كل منا يقوم بعمل روتيني. الجميع يكتب رمز boilerplate. لماذا؟ أليس من الأفضل أتمتة هذه العملية والعمل فقط على المهام المثيرة للاهتمام؟ اقرأ هذه المقالة إذا كنت تريد أن يقوم الكمبيوتر بهذا العمل نيابة عنك.
 تستند هذه المقالة إلى نص من تقرير أعده Zack Sweers ، مطور تطبيقات الهاتف المحمول في Uber ، والذي تحدث في MBLT DEV في عام 2017.
تستند هذه المقالة إلى نص من تقرير أعده Zack Sweers ، مطور تطبيقات الهاتف المحمول في Uber ، والذي تحدث في MBLT DEV في عام 2017.
لدى أوبر حوالي 300 مطور تطبيقات للهواتف المحمولة. أعمل في فريق يسمى "النظام الأساسي للجوّال". عمل فريقي هو تبسيط وتحسين عملية تطوير تطبيقات الهاتف المحمول قدر الإمكان. نحن نعمل بشكل رئيسي على الأطر الداخلية والمكتبات والهندسة المعمارية وما إلى ذلك. نظرًا للعدد الكبير من الموظفين ، يتعين علينا القيام بمشاريع كبيرة سيحتاجها مهندسونا في المستقبل. قد يكون غدًا ، أو ربما الشهر المقبل أو حتى عام.
إنشاء رمز لأتمتة
أود أن أوضح قيمة عملية إنشاء التعليمات البرمجية ، وكذلك النظر في بعض الأمثلة العملية. تبدو العملية نفسها شيء من هذا القبيل:
FileSpec.builder("", "Presentation") .addComment("Code generating your way to happiness.") .addAnnotation(AnnotationSpec.builder(Author::class) .addMember("name", "%S", "Zac Sweers") .useSiteTarget(FILE) .build()) .build()
هذا مثال على استخدام Kotlin Poet. Kotlin Poet هي مكتبة ذات واجهة برمجة تطبيقات جيدة تولد كود Kotlin. فماذا نرى هنا؟
- يقوم FileSpec.builder بإنشاء ملف يسمى " العرض التقديمي ".
- .addComment () - إضافة تعليق إلى التعليمات البرمجية التي تم إنشاؤها.
- .addAnnotation () - إضافة تعليق توضيحي من نوع المؤلف .
- .addMember () - يضيف متغير " name " بمعامل ، في حالتنا هو " Zac Sweers ". ٪ S - نوع المعلمة.
- .useSiteTarget () - تثبيت SiteTarget.
- .build () - يكمل وصف الكود الذي سيتم إنشاؤه.
بعد إنشاء الكود ، يتم الحصول على ما يلي:
Presentation.kt // Code generating your way to happiness. @file:Author(name = "Zac Sweers")
نتيجة إنشاء الشفرة هي ملف باسم المؤلف وتعليقه وشرحه واسمه. يطرح السؤال على الفور: "لماذا أحتاج إلى إنشاء هذا الرمز إذا كان بإمكاني القيام بذلك في بضع خطوات بسيطة؟" نعم ، أنت على حق ، ولكن ماذا لو كنت بحاجة إلى آلاف هذه الملفات بخيارات تكوين مختلفة؟ ماذا يحدث إذا بدأنا في تغيير القيم في هذا الرمز؟ ماذا لو كان لدينا العديد من العروض التقديمية؟ ماذا لو كان لدينا الكثير من المؤتمرات؟
conferences .flatMap { it.presentations } .onEach { (presentationName, comment, author) -> FileSpec.builder("", presentationName) .addComment(comment) .addAnnotation(AnnotationSpec.builder(Author::class) .addMember("name", "%S", author) .useSiteTarget(FILE) .build()) .build() }
نتيجة لذلك ، سوف نصل إلى استنتاج مفاده أنه من المستحيل ببساطة الاحتفاظ بهذا العدد من الملفات يدويًا - من الضروري أتمتة. لذلك ، فإن الميزة الأولى لتوليد الكود هي التخلص من العمل الروتيني.
توليد كود خالي من الأخطاء
الميزة المهمة الثانية للأتمتة هي التشغيل الخالي من الأخطاء. كل الناس يخطئون. يحدث هذا غالبًا خاصة عندما نفعل نفس الشيء. أجهزة الكمبيوتر ، على العكس من ذلك ، تؤدي مثل هذا العمل بشكل مثالي.
فكر في مثال بسيط. يوجد فئة الشخص:
class Person(val firstName: String, val lastName: String)
لنفترض أننا نريد إضافة تسلسل إليها في JSON. سنفعل ذلك باستخدام مكتبة
موشي ، لأنها بسيطة جدًا ورائعة في العرض. أنشئ PersonJsonAdapter وارث من JsonAdapter بمعلمة من النوع Person:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { }
بعد ذلك ، ننفذ طريقة fromJson. يوفر قارئًا لقراءة المعلومات التي سيتم إرجاعها في النهاية إلى الشخص. ثم نملأ الحقول بالاسم الأول والأخير ونحصل على القيمة الجديدة للشخص:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { override fun fromJson(reader: JsonReader): Person? { lateinit var firstName: String lateinit var lastName: String return Person(firstName, lastName) } }
بعد ذلك ، ننظر إلى البيانات بتنسيق JSON ، ونتحقق منها وأدخلها في الحقول الضرورية:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { override fun fromJson(reader: JsonReader): Person? { lateinit var firstName: String lateinit var lastName: String while (reader.hasNext()) { when (reader.nextName()) { "firstName" -> firstName = reader.nextString() "lastName" -> lastName = reader.nextString() } } return Person(firstName, lastName) } }
هل سينجح هذا؟ نعم ، ولكن هناك فارق بسيط: يجب أن تكون العناصر التي نقرأها داخل JSON. لتصفية البيانات الزائدة التي قد تأتي من الخادم ، أضف سطرًا آخر من التعليمات البرمجية:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { override fun fromJson(reader: JsonReader): Person? { lateinit var firstName: String lateinit var lastName: String while (reader.hasNext()) { when (reader.nextName()) { "firstName" -> firstName = reader.nextString() "lastName" -> lastName = reader.nextString() else -> reader.skipValue() } } return Person(firstName, lastName) } }
في هذه المرحلة ، نجحنا في التحايل على منطقة التعليمات البرمجية الروتينية. في هذا المثال ، حقلين فقط من القيم. ومع ذلك ، يحتوي هذا الرمز على مجموعة من الأقسام المختلفة حيث قد تتعطل فجأة. فجأة ارتكبنا خطأ في الكود؟
تأمل مثالاً آخر:
class Person(val firstName: String, val lastName: String) class City(val name: String, val country: String) class Vehicle(val licensePlate: String) class Restaurant(val type: String, val address: Address) class Payment(val cardNumber: String, val type: String) class TipAmount(val value: Double) class Rating(val numStars: Int) class Correctness(val confidence: Double)
إذا كان لديك مشكلة واحدة على الأقل كل 10 نماذج أو نحو ذلك ، فهذا يعني أنك بالتأكيد ستواجه صعوبات في هذا المجال. وهذا هو الحال عندما يمكن أن يأتي توليد التعليمات البرمجية بالفعل لمساعدتك. إذا كان هناك الكثير من الفصول الدراسية ، فلن تتمكن من العمل بدون أتمتة ، لأن جميع الأشخاص يسمحون بالأخطاء الإملائية. بمساعدة إنشاء التعليمات البرمجية ، سيتم تنفيذ جميع المهام تلقائيًا وبدون أخطاء.
هناك فوائد أخرى لإنشاء التعليمات البرمجية. على سبيل المثال ، يقدم معلومات حول الرمز أو يخبرك إذا حدث خطأ ما. سيكون إنشاء التعليمات البرمجية مفيدًا خلال مرحلة الاختبار. إذا كنت تستخدم الرمز الذي تم إنشاؤه ، يمكنك أن ترى كيف سيبدو رمز العمل حقًا. يمكنك أيضًا تشغيل إنشاء التعليمات البرمجية أثناء الاختبارات لتبسيط عملك.
الخلاصة: يجدر النظر في إنشاء التعليمات البرمجية كحل ممكن للتخلص من الأخطاء.
لنلقِ نظرة الآن على أدوات البرامج التي تساعد في إنشاء التعليمات البرمجية.
الأدوات
- مكتبات JavaPoet و KotlinPoet لـ Java و Kotlin ، على التوالي. هذه هي معايير توليد الكود.
- التزيين. مثال شائع على قوالب جافا هو Apache Velocity و iOS Handbars .
- SPI - واجهة معالج الخدمة. إنه مدمج في Java ويسمح لك بإنشاء وتطبيق واجهة ثم الإعلان عنها في JAR. عندما يتم تنفيذ البرنامج ، يمكنك الحصول على جميع التطبيقات الجاهزة للواجهة.
- اختبار الترجمة عبارة عن مكتبة من Google تساعد في اختبار الترجمة. من حيث إنشاء الشفرة ، هذا يعني: "هذا ما توقعته ، ولكن هذا ما حصلت عليه في النهاية." سيبدأ التجميع في الذاكرة ، ثم سيخبرك النظام ما إذا كانت هذه العملية قد اكتملت أم حدثت الأخطاء. إذا اكتمل التجميع ، سيُطلب منك مقارنة النتيجة بتوقعاتك. تستند المقارنة إلى التعليمات البرمجية المترجمة ، لذلك لا تقلق بشأن أشياء مثل تنسيق التعليمات البرمجية أو أي شيء آخر.
أدوات إنشاء التعليمات البرمجية
هناك أداتان رئيسيتان لرمز البناء:
- معالجة التعليقات التوضيحية - يمكنك كتابة التعليقات التوضيحية في الرمز وطلب البرنامج للحصول على معلومات إضافية عنها. سيقدم المترجم المعلومات حتى قبل أن ينتهي من العمل مع شفرة المصدر.
- Gradle هو نظام تجميع تطبيقات به العديد من الخطافات (الخطاف - اعتراض استدعاءات الوظائف) في دورة حياة تجميع الكود. يستخدم على نطاق واسع في تطوير Android. كما يسمح لك بتطبيق إنشاء التعليمات البرمجية على التعليمات البرمجية المصدر ، مستقلة عن المصدر الحالي.
الآن فكر في بعض الأمثلة.
سكين زبدة
Butter Knife هي مكتبة طورتها جيك وارتون. إنه شخصية معروفة في مجتمع المطورين. تحظى المكتبة بشعبية كبيرة بين مطوري Android لأنها تساعد على تجنب الكم الكبير من الأعمال الروتينية التي يواجهها الجميع تقريبًا.
عادة نقوم بتهيئة العرض بهذه الطريقة:
TextView title; ImageView icon; void onCreate(Bundle savedInstanceState) { title = findViewById(R.id.title); icon = findViewById(R.id.icon); }
مع Butterknife ، ستبدو كما يلي:
@BindView(R.id.title) TextView title; @BindView(R.id.icon) ImageView icon; void onCreate(Bundle savedInstanceState) { ButterKnife.bind(this); }
ويمكننا بسهولة إضافة أي عدد من المشاهدات ، في حين أن طريقة onCreate لن تنمو رمز لوحة مرجعية:
@BindView(R.id.title) TextView title; @BindView(R.id.text) TextView text; @BindView(R.id.icon) ImageView icon; @BindView(R.id.button) Button button; @BindView(R.id.next) Button next; @BindView(R.id.back) Button back; @BindView(R.id.open) Button open; void onCreate(Bundle savedInstanceState) { ButterKnife.bind(this); }
بدلاً من القيام بهذا الربط يدويًا في كل مرة ، ما عليك سوى إضافة التعليقات التوضيحية لـindView إلى هذه الحقول ، بالإضافة إلى المعرفات (المعرفات) التي تم تعيينها لها.
الشيء الرائع في Butter Knife هو أنه سيحلل الشفرة ويولد جميع أقسامه المشابهة لك. كما أن لديها قابلية ممتازة للبيانات الجديدة. لذلك ، إذا ظهرت بيانات جديدة ، فلن تكون هناك حاجة لتطبيق onCreate مرة أخرى أو تتبع شيء يدويًا. هذه المكتبة رائعة أيضًا لحذف البيانات.
لذا ، كيف يبدو هذا النظام من الداخل؟ يتم البحث في العرض عن طريق التعرف على التعليمات البرمجية ، ويتم تنفيذ هذه العملية في مرحلة معالجة التعليقات التوضيحية.
لدينا هذا المجال:
@BindView(R.id.title) TextView title;
استنادًا إلى هذه البيانات ، يتم استخدامها في FooActivity معينة:
لها معناها الخاص (R.id.title) ، الذي يعمل كهدف. يرجى ملاحظة أنه أثناء معالجة البيانات ، يصبح هذا الكائن قيمة ثابتة داخل النظام:
هذا أمر طبيعي. هذا ما يجب على سكين الزبد الوصول إليه على أي حال. هناك مكون TextView كنوع. الحقل نفسه يسمى العنوان. على سبيل المثال ، إذا أنشأنا فئة حاوية من هذه البيانات ، نحصل على شيء مثل هذا:
ViewBinding( target = "FooActivity", id = 2131361859, name = "title", type = "field", viewType = TextView.class )
لذلك ، يمكن الحصول على جميع هذه البيانات بسهولة أثناء معالجتها. كما أنها تشبه إلى حد كبير ما تفعله سكين الزبدة داخل النظام.
ونتيجة لذلك ، يتم إنشاء هذه الفئة هنا:
public final class FooActivity_ViewBinding implements Unbinder { private FooActivity target; @UiThread public FooActivity_ViewBinding(FooActivity target, View source) { this.target = target; target.title = Utils.findRequiredViewAsType(source, 2131361859,
هنا نرى أن كل هذه البيانات يتم جمعها معًا. نتيجة لذلك ، لدينا فئة الهدف ViewBinding من مكتبة جافا Underscore. في الداخل ، يتم ترتيب هذا النظام بطريقة في كل مرة تقوم فيها بإنشاء مثيل من الفصل الدراسي ، فإنه يقوم على الفور بكل هذا الربط بالمعلومات (الرمز) التي أنشأتها. وكل هذا تم إنشاؤه مسبقًا بشكل ثابت أثناء معالجة التعليقات التوضيحية ، مما يعني أنها صحيحة تقنيًا.
دعنا نعود إلى خط أنابيب برنامجنا:
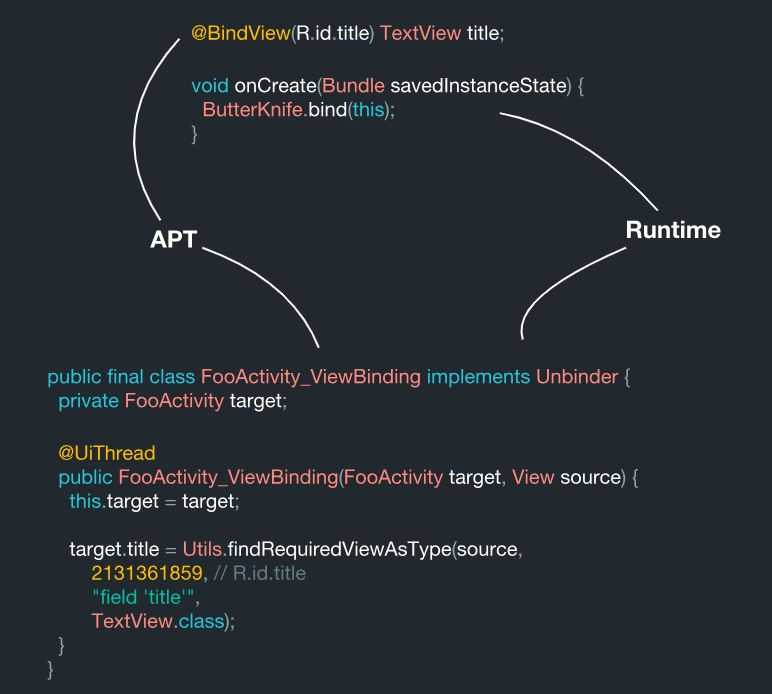
أثناء معالجة التعليقات التوضيحية ، يقوم النظام بقراءة هذه التعليقات التوضيحية وإنشاء فئة ViewBinding. وبعد ذلك أثناء إجراء الربط ، نقوم بإجراء بحث متطابق لنفس الفئة بطريقة بسيطة: نأخذ اسمه ونلحق ViewBinding في النهاية. بمفرده ، يتم استبدال قسم يحتوي على ViewBinding أثناء المعالجة في المنطقة المحددة باستخدام JavaPoet.
Rxbindings
RxBindings وحدها ليست مسؤولة عن إنشاء التعليمات البرمجية. لا يتعامل مع التعليقات التوضيحية وهو ليس ملحق Gradle. هذه مكتبة عادية. يوفر مصانع ثابتة تستند إلى مبدأ البرمجة التفاعلية لـ Android API. هذا يعني أنه ، على سبيل المثال ، إذا قمت بتعيين setOnClickListener ، فستظهر طريقة النقر التي ستعرض دفقًا من الأحداث (الملحوظة). يعمل كجسر (نمط تصميم).
ولكن في الواقع هناك توليد التعليمات البرمجية في RxBinding:
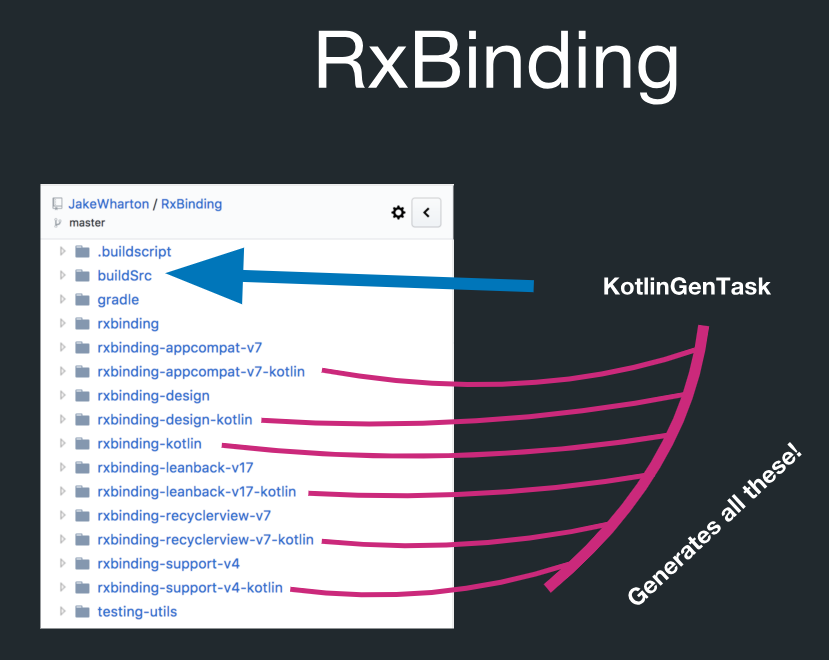
في هذا الدليل المسمى buildSrc توجد مهمة Gradle تسمى KotlinGenTask. هذا يعني أن كل هذا تم إنشاؤه بالفعل من خلال إنشاء التعليمات البرمجية. لدى RxBinding تطبيقات Java. لديها أيضا التحف Kotlin التي تحتوي على وظائف التمديد لجميع أنواع الهدف. وكل هذا يخضع لقواعد صارمة للغاية. على سبيل المثال ، يمكنك إنشاء جميع وظائف ملحق Kotlin ، ولا يتعين عليك التحكم فيها بشكل فردي.
كيف يبدو حقا؟
public static Observable<Object> clicks(View view) { return new ViewClickObservable(view); }
هنا طريقة RxBinding كلاسيكية تمامًا. يتم إرجاع الأشياء التي يمكن ملاحظتها هنا. تسمى الطريقة النقرات. يتم التعامل مع أحداث النقرات "تحت الغطاء". نحن نحذف أجزاء التعليمات البرمجية الإضافية للحفاظ على سهولة قراءة المثال. في Kotlin ، يبدو مثل هذا:
fun View.clicks(): Observable<Object> = RxView.clicks(this)
تقوم وظيفة الامتداد هذه بإرجاع كائنات يمكن ملاحظتها. في الهيكل الداخلي للبرنامج ، فإنه يستدعي مباشرة واجهة Java المعتادة بالنسبة لنا. في Kotlin ، يجب عليك تغيير هذا إلى نوع الوحدة:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
هذا ، في Java ، يبدو كما يلي:
public static Observable<Object> clicks(View view) { return new ViewClickObservable(view); }
وكذلك رمز Kotlin:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
لدينا فئة RxView تحتوي على هذه الطريقة. يمكننا استبدال أجزاء البيانات المقابلة في السمة الهدف ، في سمة الاسم باسم الطريقة وفي النوع الذي نقوم بتوسيعه ، وكذلك في نوع القيمة المرتجعة. كل هذه المعلومات ستكون كافية لبدء كتابة هذه الأساليب:
BindingMethod( target = "RxView", name = "clicks", type = View.class, returnType = "Observable<Unit>" )
الآن يمكننا استبدال هذه الأجزاء مباشرة في كود Kotlin الذي تم إنشاؤه داخل البرنامج. ها هي النتيجة:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
الجنرال الخدمة
نحن نعمل على Service Gen في Uber. إذا كنت تعمل في شركة وتتعامل مع الخصائص العامة وواجهة برمجية مشتركة لكل من الواجهة الخلفية وجانب العميل ، فبغض النظر عما إذا كنت تقوم بتطوير تطبيقات Android أو iOS أو تطبيقات الويب ، فمن غير المنطقي إنشاء نماذج وخدمات يدويًا للعمل الجماعي.
نستخدم مكتبة
AutoValue من Google
لنماذج الكائنات. يعالج التعليقات التوضيحية ، ويحلل البيانات ويولد رمز تجزئة من سطرين ، وطريقة يساوي () والتطبيقات الأخرى. كما أنها مسؤولة عن دعم التمديدات.
لدينا كائن من نوع رايدر:
@AutoValue abstract class Rider { abstract String uuid(); abstract String firstName(); abstract String lastName(); abstract Address address(); }
لدينا خطوط برقم التعريف واسم العائلة واسم العائلة والعنوان. للعمل مع الشبكة ، نستخدم مكتبات Retrofit و OkHttp و JSON كتنسيق البيانات. نستخدم أيضًا RxJava للبرمجة التفاعلية. هكذا تبدو خدمة API التي تم إنشاؤها:
interface UberService { @GET("/rider") Rider getRider() }
يمكننا كتابة كل هذا يدويًا ، إذا رغبنا في ذلك. ولفترة طويلة ، فعلنا. لكن الأمر يستغرق الكثير من الوقت. في النهاية ، يكلف الكثير من حيث الوقت والمال.
ماذا وكيف تفعل أوبر اليوم
المهمة الأخيرة لفريقي هي إنشاء محرر نص من الصفر. قررنا عدم كتابة الشفرة يدويًا التي تصل بعد ذلك إلى الشبكة ، لذلك نستخدم
Thrift . إنه شيء يشبه لغة البرمجة والبروتوكول في نفس الوقت. تستخدم Uber Thrift كلغة للمواصفات الفنية.
struct Rider { 1: required string uuid; 2: required string firstName; 3: required string lastName; 4: optional Address address; }
في Thrift ، نحدد عقود API بين الواجهة الخلفية وجانب العميل ، ثم نقوم ببساطة بإنشاء الشفرة المناسبة. نستخدم مكتبة
Thrifty لتحليل البيانات و JavaPoet لإنشاء التعليمات البرمجية. في النهاية ، نقوم بإنشاء عمليات التنفيذ باستخدام AutoValue:
@AutoValue abstract class Rider { abstract String uuid(); abstract String firstName(); abstract String lastName(); abstract Address address(); }
نقوم بكل العمل في JSON. هناك امتداد يسمى
AutoValue Moshi ، والذي يمكن إضافته إلى فئات AutoValue باستخدام طريقة jsonAdapter الثابتة:
@AutoValue abstract class Rider { abstract String uuid(); abstract String firstName(); abstract String lastName(); abstract Address address(); static JsonAdapter<Rider> jsonAdapter(Moshi moshi) { return new AutoValue_Rider.JsonAdapter(moshi); } }
يساعد التوفير أيضًا في تطوير الخدمات:
service UberService { Rider getRider() }
علينا أيضًا إضافة بعض البيانات الوصفية هنا لإعلامنا بالنتيجة النهائية التي نريد تحقيقها:
service UberService { Rider getRider() (path="/rider") }
بعد إنشاء الكود ، سوف نتلقى خدمتنا:
interface UberService { @GET("/rider") Single<Rider> getRider(); }
لكن هذه ليست سوى واحدة من النتائج المحتملة. نموذج واحد. كما نعلم من التجربة ، لم يستخدم أحد نموذجًا واحدًا على الإطلاق. لدينا العديد من النماذج التي تولد رمزًا لخدماتنا:
struct Rider struct City struct Vehicle struct Restaurant struct Payment struct TipAmount struct Rating
في الوقت الحالي لدينا حوالي 5-6 تطبيقات. ولديهم العديد من الخدمات. وكل شخص يمر بنفس خط أنابيب البرامج. كتابة كل هذا باليد سيكون جنونيا.
في التسلسل في JSON ، لا يحتاج "المحول" إلى التسجيل في Moshi ، وإذا كنت تستخدم JSON ، فلن تحتاج إلى التسجيل في JSON. من المشكوك فيه أيضًا اقتراح موظفين لتنفيذ عملية إزالة التسلسل من خلال إعادة كتابة التعليمات البرمجية من خلال رسم بياني DI.
لكننا نعمل مع Java ، حتى نتمكن من استخدام نمط Factory ، الذي
ننشئه من خلال مكتبة
Fractory . يمكننا إنشاء هذا لأننا نعرف عن هذه الأنواع قبل حدوث التجميع. يولد Fractory محولًا مثل هذا:
class ModelsAdapterFactory implements JsonAdapter.Factory { @Override public JsonAdapter<?> create(Type type, Set<? extends Annotation> annotations, Moshi moshi) { Class<?> rawType = Types.getRawType(type); if (rawType.isAssignableFrom(Rider.class)) { return Rider.adapter(moshi); } else if (rawType.isAssignableFrom(City.class)) { return City.adapter(moshi); } else if (rawType.isAssignableFrom(Vehicle.class)) { return Vehicle.adapter(moshi); }
الكود الذي تم إنشاؤه لا يبدو جيدًا جدًا. إذا كان يضر العين ، يمكن إعادة كتابته يدويًا.
هنا يمكنك رؤية الأنواع المذكورة سابقًا مع أسماء الخدمات. سيحدد النظام تلقائيًا المحولات التي سيتم تحديدها والاتصال بها. ولكن هنا نواجه مشكلة أخرى. لدينا 6000 من هذه المحولات. حتى إذا قمت بتقسيمها فيما بينها داخل نفس القالب ، فإن نموذج "Eats" أو "Driver" سيقع في نموذج "Rider" أو سيكون في تطبيقه. سيمتد الرمز. بعد نقطة معينة ، لا يمكن احتواؤها حتى في ملف .dex. لذلك ، تحتاج إلى فصل المحولات بطريقة أو بأخرى:

في النهاية ، سنقوم بتحليل الكود مقدمًا وإنشاء مشروع فرعي صالح له ، كما هو الحال في Gradle:

في الهيكل الداخلي ، تصبح هذه التبعيات تبعيات Gradle. تعتمد العناصر التي تستخدم تطبيق Rider الآن عليه. مع ذلك ، سيشكلون النماذج التي يحتاجونها. ونتيجة لذلك ، سيتم حل مهمتنا ، وسيتم تنظيم كل ذلك من خلال نظام تجميع التعليمات البرمجية داخل البرنامج.
لكننا هنا نواجه مشكلة أخرى: الآن لدينا عدد من نماذج المصانع. يتم تجميعها جميعًا في كائنات مختلفة:
class RiderModelFactory class GiftCardModelFactory class PricingModelFactory class DriverModelFactory class EATSModelFactory class PaymentsModelFactory
في عملية معالجة التعليقات التوضيحية ، لن يكون من الممكن قراءة التعليقات التوضيحية فقط على التبعيات الخارجية وإجراء إنشاء تعليمات برمجية إضافية عليها فقط.
الحل: لدينا بعض الدعم في مكتبة Fractory ، مما يساعدنا بطريقة صعبة. يتم تضمينه في عملية ربط البيانات. نقدم البيانات الوصفية باستخدام معلمة classpath في أرشيف Java لتخزينها الإضافي:
class RiderModelFactory // -> json // -> ridermodelfactory-fractory.bin class MyAppGlobalFactory // Delegates to all discovered fractories
الآن ، في كل مرة تحتاج إلى استخدامها في التطبيق ، نذهب إلى مرشح دليل classpath مع هذه الملفات ، ثم نستخرجها من هناك بتنسيق JSON لمعرفة أي من التبعيات المتاحة.
كيف يناسب كل ذلك معا
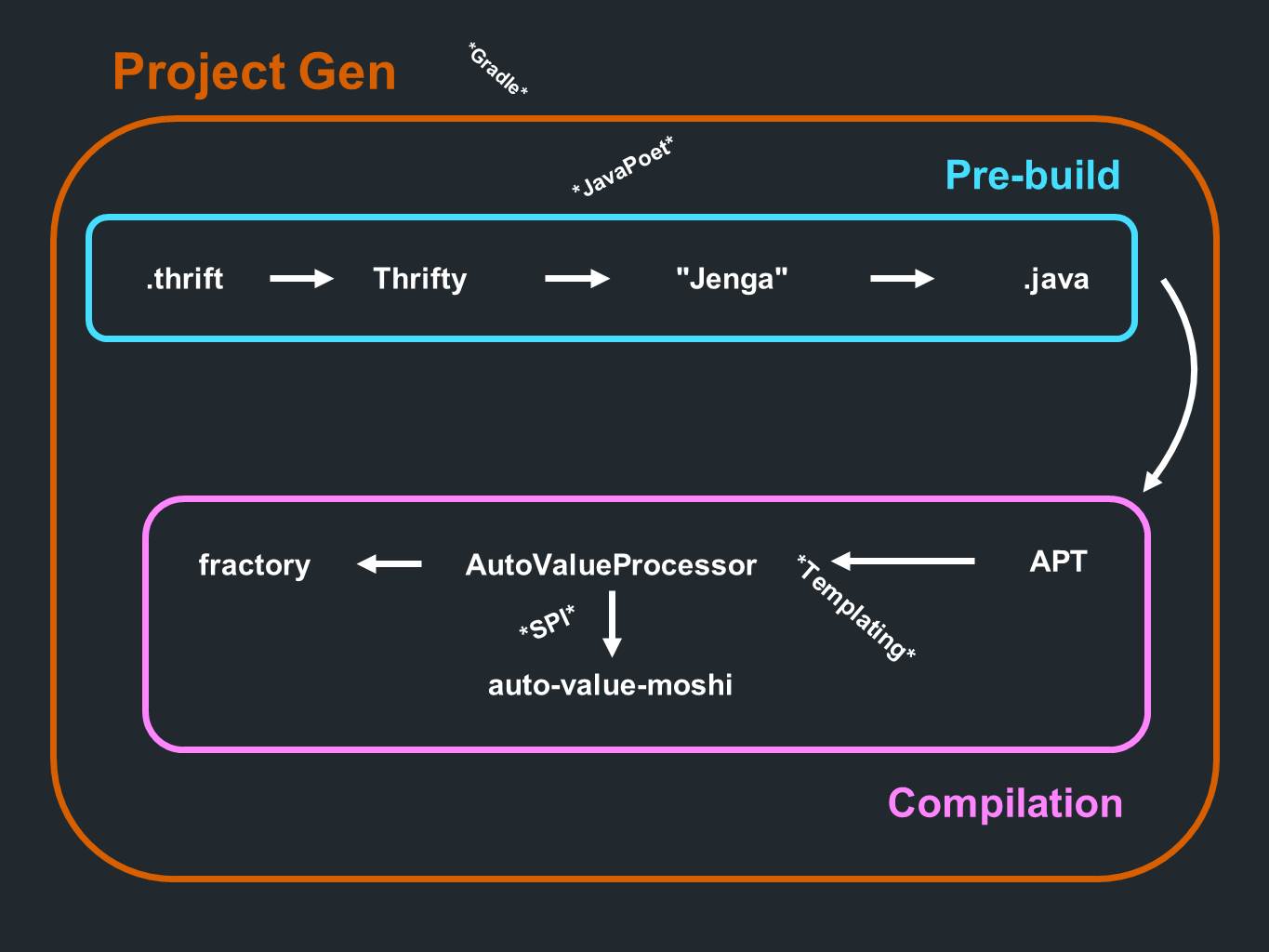
لدينا
ادخار . البيانات من هناك تذهب إلى
ثريفتي وتمر من خلال التحليل. ثم يذهبون من خلال برنامج توليد الكود الذي نسميه
Jenga . ينتج ملفات بتنسيق Java. كل هذا يحدث حتى قبل المرحلة الأولية من المعالجة أو قبل التجميع. وأثناء عملية الترجمة ، تتم معالجة التعليقات التوضيحية. حان
دور AutoValue لإنشاء تطبيق. كما أنها تدعو
AutoValue Moshi لتقديم دعم JSON.
تشارك كسرى أيضا. كل شيء يحدث أثناء عملية التجميع. يسبق العملية مكون لإنشاء المشروع نفسه ، والذي يولد في المقام الأول مشاريع
Gradle الفرعية.
الآن بعد أن رأيت الصورة الكاملة ، ستبدأ في ملاحظة الأدوات التي تم ذكرها سابقًا. لذلك ، على سبيل المثال ، هناك Gradle ، يقوم بإنشاء قوالب ، AutoValue ، JavaPoet لإنشاء التعليمات البرمجية. جميع الأدوات ليست مفيدة فقط من تلقاء نفسها ، ولكن أيضًا بالاشتراك مع بعضها البعض.سلبيات إنشاء التعليمات البرمجية
من الضروري أن نتحدث عن المزالق. أوضح ناقص هو تضخيم الرمز وفقد السيطرة عليه. على سبيل المثال ، تأخذ Dagger حوالي 10٪ من جميع التعليمات البرمجية في التطبيق. تحتل النماذج حصة أكبر بكثير - حوالي 25٪.في Uber ، نحاول حل المشكلة عن طريق التخلص من التعليمات البرمجية غير الضرورية. يجب علينا إجراء بعض التحليل الإحصائي للكود وفهم المجالات التي تشارك بالفعل في العمل. عندما نكتشف ، يمكننا إجراء بعض التحولات ومعرفة ما يحدث.نتوقع تقليل عدد النماذج المولدة بنحو 40٪. سيساعد ذلك على تسريع عملية تثبيت التطبيقات وتشغيلها ، فضلاً عن توفير المال.كيف يؤثر إنشاء الشفرة على الجداول الزمنية لتطوير المشروع
يعمل إنشاء الشفرة ، بالطبع ، على تسريع عملية التطوير ، لكن التوقيت يعتمد على الأدوات التي يستخدمها الفريق. على سبيل المثال ، إذا كنت تعمل في Gradle ، فأنت على الأرجح تفعل ذلك بوتيرة محسوبة. والحقيقة هي أن Gradle يولد نماذج مرة واحدة في اليوم ، وليس عندما يريد المطور ذلك.تعرف على المزيد حول التطوير في Uber والشركات الكبرى الأخرى.
في 28 سبتمبر ، يبدأ المؤتمر الدولي الخامس لمطوري الهواتف المحمولة MBLT DEV في موسكو . 800 مشارك ومكبر صوت ومسابقات وألغاز لأولئك المهتمين بتطوير Android و iOS. منظمو المؤتمر هم e-Legion و RAEC. يمكنك أن تصبح مشاركًا أو شريكًا في MBLT DEV 2018 على موقع المؤتمر .
تقرير الفيديو