نظام مكافحة الانتحال هو محرك بحث متخصص. كما يليق بمحرك البحث بمحركه الخاص وفهارس البحث. أكبر فهرس لدينا من حيث عدد المصادر ، بالطبع ، في الإنترنت باللغة الروسية. منذ وقت طويل ، قررنا أن نضع في هذا الفهرس كل ما هو نص (وليس صورة أو موسيقى أو فيديو) ، مكتوبًا بالروسية ، بحجم أكبر من 1 كيلوبايت وليس "نسخة مكررة تقريبًا" لشيء موجود بالفعل في الفهرس.
هذا النهج جيد لأنه لا يتطلب معالجة مسبقة معقدة ويقلل من مخاطر "رش الطفل بالماء" - تخطي وثيقة يمكن استعارة النص منها. من ناحية أخرى ، نتيجة لذلك ، لا نعرف إلا القليل عن المستندات الموجودة في الفهرس في نهاية المطاف.
مع نمو مؤشر الإنترنت - والآن ، لثانية ، أصبح بالفعل أكثر من 300 مليون مستند
باللغة الروسية فقط - يطرح سؤال طبيعي تمامًا: هل هناك العديد من المستندات المفيدة حقًا في هذا التفريغ؟
وبما أننا (
yury_chekhovich و
Andrey_Khazov )
تناولنا هذا التفكير ، فلماذا لا نجيب في نفس الوقت على بعض الأسئلة
الإضافية . كم عدد الوثائق العلمية المفهرسة وكم عدد غير علمية؟ ما هي حصة المقالات العلمية بين الشهادات والمقالات والملخصات؟ ما هو توزيع الوثائق حسب الموضوع؟

نظرًا لأننا نتحدث عن مئات الملايين من المستندات ، فمن الضروري استخدام وسائل التحليل التلقائي للبيانات ، على وجه الخصوص ، تقنية التعلم الآلي. بالطبع ، في معظم الحالات ، تتفوق جودة تقييم الخبراء على طرق الماكينة ، ولكن سيكون من المكلف للغاية جذب الموارد البشرية لحل مثل هذه المهمة الواسعة.
لذا ، نحتاج إلى حل مشكلتين:
- قم بإنشاء عامل تصفية "علمي" ، والذي يسمح لك ، من ناحية ، بتجاهل المستندات التي ليست في الهيكل والمحتوى تلقائيًا ، ومن ناحية أخرى يحدد نوع المستند العلمي. إبداء تحفظ على الفور تحت "العلمي" لا يشير بأي شكل من الأشكال إلى الأهمية العلمية أو موثوقية النتائج. مهمة المرشح هي فصل المستندات التي تحتوي على شكل مقال علمي ، أطروحة ، دبلوم ، إلخ. من أنواع النصوص الأخرى ، أي الخيال والمقالات الصحفية والمقالات الإخبارية ، وما إلى ذلك ؛
- تنفيذ أداة لتسيير المستندات العلمية التي تربط الوثيقة بأحد التخصصات العلمية (على سبيل المثال ، الفيزياء والرياضيات ، والاقتصاد ، والهندسة المعمارية ، والدراسات الثقافية ، وما إلى ذلك).
في الوقت نفسه ، نحتاج إلى حل هذه المشكلات من خلال العمل حصريًا مع النسخ النصية للمستندات ، وعدم استخدام بيانات التعريف الخاصة بها ، ومعلومات حول موقع كتل النصوص والصور داخل المستندات.
دعونا توضيح مع مثال. حتى نظرة خاطفة كافية لتمييز
مقال علمي
من ، على سبيل المثال ،
حكاية خرافية للأطفال .

ولكن إذا كانت هناك طبقة نص فقط (لنفس الأمثلة) ، فعليك قراءة المحتوى.
التصفية والفرز العلمي حسب النوع
نقوم بحل المهام بالتتابع:
- في المرحلة الأولى ، نقوم بتصفية الوثائق غير العلمية ؛
- في المرحلة الثانية ، يتم تصنيف جميع الوثائق التي تم تحديدها على أنها علمية ، حسب النوع: مقال ، أطروحة المرشح ، ملخص الدكتوراه ، دبلوم ، إلخ.
يبدو شيء مثل هذا:
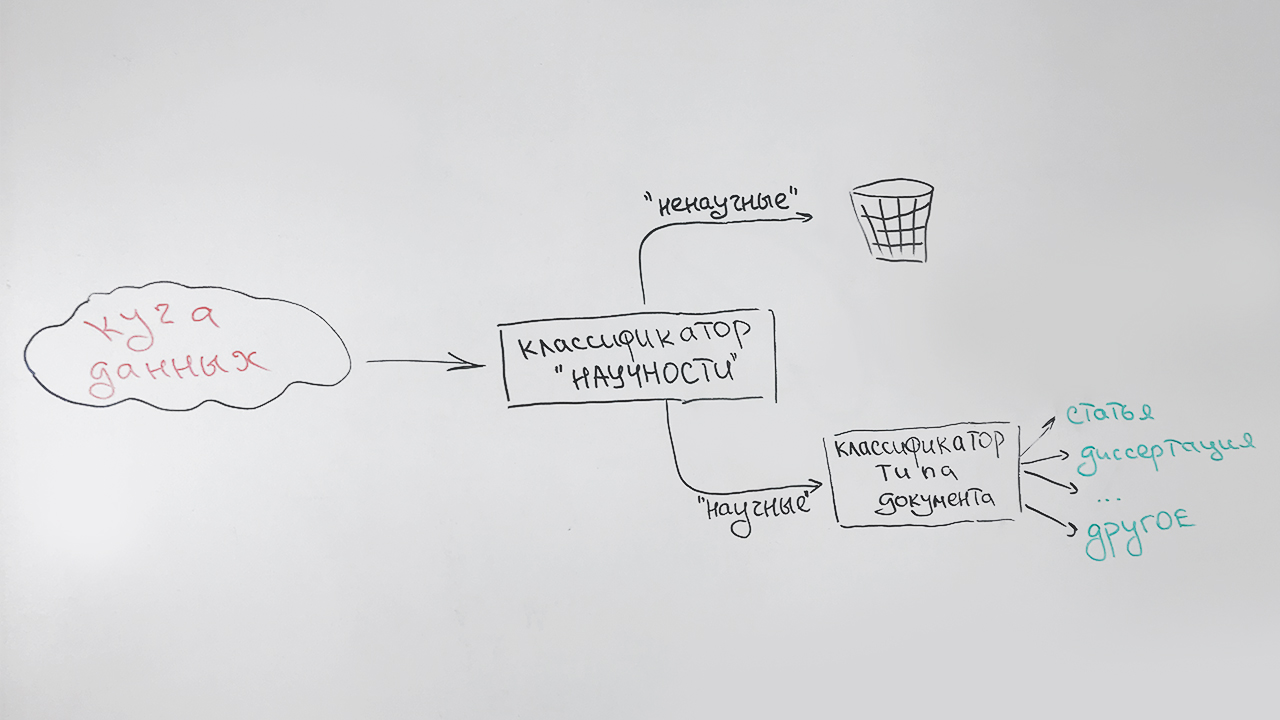
يتم تعيين نوع خاص (غير محدد) للمستندات التي لا يمكن نسبتها بشكل موثوق إلى أي نوع واحد (وهي في الأساس مستندات قصيرة - صفحات مواقع علمية ، ملخصات الملخصات). على سبيل المثال ، سيُنسب هذا المنشور إلى هذا النوع ، الذي يحتوي على بعض علامات علمية ، لكنه لا يشبه أيًا مما سبق.
هناك ظرف آخر يجب أخذه بعين الاعتبار. هذه هي سرعة عالية للخوارزمية ومتطلبات منخفضة من الموارد - ومع ذلك ، فإن مهمتنا مساعدة. لذلك ، نستخدم وصفًا إرشاديًا صغيرًا جدًا للمستندات:
- متوسط طول الجملة في النص ؛
- حصة كلمات التوقف فيما يتعلق بكل كلمات النص ؛
- مؤشر القراءة ؛
- النسبة المئوية لعلامات الترقيم فيما يتعلق بجميع أحرف النص ؛
- عدد الكلمات من القائمة ("مجردة" ، "أطروحة" ، "دبلوم" ، "شهادة" ، "تخصص" ، "دراسة" ، إلخ) في الجزء الأول من النص (السمة مسؤولة عن صفحة العنوان) ؛
- عدد الكلمات من القائمة ("قائمة" ، "أدب" ، "ببليوغرافي" ، إلخ) في الجزء الأخير من النص (السمة مسؤولة عن قائمة الأدب) ؛
- نسبة الحروف في النص ؛
- متوسط طول الكلمة ؛
- عدد الكلمات الفريدة في النص.
كل هذه العلامات جيدة من حيث أنها تحسب بسرعة. كمصنف ، نستخدم خوارزمية الغابة العشوائية (
غابة عشوائية ) ، وهي طريقة تصنيف شائعة في التعلم الآلي.
مع تقييمات الجودة في حالة عدم وجود عينة مميزة من قبل الخبراء ، من الصعب ، لذلك ندع المصنف في مجموعة من المقالات بواسطة المكتبة الإلكترونية العلمية
Elibrary.ru . نفترض أن جميع المقالات سيتم تحديدها على أنها علمية.
نتيجة 100٪؟ لا شيء من هذا القبيل - 70٪ فقط. ربما أنشأنا خوارزمية سيئة؟ نحن ننظر من خلال المقالات التي تمت تصفيتها. اتضح أن العديد من النصوص غير العلمية يتم نشرها في المجلات العلمية: الافتتاحية ، التهاني بمناسبة الذكرى ، النعي ، الوصفات ، وحتى الأبراج. مشاهدة انتقائية للمقالات التي يعتبرها المصنف علمية لا تكشف عن أخطاء ، لذلك ، نعترف بالمصنف على أنه مناسب.
الآن ننتقل إلى المهمة الثانية. هنا لا يمكنك الاستغناء عن مواد ذات جودة للتدريب. نطلب من المقيّمين إعداد عينة. نحصل على أكثر من 3.5 ألف مستند بقليل مع التوزيع التالي:
| نوع الوثيقة | عدد المستندات في العينة |
|---|
| مقالات | 679 |
| رسائل الدكتوراه | 250 |
| ملخصات رسائل الدكتوراه | 714 |
| مجموعات المؤتمرات العلمية | 75 |
| أطروحات الدكتوراه | 159 |
| ملخصات رسائل الدكتوراه | 189 |
| الدراسات | 107 |
| أدلة الدراسة | 403 |
| أطروحات | 664 |
| نوع غير محدد | 514 |
لحل مشكلة التصنيف متعدد الفئات ، نستخدم نفس الغابة العشوائية والميزات نفسها حتى لا نحسب شيئًا خاصًا.
نحصل على جودة التصنيف التالية:
| الدقة | الاكتمال | قياس F |
|---|
| 81٪ | 76٪ | 79٪ |
تظهر نتائج تطبيق الخوارزمية المدربة على البيانات المفهرسة في الرسوم البيانية أدناه. يوضح الشكل 1 أن أكثر من نصف المجموعة تتكون من وثائق علمية ، ومن بينها ، أكثر من نصف الوثائق عبارة عن مقالات.
 التين. 1. توزيع الوثائق "العلمية"
التين. 1. توزيع الوثائق "العلمية"يوضح الشكل 2 توزيع الوثائق العلمية حسب النوع ، باستثناء نوع "المقالة". يمكن ملاحظة أن النوع الثاني الأكثر شيوعًا من الوثيقة العلمية هو كتاب مدرسي ، والنوع الأكثر ندرة هو أطروحة الدكتوراه.
 التين. 2. توزيع الوثائق العلمية الأخرى حسب النوع
التين. 2. توزيع الوثائق العلمية الأخرى حسب النوعبشكل عام ، تتماشى النتائج مع التوقعات. لم نعد بحاجة إلى المصنف السريع "التقريبي".
تعريف موضوع الوثيقة
حدث ذلك أنه لم يتم إنشاء مصنف موحد ومعترف به عالميًا للمصنفات العلمية. الأكثر شعبية اليوم هي عناوين
VAK ،
GRNTI ،
UDC . تحسبًا لذلك ، قررنا تصنيف المستندات حسب الموضوع ضمن كل فئة من هذه الفئات.
لبناء مصنّف مواضيعي ، نستخدم نهجًا يعتمد على
نمذجة الموضوعات ، وهي طريقة إحصائية لبناء نموذج لمجموعة من المستندات النصية ، حيث يتم تحديد احتمالية الانتماء إلى موضوعات معينة لكل وثيقة. كأداة لبناء نموذج مواضيعي ، نستخدم مكتبة
BigARTM المفتوحة. لقد استخدمنا هذه المكتبة بالفعل من قبل ونعلم أنها رائعة للنمذجة المواضيعية لمجموعات كبيرة من المستندات النصية.
ومع ذلك ، هناك صعوبة واحدة. في النمذجة المواضيعية ، فإن تحديد تركيبة وهيكل الموضوعات هو نتيجة لحل مشكلة التحسين فيما يتعلق بمجموعة معينة من المستندات. لا يمكننا التأثير عليهم مباشرة. بطبيعة الحال ، لن تتوافق الموضوعات الناتجة عن الضبط مع مجموعتنا مع أي من المصنفات المستهدفة.
لذلك ، من أجل الحصول على القيمة غير المعروفة النهائية لمعيِّن وثائق طلب معين ، نحتاج إلى إجراء تحويل آخر. للقيام بذلك ، في مساحة موضوع BigARTM ، باستخدام خوارزمية الجوار الأقرب (
k-NN ) ، نبحث عن العديد من المستندات الأكثر تشابهًا مع الاستعلام باستخدام قواعد البيانات المعروفة ، وبناءً على ذلك ، نقوم بتعيين الفئة الأكثر صلة بمستند الاستعلام.
في شكل مبسط ، تظهر الخوارزمية في الشكل:

لتدريب النموذج ، نستخدم المستندات من مصادر مفتوحة ، بالإضافة إلى البيانات المقدمة من Elibrary.ru مع التخصصات المعروفة للجنة العليا للتصديق ، SRSTI ، UDC. نزيل من مستندات المجموعة التي ترتبط بمواضع عامة جدًا لعلم التشحيم ، على سبيل المثال ،
المشاكل العامة والمعقدة في العلوم الطبيعية والدقيقة ، لأن مثل هذه المستندات ستسبب ضجيجًا كبيرًا في التصنيف النهائي.
تضمنت المجموعة النهائية حوالي 280 ألف وثيقة للتدريب و 6 آلاف وثيقة للاختبار لكل من نماذج التقييم.
لأغراضنا ، يكفي أن نتنبأ بقيم عناوين المستوى الأول. على سبيل المثال ، بالنسبة لنص بقيمة
GRNTI 27.27.24: وظائف متناسقة وتعميماتها ، فإن توقع القسم
27: الرياضيات صحيح.
لتحسين جودة الخوارزمية المطورة ، نضيف إليها بعض الأساليب استنادًا إلى
مصنف Naive Bayes القديم الجيد. كعلامات ، فإنه يستخدم تردد الكلمات الأكثر تميزًا لكل مستند يحتوي على قيمة محددة لعنوان HAC.
لماذا هذا صعب؟ ونتيجة لذلك ، نأخذ توقعات كل من الخوارزميات ونثقلها وننتج متوسط توقعات لكل طلب. تسمى هذه التقنية في التعلم الآلي
بالتجميع . يمنحنا هذا النهج زيادة ملحوظة في الجودة. على سبيل المثال ، بالنسبة لمواصفات SRSTI ، كانت دقة الخوارزمية الأصلية 73٪ ، ودقة مصنِّف Bayes الساذج 65٪ ، وارتباطاتهم 77٪.
ونتيجة لذلك ، نحصل على مثل هذا المخطط من المصنف لدينا:
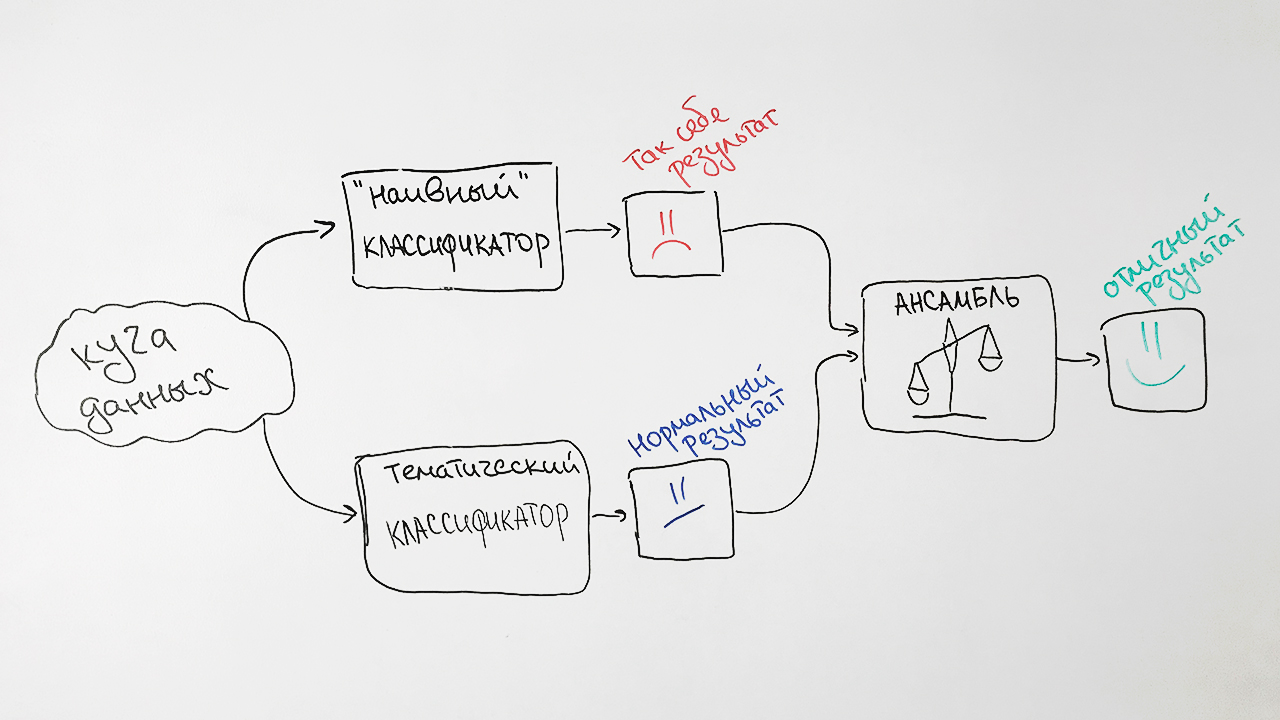
نلاحظ عاملين يؤثران على نتائج المصنف. أولاً ، يمكن تعيين أي مستند لأكثر من قيمة لقاعدة البيانات في المرة الواحدة. على سبيل المثال ، قيم عنوان الهيئة العليا للتصديق 25.00.24 و 08.00.14 (الجغرافيا
الاقتصادية والاجتماعية والسياسية والاقتصاد العالمي ). وهذا لن يكون خطأ.
ثانيًا ، من الناحية العملية ، يتم وضع قيم قواعد التقييم بخبرة ، أي ذاتيًا. ومن الأمثلة اللافتة على ذلك مواضيع تبدو مختلفة مثل
الهندسة الميكانيكية والزراعة والغابات . صنفت خوارزميتنا المقالات بعنوان
"آلات ترقق الغابة" و
"المتطلبات الأساسية لتطوير سلسلة قياسية من الجرارات لظروف المنطقة الشمالية الغربية" إلى الهندسة الميكانيكية ، ووفقًا للتخطيط الأصلي ، أشاروا بدقة إلى الزراعة.
لذلك ، قررنا عرض أهم 3 قيم محتملة لكل فئة من الفئات. على سبيل المثال ، بالنسبة لمقالة
"التسامح المهني للمعلم (على سبيل المثال نشاط المعلم الروسي في مدرسة متعددة الأعراق)" ، تم توزيع احتمالات قيم عنوان اللجنة العليا للتصديق على النحو التالي:
| قيمة المحسن | الاحتمال |
|---|
| علوم تربوية | 47٪ |
| علوم نفسية | 33٪ |
| العلوم الثقافية | 20٪ |
كانت دقة الخوارزميات الناتجة:
| منظم | أعلى 3 دقة |
|---|
| SRSTI | 93٪ |
| VAK | 92٪ |
| UDC | 94٪ |
توضح الرسوم البيانية نتائج دراسة حول توزيع مواضيع المستندات في فهرس الإنترنت باللغة الروسية للجميع (الشكل 3) والوثائق العلمية (الشكل 4) فقط. يمكن ملاحظة أن معظم الوثائق تتعلق بالعلوم الإنسانية: المواصفات الأكثر شيوعًا هي الاقتصاد والقانون والتربية. علاوة على ذلك ، من بين الوثائق العلمية فقط ، فإن حصتها أكبر.
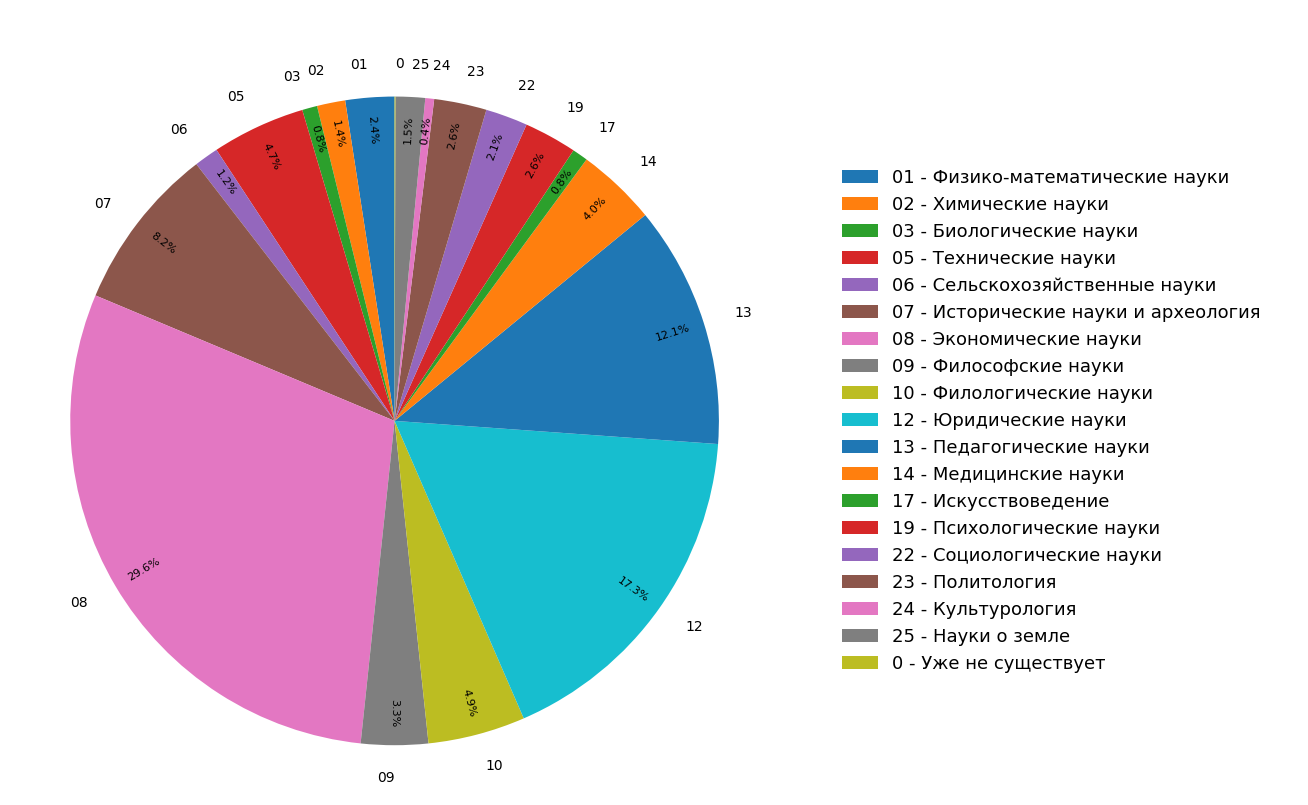 التين. 3. توزيع المواضيع في كل وحدة البحث
التين. 3. توزيع المواضيع في كل وحدة البحث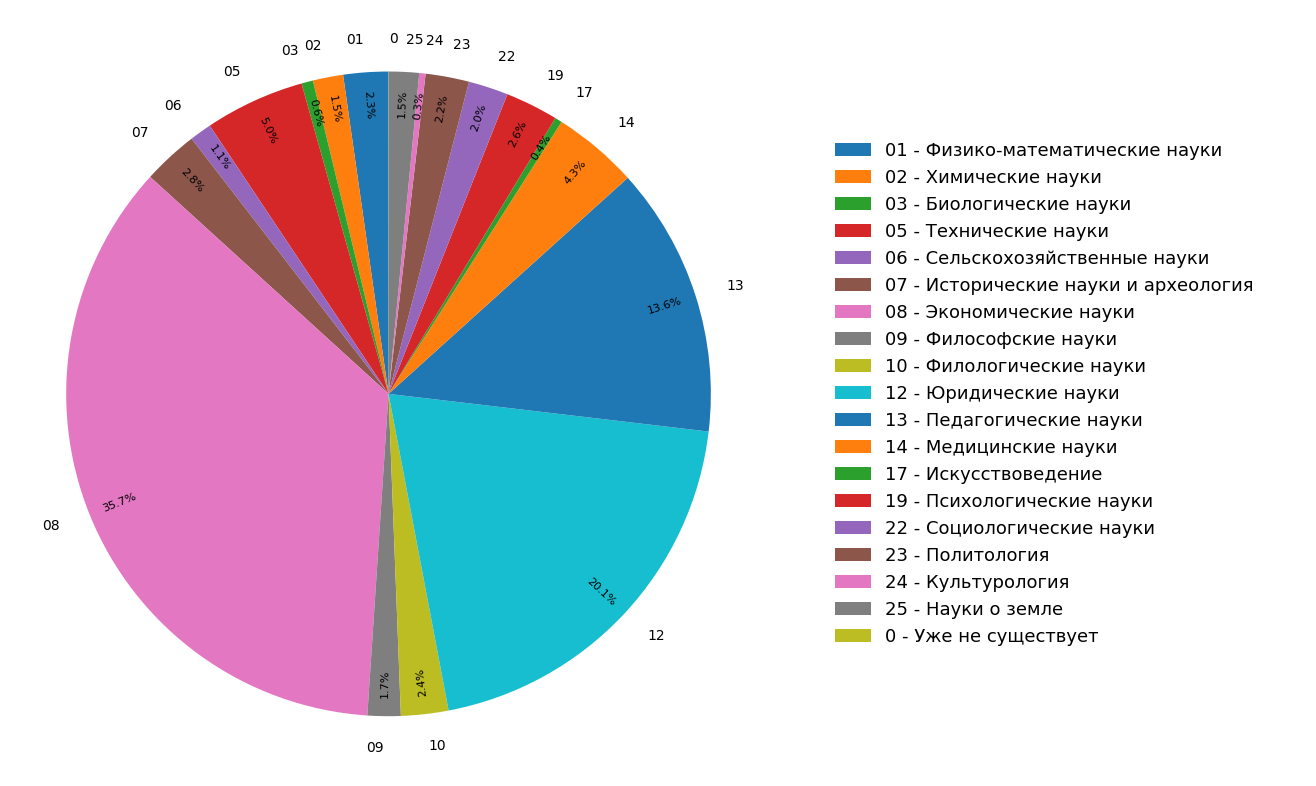 التين. 4. توزيع مواضيع الوثائق العلمية.
التين. 4. توزيع مواضيع الوثائق العلمية.ونتيجة لذلك ، فقد تعلمنا حرفياً من المواد المتوفرة ليس فقط البنية المواضيعية للإنترنت المفهرس ، ولكن أيضًا جعلنا وظائف إضافية يمكنك من خلالها "تصنيف" مقال أو مستند علمي آخر إلى ثلاث فئات مواضيعية في آن واحد.

يتم الآن تنفيذ الوظائف الموضحة أعلاه بنشاط في نظام مكافحة الانتحال ، وستتوفر قريبًا للمستخدمين.