الجزء الأول والثاني ، "Cavium ThunderX2 Evaluation: The Arm Server Dream قد تحقق".
أداء جافا
SPECjbb 2015 هو مقياس مرجعي لأعمال Java يتم استخدامه لتقييم أداء الخوادم التي تقوم بتشغيل تطبيقات Java النموذجية. يستخدم أحدث ميزات Java 7 و XML ، حيث يتداخل مع الأمان.

يرجى ملاحظة أننا قمنا بتحديث إصدار SPECjbb 1.0 إلى الإصدار 1.01.

اختبرنا SPECjbb مع أربع مجموعات من حاقنات المعاملات والخلفية. سبب استخدامنا لاختبار Multi JVM هو أنه أقرب إلى الظروف الحقيقية: تعد العديد من الأجهزة الظاهرية على الخادم ممارسة شائعة ، خاصة على الخوادم التي تحتوي على أكثر من 100 سلسلة. إصدار Java هو OpenJDK 1.8.0_161.
في كل مرة ننشر نتائج SPECjbb ، نتلقى تعليقات تفيد بأن أدائنا منخفض جدًا. لذلك ، قررنا قضاء المزيد من الوقت والانتباه إلى الإعدادات المختلفة.
- إعدادات Kernel ، مثل توقيتات جدولة المهام ، ومسح ذاكرة التخزين المؤقت للصفحة
- تعطيل ميزات توفير الطاقة ، تكوين سلوك الحالة c يدويًا.
- ضبط المراوح على أقصى سرعة (ننفق الكثير من الطاقة لصالح بضع نقاط أداء إضافية)
- تعطيل وظائف RAS (مثل فرك الذاكرة)
- العديد من الإعدادات لمعلمات Java المختلفة ... إنه غير واقعي ، لأنه في كل مرة تقوم فيها بتشغيل التطبيق على أجهزة مختلفة (والذي يحدث غالبًا في السحابة) ، يجب على المتخصصين المكلفين تكوين الإعدادات لجهاز معين ، والذي ، بالإضافة إلى ذلك ، يمكن أن يؤدي إلى توقف التطبيق على أجهزة أخرى
- تكوين إعدادات NUMA الخاصة بـ SKU وتعيينات CPU. يمكن أن يؤدي الترحيل بين وحدتي SKU مختلفتين في نفس المجموعة إلى مشكلات أداء خطيرة.
في بيئة الإنتاج ، يجب أن يكون الإعداد بسيطًا ، ويفضل ألا يكون خاصًا جدًا بالماكينة. لهذا الغرض ، قمنا بتطبيق نوعين من الإعدادات. الأول هو إعداد بسيط للغاية لقياس الأداء خارج الصندوق لوضع كل شيء على خادم مع 128 غيغابايت من ذاكرة الوصول العشوائي:
"-server -Xmx24G -Xms24G -Xmn16G"بالنسبة للإعداد الثاني ، بحثًا عن أفضل مؤشر للإنتاج ، لعبنا مع "-XX: + AlwaysPreTouch" و "-XX: -UseBiasedLocking" و "specjbb.forkjoin.workers". يؤدي "+ AlwaysPretouch" قبل البدء إلى إعادة تعيين جميع صفحات الذاكرة ، مما يقلل من تأثير الأداء على الصفحات الجديدة. يقوم "-UseBiasedLockin" بتعطيل القفل الذي يتم تمكينه افتراضيًا. يعطي القفل المتحيز الأولوية لمؤشر الترابط الذي قام بالفعل بتحميل البيانات المتنافسة في ذاكرة التخزين المؤقت. الجانب العكسي للقفل المتحيز هو عمليات إضافية معقدة للغاية (Rebias) يمكن أن تقلل الأداء في حالة وجود استراتيجية تم اختيارها بشكل غير صحيح.
يوضح الرسم البياني أدناه أقصى أداء لمعيار MultiJVM SPECJbb.

يحقق ThunderX2 أداء من 80 إلى 85٪ من Xeon 8176. هذا الرقم يكفي لتجاوز Xeon 6148. ومن المثير للاهتمام أن أنظمة Intel و Cavium تحقق أفضل نتائجها بطرق مختلفة. في حالة Dual ThunderX2 ، استخدمنا:
'-server -Xmx24G -Xms24G -Xmn16G -XX:+AlwaysPreTouch -XX:-UseBiasedLockingبينما حقق نظام Intel أفضل أداء ، مع ترك قفل الإزاحة (افتراضي). لاحظنا أن نظام Intel - ربما بسبب العدد "النسبي" نسبيًا من سلاسل العمليات - يحتوي على حمل متوسط أقل قليلاً للمعالج (نسبة مئوية قليلة) وذاكرة تخزين مؤقت أكبر L3 ، مما يجعل القفل المتحيز إستراتيجية جيدة لهذه البنية.
أخيرًا ، لدينا Critical-jOPS ، التي تقيس الإنتاجية حسب حدود وقت الاستجابة.

مع الاستخدام النشط لعدد كبير من سلاسل العمليات ، يمكنك الحصول على Critical-jOPS بشكل ملحوظ عن طريق زيادة توزيع ذاكرة الوصول العشوائي على JVM. من المثير للدهشة أن نظام Dual ThunderX2 - مع عدد أكبر من التدفقات وسرعة الساعة المنخفضة - يُظهر أفضل وقت ، ويوفر نطاقًا تردديًا عاليًا ، مع الحفاظ على وقت استجابة بنسبة 99 بالمائة إلى حد معين.
تساعد زيادة حجم كومة الذاكرة المؤقتة Intel على إغلاق الفجوة قليلاً (حتى x2) ، ولكن على حساب النطاق الترددي (من -20٪ إلى -25٪). يبدو أن شريحة Intel تحتاج إلى تخصيص أكثر من ARM. لاستكشاف المزيد ، انتقلنا إلى صفحات ضخمة شفافة (THP).
أداء جافا: صفحات كبيرة
عادة بالنسبة لوحدة المعالجة المركزية ، نادرًا ما يقوم شخص ما بإعادة تشغيل عامل آخر في العامل 3 ، لكننا قررنا التحقيق في الأمر بعمق أكبر. كان المرشح الأكثر وضوحًا هو الصفحات الضخمة ، أو كما يسميها الجميع باستثناء مجتمع Linux "الصفحات الكبيرة".
يقوم كل معالج حديث بتخزين تعيينات الذاكرة الظاهرية والمادية في TLBs الخاصة به. حجم الصفحة "العادي" هو 4 كيلوبايت ، لذلك مع 1536 عنصرًا ، يمكن لـ Skylake core تخزين حوالي 6 ميجابايت لكل نواة. على مدار الخمسة عشر عامًا الماضية ، نمت سعة ذاكرة الوصول العشوائي الديناميكي (DRAM) من غيغابايت قليلة إلى مئات غيغابايت ، وبالتالي أصبحت أخطاء TLB مصدر قلق. يعد فقدان TLB مكلفًا للغاية - فأنت بحاجة إلى بعض عمليات الوصول إلى الذاكرة لقراءة بعض الجداول والعثور على عنوان فعلي.
جميع المعالجات الحديثة تدعم الصفحات الكبيرة. في الإصدار x86-64 (Intel و AMD) ، يتوفر خيار شائع هو 2 ميجابايت ، كما تتوفر صفحة 1 جيجابايت. وفي الوقت نفسه ، هناك صفحة كبيرة على ThunderX2 لا تقل عن 0.5 غيغابايت. يقلل استخدام الصفحات الكبيرة من عدد أخطاء TLB المفقودة (على الرغم من أن عدد الإدخالات في TLBs عادة أقل بكثير للصفحات الكبيرة) ، يقلل من عدد مرات الوصول إلى الذاكرة المطلوبة عند فقد TLB.
ومع ذلك ، حان الوقت قبل أن يدعم Linux هذه الميزة بطريقة ملائمة. تسبب تجزئة الذاكرة وتضاربها وصعوبة تكوين الإعدادات وعدم التوافق وخاصة الأسماء المربكة للغاية في الكثير من المشاكل. في الواقع ، لا يزال العديد من موردي البرامج ينصحون مسؤولي الخادم بإيقاف تشغيل الصفحات الكبيرة.
تحقيقا لهذه الغاية ، دعنا نرى ما يحدث إذا قمنا بتشغيل الصفحات الشفافة الضخمة وحفظنا أفضل الإعدادات التي تمت مناقشتها سابقًا.
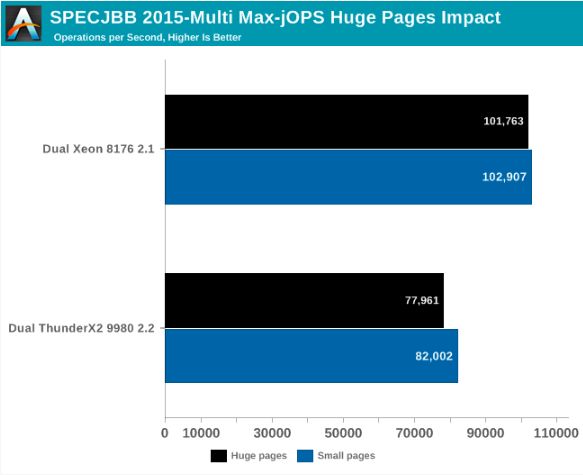
بشكل عام ، بالنسبة لـ Max-jOPs ، فإن تأثير الأداء ليس مذهلاً ؛ هذا في الواقع انحدار صغير. تفقد Xeon حوالي 1٪ من عرض النطاق الترددي ThunderX2 - حوالي 5٪.
دعنا ننتقل إلى مقياس Critical-jOPS ، حيث يتم قياس الإنتاجية كنسبة مئوية 99 من حد وقت الاستجابة.

فرق كبير! بدلاً من الهزيمة ، تتجاوز Intel ThunderX2. ومع ذلك ، يجب القول أن الأداء مع صفحات 4 كيلوبايت يبدو ضعفًا خطيرًا في بنية Intel.
أباتشي سبارك 2.x المقارنة
أخيرًا وليس آخرًا ، تحتوي ترسانتنا على اختبار Apache Spark. أباتشي سبارك هو من بنات أفكار معالجة البيانات الضخمة. لا يزال تسريع تطبيقات البيانات الضخمة مشروعًا ذا أولوية في المختبر الجامعي حيث أعمل (Sizing Servers Lab University of West-Flanders) ، لذلك قمنا بإعداد معيار يستخدم العديد من ميزات Spark ويستند إلى الاستخدام الواقعي.

يوصف الاختبار في الرسم البياني أعلاه. نبدأ بـ 300 جيجابايت من البيانات المضغوطة التي تم جمعها من CommonCrawl. هذه الملفات المضغوطة هي عدد كبير من أرشيفات الويب. نقوم بفك ضغط البيانات على الطاير لتجنب الانتظار الطويل ، والذي يرتبط بشكل رئيسي بجهاز التخزين. ثم نقوم باستخراج البيانات النصية ذات المعنى من الأرشيف باستخدام مكتبة Java BoilerPipe. باستخدام أداة معالجة اللغة الطبيعية في ستانفورد CoreNLP ، نستخرج الكيانات ("الكلمات التي تعني شيئًا") من النص ثم نحسب عناوين URL التي تحتوي على أكبر عدد من هذه الكائنات. يتم استخدام خوارزمية Alternating Lessest Square للتوصية بعناوين URL الأكثر إثارة للاهتمام لموضوع معين.
لتحقيق التوسع الأفضل ، أطلقنا 4 فنانين. أعاد الباحث Esley Havenert تكوين اختبار Spark بحيث يمكن تشغيله على Apache Spark 2.1.1.
ها هي النتائج:

(*) EPYC و Xeon E5 V4 أقدم ، يعملان على Kernel 4.8 و Java أقدم قليلاً 1.8.0_131 بدلاً من 1.8.0_161. على الرغم من أننا نتوقع أن تكون النتائج متشابهة جدًا في الإصدار 4.13 kernel و Java 1.8.0_161 ، نظرًا لأننا لم نلاحظ اختلافًا كبيرًا في Skylake Xeon بين هذين الإعدادين.
معالجة البيانات متوازية للغاية وتحمل المعالج بشكل مكثف للغاية ، ولكن بالنسبة لمراحل "التبديل العشوائي" يتطلب الكثير من التفاعل مع الذاكرة. الوقت الذي يقضيه في التواصل مع جهاز التخزين لا يكاد يذكر. لا تتطور مرحلة ALS عبر العديد من الخيوط ، ولكنها أقل من 4٪ من إجمالي وقت الاختبار.
يوفر ThunderX2 87٪ من أداء جهاز EPYC 7601 المرتفع الثمن مرتين. نظرًا لأن هذا المؤشر يتناسب جيدًا مع عدد النوى ، يمكننا تقدير أن Xeon 6148 سوف يسجل حوالي 4.8. على أباتشي سبارك ، في حين أن ThunderX2 لا يمكنه تهديد Xeon Platinum 8176 ، إلا أنه يعطي نفس الشيء مثل Gold 6148 وشقيقه مقابل أموال أقل بكثير.
وماذا في النهاية
لتلخيص كل شيء ، تظهر اختبارات SPECInt أن نوى ThunderX2 لا تزال بها بعض العيوب. أول انطباع سلبي لدينا هو أن رمز التفرع المكثف - خاصةً مع ذاكرة التخزين المؤقت المعتادة L3 (تأخير DRAM العالي) - يعمل ببطء إلى حد ما. وبالتالي ، ستكون هناك حالات خاصة عندما لا يكون ThunderX2 هو الخيار الأفضل.
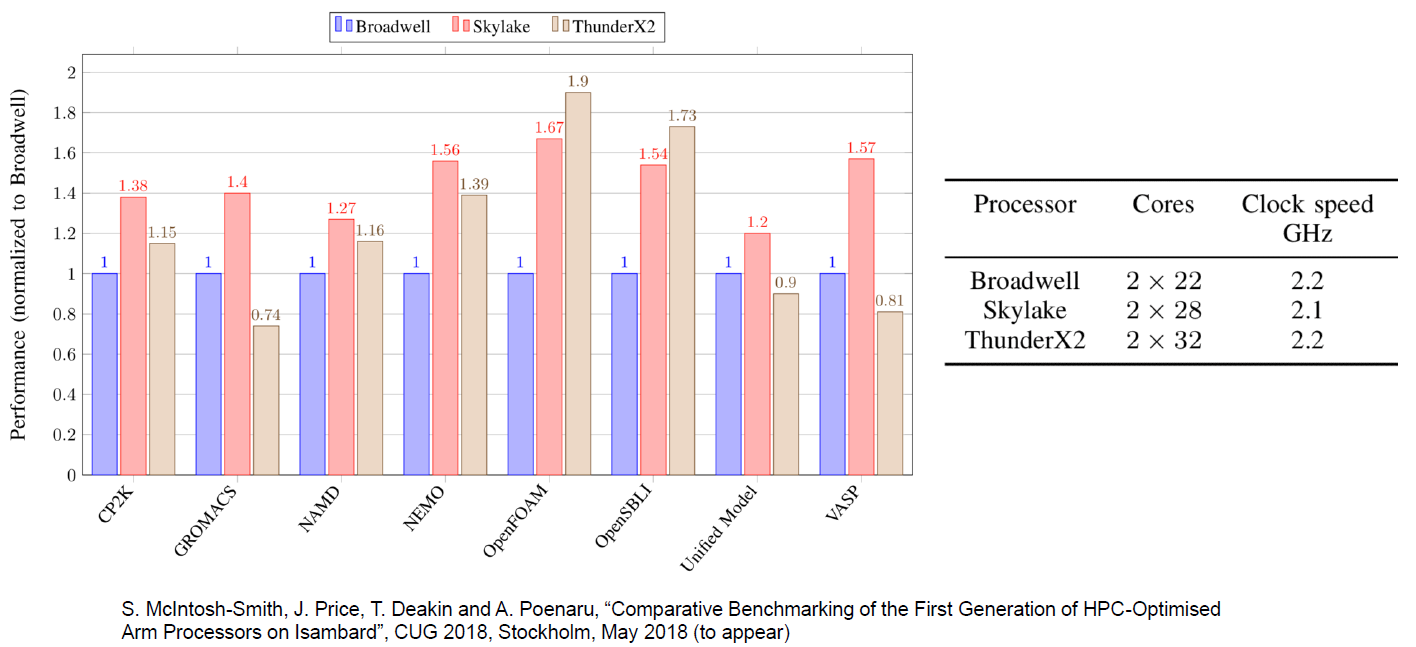
ومع ذلك ، بالإضافة إلى بعض الأسواق المتخصصة ، نحن على يقين من أن ThunderX2 سيصبح أداء قويًا. على سبيل المثال ، تؤكد قياسات الأداء التي أجراها زملاؤنا في جامعة بريستول افتراضنا بأن أعباء عمل HPC المكثفة مثل OpenFoam (CFD) و NAMD.run تعمل بشكل جيد على ThunderX2
بناءً على نتائج الاختبار المبكر لبرنامج الخادم الذي تمكنا من القيام به ، قد نفاجأ بسرور. أداء ThunderX2 مقابل دولار على كل من خادم جافا (SPECJbb) ومعالجة البيانات الضخمة - الآن - هو الأفضل في سوق الخادم. علينا إعادة اختبار معالج AMD EPYC والنسخة الذهبية من الجيل الحالي (Skylake) من Xeon ، ولكن في نفس الوقت ، سيكون من الصعب جدًا التغلب على 80-90 ٪ من أداء المعالج 8176 بربع تكلفته.
كميزة إضافية لـ Cavium و ThunderX2 ، تجدر الإشارة إلى أن النظام البيئي Arm Linux قد نضج بالفعل في عام 2018 ؛ لم تعد هناك حاجة لنواة لينكس المتخصصة والأدوات الأخرى. يمكنك ببساطة تثبيت خادم Ubuntu أو Red Hat أو Suse ، ويمكنك أتمتة نشر البرامج وتثبيتها من المستودعات القياسية. هذا تحسن كبير عما شهدناه عند إطلاق ThunderX. في عام 2016 ، قد يؤدي التثبيت البسيط من مستودعات Ubuntu العادية إلى حدوث مشكلات.
لذا ، بشكل عام ، ThunderX2 هو منافس قوي للغاية. يمكن أن يكون هذا أكثر خطورة على EPYC AMD من Skylake Xeon من Intel بسبب حقيقة أن كلا من Cavium و AMD يتنافسان على نفس المجموعة من العملاء ، نظرًا لإمكانية التخلي عن Intel. ويرجع ذلك إلى حقيقة أن العملاء الذين استثمروا في برامج الشركات باهظة الثمن (Oracle ، SAP) أقل حساسية للتكلفة من جانب الأجهزة ، لذلك هم أقل عرضة للانتقال إلى نظام أساسي جديد للأجهزة. وقد استثمر هؤلاء الأشخاص في Intel على مدى السنوات الخمس الماضية ، حيث كان هذا هو الخيار الوحيد.
وهذا بدوره يعني أن أولئك الأكثر مرونة وحساسية للسعر ، مثل مزودي الاستضافة والسحابة ، سيكونون الآن قادرين على اختيار خادم ذراع بديل مع نسبة أداء ممتازة مقابل الدولار. ومع توفر HP و Cray و Pengiun و Gigabyte و Foxconn و Inventec أنظمة تعتمد على ThunderX2 ، لا يوجد نقص في موردي الجودة.
باختصار ، ThunderX2 هي أول شركة نفط الجنوب تتنافس مع Intel و AMD في سوق خادم وحدة المعالجة المركزية. وهذه مفاجأة سارة: أخيرًا ، ظهر حل لخوادم Arm!
شكرا لك على البقاء معنا. هل تحب مقالاتنا؟ هل تريد رؤية مواد أكثر إثارة للاهتمام؟ ادعمنا عن طريق تقديم طلب أو التوصية به لأصدقائك ،
خصم 30 ٪ لمستخدمي Habr على نظير فريد من خوادم مستوى الدخول التي اخترعناها لك: الحقيقة الكاملة حول VPS (KVM) E5-2650 v4 (6 نوى) 10GB DDR4 240GB SSD 1Gbps من 20 $ أو كيفية تقسيم الخادم؟ (تتوفر الخيارات مع RAID1 و RAID10 ، حتى 24 مركزًا وحتى 40 جيجابايت DDR4).
ديل R730xd أرخص مرتين؟ فقط لدينا
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV من 249 دولارًا في هولندا والولايات المتحدة! اقرأ عن
كيفية بناء مبنى البنية التحتية الطبقة باستخدام خوادم Dell R730xd E5-2650 v4 بتكلفة 9000 يورو مقابل سنت واحد؟