بعد قراءة مقالة "
الترجمة الآلية العصبية من Google " ، تذكرت أحدث ترجمة آلية ملحمية من Google قيد التشغيل على الإنترنت مؤخرًا. من لا يستطيع الانتظار كثيرًا ، ننتقل فورًا إلى نهاية المقالة.
حسنًا ، بالنسبة للمبتدئين ، نظرية صغيرة:
GNMT هو نظام الترجمة الآلية العصبية (
NMT ) من Google الذي يستخدم شبكة عصبية (
ANN ) لزيادة دقة وسرعة الترجمة ، وبشكل خاص لإنشاء خيارات ترجمة أفضل وأكثر طبيعية للنص في ترجمة Google.
في حالة GNMT ، هذه هي طريقة الترجمة المعتمدة على الأمثلة (
EBMT ) ، أي يتعلم
ANN الأساسي للطريقة من ملايين أمثلة الترجمة ، وخلافًا للأنظمة الأخرى ، تسمح هذه الطريقة بما يسمى
الترجمة بدون طلقة ، أي الترجمة من لغة إلى أخرى دون أمثلة صريحة لهذا الزوج من اللغات المحددة في عملية التعلم (في عينة التدريب).
 التين. 1. الترجمة الصفرية
التين. 1. الترجمة الصفريةعلاوة على ذلك ، تم تصميم GNMT في المقام الأول لتحسين ترجمة العبارات والجمل ، لأن فقط في الترجمة السياقية ، لا يمكنك استخدام النسخة الحرفية للترجمة ، وغالبًا ما يتم ترجمة الجملة بشكل مختلف تمامًا.
بالإضافة إلى ذلك ، بالعودة إلى الترجمة الفورية ، تحاول Google إبراز بعض المكونات الشائعة الصالحة للعديد من اللغات في وقت واحد (عند البحث عن التبعيات وعند بناء علاقات الجمل والجمل).
على سبيل المثال ، في الشكل 2 ، يظهر هذا "مجتمع" interlingua بين جميع الأزواج الممكنة لليابانية والكورية والإنجليزية.
 التين. 2. إنترلينغوا. عرض ثلاثي الأبعاد لبيانات الشبكة للغات اليابانية والكورية والإنجليزية
التين. 2. إنترلينغوا. عرض ثلاثي الأبعاد لبيانات الشبكة للغات اليابانية والكورية والإنجليزية .
يوضح الجزء (أ) "الهندسة" العامة لهذه الترجمات ، حيث يتم تلوين النقاط بالمعنى (ولون نفس المعنى نفسه في عدة أزواج من اللغات).
يظهر الجزء (ب) زيادة في إحدى المجموعات ، بينما يظهر الجزء © في ألوان اللغة الأصلية.
يستخدم GNMT التعلم العميق لـ
ANN (
DNN ) ، والذي ، من خلال ملايين الأمثلة ، يجب أن يحسن جودة الترجمة ، ويطبق تقريبًا ملخصًا سياقيًا لخيار الترجمة الأنسب. بشكل تقريبي ، يختار أفضل نتيجة ، بمعنى أنسب قواعد اللغة البشرية ، مع الأخذ بعين الاعتبار القواسم المشتركة لبناء الروابط والعبارات والجمل لعدة لغات (أي إبراز وتعليم نموذج أو طبقات interlingua بشكل منفصل).
ومع ذلك ، عادة ما تعتمد DNN ، في كل من عملية التعلم وعملية العمل ، على الاستدلال الإحصائي (الاحتمالي) ونادراً ما تكون مرتبطة بخوارزميات غير احتمالية إضافية. على سبيل المثال لتقييم أفضل نتيجة ممكنة خرجت من المتغير ، سيتم تحديد الخيار الأفضل (المحتمل) من الناحية الإحصائية.
كل هذا ، بطبيعة الحال ، يعتمد بشكل إضافي على جودة عينة التدريب (و / أو جودة الخوارزميات في حالة نموذج التعلم الذاتي).
بالنظر إلى طريقة الترجمة الفورية وتذكر بعض المكونات المشتركة (interlingua) ، في وجود بعض الارتباط المنطقي العميق الإيجابي للغة واحدة ، وغياب المكونات السلبية للغات أخرى ، ظهر بعض الأخطاء المجردة في عملية التعلم ، ونتيجة لذلك ، من المرجح أن تتكرر ترجمة عبارة معينة للغة واحدة للغات أخرى أو حتى أزواج اللغات.
في الواقع ملحمة جديدة تفشل
جميع الصور قابلة للنقر (كدليل على صفحة ترجمة Google المقابلة).الألمانية: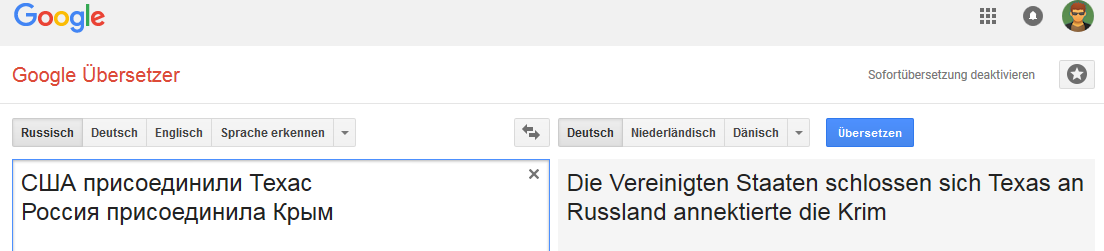 الإنجليزية:
الإنجليزية: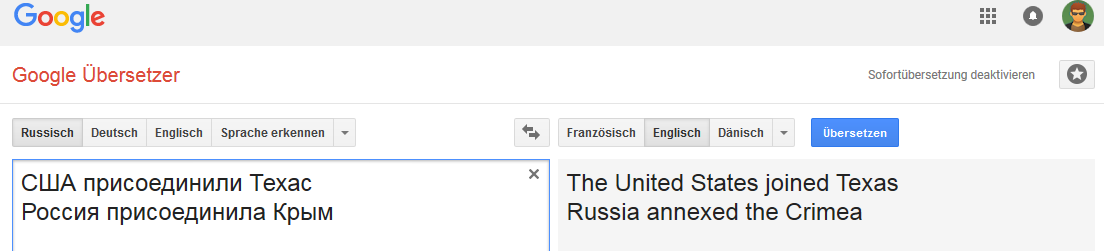 الهولندية:
الهولندية: الدانماركية:
الدانماركية: الفرنسية:
الفرنسية:
إلخ.
بدلا من الاستنتاج
الاتصال مستقر لكلمة روسيا (بمعنى أنه عندما يتم استبدال روسيا ، على سبيل المثال ، بالإمبراطورية الروسية ، يتغير خيار "النقل").
وهو ليس مستقرًا جدًا مع بعض التغييرات في العبارات غير النموذجية للترجمة إلى الإنجليزية ، ولكنها شائعة ، على سبيل المثال ، للروسية والألمانية والهولندية.
هذا للأسف بعيد عن الحالة الوحيدة والإنترنت مليء بجميع أنواع أخطاء الترجمة من Google.
ويبدو لي أن جزءًا كبيرًا من الأخطاء الحالية يتجلى بسبب مجموعة من العوامل المتعددة ، بدءًا من جودة عينة التدريب إلى جودة خوارزميات التحليل الدلالي والصرفي للغة معينة (ونموذج التعلم على وجه الخصوص).
ذات مرة ، اقترح زميل المشاركة في تحدي Google Text Normalization Challenge (للروسية والإنجليزية) على kaggle ...
قبل الموافقة ، أجريت بعد ذلك تحليلاً صغيراً لجودة عينة اختبار التدريب لجميع فئات الرموز لكلتا اللغتين ... ونتيجة لذلك رفضت المشاركة على الإطلاق ، لأنه كلما حفرت أكثر ، كلما كان الشعور أقوى بأن المنافسة ستكون مثل اليانصيب أو الذي سيفوز ستتمكن بكل دقة من تكرار جميع الأخطاء التي ارتكبت أثناء الإنشاء شبه اليدوي لمجموعة تدريب Google.
حتى أنني أردت كتابة مقال حول موضوع "كيفية رمي 50K بسهولة ..." ، ولكن الوقت - لا بأس.
إذا كان أي شخص مهتمًا فجأة - سأحاول اقتطاعه قليلاً.
[UPD] لماذا هذا ملف بالفعل. دون تشتيت كلمات الأغاني ، فإن النص الفرعي "السياسي" وكل أنواع المحاولات لتبرير "الشخص سوف يترجم بهذه الطريقة" ، إلخ.
1. هذه ترجمة خاطئة. النقطة.
2. في هذه الحالة التوضيحية ، يُظهر GNMT غيابًا تامًا لأي نموذج تصنيف (بمعنى
CADM ، حيث يجب على Google التألق ، لأن لديهم الكثير من البيانات من كل مكان). فقط بقدر ما تكون الموضوعات في كلتا الحالتين دول / دول ، والملاحق هي كيانات جغرافية (إقليم).
حتى القاعدة الأكثر غباءً من بعض تصنيفات K-nn الغامضة لن ترتكب مثل هذا الخطأ. نحن صامتون بالفعل حول الخوارزميات الحديثة لتصنيف وبناء العلاقات (الدلالية).
كما يقول المثل لا شيء شخصي ، الرياضيات البسيطة ... حسنًا ، إذا قررت Google بشكل عشوائي أن تغذي شبكته بمقاطع من الصحافة الشعبية ، فعندئذ لدي أخبار سيئة له.
ملاحظة ، وكما قال لي أحد الاستاذين ذات مرة ، "من الصعب جدًا في بعض الأحيان إثبات نقار الخشب بأنه نقار الخشب ، خاصة إذا كان متأكدًا من أنه أذكى من الأستاذ".