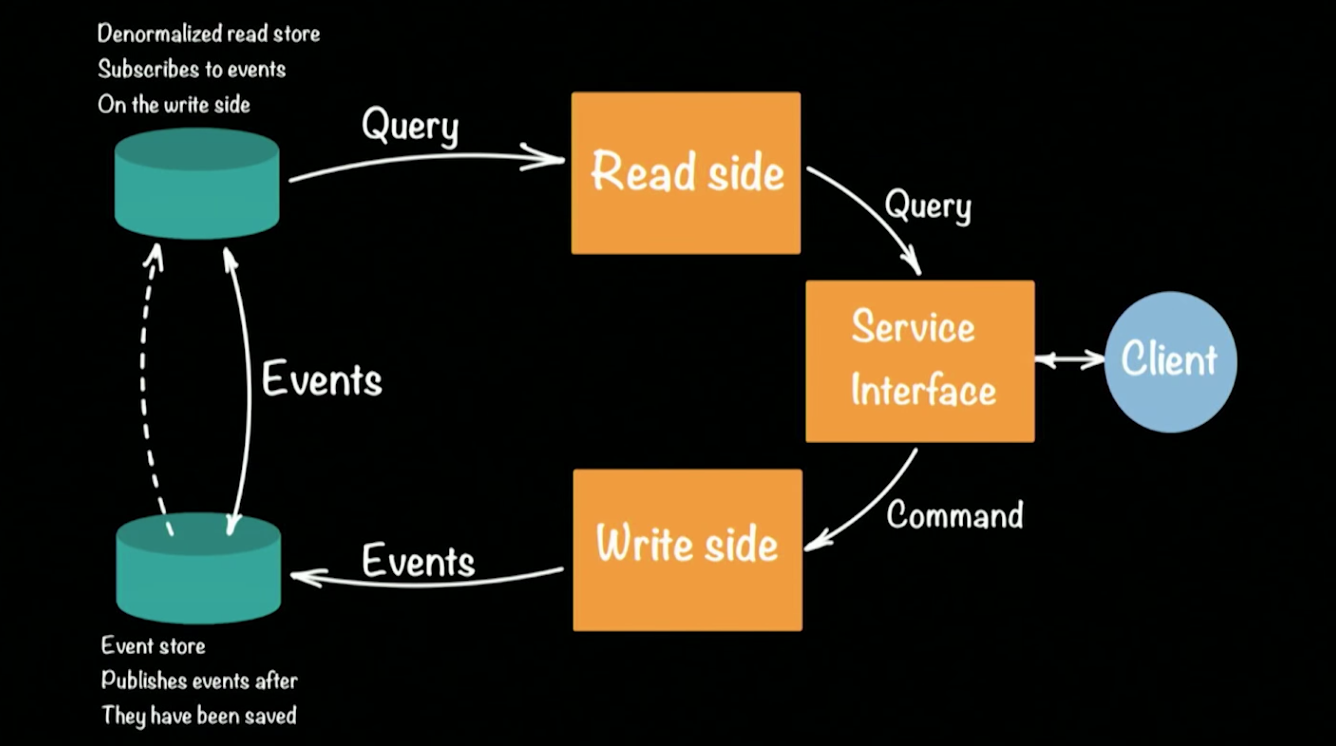
أخذ هيو نموذجًا أوليًا للبنك كمثال لنظام العمل. يقوم عميل في بنية CQRS بعمليتين: الاستعلام ، الأمر. يقوم كل فريق (على سبيل المثال ، معاملة مصرفية تحول الأموال من حساب إلى آخر) بإنشاء حدث (أمر واقع) سيتم تسجيله في EventStore (على سبيل المثال: كاساندرا). يشكل تجميع السلسلة (إيداع الأموال في حساب ، والتحويل من حساب لآخر ، والسحب في ماكينة الصراف الآلي) من الأحداث الحالة الحالية للعميل ، ورصيده في الحساب. تنتقل طلبات الحالة الحالية إلى مستودع منفصل ، وهو لقطة من مستودع الأحداث ، حيث لا معنى للاحتفاظ بسجل كامل لحساب مصرفي. يكفي تحديث الحالة المصبوبة لكل مستخدم بشكل دوري.
يتيح هذا النهج إمكانية الاسترداد تلقائيًا عند حدوث الأخطاء: لهذا نحتاج إلى الحصول على آخر حالة لحالة المستخدم ونطبق عليها جميع الأحداث التي حدثت قبل حدوث الخطأ. نظرًا لوجود مخزنين ، فإن بنية CQRS تتسامح مع أحمال الذروة الناشئة (المسامير) بشكل جيد. سيتم تحميل عدد كبير من الأحداث في Event Store ، ولكن لن يؤثر ذلك على Read Store ، وسيظل المستخدمون قادرين على تنفيذ الاستعلامات إلى قاعدة البيانات.
دعنا نعود إلى النموذج الأولي للنظام المصرفي في Akka و CQRS. سيتم تمثيل كل عميل للبنك / الحساب / الفريق المحتمل في النظام بممثل واحد (!). يمكن لبنك كبير أن يدعم مئات الآلاف من الحسابات ، ولن يكون هذا مشكلة بالنسبة لـ Akka. يدعم إطار العمل الجاهز للتجميع ، ويمكن تشغيله على مئات من JVMs. في حالة فشل أحد الأجهزة في المجموعة ، يوفر Akka آليات خاصة تستجيب تلقائيًا لمثل هذه المواقف: في حالتنا ، يمكن إعادة إنشاء ممثل العميل مرة أخرى على أي جهاز متوفر في المجموعة ، وستتم إعادة قراءة حالته من المستودع.
لا يتم إنشاء سلسلة محادثات منفصلة لممثل - وهذا يجعل من الممكن دعم عشرات الآلاف من الممثلين داخل JVM واحد. في الوقت نفسه ، يضمن الممثل أن تتم معالجة كل طلب بشكل منفصل (!) بترتيب استلام الطلبات. يلغي هذا الضمان تلقائيًا ظروف السباق المحتملة عند معالجة الطلبات. يمكنك فهم النموذج الأولي للنظام بمزيد من التفاصيل من خلال فتح الكود الخاص به باستخدام الروابط الموجودة في GitHub. يوضح كل مشروع فرعي تنفيذ المراحل الأكثر تعقيدًا لبناء نموذج أولي:
الدبابير.
ستظهر سجلات جميع التقارير عبر الإنترنت في غضون بضعة أسابيع. آمل أن تساعدك هذه المقالة في تحديد ترتيب العرض ، خاصة وأنني أعتقد أنه يستحق مشاهدة العروض.