كانت "البحث في سوق المحللين الشواغر" مهمة حقيقية للغاية لأحد المحللين الرائدين في شركة كبيرة أو صغيرة. قام المحلل بتوزيع العشرات من الأوصاف الوظيفية مع سمو يدويًا ، وتبعثرها وفقًا للمهارات المطلوبة وزاد العداد في عمود جدول البيانات المقابل.
رأيت في هذه المهمة مجالًا جيدًا للأتمتة وقررت محاولة التعامل معها بدم أقل ، بسهولة وبساطة.
كنت مهتمًا بالقضايا التالية التي أثيرت في هذه الدراسة:
- متوسط الراتب لمحللي الأعمال والنظم ،
- أكثر المهارات والصفات الشخصية المطلوبة في هذا المنصب ،
- التبعيات (إن وجدت) بين مهارات معينة ومستوى الراتب.
المفسد: لم يعمل بسهولة وببساطة.
إعداد البيانات
إذا أردنا جمع الكثير من البيانات حول الوظائف الشاغرة ، فمن المنطقي ألا تكون محدودة. ومع ذلك ، ل نقاء التجربة البساطة ، نبدأ بهذا المورد.
مجموعة
لجمع البيانات ، سنستخدم البحث عن وظيفة من خلال hh API.
سأبحث باستخدام الاستعلام النصي البسيط "محلل الأنظمة" و "محلل الأعمال" و "مالك المنتج" ، لأن الأنشطة ومجالات المسؤولية في هذه المناصب ، كقاعدة عامة ، تتداخل.
للقيام بذلك ، قم بإنشاء طلب من النموذج https://api.hh.ru/vacancies?text="systems+analyst" وقم بتحليل JSON المستلم.
لتحديد الوظائف الشاغرة الأكثر ملاءمة في العينة ، سنبحث فقط في رؤوس الوظائف الشاغرة عن طريق إضافة معلمة search_field=name إلى الاستعلام.
هنا يمكنك رؤية الحقول الشاغرة التي تم إرجاعها لهذا الطلب. اخترت ما يلي:
- المسمى الوظيفي
- المدينة
- تاريخ النشر
- راتب - الحد الأعلى والأدنى
- العملة التي يشار فيها إلى الراتب
- الإجمالي - T / F
- الشركة
- المسؤوليات
- متطلبات المرشح
بالإضافة إلى ذلك ، أريد إجراء مزيد من التحليل للمهارات الموضحة في قسم المهارات الأساسية ، ولكن هذا القسم متاح فقط في الوصف الوظيفي الكامل. لذلك ، سأحفظ أيضًا الروابط إلى الوظائف الشاغرة ، حتى أتمكن لاحقًا من الحصول على قائمة بالمهارات لكل منهم.
عرض الكود # :) library(jsonlite) library(curl) library(dplyr) library(ggplot2) library(RColorBrewer) library(plotly) hh.getjobs <- function(query, paid = FALSE) { # Makes a call to hh API and gets the list of vacancies based on the given search queries df <- data.frame( query = character() # , URL = character() # , id = numeric() # id , Name = character() # , City = character() , Published = character() , Currency = character() , From = numeric() # . , To = numeric() # . , Gross = character() , Company = character() , Responsibility = character() , Requerement = character() , stringsAsFactors = FALSE ) for (q in query) { for (pageNum in 0:99) { try( { data <- fromJSON(paste0("https://api.hh.ru/vacancies?search_field=name&text=\"" , q , "\"&search_field=name" , "&only_with_salary=", paid ,"&page=" , pageNum)) df <- rbind(df, data.frame( q, data$items$url, as.numeric(data$items$id), data$items$name, data$items$area$name, data$items$published_at, data$items$salary$currency, data$items$salary$from, data$items$salary$to, data$items$salary$gross, data$items$employer$name, data$items$snippet$responsibility, data$items$snippet$requirement, stringsAsFactors = FALSE)) }) print(paste0("Downloading page:", pageNum + 1, "; query = \"", q, "\"")) } } names <- c("query", "URL", "id", "Name", "City", "Published", "Currency", "From", "To", "Gross", "Company", "Responsibility", "Requirement") colnames(df) <- names return(df) }
في وظيفة hh.getjobs() ، يقبل الإدخال متجه استعلامات البحث التي تهمنا والتنقيح ، نحن مهتمون فقط بالوظائف الشاغرة ذات الراتب المحدد أو جميعها على التوالي (افتراضيًا ، نأخذ الخيار الثاني). يتم إنشاء إطار dafa فارغ ، ثم يتم استخدام fromJSON() لحزمة fromJSON() ، والتي تأخذ عنوان URL للإدخال وترجع قائمة منظمة. بعد ذلك ، من العقد في هذه القائمة ، نحصل على البيانات التي نهتم بها ونملأ حقول إطار البيانات المقابلة.
بشكل افتراضي ، يتم إعطاء البيانات صفحة تلو الأخرى ، مع 20 عنصرًا في كل صفحة. بحد أقصى 2000 وظيفة شاغرة. يتم تسجيل جميع البيانات التي نتلقاها في df .
Life hack 1: ليست حقيقة أنه بناء على طلبنا سيكون هناك 2000 وظيفة شاغرة ، وبدءًا من مرحلة ما ، سنستقبل صفحات فارغة. في هذه الحالة ، يقسم R ويقفز خارج الحلقة. لذلك ، نلف محتويات الحلقة الداخلية بعناية في try() .
Life hack 2: من المنطقي أيضًا إضافة ناتج حالة جمع البيانات الحالية إلى وحدة التحكم في الحلقة الداخلية ، لأن هذا ليس عملًا سريعًا. فعلت هذا:
print(paste0("Downloading page:", pageNum + 1, "; query = \"", query, "\""))
بعد ملء البيانات ، تتم إعادة تسمية الأعمدة بحيث يسهل التعامل معها ، ويتم إرجاع إطار البيانات الناتج.
سأقوم بتخزين هذا ووظائف مساعدة أخرى في functions.R منفصلة.ملف R حتى لا تزدحم النص الرئيسي ، والذي يبدو حتى الآن مثل هذا:
source("functions.R") # Step 1 - get data # 1.1 get vacancies (short info) jobdf <- hh.getjobs(query = c("business+analyst" , "systems+analyst" , "product+owner"), paid = FALSE)
الآن سنحصل على experience key_skills من الوصف الوظيفي الكامل .
hh.getxp بتمرير إطار البيانات إلى الوظيفة hh.getxp ، ونذهب من خلال الروابط المحفوظة إلى الوظائف الشاغرة ، ومن الوصف الكامل نحصل على قيمة خبرة العمل المطلوبة. يتم تخزين القيمة الناتجة في عمود جديد.
عرض الكود hh.getxp <- function(df) { df$experience <- NA for (myURL in df$URL) { try( { data <- fromJSON(myURL) df[df$URL == myURL, "experience"] <- data$experience$name } ) print(paste0("Filling in ", which(df$URL == myURL, arr.ind = TRUE), "from ", nrow(df))) } return(df) }
يتم إرسال وصف وظيفة المساعد الجديدة إلى functions.R . functions.R ، والبرنامج النصي الرئيسي يصل إليها الآن:
# s.1.2 get experience (from full info) jobdf <- hh.getxp(jobdf) # 1.3 get skills (from full info) all.skills <- hh.getskills(jobdf$URL)
في الجزء أعلاه ، نقوم أيضًا بتشكيل إطار بيانات جديد all.skills النموذج "job id - مهارة":
عرض الكود hh.getskills <- function(allurls) { analyst.skills <- data.frame( id = character(), # id skill = character() # ) for (myURL in allurls) { data <- fromJSON(myURL) if (length(data$key_skills) > 0) analyst.skills <- rbind(analyst.skills, cbind(data$id, data$key_skills)) print(paste0("Filling in " , which(allurls == myURL, arr.ind = TRUE) , " out of " , length(allurls))) } names(analyst.skills) <- c("id", "skill") analyst.skills$skill <- tolower(analyst.skills$skill) return(analyst.skills) }
المعالجة المسبقة
دعونا نرى مقدار البيانات التي تمكنا من جمعها:
> length(unique(jobdf$id)) [1] 1478 > length(jobdf$id) [1] 1498
ما يقرب من ألف ونصف وظيفة! تبدو جيدة. وعلى ما يبدو ، دخلت العديد من الوظائف الشاغرة في نتائج البحث مرتين - لطلبات مختلفة. لذلك ، فإن الخطوة الأولى هي ترك الإدخالات الفريدة فقط: jobdf <- jobdf[unique(jobdf$id),] .
من أجل مقارنة رواتب محللي سوق العمل ، أحتاج
1) التأكد من تقديم جميع البيانات المتاحة عن الرواتب بعملة واحدة ،
2) اختر في إطار بيانات منفصل الشواغر التي تم تحديد الراتب لها.
نعتبر كل مهمة فرعية بمزيد من التفصيل. سابقًا ، يمكنك معرفة ما هي العملات من حيث المبدأ في بياناتنا باستخدام table(jobdf$Currency) . في حالتي ، بالإضافة إلى الروبل ، ظهرت الدولارات واليورو والهريفنيا والتنج الكازاخستاني وحتى المبالغ الأوزبكية.
لتحويل قيم الراتب إلى الروبل ، تحتاج إلى معرفة سعر الصرف الحالي. سنكتشف من البنك المركزي :
عرض الكود quotations.update <- function(currencies) { # Parses the most up-to-date qutations data provided by the Central Bank of Russia # and returns a table with currency rate against RUR doc <- XML::xmlParse("http://www.cbr.ru/scripts/XML_daily.asp") quotationsdf <- XML::xmlToDataFrame(doc, stringsAsFactors = FALSE) quotationsdf <- select(quotationsdf, -Name) quotationsdf$NumCode <- as.numeric(quotationsdf$NumCode) quotationsdf$Nominal <- as.numeric(quotationsdf$Nominal) quotationsdf$Value <- as.numeric(sub(",", ".", quotationsdf$Value)) quotationsdf$Value <- quotationsdf$Value / quotationsdf$Nominal quotationsdf <- quotationsdf %>% select(CharCode, Value) return(quotationsdf) }
للتأكد من معالجة الدورات التدريبية بشكل صحيح في R ، تحتاج إلى التأكد من فصل الجزء العشري بنقطة. بالإضافة إلى ذلك ، يجب الانتباه إلى العمود الاسمي: في مكان ما يكون 1 ، في مكان 10 أو 100. وهذا يعني أن الجنيه الإسترليني الواحد يكلف ~ 85 روبل ، ولنفترض أنه مقابل مائة درام أرمني يمكنك شراء ~ 13 روبل. من أجل راحة المعالجة الإضافية ، قمت بتقليل القيم إلى قيمة اسمية 1 بالنسبة للروبل.
الآن يمكنك الترجمة. يقوم البرنامج النصي لدينا بذلك باستخدام الدالة convert.currency() . يتم أخذ سعر الصرف الحالي فيه من جدول quotations ، حيث قمنا بحفظ البيانات من XML المقدمة من البنك المركزي. أيضًا ، تقبل وظيفة الإدخال العملة المستهدفة للتحويل (افتراضيًا RUR) وجدول يحتوي على وظائف شاغرة ، وقيم شوكات الراتب التي من الضروري أن تؤدي إلى عملة واحدة. تقوم الدالة بإرجاع جدول بأرقام راتب محدثة (بالفعل بدون عمود العملة ، كما هو غير ضروري).
اضطررت إلى العبث بالروبل البيلاروسي: بعد تلقي بيانات غريبة للغاية في العديد من الأساليب ، أجريت بحثًا صغيرًا واكتشفت أنه منذ عام 2016 تم استخدام عملة جديدة في روسيا البيضاء ، والتي لا تختلف فقط في سعر الصرف ، ولكن أيضًا في الاختصار (الآن ليس BYR ، ولكن BYN) . في الدلائل ، مازال يتم استخدام الاختصار BYR ، الذي لا يعرف XML من البنك المركزي أي شيء. لذلك ، في الدالة convert.currency() I ليس بالطريقة الأكثر أناقة أولاً ، استبدل الاختصار بالاختصار الحالي ، ثم انتقل مباشرة إلى التحويل.
يبدو هذا:
عرض الكود convert.currency <- function(targetCurrency = "RUR", df, quotationsdf) { cond <- (!is.na(df$Currency) & df$Currency == "BYR") df[cond, "Currency"] <- "BYN" currencies <- unique(na.omit(df$Currency[df$Currency != targetCurrency])) # ( ) if (!is.null(df$From)) { for (currency in currencies) { condition <- (!is.na(df$From) & df$Currency == currency) try( df$From[condition] <- df$From[condition] * quotationsdf$Value[quotationsdf$CharCode == currency] ) } } # ( ) if (!is.null(df$To)) { for (currency in currencies) { condition <- !is.na(df$To) & df$Currency == currency try( df$To[condition] <- df$To[condition] * quotationsdf$Value[quotationsdf$CharCode == currency] ) } } return(df %>% select(-Currency)) }
يمكنك أيضًا أن تأخذ في الاعتبار أن بعض البيانات المتعلقة بالرواتب يتم تقديمها بالقيم الإجمالية ، أي أن الموظف سيحصل على مبلغ أقل قليلاً في متناول اليد. لحساب الراتب الصافي للمقيمين في الاتحاد الروسي ، يجب خصم 13 ٪ من هذه الأرقام (يتم خصم 30 ٪ لغير المقيمين).
عرض الكود gross.to.net <- function(df, resident = TRUE) { if (resident == TRUE) coef <- 0.87 else coef <- 0.7 if (!is.null(df$Gross)) { if (!is.null(df$From)) # ( ) { index <- na.omit(as.numeric(rownames(df[!is.na(df$From) & df$Gross == TRUE,]))) df$From[index] <- df$From[index] * coef } if (!is.null(df$To)) # ( ) { index <- na.omit(as.numeric(rownames(df[!is.na(df$To) & df$Gross == TRUE,]))) df$To[index] <- df$To[index] * coef } df <- df %>% select(-Gross) } return(df) }
بالطبع ، لن أفعل ذلك ، لأنه في هذه الحالة يجدر النظر في الضرائب في بلدان مختلفة ، وليس فقط في روسيا ، أو إضافة عامل تصفية حسب البلد في استعلام البحث الأولي.
الخطوة الأخيرة قبل التحليل هي تقسيم الوظائف الشاغرة إلى ثلاث فئات: حزيران / يونيو ، الأوسط والكبير ، وكتابة الوظائف المستلمة في عمود جديد. وستشمل المناصب العليا تلك التي توجد باسمها كلمة "كبار" ومرادفاتها. وبالمثل ، سنجد مواقع البداية للكلمات الرئيسية "صغار" والمرادفات ، ومن بين الوسطاء ندرج جميع تلك بين:
get.positions <- function(df) { df$lvl <- NA df[grep(pattern = "lead|senior|||", x = df$Name, ignore.case = TRUE), "lvl"] <- "senior" df[grep(pattern = "junior|||", x = df$Name, ignore.case = TRUE), "lvl"] <- "junior" df[is.na(df$lvl), "lvl"] <- "middle" return(df) }
أضف كتلة تحضير البيانات إلى البرنامج النصي الرئيسي.
تمت الإضافة # Step 2 - prepare data # 2.1. Convert all currencies to target currency # 2.1.1 get up-to-date currency rates quotations <- quotations.update() # 2.1.2 convert to RUR jobdf <- convert.currency(df = jobdf, quotationsdf = quotations) # 2.2 convert Gross to Net # jobdf <- gross.to.net(df = jobdf) # 2.3 define segments jobdf <- get.positions(jobdf)
التحليل
كما ذكر أعلاه ، سأقوم بتحليل الجوانب التالية من البيانات التي تم الحصول عليها:
- متوسط الراتب BA / SA ،
- أكثر المهارات والصفات الشخصية المطلوبة في هذا المنصب ،
- التبعيات (إن وجدت) بين مهارات معينة ومستوى الراتب.
متوسط دخل BA / SA
كما اتضح ، الشركات مترددة في تحديد حد أعلى أو أدنى للرواتب.
في إطار عمل البيانات الخاص jobdf هذه القيم في العمودين من و إلى على التوالي. أريد إيجاد المتوسطات وكتابتها في عمود راتب جديد.
بالنسبة للحالات التي يُشار فيها إلى الراتب بالكامل ، يمكن القيام بذلك بسهولة باستخدام دالة mean() ، وتصفية جميع السجلات الأخرى حيث تكون البيانات الموجودة على القابس مفقودة كليًا أو جزئيًا. ولكن في هذه الحالة ، سيبقى أقل من 10٪ من العينة الأصلية ، وهي صغيرة بالفعل. لذلك ، أحسب المعامل Podgoniana ، الذي يخبرك بمدى اختلاف قيم To و From في المتوسط في الوظائف الشاغرة حيث يُشار إلى الشوكة الكاملة ، وبمساعدتها أقوم بتعبئة البيانات الناقصة في الحالات التي تكون فيها قيمة واحدة مفقودة.
عرض الكود select.paid <- function(df, suggest = TRUE) { # Returns a data frame with average salaries between To and From # optionally, can suggest To or From value in case only one is specified if (suggest == TRUE) { df <- df %>% filter(!is.na(From) | !is.na(To)) magic.coefficient <- # shows the average difference between max and min salary round(mean(df$To/df$From, na.rm = TRUE), 1) df[is.na(df$To),]$To <- df[is.na(df$To),]$From * magic.coefficient df[is.na(df$From),]$From <- df[is.na(df$From),]$To / magic.coefficient } else { df <- na.omit(df) } df$salary <- rowMeans(x = df %>% select(From, To)) df$salary <- ceiling(df$salary / 10000) * 10000 return(df %>% select(-From, -To)) }
هذه تصفية بيانات "لينة" ، يتم تعيينها في select.paid() مع المعلمة select.paid() suggest = TRUE . بدلاً من ذلك ، يمكننا تحديد suggest = FALSE عند استدعاء الوظيفة ومجرد قطع جميع الأسطر التي تكون فيها بيانات الراتب غائبة جزئيًا على الأقل. ومع ذلك ، باستخدام التصفية الناعمة والمعامل السحري ، تمكنت من حفظ ما يقرب من ربع مجموعة البيانات الأصلية في العينة.
ننتقل إلى الجزء البصري:

يمكنك في هذا الرسم البياني تقييم كثافة توزيع رواتب BA / SA بشكل مرئي في عاصمتين وفي المناطق. ولكن ماذا لو حددنا الطلب وقارننا مقدار ما يحصل عليه الرجال الأوسطون وكبار السن في العواصم؟
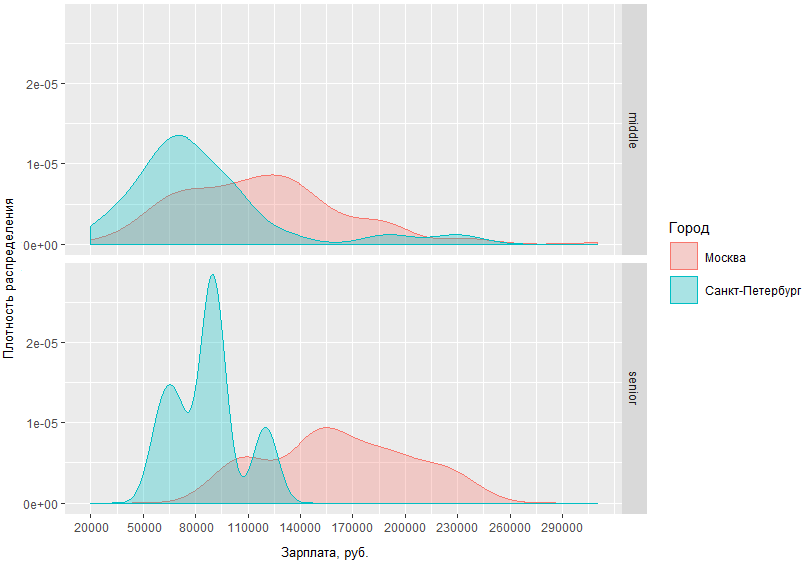
من الرسم البياني الذي تم الحصول عليه ، من الواضح أن الفرق في مواقف الرواتب بين الرجال الأوسط وكبار السن في موسكو وسان بطرسبرغ ليس مختلفًا جدًا. لذا ، في سانت بطرسبرغ ، يحصل الوسطاء ، كقاعدة عامة ، في منطقة 70 tr ، بينما في موسكو تقع ذروة الكثافة على 120 tr تقريبًا ، والفرق في دخل كبار المتخصصين في موسكو وسان بطرسبرغ يختلف بمتوسط 60 ألف.
يمكننا أيضًا أن ننظر ، على سبيل المثال ، إلى رواتب المحللين في موسكو حسب الموقف:

يمكن الاستنتاج أن أ) اليوم في موسكو هناك طلب أكبر بكثير على المحللين المبتدئين ، و ب) في نفس الوقت ، فإن الحد الأعلى للراتب لهؤلاء المتخصصين محدود أكثر بكثير من الوسطاء وكبار السن.
ملاحظة أخرى: متوسط sn المتخصصين في موسكو من المستوى المتوسط والعالي لديه منطقة تقاطع كبيرة إلى حد ما. قد يشير هذا إلى أن السوق لديها حد غير واضح بين هاتين الخطوتين.
كود كامل للمخططات تحت القطع.
عرض # Step 3 - analyze salaries # 3.1 get paid jobs (with salaries specified) jobs.paid <- select.paid(jobdf) # 3.2 plot salaries density by region ggplotly(ggplot(jobs.paid, aes(salary, fill = region, colour = region)) + geom_density(alpha=.3) + scale_fill_discrete(guide = guide_legend(reverse=FALSE)) + scale_x_continuous(labels = function(x) format(x, scientific = FALSE), name = ", .", breaks = round(seq(min(jobs.paid$salary), max(jobs.paid$salary), by = 30000),1)) + scale_y_continuous(name = " ") + theme(axis.text.x = element_text(size=9), axis.title = element_text(size=10))) # 3.3 compare salaries for middle / senior in capitals ggplot(jobs.paid %>% filter(region %in% c("", "-"), lvl %in% c("senior", "middle")), aes(salary, fill = region, colour = region)) + facet_grid(lvl ~ .) + geom_density(alpha = .3) + scale_x_continuous(labels = function(x) format(x, scientific = FALSE), name = ", .", breaks = round(seq(min(jobs.paid$salary), max(jobs.paid$salary), by = 30000),1)) + scale_y_continuous(name = " ") + scale_fill_discrete(name = "") + scale_color_discrete(name = "") + guides(fill=guide_legend( keywidth=0.1, keyheight=0.1, default.unit="inch") ) + theme(legend.spacing = unit(1,"inch"), axis.title = element_text(size=10)) # 3.4 plot salaries in Moscow by position ggplotly(ggplot(jobs.paid %>% filter(region == ""), aes(salary, fill = lvl, color = lvl)) + geom_density(alpha=.4) + scale_fill_brewer(palette = "Set2") + scale_color_brewer(palette = "Set2") + theme_light() + scale_y_continuous(name = " ") + scale_x_continuous(labels = function(x) format(x, scientific = FALSE), name = ", .", breaks = round(seq(min(jobs.paid$salary), max(jobs.paid$salary), by = 30000),1)) + theme(axis.text.x = element_text(size=9), axis.title = element_text(size=10)))
تحليل المهارات الأساسية
ننتقل إلى الهدف الرئيسي للدراسة - لتحديد أكثر المهارات المطلوبة لـ BA / SA. للقيام بذلك ، سنقوم بتحليل البيانات المشار إليها صراحة في المجال الخاص للشواغر - المهارات الرئيسية.
المهارات الأكثر شعبية
في وقت سابق ، تلقينا إطار بيانات منفصل all.skills ، حيث قمنا بتسجيل أزواج "معرف الوظيفة - مهارة". يعد العثور على المهارات الأكثر شيوعًا أمرًا سهلاً مع وظيفة table() :
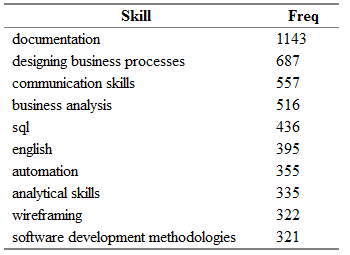
tmp <- as.data.frame(table(all.skills$skill), col.names = c("Skill", "Freq")) htmlTable::htmlTable(x = head(tmp[order(tmp$Freq, na.last = TRUE, decreasing = TRUE),]), rnames = FALSE, header = c("Skill", "Freq"), align = 'l', css.cell = "padding-left: .5em; padding-right: 2em;")
تحصل على شيء مثل ما يلي:

هنا Freq هو عدد الوظائف الشاغرة في حقل "key_skills" الذي يُشار إلى المهارة المقابلة من عمود المهارة.
"ولكن هذا ليس كل شيء!" (ج) من الواضح تمامًا أنه يمكن العثور على نفس المهارات بسهولة في الوظائف الشاغرة المختلفة بعبارات مترادفة.
قمت بتجميع قاموس صغير من المرادفات لأسماء المهارات وقسمتها إلى فئات.
القاموس عبارة عن ملف csv يحتوي على أعمدة الفئات - أحد الإجراءات التالية: الأنشطة والأدوات والمعرفة والمعايير والشخصية ؛ مهارة - الاسم الرئيسي للمهارة ، والذي سأستخدمه بدلاً من جميع المرادفات الموجودة ؛ syn1 ، syn2 ، ... syn13 - في الواقع الاختلافات الممكنة لكل مهارة. قد تحتوي بعض الصفوف على أعمدة فارغة من المرادفات.
category;skill;syn1;syn2;syn3;syn4;syn5;syn6;syn7;syn8;syn9;syn10;syn11;syn12;syn13 tools;axure;;;;;;;;;;;;; tools;lucidchart;;;;;;;;;;;;; standards;archimate;;;;;;;;;;;;; standards;uml;activity diagram;use case diagram;ucd;class diagram;;;;;;;;; personal;teamwork;team player; ;;;;;;;;;;; activities;wireframing;mockup;mock-up;;-;wireframe;;ui;ux/;/ux;;;;
أولاً ، قم باستيراد القاموس ، ثم قم بإعادة توزيع المهارات مرة أخرى بناءً على المعادلات الحالية:
# Analyze skills # 4.1 import dictionary dict <- read.csv(file = "competencies.csv", header = TRUE, stringsAsFactors = FALSE, sep = ";", na.strings = "", encoding = "UTF-8") # 4.2 match skills with dictionary all.skills <- categorize.skills(all.skills, dict)
تحت القطع ، يمكنك رؤية حشو وظيفة categorize.skills() .
تلك الشجاعة جدا! categorize.skills <- function(analyst_skills, dictionary) { analyst_skills$skill.group <- NA analyst_skills$category <- NA for (myskill in dictionary$skill) { category <- dictionary[dictionary$skill == myskill, "category"] mypattern <- paste0(na.omit(t(dictionary %>% filter(skill == myskill) %>% select(starts_with("syn")))), collapse = "|") if (nchar(mypattern) > 1) mypattern <- paste0(c(myskill, mypattern), collapse = "|") else mypattern <- myskill try( { analyst_skills[grep(x = analyst_skills$skill, pattern = mypattern),"skill.group"] <- myskill analyst_skills[grep(x = analyst_skills$skill, pattern = mypattern),"category"] <- category } ) } return(analyst_skills) }
أقوم بإضافة عمود الفئة والمهارة إلى إطار بيانات المهارات الأصلي. مجموعة - للفئة والاسم المعمم للمهارة ، على التوالي. ثم أتصفح القاموس المستورد وأكوّن نمطًا لوظيفة grep() من كل سطر من المرادفات. بإضافة قيمة كل عمود غير فارغ إلى الصف ، أفصلها بشرطة للحصول على شرط "أو". لذا ، بالنسبة لجميع المهارات من جدول المصدر ، والذي يتضمن uml|activity diagram|use case diagram|ucd|class diagram ، سأكتب القيمة "uml" في عمود المهارة. وهكذا ستكون مع الجميع! مهارة من إطار البيانات الأصلي.
من خلال إعادة طلب أعلى المهارات الأكثر شعبية ، يمكنك أن ترى أن اصطفاف القوى قد تغير إلى حد ما:
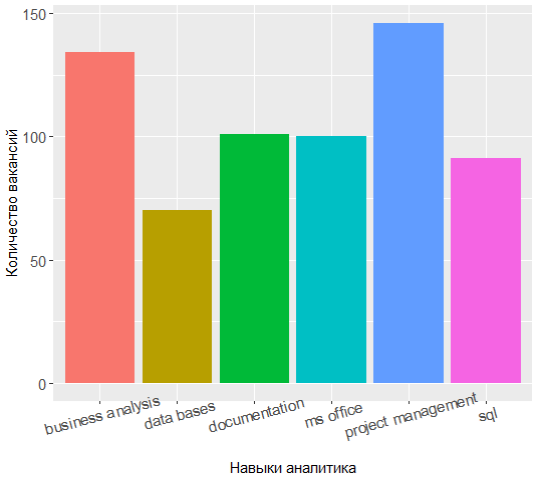
القادة الثلاثة لديهم الآن إدارة المشاريع ، تحليل الأعمال والتوثيق ، ومعرفة UML تحولت من أعلى 7.
من المثير للاهتمام للغاية مراجعة الفئات ومعرفة المهارات الأكثر طلبًا في كل منها.
على سبيل المثال ، بالنسبة لفئة المعرفة ، يكون الوضع كما يلي:
عرض الكود tmp <- merge(x = all.skills, y = jobdf %>% select(id, lvl), by = "id", sort = FALSE) tmp <- na.omit(tmp) ggplot(as.data.frame(table(tmp %>% filter(category == "knowledge") %>% select(skill.group)))) + geom_bar(colour = "#666666", stat = "identity", aes(x = reorder(Var1, Freq), y = Freq, fill = reorder(Var1, -Freq))) + scale_y_continuous(name = " ") + theme(legend.position = "none", axis.text = element_text(size = 12)) + coord_flip()

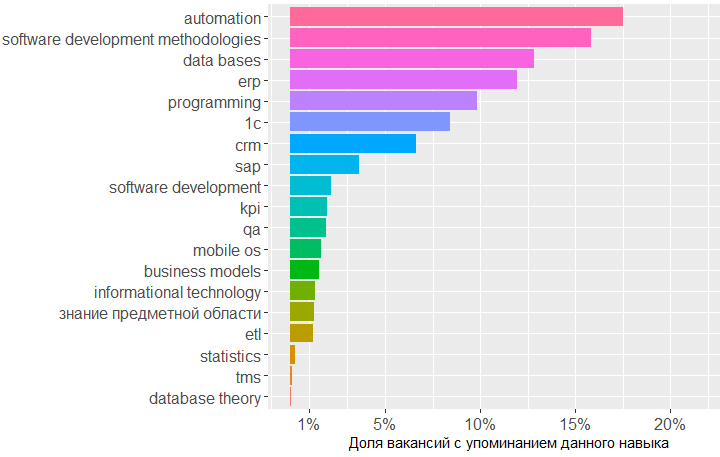
يوضح الرسم البياني أن أكبر طلب على المعرفة في مجال قواعد البيانات ومنهجيات تطوير البرمجيات و 1 C. بعد ذلك تأتي المعرفة في مجال إدارة علاقات العملاء وأنظمة تخطيط موارد المؤسسات وأساسيات البرمجة.
فيما يتعلق بالمعايير ، فإن معرفة SQL و UML مطلوبة حقًا ، يأتي تدوين ARIS على أعتابهم ، لكن GOSTs تحتل المركز السادس فقط.
هذا هو الرمز ggplot(as.data.frame(table(tmp %>% filter(category == "standards") %>% select(skill.group)))) + geom_bar(colour = "#666666", stat = "identity", aes(x = reorder(Var1, Freq), y = Freq, fill = Var1)) + scale_y_continuous(name = " ") + theme(legend.position = "none", axis.text = element_text(size = 12)) + coord_flip()

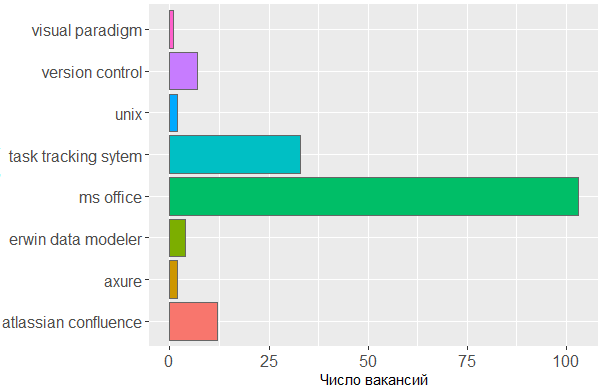
بالنسبة للأدوات المستخدمة ، نرى مرة أخرى تأكيدًا أن الرأس هو الأداة الرئيسية للمحلل. لا يمكن للمرء الاستغناء عن أنظمة تتبع المهام والخطوط الخاصة بـ MS Office ، ولكن الباقي لا يمثل سوى القليل من القلق للمحرر الذي يقوم فيه المحلل بإنشاء مخططاته الخاصة أو نماذج واجهة التخطيط.
هذا هو الرمز ggplot(tmp %>% filter(category == "tools")) + geom_histogram(colour = "#666666", stat = "count", aes(skill.group, fill = skill.group)) + scale_y_continuous(name = " ") + theme(legend.position = "none", axis.text = element_text(size = 12)) + coord_flip()
تأثير المهارات على الدخل
, , . , , , .
jobs.paid all.skills , data frame.
# 4.4 vizualize paid skills tmp <- na.omit(merge(x = all.skills, y = jobs.paid %>% select(id, salary, lvl, City), by = "id", sort = FALSE))
:
> head(tmp) id skill skill.group category salary lvl City 2 25781585 android mobile os knowledge 90000 middle 3 25781585 project management activities 90000 middle 5 25781585 project management activities 90000 middle 6 25781585 ios mobile os knowledge 90000 middle 7 25750025 aris aris standards 70000 middle 8 25750025 - business analysis activities 70000 middle
, .. . :
ggplotly(ggplot(tmp %>% filter(category == "activities"), aes(skill.group, salary)) + coord_flip() + geom_count(aes(size = ..n.., color = City)) + scale_fill_discrete(name = "") + scale_y_continuous(name = ", .") + scale_size_area(max_size = 11) + theme(legend.position = "bottom", axis.title = element_blank(), axis.text.y = element_text(size=10, angle=10)))

, BA/SA .
:
ggplot(tmp %>% filter(category == "personal", City %in% c("", "-")), aes(tools::toTitleCase(skill), salary)) + coord_flip() + geom_count(aes(size = ..n.., color = skill.group)) + scale_y_continuous(breaks = round(seq(min(tmp$salary), max(tmp$salary), by = 20000),1), name = ", .") + scale_size_area(max_size = 10) + theme(legend.position = "none", axis.title = element_text(size = 11), axis.text.y = element_text(size=10, angle=0))
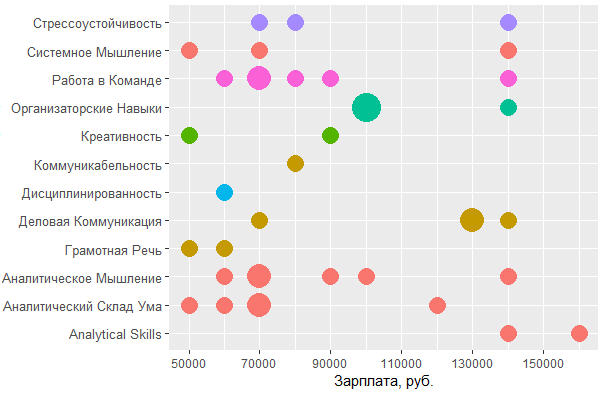
, MS Office , — , - . , , , .
, , : UML ARIS, SQL ( ) , IDEF — , "".
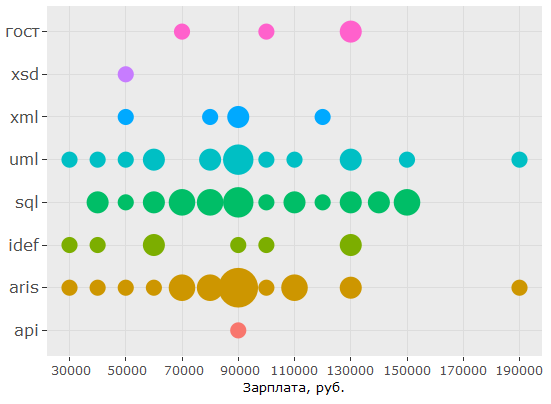
, , , . , 1478 - key_skills. , - .
, data frame:
> jobdf$Responsibility[[1]] [1] "Training course in business analysis. ● Define needs of the user/client, understand the problem which needs to be solved. ● " > jobdf$Requirement[[1]] [1] "At least 6 months' experience in business analysis. ● Knowledge of qualitative methods such as usability testing, interviewing, focus groups. ● "
, , . URL' , .
hh.get.full.desrtion <- function(df) { df$full.description <- NA for (myURL in df$URL) { try( { data <- fromJSON(myURL) if (length(data$description) > 0) { df$full.description[which(df$URL == myURL, arr.ind = TRUE)] <- data$description } print(paste0("Filling in " , which(df$URL == myURL, arr.ind = TRUE) , " out of " , length(df$URL))) } ) } df$full.description <- tolower(df$full.description) return(df) }
- , html- ., gsub :
remove.Html <- function(htmlString) { #remove html tags return(gsub("<.*?>", "", htmlString)) }
, , , , . data frame ( df), , df "id, skill.group, category".
skills.from.desc <- function(df, dictionary) { sk <- data.frame( id = numeric() , skill.group = character() , category = character() ) for (myskill in dictionary$skill) { category <- dictionary[dictionary$skill == myskill, "category"] mypattern <- paste0(na.omit(t(dictionary %>% filter(skill == myskill) %>% select(starts_with("syn")))), collapse = "|") if (nchar(mypattern) > 1) { mypattern <- paste0(c(myskill, mypattern), collapse = "|") } else { mypattern <- myskill } cond = grep(x = df$full.description, pattern = mypattern) tmp <- data.frame( id = df[cond, "id"], skill.group = rep(myskill, length(cond)), category = rep(category, length(cond)) ) sk <- rbind(sk, tmp) } return(sk) }
# 5 text analysis # 5.1 get full descriptions jobdf <- hh.get.full.description(jobdf) jobdf$full.description <- remove.Html(tolower(jobdf$full.description)) sk.from.desc <- skills.from.desc(jobdf, dict)
, ?
> head(sk.from.desc) id skill.group category 1 25638419 axure tools 2 24761526 axure tools 3 25634145 axure tools 4 24451152 axure tools 5 25630612 axure tools 6 24985548 axure tools > tmp <- as.data.frame(table(sk.from.desc$skill.group), col.names = c("Skill", "Freq")) > htmlTable::htmlTable(x = head(tmp[order(tmp$Freq, na.last = TRUE, decreasing = TRUE),], 20), rnames = FALSE, header = c("Skill", "Freq"), align = 'l', css.cell = "padding-left: .5em; padding-right: 2em;")
, ! Project management, key_skills, ( ).
, , key_skills -5.
, . 1478 , , key_skills, , .
, , BA , - .
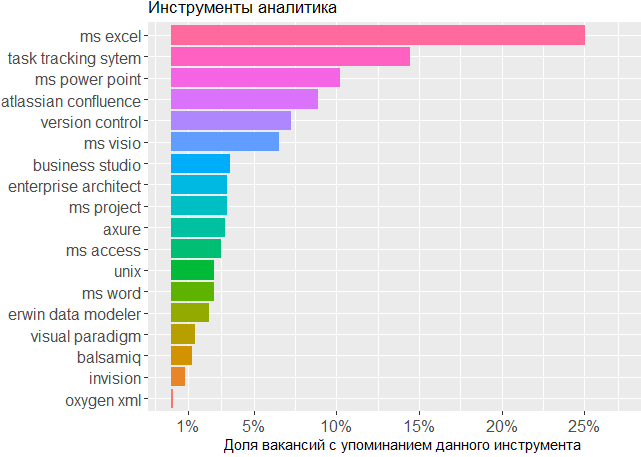
, .
data frame , , . , -.
tmp <- na.omit(merge(x = sk.from.desc, y = jobs.paid %>% filter(City %in% c("", "-")) %>% select(id, salary, lvl, City), by = "id", sort = FALSE))
> head(tmp) id skill.group category salary lvl City 1 25243346 uml standards 160000 middle 2 25243346 requirements management activities 160000 middle 3 25243346 designing business processes activities 160000 middle 4 25243346 communication skills personal 160000 middle 5 25243346 mobile os knowledge 160000 middle 6 25243346 ms visio tools 160000 middle
, , , .
ggplotly(ggplot(tmp %>% filter(category == "activities"), aes(skill.group, lvl)) + geom_count(aes(color = salary, size = ..n..)) + scale_size_area(max_size = 13) + theme(legend.position = "right", legend.title = element_text(size = 10), axis.title = element_blank(), axis.text.y = element_text(size=10)) + coord_flip() + scale_color_continuous(labels = function(x) format(x, scientific = FALSE), breaks = round(seq(min(tmp$salary), max(tmp$salary), by = 70000),1), low = "blue", high = "red", name = ", ."))
?
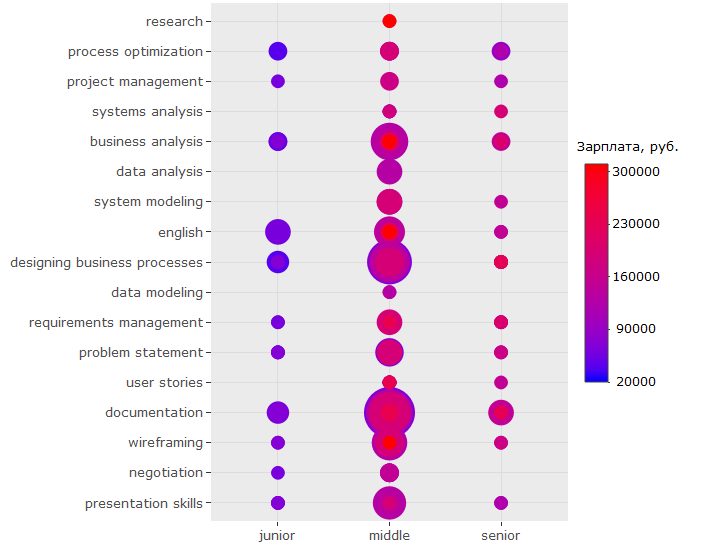
-, , - . ( , , , .)
-, , "" -, .
, key_skills.
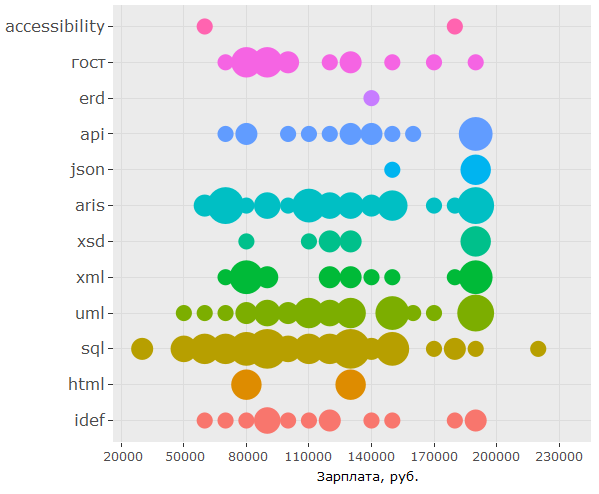
, , 150 .. UML ARIS, IDEF, , — .
:

, - , , key_skills , . , 150 .. , .
?
, - :

, , , ? , . , , . , ó ( )
, - :

-
BA/SA ,
- . , ;
- ( ) 200 .. , , ;
- ;
- — - ( , , )
key_skills hh , ;- , , , (!) ;
- , -, UX ;
- . , - 150 ..;
- , , SQL, UML & ARIS. , .. . , , ,
wordcloud2::wordcloud2(data = table(sk.from.desc$skill.group), rotateRatio = 0.3, color = 'random-dark')
