أضيف بواسطة: مناقشة جيدة على أخبار هاكرقام David Yu على GitHub بتطوير
اختبار أداء مثير للاهتمام لاستدعاءات الوظائف من خلال واجهات خارجية مختلفة (واجهات الوظائف الأجنبية ،
FFI ).
قام بإنشاء ملف كائن مشترك (
.so ) بوظيفة واحدة بسيطة C. ثم قام بكتابة التعليمات البرمجية لاستدعاء هذه الوظيفة بشكل متكرر من خلال كل مؤسسة مالية أجنبية ذات بعد زمني.
بالنسبة إلى C "FFI" ، استخدم الارتباط الديناميكي القياسي ، وليس
dlopen() . هذا الاختلاف مهم للغاية ، لأنه يؤثر حقًا على نتائج الاختبار. يمكنك أن تجادل في مدى صدق هذه المقارنة مع FFI الفعلي ، ولكن لا يزال من المثير للاهتمام القياس.
النتيجة الأكثر إثارة للدهشة هي أن FFI
الخاص بـ LuaJIT أسرع بكثير من C. إنه أسرع بحوالي 25٪ من استدعاء C أصلي لوظيفة كائن مشترك. كيف يمكن أن تتجاوز لغة البرمجة النصية المكتوبة بشكل ضعيف وديناميكي في المعيار C؟ هل النتيجة دقيقة؟
في الواقع ، هذا منطقي تمامًا. يتم تشغيل الاختبار على Linux ، لذلك يأتي التأخير من جدول ربط الإجراءات (PLT). لقد أعددت تجربة بسيطة حقًا لتوضيح التأثير في C العادي القديم:
https://github.com/skeeto/dynamic-function-benchmarkفيما يلي نتائج Intel i7-6700 (Skylake):
plt: 1.759799 ns/call
ind: 1.257125 ns/call
jit: 1.008108 ns/callهناك ثلاثة أنواع مختلفة من استدعاءات الوظائف:
- عبر PLT.
- استدعاء دالة غير مباشر (عبر
dlsym(3) ) - استدعاء وظيفة مباشرة (عبر وظيفة JIT المترجمة)
كما ترون ، هذا الأخير هو الأسرع. عادة لا يتم استخدامه في برامج C ، ولكنه خيار طبيعي في وجود مترجم JIT ، بما في ذلك ، LuaJIT.
في مقياس الأداء الخاص بي ، تسمى الوظيفة
empty() :
void empty(void) { }
ترجمة لكائن مشترك:
$ cc -shared -fPIC -Os -o empty.so empty.c
كما هو الحال في
مقارنة PRNG السابقة ، فإن المؤشر المرجعي يستدعي أكبر عدد ممكن من هذه الوظيفة قبل انطلاق التنبيه.
جداول تخطيط الإجراءات
عندما يستدعي برنامج أو مكتبة وظيفة في كائن مشترك آخر ، لا يستطيع المترجم معرفة مكان وجود هذه الوظيفة في الذاكرة. يتم العثور على المعلومات فقط في وقت التشغيل عندما يتم تحميل البرنامج وتبعياته في الذاكرة. عادة ما تكون الوظيفة موجودة في أماكن عشوائية ، على سبيل المثال ، وفقًا للعشوائية لمساحة العنوان (العنوان العشوائي لتخطيط مساحة العنوان ، ASLR).
كيف تحل مثل هذه المشكلة؟ حسنًا ، هناك العديد من الخيارات.
أحدها هو وضع علامة على كل مكالمة في البيانات الوصفية الثنائية. ثم يقوم منشئ وقت التشغيل الديناميكي
بإدراج العنوان الصحيح في كل مكالمة. تعتمد الآلية المحددة على
نموذج الكود الذي تم استخدامه أثناء التحويل البرمجي.
عيب هذا النهج هو أنه يبطئ التحميل ، يزيد من حجم الملفات الثنائية ويقلل من
تبادل صفحات الرموز بين العمليات المختلفة. تم إبطاء التنزيل نظرًا لأن جميع أقران الاتصال الديناميكي يحتاجون إلى التصحيح بالعنوان الصحيح قبل بدء البرنامج. يتم تضخيم الثنائي لأن كل إدخال يحتاج إلى مكان في الجدول. ويرتبط نقص المشاركة بتغيير في صفحات الرموز.
من ناحية أخرى ، يمكن التخلص من الحمل الزائد للوظائف الديناميكية ، مما يعطي أداءًا يشبه JIT ، كما هو موضح في المعيار.
الخيار الثاني هو توجيه جميع المكالمات الديناميكية من خلال طاولة. يشير نظير القرص الأصلي إلى كعب في هذا الجدول ، ومن هناك إلى الوظيفة الديناميكية الفعلية. مع هذا النهج ، لا يحتاج الرمز إلى تصحيح ، مما يؤدي إلى
تبادل تافه بين العمليات. لكل وظيفة ديناميكية ، تحتاج إلى تصحيح سجل واحد فقط في الجدول. علاوة على ذلك ، يمكن إجراء هذه التصحيحات
بتكاسل ، في أول استدعاء للوظيفة ، مما يسرع من التحميل أكثر.
في الأنظمة الثنائية ELF ، يُسمى هذا الجدول جدول ربط الإجراءات (PLT). لا يتم تصحيح PLT نفسه - يتم عرضه للقراءة فقط لبقية التعليمات البرمجية. بدلاً من ذلك ، يتم تصحيح جدول الإزاحة العمومية (GOT). يسترجع كعب PLT عنوان وظيفة ديناميكية من GOT وينتقل
بشكل غير مباشر إلى هذا العنوان. لتحميل عناوين الوظائف بشكل بطيء ، تتم تهيئة إدخالات GOT بعنوان الوظيفة التي تعثر على الحرف الهدف ، وتقوم بتحديث GOT بهذا العنوان ، ثم تنتقل إلى الوظيفة. تستخدم المكالمات اللاحقة عنوانًا تم الكشف عنه بتكاسل.
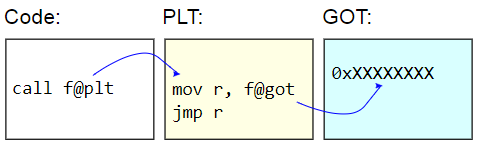
عيب PLT هو الحمل الإضافي لاستدعاء وظيفة ديناميكية ، وهو ما ظهر في المعيار. نظرًا لأن المقياس يقيس الاستدعاءات الوظيفية
فقط ، يبدو الفرق كبيرًا جدًا ، ولكنه عمليًا يكون قريبًا من الصفر.
هنا هو المعيار:
volatile sig_atomic_t running; static long plt_benchmark(void) { long count; for (count = 0; running; count++) empty(); return count; }
بما أن
empty() في كائن مشترك ، فإن المكالمة تمر عبر PLT.
مكالمات ديناميكية غير مباشرة
هناك طريقة أخرى لاستدعاء الوظائف بشكل ديناميكي وهي التنقل حول PLT والحصول على عنوان الوظيفة المستهدفة في البرنامج ، على سبيل المثال ، عبر
dlsym(3) .
void *h = dlopen("path/to/lib.so", RTLD_NOW); void (*f)(void) = dlsym("f"); f();
إذا تم استلام عنوان الوظيفة ، فستكون التكلفة أقل من استدعاء الوظيفة من خلال PLT. لا توجد وظيفة وسيطة للكعب والوصول إلى GOT. (تنبيه: إذا كان البرنامج يحتوي على سجل PLT لهذه الوظيفة ، فعندئذٍ يمكن لـ
dlsym(3) إرجاع عنوان كعب).
لكن هذا لا يزال تحديا
غير مباشر . في البنيات التقليدية ، تتلقى مكالمات الوظائف المباشرة عنوانها النسبي المباشر. أي أن الغرض من المكالمة هو بعض الإزاحة المشفرة من نقطة الاستدعاء. يمكن لوحدة المعالجة المركزية معرفة إلى أين ستذهب المكالمة قبل ذلك بكثير.
المكالمات غير المباشرة لها المزيد من النفقات العامة. أولاً ، يجب تخزين العنوان في مكان ما. حتى لو كان مجرد سجل ، فإن استخدامه يزيد من عجز السجلات. ثانيًا ، تثير المكالمات غير المباشرة مؤشرًا فرعيًا في وحدة المعالجة المركزية ، مما يفرض حملًا إضافيًا على المعالج. في أسوأ الحالات ، يمكن أن تتسبب المكالمة في توقف خط الأنابيب.
هنا هو المعيار:
volatile sig_atomic_t running; static long indirect_benchmark(void (*f)(void)) { long count; for (count = 0; running; count++) f(); return count; }
يتم استخراج الوظيفة التي تم تمريرها إلى هذا المعيار باستخدام
dlsym(3) ، لذلك لا يمكن للمترجم
القيام بشيء صعب ، مثل تحويل هذه المكالمة غير المباشرة مرة أخرى إلى مباشرة.
إذا كان جسم الحلقة معقدًا بما يكفي للتسبب في عجز في التسجيلات وبالتالي إعطاء العنوان إلى المكدس ، فلا يمكن أيضًا مقارنة هذا المعيار بصدق مع معيار PLT.
مكالمات الوظيفة المباشرة
النوعان الأولان من استدعاءات الوظائف الديناميكية بسيطة وسهلة الاستخدام. من الصعب تنظيم المكالمات
المباشرة للوظائف الديناميكية ، لأنها تتطلب تغييرات في التعليمات البرمجية أثناء التنفيذ. في مقياس الأداء الخاص بي ، قمت بتجميع
مترجم JIT صغير لإنشاء مكالمة مباشرة.
الحيلة هي أنه في x86-64 الانتقالات الواضحة تقتصر على نطاق 2 غيغابايت بسبب المعامل الموقّع 32 بت (موقّع فوري). هذا يعني أنه يجب وضع كود JIT تقريبًا بجوار الوظيفة المستهدفة
empty() . إذا كان رمز JIT يجب أن يستدعي وظيفتين ديناميكيتين مختلفتين مقسومتين على أكثر من 2 جيجابايت ، فمن المستحيل إجراء مكالمتين مباشرتين.
لتبسيط الموقف ، لا تقلق معياري بشأن الاختيار الدقيق أو الدقيق للغاية لعنوان كود JIT. بعد تلقي عنوان الوظيفة المستهدفة ، تقوم ببساطة بطرح 4 ميجابايت ، وتقريبها إلى أقرب صفحة ، وتخصيص جزء من الذاكرة وكتابة التعليمات البرمجية لها. إذا تم القيام بكل شيء كما ينبغي ، فابحث عن مكان تحتاج إليه للتحقق من تمثيلاتك الخاصة للبرنامج في الذاكرة ، ولا يمكن القيام بذلك بطريقة نظيفة ومحمولة.
يتطلب Linux
تحليل الملفات الافتراضية تحت / proc .
هذه هي الطريقة التي يبدو بها تخصيص ذاكرة JIT. يفترض
سلوك معقول لصب uintptr_t :
static void jit_compile(struct jit_func *f, void (*empty)(void)) { uintptr_t addr = (uintptr_t)empty; void *desired = (void *)((addr - SAFETY_MARGIN) & PAGEMASK); unsigned char *p = mmap(desired, len, prot, flags, fd, 0); }
تبرز صفحتان هنا: إحداهما للكتابة والأخرى برمز غير قابل للكتابة. كما هو الحال في
مكتبتي للإغلاق ، هنا الصفحة السفلى قابلة للكتابة وتحتوي على متغير
running يعيد تعيينه إلى التنبيه. يجب أن تكون هذه الصفحة بجوار رمز JIT من أجل توفير وصول فعال بخصوص RIP ، كدالة في المعيارين الآخرين. تحتوي الصفحة العلوية على رمز التجميع هذا:
jit_benchmark: push rbx xor ebx, ebx .loop: mov eax, [rel running] test eax, eax je .done call empty inc ebx jmp .loop .done: mov eax, ebx pop rbx ret
call empty هي التعليمات الوحيدة التي يتم إنشاؤها ديناميكيًا ، فمن الضروري ملء العنوان النسبي بشكل صحيح (ناقص 5 موضح بالنسبة إلى
نهاية التعليمات):
// call empty uintptr_t rel = (uintptr_t)empty - (uintptr_t)p - 5
إذا لم تكن الوظيفة
empty() في الكائن العام ، ولكن في نفس الملف الثنائي ، فهذا في الأساس عبارة عن استدعاء مباشر
plt_benchmark() المحول البرمجي لـ
plt_benchmark() ، بافتراض أنه لسبب ما لم يتم إنشاؤه
empty() .
ومن المفارقات ، استدعاء رمز JIT المترجمة يتطلب مكالمة غير مباشرة (على سبيل المثال ، من خلال مؤشر دالة) ، ولا توجد طريقة لذلك. ماذا يمكنني أن أفعل هنا ، JIT-compile وظيفة أخرى لإجراء مكالمة مباشرة؟ لحسن الحظ ، هذا لا يهم لأنه يتم قياس المكالمة المباشرة فقط في حلقة.
ليس سرا
بالنظر إلى هذه النتائج ، يصبح من الواضح لماذا تقوم LuaJIT بإجراء مكالمات أكثر كفاءة للوظائف الديناميكية من PLT ،
حتى إذا ظلت مكالمات غير مباشرة . في مقياس الأداء الخاص بي ، كانت المكالمات غير المباشرة بدون PLT أسرع بنسبة 28٪ من مكالمات PLT ، وكانت المكالمات المباشرة بدون PLT أسرع بنسبة 43٪ من مكالمات PLT. يتم تحقيق هذه الميزة الصغيرة لبرامج JIT على البرامج الأصلية القديمة البسيطة بسبب الرفض المطلق لتبادل التعليمات البرمجية بين العمليات.