في مهرجان البيانات 2 في مينسك ، لاحظ فلاديمير إيغلوفيكوف ، مهندس الرؤية الآلية في Lyft ،
تمامًا أن أفضل طريقة لتعلم علوم البيانات هي المشاركة في المسابقات ، وتشغيل حلول الآخرين ، ودمجها ، وتحقيق النتائج وإظهار عملك. في الواقع ، في إطار هذا النموذج ، قررت أن أنظر عن كثب في
مسابقة تقييم مخاطر الائتمان الرئيسية وأشرح (للمبتدئين والعلماء وقبل كل شيء بنفسي) كيفية تحليل مجموعات البيانات هذه بشكل صحيح وبناء نماذج لهم.
(صورة
من هنا )

مجموعة الائتمان الرئيسية هي مجموعة من البنوك والمنظمات الائتمانية غير المصرفية التي تجري عمليات في 11 دولة (بما في ذلك روسيا كبنك الائتمان والتمويل المنزلي ذ.م.م). الغرض من المسابقة هو إنشاء منهجية لتقييم الجدارة الائتمانية للمقترضين الذين ليس لديهم تاريخ ائتماني. وهو ما يبدو نبيلًا إلى حد ما - غالبًا ما لا يتمكن المقترضون من هذه الفئة من الحصول على أي ائتمان من البنك ويضطرون إلى اللجوء إلى المحتالين والقروض الصغيرة. من المثير للاهتمام أن العميل لم يحدد متطلبات الشفافية وقابلية تفسير النموذج (كما هو الحال عادة مع البنوك) ، يمكنك استخدام أي شيء ، حتى الشبكة العصبية.
تتكون عينة التدريب من أكثر من 300 ألف سجل ، وهناك الكثير من العلامات - 122 ، من بينها العديد من العلامات الفئوية (غير العددية). تصف اللافتات المقترض بتفاصيل كافية ، وصولاً إلى المواد التي تصنع منها جدران منزله. جزء من البيانات موجود في 6 جداول إضافية (بيانات عن مكتب الائتمان ورصيد بطاقة الائتمان والقروض السابقة) ، ويجب أيضًا معالجة هذه البيانات بطريقة أو بأخرى وتحميلها على الجداول الرئيسية.
تبدو المنافسة كمهمة تصنيف قياسية (1 في حقل TARGET يعني أي صعوبات في الدفع ، 0 يعني عدم وجود صعوبات). ومع ذلك ، فليس من 0/1 ما ينبغي توقعه ، ولكن احتمالية المشاكل (التي ، بالمناسبة ، يمكن حلها بسهولة من خلال طرق التنبؤ الاحتمالية للتنبؤ بها التي تمتلكها جميع النماذج المعقدة).
للوهلة الأولى ، تعد مجموعة البيانات معيارًا جيدًا لمهام التعلم الآلي ، وقد قدم المنظمون جائزة كبيرة بقيمة 70 ألف دولار ، ونتيجة لذلك ، يشارك أكثر من 2600 فريق في المسابقة اليوم ، والمعركة في الألف من المئة. ومع ذلك ، من ناحية أخرى ، تعني هذه الشعبية أن مجموعة البيانات قد تمت دراستها صعودًا وهبوطًا وتم إنشاء العديد من النوى باستخدام EDA جيد (تحليلات البيانات الاستكشافية - البحث وتحليل البيانات في الشبكة ، بما في ذلك الرسوم البيانية) ، هندسة الميزات (العمل مع السمات) ومع نماذج مثيرة للاهتمام. (Kernel هو مثال على العمل مع مجموعة بيانات يمكن لأي شخص وضعها لعرض عملهم على kugglers الآخرين.)
تستحق الألباب الاهتمام:
للعمل مع البيانات ، يوصى عادةً بالخطة التالية ، والتي سنحاول اتباعها.
- فهم المشكلة والتعرف على البيانات
- تنظيف وتنسيق البيانات
- جمعية الإمارات للغوص
- نموذج أساسي
- تحسين النموذج
- تفسير النموذج
في هذه الحالة ، يجب أن تأخذ في الاعتبار حقيقة أن البيانات واسعة جدًا ولا يمكن التغلب عليها على الفور ، فمن المنطقي التصرف على مراحل.
لنبدأ باستيراد المكتبات التي نحتاجها في التحليل للعمل مع البيانات في شكل جداول ، وإنشاء الرسوم البيانية ، والعمل مع المصفوفات.
import pandas as pd import matplotlib.pyplot as plt import numpy as np import seaborn as sns %matplotlib inline
قم بتنزيل البيانات. دعونا نرى ما لدينا جميعا. بالمناسبة ، هذا الموقع في دليل "../input/" مرتبط بمتطلبات وضع حباتك على Kaggle.
import os PATH="../input/" print(os.listdir(PATH))
['application_test.csv', 'application_train.csv', 'bureau.csv', 'bureau_balance.csv', 'credit_card_balance.csv', 'HomeCredit_columns_description.csv', 'installments_payments.csv', 'POS_CASH_balance.csv', 'previous_application.csv']هناك 8 جداول بالبيانات (لا تحسب الجدول HomeCredit_columns_description.csv ، الذي يحتوي على وصف للحقول) ، وهي مترابطة فيما يلي:
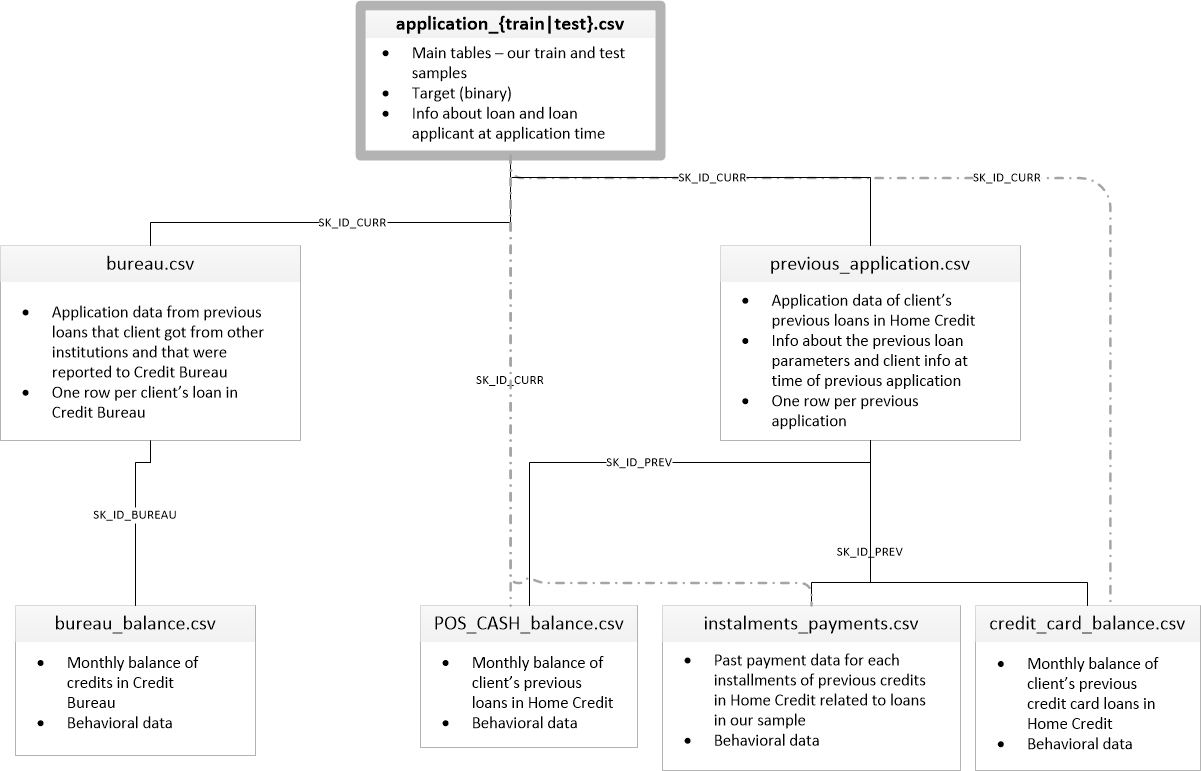
application_train / application_test: بيانات رئيسية ، يتم تحديد المقترض بواسطة الحقل SK_ID_CURR
المكتب: بيانات القروض السابقة من مؤسسات ائتمانية أخرى من مكتب ائتمان
bureau_balance: بيانات شهرية عن قروض المكتب السابقة. كل سطر هو شهر استخدام القرض
previous_application: التطبيقات السابقة للحصول على قروض في الائتمان المنزلي ، لكل منها حقل فريد SK_ID_PREV
POS_CASH_BALANCE: بيانات شهرية عن القروض في الائتمان السكني مع إصدار النقد والقروض لشراء السلع
credit_card_balance: بيانات رصيد بطاقة الائتمان الشهرية في رصيد المنزل
الأقساط: تاريخ السداد للقروض السابقة في الائتمان المنزلي.
دعونا نركز أولاً على مصدر البيانات الرئيسي ونرى ما هي المعلومات التي يمكن استخلاصها منها والنماذج التي نبنيها. قم بتنزيل البيانات الأساسية.
- app_train = pd.read_csv (PATH + 'application_train.csv'،)
- app_test = pd.read_csv (PATH + 'application_test.csv'،)
- print ("تنسيق مجموعة التدريب:"، app_train.shape)
- طباعة ("تنسيق عينة الاختبار:" ، app_test.shape)
- شكل عينة التدريب: (307511 ، 122)
- تنسيق عينة الاختبار: (48744 ، 121)
في المجموع ، لدينا 307 آلاف سجل و 122 علامة في عينة التدريب و 49 ألف سجل و 121 علامة في الاختبار. من الواضح أن التناقض يرجع إلى حقيقة أنه لا توجد سمة الهدف TARGET في عينة الاختبار ، وسوف نتوقع ذلك.
دعونا نلقي نظرة فاحصة على البيانات
pd.set_option('display.max_columns', None)
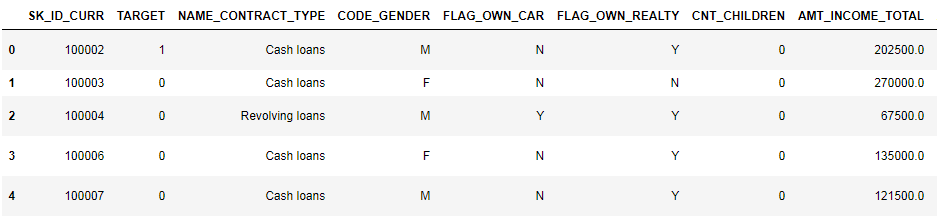
(أول 8 أعمدة معروضة)
من الصعب جدًا مشاهدة البيانات بهذا التنسيق. دعونا نلقي نظرة على قائمة الأعمدة:
app_train.info(max_cols=122)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 307511 entries, 0 to 307510
Data columns (total 122 columns):
SK_ID_CURR 307511 non-null int64
TARGET 307511 non-null int64
NAME_CONTRACT_TYPE 307511 non-null object
CODE_GENDER 307511 non-null object
FLAG_OWN_CAR 307511 non-null object
FLAG_OWN_REALTY 307511 non-null object
CNT_CHILDREN 307511 non-null int64
AMT_INCOME_TOTAL 307511 non-null float64
AMT_CREDIT 307511 non-null float64
AMT_ANNUITY 307499 non-null float64
AMT_GOODS_PRICE 307233 non-null float64
NAME_TYPE_SUITE 306219 non-null object
NAME_INCOME_TYPE 307511 non-null object
NAME_EDUCATION_TYPE 307511 non-null object
NAME_FAMILY_STATUS 307511 non-null object
NAME_HOUSING_TYPE 307511 non-null object
REGION_POPULATION_RELATIVE 307511 non-null float64
DAYS_BIRTH 307511 non-null int64
DAYS_EMPLOYED 307511 non-null int64
DAYS_REGISTRATION 307511 non-null float64
DAYS_ID_PUBLISH 307511 non-null int64
OWN_CAR_AGE 104582 non-null float64
FLAG_MOBIL 307511 non-null int64
FLAG_EMP_PHONE 307511 non-null int64
FLAG_WORK_PHONE 307511 non-null int64
FLAG_CONT_MOBILE 307511 non-null int64
FLAG_PHONE 307511 non-null int64
FLAG_EMAIL 307511 non-null int64
OCCUPATION_TYPE 211120 non-null object
CNT_FAM_MEMBERS 307509 non-null float64
REGION_RATING_CLIENT 307511 non-null int64
REGION_RATING_CLIENT_W_CITY 307511 non-null int64
WEEKDAY_APPR_PROCESS_START 307511 non-null object
HOUR_APPR_PROCESS_START 307511 non-null int64
REG_REGION_NOT_LIVE_REGION 307511 non-null int64
REG_REGION_NOT_WORK_REGION 307511 non-null int64
LIVE_REGION_NOT_WORK_REGION 307511 non-null int64
REG_CITY_NOT_LIVE_CITY 307511 non-null int64
REG_CITY_NOT_WORK_CITY 307511 non-null int64
LIVE_CITY_NOT_WORK_CITY 307511 non-null int64
ORGANIZATION_TYPE 307511 non-null object
EXT_SOURCE_1 134133 non-null float64
EXT_SOURCE_2 306851 non-null float64
EXT_SOURCE_3 246546 non-null float64
APARTMENTS_AVG 151450 non-null float64
BASEMENTAREA_AVG 127568 non-null float64
YEARS_BEGINEXPLUATATION_AVG 157504 non-null float64
YEARS_BUILD_AVG 103023 non-null float64
COMMONAREA_AVG 92646 non-null float64
ELEVATORS_AVG 143620 non-null float64
ENTRANCES_AVG 152683 non-null float64
FLOORSMAX_AVG 154491 non-null float64
FLOORSMIN_AVG 98869 non-null float64
LANDAREA_AVG 124921 non-null float64
LIVINGAPARTMENTS_AVG 97312 non-null float64
LIVINGAREA_AVG 153161 non-null float64
NONLIVINGAPARTMENTS_AVG 93997 non-null float64
NONLIVINGAREA_AVG 137829 non-null float64
APARTMENTS_MODE 151450 non-null float64
BASEMENTAREA_MODE 127568 non-null float64
YEARS_BEGINEXPLUATATION_MODE 157504 non-null float64
YEARS_BUILD_MODE 103023 non-null float64
COMMONAREA_MODE 92646 non-null float64
ELEVATORS_MODE 143620 non-null float64
ENTRANCES_MODE 152683 non-null float64
FLOORSMAX_MODE 154491 non-null float64
FLOORSMIN_MODE 98869 non-null float64
LANDAREA_MODE 124921 non-null float64
LIVINGAPARTMENTS_MODE 97312 non-null float64
LIVINGAREA_MODE 153161 non-null float64
NONLIVINGAPARTMENTS_MODE 93997 non-null float64
NONLIVINGAREA_MODE 137829 non-null float64
APARTMENTS_MEDI 151450 non-null float64
BASEMENTAREA_MEDI 127568 non-null float64
YEARS_BEGINEXPLUATATION_MEDI 157504 non-null float64
YEARS_BUILD_MEDI 103023 non-null float64
COMMONAREA_MEDI 92646 non-null float64
ELEVATORS_MEDI 143620 non-null float64
ENTRANCES_MEDI 152683 non-null float64
FLOORSMAX_MEDI 154491 non-null float64
FLOORSMIN_MEDI 98869 non-null float64
LANDAREA_MEDI 124921 non-null float64
LIVINGAPARTMENTS_MEDI 97312 non-null float64
LIVINGAREA_MEDI 153161 non-null float64
NONLIVINGAPARTMENTS_MEDI 93997 non-null float64
NONLIVINGAREA_MEDI 137829 non-null float64
FONDKAPREMONT_MODE 97216 non-null object
HOUSETYPE_MODE 153214 non-null object
TOTALAREA_MODE 159080 non-null float64
WALLSMATERIAL_MODE 151170 non-null object
EMERGENCYSTATE_MODE 161756 non-null object
OBS_30_CNT_SOCIAL_CIRCLE 306490 non-null float64
DEF_30_CNT_SOCIAL_CIRCLE 306490 non-null float64
OBS_60_CNT_SOCIAL_CIRCLE 306490 non-null float64
DEF_60_CNT_SOCIAL_CIRCLE 306490 non-null float64
DAYS_LAST_PHONE_CHANGE 307510 non-null float64
FLAG_DOCUMENT_2 307511 non-null int64
FLAG_DOCUMENT_3 307511 non-null int64
FLAG_DOCUMENT_4 307511 non-null int64
FLAG_DOCUMENT_5 307511 non-null int64
FLAG_DOCUMENT_6 307511 non-null int64
FLAG_DOCUMENT_7 307511 non-null int64
FLAG_DOCUMENT_8 307511 non-null int64
FLAG_DOCUMENT_9 307511 non-null int64
FLAG_DOCUMENT_10 307511 non-null int64
FLAG_DOCUMENT_11 307511 non-null int64
FLAG_DOCUMENT_12 307511 non-null int64
FLAG_DOCUMENT_13 307511 non-null int64
FLAG_DOCUMENT_14 307511 non-null int64
FLAG_DOCUMENT_15 307511 non-null int64
FLAG_DOCUMENT_16 307511 non-null int64
FLAG_DOCUMENT_17 307511 non-null int64
FLAG_DOCUMENT_18 307511 non-null int64
FLAG_DOCUMENT_19 307511 non-null int64
FLAG_DOCUMENT_20 307511 non-null int64
FLAG_DOCUMENT_21 307511 non-null int64
AMT_REQ_CREDIT_BUREAU_HOUR 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_DAY 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_WEEK 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_MON 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_QRT 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_YEAR 265992 non-null float64
dtypes: float64(65), int64(41), object(16)
memory usage: 286.2+ MBاسترجع التعليقات التوضيحية التفصيلية حسب الحقل في ملف HomeCredit_columns_description. كما ترى من المعلومات ، جزء من البيانات غير مكتمل وجزء فئوي ، يتم عرضها ككائن. معظم النماذج لا تعمل مع هذه البيانات ، سيتعين علينا فعل شيء معها. على هذا ، يمكن اعتبار التحليل الأولي مكتملاً ، وسوف ننتقل مباشرةً إلى جمعية الإمارات للغوص
تحليل البيانات الاستكشافية أو استخراج البيانات الأولية
في عملية EDA ، نحسب الإحصائيات الأساسية ونرسم الرسوم البيانية للعثور على الاتجاهات والشذوذ والأنماط والعلاقات داخل البيانات. هدف EDA هو معرفة ما يمكن أن تخبره البيانات. عادة ، ينتقل التحليل من الأعلى إلى الأسفل - من نظرة عامة إلى دراسة المناطق الفردية التي تجذب الانتباه وقد تكون ذات فائدة. بعد ذلك ، يمكن استخدام هذه النتائج في بناء النموذج ، واختيار الميزات له وتفسيره.
التوزيع المتغير الهدف
app_train.TARGET.value_counts()
0 282686
1 24825
Name: TARGET, dtype: int64 plt.style.use('fivethirtyeight') plt.rcParams["figure.figsize"] = [8,5] plt.hist(app_train.TARGET) plt.show()
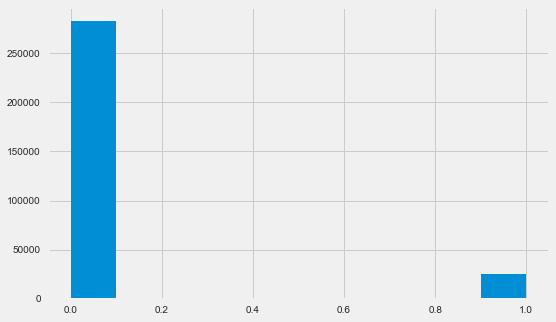
دعني أذكرك أن 1 تعني مشاكل من أي نوع مع عودة ، 0 لا تعني مشاكل. كما ترون ، ليس لدى المقترضين بشكل رئيسي أي مشاكل في السداد ، تبلغ حصة الإشكالية حوالي 8 ٪. هذا يعني أن الفصول غير متوازنة وقد يلزم أخذ ذلك في الاعتبار عند بناء النموذج.
البحث عن البيانات المفقودة
لقد رأينا أن نقص البيانات كبير للغاية. دعونا نرى بمزيد من التفصيل أين وماذا ينقص.
122 .
67 .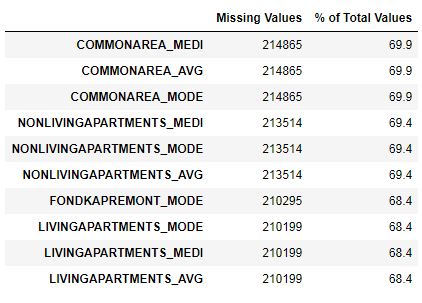
بتنسيق رسومي:
plt.style.use('seaborn-talk') fig = plt.figure(figsize=(18,6)) miss_train = pd.DataFrame((app_train.isnull().sum())*100/app_train.shape[0]).reset_index() miss_test = pd.DataFrame((app_test.isnull().sum())*100/app_test.shape[0]).reset_index() miss_train["type"] = "" miss_test["type"] = "" missing = pd.concat([miss_train,miss_test],axis=0) ax = sns.pointplot("index",0,data=missing,hue="type") plt.xticks(rotation =90,fontsize =7) plt.title(" ") plt.ylabel(" %") plt.xlabel("")
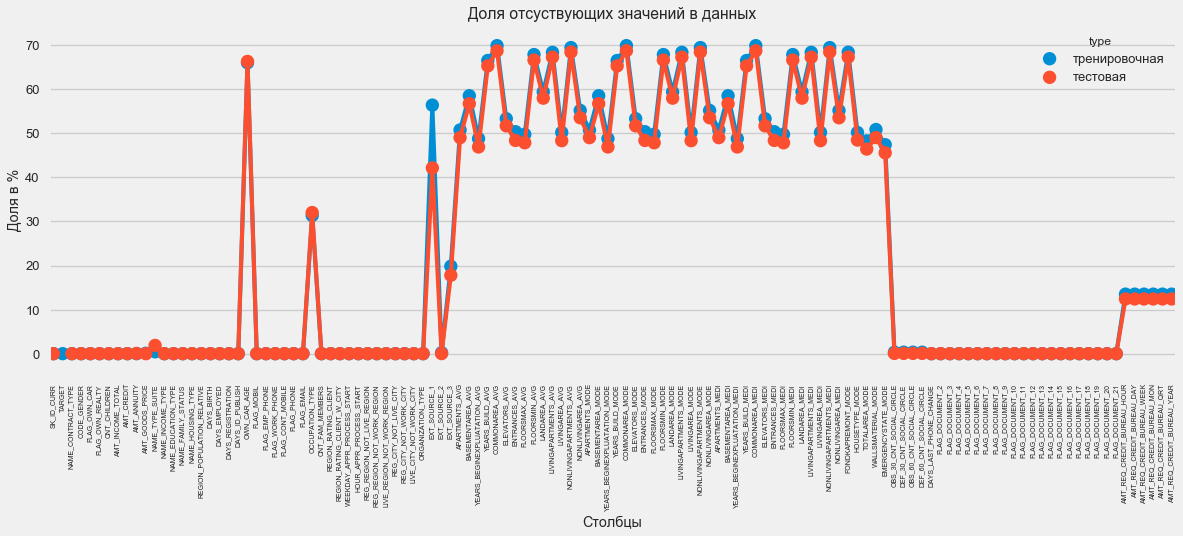
هناك العديد من الإجابات على السؤال "ماذا تفعل بكل هذا". يمكنك ملئه بالأصفار ، يمكنك استخدام القيم المتوسطة ، يمكنك فقط حذف الأسطر بدون المعلومات الضرورية. كل هذا يتوقف على النموذج الذي نخطط لاستخدامه ، حيث يتعامل بعضها بشكل مثالي مع القيم المفقودة. بينما نتذكر هذه الحقيقة ونترك كل شيء كما هو.
أنواع الأعمدة والترميز القاطع
كما نتذكر. جزء من الأعمدة من نوع الكائن ، أي أنه ليس له قيمة عددية ، ولكنه يعكس بعض الفئات. دعونا نلقي نظرة على هذه الأعمدة عن كثب.
app_train.dtypes.value_counts()
float64 65
int64 41
object 16
dtype: int64 app_train.select_dtypes(include=[object]).apply(pd.Series.nunique, axis = 0)
NAME_CONTRACT_TYPE 2
CODE_GENDER 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
OCCUPATION_TYPE 18
WEEKDAY_APPR_PROCESS_START 7
ORGANIZATION_TYPE 58
FONDKAPREMONT_MODE 4
HOUSETYPE_MODE 3
WALLSMATERIAL_MODE 7
EMERGENCYSTATE_MODE 2
dtype: int64لدينا 16 عمودًا ، لكل منها 2 إلى 58 خيارًا مختلفًا للقيمة. بشكل عام ، لا يمكن لنماذج تعلُّم الآلة أن تفعل أي شيء مع هذه الأعمدة (باستثناء البعض ، مثل LightGBM أو CatBoost). نظرًا لأننا نخطط لتجربة نماذج مختلفة في مجموعة البيانات ، فلا بد من عمل شيء ما بهذا. هناك نهجان في الأساس:
- ترميز التسمية - يتم تعيين الفئات للأرقام 0 و 1 و 2 وما إلى ذلك ويتم كتابتها في نفس العمود
- ترميز واحد ساخن - يتحلل عمود واحد إلى عدة وفقا لعدد الخيارات وتشير هذه الأعمدة إلى الخيار الذي يحتويه هذا السجل.
من بين
الأنواع الشائعة ، تجدر الإشارة إلى
ترميز الهدف المتوسط (شكرًا للتوضيح
roryorangepants ).
هناك مشكلة صغيرة في Label Encoding - فهو يعين القيم العددية التي لا علاقة لها بالواقع. على سبيل المثال ، إذا كنا نتعامل مع قيمة عددية ، فإن دخل المقترض البالغ 100000 بالتأكيد أكبر وأفضل من دخل 20000. ولكن يمكننا القول ، على سبيل المثال ، أن مدينة واحدة أفضل من أخرى لأنه تم تعيين القيمة 100 والآخر 200 ؟؟؟
من ناحية أخرى ، يعد ترميز One-Hot أكثر أمانًا ، ولكن يمكنه إنتاج أعمدة "إضافية". على سبيل المثال ، إذا قمنا بتشفير نفس الجنس باستخدام One-Hot ، نحصل على عمودين ، "جنس الذكور" و "جنس الإناث" ، على الرغم من أن أحد الأعمدة سيكون كافيًا ، "هل هو ذكر".
للحصول على مجموعة بيانات جيدة ، سيكون من الضروري ترميز العلامات ذات التباين المنخفض باستخدام ترميز التسمية وكل شيء آخر - One-Hot ، ولكن من أجل البساطة ، نقوم بترميز كل شيء وفقًا لـ One-Hot. لن تؤثر عمليًا على سرعة الحساب والنتيجة. عملية ترميز الباندا نفسها بسيطة للغاية.
app_train = pd.get_dummies(app_train) app_test = pd.get_dummies(app_test) print('Training Features shape: ', app_train.shape) print('Testing Features shape: ', app_test.shape)
Training Features shape: (307511, 246)
Testing Features shape: (48744, 242)نظرًا لأن عدد الخيارات في أعمدة التحديد غير متساوٍ ، فإن عدد الأعمدة لا يتطابق الآن. المحاذاة مطلوبة - تحتاج إلى إزالة الأعمدة من مجموعة التدريب غير الموجودة في مجموعة الاختبار. هذا يجعل طريقة المحاذاة ، تحتاج إلى تحديد المحور = 1 (للأعمدة).
: (307511, 242)
: (48744, 242)ارتباط البيانات
طريقة جيدة لفهم البيانات هي حساب معاملات ارتباط بيرسون للبيانات المتعلقة بالسمة الهدف. هذه ليست أفضل طريقة لإظهار مدى صلة الميزات ، ولكنها بسيطة وتسمح لك بالحصول على فكرة عن البيانات. يمكن تفسير المعاملات على النحو التالي:
- 00 -19 "ضعيف جدًا"
- 20 -39 "ضعيف"
- 40-59 "متوسط"
- 60 -79 قوية
- 80-1.0 "قوي جدا"
:
DAYS_REGISTRATION 0.041975
OCCUPATION_TYPE_Laborers 0.043019
FLAG_DOCUMENT_3 0.044346
REG_CITY_NOT_LIVE_CITY 0.044395
FLAG_EMP_PHONE 0.045982
NAME_EDUCATION_TYPE_Secondary / secondary special 0.049824
REG_CITY_NOT_WORK_CITY 0.050994
DAYS_ID_PUBLISH 0.051457
CODE_GENDER_M 0.054713
DAYS_LAST_PHONE_CHANGE 0.055218
NAME_INCOME_TYPE_Working 0.057481
REGION_RATING_CLIENT 0.058899
REGION_RATING_CLIENT_W_CITY 0.060893
DAYS_BIRTH 0.078239
TARGET 1.000000
Name: TARGET, dtype: float64
:
EXT_SOURCE_3 -0.178919
EXT_SOURCE_2 -0.160472
EXT_SOURCE_1 -0.155317
NAME_EDUCATION_TYPE_Higher education -0.056593
CODE_GENDER_F -0.054704
NAME_INCOME_TYPE_Pensioner -0.046209
ORGANIZATION_TYPE_XNA -0.045987
DAYS_EMPLOYED -0.044932
FLOORSMAX_AVG -0.044003
FLOORSMAX_MEDI -0.043768
FLOORSMAX_MODE -0.043226
EMERGENCYSTATE_MODE_No -0.042201
HOUSETYPE_MODE_block of flats -0.040594
AMT_GOODS_PRICE -0.039645
REGION_POPULATION_RELATIVE -0.037227
Name: TARGET, dtype: float64وبالتالي ، فإن جميع البيانات ترتبط ارتباطًا ضعيفًا بالهدف (باستثناء الهدف نفسه ، والذي بالطبع يساوي نفسه). ومع ذلك ، يتم تمييز العمر وبعض "مصادر البيانات الخارجية" عن البيانات. ربما هذه بعض البيانات الإضافية من منظمات الائتمان الأخرى. من المضحك أنه على الرغم من إعلان الهدف على أنه الاستقلال عن هذه البيانات في اتخاذ قرار ائتماني ، إلا أننا في الواقع سنستند إليها في المقام الأول.
العمر
من الواضح أنه كلما كبر العميل ، زاد احتمال العائد (حتى حد معين ، بالطبع). ولكن لسبب ما ، يشار إلى العمر في الأيام السلبية قبل إصدار القرض ، وبالتالي ، يرتبط ارتباطًا إيجابيًا بعدم السداد (والذي يبدو غريبًا إلى حد ما). نأتي بها إلى قيمة إيجابية ونلقي نظرة على العلاقة.
app_train['DAYS_BIRTH'] = abs(app_train['DAYS_BIRTH']) app_train['DAYS_BIRTH'].corr(app_train['TARGET'])
-0.078239308309827088دعونا نلقي نظرة فاحصة على المتغير. لنبدأ بالرسم البياني.
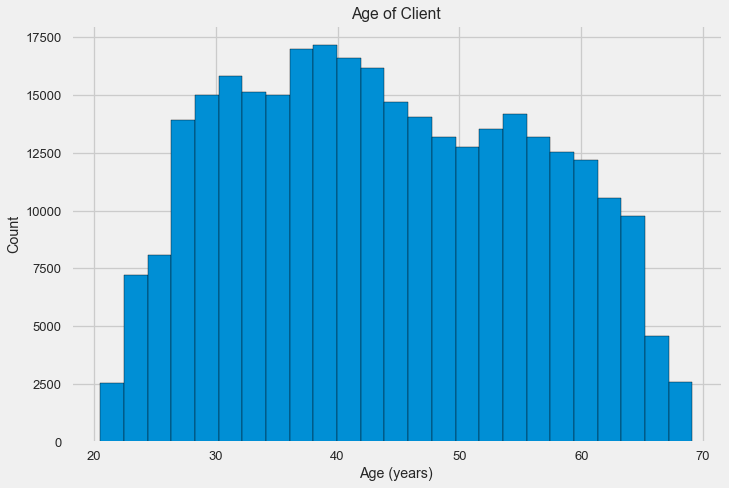
قد يقول الرسم البياني للتوزيع نفسه مفيدًا بعض الشيء ، باستثناء أننا لا نرى أي قيم متطرفة وكل شيء يبدو أكثر أو أقل تصديقًا. لإظهار تأثير تأثير العمر على النتيجة ، يمكننا إنشاء رسم بياني لتقدير كثافة النواة (KDE) - توزيع الكثافة النووية ، مطلية بألوان السمة المستهدفة. يظهر توزيع متغير واحد ويمكن تفسيره على أنه رسم بياني سلس (محسوب كنواة غوسية لكل نقطة ، والتي يتم حسابها بعد ذلك لتنعيمها).
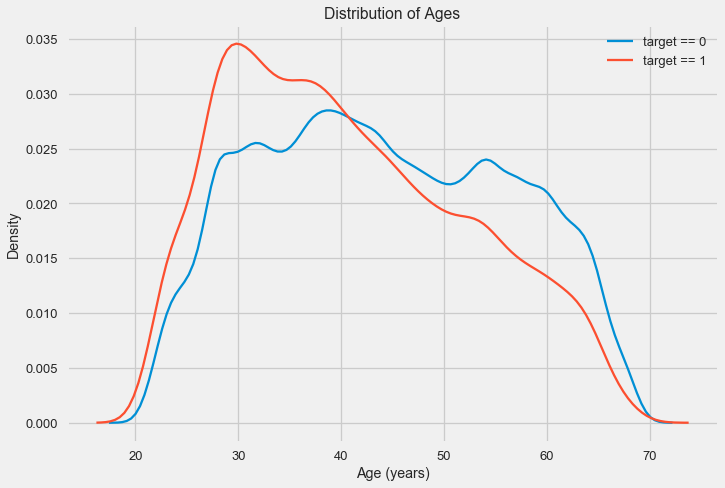
كما يتبين ، فإن نسبة التخلف عن السداد أعلى للشباب وتنخفض مع تقدم العمر. هذا ليس سببا لرفض الائتمان للشباب دائما ، مثل هذه "التوصية" لن تؤدي إلا إلى فقدان الدخل والسوق للبنك. هذه مناسبة للتفكير في رصد أكثر شمولاً لمثل هذه القروض والتقييم ، وربما حتى نوع من التعليم المالي للمقترضين الشباب.
مصادر خارجية
دعونا نلقي نظرة فاحصة على "مصادر البيانات الخارجية" EXT_SOURCE وارتباطها.
ext_data = app_train[['TARGET', 'EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH']] ext_data_corrs = ext_data.corr() ext_data_corrs
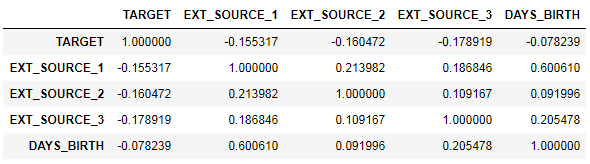
كما أنه مناسب لعرض الارتباط باستخدام مخطط الحرارة
sns.heatmap(ext_data_corrs, cmap = plt.cm.RdYlBu_r, vmin = -0.25, annot = True, vmax = 0.6) plt.title('Correlation Heatmap');
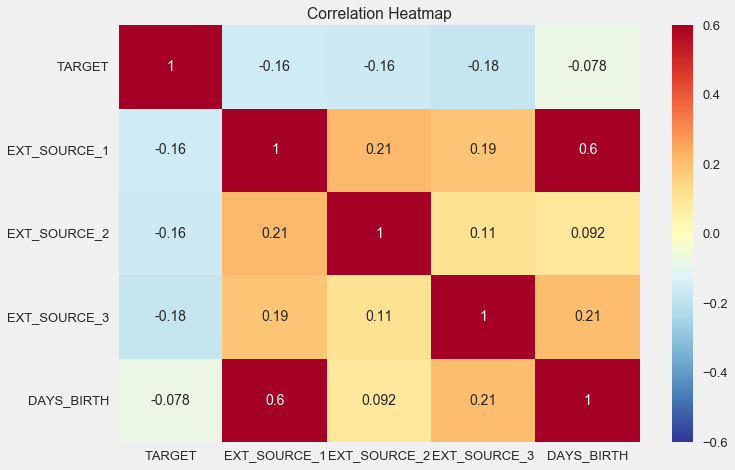
كما ترى ، تظهر جميع المصادر علاقة سلبية مع الهدف. دعونا نلقي نظرة على توزيع كيدي لكل مصدر.
plt.figure(figsize = (10, 12))
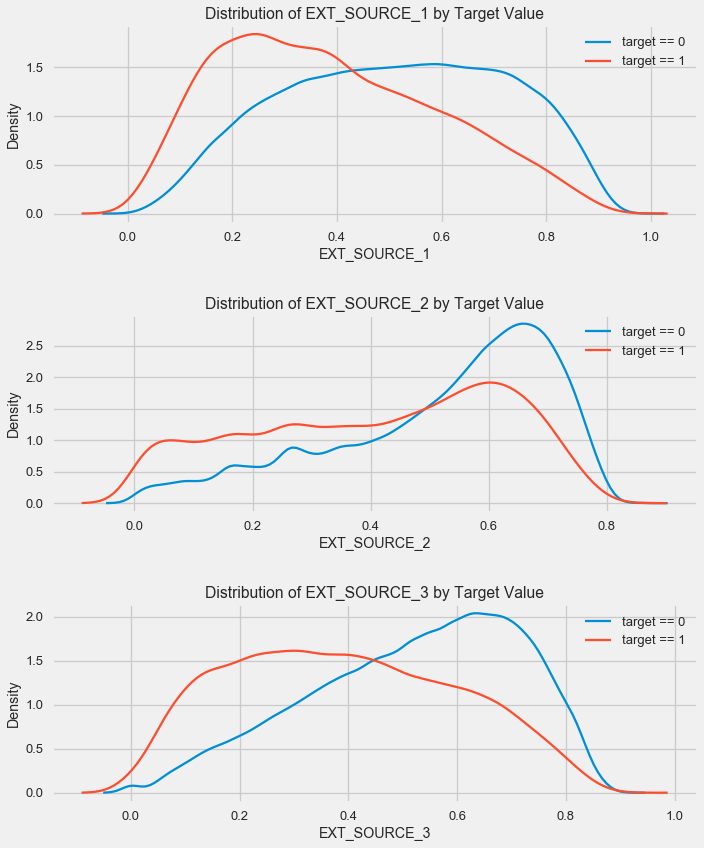
الصورة مشابهة للتوزيع حسب العمر - مع زيادة المؤشر ، يزداد احتمال عودة القرض. المصدر الثالث هو الأقوى في هذا الصدد. على الرغم من أن العلاقة مع المتغير الهدف لا تزال من حيث القيمة المطلقة في الفئة "منخفضة جدًا" ، إلا أن مصادر البيانات الخارجية والعمر ستكون ذات أهمية قصوى في بناء النموذج.
جدول الزوج
لفهم علاقة هذه المتغيرات بشكل أفضل ، يمكنك إنشاء مخطط زوجي ، حيث يمكننا أن نرى علاقة كل زوج ومخطط بياني للتوزيع على طول القطر. فوق القطر ، يمكنك إظهار مخطط النقاط ، وأدناه - 2d كيدي.
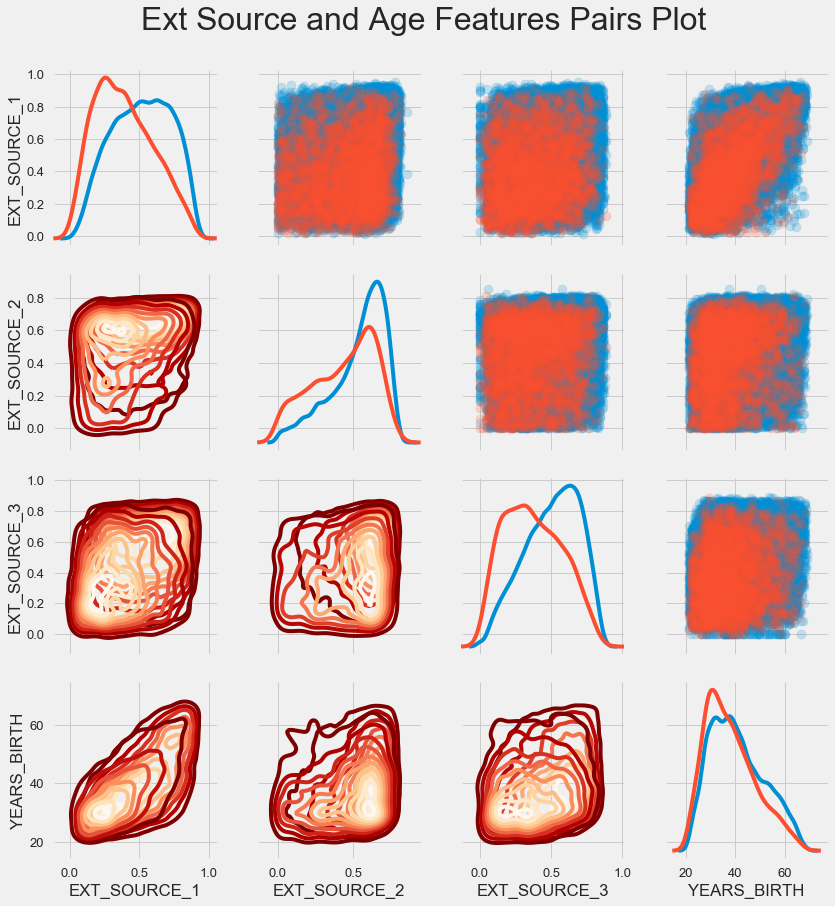
تظهر القروض القابلة للسداد باللون الأزرق وغير قابلة للسداد باللون الأحمر. إن تفسير كل هذا أمر صعب إلى حد ما ، ولكن يمكن أن تظهر صورة جيدة على قميص أو صورة في متحف للفن الحديث من هذه الصورة.
فحص العلامات الأخرى
دعونا نفكر بمزيد من التفصيل في الميزات الأخرى واعتمادها على المتغير المستهدف. نظرًا لوجود العديد من الفئات الفئوية (وتمكنا بالفعل من ترميزها) ، نحتاج مرة أخرى إلى البيانات الأولية. دعنا نسميها بشكل مختلف قليلاً لتجنب الارتباك
application_train = pd.read_csv(PATH+"application_train.csv") application_test = pd.read_csv(PATH+"application_test.csv")
سنحتاج أيضًا إلى وظيفتين لعرض التوزيعات وتأثيرها على المتغير المستهدف بشكل جميل. شكرا جزيلا لهم
لمؤلف هذه
النواة def plot_stats(feature,label_rotation=False,horizontal_layout=True): temp = application_train[feature].value_counts() df1 = pd.DataFrame({feature: temp.index,' ': temp.values})
لذا ، سننظر في العلامات الرئيسية للعملاء
نوع القرض
plot_stats('NAME_CONTRACT_TYPE')
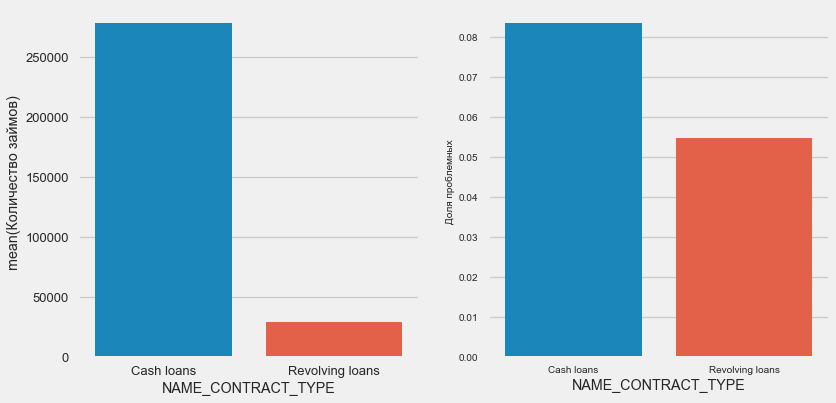
ومن المثير للاهتمام أن القروض المتجددة (على الأرجح السحب على المكشوف أو شيء من هذا القبيل) تشكل أقل من 10٪ من إجمالي عدد القروض. وفي الوقت نفسه ، فإن نسبة عدم العودة بينهم أعلى بكثير. سبب وجيه لمراجعة منهجية العمل مع هذه القروض ، وربما حتى التخلي عنها.
جنس العميل
plot_stats('CODE_GENDER')
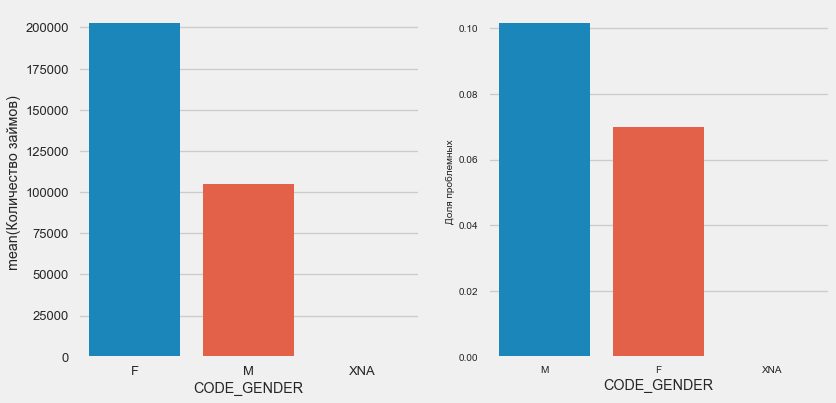
هناك ما يقرب من ضعف عدد العملاء من النساء ، حيث يظهر الرجال خطرًا أكبر بكثير.
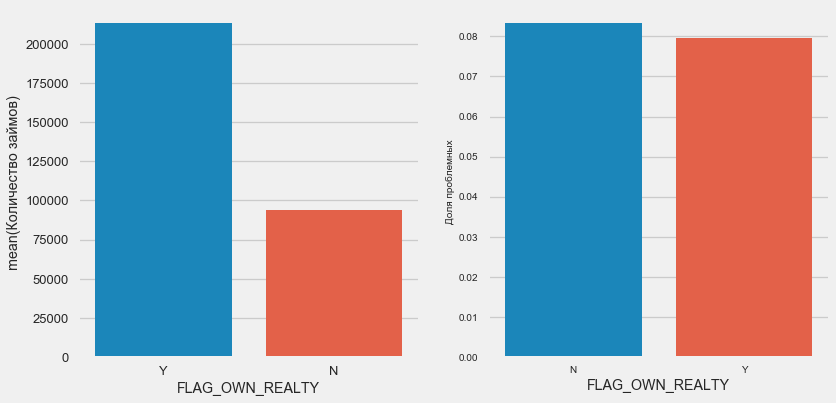
ملكية السيارة والممتلكات
plot_stats('FLAG_OWN_CAR') plot_stats('FLAG_OWN_REALTY')
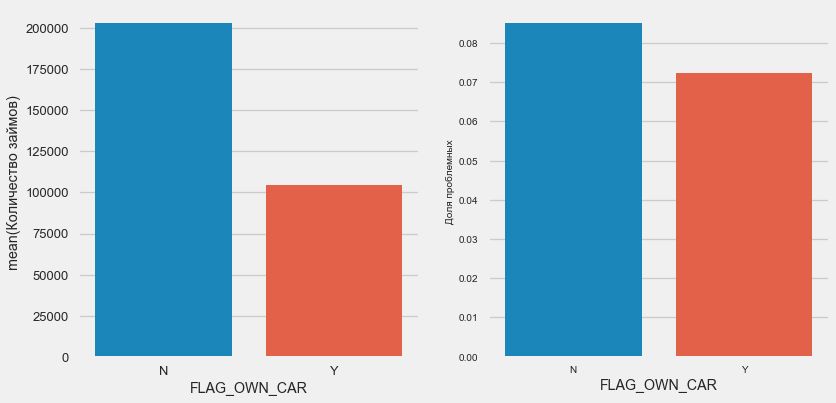
عملاء السيارة هم نصف "بلا حصان". الخطر هو نفسه تقريبًا ، يدفع العملاء الذين لديهم الماكينة أفضل قليلاً.
بالنسبة للعقار ، فإن العكس هو الصحيح - هناك نصف عدد قليل من العملاء بدونه. كما أن الخطر على مالكي العقارات أقل بقليل.
الحالة الزوجية
plot_stats('NAME_FAMILY_STATUS',True, True)
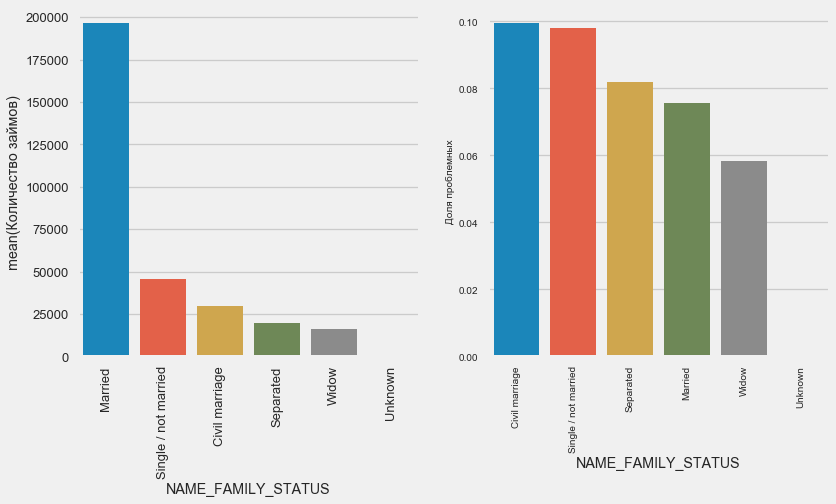
في حين أن معظم العملاء متزوجون ، فإن الأكثر خطورة هم العملاء المدنيون والعزاب. يظهر الأرامل الحد الأدنى من المخاطر.
عدد الاطفال
plot_stats('CNT_CHILDREN')
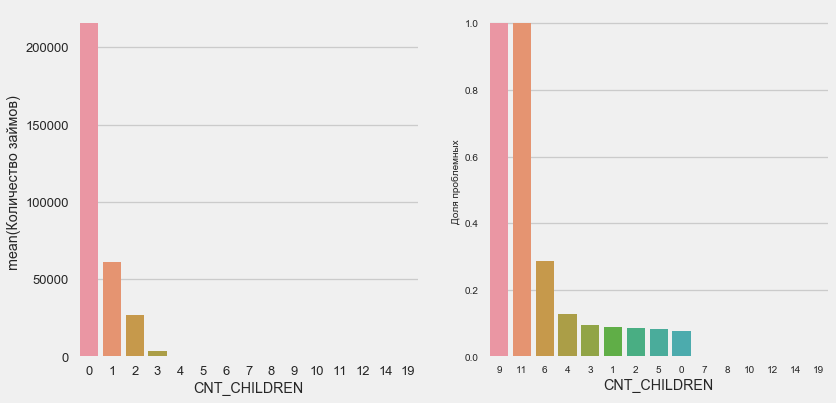
معظم العملاء بلا أطفال. في الوقت نفسه ، يُظهر العملاء الذين لديهم 9 و 11 طفلاً عدم استرداد الأموال بالكامل
application_train.CNT_CHILDREN.value_counts()
0 215371
1 61119
2 26749
3 3717
4 429
5 84
6 21
7 7
14 3
19 2
12 2
10 2
9 2
8 2
11 1
Name: CNT_CHILDREN, dtype: int64كما يظهر حساب القيم ، فإن هذه البيانات غير مهمة إحصائيًا - فقط عميلان من الفئتين. ومع ذلك ، فقد عجز الثلاثة عن العمل ، كما فعل نصف العملاء الذين لديهم 6 أطفال.
عدد أفراد الأسرة
plot_stats('CNT_FAM_MEMBERS',True)
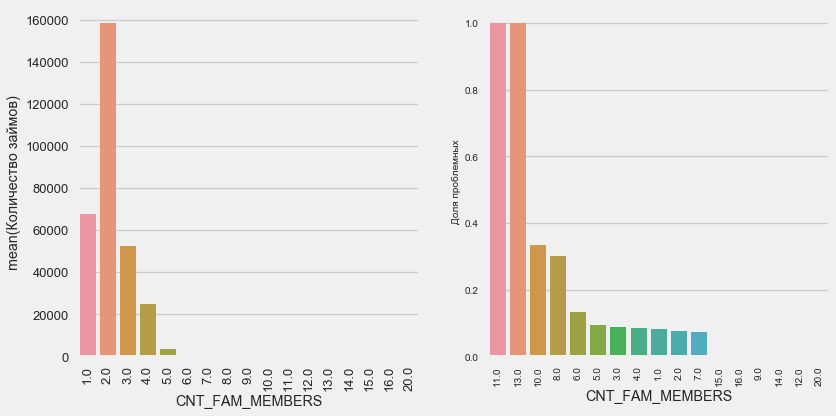
الوضع مشابه - كلما قل عدد الأفواه ، كلما زاد العائد.
نوع الدخل
plot_stats('NAME_INCOME_TYPE',False,False)
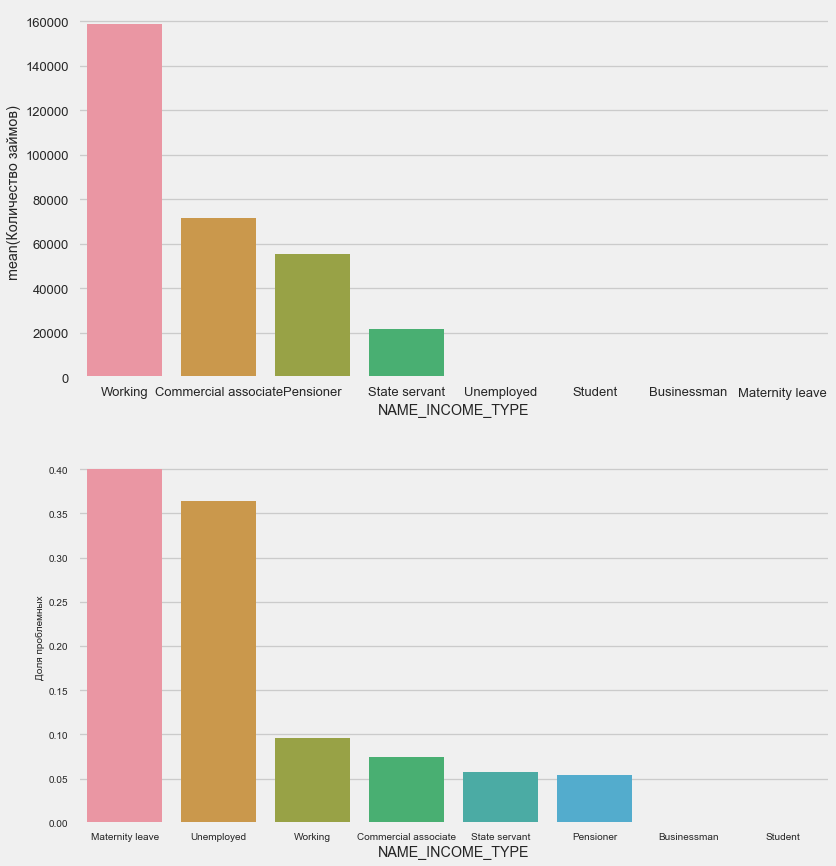
من المرجح أن تنقطع الأمهات العازبات والعاطلات عن العمل في مرحلة التقديم - فهناك القليل جدًا منهن في العينة. لكن المشاكل تظهر بثبات.
نوع النشاط
plot_stats('OCCUPATION_TYPE',True, False)
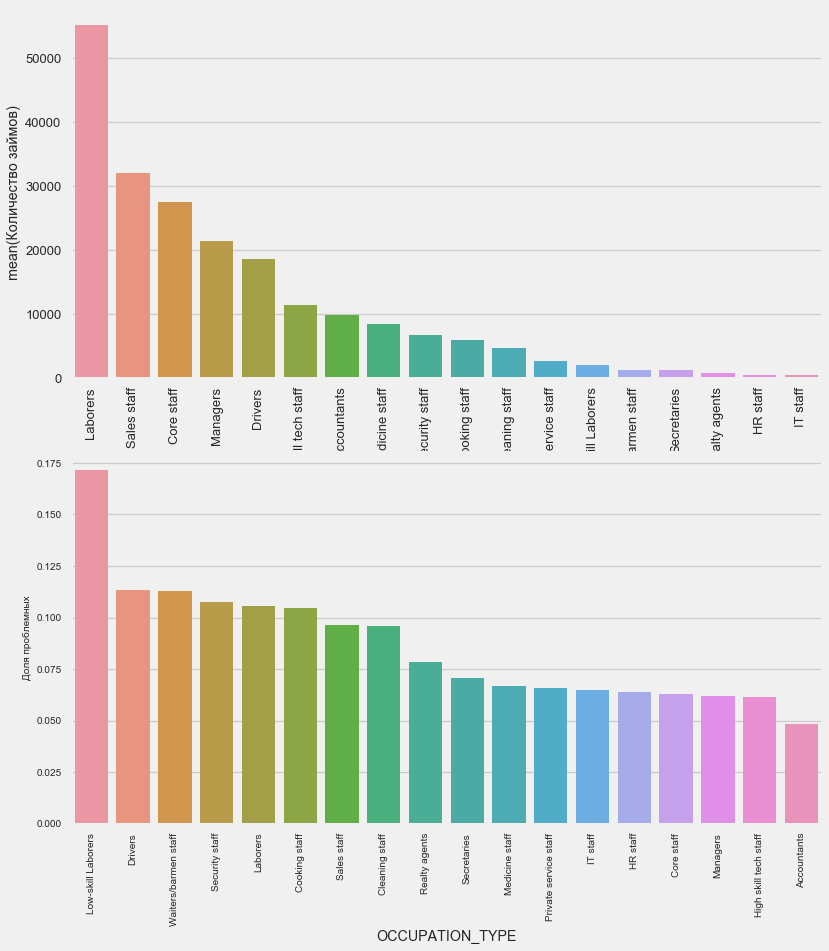
application_train.OCCUPATION_TYPE.value_counts()
Laborers 55186
Sales staff 32102
Core staff 27570
Managers 21371
Drivers 18603
High skill tech staff 11380
Accountants 9813
Medicine staff 8537
Security staff 6721
Cooking staff 5946
Cleaning staff 4653
Private service staff 2652
Low-skill Laborers 2093
Waiters/barmen staff 1348
Secretaries 1305
Realty agents 751
HR staff 563
IT staff 526
Name: OCCUPATION_TYPE, dtype: int64إنها ذات أهمية للسائقين وضباط الأمن الذين هم كثيرون ويواجهون مشاكل في كثير من الأحيان أكثر من الفئات الأخرى.
التعليم
plot_stats('NAME_EDUCATION_TYPE',True)
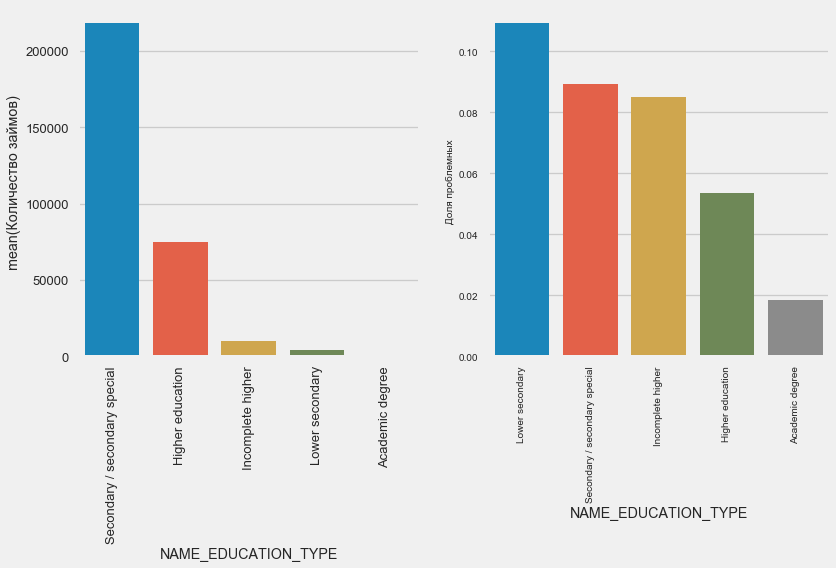
كلما زاد التعليم ، كلما كان التكرار أفضل.
نوع المنظمة - صاحب العمل
plot_stats('ORGANIZATION_TYPE',True, False)
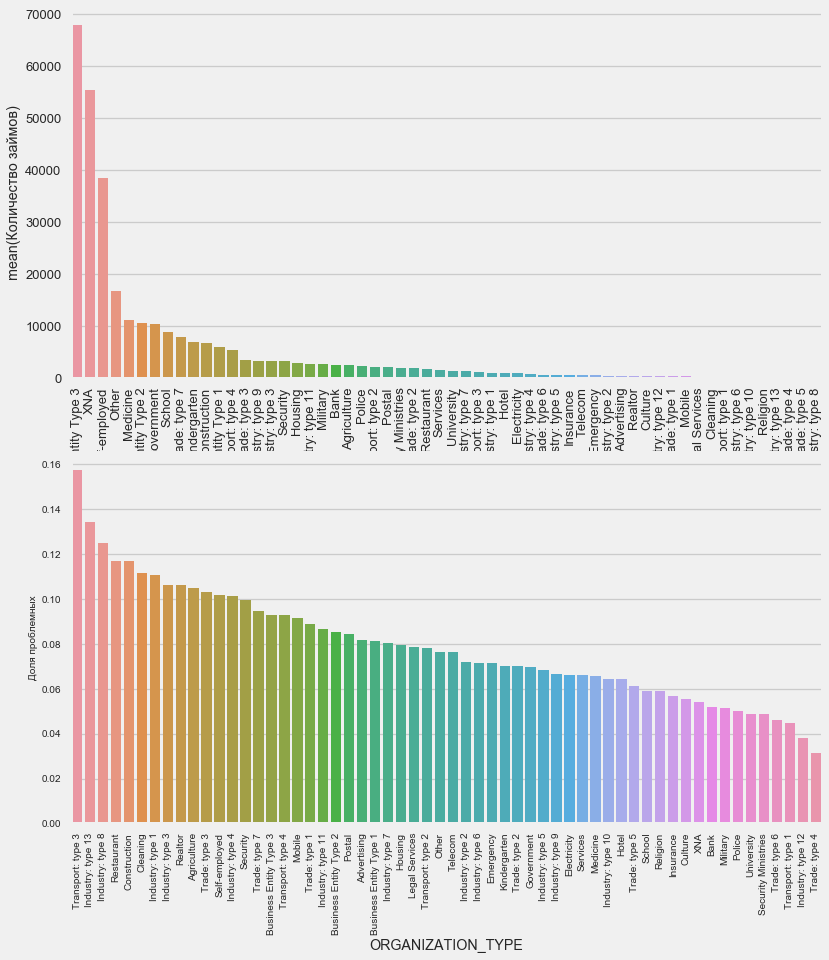
لوحظت أعلى نسبة من عدم العودة في النقل: النوع 3 (16٪) ، الصناعة: النوع 13 (13.5٪) ، الصناعة: النوع 8 (12.5٪) والمطعم (حتى 12٪).
تخصيص القرض
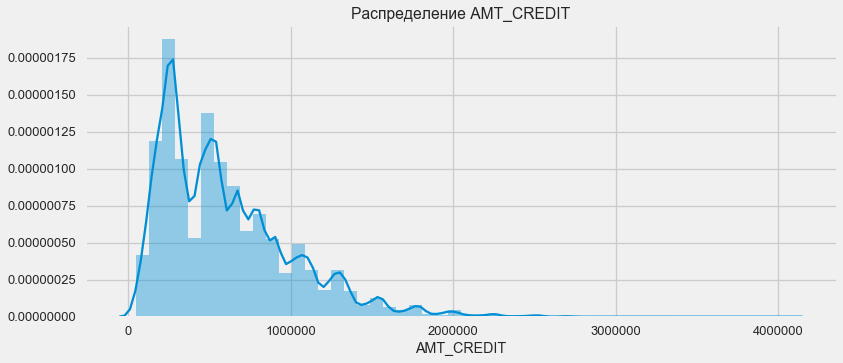
النظر في توزيع مبالغ القروض وأثرها على السداد
plt.figure(figsize=(12,5)) plt.title(" AMT_CREDIT") ax = sns.distplot(app_train["AMT_CREDIT"])
plt.figure(figsize=(12,5))
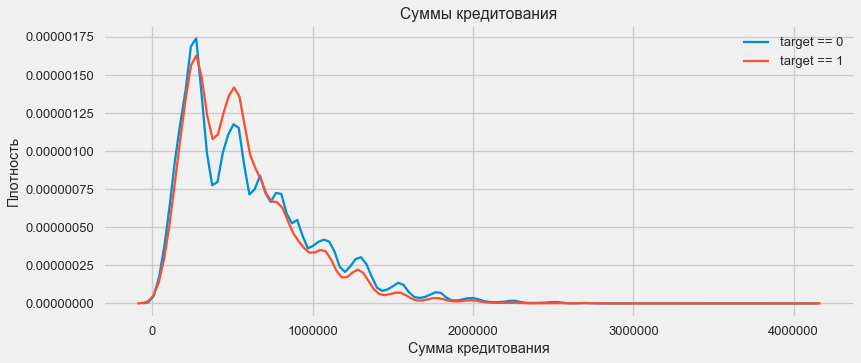
كما يظهر الرسم البياني للكثافة ، يتم إرجاع كميات قوية في كثير من الأحيان
توزيع الكثافة
plt.figure(figsize=(12,5)) plt.title(" REGION_POPULATION_RELATIVE") ax = sns.distplot(app_train["REGION_POPULATION_RELATIVE"])
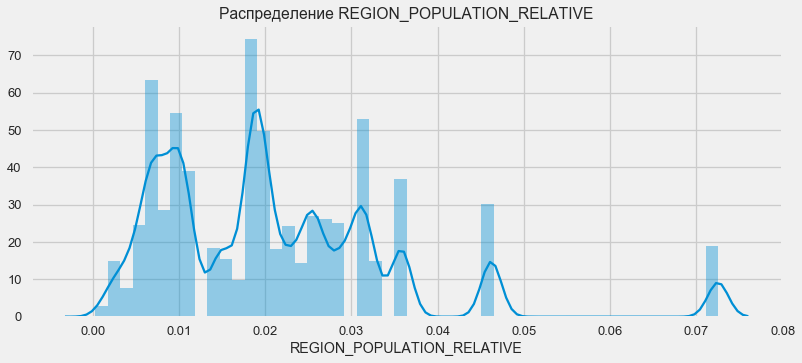
plt.figure(figsize=(12,5))
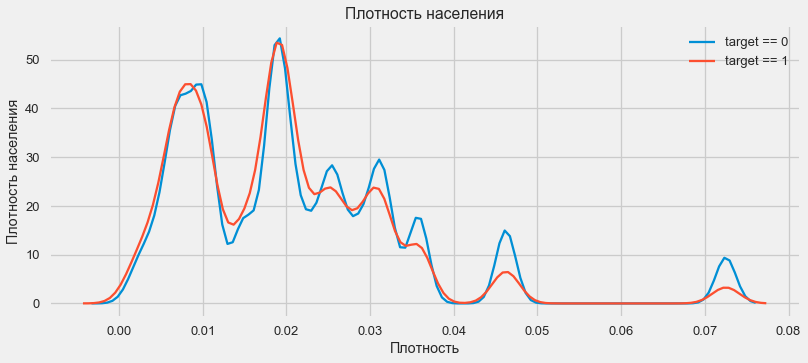
يميل العملاء من المناطق الأكثر سكانًا إلى دفع القروض بشكل أفضل.
وهكذا ، حصلنا على فكرة عن السمات الرئيسية لمجموعة البيانات وتأثيرها على النتيجة. لن نفعل أي شيء على وجه التحديد مع تلك المدرجة في هذه المقالة ، ولكن يمكن أن تكون مهمة جدًا في العمل المستقبلي.
هندسة الميزات - تحويل الميزة
يتم الفوز بالمسابقات على Kaggle عن طريق تحويل العلامات - الشخص الذي يمكنه إنشاء أكثر العلامات المفيدة من البيانات يفوز. على الأقل بالنسبة للبيانات المنظمة ، فإن النماذج الفائزة هي الآن خيارات مختلفة لتعزيز التدرج. في أغلب الأحيان ، يكون قضاء الوقت في تحويل السمات أكثر كفاءة من إعداد المعلمات المفرطة أو اختيار النماذج. لا يزال بإمكان النموذج التعلم فقط من البيانات التي تم نقلها إليه. إن التأكد من أن البيانات ذات صلة بالمهمة هي المسؤولية الرئيسية عن تاريخ العالم.
قد تتضمن عملية تحويل الخصائص إنشاء بيانات جديدة متاحة واختيار أهم البيانات المتاحة وما إلى ذلك. سنحاول هذه المرة علامات كثيرة الحدود.
علامات كثيرة الحدود
إن الطريقة متعددة الحدود لبناء الميزات هي أننا نقوم ببساطة بإنشاء ميزات هي درجة الميزات المتاحة ومنتجاتها. في بعض الحالات ، قد يكون لهذه السمات المركبة ارتباط أقوى مع المتغير المستهدف من "آبائهم". على الرغم من أن هذه الأساليب غالبًا ما تستخدم في النماذج الإحصائية ، إلا أنها أقل شيوعًا في التعلم الآلي. ومع ذلك. لا شيء يمنعنا من تجربتها ، خاصة وأن Scikit-Learn لديها فئة مخصصة لهذه الأغراض - PolynomialFeatures - التي تخلق ميزات متعددة الحدود ومنتجاتها ، ما عليك سوى تحديد الميزات الأصلية نفسها وأقصى درجة يجب رفعها. نحن نستخدم التأثيرات الأكثر قوة على نتيجة 4 سمات ودرجة 3 حتى لا نعقد النموذج كثيرًا وتجنب الإفراط في التجهيز (الإفراط في تدريب النموذج - تعديله المفرط لعينة التدريب).
: (307511, 35)
get_feature_names poly_transformer.get_feature_names(input_features = ['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH'])[:15]
['1',
'EXT_SOURCE_1',
'EXT_SOURCE_2',
'EXT_SOURCE_3',
'DAYS_BIRTH',
'EXT_SOURCE_1^2',
'EXT_SOURCE_1 EXT_SOURCE_2',
'EXT_SOURCE_1 EXT_SOURCE_3',
'EXT_SOURCE_1 DAYS_BIRTH',
'EXT_SOURCE_2^2',
'EXT_SOURCE_2 EXT_SOURCE_3',
'EXT_SOURCE_2 DAYS_BIRTH',
'EXT_SOURCE_3^2',
'EXT_SOURCE_3 DAYS_BIRTH',
'DAYS_BIRTH^2']ما مجموعه 35 سمة متعددة الحدود ومشتقة. تحقق من ارتباطها بالهدف.
EXT_SOURCE_2 EXT_SOURCE_3 -0.193939
EXT_SOURCE_1 EXT_SOURCE_2 EXT_SOURCE_3 -0.189605
EXT_SOURCE_2 EXT_SOURCE_3 DAYS_BIRTH -0.181283
EXT_SOURCE_2^2 EXT_SOURCE_3 -0.176428
EXT_SOURCE_2 EXT_SOURCE_3^2 -0.172282
EXT_SOURCE_1 EXT_SOURCE_2 -0.166625
EXT_SOURCE_1 EXT_SOURCE_3 -0.164065
EXT_SOURCE_2 -0.160295
EXT_SOURCE_2 DAYS_BIRTH -0.156873
EXT_SOURCE_1 EXT_SOURCE_2^2 -0.156867
Name: TARGET, dtype: float64
DAYS_BIRTH -0.078239
DAYS_BIRTH^2 -0.076672
DAYS_BIRTH^3 -0.074273
TARGET 1.000000
1 NaN
Name: TARGET, dtype: float64لذا ، تظهر بعض العلامات ارتباطًا أعلى من الأصل. من المنطقي محاولة التعلم معهم وبدونهم (مثل الكثير في التعلم الآلي ، يمكن تحديد ذلك تجريبيًا). للقيام بذلك ، قم بإنشاء نسخة من إطارات البيانات وإضافة ميزات جديدة هناك.
: (307511, 277)
: (48744, 277)تدريب نموذجي
المستوى الأساسي
في الحسابات ، تحتاج إلى البدء من بعض المستوى الأساسي للنموذج ، والذي لم يعد من الممكن أن ينخفض. في حالتنا ، يمكن أن يكون هذا 0.5 لجميع عملاء الاختبار - وهذا يدل على أنه ليس لدينا أي فكرة على الإطلاق عما إذا كان العميل سوف يسدد القرض أم لا. في حالتنا ، تم بالفعل العمل التمهيدي ويمكن استخدام نماذج أكثر تعقيدًا.الانحدار اللوجستي
لحساب الانحدار اللوجستي ، نحتاج إلى أخذ جداول بميزات فئوية مشفرة ، وملء البيانات المفقودة وتطبيعها (نقلها إلى قيم من 0 إلى 1). كل هذا ينفذ الكود التالي: from sklearn.preprocessing import MinMaxScaler, Imputer
: (307511, 242)
: (48744, 242)نستخدم الانحدار اللوجستي من Scikit-Learn كنموذج أول. لنأخذ نموذج التكسير بتصحيح واحد - نخفض معلمة التسوية C لتجنب الإفراط في التجهيز. بناء الجملة أمر طبيعي - نحن ننشئ نموذجًا ، ندربه ونتنبأ بالاحتمالية باستخدام prob_proba (نحتاج إلى الاحتمالية ، وليس 0/1) from sklearn.linear_model import LogisticRegression
يمكنك الآن إنشاء ملف للتحميل إلى Kaggle. إنشاء إطار بيانات من الرقم التعريفي للعميل واحتمال عدم الإرجاع وتحميله. submit = app_test[['SK_ID_CURR']] submit['TARGET'] = log_reg_pred submit.head()
SK_ID_CURR TARGET
0 100001 0.087954
1 100005 0.163151
2 100013 0.109923
3 100028 0.077124
4 100038 0.151694 submit.to_csv('log_reg_baseline.csv', index = False)
إذن ، نتيجة عملنا العملاق: 0.673 ، مع أفضل نتيجة لهذا اليوم هي 0.802.نموذج محسن - غابة عشوائية
لا يظهر لوجريج نفسه جيدًا ، فلنحاول استخدام نموذج محسّن - غابة عشوائية. هذا نموذج أكثر قوة يمكنه بناء مئات الأشجار وتحقيق نتيجة أكثر دقة. نستخدم 100 شجرة. مخطط العمل مع النموذج هو نفسه ، قياسي تمامًا - تحميل المصنف ، التدريب. التنبؤ. from sklearn.ensemble import RandomForestClassifier
نتيجة الغابات العشوائية أفضل قليلاً - 0.683نموذج تدريب مع ميزات كثيرة الحدود
الآن لدينا نموذج. الذي يفعل شيئًا على الأقل - حان الوقت لاختبار علاماتنا متعددة الحدود. لنفعل نفس الشيء معهم ومقارنة النتيجة. poly_features_names = list(app_train_poly.columns)
نتيجة غابة عشوائية ذات سمات كثيرة الحدود أصبحت أسوأ - 0.633. الأمر الذي يشكك كثيرًا في الحاجة إلى استخدامها.تعزيز التدرج
تعزيز التدرج هو "نموذج جاد" لتعلم الآلة. يتم تقريبًا إجراء جميع المسابقات الأخيرة تقريبًا. دعونا نبني نموذجًا بسيطًا ونختبر أدائه. from lightgbm import LGBMClassifier clf = LGBMClassifier() clf.fit(train, train_labels) predictions = clf.predict_proba(test)[:, 1]
نتيجة LightGBM هي 0.735 ، والتي تترك وراءها جميع الموديلات الأخرى.تفسير النموذج - أهمية السمات
أسهل طريقة لتفسير النموذج هي النظر إلى أهمية الميزات (التي لا يمكن لجميع الموديلات فعلها). نظرًا لأن المصنف قد عالج الصفيف ، فسوف يستغرق الأمر بعض العمل لإعادة تعيين أسماء الأعمدة وفقًا لأعمدة هذا الصفيف.
وكما هو متوقع، والأكثر أهمية لنموذج كل نفس 4 ميزات. أهمية السمات ليست أفضل طريقة لتفسير النموذج ، ولكنها تتيح لك فهم العوامل الرئيسية التي يستخدمها النموذج للتنبؤاتfeature importance
28 EXT_SOURCE_1 310
30 EXT_SOURCE_3 282
29 EXT_SOURCE_2 271
7 DAYS_BIRTH 192
3 AMT_CREDIT 161
4 AMT_ANNUITY 142
5 AMT_GOODS_PRICE 129
8 DAYS_EMPLOYED 127
10 DAYS_ID_PUBLISH 102
9 DAYS_REGISTRATION 69
0.01 = 158
إضافة بيانات من جداول أخرى
الآن سننظر بعناية في الجداول الإضافية وما يمكن فعله بها. ابدأ فورًا في إعداد الجداول لمزيد من التدريب. ولكن أولاً ، احذف الجداول الضخمة السابقة من الذاكرة ، وامسح الذاكرة باستخدام جامع القمامة ، واستورد المكتبات اللازمة لمزيد من التحليل. import gc
استيراد البيانات ، قم بإزالة العمود الهدف على الفور في عمود منفصل data = pd.read_csv('../input/application_train.csv') test = pd.read_csv('../input/application_test.csv') prev = pd.read_csv('../input/previous_application.csv') buro = pd.read_csv('../input/bureau.csv') buro_balance = pd.read_csv('../input/bureau_balance.csv') credit_card = pd.read_csv('../input/credit_card_balance.csv') POS_CASH = pd.read_csv('../input/POS_CASH_balance.csv') payments = pd.read_csv('../input/installments_payments.csv')
ترميز الميزات الفئوية على الفور. لقد قمنا بذلك بالفعل من قبل ، وقمنا بتشفير عينات التدريب والاختبار بشكل منفصل ، ثم قمنا بمحاذاة البيانات. دعنا نجرب نهجًا مختلفًا بعض الشيء - سنجد كل هذه العلامات الفئوية ، ودمج إطارات البيانات ، والتشفير من قائمة تلك الموجودة ، ثم تقسيم العينات مرة أخرى إلى تدريب واختبار. categorical_features = [col for col in data.columns if data[col].dtype == 'object'] one_hot_df = pd.concat([data,test]) one_hot_df = pd.get_dummies(one_hot_df, columns=categorical_features) data = one_hot_df.iloc[:data.shape[0],:] test = one_hot_df.iloc[data.shape[0]:,] print (' ', data.shape) print (' ', test.shape)
(307511, 245)
(48744, 245)بيانات مكتب الائتمان حول رصيد القرض الشهري.
buro_balance.head()
 MONTHS_BALANCE - عدد الأشهر قبل تاريخ تقديم طلب الحصول على قرض. ألق نظرة عن كثب على "الحالات"
MONTHS_BALANCE - عدد الأشهر قبل تاريخ تقديم طلب الحصول على قرض. ألق نظرة عن كثب على "الحالات" buro_balance.STATUS.value_counts()
C 13646993
0 7499507
X 5810482
1 242347
5 62406
2 23419
3 8924
4 5847
Name: STATUS, dtype: int64الحالات تعني ما يلي:- مغلق ، أي قرض مدفوع. X حالة غير معروفة. 0 - القرض الحالي بدون انحراف. 1 - التأخير من 1-30 يومًا ، 2 - التأخير من 31-60 يومًا ، وهكذا حتى الوضع 5 - يباع القرض لطرف ثالث أو يتم شطبه.هنا ، على سبيل المثال ، يمكن تمييز العلامات التالية: buro_grouped_size - عدد الإدخالات في قاعدة البيانات buro_grouped_max - الحد الأقصى لرصيد القرض buro_grouped_min - الحد الأدنى لرصيدالقرض ويمكن تشفير جميع حالات القرض هذه (نستخدم طريقة unstack ، ثم نرفق البيانات المستلمة بجدول المكتب ، حيث إن SK_ID_BUREAU هو نفسه هنا وهناك. buro_grouped_size = buro_balance.groupby('SK_ID_BUREAU')['MONTHS_BALANCE'].size() buro_grouped_max = buro_balance.groupby('SK_ID_BUREAU')['MONTHS_BALANCE'].max() buro_grouped_min = buro_balance.groupby('SK_ID_BUREAU')['MONTHS_BALANCE'].min() buro_counts = buro_balance.groupby('SK_ID_BUREAU')['STATUS'].value_counts(normalize = False) buro_counts_unstacked = buro_counts.unstack('STATUS') buro_counts_unstacked.columns = ['STATUS_0', 'STATUS_1','STATUS_2','STATUS_3','STATUS_4','STATUS_5','STATUS_C','STATUS_X',] buro_counts_unstacked['MONTHS_COUNT'] = buro_grouped_size buro_counts_unstacked['MONTHS_MIN'] = buro_grouped_min buro_counts_unstacked['MONTHS_MAX'] = buro_grouped_max buro = buro.join(buro_counts_unstacked, how='left', on='SK_ID_BUREAU') del buro_balance gc.collect()
معلومات عامة عن مكاتب الائتمان
buro.head()
 (يتم عرض الأعمدة السبعة الأولى) هناكقدر كبير من البيانات ، بشكل عام ، يمكنك محاولة التشفير ببساطة باستخدام One-Hot-Encoding ، وتجميعها حسب SK_ID_CURR ، في المتوسط ، وبنفس الطريقة ، الاستعداد للانضمام مع الجدول الرئيسي
(يتم عرض الأعمدة السبعة الأولى) هناكقدر كبير من البيانات ، بشكل عام ، يمكنك محاولة التشفير ببساطة باستخدام One-Hot-Encoding ، وتجميعها حسب SK_ID_CURR ، في المتوسط ، وبنفس الطريقة ، الاستعداد للانضمام مع الجدول الرئيسي buro_cat_features = [bcol for bcol in buro.columns if buro[bcol].dtype == 'object'] buro = pd.get_dummies(buro, columns=buro_cat_features) avg_buro = buro.groupby('SK_ID_CURR').mean() avg_buro['buro_count'] = buro[['SK_ID_BUREAU', 'SK_ID_CURR']].groupby('SK_ID_CURR').count()['SK_ID_BUREAU'] del avg_buro['SK_ID_BUREAU'] del buro gc.collect()
بيانات عن التطبيقات السابقة
prev.head()
 وبالمثل ، نقوم بتشفير الميزات الفئوية والمتوسط والجمع بين المعرّف الحالي.
وبالمثل ، نقوم بتشفير الميزات الفئوية والمتوسط والجمع بين المعرّف الحالي. prev_cat_features = [pcol for pcol in prev.columns if prev[pcol].dtype == 'object'] prev = pd.get_dummies(prev, columns=prev_cat_features) avg_prev = prev.groupby('SK_ID_CURR').mean() cnt_prev = prev[['SK_ID_CURR', 'SK_ID_PREV']].groupby('SK_ID_CURR').count() avg_prev['nb_app'] = cnt_prev['SK_ID_PREV'] del avg_prev['SK_ID_PREV'] del prev gc.collect()
رصيد بطاقة الائتمان
POS_CASH.head()

POS_CASH.NAME_CONTRACT_STATUS.value_counts()
Active 9151119
Completed 744883
Signed 87260
Demand 7065
Returned to the store 5461
Approved 4917
Amortized debt 636
Canceled 15
XNA 2
Name: NAME_CONTRACT_STATUS, dtype: int64نقوم بتشفير الميزات الفئوية وإعداد جدول للجمع le = LabelEncoder() POS_CASH['NAME_CONTRACT_STATUS'] = le.fit_transform(POS_CASH['NAME_CONTRACT_STATUS'].astype(str)) nunique_status = POS_CASH[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').nunique() nunique_status2 = POS_CASH[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').max() POS_CASH['NUNIQUE_STATUS'] = nunique_status['NAME_CONTRACT_STATUS'] POS_CASH['NUNIQUE_STATUS2'] = nunique_status2['NAME_CONTRACT_STATUS'] POS_CASH.drop(['SK_ID_PREV', 'NAME_CONTRACT_STATUS'], axis=1, inplace=True)
بيانات البطاقة
credit_card.head()
 (الأعمدة السبعة الأولى)عمل مماثل
(الأعمدة السبعة الأولى)عمل مماثل credit_card['NAME_CONTRACT_STATUS'] = le.fit_transform(credit_card['NAME_CONTRACT_STATUS'].astype(str)) nunique_status = credit_card[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').nunique() nunique_status2 = credit_card[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').max() credit_card['NUNIQUE_STATUS'] = nunique_status['NAME_CONTRACT_STATUS'] credit_card['NUNIQUE_STATUS2'] = nunique_status2['NAME_CONTRACT_STATUS'] credit_card.drop(['SK_ID_PREV', 'NAME_CONTRACT_STATUS'], axis=1, inplace=True)
بيانات الدفع
payments.head()
 (تظهر الأعمدة السبعة الأولى)لننشئ ثلاثة جداول - بالقيم المتوسطة والحد الأدنى والحد الأقصى من هذا الجدول.
(تظهر الأعمدة السبعة الأولى)لننشئ ثلاثة جداول - بالقيم المتوسطة والحد الأدنى والحد الأقصى من هذا الجدول. avg_payments = payments.groupby('SK_ID_CURR').mean() avg_payments2 = payments.groupby('SK_ID_CURR').max() avg_payments3 = payments.groupby('SK_ID_CURR').min() del avg_payments['SK_ID_PREV'] del payments gc.collect()
ربط الجدول
data = data.merge(right=avg_prev.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_prev.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_buro.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_buro.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(POS_CASH.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') test = test.merge(POS_CASH.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') data = data.merge(credit_card.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') test = test.merge(credit_card.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_payments.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_payments.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_payments2.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_payments2.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_payments3.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_payments3.reset_index(), how='left', on='SK_ID_CURR') del avg_prev, avg_buro, POS_CASH, credit_card, avg_payments, avg_payments2, avg_payments3 gc.collect() print (' ', data.shape) print (' ', test.shape) print (' ', y.shape)
(307511, 504)
(48744, 504)
(307511,)وفي الواقع ، سنصل إلى هذا الجدول المضاعف مع تعزيز التدرج! from lightgbm import LGBMClassifier clf2 = LGBMClassifier() clf2.fit(data, y) predictions = clf2.predict_proba(test)[:, 1]
تكون النتيجة 0.770.حسنًا ، أخيرًا ، دعنا نجرب تقنية أكثر تعقيدًا مع الطي في الطيات والتحقق المتقاطع واختيار أفضل تكرار. folds = KFold(n_splits=5, shuffle=True, random_state=546789) oof_preds = np.zeros(data.shape[0]) sub_preds = np.zeros(test.shape[0]) feature_importance_df = pd.DataFrame() feats = [f for f in data.columns if f not in ['SK_ID_CURR']] for n_fold, (trn_idx, val_idx) in enumerate(folds.split(data)): trn_x, trn_y = data[feats].iloc[trn_idx], y.iloc[trn_idx] val_x, val_y = data[feats].iloc[val_idx], y.iloc[val_idx] clf = LGBMClassifier( n_estimators=10000, learning_rate=0.03, num_leaves=34, colsample_bytree=0.9, subsample=0.8, max_depth=8, reg_alpha=.1, reg_lambda=.1, min_split_gain=.01, min_child_weight=375, silent=-1, verbose=-1, ) clf.fit(trn_x, trn_y, eval_set= [(trn_x, trn_y), (val_x, val_y)], eval_metric='auc', verbose=100, early_stopping_rounds=100
Full AUC score 0.785845النتيجة النهائية على kaggle 0.783إلى أين أذهب بعد ذلك
بالتأكيد تواصل العمل مع العلامات. استكشف البيانات ، حدد بعض العلامات ، ودمجها ، وإرفاق جداول إضافية بطريقة مختلفة. يمكنك تجربة معاملات hyperparameters Mogheli - الكثير من الاتجاهات.آمل أن تكون هذه المجموعة الصغيرة قد أظهرت لك الأساليب الحديثة للبحث عن البيانات وإعداد النماذج التنبؤية. تعلم قواعد البيانات ، شارك في المسابقات ، كن هادئا!ومرة أخرى روابط للنواة التي ساعدتني في إعداد هذا المقال. تم نشر المقالة أيضًا في شكل كمبيوتر محمول على Github ، يمكنك تنزيله ، ومجموعة البيانات والتشغيل والتجربة.ويل كوهرسن. ابدأ هنا: سبان مقدمةلطيفة. HomeCreditRisk: Extensive EDA + Baseline [0.772]Gabriel Preda. Home Credit Default Risk Extensive EDAPavan Raj. Loan repayers v/s Loan defaulters — HOME CREDITLem Lordje Ko. 15 lines: Just EXT_SOURCE_xShanth. HOME CREDIT — BUREAU DATA — FEATURE ENGINEERINGDmitriy Kisil. Good_fun_with_LigthGBM