
شرح
تعتبر معالجة البيانات في الوقت الفعلي بالضبط مرة واحدة (مرة واحدة بالضبط ) مهمة غير تافهة للغاية وتتطلب نهجًا جادًا ومدروسًا طوال سلسلة الحسابات بأكملها. يعتقد البعض أن مثل هذه المهمة مستحيلة . في الواقع ، أريد أن يكون لدي نهج يوفر معالجة متسامحة مع الأخطاء دون أي تأخير على الإطلاق واستخدام تخزين مختلف للبيانات ، والذي يطرح متطلبات جديدة أكثر صرامة للنظام: متزامن مرة واحدة بالضبط وعدم تجانس الطبقة الثابتة. حتى الآن ، لا يدعم هذا المطلب أيًا من الأنظمة الموجودة.
سيكشف النهج المقترح باستمرار عن المكونات السرية والمفاهيم الضرورية التي تجعل من السهل نسبيًا تنفيذ المتزامنة غير المتجانسة بالضبط مرة واحدة بالضبط من مكونين حرفيا.
مقدمة
يمر مطور الأنظمة الموزعة بعدة مراحل:
المرحلة 1: الخوارزميات . هنا دراسة الخوارزميات الأساسية وهياكل البيانات ونهج البرمجة مثل OOP وما إلى ذلك. الكود مترابط بشكل حصري. المرحلة الأولى من دخول المهنة. ومع ذلك ، فهي معقدة للغاية ويمكن أن تستمر لسنوات.
المرحلة 2: multithreading . بعد ذلك ، تطرح أسئلة حول استخراج أقصى قدر من الكفاءة من الحديد ، وهناك تعدد مؤشرات ، وعدم التزامن ، والسباق ، وتصحيح الأخطاء ، والركود ، وليالي بلا نوم ... يتعثر الكثير في هذه المرحلة وحتى يبدأ في التقاط إثارة لا يمكن تفسيرها في مرحلة ما. لكن قلة قليلة فقط فهمت بنية الذاكرة الافتراضية ونماذج الذاكرة ، والخوارزميات الخالية من القفل / الانتظار ، والنماذج المختلفة غير المتزامنة. وتقريبا لا أحد على الإطلاق - التحقق من التعليمات البرمجية متعددة الخيوط.
المرحلة 3: التوزيع . هنا يحدث مثل هذه القمامة لا في حكاية خرافية ولا قلم لوصف.
يبدو أن شيئًا معقدًا. نقوم بالتحويل: العديد من الخيوط -> العديد من العمليات -> العديد من الخوادم. لكن كل خطوة من خطوات التحول تحدث تغييرات نوعية ، وكلها تقع على النظام ، وتسحقه وتحوله إلى غبار.
والنقطة هنا هي تغيير مجال معالجة الخطأ وتوافر الذاكرة المشتركة. إذا كان هناك دائمًا جزء من الذاكرة كان متاحًا في كل خيط ، وإذا رغبت في ذلك ، في كل عملية ، الآن لا توجد مثل هذه القطعة ولا يمكن أن تكون. كل لنفسه ومستقل وفخور.
إذا كان الفشل في الدفق في وقت سابق قد دفن الدفق والعملية في نفس الوقت ، وكان هذا جيدًا ، لأنه لم يؤد إلى فشل جزئي ، والآن أصبح الفشل الجزئي هو القاعدة وفي كل مرة قبل كل عمل تفكر فيه: "ماذا لو؟". هذا مزعج للغاية ويشتت الانتباه عن الكتابة ، في الواقع ، الإجراءات نفسها التي ينمو بها الرمز بسبب هذا ليس في بعض الأحيان ، ولكن بأوامر من الحجم. كل شيء يتحول إلى شعيرية معالجة الأخطاء ، وتبديل الحالة والحفاظ على السياق ، والترميم بسبب فشل أحد المكونات ، ومكون آخر ، وعدم إمكانية الوصول إلى بعض الخدمات ، إلخ. الخ. بعد أن أخطأت مراقبة كل هذه الأشياء ، يمكنك الحصول على نوم هنيئ على جهاز الكمبيوتر المحمول المفضل لديك.
سواء كانت مسألة تعدد المواضيع: لقد أخذت كائن المزامنة وذهبت لتمزيق الذاكرة المشتركة من أجل المتعة. جمال!
ونتيجة لذلك ، لدينا أن الأنماط الرئيسية واختبار المعارك قد تم سحبها ، وأن الأنماط الجديدة ، لتحل محلها ، لسبب ما لم يتم تسليمها ، واتضح الأمر كما لو كان نكتة حول كيف تلوح الجنية بعصاها وسقط البرج من الدبابة.
ومع ذلك ، فإن الأنظمة الموزعة لديها مجموعة من الممارسات المثبتة والخوارزميات المثبتة. ومع ذلك ، يعتبر كل مبرمج يحترم نفسه أنه من واجبه رفض الإنجازات المعروفة ودراجة مصلحته ، على الرغم من الخبرة المكتسبة ، عدد كبير من المقالات العلمية والبحث الأكاديمي. بعد كل شيء ، إذا استطعت الدخول إلى الخوارزميات والتعددية ، كيف يمكنك الدخول في فوضى مع التوزيع؟ لا يمكن أن يكون هناك رأيين هنا!
نتيجة لذلك ، الأنظمة هي عربات التي تجرها الدواب ، تتباعد البيانات وتتدهور ، تصبح الخدمات غير متوفرة بشكل دوري للكتابة ، أو حتى غير متاحة تمامًا ، لأنه فجأة تعطلت العقدة ، تعطلت الشبكة ، استهلكت Java الكثير من الذاكرة و GC مملة ، وهناك العديد من الأسباب الأخرى التي يمكن أن تؤخر نهايتها للسلطات.
ومع ذلك ، حتى مع النهج المعروفة والمثبتة ، لا تصبح الحياة أسهل ، لأن البدائية الموثوقة الموزعة هي الوزن الثقيل مع متطلبات خطيرة لمنطق التعليمات البرمجية القابلة للتنفيذ. لذلك ، يتم قطع الزوايا كلما أمكن ذلك. وكما يحدث في كثير من الأحيان ، مع قطع الزوايا على عجل ، تظهر البساطة وقابلية التوسع النسبية ، ولكن موثوقية وتوافر واتساق النظام الموزع يختفي.
من الناحية المثالية ، لا أود أن أفكر على الإطلاق في أن نظامنا موزع ومتعدد المواضيع ، أي العمل في المرحلة الأولى (الخوارزميات) ، دون التفكير في المرحلة الثانية (تزامن متعدد + التزامن) والثالثة (التوزيع). هذه الطريقة لعزل التجريد من شأنها أن تزيد بشكل كبير من البساطة والموثوقية وسرعة كتابة التعليمات البرمجية. لسوء الحظ ، في الوقت الحالي هذا ممكن فقط في الأحلام.
ومع ذلك ، فإن التجريد الفردي يسمح بالعزلة النسبية. أحد الأمثلة النموذجية هو استخدام coroutines ، حيث بدلاً من الرمز غير المتزامن نحصل على متزامن ، أي ننتقل من المرحلة الثانية إلى المرحلة الأولى ، مما يسمح لنا بتبسيط كتابة الرمز والحفاظ عليه بشكل كبير.
تكشف المقالة على التوالي عن استخدام خوارزميات خالية من القفل لإنشاء نظام في الوقت الحقيقي قابل للتوزيع وموزع موثوق به ومتناسق ، أي كيف تساعد الإنجازات بدون قفل للمرحلة الثانية في تنفيذ المرحلة الثالثة ، مما يقلل من المهمة إلى خوارزميات مفردة الخيوط للمرحلة الأولى.
بيان المشكلة
توضح هذه المهمة فقط بعض الأساليب الهامة ويتم تقديمها كمثال لإدخال المشكلات في السياق. يمكن تعميمه بسهولة على الحالات الأكثر تعقيدًا ، والتي سيتم إجراؤها في المستقبل.
المهمة: معالجة البيانات المتدفقة في الوقت الفعلي .
هناك نوعان من تيارات الأرقام. يقرأ المعالج بيانات تدفقات الإدخال هذه ويحدد الأرقام الأخيرة لفترة معينة. يتم حساب متوسط هذه الأرقام خلال هذه الفترة الزمنية ، أي في نافذة بيانات منزلقة لوقت معين. يجب كتابة متوسط القيمة التي تم الحصول عليها إلى قائمة انتظار الإخراج للمعالجة اللاحقة. بالإضافة إلى ذلك ، إذا تجاوز عدد الأرقام في النافذة عتبة معينة ، فقم بزيادة العداد في قاعدة بيانات المعاملات الخارجية بمقدار واحد.
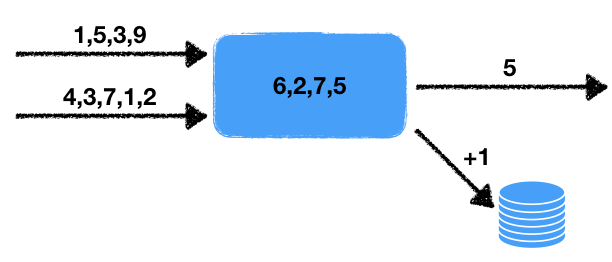
نلاحظ بعض ميزات هذه المشكلة.
- اللا حتمية . هناك مصدران للسلوك غير القطعي: هذه قراءة من تيارين ، بالإضافة إلى نافذة زمنية. من الواضح أنه يمكن إجراء القراءة بطرق مختلفة ، وستعتمد النتيجة النهائية على تسلسل البيانات التي سيتم استخراجها. تغير النافذة الزمنية النتيجة أيضًا من البداية إلى البداية ، مثل كمية البيانات في النافذة تعتمد على سرعة العمل.
- حالة المعالج . توجد حالة المعالج في شكل مجموعة من الأرقام في النافذة ، والتي تعتمد عليها نتائج العمل الحالية واللاحقة. على سبيل المثال لدينا معالج رسمي.
- التفاعل مع التخزين الخارجي . من الضروري تحديث قيمة العداد في قاعدة البيانات الخارجية. النقطة الحاسمة هي أن نوع التخزين الخارجي يختلف عن تخزين حالة المعالج والخيوط.
كل هذا ، كما هو موضح أدناه ، يؤثر بشكل خطير على الأدوات المستخدمة وطرق التنفيذ الممكنة.
يبقى إضافة لمسة صغيرة إلى المهمة ، التي تنقل المهمة على الفور من منطقة تتجاوز التعقيد إلى مستحيل: هناك حاجة إلى ضمان متزامن لمرة واحدة بالضبط .
مرة واحدة بالضبط
غالبًا ما يتم تفسيره مرة واحدة على نطاق واسع جدًا ، مما يعوق المصطلح نفسه ، ويتوقف عن تلبية المتطلبات الأصلية للمهمة. إذا كنا نتحدث عن نظام يعمل محليًا على جهاز كمبيوتر واحد - فإن كل شيء بسيط: خذ المزيد ، ورمي أبعد. لكن في هذه الحالة نتحدث عن نظام موزع:
- يمكن أن يكون عدد المعالجات كبيرًا: يعمل كل معالج مع قطعة البيانات الخاصة به. علاوة على ذلك ، يمكن إضافة النتائج إلى أماكن مختلفة ، على سبيل المثال ، قاعدة بيانات خارجية ، ربما حتى يتم تبديلها.
- يمكن لكل معالج إيقاف المعالجة فجأة. يشير النظام المتسامح مع الخطأ إلى استمرار التشغيل حتى في حالة فشل الأجزاء الفردية من النظام.
وبالتالي ، يجب أن نكون مستعدين لحقيقة أن المعالج قد يقع ، ويجب أن يلتقط معالج آخر العمل المنجز بالفعل ومواصلة المعالجة.
يطرح السؤال على الفور: ما الذي سيعني بالضبط مرة واحدة إذا كان المعالج غير القطعي يعمل؟ بعد كل شيء ، في كل مرة نعيد فيها العمل ، سوف نتلقى ، بشكل عام ، حالات مختلفة مختلفة. الجواب هنا بسيط: مع مرة واحدة بالضبط ، هناك تنفيذ للنظام يتم فيه معالجة كل قيمة إدخال مرة واحدة بالضبط ، مما يعطي نتيجة الإخراج المقابلة. علاوة على ذلك ، لا يجب أن يكون هذا التنفيذ جسديًا على نفس العقدة. ولكن يجب أن تكون النتيجة كما لو تم معالجة كل شيء على عقدة منطقية واحدة بدون أعطال .
متزامن مرة واحدة بالضبط
لتفاقم المتطلبات ، نقدم مفهومًا جديدًا: متزامن مرة واحدة بالضبط . الاختلاف الأساسي عن البسيط لمرة واحدة هو عدم وجود فترات توقف مؤقت أثناء المعالجة ، كما لو تم معالجة كل شيء على نفس العقدة بدون قطرات وبدون توقفات . في مهمتنا ، سنطلب متزامنة تمامًا مرة واحدة بالضبط ، من أجل بساطة العرض ، حتى لا نفكر في مقارنة مع الأنظمة الحالية غير المتوفرة اليوم.
ستتم مناقشة نتائج مثل هذا الشرط أدناه.
المعاملات
حتى يكون القارئ مشبعًا بعمق أكبر بالتعقيد الذي نشأ ، فلنلقِ نظرة على سيناريوهات سيئة مختلفة يجب أخذها في الاعتبار عند تطوير مثل هذا النظام. سنحاول أيضًا استخدام نهج عام يسمح لنا بحل المشكلة المذكورة أعلاه مع مراعاة متطلباتنا.
أول ما يتبادر إلى الذهن هو الحاجة إلى تسجيل حالة المعالج وتدفق الإدخال والإخراج. يتم وصف حالة تدفقات الإخراج بقائمة انتظار بسيطة من الأرقام ، وحالة تدفقات الإدخال حسب الموضع الموجود فيها. في جوهره ، يعد الدفق قائمة انتظار غير محدودة ، ويعين الموضع في قائمة الانتظار موقعًا فريدًا.

ينشأ التنفيذ الساذج التالي للمعالج باستخدام نوع من مستودع البيانات. في هذه المرحلة ، لن تكون الخصائص المحددة للمستودع مهمة بالنسبة لنا. سنستخدم لغة Pseco لتوضيح الفكرة (Pseco: = pseudo code):
handle(input_queues, output_queues, state): # input_indexes = storage.get_input_indexes() # while true: # items, new_input_indexes = input_queues.get_from(input_indexes) # state.queue.push(items) # duration state.queue.trim_time_window(duration) avg = state.queue.avg() need_update_counter = state.queue.size() > size_boundary # (A) output_queues[0].push(avg) if need_update_counter: # (B) db.increment_counter() # (C) storage.save_state(state) # (D) storage.save_queue_indexes(new_input_indexes) # (E) input_indexes = new_input_indexes
فيما يلي خوارزمية بسيطة مفردة الخيوط تقرأ البيانات من تدفقات الإدخال وتكتب القيم المطلوبة وفقًا للمهمة الموضحة أعلاه.
دعونا نرى ما يحدث في حالة سقوط العقدة في نقاط عشوائية في الوقت المناسب ، وكذلك بعد استئناف العمل. من الواضح أنه في حالة السقوط في النقطتين (A) و (E) سيكون كل شيء على ما يرام: إما أن البيانات لم يتم تسجيلها في أي مكان حتى الآن ونستعيد الحالة ببساطة ونستمر في العقدة الأخرى ، أو تم تسجيل جميع البيانات الضرورية بالفعل ونستمر في الخطوة التالية فقط.
ومع ذلك ، في حالة السقوط في جميع النقاط الأخرى ، تنتظرنا مشاكل غير متوقعة. إذا حدث انخفاض عند النقطة (B) ، فعند إعادة تشغيل المعالج ، سنستعيد الحالة ونعيد تسجيل متوسط القيمة في نفس نطاق الأرقام تقريبًا. في حالة السقوط عند النقطة (C) بالإضافة إلى متوسط التكرار ، سيحدث تكرار في زيادة القيمة. وفي حالة حدوث انخفاض في (D) سنحصل على حالة غير متناسقة للمعالج: تتوافق الحالة مع لحظة جديدة في الوقت المناسب ، وسنقرأ القيم من تدفقات الإدخال القديمة.

في الوقت نفسه ، لن يتغير شيء جوهريًا عند إعادة ترتيب عمليات التسجيل: سيبقى عدم الاتساق والتكرار كذلك. وبالتالي ، نصل إلى استنتاج مفاده أن جميع الإجراءات لتغيير حالة المعالج في المستودع وقائمة انتظار الإخراج وقاعدة البيانات يجب أن يتم تنفيذها بالمعاملة ، أي كل شيء ذري في نفس الوقت.
وبناءً على ذلك ، من الضروري تطوير آلية حتى تتمكن المخازن المختلفة من تغيير حالتها ، وليس داخل كل منها بشكل مستقل ، ولكن معاملات بين جميع المخازن في وقت واحد. بالطبع ، يمكنك وضع التخزين داخل قاعدة بيانات خارجية ، ومع ذلك ، افترضت المهمة أن محرك قاعدة البيانات ومحرك إطار معالجة البيانات المتدفقة منفصلان ويعملان بشكل مستقل عن بعضهما البعض. هنا أريد أن أعتبر الحالة الأكثر صعوبة ، لأن الحالات البسيطة ليست مثيرة للاهتمام للنظر فيها.
الاستجابة التنافسية
فكر في التنفيذ التنافسي مرة واحدة بالضبط بمزيد من التفاصيل. في حالة وجود نظام يتحمل الأخطاء ، نحتاج إلى استمرار العمل من نقطة ما. من الواضح أن هذه النقطة ستكون نقطة في الماضي ، لأنه للحفاظ على الأداء ، من المستحيل تخزين جميع لحظات تغييرات الحالة في الحاضر والمستقبل: إما أن يتم حفظ النتيجة الأخيرة للعمليات أو مجموعة من القيم لزيادة الإنتاجية. يقودنا هذا السلوك على الفور إلى حقيقة أنه بعد استعادة حالة المعالج ، سيكون هناك بعض التأخير في النتائج ، وسوف تزداد مع زيادة حجم مجموعة القيم وحجم الحالة.
بالإضافة إلى هذا التأخير ، هناك أيضًا تأخيرات في النظام مرتبطة بتحميل الحالة إلى عقدة أخرى. بالإضافة إلى ذلك ، فإن اكتشاف عقدة مشكلة يستغرق أيضًا بعض الوقت ، وغالبًا ما يكون كثيرًا. هذا يرجع ، أولاً وقبل كل شيء ، إلى حقيقة أنه إذا حددنا وقتًا قصيرًا للكشف ، فإن الإنذارات الكاذبة المتكررة ممكنة ، مما سيؤدي إلى جميع أنواع التأثيرات الخاصة غير السارة.
بالإضافة إلى ذلك ، مع الزيادة في عدد المعالجات المتوازية ، اتضح فجأة أنه ليس كلهم يعملون بشكل جيد على قدم المساواة حتى في غياب الفشل. في بعض الأحيان تحدث التواءات ، مما يؤدي أيضًا إلى تأخيرات في المعالجة. يمكن أن يتنوع سبب هذه التباعد:
- البرنامج : توقف GC مؤقتًا ، وتجزئة الذاكرة ، وإيقاف مؤقت للمخصص ، وانقطاع kernel ، وجدولة المهام ، ومشكلات في برامج تشغيل الجهاز تتسبب في حدوث بطء.
- الأجهزة : تحميل عالي للقرص أو الشبكة ، اختناق وحدة المعالجة المركزية بسبب مشاكل التبريد ، التحميل الزائد ، إلخ ، تباطؤ القرص بسبب المشاكل التقنية.
وهذه ليست بأي حال قائمة حصرية بالمشكلات التي يمكن أن تبطئ المعالجات.
وبناء على ذلك ، فإن التباطؤ هو أمر يجب على المرء أن يعيش معه. في بعض الأحيان لا تكون هذه مشكلة خطيرة ، وأحيانًا يكون من المهم للغاية الحفاظ على سرعة معالجة عالية على الرغم من الفشل أو التباطؤ.
على الفور تنشأ فكرة ازدواجية الأنظمة: فلنركض لدفق واحد ونفس البيانات ليس معالجًا واحدًا بل معالجين في وقت واحد ، أو حتى ثلاثة. المشكلة هنا هي أنه في هذه الحالة ، يمكن أن يحدث سلوك النظام المكرر وغير المتناسق بسهولة. عادةً ، لم يتم تصميم أطر العمل لهذا السلوك وتشير إلى أن عدد المعالجات في أي وقت معين لا يتجاوز واحد. الأنظمة التي تسمح بالازدواجية الموصوفة للتنفيذ تسمى متزامنة مرة واحدة بالضبط .
تتيح لك هذه البنية حل العديد من المشاكل في وقت واحد:
- السلوك غير الآمن: إذا سقطت إحدى العقد ، تستمر الأخرى ببساطة في العمل كما لو لم يحدث شيء. ليست هناك حاجة لتنسيق إضافي ، مثل يتم تنفيذ المعالج الثاني بغض النظر عن حالة الأول.
- إزالة الصدمات: كل من قدم النتيجة جيدًا بالنسبة له. والآخر سيكون عليه فقط اختيار دولة جديدة والاستمرار من هذه اللحظة.
هذا النهج ، على وجه الخصوص ، يسمح لك بإكمال عملية حسابية صعبة وصعبة لفترة أطول يمكن التنبؤ بها ، لأنه احتمالية أن يصبح كلاهما غبيًا وسقوطًا أقل بشكل ملحوظ.
تقييم الاحتمالات
دعونا نحاول تقييم فوائد ازدواجية الأداء. افترض أن شيئًا ما يحدث في المتوسط كل يوم مع المعالج: إما أن يكون GC قد تضاءل ، أو أن العقدة تكذب ، أو أن الحاويات أصبحت سرطانية. افترض أيضًا أننا نقوم بإعداد حزم البيانات في 10 ثوانٍ.
ثم يكون احتمال حدوث شيء ما أثناء إنشاء العبوة هو 10 / (24 · 3600) ≃ 1e-4 .
إذا قمت بتشغيل معالجين بالتوازي ، فإن احتمال أن كلا ≃ 1e-8 هو ≃ 1e-8 . لذا سيأتي هذا الحدث في غضون 23 عامًا! نعم ، الأنظمة لا تعيش كثيرًا ، مما يعني أن هذا لن يحدث أبدًا!
علاوة على ذلك ، إذا كان وقت تحضير العبوة أقصر و / أو سيحدث انخفاض أقل في كثير من الأحيان ، فإن هذا الرقم سيزداد فقط.
وبالتالي ، نستنتج أن النهج قيد النظر يزيد بشكل كبير من موثوقية نظامنا بأكمله. يبقى فقط لحل سؤال صغير مثل هذا: أين تقرأ حول كيفية إنشاء نظام متزامن مرة واحدة بالضبط . والجواب بسيط: عليك أن تقرأ هنا.
نصف معاملة
لمزيد من المناقشة ، نحن بحاجة إلى مفهوم نصف الصفقة . أسهل طريقة لتفسير ذلك هي من خلال مثال.
فكر في تحويل الأموال من حساب مصرفي إلى آخر. يمكن وصف النهج التقليدي باستخدام المعاملات بلغة Pseco كما يلي:
transfer(from, to, amount): tx = db.begin_transaction() amount_from = tx.get(from) if amount_from < amount: return error.insufficient_funds tx.set(from, amount_from - amount) tx.set(to, tx.get(to) + amount) tx.commit() return ok
ولكن ماذا لو لم تكن هذه المعاملات متاحة لنا؟ باستخدام الأقفال ، يمكن القيام بذلك على النحو التالي:
transfer(from, to, amount): # lock_from = db.lock(from) lock_to = db.lock(to) amount_from = db.get(from) if amount_from < amount: return error.insufficient_funds db.set(from, amount_from - amount) db.set(to, db.get(to) + amount) return ok
هذا النهج يمكن أن يؤدي إلى طريق مسدود ، كما يمكن أخذ الأقفال بتسلسل مختلف بالتوازي. لتصحيح هذا السلوك ، يكفي تقديم وظيفة تأخذ في الوقت نفسه عدة أقفال في تسلسل حاسم (على سبيل المثال ، فرز حسب المفاتيح) ، مما يلغي تمامًا الجمود المحتمل.
ومع ذلك ، يمكن تبسيط التنفيذ إلى حد ما:
transfer(from, to, amount): lock_from = db.lock(from) amount_from = db.get(from) if amount_from < amount: return error.insufficient_funds db.set(from, amount_from - amount) lock_from.release() # , # .. db.set(db.get...) lock_to = db.lock(to) db.set(to, db.get(to) + amount) return ok
هذا النهج يجعل أيضًا الحالة النهائية متسقة ، مع الحفاظ على الثوابت بنوع منع الإنفاق المفرط للأموال. الفرق الرئيسي عن النهج السابق هو أنه في مثل هذا التنفيذ لدينا فترة زمنية معينة تكون فيها الحسابات في حالة غير متناسقة. وهي مثل هذه العملية تعني أن الحالة الإجمالية للأموال في الحسابات لا تتغير. في هذه الحالة ، هناك فجوة زمنية بين lock_from.release() و db.lock(to) ، قد تعطي قاعدة البيانات خلالها قيمة غير متناسقة: قد يختلف المبلغ الإجمالي عن المبلغ الصحيح إلى الأسفل.
في الواقع ، قمنا بتقسيم معاملة واحدة لتحويل الأموال إلى نصفين من المعاملات:
- تقوم النصف الأول من المعاملة بعمل شيك وخصم المبلغ الضروري من الحساب.
- النصف الثاني من المعاملة يكتب المبلغ المسحوب إلى حساب آخر.
من الواضح أن تقسيم المعاملة إلى معاملات أصغر ، بشكل عام ، ينتهك سلوك المعاملات. والمثال أعلاه ليس استثناء. ومع ذلك ، إذا تم تحقيق جميع المعاملات النصف في السلسلة بالكامل ، فستكون النتيجة متسقة مع جميع الثوابت المحفوظة. هذا هو بالضبط ما هو خاصية مهمة لسلسلة نصف المعاملات.
نفقد بعض الاتساق مؤقتًا ، ومع ذلك نكتسب ميزة أخرى مفيدة: استقلالية العمليات ، ونتيجة لذلك ، قابلية التوسع الأفضل. يتجلى الاستقلال في حقيقة أن نصف المعاملة في كل مرة تعمل مع سطر واحد فقط ، وهي قراءة بياناتها والتحقق منها وتغييرها ، دون الاتصال ببيانات أخرى. وبالتالي ، يمكنك خلط قاعدة بيانات تعمل مع جزء واحد فقط. علاوة على ذلك ، يمكن استخدام هذا النهج في حالة المستودعات غير المتجانسة ، أي يمكن أن تبدأ نصف المعاملات على نوع واحد من التخزين ، وتنتهي على نوع آخر. إنها خصائص مفيدة سيتم استخدامها في المستقبل.
يطرح سؤال شرعي: كيفية تطبيق نصف الغيبوبة في الأنظمة الموزعة وليس أشعل النار؟ لحل هذه المشكلة ، تحتاج إلى النظر في نهج عدم القفل.
بدون قفل
كما تعلم ، تعمل المناهج الخالية من القفل أحيانًا على تحسين أداء الأنظمة متعددة الخيوط ، خاصة في حالة الوصول التنافسي إلى المورد. ومع ذلك ، ليس من الواضح تمامًا أن مثل هذا النهج يمكن استخدامه في الأنظمة الموزعة. دعونا نتعمق بعمق وننظر في ما هو بدون قفل ولماذا ستكون هذه الخاصية مفيدة في حل مشكلتنا.
في بعض الأحيان لا يفهم بعض المطورين تمامًا ما هو قفل مجاني. تشير النظرة الضيقة إلى أن هذا أمر يتعلق بتعليمات المعالج الذري. من المهم أن نفهم هنا أن القفل الحر يعني استخدام "الذرات" ، والعكس غير صحيح ، أي ليس كل "الذرات" تعطي سلوكًا بدون قفل.
من الخصائص المهمة للخوارزمية الخالية من القفل هي أن مؤشر ترابط واحد على الأقل يحقق تقدمًا في النظام. ولكن لسبب ما ، يعزو الكثيرون هذه الخاصية إلى تعريف (هذا تعريف صريح يمكن العثور عليه ، على سبيل المثال ، على ويكيبيديا ). هنا من الضروري إضافة فارق بسيط واحد مهم: يتم إحراز تقدم حتى في حالة هشاشة موضوع واحد أو أكثر. هذه نقطة حرجة للغاية يتم تجاهلها غالبًا ولها آثار خطيرة على النظام الموزع.
لماذا ينفي غياب شرط التقدم لخيوط واحد على الأقل مفهوم الخوارزمية الخالية من القفل؟ والحقيقة هي أنه في هذه الحالة سيكون spinlock المعتاد أيضًا بدون قفل. في الواقع ، الشخص الذي أخذ القفل سيحرز تقدمًا. هل هناك خيط مع التقدم => بدون قفل؟
من الواضح أن الإقفال يعني بدون أقفال ، بينما يشير spinlock باسمه إلى أن هذا قفل حقيقي. هذا هو السبب في أنه من المهم إضافة شرط على التقدم حتى في حالة التصدعات. بعد كل شيء ، يمكن أن تستمر هذه التأخيرات إلى أجل غير مسمى ، لأنه لا يقول التعريف شيئًا عن الحد الزمني العلوي. وإذا كان الأمر كذلك ، فإن مثل هذه التأخيرات ستكون معادلة إلى حد ما لإيقاف التدفقات. في هذه الحالة ، ستنتج الخوارزميات الخالية من القفل تقدمًا في هذه الحالة.
ولكن من قال إن المقاربات الخالية من القفل تنطبق حصريًا على الأنظمة متعددة الخيوط؟ استبدال خيوط في نفس العملية على نفس العقدة مع العمليات على العقد المختلفة ، والذاكرة المشتركة للخيوط مع التخزين الموزع المشترك ، نحصل على خوارزمية موزعة بدون قفل.
انخفاض العقدة في مثل هذا النظام يعادل التأخير في تنفيذ مؤشر ترابط لبعض الوقت ، لأنه حان الوقت لاستعادة العمل. في الوقت نفسه ، يسمح نهج عدم القفل للمشاركين الآخرين في النظام الموزع بمواصلة العمل. علاوة على ذلك ، يمكن تشغيل خوارزميات خاصة خالية من القفل بالتوازي مع بعضها البعض ، للكشف عن تغيير تنافسي واستبعاد التكرارات.
يشير النهج الذي يتم استخدامه مرة واحدة بالضبط إلى وجود تخزين موزع متناسق. مثل هذه المخازن كقاعدة تمثل جدول قيمة رئيسية ثابتًا ضخمًا. العمليات المحتملة: set ، get ، del . ومع ذلك ، يلزم إجراء عملية أكثر تعقيدًا للنهج بدون قفل: CAS أو مقارنة ومبادلة. دعونا نفكر بمزيد من التفصيل في هذه العملية ، وإمكانيات استخدامها ، وكذلك النتائج التي تعطيها.
كاس
CAS أو مقارنة ومبادلة هي بدائية المزامنة الرئيسية والمهمة لخوارزميات بدون قفل وخالية من الانتظار. يمكن توضيح جوهره من خلال Pseco التالي:
CAS(var, expected, new): # , atomic, atomic: if var.get() != expected: return false var.set(new) return true
في بعض الأحيان ، من أجل التحسين ، لا يعودون true أو false ، ولكن القيمة السابقة ، لأن في كثير من الأحيان يتم تنفيذ هذه العمليات في حلقة ، وللحصول على القيمة expected ، يجب عليك أولاً قراءتها:
CAS_optimized(var, expected, new): # , atomic, atomic: current = var.get() if current == expected: var.set(new) return current # CAS CAS_optimized CAS(var, expected, new): return var.CAS_optimized(expected, new) == expected
يمكن أن يوفر هذا النهج قراءة واحدة. كجزء من مراجعتنا ، سنستخدم شكلًا بسيطًا من CAS ، لأنه إذا رغبت في ذلك ، يمكن إجراء هذا التحسين بشكل مستقل.
في حالة الأنظمة الموزعة ، يتم إصدار كل تغيير. على سبيل المثال أولاً نقرأ القيمة من المتجر ، نحصل على الإصدار الحالي من البيانات. ثم نحاول الكتابة ، متوقعين أن إصدار البيانات لم يتغير. في هذه الحالة ، تزداد النسخة في كل مرة يتم فيها تحديث البيانات:
CAS_versioned(var, expected_version, new): atomic: if var.get_version() != expected_version: return false var.set(new, expected_version + 1) return true
يسمح لك هذا النهج بالتحكم بشكل أكثر دقة في تحديث القيم ، وتجنب مشكلة ABA . على وجه الخصوص ، يدعم الإصدار Etcd و Zookeeper.
لاحظ الخاصية الهامة التي CAS_versioned استخدام عمليات CAS_versioned . والحقيقة هي أنه يمكن تكرار مثل هذه العملية دون المساس بالمنطق المتفوق. في البرمجة متعددة الخيوط ، هذه الخاصية ليس لها قيمة خاصة ، لأن هناك ، إذا فشلت العملية ، فنحن على يقين من أنها لم تنطبق. في حالة النظم الموزعة ، تم انتهاك هذا الثابت ، لأنه قد يصل الطلب إلى المستلم ، ولكن الاستجابة الناجحة لم تعد موجودة. لذلك ، من المهم أن تكون قادرًا على إعادة إرسال الطلبات دون خوف من كسر ثوابت المنطق رفيع المستوى.
هذه هي الخاصية التي CAS_versioned عملية CAS_versioned . في الواقع ، يمكن تكرار هذه العملية إلى ما لا نهاية حتى يتم إرجاع الاستجابة الحقيقية من المستلم. وهو بدوره يلقي فئة كاملة من الأخطاء المتعلقة بتفاعل الشبكة.
مثال
دعونا نلقي نظرة على كيفية CAS_versioned ونصف المعاملات ، من حساب إلى آخر ، والتي تنتمي ، على سبيل المثال ، إلى نسخ مختلفة من Etcd. هنا ، أفترض أن الدالة CAS_versioned قد تم تنفيذها وفقًا لذلك بناءً على واجهة برمجة التطبيقات المقدمة.
withdraw(from, amount): # CAS- while true: # version_from, amount_from = from.get_versioned() if amount_from < amount: return error.insufficient_funds if from.CAS_versioned(version_from, amount_from - amount): break return ok deposit(to, amount): # CAS- while true: version_to, amount_to = to.get_versioned() if to.CAS_versioned(version_to, amount_to + amount): break return ok transfer(from, to, amount): # if withdraw(from, amount) is ok: # , # deposit(to, amount)
قمنا هنا بتقسيم عمليتنا إلى نصف المعاملات ، وننفذ كل معاملة نصف من خلال عملية CAS_versioned . يسمح لك هذا النهج بالعمل بشكل مستقل مع كل حساب ، مما يسمح باستخدام التخزين غير المتجانسة غير المرتبط ببعضه البعض. المشكلة الوحيدة التي تنتظرنا هنا هي خسارة المال في حالة حدوث انخفاض في العملية الحالية في الفترة الفاصلة بين نصف المعاملات.
قائمة الانتظار
للمضي قدمًا ، تحتاج إلى تنفيذ قائمة انتظار الأحداث. تكمن الفكرة في أنه بالنسبة للمعالجين للتواصل مع بعضهم البعض ، يجب أن يكون لديك قائمة انتظار رسائل مرتبة لا يتم فيها فقد البيانات أو تكرارها. وبناءً على ذلك ، سيتم بناء جميع التفاعلات في سلسلة المعالجات على هذا البدائي. كما أنها أداة مفيدة لتحليل وتدقيق تدفقات البيانات الواردة والصادرة. بالإضافة إلى ذلك ، يمكن أيضًا إجراء طفرات في حالة المعالجات من خلال قائمة الانتظار.
ستتألف قائمة الانتظار من زوج من العمليات:
- أضف رسالة إلى نهاية قائمة الانتظار.
- استقبال رسالة من الصف في الفهرس المحدد.
في هذا السياق ، لا أفكر في إزالة الرسائل من قائمة الانتظار لعدة أسباب:
- يمكن لعدة معالجات القراءة من قائمة الانتظار نفسها. ستكون إزالة التزامن مهمة غير تافهة ، على الرغم من أنها ليست مستحيلة.
- من المفيد الاحتفاظ بقائمة انتظار لفترة طويلة نسبيًا (يوم أو أسبوع) لتصحيح الأخطاء والتدقيق. من الصعب المبالغة في فائدة هذه الخاصية.
- يمكنك حذف العناصر القديمة إما في الموعد المحدد أو عن طريق تعيين TTL على عناصر قائمة الانتظار. من المهم التأكد من أن المعالجات تمكنت من معالجة البيانات قبل وصول المكنسة وتنظيف كل شيء. إذا كان وقت المعالجة بترتيب الثواني ، و TTL لترتيب الأيام ، فيجب ألا يحدث أي شيء من هذا.
لتخزين العناصر وتنفيذ الإضافة بشكل فعال ، نحتاج إلى:
- القيمة مع الفهرس الحالي. يشير هذا الفهرس إلى نهاية قائمة الانتظار لإضافة عناصر.
- , .
lock-free
: . :
- CAS .
- .
, , .
- lock-free . , , . Lock-free? ! , 2 : . lock-free, — ! , , , . . , .. , .
- . , . .
, lock-free .
Lock-free
, , : , .. , :
push(queue, value): # index = queue.get_current_index() while true: # , # var = queue.at(index) # = 0 , .. # , if var.CAS_versioned(0, value): # , queue.update_index(index + 1) break # , . index = max(queue.get_current_index(), index + 1) update_index(queue, index): while true: # cur_index, version = queue.get_current_index_versioned() # , # , . if cur_index >= index: # - , # break if queue.current_index_var().CAS_versioned(version, index): # , break # - . # , ,
. , ( — , , ). lock-free . ?
, push , ! , , .
. : . , - , - . , , .. . . ? , .. , , .
, , . .. . , , . , .
, . , . , , . , .
, , , .
. .
, :
- , .. stateless.
- , — .
, , concurrent exactly-once .
:
handle(input, output): index = 0 while true: value = input.get(index) output.push(value) index += 1
. :
handle(input, output, state): # index = state.get() while true: value = input.get(index) output.push(value) index += 1 # state.set(index)
exactly-once . , , , .
exactly-once , , . .., , , , , — :
# get_next_index(queue): index = queue.get_index() # while queue.has(index): # queue.push index = max(index + 1, queue.get_index()) return index # . # true push_at(queue, value, index): var = queue.at(index) if var.CAS_versioned(0, value): # queue.update_index(index + 1) return true return false handle(input, output, state): # # {PREPARING, 0} fsm_state = state.get() while true: switch fsm_state: case {PREPARING, input_index}: # : , # output_index = output.get_next_index() fsm_state = {WRITING, input_index, output_index} case {WRITING, input_index, output_index}: value = input.get(input_index) if output.push_at(value, output_index): # , input_index += 1 # , push_at false, # fsm_state = {PREPARING, input_index} state.set(fsm_state)
push_at ? , . , , , . , . . - , lock-free .
, :
- : .
- , : .
: concurrent exactly-once .
? :
- , ,
push_at false. . - , . , , .
concurrent exactly-once ? , , . , . .
:
# , , # .. true, # true. # false push_at_idempotent(queue, value, index): return queue.push_at(value, index) or queue.get(index) == value handle(input, output, state): version, fsm_state = state.get_versioned() while true: switch fsm_state: case {PREPARING, input_index}: # , , # output_index = output.get_next_index() fsm_state = {WRITING, input_index, output_index} case {WRITING, input_index, output_index}: value = input.get(input_index) # , # if output.push_at_idempotent(value, output_index): input_index += 1 fsm_state = {PREPARING, input_index} # if state.CAS_versioned(version, fsm_state): version += 1 else: # , version, fsm_state = state.get_versioned()
:

, . , .
kernel panic, , .. . . : , . , .
, , .
: .
: , , , , :
# : # - input_queues - # - output_queues - # - state - # - handler - : state, inputs -> state, outputs handle(input_queues, output_queues, state, handler): # version, fsm_state = state.get_versioned() while true: switch fsm_state: # input_indexes case {HANDLING, user_state, input_indexes}: # inputs = [queue.get(index) for queue, index in zip(input_queues, input_indexes)] # , next_indexes = next(inputs, input_indexes) # # user_state, outputs = handler(user_state, inputs) # , # fsm_state = {PREPARING, user_state, next_indexes, outputs, 0} case {PREPARING, user_state, input_indexes, outputs, output_pos}: # , # output_index = output_queues[output_pos].get_next_index() # fsm_state = { WRITING, user_state, input_indexes, outputs, output_pos, output_index } case { WRITING, user_state, input_indexes, outputs, output_pos, output_index }: value = outputs[output_pos] # if output_queues[output_pos].push_at_idempotent( value, output_index ): # , output_pos += 1 # , PREPARING. # # fsm_state = if output_pos == len(outputs): # , # {HANDLING, user_state, input_indexes} else: # # , # {PREPARING, user_state, input_indexes, outputs, output_pos} if state.CAS_versioned(version, fsm_state): version += 1 else: # , version, fsm_state = state.get_versioned()
:

: HANDLING . , .., , . , . , PREPARING WRITING , . , HANDLING .
, , , . , . , .
. . .

:
my_handler(state, inputs): # state.queue.push(inputs) # duration state.queue.trim_time_window(duration) # avg = state.queue.avg() need_update_counter = state.queue.size() > size_boundary return state, [ avg, if need_update_counter: true else: # none none ]
, , concurrent exactly-once handle .
:
handle_db(input_queue, db): while true: # tx = db.begin_transaction() # . # , # index = tx.get_current_index() # tx.write_current_index(index + 1) # value = intput_queue.get(index) if value: # tx.increment_counter() tx.commit() # , , #
. لأن , , , , concurrent exactly-once . .
— . , , .
, , . , , .
. , . لأن , . . .
— . , , . , - , , . , .. , , .
. , , . , , .
. , . : , . , .
, , :
- , . .
- . , .
- . , . , , . .. . : .
, , -, , -, .
, . :
transfer(from, to, amount): # if withdraw(from, amount) is ok: # , # deposit(to, amount)
withdraw , , deposit : ? deposit - (, , ), . , , , , ? , , - , .
, , , . , , , . , . , , . لأن , , . , : , — .
, .
: , , , , . , - :
, , .
, , .. , , . , .
: lock-free , . , .. , .
CAS . , :
# , handle(input, output, state): # ... while true: switch fsm_state: case {HANDLING, ...}: # fsm_state = {PREPARING, ...} case {PREPARING, input_index}: # ... output_index = ...get_next_index() fsm_state = {WRITING, output_index, ...} case {WRITING, output_index, ...}: # , output_index
, . . :
- PREPARING . , .
- WRITING . . , PREPARING .
, . , , — . :
- . , , .. , .
- , .. . , .
, lock-free , , .
, . , Stale Read , . — CAS: . :
- Distributed single register — (, etcd Zookeeper):
- Linearizability
- Sequential consistency
- Transactional — (, MySQL, PostgreSQL ..):
- Serializability
- Snapshot Isolation
- Repeatable Read
- Read Committed
- Distributed Transactional — NewSQL :
- Strict Consistency
: ? , , . , , CAS . , , Read My Writes .
الخلاصة
exactly-once . , .. , , , . , , , , .. , .
lock-free .
:
- : .
- : .
- : : exactly-once .
- Concurrent : .
- Real-time : .
- Lock-free : , .
- Deadlock free : , .
- Race condition free : .
- Hot-hot : .
- Hard stop : .
- No failover : .
- No downtime : .
- : , .
- : .
- : .
- : .
, . لكن هذه قصة أخرى.

:
- Concurrent exactly-once.
- Semi-transactions .
- Lock-free two-phase commit, .
- .
- lock-free .
- .
الأدب
[1] : ABA.
[2] Blog: You Cannot Have Exactly-Once Delivery
[3] : .
[4] : 3: .
[5] : .