مرحبًا ، اسم المستخدم! نواجه كل يوم بحثًا عن بيانات مختلفة. تقريبا كل موقع لديه الكثير من المعلومات لديه الآن بحث. البحث في أجهزة الكمبيوتر المنزلية ، في الهواتف المحمولة ، في أنواع مختلفة من البرمجيات. بالطبع ، إذا سألت أي مطور عن البحث من حيث التكنولوجيا ، فإن elasticearch ، lucene أو sphinx سيتبادر إلى الذهن على الفور. اليوم أريد أن أنظر إليك "تحت غطاء محرك البحث" للبحث عن نص كامل ومعرفة أول تقريب لكيفية عمله ، باستخدام مثال hh.ru.
 إخلاء المسؤولية: هذه المقالة ليست وجهة النظر الحقيقية الوحيدة ، وهي تعمل فقط كنقطة تمهيدية للتعرف الأولي على عمل البحث النصي وبعض الخيارات لتنفيذ أجزائه الفردية.
إخلاء المسؤولية: هذه المقالة ليست وجهة النظر الحقيقية الوحيدة ، وهي تعمل فقط كنقطة تمهيدية للتعرف الأولي على عمل البحث النصي وبعض الخيارات لتنفيذ أجزائه الفردية.إذا نظرت إلى تفاصيل البحث ، فبالإضافة إلى الجزء الواضح في شكل سلسلة بحث ، يمكنك رؤية المزيد:
- تلميح (تقترح)
- عداد نتائج البحث (عداد) ،
- أنواع مختلفة من الفرز (الفرز) ،
- الواجهات - الخصائص المجمعة للوثائق ، على سبيل المثال ، المترو الذي يوجد فيه مكان شاغر ، يؤدي أيضًا وظيفة الفلاتر (الفلاتر) ،
- المرادفات
- ترقيم الصفحات
- مقتطف (مقتطف) - وصف صغير للمستند في الإصدار ،
- الخ.

وكل هذا يخدم غرضًا واحدًا - لتلبية حاجة المستخدم للعثور على المعلومات الصحيحة في أسرع وقت ممكن وذات صلة. على سبيل المثال ، التصفية مهمة لتضييق نتائج البحث ، في حالتنا قد تكون تصفية حسب تجربة المرشح أو موقعه أو وظيفته. تعد الأوجه مفيدة لعرض عدد الوظائف الشاغرة في كل نطاق راتب. من المهم أيضًا استكمال الاستعلامات والمستندات بمرادفات بحيث يمكنهم العثور على مستندات "مطور جافا" بناءً على طلب "مطور جافا".
بالإضافة إلى البحث نفسه ، هناك دائمًا الكثير من المكونات التي تجعل الحياة أسهل للمستخدم: الوصي المسؤول عن إصلاح الأخطاء ، أو الحكيم الذي يطالب باستعلامات أكثر ملاءمة عند التفاعل مع شريط البحث. في بعض الحالات ، من المهم أن تكون قادرًا على إعادة صياغة الطلب. على سبيل المثال ، انقل جزءًا من الطلب إلى الفلاتر: من طلب "مبرمج موسكو" يمكن إخراج موسكو إلى الفلتر حسب المدينة.
1. الأساسية
الآن إلى النقطة. ينقسم البحث نفسه إلى مرحلتين كبيرتين:
- الفهرسة (معالجة المستندات ووضعها وفقًا لهياكل فهرسة خاصة ، بحيث يمكنك بعد ذلك إجراء البحث نفسه بسرعة) ،
- البحث (تطبيق الفلاتر ، البحث المنطقي ، الترتيب ، إلخ).
1.1. الفهرسة
انحدار غنائي طفيف. علاوة على ذلك ، سأقدم مفهوم المصطلح - حيث من المعتاد استدعاء الحد الأدنى من وحدة الفهرسة والاستعلام. هذه هي الوحدة نفسها التي سيتم تخزينها في قاموس الفهرس. يمكن أن تكون كلمة مختصرة إلى شكلها العادي أو قاعدتها أو رقمها أو بريدها الإلكتروني أو حرف n-grams أو أي شيء آخر. عادة ، يتضمن المصطلح حقلًا تتم فهرسته فيه أو يتم فيه البحث.
أولاً ، تحتاج إلى تحويل مستندات الإدخال إلى مجموعة من المصطلحات وتصفية كلمات التوقف. يمكن أن تكون مثل الكلمات التي تحدث بشكل متكرر - حروف الجر ، والعطف ، والمداخلات ، وأشياء أخرى ، على سبيل المثال ، الأحرف الخاصة التي لا نريد البحث عنها. لكي يعمل البحث بأشكال كلمات مختلفة ، أثناء عملية الفهرسة نأتي عادة بكل الكلمات إلى بعض الحالة الأساسية. عادة يتم استخدام أحد الإجراءين: إما الجذعية - عملية عزل أساس الكلمة (تطوير-> تنمية) ، أو lemmatization - عملية إحضار كلمة إلى الشكل الطبيعي (المهارات-> المهارة).
1.2 هياكل المؤشر
الطريقة الأكثر شيوعًا لتمثيل فهرس هي فهرس مقلوب. في الواقع ، هذا نوع من جدول التجزئة ، حيث يكون المفتاح عبارة عن المصطلح ، والقيمة هي قائمة المستندات (عادةً قائمة معرف المستند تسمى قائمة الترحيلات) التي يوجد فيها هذا المصطلح. عادة ما يتكون الفهرس المقلوب من جزئين - قاموس (قاموس المصطلحات) وقوائم الوثائق لكل مصطلح (قائمة النشر):

بالإضافة إلى ذلك ، قد يحتوي الفهرس على معلومات حول مواضع المصطلحات في المستند (فهرس المواضع) ، والتي ستكون مفيدة عند البحث عن المصطلحات على مسافة معينة ، لا سيما مع استعلامات الجملة ، حول تواتر المصطلحات ، مما سيساعد في ترتيب وبناء خطة استعلام. ولكن المزيد عن ذلك أدناه.
1.2.1 قاموس المصطلح
يقوم القاموس بتخزين جميع المصطلحات الموجودة في الفهرس ، وهو مصمم للعثور بسرعة على ارتباطات إلى قائمة المستندات. هناك عدة خيارات لتخزين القاموس:
- جدول تجزئة ، حيث المصطلح هو المفتاح ، والقيمة هي رابط لقائمة مستندات هذا المصطلح.
- قائمة مرتبة يمكنك من خلالها البحث عن طريق البحث الثنائي.
- شجرة البادئة.
الطريقة المثلى هي الخيار الأخير ، لأنه لها مزايا عديدة. أولاً ، على عدد كبير من المصطلحات ، ستشغل شجرة البادئة ذاكرة أقل بكثير ، لأنه سيتم تخزين الأجزاء المتكررة من البادئات مرة واحدة فقط. ثانيًا ، لدينا الفرصة على الفور لتقديم طلبات البادئة. وثالثًا ، يمكن ضغط مثل هذه الشجرة عن طريق الجمع بين الأجزاء غير المتفرعة.
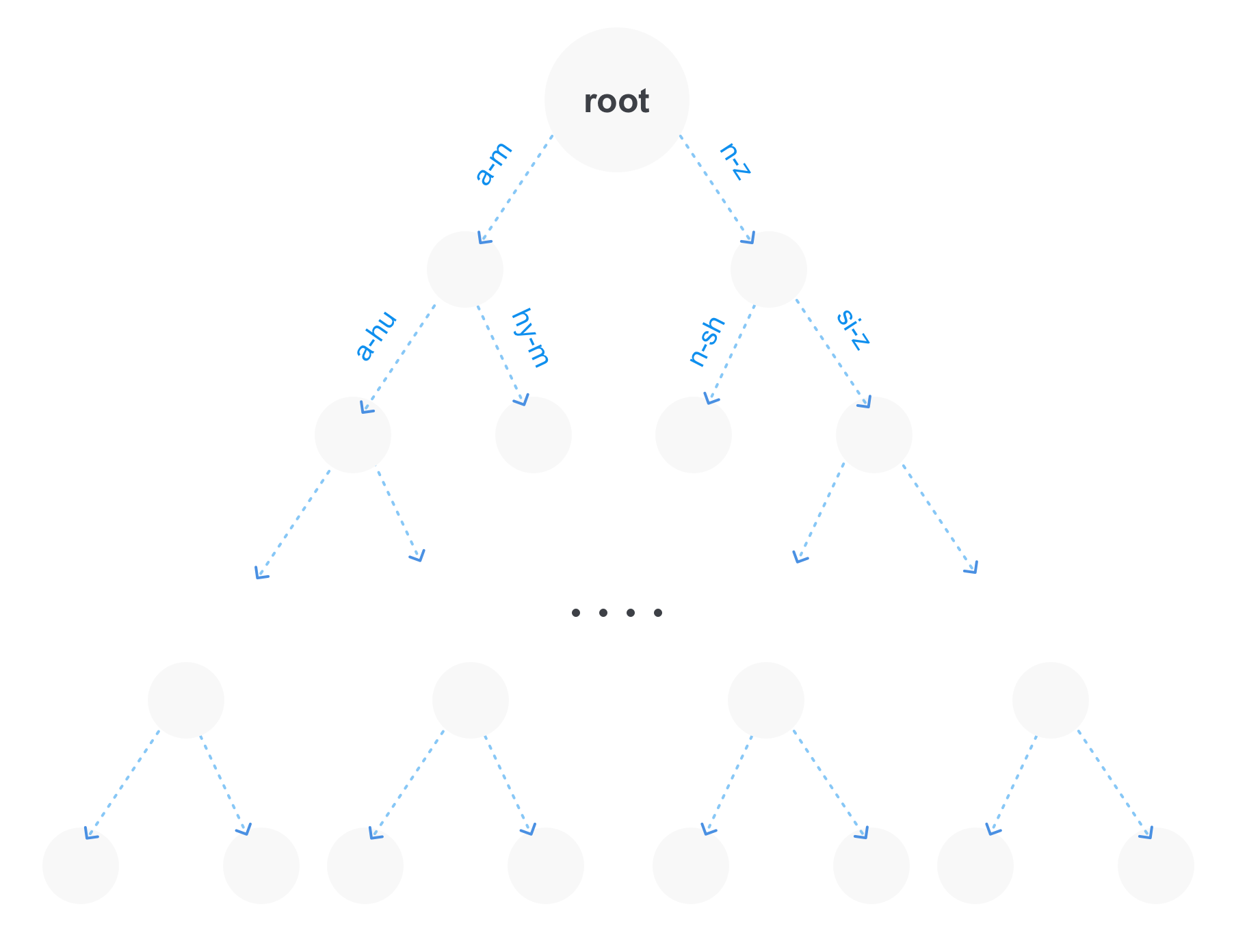
بالطبع ، قد لا تكون شجرة البادئة هي الهيكل الوحيد لتخزين المصطلحات في فهرس. على سبيل المثال ، قد تكون شجرة اللاحقة قريبة أيضًا ، والتي بدورها ستكون أكثر مثالية للاستعلامات مع الجوكر (استعلامات النموذج po * sql).
1.2.2 قائمة الترحيل
قائمة المستندات هي قائمة مرتبة من معرفات الوثيقة ، والتي تسمح بإجراء بعض التحسينات معها. عادة ما يقوم بتخزين في حد ذاته ليس فقط قائمة بالمستندات التي يحدث فيها المصطلح ، ولكن أيضًا المواقف (الترحيلات) التي تحدث فيها. هذا يحل العديد من المشاكل في وقت واحد: نحن نعلم على الفور عدد المرات التي تحدث فيها كلمة في المستند ، يمكننا عمل عبارات واستعلامات بمسافة معينة بين المصطلحات ، عبور عدة قوائم من المستندات في وقت واحد والنظر في مواضع المصطلحات.

على سبيل المثال ، في هذه القائمة بالمصطلح
scala في المستند السادس في
العنوان تحدث الكلمة 4 مرات ، في المواضع 2 و 15 و 18 و 25.
1.2.3 الوثائق ذات المجالات المتعددة
يتكون معظم المستند من عدة حقول ، على الأقل من اسم المستند ونصه. يساعد هذا عند البحث عن أجزاء فردية من المستند وعندما يكون المصطلح مهمًا عند التصنيف (على سبيل المثال ، يمكن اعتبار المصطلح الذي يظهر في العنوان أكثر أهمية).
بالإضافة إلى ذلك ، لا يتم تخزين الحقول النصية في الفهرس فقط ، ولكن يمكن أيضًا تخزين إشارات المستندات ، وبعض القيم العددية ، وما إلى ذلك. وعادة ما يأخذ التخزين في الفهرس شكل {field-term}.

على سبيل المثال ، إذا كنت شاغرًا ، فستتضمن عدة حقول في وقت واحد: الاسم والوصف والشركة وكشوف المرتبات والمدينة والخبرة اللازمة. يعد ذلك ضروريًا بحيث يمكن للمستخدم البحث بسهولة ليس فقط عن طريق اسم ونص الشركة ، ولكن أيضًا يمكنه التصفية حسب الراتب والخبرة ، ومعرفة عدد الوظائف الشاغرة في مدينته وفي المدن المجاورة ، أو حتى البحث عن وظائف شاغرة لشركة معينة.
1.3 ضغط المؤشر والتحسين
سرعة العمل مهمة للبحث ، وبالتالي ، فإن معظم عمليات البحث عن الفهرس يتم إجراؤها عادة في ذاكرة الوصول العشوائي. للقيام بذلك ، من المهم جدًا تطبيق عدد من التحسينات على الفهرس ، والتي ستلائم حجم الذاكرة المحدود. بالإضافة إلى ذلك ، يتم عادةً تطبيق عدد من التحسينات ، مما يسمح لك بالتنقل حول الفهرس بسرعة أعلى عند البحث ، وتخطي الأجزاء غير الضرورية منه.
1.3.1 ضغط دلتا
نظرًا لأننا نتذكر أن قائمة المستندات حسب المصطلح (تُعرف أيضًا باسم قائمة الترحيلات) مرتبة ، فإن الفكرة الأولى حول كيفية ضغطها هي إنشاء قائمة بإزاحة معرف المستندات بدلاً من القائمة التي تحتوي على مستندات الهوية. في قائمة محددة من 6 معرّفات ، ستبدو كما يلي:

وبالتالي ، من خلال الانتقال إلى القائمة ، سنحسب دائمًا المعرّف الحالي من القيمة السابقة التي تم الحصول عليها. على سبيل المثال ، إلى الإزاحة الثانية 3 ، نضيف القيمة الأولى 2 ونحصل على المعرف 5 ، والثالثة 4 نضيف 5 ، ونحصل على 9 وهكذا. مع وجود عدد كبير من المستندات ، يعمل هذا بشكل جيد للغاية ، خاصةً بالاقتران مع طريقة أخرى للضغط - تسجيل أرقام متغيرة التنسيق.
1.3.2 VarByte و VarInt
هذه طريقة لتخزين كل عنصر قائمة فردي في الذاكرة بحيث تشغل الحد الأدنى من المساحة. على سبيل المثال ، إذا كانت الإزاحات الثلاثة الأولى تتناسب مع بايت واحد فقط ، فلا داعي لاتخاذ المزيد. مع الأخذ في الاعتبار أن قائمتنا لا تحتوي على وثائق هوية ، ولكن الدلتا ، سيكون الضغط فعالًا جدًا. في هذا التمثيل للأرقام ، فإن البت الأول من كل بايت هو العلم ما إذا كان تمثيل الرقم الحالي ينتهي عند هذا البايت.

إذا كانت البتة الأولى من البايت 0 هي البايت الأخير من الرقم ، إذا لم يكن البايت 1.
1.3.3 تخطي قائمة / جدول الانتقال السريع
قائمة التخطي هي إحدى الهياكل للتنقل بسرعة عبر قائمة مستندات ذات مصطلح معين ، وتخطي جزء غير ضروري من القائمة. تكمن الفكرة في تخزين الروابط إلى العناصر البعيدة في القائمة على القرص أمام القائمة نفسها ، لأنه بعد الضغط لا يمكننا تحديد مكان المستند 100 أو 200 بالضبط. على سبيل المثال ، يعد هذا مناسبًا عندما يكون هناك استعلام عن مصطلحين ، حيث سيتم العثور على مصطلح واحد بشكل متكرر ، والثاني ، على العكس من ذلك ، سيكون نادرًا ، وستبدأ قائمة المستندات بمعرف المستند رقم 200 فقط. بعد ذلك ، إذا كانت هناك قائمة تحتوي على تصاريح للقائمة الأولى ، فيمكننا توفير الوقت عند الانتقال وتخطي كتلة المعرفات غير الضرورية على الفور.

1.4 الطلبات
1.4.0 استعلام مصطلح
أبسط نوع من الطلبات التي نحتاج فيها فقط إلى العثور على قائمة المستندات المناسبة وإصدار المستندات التي تم فرزها بعد التصنيف.
على سبيل المثال ، بهذه الطريقة نجد قائمة
بمواضع جافا :

1.4.1 الاستعلامات المنطقية (و ، أو لا)
البحث المنطقي هو واحد من أهم الأجزاء في استرجاع المعلومات التي نجدها في كل مكان. يعتمد البحث المنطقي بأكمله على مزيج من AND و OR و NOT. على سبيل المثال ، عندما نبحث عن استعلام بكلمتين:
java android ، في الواقع ، في بحث بسيط ، سيتم تحويله إلى
java AND android . وهذا يعني أننا نريد العثور على جميع المستندات التي تحتوي على كلتا الكلمتين.
من الجدير بالذكر على الفور كيف تتنقل في قائمة المستندات. نظرًا لأن قوائم المستندات لكل مصطلح يتم فرزها ، هناك عادةً طريقتان للتنقل عبر القوائم: الانتقال عبر المستندات بالتسلسل ، أو تمريرها واحدة تلو الأخرى ، أو الانتقال مباشرة إلى مستند معين ، وتخطي تلك غير المطلوبة (على سبيل المثال ، عندما تكون القائمة الأولى أصغر كثيرًا ، ولسنا بحاجة إلى تصفح مجموعة كبيرة من المستندات في القائمة الثانية). في هذه الحالة ، نستخدم أولاً المؤشر من تخطي المؤشرات للقائمة الثانية للتنقل قدر الإمكان من معرف المستند المطلوب ، ثم ننتقل إليه خطيًا.
في وقت البحث ، يحدث ما يلي: في فهرس المصطلحين java و android قوائم بالمستندات ، ثم يتم إجراء تقاطع عليها - أي أننا نجد المستندات التي تحتوي على كلا المصطلحين. باستخدام هذا البحث ، يتم استخدام طريقتين للتنقل عبر القوائم لعبور أسرع.

مع استعلامات OR للنموذج java OR scala ، حيث نحتاج إلى العثور على جميع المستندات التي تحتوي على واحد على الأقل من المصطلحات ، فإن الوضع مختلف - هنا لا نحتاج إلى المصطلح ليكون في جميع قوائم المستندات في وقت واحد. ولكن هناك استعلامات مع العديد من عوامل التشغيل OR ، ثم قد يحدث شرط الحد الأدنى لعدد التطابقات ، على سبيل المثال ، قد يكون هناك استعلام جافا أو OR scala OR cotlin OR clojure مع مطابقتين على الأقل ، ثم يجب أن نعرض جميع المستندات التي تحتوي على كلمتين على الأقل من الاستعلام .
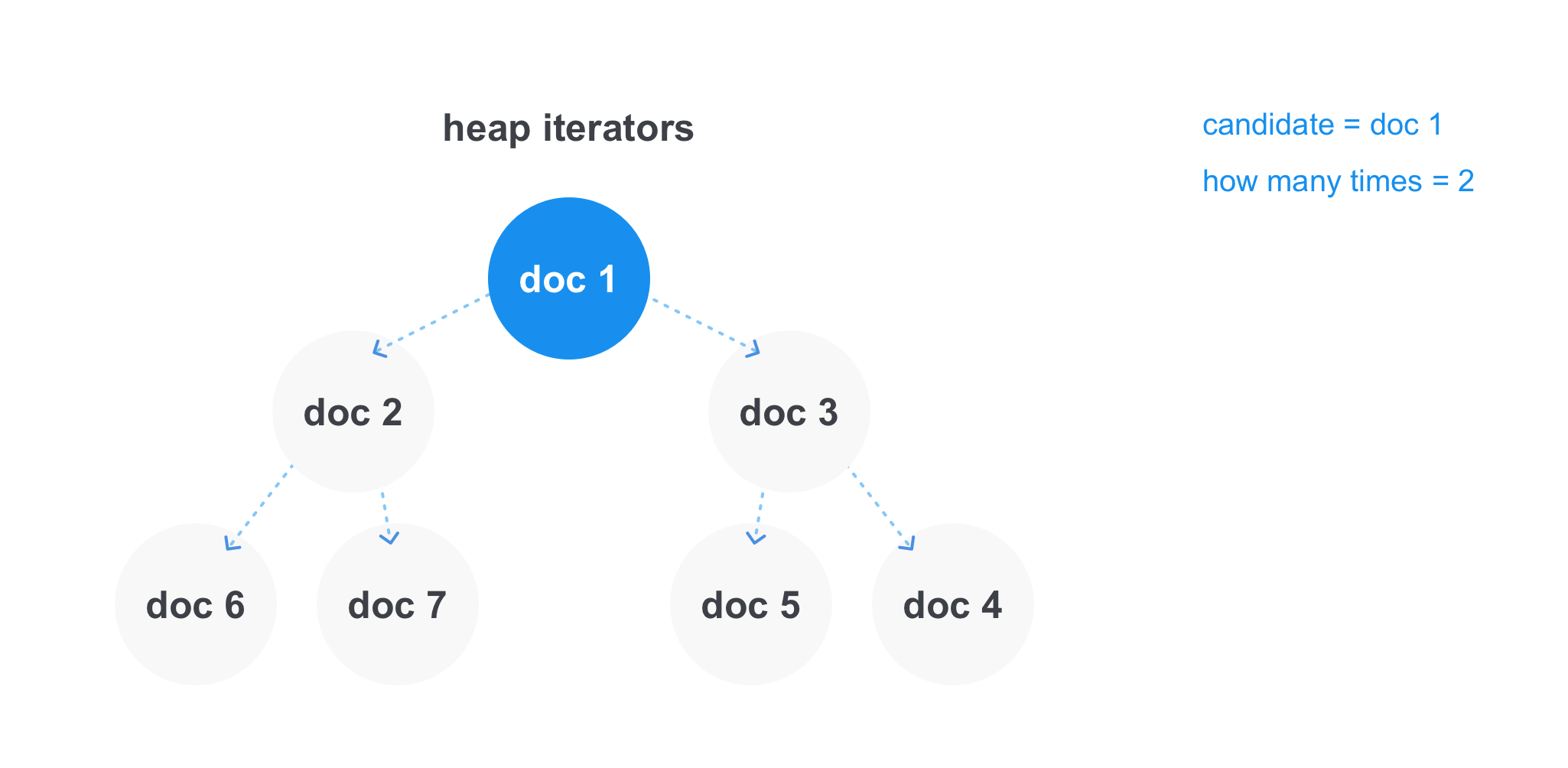
في هذه الحالة ، يعمل كومة الذاكرة المؤقتة بشكل أكثر كفاءة. يمكننا أن نخزن فيه روابط لمكررات كل قائمة ونحصل على الحد الأدنى للعنصر لوقت ثابت. بعد أن نأخذ الحد الأدنى للعنصر ، نزيل المكرر من الكومة ، ونأخذ خطوة للأمام ونضيفه إلى الكومة مرة أخرى. يمكنك تخزين المرشح الحالي بشكل منفصل لإضافته إلى النتيجة والعداد ، وعدد المرات التي التقى فيها ، وفي الوقت الذي سيختلف فيه المرشح عن الحد الأدنى للعنصر في الكومة ، راجع ما إذا كنا نجتاز بالحد الأدنى لعدد التطابقات في العملية. وأضف إما إلى القائمة النهائية للنتائج ، أو تجاهل المستند.
1.4.2 بادئة / جوكرز
نرغب أحيانًا في العثور على جميع المستندات التي تحتوي على كلمة تبدأ ببادئة معينة. في مثل هذه الحالات ، سيساعدنا طلب البادئة ، والذي سيبدو مثل
jav * . يعمل طلب البادئة بشكل جيد للغاية عندما يتم تنفيذ القاموس على شجرة البادئة ، ثم نصل إلى تداخل البادئة ونأخذ جميع المصطلحات التي تكمن أدناه.
1.4.3 استفسارات حول العبارات وقرب الاستعلام
هناك أوقات تحتاج فيها إلى العثور على العبارة بأكملها ، على سبيل المثال ، "مطور جافا" ، أو العثور على الكلمات التي لن يكون هناك أكثر من بضع كلمات بينها ، على سبيل المثال ، "جافا" و "مطور" ، والتي لا يوجد بينها أكثر من كلمتين ، بحيث يمكنك العثور على مستندات تحتوي على مطور Java android kotlin. لهذا ، يتم استخدام قوائم مواقف الكلمات في كل وثيقة بالإضافة إلى ذلك.

في لحظة عبور قوائم الوثائق ، كل شيء هو نفسه مع عملية AND. ولكن بعد العثور على المستند في كلتا القائمتين ، يتم إجراء تحقق إضافي - أن المصطلحات تقع على مسافة مناسبة من بعضها البعض ، من خلال الاختلاف في الموضع (الموضع).
1.4.4 خطة الطلب
عادة ، قبل تنفيذ الطلب نفسه ، يتم بناء خطته. يحدث هذا من أجل تحسين تنفيذ الطلب وإجراء تحسينات مثل قائمة بحذف قائمة المستندات.
إن أسهل طريقة لتحسين الاستعلام الخاص بك هي عبور قوائم المستندات من أجل زيادة الحجم. وبالتالي ، لن نضيع وثائق الهدر من القوائم الكبيرة التي ليست في قوائم صغيرة.
على سبيل المثال ، دعنا
نحلل استعلام android AND java AND sql . لنفترض أن هناك 10 مستندات في قائمة android ، في sql - 20 وفي java - 100. في هذه الحالة ، من الأفضل عبور أصغر القوائم أولاً ، وسيبدو الاستعلام الأمثل مثل
(android AND sql) و java .
في حالة OR ، أبسطها هو حساب عدد المستندات عند التقاطع كمجموع قائمتين محتملين للتقاطع.
1.4.5 ملحق الاستعلام - المرادفات
بالإضافة إلى ما يدخله المستخدم في شريط البحث ، يحاول البحث عادةً توسيع الاستعلام نفسه للعثور على المزيد من المستندات ذات الصلة. يمكن استخدام الكثير لتوسيع البحث: سجل استعلامات المستخدم ، وبعض البيانات الشخصية عنه ، والمزيد. ولكن بالإضافة إلى كل هذا ، هناك أيضًا طريقة عالمية لتوسيع الطلب - المرادفات.
في هذه الحالة ، عند كتابة المستندات إلى الفهرس ، يتم استبدال المصطلح بـ "ارتباط" في قاموس المرادفات:
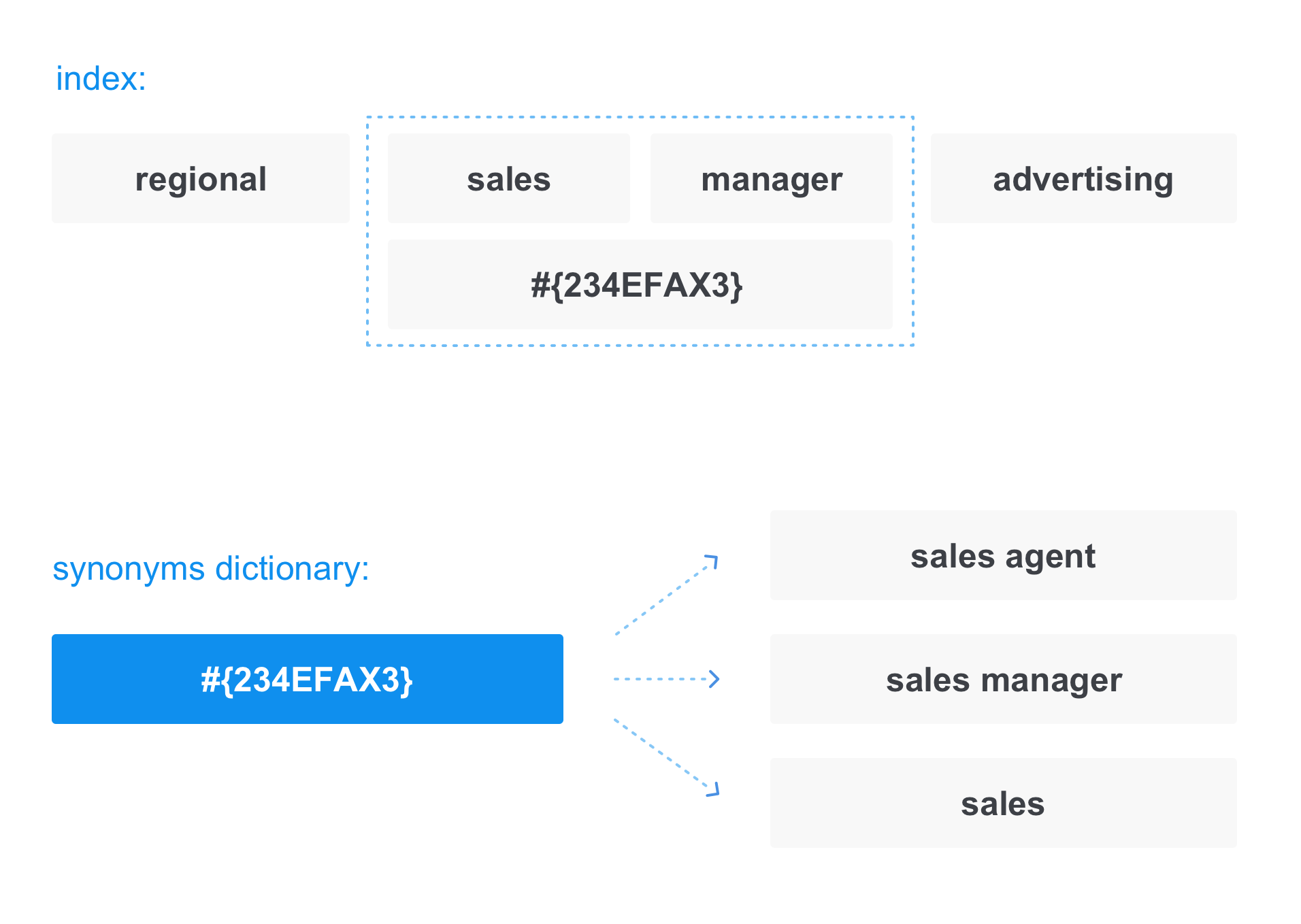
يحدث نفس الشيء عند تحويل طلب. على سبيل المثال ، عندما نطلب
مدير مبيعات ، يبدو الطلب كما يلي:

وبالتالي ، في الرد لن نتلقى فقط تلك المستندات التي تحتوي على مدير المبيعات ، ولكن أيضًا تلك التي تحتوي على وكيل مبيعات ومبيعات.
1.5 التصفية
1.5.1 مرشح النطاق السريع
في بعض الأحيان نريد تصفية شيء ما وفقًا لمجموعة من القيم ، على سبيل المثال ، حسب الخبرة في السنوات. لنفترض أننا نريد العثور على جميع الوظائف الشاغرة مع الخبرة المطلوبة من 3 إلى 11 سنة. القرار الأول هو تقديم طلب مع جميع الخيارات من النطاق ، والجمع بينها من خلال OR. لكن المشكلة هي أنه قد تكون هناك قيم كثيرة جدًا. إحدى الطرق لحل هذه المشكلة هي تسجيل القيمة بدقة متعددة في وقت واحد:

في هذه الحالة ، سنقوم بتخزين 5 قيم للدقة: سنة (سنعتبر هذه القيمة الأولية) ، اثنان ، أربعة ، ثمانية وستة عشر.
بعد ذلك ، عند التسجيل ، سيحدث ما يلي: على سبيل المثال ، عند تسجيل مستند يتطلب خبرة لمدة 6 سنوات ، نسجل القيمة على الفور بكل دقة:

عند التصفية "من 3 إلى 11 عامًا" ، يحدث ما يلي: نختار فقط القيم التي نحتاجها بالدقة المطلوبة ، ونحصل على 3 قيم فقط بدلاً من 8 ونحصل على الاستعلام
(القيمة الحقيقية == 3) أو (الدقة 4 == 4) أو (الدقة 4 == 8)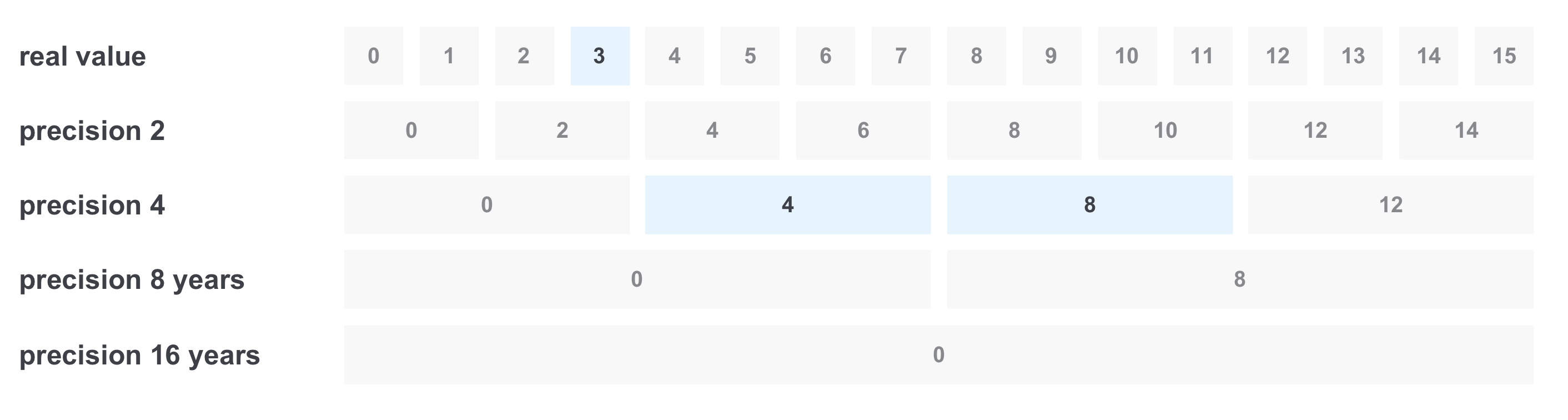
1.5.2 أقنعة البت
أقنعة البت هي جزء لا يتجزأ من الفهرس. الاستخدام الأكثر أهمية هو تصفية المستندات المحذوفة. عند حذف مستند من الفهرس ، لا يحدث الحذف الفعلي على الفور. تتم كتابة بنية خاصة بجوار الفهرس ، حيث تعني كل بت معرف المستند في الفهرس ، وعندما يتم حذفه ، يتم رفع البت ، وعند البحث ، تتم تصفية هذه المستندات ولا تقع في الإخراج.
يمكنك أيضًا استخدام أقنعة البت لتعيين أذونات لكل مستخدم إلى مستندات معينة وتخزين عوامل التصفية الشائعة الفردية. ثم عادة ما يتم تخزين أقنعة البت بشكل منفصل عن الفهرس.
على سبيل المثال ، لدينا فلاتر شائعة: مدينة موسكو ، بدوام جزئي فقط ، دون خبرة عملية. بعد ذلك ، قبل الطلب ، يمكننا الحصول على أقنعة البت المحفوظة بالفعل لهذه المستندات ، وإضافتها ، والحصول على قناع البت النهائي - أي المستندات التي تمر عبر هذه المرشحات الثلاثة ، وبالتالي توفير الوقت على التصفية.

2. الترتيب
كما نتذكر ، فإن المهمة الرئيسية للبحث هي الحصول على المعلومات الأكثر صلة في الحد الأدنى من الوقت. وفي هذا سوف يساعدنا ترتيب الوثائق بعد أن قمنا بتصفية الوثائق حسب الاستعلام النصي وتطبيق الفلاتر والحقوق اللازمة.
الطريقة الأسهل والأرخص للقيام بالتصنيف هي ببساطة فرز المستندات حسب التاريخ. في بعض الأنظمة ، تم ذلك سابقًا ، على سبيل المثال ، في الأخبار أو في الإعلانات العقارية ، لذلك تم عرض المستخدم لأول مرة على أحدث المستندات.
في بعض الأحيان ، يمكن استخدام نموذج تصنيف حسب عدد الكلمات الموجودة في المستند ، على سبيل المثال ، عندما لا يكون هناك الكثير من المستندات ، ونريد العثور على جميع المستندات التي توجد فيها واحدة على الأقل من كلمات الاستعلام. في هذه الحالة ، ستكون تلك المستندات التي تم العثور على جميع الكلمات من الاستعلام أو أكثر منها أكثر صلة بالموضوع.
بالطبع ، في الوقت الحاضر ، أصبحت هذه الأساليب غير ذات صلة بالفعل ، ومن المرجح أن تُعزى إلى تاريخ المشكلة.
2.1 TF-IDF
يعد TF-IDF (تردد المصطلح - تردد المستند المعكوس) أحد صيغ التصنيف الأساسية والأكثر استخدامًا. جوهر الصيغة هو تقليل المصطلحات المستخدمة في كل مكان ، على سبيل المثال ، حروف الجر والمداخلات ، وجعل المصطلحات ذات مغزى أكثر ندرة ، وبالتالي إظهار المستندات الأولى ذات المصطلحات الأكثر ندرة وذات مغزى من الاستعلام. الآن دعنا نكسر الصيغة إلى أجزاء:
TF (تردد المصطلح) هو تردد المصطلح الذي يحدث في المستند. يتم حسابها ببساطة:
TF term `java` = رقم المصطلح` java` في المستند / رقم جميع المصطلحات في المستند
IDF (تردد معكوس للمستند) - معكوس التردد الذي تحدث به الكلمة في مجموعة الوثائق. يساعد على تقليل وزن الكلمات شائعة الاستخدام.
IDF (`java`) = السجل (عدد المستندات في المجموعة / عدد المستندات التي يظهر فيها المصطلح` java`)علاوة على ذلك ، للحصول على TF-IDF لمصطلح java ، نحتاج فقط إلى مضاعفة قيم TF و IDF التي تم الحصول عليها. , , . , , developer , , java developer .
2.2
, , . , , , .
2.3 BM25 BM*
BM25 (Okapi best match 25) TF-IDF . BM25F, ( ).
2.4
, :
- DFR (divergence from randomness),
- IBS (information-based models),
- LM Dirichlet,
- Jelinek-Mercer.
2.5
, , . ,
.
2.6 Top k
, . , , .
, .
top k .
— . k, k
* . heap. n*log(n) k.
. , , , 10 12, score 10 score . , n — (n*page size) .
3.
3.1
— . , .
, : , , . , . . ( , ). (merge).
, , :

. , , , - .
3.2 (megre)
— . «» — . , , ( ).

, , , . :
4.
, , . , - (, . .). , , , .

4.1
(, hh , ), . .
, , . -, , . -, , , .
4.2
, . , .
, hh,
, , - :
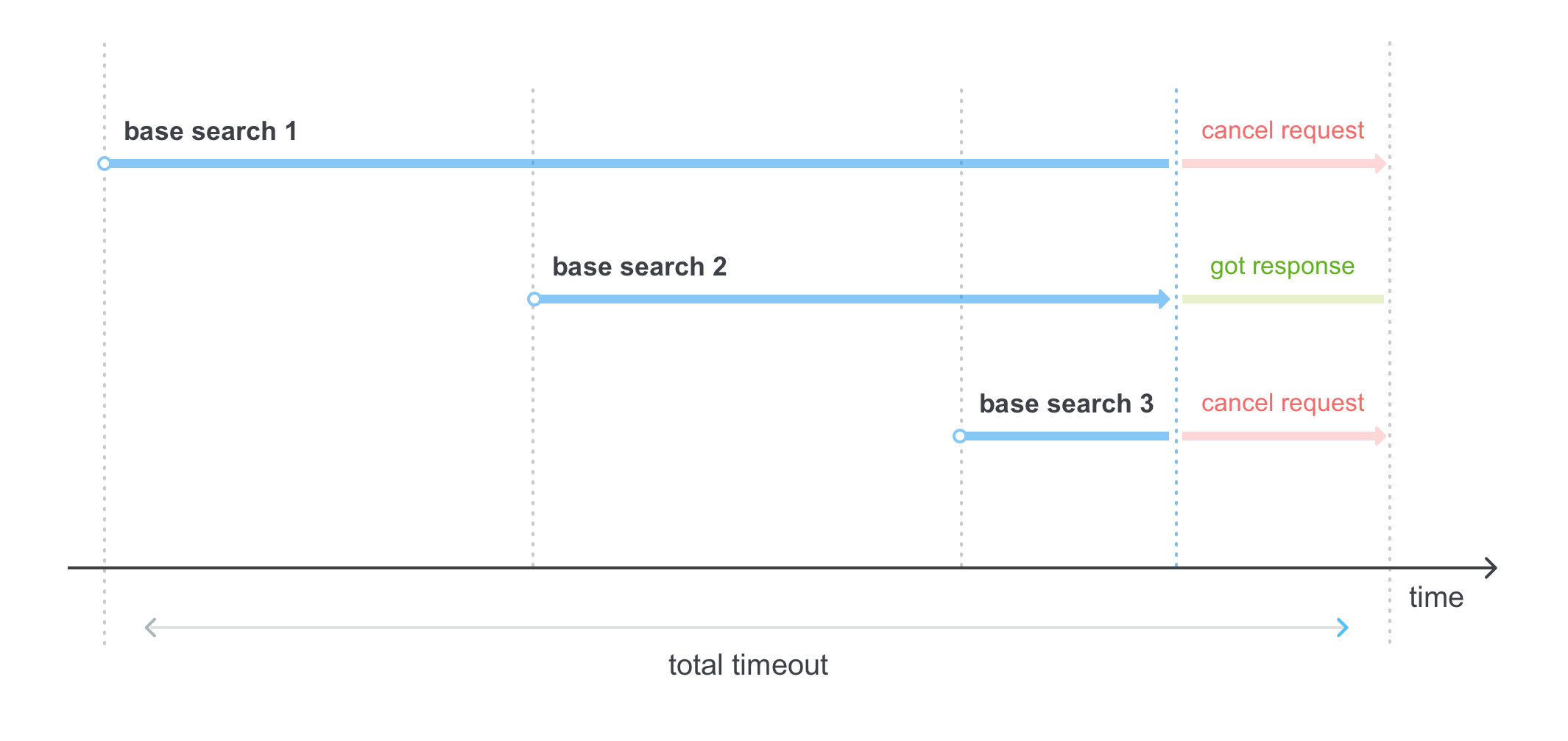
5. …
, , , . , : , , , , , (highlight), . , , , top k .
:
هذا كل شيء ، شكرًا لكم جميعًا على اهتمامكم ، من المثير للاهتمام سماع تعليقاتكم وأسئلتكم.ملاحظة
أود أن أعرب عن امتناني لغدانشين لمساعدتي في كتابة هذا المقال.