مرحباً هابر. أود اليوم أن أطور موضوع
التحسين المتغير وأخبره عن كيفية تطبيقه على مهمة تشذيب القنوات غير المعلوماتية في الشبكات العصبية (التقليم). باستخدامه ، يمكن للمرء بسهولة زيادة "معدل إطلاق النار" للشبكة العصبية دون تجريف بنيتها.
إن فكرة تقليل العناصر الزائدة في خوارزميات التعلم الآلي ليست جديدة على الإطلاق. في الواقع ، هو أقدم من مفهوم التعلم العميق: في وقت سابق فقط تم قطع فروع الأشجار الحاسمة ، والآن الأوزان في شبكة عصبية.
الفكرة الأساسية بسيطة: نجد في الشبكة مجموعة فرعية من الأوزان عديمة الفائدة وصفرها. بدون بحث شامل ، من الصعب تحديد أي الأوزان تشارك حقًا في التنبؤ ، وأيها يتظاهر فقط ، ولكن هذا ليس مطلوبًا. طرق تسوية مختلفة ، تلف الدماغ الأمثل والخوارزميات الأخرى تعمل بشكل جيد. لماذا إزالة أي أوزان على الإطلاق؟ اتضح أن هذا يحسن القدرة العامة على الشبكة: كقاعدة عامة ، فإن الأوزان غير المهمة إما تضيف ضوضاء إلى التوقع ، أو يتم شحذها بشكل خاص لعلامات مجموعة بيانات التدريب (أي قطعة أثرية لإعادة التدريب). بهذا المعنى ، يمكن مقارنة انخفاض الاتصالات مع طريقة فصل الخلايا العصبية العشوائية (التسرب) أثناء التدريب على الشبكة. بالإضافة إلى ذلك ، إذا كانت الشبكة تحتوي على العديد من الأصفار ، فإنها تشغل مساحة أقل في الأرشيف وتكون قادرة على القراءة بشكل أسرع في بعض البنى.
يبدو جيدًا ، ولكن من المثير جدًا التخلص من الأوزان غير المنفصلة ، ولكن الخلايا العصبية من طبقات أو قنوات متصلة بالكامل من الحزم بأكملها. في هذه الحالة ، لوحظ تأثير ضغط الشبكة وتسريع التنبؤات بشكل أكثر وضوحًا. ولكن هذا أكثر تعقيدًا من تدمير الأوزان الفردية: إذا حاولت تنفيذ تلف الدماغ الأمثل ، مع أخذ الحزمة بأكملها بدلاً من اتصال واحد ، فمن المرجح أن تكون النتائج غير مثيرة للإعجاب. من أجل أن تكون قادرًا على إزالة الخلايا العصبية بشكل غير مؤلم ، من الضروري جعلها بحيث لا يكون لها اتصال مفيد واحد. للقيام بذلك ، تحتاج إلى حث الخلايا العصبية "القوية" إلى حد ما لتصبح أقوى ، وأخرى "ضعيفة" لتصبح أضعف. هذه المهمة مألوفة لنا بالفعل: في الواقع ، نحن نجبر الشبكة على إحداث ندرة مع بعض القيود على تجميع الأوزان.
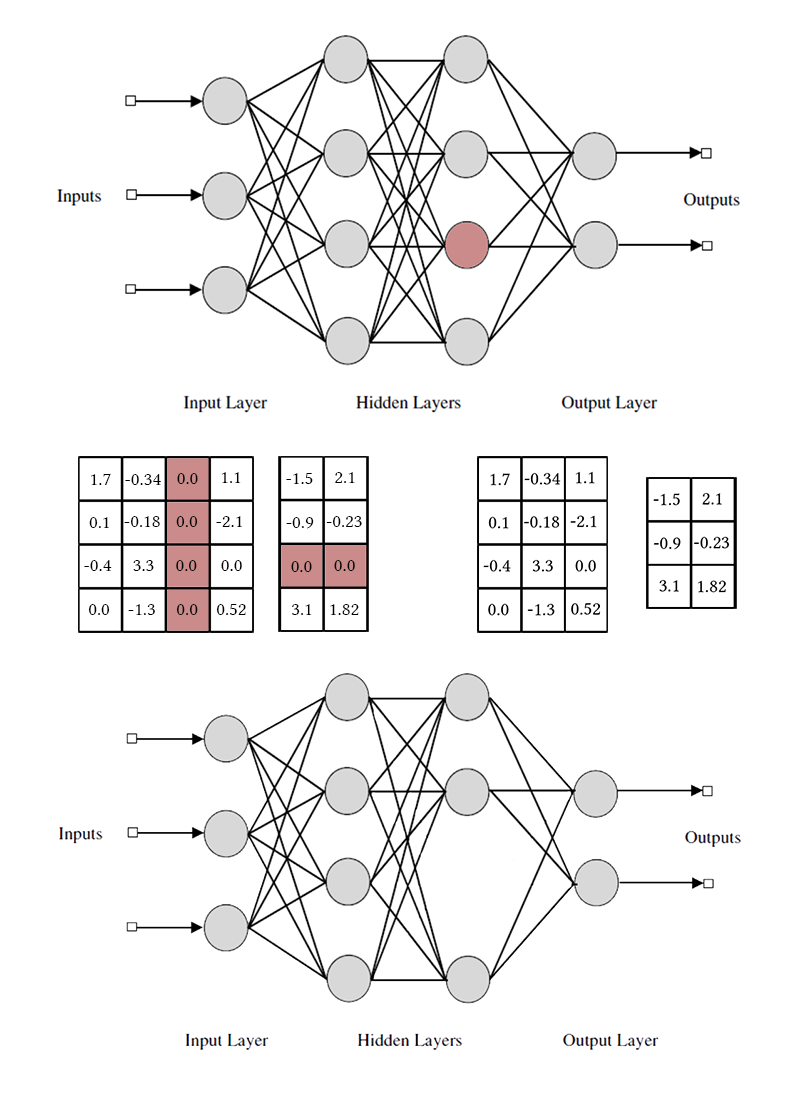
لاحظ أنه لإزالة قناة عصبية أو تلافيفية واحدة ، تحتاج إلى تعديل مصفوفتين للأوزان. لن أميز بين القنوات التلافيفية والخلايا العصبية: العمل معهم هو نفسه ، فقط الأوزان المحددة التي تمت إزالتها وطريقة التبديل تختلف.
الطريقة السهلة: تسوية المجموعة L1
للبدء ، سأخبرك عن الطريقة الأكثر بساطة وفعالية لإزالة الخلايا العصبية الزائدة من الشبكة - مجموعة LASSO - تسوية. في أغلب الأحيان يتم استخدامه للحفاظ على الأوزان غير المفيدة في الشبكات القريبة من الصفر ؛ يعمم بشكل تافه على كل حالة على حدة. على عكس التسوية المنتظمة ، نحن لا نقوم بتنظيم الوزن أو تنشيط الطبقة مباشرة ، الفكرة أصعب قليلاً. [تشذيب القناة لتسريع الشبكات العصبية العميقة ؛ Yihui He وآخرون ؛ 2017]
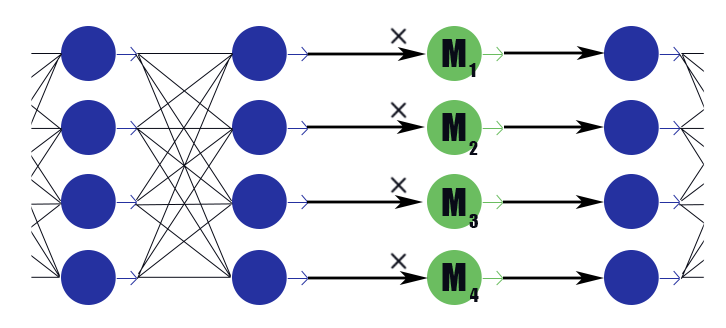
ضع في اعتبارك طبقة قناع خاصة مع متجه الوزن
M=( beta1، beta2، dots، betan) . استنتاجه هو مجرد عمل مجزأ
M إلى استنتاجات الطبقة السابقة ، ليس لديه وظيفة تفعيل. نضع في طبقة التقنيع بعد كل طبقة ، القنوات التي نريد التخلص منها ، ونخضع الأوزان في هذه الطبقات إلى تسوية L1. وبالتالي وزن القناع
betai مضروبًا في ناتج إيث للطبقة يفرض ضمنيًا تقييدًا على جميع الأوزان التي يعتمد عليها هذا الاستنتاج. إذا كان من بين هذه الأوزان ، قل نصف مفيد ، ثم
betai ستبقى أقرب إلى الوحدة ، وستكون هذه النتيجة قادرة على نقل المعلومات بشكل جيد. ولكن إذا كان واحد أو لا شيء على الإطلاق ،
betai ستنخفض إلى الصفر ، مما سيعيد ضبط خرج العصبون ، وفي الواقع ، سيعيد ضبط جميع الأوزان التي يعتمد عليها هذا الاستنتاج (في حالة وظيفة التنشيط تساوي صفر عند الصفر). يرجى ملاحظة أنه بهذه الطريقة تتلقى الشبكة تعزيزات أقل سلبية في حالة وجود وزن كبير من الناحية القانونية ، أو استجابة قوية من الناحية القانونية. فائدة الخلايا العصبية ككل مهمة.
اتضح هذه الصيغة:
أين
lambda - ثابت ترجيح شبكة المفقودة وتناقص الخسارة. يبدو أن الصيغة المعتادة L1- تسوية ، المصطلح الثاني فقط يحتوي على ناقلات طبقات اخفاء ، وليس وزن الشبكة.
بعد تدريب الشبكة ، ننتقل إلى الخلايا العصبية وقيمها المقنعة. إذا
betai أكثر من عتبة معينة ، ثم ضرب الأوزان العصبية
betai إذا كانت أقل ، يتم إزالة العناصر المقابلة للخلايا العصبية من مصفوفات الأوزان الواردة والصادرة (كما في الصورة أعلى قليلاً). بعد ذلك ، يمكن إسقاط الأقنعة وإكمال الشبكة.
في تطبيق مجموعة LASSO هناك عدة خفايا:
- تسوية طبيعية. إلى جانب تسوية أوزان القناع ، يجب تطبيق تسوية L1 / L2 على جميع أوزان الشبكة الأخرى. بدون هذا ، سيتم تعويض انخفاض وزن الإخفاء في حالة وظائف التنشيط غير المشبعة (ReLu ، ELu) بسهولة عن طريق زيادة الأوزان ، ولن يعمل تأثير الإبطال. نعم ، وبالنسبة إلى السيني العادي ، يسمح لك ذلك ببدء العملية بشكل أفضل بتعليقات إيجابية: Mi يصبح المخرج غير المعلوماتي أصغر ، ولهذا السبب يجب على المحسن أن يفكر بقوة أكبر في كل وزن معين ، مما يجعل الناتج أكثر إفادة ، ولهذا السبب Mi يقلل أكثر من ذلك وهلم جرا.
- ينصح مؤلفو المقالة أيضًا بفرض قيود كروية على وزن الطبقات |Wi|2=1 . من المحتمل أن يساهم هذا في "تدفق" التوازن من الخلايا العصبية الضعيفة إلى القوية ، لكني لم ألاحظ اختلافًا كبيرًا.
- تدريب الدفع والسحب. يقترح مؤلفو المقالة بالتناوب تدريب الأوزان العادية للشبكة العصبية وإخفاء الأوزان. إنها أطول من تعليم كل شيء في كل مرة ، ولكن كما لو كانت النتائج أفضل قليلاً؟
- لا تنسى الضبط الدقيق الطويل للشبكة (الضبط الدقيق) بعد إصلاح القناع ، فهذا مهم جدًا.
- راقب بعناية أقنعةك: قبل أو بعد وظيفة التنشيط. قد تواجه مشكلات في التنشيطات التي لا تساوي الصفر عندما تكون الوسيطة صفرًا (على سبيل المثال ، سيني).
- التقليم ليس وديًا مع batchnorm لنفس السبب الذي يجعل التسرب غير ودي معه: من وجهة نظر التطبيع ، عندما يكون هناك 32 قيمة في الحزمة 32 منها 12 صفراً ، وعندما تكون 20 قيمة في الحزمة مواقف مختلفة جدًا. بعد تمزيق الرصيد الصفري ، يتوقف التوزيع الذي تعلمته طبقة batchnorm عن كونه صالحًا. تحتاج إما إلى إدراج طبقات التقليم بعد كل طبقات batchnorm ، أو تعديل الطبقة الأخيرة بطريقة أو بأخرى.
- هناك أيضًا صعوبات في تطبيق تخفيض القناة على معماريات التفرع والشبكات المتبقية (ResNet). بعد تقليم الخلايا العصبية الإضافية أثناء دمج الفروع ، قد لا تتطابق الأبعاد. يتم حل هذا بسهولة عن طريق إدخال طبقات عازلة ، حيث لا نرفض الخلايا العصبية. بالإضافة إلى ذلك ، إذا كانت فروع الشبكة تحمل قدرًا مختلفًا من المعلومات ، فمن المنطقي أن تقوم بتعيين بيانات مختلفة lambda حتى لا يتضح أن التقليم قطع جميع الخلايا العصبية في الفرع الأقل إفادة. ومع ذلك ، إذا تم قطع جميع الخلايا العصبية ، فهل هذا الفرع ليس بهذه الأهمية؟
- في البيان الأصلي للمشكلة ، هناك قيود صارمة على عدد القنوات غير الصفرية ، ولكن في رأيي يكفي فقط تغيير معلمات الوزن للخسارة الأولية وفقدان L1 لأوزان القناع ، ثم السماح للمحسن بتحديد عدد القنوات التي يجب أن يغادرها.
- أقنعة التقاط. هذا ليس في المقالة الأصلية ، ولكن في رأيي ، هذه آلية عملية جيدة لتحسين التقارب. عندما تصل قيمة القناع إلى قيمة منخفضة محددة مسبقًا ، نعيد ضبطه ونمنع تغيير هذا الجزء من القناع. وبالتالي ، تتوقف الأوزان الضعيفة تمامًا عن المساهمة في التنبؤ بالفعل أثناء تدريب النموذج ، ولا تدخل أي قيم طائشة في الكميات المقابلة. من الناحية النظرية ، قد يمنع هذا قناة يمكن أن تكون مفيدة من العودة إلى الخدمة ، ولكن لا أعتقد أن هذا يحدث عمليًا.
الطريق الصعب: تسوية L0
لكننا لا نبحث عن طرق سهلة ، أليس كذلك؟
رفض القناة باستخدام تسوية L1 ليس عادلاً تمامًا. يسمح للقناة بالتحرك على نطاق "استجابة قوية" - "استجابة ضعيفة" - "استجابة صفر". فقط عندما يكون وزن القناع قريبًا بما يكفي من الصفر ، نتجاهل القناة باستخدام قناع الالتقاط. تشوه هذه الحركة الصورة بشكل كبير وتُجري تغييرات على القنوات الأخرى أثناء التدريب: قبل أن يتمكنوا من معرفة ما يجب فعله عندما يتم فصل العصبون السابق تمامًا ، يجب أن يتعلموا ما يجب فعله عندما يعطي استجابة ضعيفة بشكل منهجي.
دعني أذكرك بأنه ، من الناحية المثالية ، نود أن نختار بفارغ الصبر القناة الأقل إفادة من الشبكة ، والاستمرار في تعلم الشبكة بدونها ، وحذف القناة التالية الأقل إفادة ، وضبط الشبكة مرة أخرى ، وما إلى ذلك. للأسف ، في مثل هذه الصيغة ، فإن المهمة لا تحتمل حسابيا حتى بالنسبة للشبكات البسيطة نسبيا. علاوة على ذلك ، لا يترك هذا النهج القنوات فرصة ثانية - بمجرد أن لا يتمكن العصبون البعيد من العودة إلى العمل مرة أخرى. دعنا نغير المهمة قليلاً: سنزيل العصبون أحيانًا ، ونتركه أحيانًا. علاوة على ذلك ، إذا كان العصبون ككل مفيدًا ، فإنه غالبًا ما يترك ، ولكن إذا كان عديم الفائدة - والعكس صحيح. لهذا ، سوف نستخدم نفس طبقات الإخفاء كما هو الحال في حالة L1 - تسوية (لم يكن من دون سبب تم إدخالها!). فقط أوزانهم لن تتحرك على طول المحور الحقيقي بأكمله مع الجاذب عند الصفر ، ولكن سيتم تركيزه حول 0 و 1. ليس أنه أصبح أبسط بكثير ، ولكن على الأقل حل مشكلة الإزالة القاطعة للخلايا العصبية.
تقترح غريزة مدرب الشبكة أنه لا يستحق حل المشكلة عن طريق البحث الشامل ، ولكنك تحتاج إلى إضافة عدد الخلايا العصبية النشطة في الطبقات في التشغيل الحالي إلى وظيفة الخسارة. ومع ذلك ، فإن مثل هذا المصطلح في الخسارة سيكون ثابتًا بشكل تدريجي ، ولا يمكن أن يعمل أصل التدرج معه. من الضروري تعليم خوارزمية التعلم بطريقة أو بأخرى لاستبعاد بعض الخلايا العصبية بشكل دوري ، على الرغم من عدم وجود تدرج.
لدينا طريقة لإزالة الخلايا العصبية مؤقتًا: يمكننا تطبيق التسرب على طبقة القناع. دع أثناء التدريب
betai=1 مع الاحتمال
pi و
betai=0 مع الاحتمال
1− pi . الآن في دالة الخسارة يمكنك وضع المبلغ
pi وهو رقم حقيقي. هنا نواجه عقبة أخرى: التوزيع منفصل ، ليس من الواضح كيف يعمل الانتشار العكسي معه. بشكل عام ، هناك خوارزميات تحسين خاصة يمكن أن تساعدنا هنا (انظر REINFORCE) ، لكننا سنتخذ نهجًا مختلفًا.
ثم جاءت اللحظة التي تدخل فيها
التحسينات المتغيرة : يمكننا تقريب التوزيع المنفصل للأصفار والأصفار في طبقة التقنيع بواسطة واحد مستمر وتحسين معلمات الأخير باستخدام خوارزمية الانتشار العكسي المعتادة. هذه هي الفكرة وراء العمل [Learning Sparse Neural Networks through L0 Regularization؛ كريستوس لويزوس وآخرون ؛ 2017].
سيتم لعب دور التوزيع المستمر عن طريق توزيع الخرسانة الصلبة [التوزيع الخرساني: الاسترخاء المستمر للمتغيرات العشوائية المنفصلة ؛ كريس ماديسون 2017] ، هنا شيء صعب من اللوغاريتمات التي تقارب توزيع برنولي:
alpha - توزيع التخالف بالنسبة للمركز
بيتا - درجة الحرارة. في
beta rightarrow0 يبدأ التوزيع أكثر فأكثر لتقريب توزيع برنولي الحقيقي ، لكنه يفقد تمايزه. في
0< بيتا<1 كثافة التوزيع مقعرة (هذه هي الحالة التي نهتم بها) ، لـ
بيتا>1 - محدب. نمر هذا التوزيع من خلال السيني الصلب بحيث يمكن أن يعطي بمهارة احتمال محدود غير صفري
z=0 و
z=1 ، وعلى الفاصل الزمني (0 ، 1) كان له كثافة مختلفة قابلة للتمييز. بعد الانتهاء من التقليم ، ننظر في الاتجاه الذي تحول فيه التوزيع ونستبدل المتغير العشوائي
z إلى قيمة قناع معينة
بيتا ونأتي إلى الشرط نموذج قطعي بالفعل.
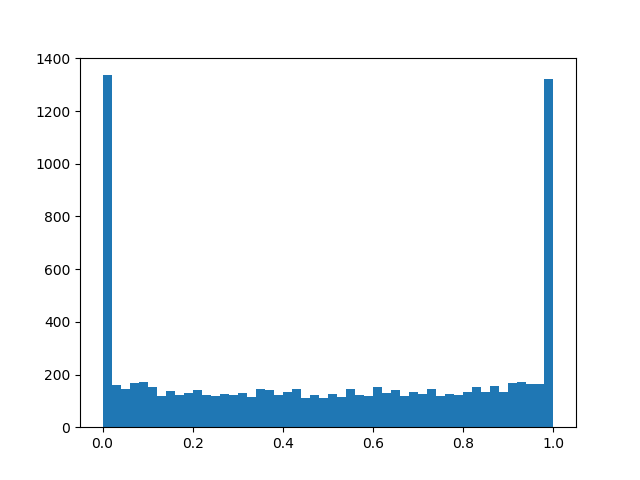
للشعور بتوزيع أفضل قليلاً ، سأقدم بعض الأمثلة على كثافته لمعايير مختلفة:
كثافة التوزيع a l p h a = 0.0 ، b e t a = 0.8 :
 a l p h a = 1.0 ، ب ي ت ا = 0.8 د و ل ا
a l p h a = 1.0 ، ب ي ت ا = 0.8 د و ل ا :
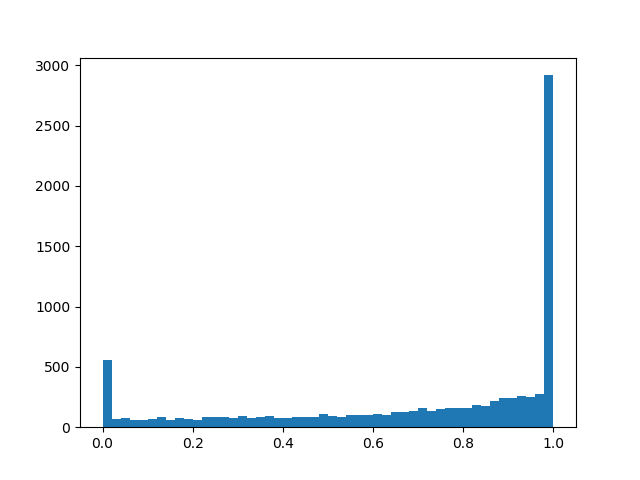 alpha=2.0، beta=0.8
alpha=2.0، beta=0.8 :
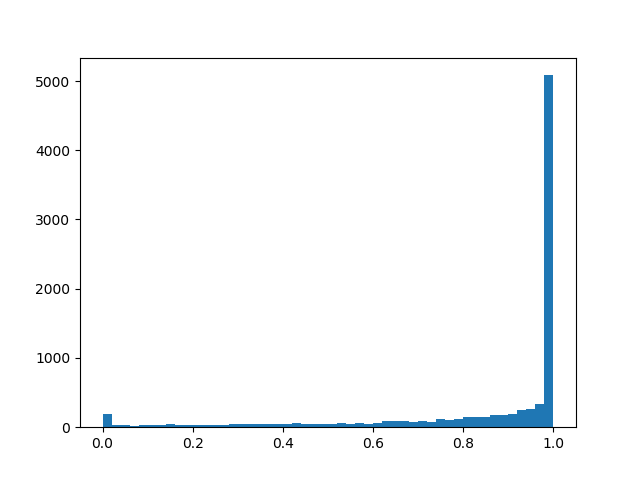 alpha=0.0، beta=0.5
alpha=0.0، beta=0.5 :
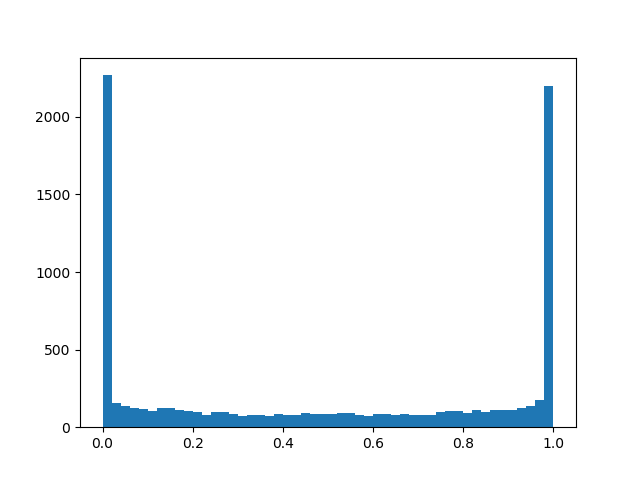 alpha=1.0، بيتا=0.5
alpha=1.0، بيتا=0.5 :
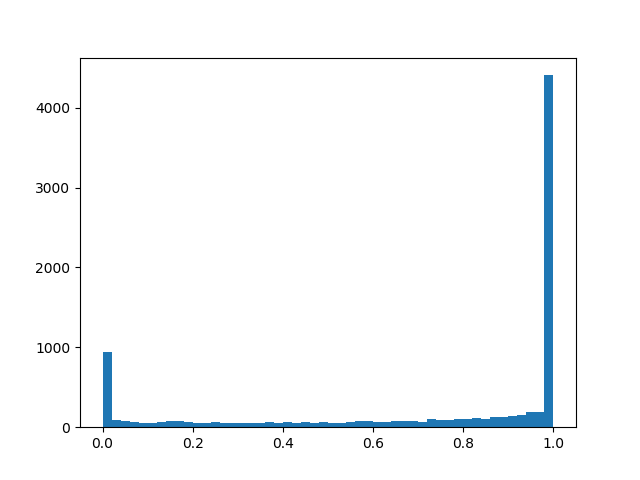 alpha=2.0، beta=0.5
alpha=2.0، beta=0.5 :
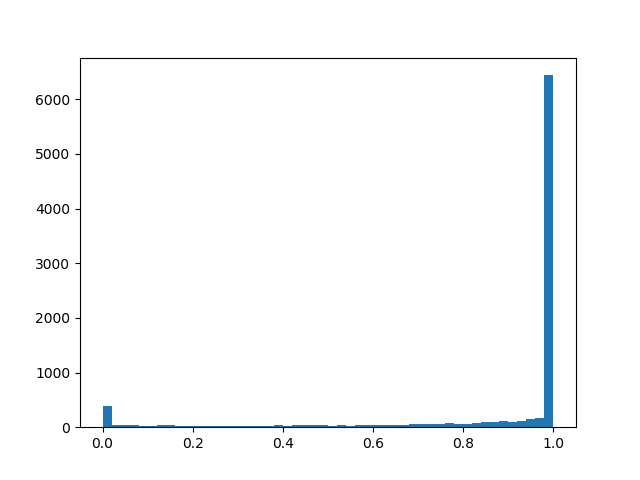 alpha=2.0، beta=0.1
alpha=2.0، beta=0.1 :
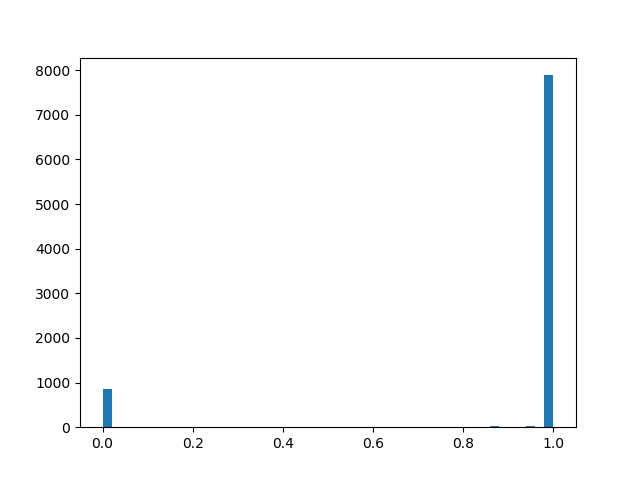 alpha=2.0، beta=2.0
alpha=2.0، beta=2.0 :
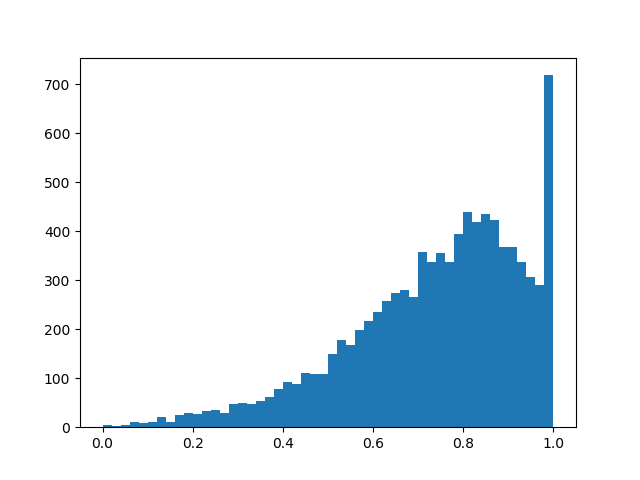
في الجوهر ، لدينا طبقة تسرب "ذكية" تتعرف على الاستنتاجات التي يجب التخلص منها في كثير من الأحيان. ولكن ما الذي نقوم بتحسينه بالضبط؟ في حالة الخسارة ، يجب عليك وضع تكامل كثافة التوزيع في منطقة غير صفرية (احتمال أن يتحول القناع إلى غير صفري أثناء التدريب ، ببساطة):
تمت إضافة الميزات التالية إلى تدريب الدفع والسحب ، والتسوية المنتظمة ، وتفاصيل التنفيذ الأخرى المذكورة في الفصل الخاص بتسوية L1:
- مرة أخرى: طبقة التسرب "الذكية" الخاصة بنا مع بعض الاحتمالية الملحوظة تعيد تعيين الناتج ، مع البعض - تتركه كما هو ، بالإضافة إلى أن هناك فرصة صغيرة اعتمادًا على betaو xiو gamma أن الناتج سوف يتم ضربه برقم عشوائي من 0 إلى 1. الجزء الأخير هو أكثر طفيلية من مفيد لهدفنا النهائي ، ولكن بدونه بأي شكل من الأشكال - فهو ضروري لعودة backpropagation'a.
- بشكل عام و alpha و بيتا - معلمات التدريب ، لكن في تجاربي شعرت أنه إذا طلبت فقط القليل بيتا (0.05) وفي عملية التعلم لا يزال يتم تقليلها بشكل خطي ، تتقارب الخوارزمية بشكل أفضل مما لو كنت تتعلمها بصدق. alpha من الأفضل ضبط الحجم الكافي l o g a l p h a ت ق ر ي ب ا 2.5 بحيث يتم الحفاظ على الخلايا العصبية في البداية في كثير من الأحيان أكثر من التخلص منها ، ولكنها ليست كبيرة بما يكفي لإشباع السيني في الفقدان.
- إذا تم استبدالها في الصيغ l o g a l p h a فقط و ل ص ح ل كما لو كانت الشبكة تتقارب بشكل أفضل وأقل احتمالية أن تصادف NaN أثناء التدريب. مع هذه المناورة ، يجب ألا ينسى المرء تغيير المصطلح في دالة الخسارة والتهيئة.
- أيضا ، إذا قمت بالغش واستبدال السيني المعتاد في الخسارة بأخرى جامدة مع قيود على l o g a l p h a i n [ - 4 ، 4 ] ، فإن التقوية سوف تتقارب وتعمل بشكل أفضل.
- إلى و ل ص ح ل و ب ي ت ا يمكنك أيضًا تطبيق التسوية لزيادة التفرقة.
- بعد التدريب ، يجب عليك تنقيط النتائج وتدريب الشبكة باستمرار باستخدام القناع المحدد حتى تصل دقة فال إلى الثابت. تقدم المقالة صيغة أكثر دقة يمكن من خلالها جعل ناتج الخلايا العصبية حتمية أثناء التحقق من الصحة أو لإطلاق شبكة في الإصدار ، ولكن يبدو أنه بحلول نهاية التدريب و ل ص ح ل اتضح أنه مستقطب بما يكفي ليعمل استدلال بسيط: a l p h a < 0 - قناع 0 ، a l p h a g e q 0 - القناع 1 (ولكن هذا ليس دقيقاً). بعد الانتقال إلى الأقنعة القطعية ، سترى قفزة في الجودة. لا تنس أننا وصلنا إلى هنا بأوزان صفر ، وتحت عتبة معينة للوزن ، ما زلت بحاجة إلى استبدال أوزان إخفاء بأصفار.
- بالإضافة إلى نهج L0 - تبدأ طبقات الإخفاء في العمل مثل التسرب ، مما يجلب تأثير تنظيم قوي على الشبكة. لكن هذا سيف ذو حدين: إذا بدأت التدريب بقليل جدًا و ل ص ح ل هناك خطر تدمير بنية الشبكة المدربة مسبقًا.
التجارب
للتجربة ، خذ مجموعة بيانات CIFAR-10 وشبكة بسيطة نسبيًا من أربع طبقات تلافيفية ، متبوعة بطبقتين متصلتين بالكامل: Conv2D ، Mask ، Conv2D ، Mask ، Pool2D ، Conv2D ، Mask ، Conv2D ، Mask ، Pool2D ، Flatten ، Dropout (p = 0.5) ، كثيف ، قناع ، كثيف (لوجتس). يُعتقد أن خوارزميات التقليم تعمل بشكل أفضل على الشبكات الأكثر سمكًا ، ولكني صادفت هنا مشكلة فنية بحتة تتمثل في نقص القدرة الحاسوبية. كمحسن ، تم استخدام Adam بمعدل تعلم = 0.0015 وحجم الدفعة = 32. بالإضافة إلى ذلك ، تم استخدام تسوية L1 (0.00005) و L2 (0.00025) المعتادة. لم يتم تطبيق تكبير الصورة. تم تدريب الشبكة على 200 حقبة قبل التقارب ، وبعد ذلك تم حفظها ، وتم تطبيق خوارزميات اختزال الخلايا العصبية عليها.
بالإضافة إلى تطبيق الخوارزميات الموضحة أعلاه للتقليم ، قمنا بتعيين نقطة مرجعية تافهة للتأكد من أن الخوارزميات تفعل شيئًا على الإطلاق. دعونا نحاول التخلص من الطبقة الأولى من كل طبقة
ك الخلايا العصبية وتنتهي الشبكة الناتجة.
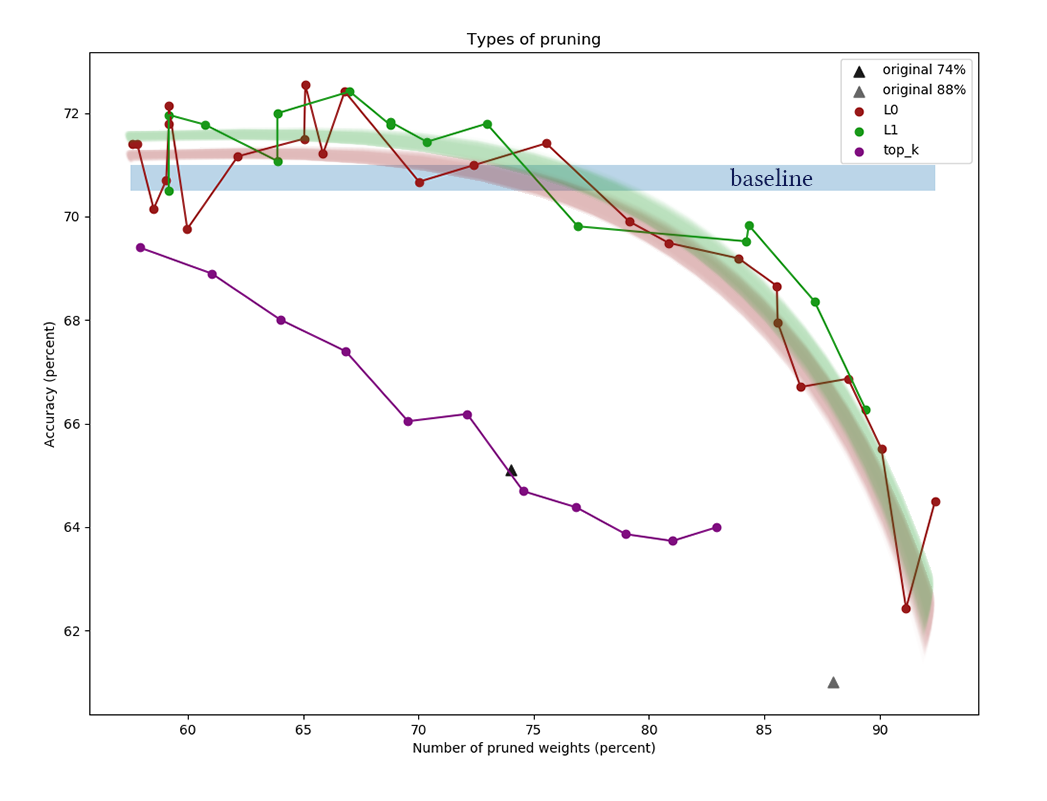
يوضح الرسم البياني نتائج مقارنة خوارزميات اختزال القناة L1 و L0 بعد سلسلة من التجارب مع ثوابت قدرة تسوية مختلفة.
يمثل المحور س نسبة الانخفاض في عدد
الأوزان بعد تطبيق الخوارزمية. على المحور ص ، دقة الشبكة المقطوعة في عينة التحقق. الشريط الأزرق في المنتصف هو الجودة التقريبية لشبكة لم يتم قطعها بعد من الخلايا العصبية. يمثل الخط الأخضر خوارزمية تعلم قناع L1 بسيطة. الخط الأحمر هو تقليم L0. الخط الأرجواني - الإزالة الأولى
ك القنوات. المثلثات السوداء - تدريب شبكة ذات أوزان أقل في البداية.
مثال آخر على CIFAR-100 وشبكة أطول قليلاً وأوسع من نفس البنية تقريبًا ومع معلمات تدريب مماثلة:
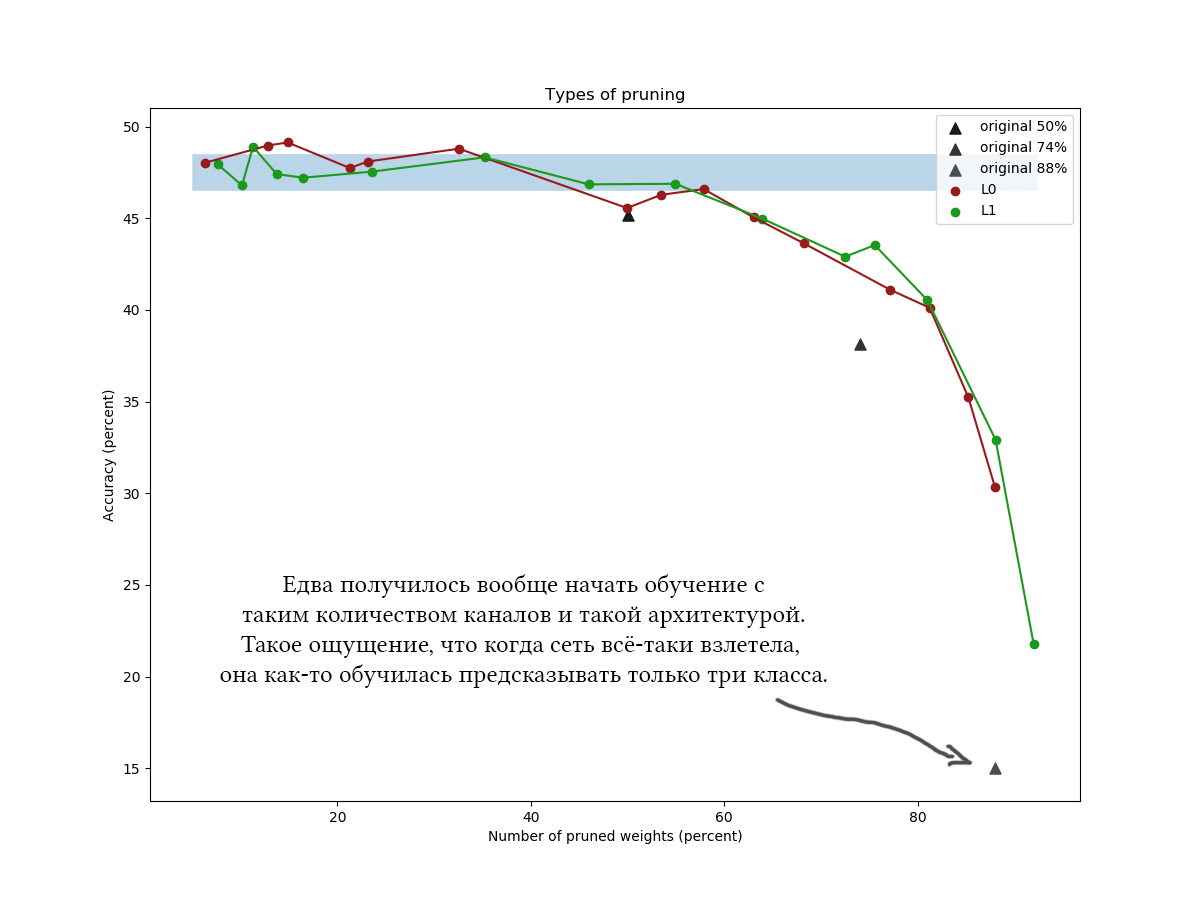
ثالثًا في الرسوم البيانية ، من الواضح أن خوارزمية L1 البسيطة لا تتأقلم مع التحسين المتغير الماكر ، ويبدو أنها حتى تحسن جودة الشبكة قليلاً عند قيم ضغط منخفضة. يتم تأكيد النتائج أيضًا من خلال تجارب لمرة واحدة مع مجموعات بيانات أخرى وهياكل الشبكة. هذه نتيجة متوقعة تمامًا ، والتي كنت أعول عليها عندما بدأت تجارب على تقليل الشبكة. بصراحة. تنهد.
حسنًا ، لأكون صادقًا ، فوجئت قليلاً ، وحاولت اللعب مع الخوارزمية والشبكة: بنى مختلفة ، ومعلمات مفرطة للشبكة ، وصيغ دقيقة لتوزيع الخرسانة الصلبة ، والقيم الأولية
و ل ص ح ل و
ب ي ت ا عدد فترات الضبط المتوسط. يبدو تنظيم L0 رائعًا من الناحية النظرية ، ولكن من الناحية العملية ، من الصعب التقاط معلمات مفرطة ، ويستغرق الأمر وقتًا أطول ، لذلك لا أوصي باستخدامه بدون تجارب إضافية ومعالجة الملفات. من فضلك لا تفكر في الوقت الذي يقضيه في قراءة المقال: يبدو التقليم L0 قابلًا للتصديق جدًا حقًا ، وأود أن أقول إنني أفضل تطبيق الخوارزمية في مكان ما بشكل غير صحيح ، لأنني لم أحصل على المكاسب الموعودة. بالإضافة إلى ذلك ، التحسين الأمثل هو الأساس لخوارزميات الاختزال الأكثر تقدمًا [على سبيل المثال ، ضغط الشبكات العصبية باستخدام المتغير
اختناق المعلومات ، 2018].
بشكل عام ، يمكن استخلاص الاستنتاجات التالية:- . 30-50% . «» , . [The Lottery Ticket Hypothesis: Training Pruned Neural Networks, J. Frankle and M. Carbin, 2018] ( , , , ).
- , . . , ?
- , . 60-90% . k <7%, .
- , (<60%) : , !
- L1 L0 (APoZ), , .. , k .
- , . , , , , . , , . pruning' , . - , .
تذكر كيف كتبت في بداية المنشور أنه بعد الانتهاء من الخوارزمية المبهرة ، يمكنك "قطع الأجزاء الإضافية من الشبكة بالكامل"؟ لذا ، فإن قطع قطع إضافية من الشبكة ليس بالأمر السهل على الإطلاق. يقوم Tensorflow والمكتبات الأخرى بإنشاء رسم بياني حسابي ، ولا يمكن تغييره بسهولة عندما يكون قيد التشغيل بالفعل. يجب عليك حفظ الشبكة باستخدام الأقنعة المحسوبة ، وتمزيق قائمة الأوزان الضرورية منها ، وتحويل الأوزان حسب الحاجة ، وحذف المجموعات التي تحتوي على صفر ، وإعادة تبديلها ، وإنشاء شبكة جديدة بناءً على مجموعة المخرجات. يجب أن يكون للشبكة الناتجة نفس التخطيط الأصلي ، ولكن سيكون لديها عدد أقل من الخلايا العصبية. توقع صداعًا مع الحفاظ على نفس مخطط الشبكة في وظيفة إنشاء الشبكة الأولية والنهائية ، خاصة إذا لم تكن خطية ، ولكنها متفرعة.ربما لإخفاء مريح عليك إنشاء طبقاتك الخاصة. إنه أمر سهل ، ولكن كن حذرًا بشأن المجموعات التي تضيف إليها خيارات التقنيع. من السهل ارتكاب خطأ وتدريب معلمات خفض القناة عن طريق الخطأ مع جميع المقاييس الأخرى.وتجدر الإشارة إلى أن جزءًا كبيرًا من أوزان الشبكات التي لا تحتوي على معماريات عميقة للغاية يتركز عادةً على الانتقال من جزء تلافيفي إلى جزء متصل بالكامل. ويرجع ذلك إلى حقيقة أن الطبقة التلافيفية الأخيرة أصبحت مسطحة ، ونتيجة لذلك ، تم تشكيل (عدد القنوات) * (عرض) * (ارتفاع) الخلايا العصبية فيها ، والمصفوفة التالية من الأوزان واسعة جدًا. من غير المحتمل أن يتم قطع هذه الأوزان. علاوة على ذلك ، لا ينبغي القيام بذلك ، وإلا فإن الطبقات الأخيرة من الشبكة ستكون "عمياء" للميزات الموجودة في بعض الأماكن. في مثل هذه الحالات ، حاول أن تجعل العدد النهائي للقنوات أصغر واستخدام maxpool'ing أو حتى استخدام معماريات تلافيفية كاملة أو متصلة بالكامل.شكرًا لكم جميعًا على اهتمامكم ، إذا كان شخص ما مهتمًا بتكرار التجارب على CIFAR-10 و CIFAR-100 ،يمكن أن تؤخذ التعليمات البرمجية على جيثب . أتمنى لك يوم عمل لطيف!