الجزء الأول ، "تقييم ThunderX2 من Cavium: حلم خادم الذراع يتحقق"
هناتكوين ومنهجية الاختبار
لمراجعة ThunderX2 ، تم إجراء جميع اختباراتنا على Ubuntu Server 17.10 ، Linux 4.13 64 bit kernel. نستخدم عادةً إصدار LTS ، ولكن نظرًا لأن Cavium يأتي مع هذا الإصدار الخاص من Ubuntu ، فإننا لم نخاطر بتبديل نظام التشغيل. يتضمن توزيع أوبونتو مترجم 7.2 دول مجلس التعاون الخليجي.

ستلاحظ أن مقدار DRAM يختلف في تكوينات الخادم. والسبب بسيط: لدى Intel 6 قنوات ذاكرة ، و Cavium's ThunderX2 به 8 قنوات ذاكرة.
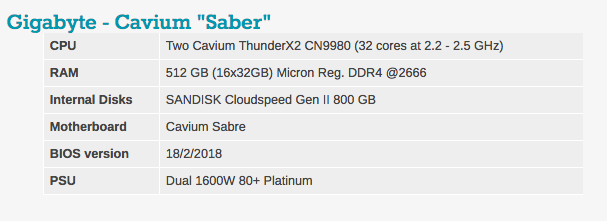
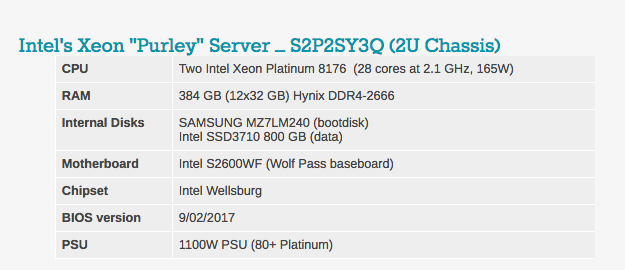
يمكن رؤية إعدادات BIOS النموذجية أدناه. تجدر الإشارة إلى أنه يتم تضمين تقنية hyperthreading وتقنية Intel الافتراضية.
ملاحظات أخرىيتم تشغيل كلا الخادمين وفقًا للمعايير الأوروبية - 230 فولت (بحد أقصى 16 أمبير). يتم التحكم في درجة حرارة الهواء الداخلي والحفاظ عليها عند 23 درجة مئوية بواسطة أجهزة Airwell CRAC.
استهلاك الطاقة
ومن الجدير بالذكر أن نظام Gigabyte “Sabre” استهلك 500 واط إذا كان يعمل بنظام Linux فقط (بمعنى أنه كان خاملاً في الغالب). ومع ذلك ، تحت الحمل ، يستهلك النظام حوالي 800 واط ، وهو ما يفي بتوقعاتنا من حيث المبدأ ، نظرًا لوجود شريحتين بقدرة 180 واط TDP في الداخل. كما هو الحال عادةً مع أنظمة الاختبار المبكرة ، لا يمكننا إجراء مقارنات دقيقة للطاقة.
في الواقع ، يدعي Cavium أن الأنظمة الحالية من HP و Gigabyte وغيرها ستكون أكثر كفاءة. كان لنظام اختبار سيبر الذي تم استخدامه العديد من المشاكل في إدارة الطاقة: التحكم غير السليم في البرامج الثابتة للمروحة ، وخطأ BMC ووحدة تزويد الطاقة مع الكثير من الطاقة (1600 واط).
النظام الفرعي للذاكرة: النطاق الترددي
أصبح استخدام المعيار المرجعي لعرض النطاق الترددي لـ John McCalpin في أحدث المعالجات أمرًا صعبًا بشكل متزايد لقياس الإمكانات الكاملة لعرض النطاق الترددي للنظام مع تزايد عدد القنوات الأساسية والذاكرة. كما ترى من النتائج أدناه ، فإن تقدير الإنتاجية ليس بالأمر السهل. تعتمد النتيجة بشكل كبير على الإعدادات المحددة.

نظريًا ، يتمتع ThunderX2 بنطاق ترددي أكثر بنسبة 33٪ من Intel Xeon ، نظرًا لأن SoC بها 8 قنوات ذاكرة مقارنة بست قنوات Intel. لا يتم تحقيق أرقام الإنتاجية العالية هذه إلا في ظل ظروف محددة للغاية ، وتتطلب بعض الضبط لتجنب استخدام الذاكرة البعيدة. على وجه الخصوص ، يجب أن نضمن عدم نقل التدفقات من مقبس إلى آخر.
بالنسبة للمبتدئين ، حاولنا تحقيق أفضل النتائج على كلا المعماريين. في حالة Intel ، حقق مترجم ICC دائمًا نتائج أفضل مع بعض التحسينات ذات المستوى المنخفض داخل حلقات الدفق. في حالة Cavium ، اتبعنا تعليمات Cavium. تحدث الصورة تقريبًا ، وهي فكرة عن النطاق الترددي الذي يمكن أن تحققه هذه المعالجات عند ذروتها. لنكون صادقين مع Intel ، من خلال الإعدادات المثالية (AVX-512) يمكنك الوصول إلى 200 جيجابايت / ثانية.
ومع ذلك ، من الواضح أن نظام ThunderX2 يمكن أن يوفر عرض نطاق ترددي أكثر بنسبة 15 إلى 28٪ إلى نوى المعالج. والنتيجة هي 235 جيجابايت / ثانية ، أو حوالي 120 جيجابايت / ثانية لكل فتحة. وهذا ، بدوره ، أكبر بثلاث مرات من ThunderX الأصلي.
النظام الفرعي للذاكرة: التأخير
على الرغم من أن قياسات عرض النطاق الترددي تنطبق فقط على جزء صغير من سوق الخوادم ، إلا أن كل تطبيق تقريبًا يعتمد بشكل كبير على كمون النظام الفرعي للذاكرة. في محاولات قياس ذاكرة التخزين المؤقت ووقت استجابة الذاكرة ، استخدمنا LMBench. البيانات التي نريد أن نراها نتيجة لذلك هي "تأخير عند التحميل العشوائي ، الخطوة = 16 بايت". لاحظ أننا نعبر عن وقت استجابة L3 وتأخير وقت DRAM بالثانية ، حيث لا توجد لدينا قيم دقيقة لذاكرة التخزين المؤقت L3.
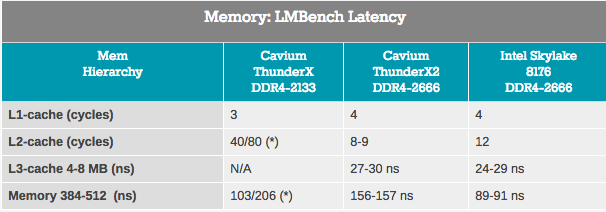
يتم الوصول إلى ذاكرة التخزين المؤقت ThunderX2 L2 بوقت استجابة منخفض جدًا ، وعند استخدام دفق واحد ، تبدو ذاكرة التخزين المؤقت L3 منافسًا لذاكرة التخزين المؤقت L3 المدمجة من Intel. ومع ذلك ، عندما وصلنا إلى DRAM ، أظهرت Intel وقت استجابة أقل بكثير.
النظام الفرعي للذاكرة: TinyMemBench
للحصول على فهم أعمق للهياكل ذات الصلة ، تم استخدام اختبار TinyMemBench مفتوح المصدر. تم تجميع شفرة المصدر باستخدام GCC 7.2 ، وتم تعيين مستوى التحسين إلى -O3. يتم وصف استراتيجية الاختبار جيدًا في دليل المعايير:
يتم قياس متوسط الوقت للوصول العشوائي للذاكرة في المخازن المؤقتة بأحجام مختلفة. كلما زاد حجم المخزن المؤقت ، زادت المساهمة النسبية لذاكرة التخزين المؤقت TLB ، ووصول L1 / L2 ، و DRAM. تمثل جميع الأرقام الوقت الإضافي الذي يجب إضافته إلى زمن وصول ذاكرة التخزين المؤقت L1 (4 دورات).
لقد اختبرنا قراءة واحدة واثنتين عشوائيتين (بدون صفحات ضخمة) ، لأننا أردنا أن نرى كيف تعامل نظام الذاكرة مع العديد من طلبات القراءة.
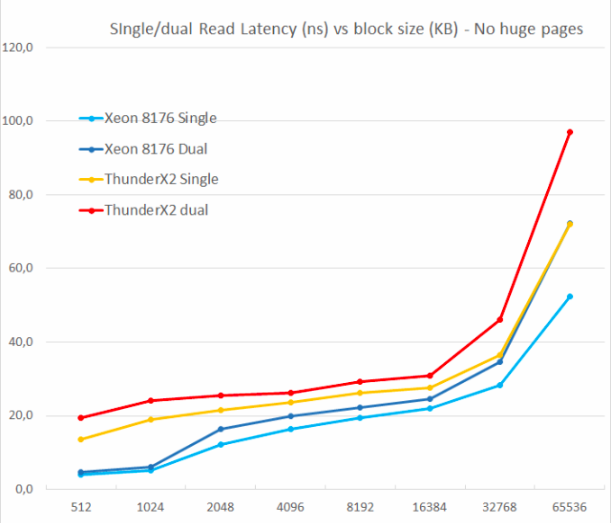
كان أحد العوائق الرئيسية لـ ThunderX الأصلي هو عدم القدرة على دعم العديد من الأخطاء البارزة. التزامن على مستوى الذاكرة هو ميزة مهمة لأي نواة حديثة عالية الأداء: بمساعدته ، يتجنب أخطاء التخزين المؤقت التي يمكن أن تسبب "الجوع" في النهاية. وبالتالي ، فإن ذاكرة التخزين المؤقت غير المحظورة هي سمة رئيسية للنوى الكبيرة.
لا يعاني ThunderX2 من هذه المشكلة على الإطلاق ، وذلك بفضل ذاكرة التخزين المؤقت غير المحجوبة. تمامًا مثل نواة Skylake في Xeon 8176 ، تزيد القراءة الثانية من الكمون الإجمالي بنسبة 15-30 ٪ فقط ، وليس 100 ٪. وفقًا لـ TinyMemBench ، فإن نواة Skylake لها كمون أفضل بشكل ملحوظ. من السهل شرح النقطة المرجعية بسعة 512 كيلوبايت: لا يزال قلب Skylake يتعافى من سرعة L2 ، ويجب أن يصل قلب ThunderX2 إلى L3. لكن أرقام 1 و 2 ميجابايت تُظهر أن أجهزة الجلب المسبق من Intel تقدم ميزة جدية ، لأن الكمون هو متوسط ذاكرة التخزين المؤقت L2 و L3. تتشابه معدلات الكمون في نطاق 8 إلى 16 ميجابايت ، ولكن بمجرد أن نتجاوز L3 (64 ميجابايت) ، توفر Intel Skylake ذاكرة زمن وصول أقل.
أداء واحد الخيوط: SPEC CPU2006
نبدأ بقياس أداء الحوسبة الفعلي ، نبدأ بحزمة SPEC CPU2006. سيشير القراء المطلعون إلى أن SPEC CPU2006 قد تم إيقافه عندما ظهر SPEC CPU2017. ولكن نظرًا لوقت الاختبار المحدود وحقيقة أننا لم نتمكن من إعادة اختبار ThunderX ، قررنا التمسك بـ CPU2006.
بالنظر إلى أن SPEC هو تقريبًا مقياس مرجعي جيد مثل الأجهزة ، فإننا نعتقد أنه سيكون من المناسب صياغة فلسفة الاختبار لدينا. تحتاج إلى تقييم المؤشرات الحقيقية ، وعدم تضخيم نتائج الاختبار. لذلك ، من المهم أن نخلق ، قدر الإمكان ، ظروفًا "كما هو الحال في العالم الحقيقي" مع الإعدادات التالية (يُرحب بالنقد البناء بشأن هذه المسألة):
- 64 bit gcc: المترجم الأكثر استخدامًا على Linux ، مترجم جيد لا يحاول "مقاطعة" الاختبارات (libquantum ...)
- -Ofast: تحسين المترجم الذي يمكن للعديد من المطورين استخدامه
- -fno-صارمة التعرج: مطلوب لتجميع بعض الاختبارات الفرعية
- التشغيل الأساسي: كل اختبار فرعي يتم تجميعه بنفس الطريقة
أولاً ، تحتاج إلى قياس الأداء في التطبيقات التي يحدث فيها ، لسبب ما ، تأخير بسبب "بيئة معادية متعددة مؤشرات الترابط". ثانيًا ، تحتاج إلى فهم مدى جودة عمل هندسة ThunderX LLC مع مؤشر ترابط واحد مقارنة ببنية Skylake من Intel. يرجى ملاحظة أنه في نموذج Skylake الخاص يمكنك زيادة تردد التشغيل إلى 3.8 جيجا هرتز. ستعمل الشريحة بتردد 2.8 جيجا هرتز في جميع المواقف تقريبًا (28 خيط نشط) وستدعم 3.4 جيجا هرتز مع 14 خيط نشط.
بشكل عام ، يضع Cavium ThunderX2 CN9980 (1795 دولارًا) على أنه "أفضل من 6148" (3072 دولارًا) ، وهو معالج يعمل بسرعة 2.6 جيجا هرتز (20 سلسلة) ويصل إلى 3.3 جيجا هرتز دون أي مشاكل (حتى 16 سلسلة نشطة) ) من ناحية أخرى ، ستحظى Intel-SKU بميزة كبيرة بنسبة 30 بالمائة في سرعة الساعة في العديد من المواقف (3.3 جيجا هرتز مقابل 2.5 جيجا هرتز).
قرر Cavium التعويض عن عجز التردد من خلال عدد النوى ، حيث قدم 32 نواة - وهو ما يزيد بنسبة 60٪ عن Xeon 6148 (20 نواة). من الجدير بالذكر أن عددًا أكبر من النوى سيؤدي إلى انخفاض العائد في العديد من التطبيقات (على سبيل المثال ، Amdahl). لذلك ، إذا أراد Cavium هز مركز Intel المهيمن مع ThunderX2 ، فيجب على كل نواة على الأقل تقديم أداء تنافسي على أرض الواقع. أو في هذه الحالة ، يجب أن يوفر ThunderX2 أداء Skylake أحادي السن بنسبة 66٪ (2.5 مقابل 3.8) على الأقل.
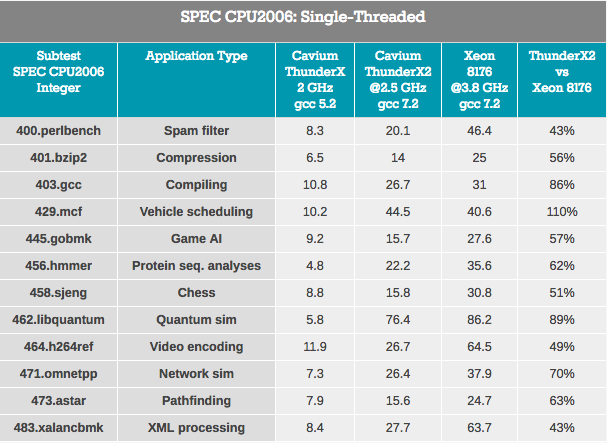
النتائج ضبابية لأن ThunderX2 يعمل مع رمز ARMv8 (AArch64) ، ويستخدم Xeon رمز x86-64.
اختبارات تتبع المؤشر - معالجة XML (أيضًا مخازن OoO كبيرة) وإيجاد المسارات التي تعتمد عادةً على ذاكرة تخزين مؤقت كبيرة L3 لتقليل تأثير وقت الوصول هي الأسوأ لـ ThunderX2. يمكن افتراض أن الكمون الأعلى لنظام DRAM يقلل من الأداء.
أعباء العمل التي يكون فيها تأثير التنبؤ بالفروع أعلى (على الأقل في x86-64: نسبة أعلى من اختيار الفرع الخاطئ) - gobmk ، sjeng ، hmmer - ليست أفضل الأحمال على ThunderX2.
من الجدير بالذكر أيضًا أن تعليمات perlbench و gobmk و hmmer و h264ref معروفة بالاستفادة من ذاكرة التخزين المؤقت الأكبر حجمًا لـ Skylake (512 كيلوبايت). نعرض لك بضع قطع من اللغز ، ولكن معًا يمكن أن يساعدوا في تجميع الصورة معًا.
على الجانب الإيجابي ، عمل ThunderX2 بشكل جيد مع gcc ، والذي يعمل في الغالب داخل ذاكرة التخزين المؤقت L1 و L2 (وبالتالي يعتمد على الكمون المنخفض L2) ، وتأثير أداء مؤشر الفروع ضئيل. بشكل عام ، أفضل اختبار لـ TunderX2 هو mcf (توزيع المركبات في وسائل النقل العام) ، والذي ، كما تعلم ، يتخطى ذاكرة التخزين المؤقت للبيانات L1 تقريبًا ، بالاعتماد على ذاكرة التخزين المؤقت L2 ، وهذه هي النقطة القوية في ThunderX2. تطالب Mcf أيضًا بعرض النطاق الترددي للذاكرة. Libquantum هو اختبار يحتاج بشدة إلى عرض نطاق الذاكرة. حقيقة أن Skylake تقدم عرض النطاق الترددي ذو الخيوط المتواضعة إلى حد ما هو على الأرجح السبب وراء أداء ThunderX2 بشكل جيد على libquantum و mcf.
SPEC CPU2006 المحتويات: أداء قائم على النواة مع SMT
إذا تجاوزنا الأداء ذو الترابط الفردي ، يجب أيضًا مراعاة الأداء متعدد الخيوط داخل قلب واحد. تم تصميم بنية معالج فولكان في الأصل لاستخدام SMT4 للحفاظ على نوى التحميل وزيادة الإنتاجية الإجمالية ، وسنتحدث عن ذلك الآن.
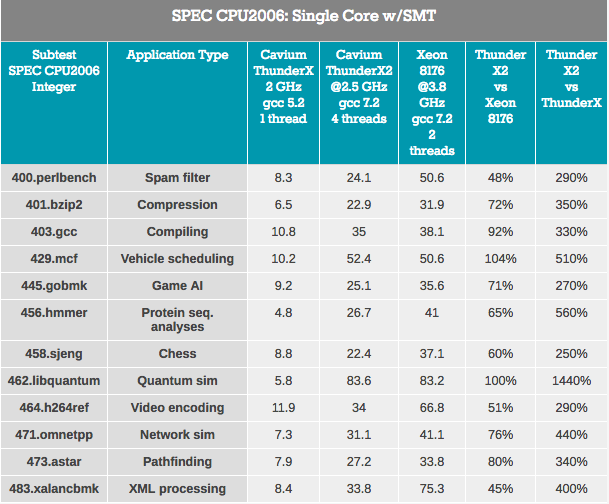
بادئ ذي بدء ، فإن نواة ThunderX2 "خضعت" للعديد من التحسينات الهامة على نواة ThunderX الأولى. حتى مع أخذ libquantum في الاعتبار ، يمكن تشغيل هذا الاختبار بسهولة 3 مرات أسرع على نواة ThunderX القديمة بعد بعض التحسينات والتحسينات للمترجم. حسنًا ، ThunderX2 الجديد ليس أقل من 3.7 مرة أسرع من أخيها الأكبر. إن تفوق IPC هذا يلغي أي مزايا لـ ThunderX السابق.
عند النظر في تأثير SMT ، في المتوسط نرى أن SMT رباعي الاتجاهات يحسن أداء ThunderX2 بنسبة 32٪. هذا يتراوح من 8٪ لترميز الفيديو إلى 74٪ لـ Pathfinding. في غضون ذلك ، تكسب Intel 18٪ من SMT ثنائي الاتجاه ، من 4٪ إلى 37٪ في نفس السيناريوهات.
بشكل عام ، زيادة أداء ThunderX2 هي 32 ٪ ، وهو أمر جيد جدًا. ولكن هنا يبرز السؤال الواضح: كيف تختلف عن غيرها من معماريات SMT4؟ على سبيل المثال ، يُظهر IBM POWER8 ، الذي يدعم SMT4 أيضًا ، زيادة بنسبة 76٪ في نفس السيناريو.
ومع ذلك ، هذه ليست مقارنة تمامًا بالمتشابه مع المتشابه ، نظرًا لأن شريحة IBM لها خلفية خلفية أوسع بكثير: يمكنها معالجة 10 تعليمات ، بينما يقتصر جوهر ThunderX2 على 6 تعليمات لكل دورة. إن POWER8 core أكثر شراهة: يمكن للمعالج أن يستوعب 10 فقط من هذه النوى "العريضة للغاية" بميزانية طاقة 190 W في عملية 22 nm. على الأرجح ، ستتطلب زيادة أخرى في الأداء من استخدام SMT4 نوى أكبر ، وبالتالي ، ستؤثر بشكل خطير على عدد النوى المتاحة داخل ThunderX2. ومع ذلك ، من المثير للاهتمام النظر إلى هذه الزيادة بنسبة 32٪ في المستقبل.
في الجزء (3) التالي:
- أداء جافا
- أداء جافا: صفحات ضخمة
- أباتشي سبارك 2.x المقارنة
- الملخص
شكرا لك على البقاء معنا. هل تحب مقالاتنا؟ هل تريد رؤية مواد أكثر إثارة للاهتمام؟ ادعمنا عن طريق تقديم طلب أو التوصية به لأصدقائك ،
خصم 30 ٪ لمستخدمي Habr على نظير فريد من خوادم مستوى الدخول التي اخترعناها لك: الحقيقة الكاملة حول VPS (KVM) E5-2650 v4 (6 نوى) 10GB DDR4 240GB SSD 1Gbps من 20 $ أو كيفية تقسيم الخادم؟ (تتوفر الخيارات مع RAID1 و RAID10 ، حتى 24 مركزًا وحتى 40 جيجابايت DDR4).
ديل R730xd أرخص مرتين؟ فقط لدينا
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV من 249 دولارًا في هولندا والولايات المتحدة! اقرأ عن
كيفية بناء مبنى البنية التحتية الطبقة باستخدام خوادم Dell R730xd E5-2650 v4 بتكلفة 9000 يورو مقابل سنت واحد؟