
في الصيف الماضي ، انتهت
المنافسة في موقع kaggle ، الذي تم تخصيصه لتصنيف صور الأقمار الصناعية لغابات الأمازون. احتل فريقنا المركز السابع من بين أكثر من 900 مشارك. على الرغم من حقيقة أن المنافسة قد انتهت منذ وقت طويل ، إلا أن جميع أساليب حلنا لا تزال قابلة للتطبيق ، وليس فقط للمسابقات ، ولكن أيضًا لتدريب الشبكات العصبية للبيع. للحصول على تفاصيل تحت القط.
tldr.pyimport kaggle from ods import albu, alno, kostia, n01z3, nizhib, romul, ternaus from dataset import x_train, y_train, x_test oof_train, oof_test = [], [] for member in [albu, alno, kostia, n01z3, nizhib, romul, ternaus]: for model in member.models: model.fit_10folds(x_train, y_train, config=member.fit_config) oof_train.append(model.predict_oof_tta(x_train, config=member.tta_config)) oof_test.append(model.predict_oof_tta(x_test, config=member.tta_config)) for model in albu.second_level: model.fit(oof_train) y_test = model.predict_proba(oof_test) y_test = kostia.bayes_f2_opt(y_test) kaggle.submit(y_test)
وصف المهمة
أعد الكوكب مجموعة من صور الأقمار الصناعية في صيغتين:
- TIF - 16 بت RGB + N ، حيث N - بالقرب من Infra Red
- JPG - 8bit RGB ، المشتقة من TIF والتي تم توفيرها لتقليل الحد الأدنى لدخول المهمة ، وكذلك لتبسيط التصور. في المنافسة السابقة في Kaggle ، كان من الضروري العمل مع الصور متعددة الأطياف. غير المرئي ، أي بالأشعة تحت الحمراء ، بالإضافة إلى القنوات ذات الطول الموجي الأطول ، أدى إلى تحسين جودة التنبؤ بشكل كبير ، سواء في الشبكات أو الطرق غير الخاضعة للرقابة.
جغرافيا ، تم أخذ البيانات من أراضي حوض الأمازون ، ومن أراضي دول البرازيل ، وبيرو ، وأوروغواي ، وكولومبيا ، وفنزويلا ، وغيانا ، وبوليفيا ، والإكوادور ، حيث تم اختيار مناطق سطح مثيرة للاهتمام ، والتي تم تقديم الصور منها للمشاركين.
بعد إنشاء jpg من tif ، تم قطع جميع المشاهد إلى قطع صغيرة بحجم 256x256. ووفقًا لـ jpg التي تلقاها موظفو Planet من مكاتب برلين وسان فرانسيسكو ، وكذلك من خلال منصة Crowd Flower ، تم وضع العلامات.
تم تكليف المشاركين بالتنبؤ لكل علامة 256x256 بلاطة واحدة من علامات الطقس الحصرية المتبادلة:
غائم ، غائم جزئياً ، ضباب ، صافي
وأيضًا 0 أو أكثر من سوء الأحوال الجوية: الزراعة ، الابتدائية ، التسجيل الانتقائي ، السكن ، المياه ، الطرق ، زراعة التحول ، التفتح ، التعدين التقليدي
ما مجموعه 4 طقس و 13 غير الطقس ، الطقس حصريًا بشكل متبادل ، ولكن لا يوجد طقس ، ولكن إذا كانت الصورة غائمة ، فيجب ألا تكون هناك علامات أخرى.

تم تقدير دقة النموذج بواسطة مقياس F2:

علاوة على ذلك ، كان لجميع الملصقات نفس الوزن وتم حساب أول F2 لكل صورة ، ثم كان هناك متوسط عام. عادة ما يفعلون ذلك بشكل مختلف قليلاً ، أي أنه يتم حساب مقياس معين لكل فئة ، ثم يتم حسابه في المتوسط. المنطق هو أن الخيار الأخير أكثر قابلية للتفسير ، لأنه يسمح لك بالإجابة على السؤال حول كيفية تصرف النموذج في كل فئة معينة. في هذه الحالة ، ذهب المنظمون وفقًا للخيار الأول ، والذي ، على ما يبدو ، يتعلق بخصائص أعمالهم.
هناك 40 ألف عينة في القطار. في الاختبار 40 ك. نظرًا لصغر حجم مجموعة البيانات ، ولكن الحجم الكبير للصور ، يمكننا القول أن هذا "MNIST على المنشطات"
الاستطراد الغنائيكما ترى من الوصف ، فإن المهمة مفهومة تمامًا والحل ليس بمعنى الصاروخ: أنت فقط بحاجة إلى ملف الشبكة. ومع الأخذ في الاعتبار تفاصيل cuggle ، يمكنك أيضًا تكديس مجموعة من النماذج في الأعلى. ومع ذلك ، للحصول على ميدالية ذهبية ، لا تحتاج فقط إلى تدريب مجموعة من النماذج بطريقة أو بأخرى. من الضروري أن يكون لدينا العديد من النماذج المتنوعة الأساسية ، والتي يظهر كل منها في حد ذاته نتيجة رائعة. وفوق هذه النماذج ، يمكنك إنهاء التراص وغيرها من الاختراقات.
| عضو | صافي | 1 محصول | Tta | فرق ، ٪ |
|---|
| ألنو | احمد علي محمد الجليمي 121 | 0.9278 | 0.9294 | 0.1736 |
| nizhib | 169 | 0.9243 | 0.9277 | 0.3733 |
| رومول | vgg16 | 0.9266 | 0.9267 | 0.0186 |
| ternaus | احمد علي محمد الجليمي 121 | 0.9232 | 0.9241 | 0.0921 |
| ألبو | احمد علي محمد الجليمي 121 | 0.9294 | 0.9312 | 0.1933 |
| كوستيا | resnet50 | 0.9262 | 0.9271 | 0.0907 |
| n01z3 | resnext50 | 0.9281 | 0.9298 | 0.1896 |
يوضح الجدول نماذج درجات F2 لجميع المشاركين لمحصول واحد و TTA. كما ترى ، الفرق صغير للاستخدام الحقيقي ، ولكنه مهم لوضع المنافسة.
تفاعل الفريقألكسندر
بوسلايف ألبوفي وقت المشاركة في المسابقة ، قاد اتجاه ml بالكامل في Geoscan. ولكن منذ ذلك الحين ، سحب مجموعة من المسابقات ، وأصبح آباء جميع المواد المستنفدة للأوزون في التقسيم الدلالي وغادر إلى مينسك ، التجديف في Mapbox ، التي تم
نشر المقال عنهاأليكسي نوسكوف
ألنومقاتلة مل العالمية. عملت في Evil Martians. انتقل الآن إلى ياندكس.
Konstantin Lopukhin
kostialopuhinعملت وتستمر في العمل في Scrapinghub. منذ ذلك الحين ، تمكن Kostya من الحصول على عدد قليل من الميداليات وبدون 5 دقائق Kaggle Grandmaster
آرثر كوزين
n01z3في وقت المشاركة في هذه المسابقة ، عملت في Avito. ولكن في العام الجديد تقريبًا ،
انتقل عالم البيانات القيادي الرائد
في Dbrain إلى سلسلة الكتل . آمل أن نسعد المجتمع قريبًا بمسابقاتنا مع عمال الرصيف وعلامات المصباح.
إيفجيني
نيزيبيتسكيLead Data Scientist في Rambler & Co. من هذه المسابقة ، اكتشف يوجين القدرة السرية على العثور على الوجوه في المسابقات المصورة. ما ساعده على سحب مسابقتين على منصة Topcoder. لقد
تحدثت عن واحد منهم.
رسلان
بايكولوف رومولشارك في تتبع الأحداث الرياضية في كونستانتا.
فلاديمير إيغوفيكوف
تيرناوسيمكن أن تتذكر
مقالًا مليئًا بالإثارة حول التحرش من قبل المخابرات البريطانية. كان يعمل في TrueAccord ، ولكن بعد ذلك انضم إلى الشباب Lyft العصري. أين تعمل رؤية الكمبيوتر للسيارة ذاتية القيادة. تواصل سحب المسابقات واستقبلت مؤخرا Kaggle Grandmaster.
يمكن أن يسمى جمعيتنا وشكل المشاركة نموذجي. كان قرار التوحد يرجع إلى حقيقة أننا جميعًا حققنا نتائج قريبة على لوحة الصدارة. وقد رأى كل منا خط الأنابيب المستقل الخاص بنا ، والذي كان حلاً مستقلاً تمامًا من البداية إلى النهاية. أيضا ، بعد الاندماج ، شارك العديد من المشاركين في التراص.
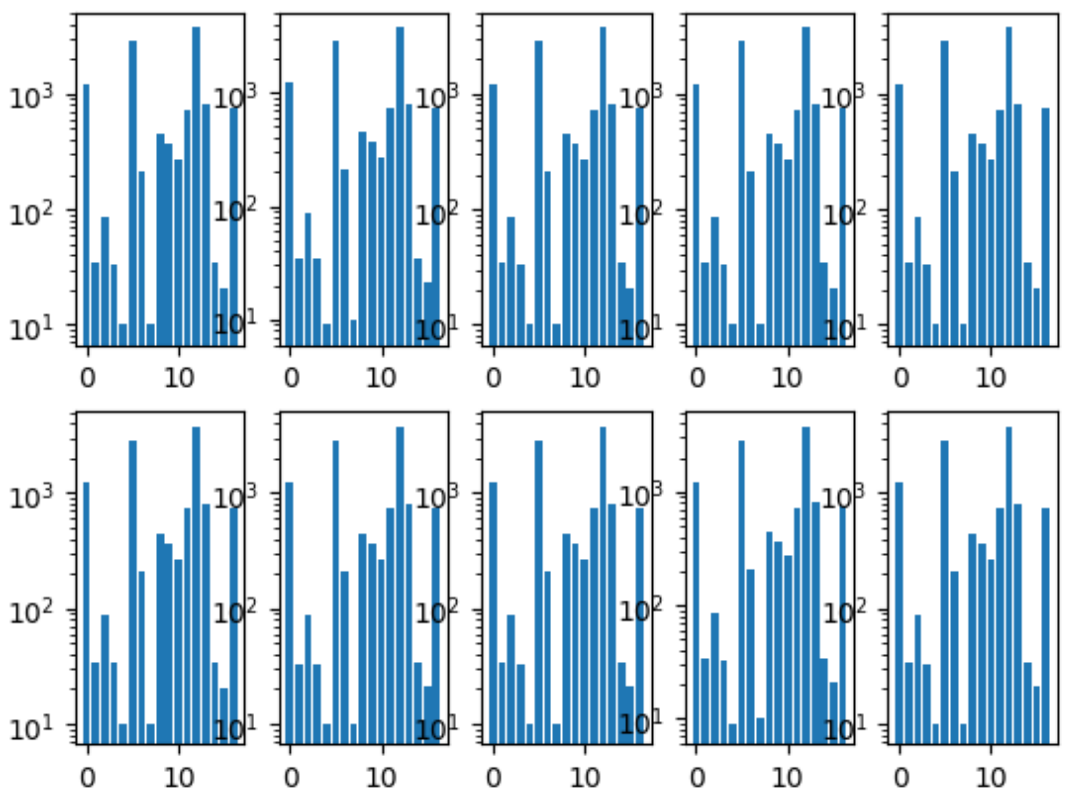
أول شيء فعلناه هو مشاركة الطيات. لقد تأكدنا من أن توزيع الطبقات في كل حظيرة هو نفسه كما في مجموعة البيانات بأكملها. لهذا ، تم اختيار أندر فئة ، طبقًا لها ، لأن الصور المتبقية طبقتها الطبقة الثانية الأكثر شعبية ، وهكذا حتى لم يتبق أي صور.
الرسم البياني لطبقات أضعاف:
كان لدينا أيضًا مستودع مشترك ، حيث كان لكل عضو في الفريق مجلده الخاص ، والذي قام من خلاله بتنظيم الرمز كما يريد.
واتفقنا أيضًا على شكل التوقعات ، لأن هذه كانت نقطة التفاعل الوحيدة للجمع بين نماذجنا.
تدريب الشبكات العصبيةنظرًا لأن كل واحد منا لديه خط أنابيب مستقل ، فقد كنا عينة شبكية من عملية التعلم المثلى بالتوازي مع الناس.
نهج عام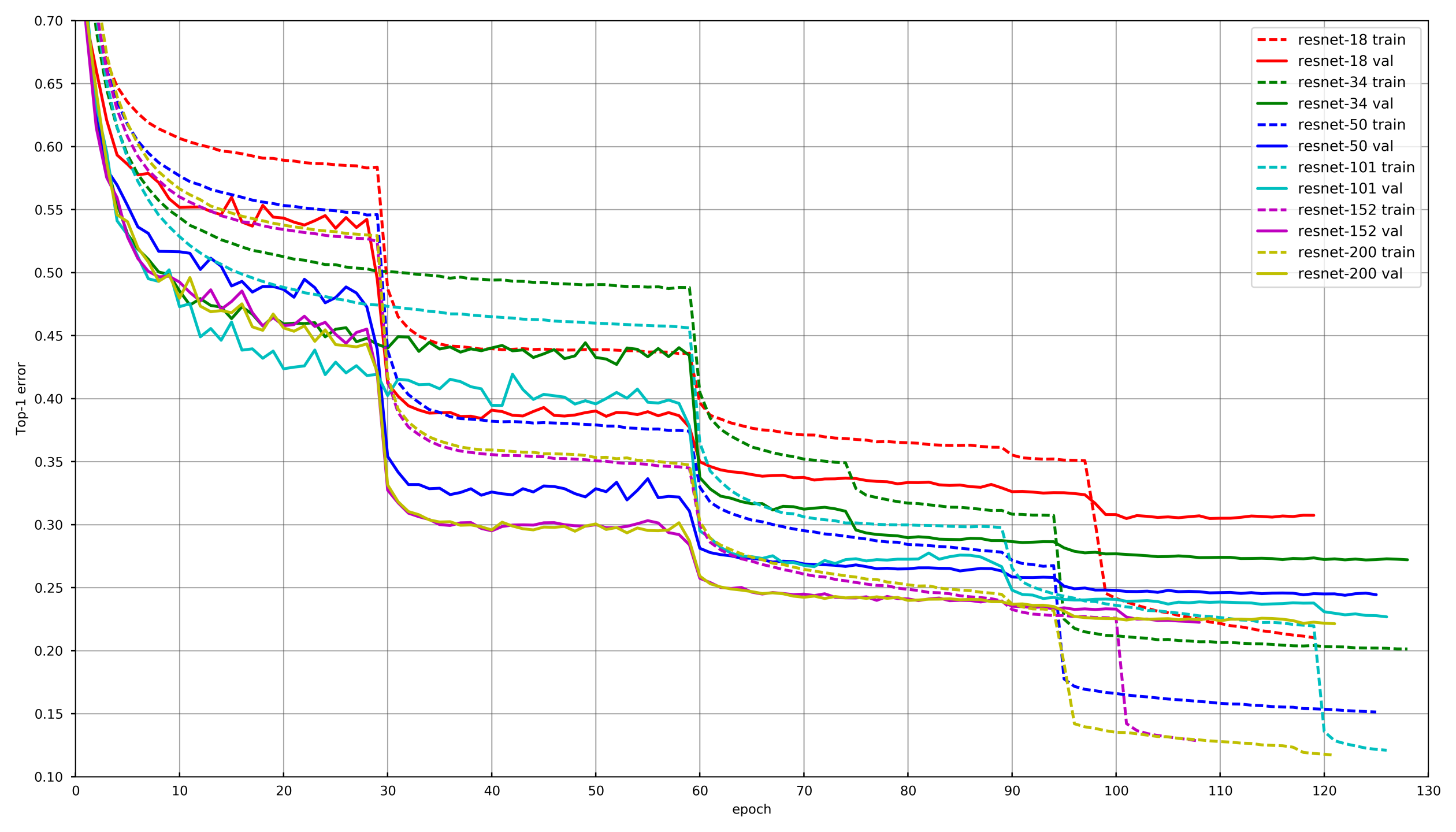
صورة من
github.com/tornadomeet/ResNetيتم تقديم عملية التعلم النموذجية في الجدول الزمني للتدريب من الشبكات العصبية Resnet على imagenet. يبدأون من الأوزان التي تم تهيئتها عشوائيًا باستخدام SGD (lr 0.1 Nesterov Momentum 0.0001 WD 0.9) ثم بعد 30 مسحًا أقل من معدل التعلم بمقدار 10 مرات.
من الناحية النظرية ، استخدم كل منا نفس النهج ، ومع ذلك ، من أجل عدم التقدم في العمر أثناء تدريب كل شبكة ، حدث انخفاض في LR إذا لم يسهم التحقق من الخسارة لمدة 3-5 عصور على التوالي. أو ، قام بعض المشاركين ببساطة بتقليل عدد العصور على كل ضرر LR وخفضها وفقًا للجدول الزمني.
تكبيراختيار التعزيزات الصحيحة مهم جدا عند تدريب الشبكات العصبية. يجب أن تعكس التعزيزات تنوع طبيعة البيانات. تقليديا ، يمكن تقسيم التعزيزات إلى نوعين: تلك التي تدخل التحيز في البيانات ، وتلك التي لا. من خلال التحيز ، يمكن للمرء فهم مختلف الإحصاءات ذات المستوى المنخفض ، مثل الرسوم البيانية الملونة أو الحجم المميز. في هذا الصدد ، دعنا نقول أن التعزيزات والمقاييس HSV تقدم تعويضًا ، ولكن المحصول العشوائي لا يفعل ذلك.
في المراحل الأولى من تدريب الشبكة ، يمكنك الذهاب إلى أبعد الحدود مع زيادة الحجم واستخدام مجموعة صعبة للغاية. ومع ذلك ، في نهاية التدريب ، يجب عليك إما إيقاف التعزيزات أو ترك فقط تلك التي لا تقدم تحيزًا. هذا يسمح للشبكة العصبية بتضخم قليلاً تحت القطار وإظهار نتيجة أفضل قليلاً عند التحقق من الصحة.
تجميد الطبقةفي الغالبية العظمى من المهام ، ليس من المنطقي تدريب شبكة عصبية من الصفر ، بل يكون أكثر كفاءة في العبث بالشبكات المدربة مسبقًا ، على سبيل المثال مع Imagenet. ومع ذلك ، يمكنك الذهاب إلى أبعد من ذلك وليس فقط تغيير الطبقة المتصلة بالكامل تحت الطبقة مع العدد المطلوب من الفئات ، ولكن أولاً قم بتدريبها على تجميد جميع الالتواءات. إذا لم تقم بتجميد الالتواءات وقمت على الفور بتدريب الشبكة بالكامل باستخدام أوزان مبدئية عشوائية للطبقة المتصلة بالكامل ، فسوف تتلف أوزان الالتواءات وسيكون الأداء النهائي للشبكة العصبية أقل. في هذه المهمة ، كان هذا ملحوظًا بشكل خاص نظرًا لصغر حجم عينة التدريب. في المسابقات الأخرى التي تحتوي على كمية كبيرة من البيانات مثل cdiscount ، لم يكن من الممكن تجميد الشبكة العصبية بأكملها ، ولكن مجموعات من الالتواءات من النهاية. بهذه الطريقة ، يمكن تسريع التدريب بشكل كبير ، حيث لم يتم النظر في التدرجات للطبقات المجمدة.
التلدين الدوريهذه العملية تبدو هكذا. بعد الانتهاء من عملية التدريب الأساسية للشبكة العصبية ، يتم أخذ أفضل الأوزان وتكرار عملية التدريب. لكنه يبدأ بمعدل تعلم أقل ويحدث في وقت قصير ، على سبيل المثال 3-5 عصور. هذا يسمح للشبكة العصبية بالهبوط إلى أدنى حد محلي محلي وإظهار أداء أفضل. تعمل هذه الحملة المستقرة على تحسين النتيجة في عدد كبير من المسابقات.
بمزيد من التفصيل حول اثنين من حفلات الاستقبال
هنازيادة وقت الاختبارنظرًا لأن هذه منافسة وليس لدينا قيود رسمية على وقت الاستدلال ، يمكنك استخدام التعزيزات أثناء الاختبار. يبدو أن الصورة مشوهة بنفس الطريقة التي حدثت أثناء التدريب. لنقل ، إنه ينعكس عموديًا ، أفقيًا ، يدور بزاوية ، إلخ. كل زيادة تعطي صورة جديدة نحصل منها على تنبؤات. ثم يتم حساب متوسط التوقعات لمثل هذه التشوهات لصورة واحدة (كقاعدة بوسائل هندسية). كما أنه يعطي ربحًا. في مسابقات أخرى ، جربت أيضًا زيادة عشوائية. لنفترض أنه لا يمكنك تطبيق واحد في كل مرة ، ولكن ببساطة قلل سعة اتساع المنعطفات والتباينات وزيادة الألوان بمقدار النصف ، وقم بإصلاح البذرة وصنع العديد من هذه الصور المشوهة عشوائيًا. هذا أعطى أيضا زيادة.
تجميع اللقطات (نقاط متعددة TTA)يمكن تطوير فكرة التلدين بشكل أكبر. في كل مرحلة من التلدين ، تطير الشبكة العصبية إلى حد أدنى محلي مختلف قليلاً. وهذا يعني أن هذه نماذج مختلفة اختلافًا طفيفًا يمكن حسابها في المتوسط. وهكذا ، أثناء تنبؤات الاختبار ، يمكنك أن تأخذ أفضل ثلاث نقاط تفتيش وتوقع متوسط توقعاتها. كما حاولت ألا أتناول أفضل ثلاث نقاط ، لكن النقاط الثلاث الأكثر تنوعًا من بين نقاط التفتيش العشرة الأولى - كان الوضع أسوأ. حسنًا ، لإنتاج مثل هذه الخدعة غير قابل للتطبيق وحاولت حساب متوسط وزن النماذج. أعطى هذا زيادة ضئيلة للغاية ولكن مطردة.
 نهج كل عضو في الفريق
نهج كل عضو في الفريقوبناءً على ذلك ، استخدم كل عضو من أعضاء فريقنا ، إلى درجة أو أخرى ، مجموعة مختلفة من التقنيات المذكورة أعلاه.
| نيك | تجميد التحويل ،
عهد | محسّن | إستراتيجية | أغسطس | Tta |
|---|
| ألبو | 3 | دولار سنغافوري | 15 عصر تسوس LR ،
الدائرة 13 عهود | د 4 ،
مقياس ،
تعويض
تشويه
التباين
طمس | د 4 |
|---|
| ألنو | 3 | دولار سنغافوري | تسوس Lr | د 4 ،
مقياس ،
تعويض
تشويه
التباين
طمس
القص
مضاعف القناة | د 4 |
|---|
| n01z3 | 2 | دولار سنغافوري | إسقاط LR ، مريض 10 | د 4 ،
مقياس ،
تشويه
التباين
طمس | D4 ، 3 نقاط تفتيش |
|---|
| ternaus | - | آدم | دوري LR (1e-3: 1e-6) | د 4 ،
مقياس ،
إضافة قناة
التباين | د 4 ،
محصول عشوائي |
|---|
| nizhib | - | آدم | StepLR ، 60 حقبة ، 20 لكل تسوس | د 4 ،
RandomSizedCrop | د 4 ،
4 زوايا ،
المركز
مقياس |
|---|
| كوستيا | 1 | آدم | | د 4 ،
مقياس ،
تشويه
التباين
طمس | د 4 |
|---|
| رومول | - | دولار سنغافوري | base_lr: 0.01 - 0.02
lr = base_lr * (0.33 ** (عصر / 30))
عصر: 50 | D4 ، مقياس | D4 ، محصول مركزي ،
المحاصيل الزاوية |
|---|
التراص والاختراققمنا بتدريب كل نموذج مع كل مجموعة من المعلمات على 10 أضعاف. وبعد ذلك ، قمنا بتدريس نماذج من المستوى الثاني: أشجار إضافية ، انحدار خطي ، شبكة عصبية ، وببساطة حساب متوسط النماذج.
وبالفعل في OOF ، التقطت توقعات نماذج المستوى الثاني أوزانًا للخلط. يمكنك قراءة المزيد حول التراص
هنا وهنا .
في الإنتاج الحقيقي ، ومن الغريب ، يحدث هذا النهج أيضًا. على سبيل المثال ، عندما تكون هناك بيانات متعددة الوسائط (صور ، نص ، فئات ، وما إلى ذلك) وتريد دمج تنبؤات النماذج. يمكنك ببساطة متوسط الاحتمالات ، لكن تدريب نموذج المستوى الثاني يعطي أفضل نتيجة.
Baes Optimization F2أيضًا ، تم ضبط التوقعات النهائية قليلاً باستخدام تحسين Bayesian. افترض أن لدينا احتمالات مثالية ، ثم يتم الحصول على F2 مع أفضل حصيرة توقع (أي من النوع الأمثل) بالصيغة التالية:
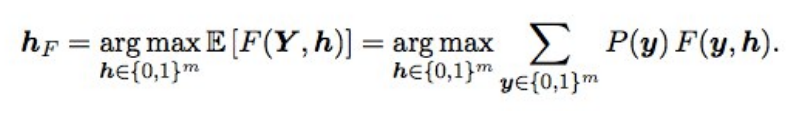
ماذا يعني هذا؟ نحن بحاجة إلى فرز جميع المجموعات (أي لكل تسمية 0 و 1) ، وحساب احتمال كل تركيبة ، والضرب في F2 - نحصل على F2 المتوقع. لأي تركيبة يكون أفضل ، وسيعطي F2 الأمثل. اعتبرت الاحتمالات ببساطة مضاعفة احتمالات التسميات الفردية (إذا كانت التسمية هي 0 ، فنحن نأخذ 1 - ص) ، وحتى لا يتم فرز 2 إلى 17 خيارًا ، كانت التصنيفات ذات الاحتمال من 0.05 إلى 0.5 متداخلة - كان هناك 3-7 منها على التوالي ، لذلك كانت الخيارات قليلاً (تم التقديم خلال دقيقتين). من الناحية النظرية ، سيكون من الرائع الحصول على احتمال مجموعة من التسميات ، ليس فقط مضاعفة الاحتمالات الفردية (لأن التسميات ليست مستقلة) ، ولكنها لم تنجح.
ماذا أعطى؟ عندما أصبحت النماذج جيدة ، توقف اختيار العتبات بعد المجموعة عن العمل ، وأعطى هذا الشيء زيادة صغيرة ولكنها مستقرة في كل من التحقق العام والخاص.
خاتمةونتيجة لذلك ، قمنا بتدريب 48 نموذجًا مختلفًا ، كل منها في 10 أضعاف ، أي 480 نماذج من المستوى الأول. سمحت لي مثل هذه الشبكة البشرية بتجربة تقنيات مختلفة عند تدريب الشبكات العصبية التلافيفية العميقة ، والتي ما زلت أستخدمها في العمل والمسابقات.
هل كان من الممكن تدريب عدد أقل من النماذج والحصول على نفس النتيجة أو نتيجة أفضل؟ نعم ، تمامًا. مواطنونا من المركز الثالث ، ستانيسلاف
stasg7 Semenov و Roman
ZFTurbo Soloviev ، يكلفون عددًا أصغر من نماذج المستوى الأول
ويقابلون أكثر من 250 طرازًا من المستوى الثاني. حول الحل ، يمكنك
رؤية التحليل
وقراءة المنشور.
ذهب المركز الأول إلى أفضل تركيب غامض. بشكل عام ، هذا الرجل رائع للغاية ، والآن أصبح تصنيف Keggle الأول ، بعد أن سحب الكثير من مسابقات الصورة. بقي مجهولاً لفترة طويلة ، حتى كسرت نفيديا الغطاء بمقابلته. اعترف فيه أن 200 من المرؤوسين سيخبرونه ... وهناك أيضًا
منشور حول القرار.
شيء آخر مثير للاهتمام: معروف على نطاق واسع في الدوائر الضيقة
جيريمي هوارد ، أنهى الأب
فاستاي 22 م. وإذا كنت تعتقد أنه أرسل تواً إرسالين لمشجعيه ، فلا يمكنك التخمين. شارك في الفريق وأرسل 111 طرداً.
أيضًا ، طلاب الدراسات العليا في ستانفورد الذين كانوا يتلقون الدورة الأسطورية CS231n في ذلك الوقت ، والذين سمح لهم باستخدام هذه المهمة كمشروع دورة ، أنهوا الفريق بأكمله في منتصف لوحة الصدارة.
كمكافأة ،
تحدثت في Mail.ru مع مادة هذا المنشور وهنا
عرض آخر
قدمه فلاديمير إيغلوفيكوف من اجتماع في الوادي.