ستركز هذه المقالة على بعض خوارزميات البحث وأوصاف نقاط الصورة المحددة. هنا
أثير هذا الموضوع بالفعل ، وأكثر
من مرة . سأعتبر أن التعريفات الأساسية مألوفة بالفعل للقارئ ، وسوف نفحص بالتفصيل الخوارزميات الإرشادية FAST و FAST-9 و FAST-ER و BRIEF و rBRIEF و ORB ، ومناقشة الأفكار البراقة التي تكمن وراءها. جزئيًا ، ستكون هذه ترجمة مجانية لجوهر العديد من المقالات [1،2،3،4،5] ، سيكون هناك بعض التعليمات البرمجية لـ "try".

خوارزمية سريعة
كان FAST ، الذي تم اقتراحه لأول مرة في عام 2005 في [1] ، أحد الأساليب الإرشادية الأولى للعثور على نقاط فردية ، والتي اكتسبت شعبية كبيرة بسبب كفاءتها الحسابية. لاتخاذ قرار بشأن اعتبار نقطة معينة C خاصة أم لا ، تعتبر هذه الطريقة سطوع وحدات البكسل على دائرة متمركزة في النقطة C والنصف قطر 3:

بمقارنة سطوع وحدات بكسل الدائرة مع سطوع المركز C ، نحصل على كل نتيجة من النتائج المحتملة الثلاثة (أفتح ، أغمق ، على ما يبدو):
$ inline $ \ start {array} {l} {I_p}> {I_C} + t \\ {I_p} <{I_C} -t \\ {I_C} -t <{I_p} <{I_C} + t \ end {array} $ مضمنة $
أنا هنا هو سطوع البكسل ، t هو حد سطوع محدد مسبقًا.
يتم وضع علامة على النقطة على أنها خاصة إذا كان هناك = 12 بكسل في صف أغمق أو 12 بكسل أفتح من المركز.
كما أظهرت الممارسة ، في المتوسط ، لاتخاذ قرار ، كان من الضروري التحقق من حوالي 9 نقاط. من أجل تسريع العملية ، اقترح المؤلفون أولاً التحقق من أربعة بكسل فقط بأرقام: 1 ، 5 ، 9 ، 13. إذا كان من بينها 3 بكسل أفتح أو أغمق ، يتم إجراء فحص كامل على 16 نقطة ، وإلا ، يتم وضع علامة على الفور على أنها " ليست مميزة. " هذا يقلل بشكل كبير من وقت العمل ، لاتخاذ قرار في المتوسط يكفي استطلاع حوالي 4 نقاط فقط من الدائرة.
قليلا من الشفرة الساذجة تكمن
هناالمعلمات المتغيرة (الموصوفة في الكود): نصف قطر الدائرة (يأخذ القيم 1،2،3) ، المعلمة n (في الأصل ، n = 12) ، المعلمة t. يفتح الكود ملف in.bmp ، ويعالج الصورة ، ويحفظها في out.bmp. الصور عادية 24 بت.
بناء شجرة قرارات ، شجرة FAST ، FAST-9
في عام 2006 ، في [2] ، كان من الممكن تطوير فكرة أصلية باستخدام التعلم الآلي وأشجار القرار.
يحتوي FAST الأصلي على العيوب التالية:
- يمكن تمييز العديد من وحدات البكسل المجاورة كنقاط خاصة. نحن بحاجة إلى بعض قياس "قوة" الميزة. أحد المقاييس الأولى المقترحة هو القيمة القصوى لـ t حيث لا تزال النقطة تؤخذ كنقطة خاصة.
- لا يتم تعميم اختبار سريع من 4 نقاط لـ n أقل من 12. لذلك ، على سبيل المثال ، يتم تحقيق أفضل النتائج للطريقة بصريًا مع n = 9 ، وليس 12.
- أود أيضًا تسريع الخوارزمية!
بدلاً من استخدام سلسلة من اختبارين لـ 4 و 16 نقطة ، يُقترح القيام بكل شيء بتمريرة واحدة عبر شجرة القرار. على غرار الطريقة الأصلية ، سنقارن سطوع نقطة المركز بالنقاط الموجودة في الدائرة ، ولكن بهذا الترتيب لاتخاذ القرار في أسرع وقت ممكن. وتبين أنه يمكنك اتخاذ قرار لمقارنتين فقط (2) في المتوسط.
الملح هو كيفية إيجاد الترتيب الصحيح لمقارنة النقاط. البحث باستخدام التعلم الآلي. افترض أن شخصًا ما لاحظنا في الصورة الكثير من النقاط الخاصة. سوف نستخدمها كمجموعة من أمثلة التدريب ، والفكرة هي أن تختار
بفارغ الصبر المثال الذي سيعطي أكبر قدر من المعلومات في هذه الخطوة كنقطة تالية. على سبيل المثال ، لنفترض في البداية في عينتنا وجود 5 نقاط فردية و 5 نقاط غير فردية. على شكل جهاز لوحي مثل:
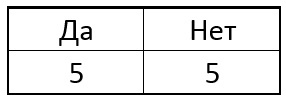
الآن نختار واحدة من وحدات البكسل في الدائرة ونقارن بين البكسل المركزي مع النقاط المحددة لجميع النقاط المفردة. اعتمادًا على سطوع البكسل المحدد بالقرب من كل نقطة معينة ، قد يكون للجدول النتيجة التالية:
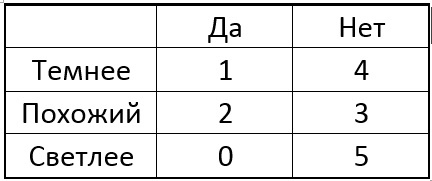
الفكرة هي اختيار نقطة p بحيث تكون الأرقام في أعمدة الجدول مختلفة قدر الإمكان. وإذا حصلنا الآن على نقطة جديدة غير معروفة حصلنا على نتيجة المقارنة "أخف" ، فيمكننا بالفعل أن نقول على الفور أن النقطة "ليست خاصة" (انظر الجدول). تستمر العملية بشكل متكرر حتى تقع نقاط فئة واحدة فقط من الفئات في كل مجموعة بعد الانقسام إلى "أفتح مثل الأفتح". اتضح شجرة من الشكل التالي:
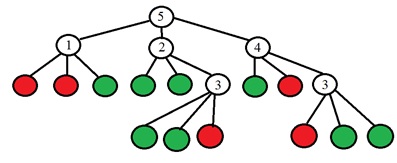
تكون القيمة الثنائية في أوراق الشجرة (الأحمر خاص ، الأخضر ليس خاصًا) ، وفي رؤوس الشجرة الأخرى هو عدد النقطة التي يجب تحليلها. بشكل أكثر تحديدًا ، في المقالة الأصلية ، يقترحون اختيار رقم النقطة عن طريق تغيير الكون. يتم حساب الانتروبيا لمجموعة النقاط:
$$ display $$ H = \ left ({c + \ overline c} \ right) {\ log _2} \ left ({c + \ overline c} \ right) - c {\ log _2} c - \ overline c {\ log _2} \ overline c $$ display $$
c هو عدد النقاط المفردة ،
$ مضمنة $ {\ bar c} $ مضمنة $ هو عدد النقاط غير المفردة للمجموعة
التغيير في الإنتروبيا بعد نقطة المعالجة p:
$$ display $$ \ Delta H = H - {H_ {dark}} - {H_ {يساوي}} - {H_ {bright}} $$ display $$
وفقًا لذلك ، يتم تحديد نقطة يكون فيها التغيير في الإنتروبيا بحد أقصى. تتوقف عملية التقسيم عندما يكون الإنتروبيا صفرًا ، مما يعني أن جميع النقاط إما فردية أو العكس بالعكس - كلها ليست خاصة. مع تنفيذ البرنامج ، بعد كل هذا ، يتم تحويل شجرة القرار التي تم العثور عليها إلى مجموعة من الإنشاءات من النوع "if-else".
الخطوة الأخيرة من الخوارزمية هي عملية قمع غير الحد الأقصى للحصول على واحدة من عدة نقاط متجاورة. يقترح المطورون استخدام المقياس الأصلي بناءً على مجموع الاختلافات المطلقة بين نقطة المركز ونقاط الدائرة في هذا النموذج:
$$ display $$ V = \ max \ left ({\ sum \ limits_ {x \ in {S_ {bright}}} {\ left | {{I_x} - {I_p}} \ right | - t، \ sum \ limits_ {x \ in {S_ {dark}}} {\ left | {{I_p} - {I_x}} \ right | - t}}} \ right) $$ display $$
هنا
$ مضمنة $ {S_ {bright}} $ مضمنة $ و
$ مضمنة $ {S_ {dark}} $ مضمنة $ على التوالي ، تكون مجموعات وحدات البكسل أفتح وأغمق ، t هي قيمة سطوع العتبة ،
$ مضمنة $ {I_p} $ مضمنة $ - سطوع البكسل المركزي ،
$ مضمنة $ {{I_x}} $ مضمنة $ - سطوع البكسل على الدائرة. يمكنك تجربة الخوارزمية باستخدام
الكود التالي . الكود مأخوذ من OpenCV ويتم تحريره من كل التبعيات ، فقط قم بتشغيله.
تحسين شجرة القرار - FAST-ER
FAST-ER [3] هو خوارزمية لنفس المؤلفين مثل المؤلف السابق ، يتم إنشاء كاشف سريع بالمثل ، كما يتم البحث عن التسلسل الأمثل للنقاط للمقارنة ، كما يتم بناء شجرة القرار ، ولكن باستخدام طريقة مختلفة - طريقة التحسين.
نحن نفهم بالفعل أنه يمكن تمثيل الكاشف على أنه شجرة قرارات. إذا كان لدينا أي معيار لمقارنة أداء الأشجار المختلفة ، فيمكننا تعظيم هذا المعيار من خلال الفرز من خلال أنواع مختلفة من الأشجار. وعلى هذا النحو ، يُقترح استخدام "التكرار".
يظهر التكرار مدى اكتشاف النقاط الفردية للمشهد من زوايا مختلفة. بالنسبة إلى زوج من الصور ، تسمى نقطة "مفيدة" إذا تم العثور عليها في إطار واحد ويمكن العثور عليها نظريًا في إطار آخر ، أي لا تحجب عناصر المشهد. وتسمى النقطة "مكرر" (مكرر) ، إذا تم العثور عليها في الإطار الثاني أيضًا. نظرًا لأن بصريات الكاميرا ليست مثالية ، فقد لا تكون النقطة على الإطار الثاني بالبكسل المحسوب ، ولكن في مكان قريب في الجوار. استغرق المطورون حيًا يبلغ 5 بكسل. نحدد التكرار على أنه نسبة عدد النقاط المتكررة إلى عدد النقاط المفيدة:
$$ display $$ R = \ frac {{{N_ {تكرار}}}} {{{N_ {مفيدة}}}} $$ display $$
للعثور على أفضل كاشف ، يتم استخدام طريقة محاكاة التلدين. هناك بالفعل
مقال ممتاز عن حبري عنه. باختصار ، جوهر الطريقة هو كما يلي:
- تم تحديد بعض الحلول الأولية للمشكلة (في حالتنا ، هذا نوع من شجرة الكاشف).
- تعتبر التكرار.
- يتم تعديل الشجرة بشكل عشوائي.
- إذا كانت النسخة المعدلة أفضل وفقًا لمعيار التكرار ، فسيتم قبول التعديل ، وإذا كان أسوأ من ذلك ، فيمكن قبوله أم لا ، مع بعض الاحتمال ، والذي يعتمد على رقم حقيقي يسمى "درجة الحرارة". كلما زاد عدد التكرارات ، تنخفض درجة الحرارة إلى الصفر.
بالإضافة إلى ذلك ، لا يتضمن بناء الكاشف الآن 16 نقطة من الدائرة ، كما كان من قبل ، ولكن 47 ، لكن المعنى لا يتغير على الإطلاق:

وفقًا لطريقة التلدين المحاكية ، نحدد ثلاث وظائف:
• دالة التكلفة ك. في حالتنا ، نستخدم التكرار كقيمة. لكن هناك مشكلة واحدة. تخيل أنه تم الكشف عن جميع النقاط في كل من الصورتين على أنها مفردة. ثم اتضح أن التكرار 100 ٪ - سخافة. من ناحية أخرى ، حتى لو وجدنا نقطة معينة في صورتين ، وتتزامن هذه النقاط - التكرار هو أيضًا 100٪ ، لكن هذا أيضًا لا يثير اهتمامنا. وبالتالي ، اقترح المؤلفون استخدام هذا كمعيار للجودة:
$$ display $$ k = \ left ({1 + {{\ left ({\ frac {{{w_r}}} {R}} \ right)} ^ 2}} \ يمين) \ left ({1 + \ frac {1} {N} \ sum \ limits_ {i = 1} {{{\ left ({\ frac {{{d_i}}} {{{w_n}}}} يمين)} ^ 2}}} \ يمين) \ يسار ({1 + {{\ يسار ({\ frac {s} {{{w_s}}}} يمين)} ^ 2}} \ يمين) $$ display $$
ص هو التكرار
$ مضمنة $ {{d_i}} $ مضمنة $ هو عدد الزوايا المكتشفة في الإطار i ، و N هو عدد الإطارات ، و s هو حجم الشجرة (عدد القمم). W هي معلمات طريقة مخصصة.]
• وظيفة تغير درجة الحرارة بمرور الوقت:
$$ display $$ T \ left (I \ right) = \ beta \ exp \ left ({- \ frac {{\ alpha I}} {{{I _ {\ max}}}} \ right) $$ display $$
أين
$ inline $ \ alpha ، \ beta $ inline $ هي المعاملات ، إيماكس هو عدد التكرارات.
• وظيفة تولد حلا جديدا. تقوم الخوارزمية بإجراء تعديلات عشوائية على الشجرة. أولاً ، حدد بعض الذروة. إذا كان الرأس المحدد ورقة من شجرة ، فعندئذٍ باحتمال متساوٍ نقوم بما يلي:
- استبدل الرأس بشجرة فرعية عشوائية بالعمق 1
- تغيير فئة هذه الورقة (النقاط غير المفردية)
إذا لم تكن هذه ورقة:
- استبدل رقم النقطة المختبرة برقم عشوائي من 0 إلى 47
- استبدل قمة الرأس بورقة مع فئة عشوائية
- قم بتبديل شريحتين فرعيتين من هذا الرأس
الاحتمال P لقبول التغيير عند التكرار I هو:
$ inline $ P = \ exp \ left ({\ frac {{k \ left ({i - 1} \ right) - k \ left (i \ right)}} {T}} \ right) $ مضمنة $
k هي دالة التكلفة ، T هي درجة الحرارة ، i هي رقم التكرار.
تسمح هذه التعديلات للشجرة بنمو الشجرة وتقليلها. الطريقة عشوائية ولا تضمن الحصول على أفضل شجرة. قم بتشغيل الطريقة عدة مرات ، واختيار أفضل حل. في المقالة الأصلية ، على سبيل المثال ، يتم تشغيلها 100 مرة لكل 100000 تكرار لكل منها ، الأمر الذي يستغرق 200 ساعة من وقت المعالج. كما تظهر النتائج ، فإن النتيجة أفضل من شجرة FAST ، خاصة في الصور الصاخبة.
واصف مختصر
بعد العثور على النقاط المفردة ، يتم حساب واصفيها ، أي مجموعات من السمات التي تميز حي كل نقطة منفردة. BRIEF [4] هو واصف إرشادي سريع ، مبني من 256 مقارنة ثنائية بين سطوع البكسل في صورة
ضبابية . يتم تحديد الاختبار الثنائي بين النقطتين x و y على النحو التالي:
$$ display $$ \ tau \ left ({P، x، y} \ right): = \ left \ {{\ start {array} {* {20} {c}} {1: p \ left (x \ يمين) <p \ left (y \ right)} \\ {0: p \ left (x \ right) \ ge p \ left (y \ right)} \ end {array}} \ right. $$ display $$

في المقالة الأصلية ، تم النظر في عدة طرق لاختيار نقاط لمقارنات ثنائية. كما اتضح ، فإن إحدى أفضل الطرق هي تحديد النقاط عشوائيًا باستخدام توزيع غوسي حول بكسل مركزي. يتم تحديد هذا التسلسل العشوائي للنقاط مرة واحدة ولا يتغير أكثر. حجم الجوار المدروس هو 31x31 بكسل ، وفتحة التمويه 5.
إن الواصف الثنائي الناتج مقاوم للتغيرات في الإضاءة ، وتشويه المنظور ، ويتم حسابه ومقارنته بسرعة ، ولكنه غير مستقر للغاية للدوران في مستوى الصورة.
ORB - سريع وفعال
تم تطوير كل هذه الأفكار باستخدام خوارزمية ORB (موجزة سريعة وموجزة) [5] ، حيث جرت محاولة لتحسين أداء BRIEF أثناء تدوير الصورة. يُقترح أولاً حساب اتجاه النقطة المفردة ثم إجراء مقارنات ثنائية وفقًا لهذا التوجه. تعمل الخوارزمية على النحو التالي:
1) تم الكشف عن نقاط الميزة باستخدام شجرة FAST السريعة في الصورة الأصلية وفي العديد من الصور من الهرم المصغر.
2) بالنسبة للنقاط المكتشفة ، يتم حساب مقياس هاريس ، ويتم استبعاد المرشحين ذوي القيمة المنخفضة لقياس هاريس.
3) يتم حساب زاوية الاتجاه للنقطة المفردة. لهذا ، يتم حساب لحظات السطوع لحي نقطة المفرد أولاً:
$ inline $ {m_ {pq}} = \ sum \ limits_ {x، y} {{x ^ p} {y ^ q} I \ left ({x، y} \ right)} $ مضمنة $
إحداثيات س ، ص - بكسل ، I - السطوع. ثم زاوية توجيه النقطة المفردة:
$ inline $ \ theta = {\ rm {atan2}} \ left ({{m_ {01}} ، {m_ {10}}} \ right) $ مضمنة $
كل هذا ، أطلق المؤلفون على "التوجه المركزي". نتيجة لذلك ، نحصل على اتجاه معين لحي النقطة المفردة.
4) عند وجود زاوية الاتجاه للنقطة المفردة ، يدور تسلسل النقاط للمقارنات الثنائية في واصف BRIEF وفقًا لهذه الزاوية ، على سبيل المثال:
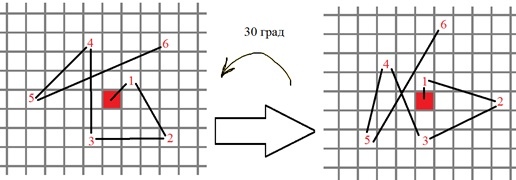
بشكل أكثر رسمية ، يتم حساب المواضع الجديدة لنقاط الاختبار الثنائية على النحو التالي:
$$ display $$ \ left ({\ start {array} {* {20} {c}} {{x_i} '} \\ {{y_i}'} \ end {array}} \ right) = R \ left (\ theta \ right) \ cdot \ left ({\ start {array} {* {20} {c}} {{x_i}} \\ {{y_i}} \ end {array}} \ right) $$ display $$
5) بناءً على النقاط المستلمة ، يتم حساب واصف BRIEF الثنائي
وهذا ليس كل شيء! هناك تفاصيل أخرى مثيرة للاهتمام في ORB تتطلب شرحًا منفصلاً. والحقيقة هي أنه في الوقت الذي "ندير" جميع النقاط المفردة إلى زاوية صفرية ، فإن الاختيار العشوائي للمقارنات الثنائية في الواصف يتوقف عن كونه عشوائيًا. هذا يؤدي إلى حقيقة أن بعض المقارنات الثنائية تتحول أولاً إلى بعضها البعض ، وثانيًا ، لم يعد متوسطها يساوي 0.5 (1 أخف ، 0 أغمق عندما كان الاختيار عشوائيًا ، ثم كان المتوسط 0.5) كل هذا يقلل بشكل كبير من قدرة الواصف على تمييز النقاط المفردة فيما بينها.
الحل - تحتاج إلى تحديد الاختبارات الثنائية "الصحيحة" في عملية التعلم ، هذه الفكرة تضفي نفس النكهة مثل تدريب الشجرة لخوارزمية FAST-9. لنفترض أن لدينا مجموعة من النقاط الفردية التي تم العثور عليها بالفعل. فكر في جميع الخيارات الممكنة للاختبارات الثنائية. إذا كان الحي 31 × 31 ، وكان الاختبار الثنائي عبارة عن زوج من مجموعات فرعية 5 × 5 (بسبب التعتيم) ، فهناك الكثير من الخيارات لاختيار N = (31-5) ^ 2. خوارزمية البحث للاختبارات "الجيدة" هي كما يلي:
- نحسب نتيجة جميع الاختبارات لجميع النقاط الفردية
- رتّب المجموعة الكاملة من الاختبارات حسب بعدها عن المتوسط 0.5
- إنشاء قائمة تحتوي على الاختبارات "الجيدة" المحددة ، دعنا ندعو قائمة R.
- أضف إلى R الاختبار الأول من المجموعة التي تم فرزها
- نأخذ الاختبار التالي ونقارنه بجميع الاختبارات في R. إذا كان الارتباط أكبر من العتبة ، فإننا نتجاهل الاختبار الجديد ، وإلا فإننا نضيفه.
- كرر الخطوة 5 حتى نكتب العدد المطلوب من الاختبارات.
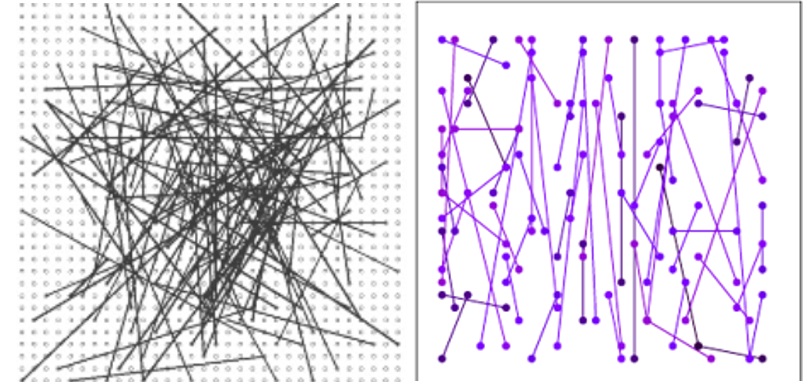
وتبين أنه تم اختيار الاختبارات بحيث ، من ناحية ، يكون متوسط قيمة هذه الاختبارات أقرب ما يمكن إلى 0.5 ، من ناحية أخرى ، بحيث يكون الارتباط بين الاختبارات المختلفة ضئيلاً. وهذا ما نحتاجه. قارن كيف كانت وكيف أصبحت:
لحسن الحظ ، يتم تنفيذ خوارزمية ORB في مكتبة OpenCV في فئة cv :: ORB. أستخدم الإصدار 2.4.13. يقبل مُنشئ الصنف المعلمات التالية:
nfeatures - الحد الأقصى لعدد النقاط الفردية
scaleFactor - مضاعف لهرم الصور ، أكثر من واحد. تطبق القيمة 2 الهرم الكلاسيكي.
nlevels - عدد المستويات في هرم الصور.
edgeThreshold - عدد وحدات البكسل عند حدود الصورة حيث لا يتم الكشف عن النقاط المفردة.
المستوى الأول - اترك الصفر.
WTA_K - عدد النقاط المطلوبة لعنصر واحد من الواصف. إذا كان يساوي 2 ، فسيتم مقارنة سطوع وحدتي بكسل تم اختيارهما عشوائيًا. هذا هو المطلوب.
ScoreType - إذا كان 0 ، فسيتم استخدام هاريس كمقياس للميزات ، وإلا - مقياس FAST (بناءً على مجموع وحدات اختلافات السطوع عند نقاط الدائرة). مقياس FAST أقل استقرارًا بقليل ، ولكنه أسرع.
patchSize - حجم الحي الذي يتم اختيار وحدات البكسل العشوائية منه للمقارنة. تبحث الشفرة وتقارن النقاط المفردة في صورتين ، "templ.bmp" و "img.bmp"
كودcv::Mat img_object=cv::imread("templ.bmp", 0); std::vector<cv::KeyPoint> keypoints_object, keypoints_scene; cv::Mat descriptors_object, descriptors_scene; cv::ORB orb(500, 1.2, 4, 31, 0, 2, 0, 31);
إذا ساعد شخص ما على فهم جوهر الخوارزميات ، فهذا ليس عبثا. إلى كل هبر.
المراجع:
1.
دمج النقاط والخطوط للتتبع عالي الأداء2.
التعلم الآلي للكشف عن الزاوية عالية السرعة3.
أسرع وأفضل: نهج التعلم الآلي لاكتشاف الزوايا4.
موجز: الميزات الابتدائية المستقلة القوية الثنائية5.
ORB: بديل فعال لـ SIFT أو SURF