عادة ما تكون هذه المدونة مخصصة للتعرف على لوحة الترخيص. ولكن ، في العمل على هذه المهمة ، توصلنا إلى حل مثير للاهتمام يمكن تطبيقه بسهولة على مجموعة واسعة جدًا من مهام رؤية الكمبيوتر. سنتحدث عن هذا الآن: كيفية إنشاء نظام التعرف الذي لن يخيب ظنك. وإذا فشلت ، يمكنك إخبارها بمكان الخطأ ، وإعادة التدريب والحصول على حل موثوق به أكثر قليلاً من ذي قبل. مرحبًا بك في القط!

ماذا حدث؟
تخيل أنك واجهت المهمة: العثور على بيتزا في الصورة وتحديد نوع البيتزا.
دعنا نذهب بإيجاز عبر المسار القياسي الذي نسير فيه كثيرًا. لماذا؟ لفهم كيفية القيام ... لا حاجة.
الخطوة 1: التقط القاعدة
 الخطوة 2: من
الخطوة 2: من أجل موثوقية التعرف ، يمكن ملاحظة أن هناك بيتزا وما هي الخلفية (لذلك سنقوم بتضمين شبكة عصبية مجزأة في إجراء التعرف ، ولكن غالبًا ما يستحق ذلك):
 الخطوة 3:
الخطوة 3: نضعها في "شكل طبيعي" ونصنف باستخدام شبكة عصبية تلافيفية أخرى:

عظيم! الآن لدينا قاعدة تدريب. في المتوسط ، يمكن أن يكون حجم قاعدة التدريب عدة آلاف من الصور.
نأخذ شبكتين ملتويتين ، على سبيل المثال ، Unet و VGG. يتم تدريب الأول على الصور المدخلة ، ثم نقوم بتطبيع الصورة وتدريب VGG للتصنيف. إنه يعمل بشكل رائع ، ننقله إلى العميل وننظر في الأموال المكتسبة بصدق.
لا يعمل هكذا!
لسوء الحظ ، تقريبًا. هناك العديد من المشاكل الخطيرة التي تنشأ أثناء التنفيذ:
- تقلب بيانات الإدخال. درسنا في مثال واحد ، في الواقع ، تحول كل شيء بشكل مختلف. نعم ، فقط أثناء العملية ، حدث خطأ ما.
- في كثير من الأحيان ، تظل دقة التعرف غير كافية. أريد 99.5٪ ، لكن من 60٪ إلى 90٪ في يوم جيد. لكنهم أرادوا ، كقاعدة عامة ، أتمتة حل يعمل في حد ذاته ، وحتى أفضل من الناس!
- غالبًا ما يتم الاستعانة بمصادر خارجية لمثل هذه المهام ، مما يعني أن العقود قد تم إغلاقها بالفعل ، ويتم التوقيع على الإجراءات ويجب على صاحب العمل أن يقرر ما إذا كان سيستثمر في المراجعة أو التخلي عن القرار تمامًا.
- نعم ، إنها تبدأ في التدهور بمرور الوقت ، كما هو الحال في أي نظام معقد ، إذا لم تقم بإشراك متخصصين شاركوا في الإنشاء ، أو نفس المستوى من التأهيل.
نتيجة لذلك ، بالنسبة للكثيرين الذين لمسوا كل هذه الميكانيكا بأيديهم ، يصبح من الواضح أن كل شيء يجب أن يحدث بطريقة مختلفة تمامًا. شيء من هذا القبيل:
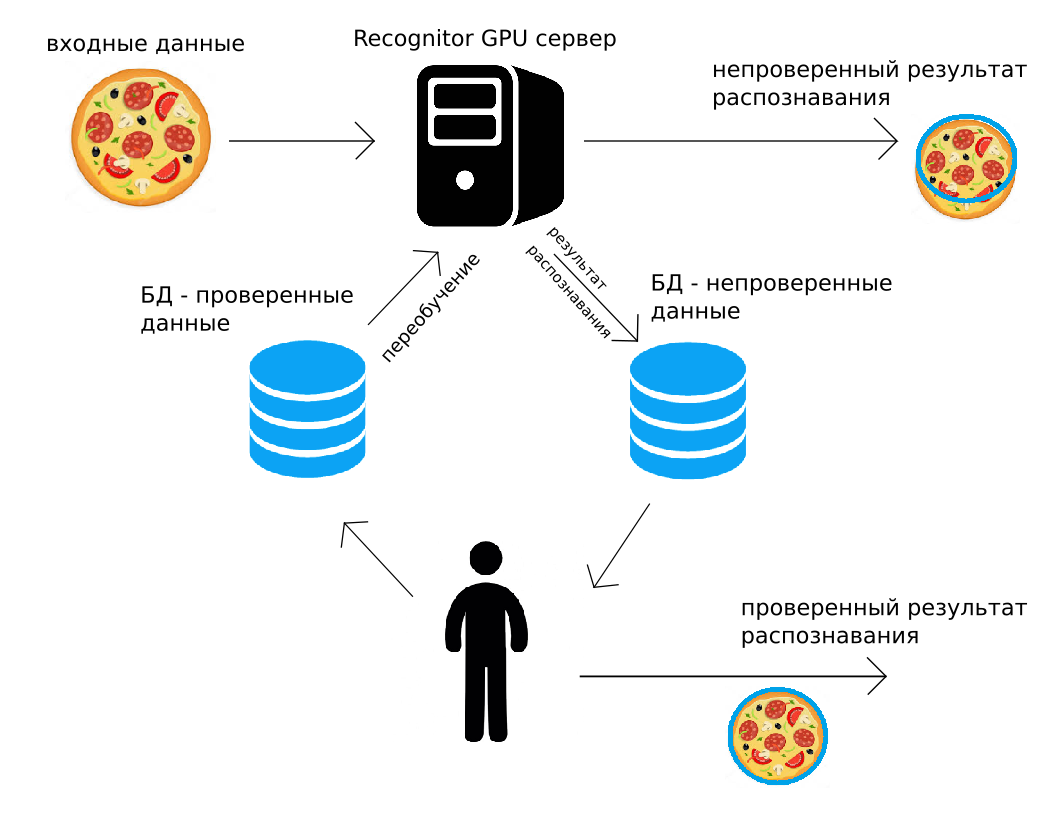
يتم إرسال البيانات إلى خادمنا (عبر http POST ، أو باستخدام Python API) ، سيتعرف خادم GPU عليها "كما يمكن" ، ويعيد النتيجة على الفور. على طول الطريق ، تتم إضافة نفس نتيجة التعرف مع الصورة إلى الأرشيف. ثم يتحكم الشخص في جميع البيانات أو جزء عشوائي منها ، ويقوم بتصحيحها. يتم وضع النتيجة المصححة في الأرشيف الثاني. وبعد ذلك ، عندما يكون من الملائم القيام بذلك (على سبيل المثال ، في الليل) ، سيتم إعادة تدريب جميع الشبكات العصبية التلافيفية المستخدمة للاعتراف ، باستخدام البيانات التي قام الشخص بتصحيحها.
مثل هذه الدائرة الاعتراف ، والإشراف البشري ، والمزيد من التدريب يحل العديد من المشاكل المذكورة أعلاه. بالإضافة إلى ذلك ، في تلك الحلول التي تتطلب دقة عالية ، يمكن استخدام الإخراج المتحقق منه بواسطة الإنسان. يبدو أن هذا الاستخدام للبيانات التي تم التحقق منها من قبل الإنسان مكلف للغاية ، ولكن بعد ذلك سنوضح أنه دائمًا ما يكون له معنى اقتصادي.
مثال حقيقي
لقد قمنا بتطبيق المبدأ الموصوف وقمنا بتطبيقه بنجاح على العديد من المهام الحقيقية. أحدها هو التعرف على الأرقام على صور الحاويات في محطات السكك الحديدية المأخوذة من جهاز لوحي. إنه مريح للغاية - وجه الجهاز اللوحي إلى الحاوية ، واحصل على الرقم المعترف به وقم بالتعامل معه في برنامج الجهاز اللوحي.
مثال على اللقطة النموذجية:

في الصورة ، الرقم مثالي تقريبًا ، فقط الكثير من الضوضاء البصرية. ولكن تحدث الظلال القاسية أو الثلج أو تخطيطات الحروف غير المتوقعة أو الانحرافات الخطيرة أو وجهات النظر عند التصوير.
وهكذا يبدو وكأنه مجموعة من صفحات الويب التي يحدث فيها كل "السحر":
1) تحميل الملف إلى الخادم (بالطبع ، يمكن القيام بذلك ليس من صفحة html ، ولكن باستخدام Python أو أي لغة برمجة أخرى):
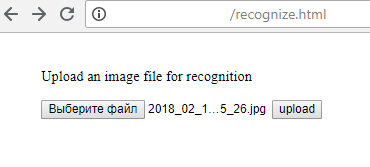
2) يعرض الخادم نتيجة التعرف:
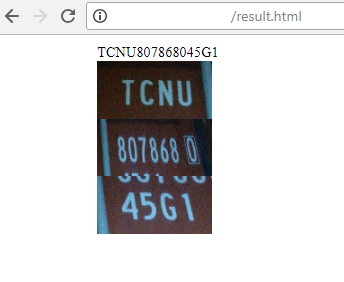
3) وهذه صفحة للمشغل الذي يراقب نجاح الاعتراف وتصحيح النتيجة ، إذا لزم الأمر. هناك مرحلتان: البحث عن مناطق مجموعات الرموز والتعرف عليها. يمكن للعامل تصحيح كل هذا إذا رأى خطأ.
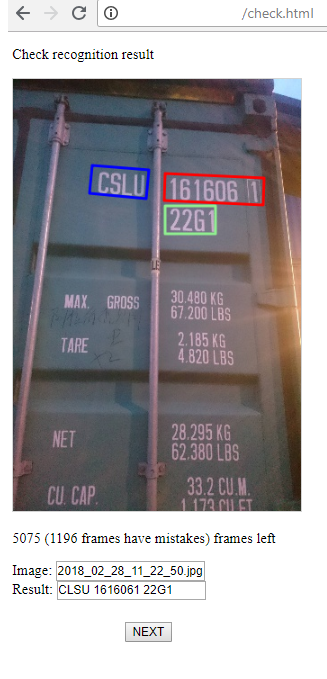
4) إليك صفحة بسيطة حيث يمكنك بدء التدريب لكل مرحلة من مراحل التعرف ، ومن خلال الجري ، شاهد الخسارة الحالية.
بساطتها قاسية ، لكنها تعمل بشكل رائع!
كيف يمكن أن يبدو هذا من جانب شركة تخطط لاستخدام النهج الموصوف (أو خبراتنا وخوادم التعرف)؟
- يتم اختيار الشبكات العصبية الحديثة. إذا كان كل شيء يستند إلى حلول تصحيح الأخطاء الموجودة ، فيمكنك عندئذ بدء تشغيل الخادم وتكوين الترميز في غضون أسبوع.
- يتم تنظيم دفق بيانات (يفضل أن يكون لا نهائي) على الخادم ، ويتم وضع علامة على عدة مئات من الإطارات.
- يبدأ التدريب. إذا كان كل شيء "مناسبًا" ، فإن النتيجة هي 60-70٪ من الاعتراف الناجح ، مما يساعد بشكل كبير في المزيد من العلامات.
- ثم يبدأ العمل المنهجي لعرض جميع المواقف الممكنة ، والتحقق من نتائج التعرف ، والتحرير ، وإعادة التدريب. كما تعلم ، أصبح تضمين النظام في عملية تجارية أكثر فعالية من حيث التكلفة.
من يفعل هذا أيضا؟
سمة الحلقة المغلقة ليست جديدة. تقدم العديد من الشركات أنظمة معالجة البيانات من نوع أو آخر. ولكن يمكن بناء نموذج العمل بطرق مختلفة تمامًا:
- Nvidia Digits هي بعض الموديلات الجيدة والقوية ملفوفة في واجهة المستخدم الرسومية البديهية حيث يحتاج المستخدم لإرفاق صوره و JSON. زائد الرئيسي - الحد الأدنى من المعرفة بالبرمجة والإدارة يمنحك حلاً جيدًا. ناقص - يمكن أن يكون هذا الحل بعيدًا عن المثلى (على سبيل المثال ، لا يمكن البحث عن أرقام السيارات عبر SSD جيدًا). ولفهم كيفية تحسين الحل ، لا يمتلك المستخدم المعرفة الكافية. إذا كان لديه ما يكفي من المعرفة ، فهو لا يحتاج إلى أرقام. النقص الثاني - تحتاج إلى امتلاك معداتك الخاصة لتكوين ونشر كل شيء.
- خدمات الترميز مثل Mechanical Turk و Toloka و Supervise.ly. توفر لك الأولين أدوات الترميز ، وكذلك الأشخاص الذين يمكنهم ترميز البيانات. يوفر الأخير أدوات رائعة ، ولكن بدون أشخاص. من خلال الخدمات ، يمكنك أتمتة العمل البشري ، ولكن يجب أن تكون خبيرًا في تحديد المهمة.
- الشركات التي تدربت بالفعل وقدمت حلاً ثابتًا (Microsoft و Google و Amazon). اقرأ المزيد عنها هنا (https://habr.com/post/312714/). قراراتهم ليست مرنة ، ولن تكون دائمًا "تحت الغطاء" أفضل القرارات اللازمة في قضيتك. بشكل عام ، لا يساعد ذلك دائمًا.
- الشركات التي تعمل بشكل خاص مع بياناتك ، على سبيل المثال ScaleAPI (https://www.scaleapi.com/). لديهم واجهة برمجة تطبيقات رائعة ، بالنسبة للعميل سيكون صندوقًا أسود. بيانات الإدخال - نتيجة الإخراج. من المحتمل جدًا أنه يوجد في الداخل أفضل حلول الأتمتة ، ولكن هذا لا يهمك. حلول مكلفة للغاية من حيث إطار واحد ، ولكن إذا كانت بياناتك ذات قيمة حقًا - فلماذا؟
- الشركات التي تمتلك الأدوات اللازمة للقيام بدورة كاملة تقريبًا بأيديهم. على سبيل المثال ، PowerAI من IBM . إنها تقريبًا مثل DIGITS ، ولكن عليك فقط ترميز مجموعات البيانات. بالإضافة إلى ذلك ، لا أحد يحسن الشبكات والحلول العصبية. ولكن تم حل الكثير من الحالات. يتم نشر نموذج الشبكة العصبية الناتج لك وسيتم منحه وصول http. هناك نفس العيب هنا كما هو الحال في الأرقام - تحتاج إلى فهم ما يجب فعله. هذه هي حالتك التي قد "لا تتلاقى" أو تتطلب ببساطة نهجًا غير معتاد للاعتراف. بشكل عام ، الحل مثالي إذا كان لديك مهمة قياسية إلى حد ما ، مع كائنات قابلة للفصل جيدًا يجب تصنيفها.
- الشركات التي تحل مشكلتك تمامًا باستخدام أدواتها. لا يوجد العديد من هذه الشركات. في الواقع ، أود أن أشير فقط إلى CrowdFlower. هنا للحصول على أموال معقولة ، سيضعون الخربشات ، ويخصصون مديرًا ، وينشرون خوادمهم ، حيث سيتم إطلاق نماذجك. وللحصول على أموال أكثر جدية ، سيكونون قادرين على تغيير أو تحسين قراراتهم لمهمتك.
تعمل معها الشركات الكبرى - ايباي ، أوراكل ، تيسكو ، أدوبي. من خلال انفتاحهم ، يتفاعلون بنجاح مع الشركات الصغيرة.
كيف يختلف هذا عن التطوير المخصص الذي تفعله EPAM ، على سبيل المثال؟ حقيقة أن كل شيء جاهز هنا. لم يتم كتابة 99٪ من الحل ، ولكن تم تجميعه من وحدات جاهزة: ترميز البيانات ، واختيار الشبكة ، والتدريب ، والتطوير. الشركات التي تتطور حسب الطلب لا تملك هذه السرعة وديناميات تطوير الحلول والبنية التحتية النهائية. نعتقد أن الاتجاه والنهج اللذين حددهما CrowdFlower صحيحان.
ما المهام التي يعمل بها هذا؟
ربما يتم أتمتة 70٪ من المهام بهذه الطريقة. المهام الأكثر ملاءمة هي التعرف المتنوع على المناطق التي تحتوي على نص. على سبيل المثال ، لوحات تسجيل السيارات ، التي
تحدثنا عنها بالفعل ، أرقام القطارات (
هنا مثالنا قبل عامين ) ، النقوش على الحاويات.

يتم التعرف على الكثير من المعلومات التقنية الرمزية في المصانع لحساب المنتجات وجودتها.
يساعد هذا النهج كثيرًا عند التعرف على المنتجات على رفوف المتاجر وبطاقات الأسعار ، على الرغم من أنه يجب إنشاء حلول التعرف المعقدة للغاية هناك.

ولكن ، يمكنك الهروب من المهام بالمعلومات التقنية. أي دلالات ، سواء كانت تجزئة المثال ، مع اكتشاف السيارات ، والأختام أرجالي ، موس والفراء ستقع أيضًا بشكل مثالي على هذا النهج.

الاتجاه الواعد للغاية هو الحفاظ على التواصل مع الناس في الروبوتات الدردشة الصوتية والنصية. ستكون هناك طريقة غير معتادة للترميز: السياق ونوع العبارة و "حشوها". لكن المبدأ هو نفسه: نحن نعمل في وضع تلقائي ، يتحكم الشخص في صحة الفهم والإجابات. يمكنك اللجوء إلى مساعدة المشغل في حالة نبرة العميل المستاءة أو المتهيجة. مع تراكم البيانات ، نعيد التدريب.
كيف تعمل مع الفيديو؟
إذا قمت أنت أو داخل شركتك بتطوير الكفاءات اللازمة (خبرة قليلة في تعلم الآلة ، والعمل مع إطار حديقة الحيوان ، سواء في وضع عدم الاتصال أو عبر الإنترنت) ، فلن تكون هناك صعوبة في حل مشاكل رؤية الكمبيوتر البسيطة: التقسيم ، والتصنيف ، والتعرف على النص ، أخرى
لكن بالنسبة للفيديو ، كل شيء ليس على ما يرام. كيف ترميز هذه الكميات اللانهائية من البيانات؟ على سبيل المثال ، قد يتبين أنه مرة كل بضع ثوانٍ يظهر كائن (أو عدة كائنات) في الإطار يحتاج إلى وضع علامة عليه. ونتيجة لذلك ، يمكن أن يتحول كل هذا إلى عرض إطار بإطار ويستهلك الكثير من الموارد بحيث لا يحتاج المرء حتى للحديث عن تحكم إضافي من قبل شخص بعد إطلاق حل. ولكن يمكن التغلب على ذلك إذا قمت بتقديم الفيديو بالطريقة الصحيحة من أجل إبراز الإطارات ذات مجال الاهتمام.
على سبيل المثال ، صادفنا سلسلة فيديو ضخمة كان من الضروري فيها تسليط الضوء على كائن معين واحد - اقتران منصات السكك الحديدية. ولم يكن الأمر سهلاً حقًا. اتضح أن كل شيء ليس مخيفًا جدًا ، إذا أخذت الشاشة على نطاق أوسع ، اختر معدل إطار ، على سبيل المثال 10FPS ، ووضع 256 إطارًا على صورة واحدة ، أي 25.6 ثانية في صورة واحدة:

ربما يبدو مخيفا. ولكن في الواقع ، يستغرق الأمر حوالي 15 ثانية للنقر إلى إطار واحد ، واختيار مركز اقتران السيارة على الإطار. وحتى شخص واحد في يوم أو يومين يمكنه ترميز ما لا يقل عن 10 ساعات من الفيديو. احصل على أكثر من 30 ألف مثال للتدريب. بالإضافة إلى ذلك ، فإن مرور المنصات أمام الكاميرا في هذه الحالة ليس عملية مستمرة (ولكن نادرًا ما يجب ملاحظة ذلك) ، فمن الواقعي تمامًا حتى في الوقت الفعلي تقريبًا تصحيح جهاز التعرف ، وتجديد قاعدة التدريب! وإذا حدث التعرف في معظم الحالات بشكل صحيح ، فيمكن التغلب على ساعة من الفيديو في غضون دقيقتين. ومن ثم فإن تجاهل الشخص للسيطرة الكاملة ، كقاعدة عامة ، ليس مربحًا اقتصاديًا.
لا يزال الأمر أسهل إذا كان الفيديو يحتاج إلى وضع علامة "نعم / لا" بدلاً من توطين الكائن. بعد كل شيء ، غالبًا ما "تلتصق الأحداث معًا" ، وبتمرير واحد للماوس ، يمكنك تمييز ما يصل إلى 16 إطارًا في المرة الواحدة.
الشيء الوحيد ، كقاعدة ، يجب عليك استخدام مرحلتين في تحليل الفيديو: البحث عن "إطارات أو مناطق اهتمام" ، ثم العمل مع كل إطار (أو تسلسل إطار) بواسطة خوارزميات أخرى.
الاقتصاد البشري - الآلة
كم يمكن تحسين تكلفة معالجة البيانات المرئية؟ بطريقة أو بأخرى ، من الضروري للغاية وجود شخص يتحكم في التعرف على البيانات. إذا كان هذا التحكم انتقائيًا ، فإن التكاليف لا تكاد تذكر. ولكن إذا كنا نتحدث عن السيطرة الكاملة ، فكم يمكن أن تكون مفيدة؟ اتضح أن هذا منطقي دائمًا تقريبًا ، إذا كان الشخص قبل أن يؤدي نفس المهمة دون مساعدة من آلة.
لنأخذ أفضل مثال في البداية: ابحث عن بيتزا في الصورة ، وترميز واختيار النوع (وفي الواقع ، عدد من الخصائص الأخرى). على الرغم من أن المهمة ليست اصطناعية كما قد تبدو. التحكم في مظهر منتجات شبكة الامتياز في الواقع موجود.
لنفترض أن التعرف باستخدام خادم GPU يتطلب 0.5 ثانية من وقت الماكينة ، لكي يقوم الشخص بترميز إطار لحوالي 10 ثوانٍ (اختر نوع البيتزا وجودتها وفقًا لعدد من المعلمات) ، وللتحقق مما إذا تم اكتشاف كل شيء بشكل صحيح بواسطة الكمبيوتر ، فأنت بحاجة إلى 2 ثانية. بالطبع ، سيكون هناك تحدي في مدى ملاءمة تقديم هذه البيانات ، ولكن مثل هذه الأوقات قابلة للمقارنة تمامًا مع ممارستنا.
نحن بحاجة إلى المزيد من المدخلات لتكلفة التخطيط اليدوي واستئجار خادم GPU. كقاعدة ، ليس عليك الاعتماد على تحميل كامل للخادم. فليكن من الممكن تحميل 100.000 إطار في اليوم (ستستغرق 60٪ من قوة المعالجة لوحدة معالجة رسومات واحدة) بتكلفة تقديرية لاستئجار خادم شهريًا يبلغ 60،000 روبل. اتضح 2 بنسات لتحليل إطار واحد على GPU. سيكلف التحليل اليدوي بتكلفة 30،000r لمدة 40 ساعة من وقت العمل 26 كوبيل لكل إطار.
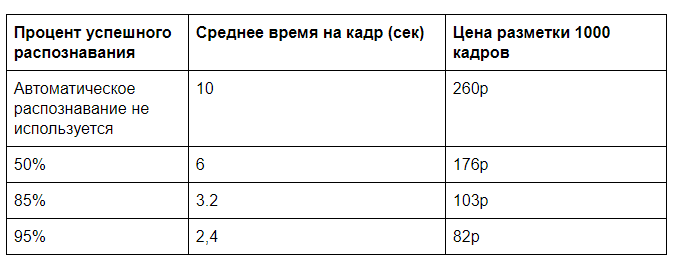
وإذا قمت بعد ذلك بإزالة عنصر التحكم الكلي ، فستتمكن من تحقيق سعر ما يقرب من 20 روبل لكل 1000 إطار. إذا كان هناك الكثير من بيانات الإدخال ، فمن الممكن تحسين خوارزميات التعرف ، والعمل على نقل البيانات وتحقيق كفاءة أكبر.
من الناحية العملية ، فإن تفريغ شخص كما يتعلم نظام التعرف له معنى آخر مهم - فهو يجعل من الأسهل بكثير توسيع نطاق منتجك. تسمح لك الزيادة الكبيرة في كمية البيانات بتدريب خادم التعرف بشكل أفضل ، وتزداد الدقة. وسيزداد عدد الموظفين المشاركين في عملية معالجة البيانات بشكل غير متناسب مع حجم البيانات ، الأمر الذي سيبسط بشكل كبير نمو الشركة من وجهة نظر تنظيمية.
كقاعدة ، كلما زاد عدد النصوص والمخططات التي يجب عليك إدخالها يدويًا ، كلما كان أكثر ربحية هو استخدام التعرف التلقائي.
وهل يتغير كل شيء؟
بالطبع ، ليس كل شيء. لكن الآن بعض مجالات العمل ليست مجنونة كما كانت من قبل.
هل تريد تقديم خدمة دون اتصال بالإنترنت دون وجود شخص في المنشأة؟ زرع عامل عن بعد ورصد
على الكاميرات لكل عميل؟ سوف يتحول إلى أسوأ قليلا من شخص حي في المكان. نعم ، ويحتاج المشغلون إلى المزيد تقريبًا. وإذا قمت بتفريغ عامل التشغيل كل 5 مرات؟ يمكن أن يكون هذا صالون تجميل بدون استقبال وتحكم في المصنع وأنظمة الأمان. دقة 100٪ غير مطلوبة - يمكنك استبعاد عامل التشغيل بالكامل من السلسلة.
من الممكن تنظيم أنظمة محاسبية معقدة نوعًا ما للخدمات القائمة لزيادة كفاءتها: التحكم في الركاب والمركبات ووقت الخدمات ، حيث يوجد خطر "تجاوز" مكتب التذاكر ، إلخ.
إذا كانت المهمة في المستوى الحالي لتطوير رؤية الكمبيوتر ولا تتطلب حلولًا جديدة تمامًا ، فلن يتطلب ذلك استثمارات جادة في التنمية.