 الانتقام من مونتيزوما لعبة مستويات اللعبةأظهر
الانتقام من مونتيزوما لعبة مستويات اللعبةأظهر DeepMind عملية تعلم الذكاء الاصطناعي (شكله الضعيف) لتمرير الألعاب على Atari. تم التدريب من خلال توضيح نظام تمرير لعبة الفيديو من يوتيوب. يتم استخدام هذه الطريقة من قبل العديد من اللاعبين البشر الذين لم يتمكنوا ، لسبب أو لآخر ، من اجتياز نوع من اللعبة.
عادة ، لحل هذه المشكلة ، من الضروري استخدام ما يسمى أسلوب
التعلم المعزز . هذه التقنية شائعة جدًا ، لأنها تتيح لك تدريب الروبوتات على أداء مهام محددة مختلفة. بمجرد أن يحقق النظام أي نتيجة ، فإنه يحصل على مكافأة صغيرة.
يقوم المطورون بإنشاء خوارزميات ونماذج قادرة على تقييم بيئة الألعاب ، بما في ذلك المكافآت المحتملة للإكمال (النقاط والمكافآت وما إلى ذلك). تتعلم هذه الأنظمة اللعبة خطوة بخطوة ، وتتحرك تدريجيًا إلى المباراة النهائية.
تختلف الطريقة الجديدة التي تم تطويرها في DeepMind عن غيرها. تمكن المتخصصون في الشركة من تدريب الذكاء الاصطناعي للعب الألعاب في Atari مثل Montezuma's Revenge و Pitfall و Private Eye. في الوقت نفسه ، لم يتم التركيز على النقاط والجوائز - ذهب التدريب على دروس من YouTube. وهذا سمح لنا بتحقيق نتائج غير عادية للذكاء الاصطناعي.
والحقيقة هي أن الألعاب مثل لعبة Revenge من Montezuma يصعب على الأجهزة "فهمها". لا توجد مهمة واضحة ، وليس من الواضح إلى أين تذهب ، وما هي العناصر التي يجب جمعها وما يجب فعله بها في المستقبل. يتم فقدان الماكينة ببساطة ، لأنه في عملية الترقية لا تحصل على مكافآت والتدريب مع تعزيزات هنا تصبح عديمة الفائدة أو عديمة الفائدة تقريبًا.
في اللعبة المعنية ، تحتاج إلى التحكم في شخصية تسمى بنما جو. في النهاية ، يجب أن يصل إلى الخزانة في المعبد القديم. وفقًا للأسطورة ، تنتمي هذه الكنوز إلى مونتيزوما. تحتاج أولاً إلى العثور على أول عنصر حاسم لتمرير اللعبة - المفتاح الذهبي. لاكتشاف ذلك ، تحتاج إلى اتباع حوالي 100 خطوة. ولكن هذا إذا كنت تعرف ماذا تفعل حيال ذلك. إذا لم يكن الأمر كذلك ، فهناك عدد كبير من الاحتمالات 100 من الإجراءات الـ
18 الأولية. هذا كثير جدًا على أي ذكاء اصطناعي تم إنشاؤه بواسطة الإنسان. حسنًا ، لن تحصل على مكافأة هنا ، كل شيء محدد للغاية.
إحدى الطرق لإعلام الكمبيوتر بما يجب فعله هي إظهار سيناريوهات المقطع. في الواقع ، ليس فقط السيارات ، ولكن أيضًا يتعلم الناس أداء مهام مختلفة عن طريق الأمثلة. الرقص ، أعمال الفنان ، اللحام - كل هذا أفضل رؤيته مرة واحدة ، وليس 100 مرة لسماع كيفية القيام بذلك.
توصل DeepMind إلى استنتاج مفاده أن هذه هي أفضل طريقة لإظهار الكمبيوتر لكيفية إتمام مهمة بنتيجة ضمنية. ساعدت التكنولوجيا التي أنشأها الخبراء حقا. تم استخدام طريقتين لتدريس المثال: TDC (تصنيف المسافة الزمنية) و CDC (تصنيف المسافة الزمنية عبر الوسائط).
في الحالة الأولى ، يتم تدريب الذكاء الاصطناعي لتحديد المسافة في بيئة اللعبة ، لملاحظة الفرق بين إطارين مختلفين. كما تفهم منظمة العفو الدولية ما يجب القيام به للانتقال من مكان إلى آخر. للتدريب على موقع YouTube ، يتم تخصيص مقاطع الفيديو لأزواج من الإطارات بترتيب عشوائي.
في الحالة الثانية ، يتم أيضًا إضافة "فهم" المرافقة الصوتية. تتوافق الأصوات في جميع الألعاب تقريبًا مع أداء بعض الإجراءات. على سبيل المثال ، القفز ، والحصول على العناصر ، وما إلى ذلك. وبالتالي ، يتم تدريب الكمبيوتر على إدراك الأصوات كعناصر مهمة في اللعبة. يسمح Video + sound للكمبيوتر بالقيام بعمل جيد في عملية اجتياز اللعبة.
فيما يلي إجراءات منظمة العفو الدولية المدربة في انتقام مونتيزوما. تم العثور على مرور المباراتين الأخريين المذكورين في البداية.
صحيح أنه لم يكن من الممكن التخلي تمامًا عن دور المكافآت - حتى الآن ، يعتمد الذكاء الاصطناعي على نفس النقاط. لكن الطريقة المعتادة لتدريس النظام ، والتي تم استخدامها سابقًا ، لم تسمح بالحصول على الأقل على المفتاح الذهبي ، الذي تم من خلاله إعطاء المئات الأولى من النقاط. لذا فإن الذكاء الاصطناعي ، مثل الهريرة العمياء ، مطعون في كل الاتجاهات ، ولا يفهمون ماذا يفعلون. صحيح ، تم تعديل نظام "التعزيز" أيضًا.
في عملية تمرير كل إطار فيديو 16 من سجل تمرير لعبة الذكاء الاصطناعي ، تتم مقارنته بإطارات الفيديو التي تمر باللعبة بواسطة الأشخاص. إذا أظهرت المقارنة درجة عالية من التشابه ، فإن الذكاء الاصطناعي يحصل على مكافأة. بمرور الوقت ، يبدأ الذكاء الاصطناعي في تنفيذ نفس تسلسل الإجراءات التي يقوم بها الشخص ، من أجل الحصول على إطار مماثل.
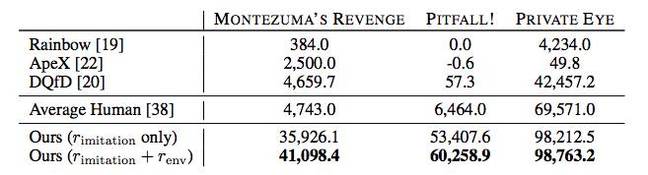
علاوة على ذلك ، يظهر الذكاء الاصطناعي في كثير من الحالات نتائج أفضل من اللاعبين البشريين أو خوارزميات تمرير أخرى ، بما في ذلك Rainbow و ApeX و DQfD.
من حيث المبدأ ، كل هذا مثير للإعجاب ، ولكن حتى الآن الفوائد العملية لإنجازات DeepMind غير واضحة. هل من الممكن استخدام طريقة تدريس الذكاء الاصطناعي التي تقترحها الشركة في أي مكان غير اجتياز الألعاب القديمة؟ ولكن بمعرفة إنجازات DeepMind في مجال الذكاء الاصطناعي ، ليس هناك شك في أنه يمكن استخدام كل هذا بطريقة أو بأخرى لأغراض عملية - من غير المحتمل أن يبدأ الخبراء في العمل على هذه القضية من أجل "المرح".