في الآونة الأخيرة ، انتهت منافسة iMaterialist Challenge (الأثاث) في Kaggle ، حيث كانت المهمة هي تصنيف الصور إلى 128 نوعًا من الأثاث والأدوات المنزلية (ما يسمى التصنيف الدقيق ، حيث تكون الفصول قريبة جدًا من بعضها البعض).
في هذه المقالة
سأصف النهج الذي جلب لنا المركز الثالث مع
m0rtido ، ولكن قبل الانتقال إلى هذه النقطة ، أقترح استخدام الشبكة العصبية الطبيعية في رأسي لحل هذه المشكلة وتقسيم الكراسي في الصورة أدناه إلى ثلاث فئات.

هل خمنت صحيح؟ أنا لا.
ولكن توقف ، أولاً وقبل كل شيء.
بيان المشكلة
في المسابقة ، حصلنا على مجموعة بيانات تم تقديم 128 فئة من الأغراض المنزلية العادية ، مثل الكراسي والتلفزيونات والمقالي والوسائد في شكل شخصيات أنيمي.
تألف الجزء التدريبي من مجموعة البيانات من 190 ألف صورة تقريبًا (من الصعب معرفة العدد الدقيق لأنه لم يتم تزويد المشاركين إلا بمجموعة من عناوين URL للتنزيل ، بعضها لم ينجح بالطبع ، وكان توزيع الفصول بعيدًا عن التوحيد (انظر الصورة القابلة للنقر أدناه) .

تم تمثيل مجموعة بيانات الاختبار بـ 12800 صورة ، وكانت متوازنة تمامًا: كان هناك 100 صورة لكل فصل. كما تم إصدار مجموعة بيانات للتحقق ، والتي كان لها أيضًا توزيع متوازن للفئات وكانت بالضبط نصف حجم الاختبار.
كان مقياس تقييم المهمة

.
كيف قررنا؟
بادئ ذي بدء ، قمنا بتنزيل البيانات ونظرنا إلى جزء صغير بأعيننا. بدلاً من العديد من الصور ، تم تنزيل صورة 1x1 أو عنصر نائب به خطأ. قمنا بحذف هذه الصور على الفور باستخدام برنامج نصي.
نقل التعلم
كان من الواضح أنه مع العدد المتاح من الصور والحدود الزمنية ، ليس من الجيد تدريب الشبكات العصبية من الصفر على مجموعة البيانات هذه. بدلاً من ذلك ، استخدمنا نهج التعلم في النقل ، وفكرته كما يلي: يمكن استخدام وزن الشبكة المدربة على مهمة واحدة لمجموعة بيانات مختلفة تمامًا والحصول على جودة لائقة ، أو حتى زيادة في الدقة مقارنة بالتعلم من البداية.
كيف يعمل؟ تعمل الطبقات المخفية في الشبكات العصبية العميقة كمستخلصات للميزات ، وتستخرج المعالم التي تستخدمها الطبقات العليا مباشرة للتصنيف.
استفدنا من هذا من خلال استكمال سلسلة من CNN العميقة التي تم تدريبها مسبقًا على ImageNet. لهذه الأغراض ، استخدمنا Keras وحديقة النماذج الخاصة به ، حيث كان الكود التالي كافيًا لتحميل البنية النهائية:
base_model = densenet.DenseNet201(weights='imagenet', include_top=False, input_shape=(img_width, img_height, 3), pooling='avg')
بعد ذلك ، استخرجنا ما يسمى بعلامات عنق الزجاجة (الميزات عند الخروج من الطبقة التلافيفية الأخيرة) من الشبكة وقمنا بتدريب softmax مع
التسرب فوقها.
بعد ذلك ، قمنا بتوصيل الأوزان "العليا" المدربة بالجزء التلافيفي من الشبكة وقمنا بتدريب الشبكة بأكملها في وقت واحد.
عرض الكود. for layer in base_model.layers: layer.trainable = True top_model = Sequential() top_model.add(Dropout(0.5, name='top_dropout', input_shape=base_model.output_shape[1:])) top_model.add(Dense(128, activation='softmax', name='top_softmax')) top_model.load_weights('top-weights-densenet.hdf5', by_name=True) model = Model(inputs=base_model.input, outputs=top_model(base_model.output)) initial_lrate = 0.0005 model.compile(optimizer=Adam(lr=initial_lrate), loss='categorical_crossentropy', metrics=['accuracy'])
مع هذا الضبط الدقيق للشبكات ، تمكنا من تجربة الاختراق التالي:
- زيادة البيانات . لمكافحة التركيب الزائد ، استخدمنا زيادة صارمة جدًا: الانعكاس الأفقي ، والتكبير ، والتحولات ، والتناوب ، والإمالة ، وإضافة ضوضاء اللون ، وتحولات قناة اللون ، والتدريب على خمسة خطوط قص (الزوايا ومركز الصورة). أردنا أيضًا تجربة FancyPCA ، ولكن فشلنا بسبب نقص موارد الحوسبة.
- TTA للتنبؤ بالفصول على التحقق والاختبار ، استخدمنا التعزيز ، أقل عدوانية بقليل مما كان عليه أثناء التدريب ، وقمنا بحساب متوسط نتائج التنبؤات لزيادة الدقة.
- معدل تعلم ركوب الدراجات . ساعدت الزيادة الدورية والنقصان في وتيرة التدريب النماذج على عدم الوقوع في أدنى المستويات المحلية.
- تدريب نموذجي على مجموعة فرعية من الفصول . كما ترون من الصورة فوق القطع ، تحتوي مجموعة البيانات على فئات قريبة جدًا من بعضها البعض. قريبة جدًا من أنه في مجموعات معينة من الأشياء (على سبيل المثال ، على الكراسي والكراسي التي كانت تمثل ما يصل إلى 8 فصول) ، كانت نماذجنا أكثر خطأ من الأنواع الأخرى من الأشياء. حاولنا تدريب شبكة CNN منفصلة للتعرف على الكراسي فقط ، على أمل أن تتعلم مثل هذه الشبكة التمييز بين أنواع الكراسي بشكل أفضل من شبكة الأغراض العامة ، لكن هذا النهج لا يعطي زيادة في الدقة.
لماذا؟ يتم عرض جزء من إجابة هذا السؤال في الصورة قبل القطع - كانت الفصول متشابهة لدرجة أنه حتى مع الترميز الأولي للبيانات ، لا يمكن للأشخاص الذين وضعوا ملصقات الفصل التمييز بينهم ، لذلك لن يكون من الممكن الضغط على هذه البيانات بدقة جيدة. - شبكة المحولات المكانية . على الرغم من حقيقة أننا دربنا إحدى الشبكات بها وحصلنا على دقة جيدة ، إلا أنها للأسف لم يتم تضمينها في التقديم النهائي.
- دالة الخسارة الموزونة . استخدمنا الخسارة المرجحة للتعويض عن التوزيع غير المتوازن للفئات. وقد ساعد ذلك في تدريب "قمم" softmax وفي التدريب الإضافي للشبكة بأكملها. تم حساب الأوزان باستخدام دالة scikit-learn ثم تم تمريرها إلى طريقة ملائمة للنموذج:
train_labels = utils.to_categorical(train_generator.classes) y_integers = np.argmax(train_labels, axis=1) class_weights = compute_class_weight('balanced', np.unique(y_integers), y_integers)
شكلت الشبكات المدربة بهذه الطريقة 90 ٪ من مجموعتنا النهائية.
التراص علامات عنق الزجاجة
إخلاء المسؤولية: لا تكرر أبدًا التقنية الموضحة لاحقًا في الحياة الواقعية.
لذلك ، كما حددنا في القسم السابق ، يمكن استخدام ميزات الاختناق من الشبكات المدربة على ImageNet للتصنيف في مهام أخرى. قرر
m0rtido المضي قدمًا واقترح الاستراتيجية التالية:
- نأخذ جميع البنى المدربة مسبقًا المتاحة لنا (على وجه الخصوص ، تم أخذ NasNet Large ، InceptionV4 ، Vgg19 ، Vgg16 ، InceptionV3 ، InceptionResnetV2 ، Resnet-50 ، Resnet-101 ، Resnet-152 ، Xception ، Densenet-169 ، Densenet-121 ، Densenet-201 ) واستخراج علامات الاختناق منها. سنحسب أيضًا علامات النسخ المنعكسة للصور (مثل هذه الزيادة الضئيلة).
- قم بتقليل أبعاد ميزات كل من النماذج ثلاث مرات بمساعدة SAR بحيث تتناسب بشكل طبيعي مع ذاكرة الوصول العشوائي 16 جيجابايت المتوفرة لنا.
- قم بتسلسل هذه الميزات في متجه واحد كبير للميزات.
- سنقوم بتعليم مفهوم متعدد الطبقات فوق كل هذا وسننشئ تنبؤات. سوف نتدرب أيضًا على كسر الطيات ومتوسط كل هذه التوقعات.
أعطى التراص الوحشي الناتج زيادة كبيرة في الدقة للمجموعة الشاملة.
مجموعة النماذج
بعد كل ما سبق ، كان لدينا حوالي عشرين من الشبكات التلافيفية المحجوبة ، بالإضافة إلى اثنين من المفاهيم في أعلى علامات الاختناق. كان السؤال: كيف نحصل على توقع واحد من كل هذا؟
بطريقة جيدة ، في أفضل تقاليد Kaggle ، كان علينا أن
نكدس فوق كل هذا ، ولكن من أجل القيام بالتراص OOF ، لم يكن لدينا وقت ولا GPU ، وتدريب نموذج عالي المستوى على حالة تعليق للتحقق أدى إلى زيادة كبيرة جدًا. لذلك ، قررنا تنفيذ خوارزمية بسيطة لإنشاء فرقة الجشع:
- تهيئة فرقة فارغة.
- نحاول إضافة كل نموذج بدوره وننظر في النتيجة. نختار النموذج الذي يزيد القياس أكثر ونضيفه إلى المجموعة. يتم حساب متوسط نتائج التنبؤ بالنماذج في المجموعة.
- إذا لم يعمل أي من النماذج على تحسين الأداء ، فإننا ننتقل إلى المجموعة ونحاول إزالة النماذج منها. إذا اتضح إزالة نموذج ما لتحسين النتيجة ، نقوم بذلك ونعود إلى الخطوة 2.
كمقياس تم اختياره

. تم اختيار هذه الصيغة تجريبيا بطريقة

و
تبين أن نفس المقياس. يرتبط مثل هذا المقياس المتكامل بشكل جيد مع
سواء في المصادقة أو في الصدارة العامة.
بالإضافة إلى ذلك ، فإن حقيقة أننا أضفنا أو أزلنا نموذجًا واحدًا في كل تكرار (أي أن أوزان النموذج ظلت دائمًا أعدادًا صحيحة) تلعب دورًا في نوع من التنظيم ، وعدم السماح للمجموعة بأن تفرط في إطار مجموعة بيانات التحقق.
ونتيجة لذلك ، تضمنت المجموعة النماذج التالية:
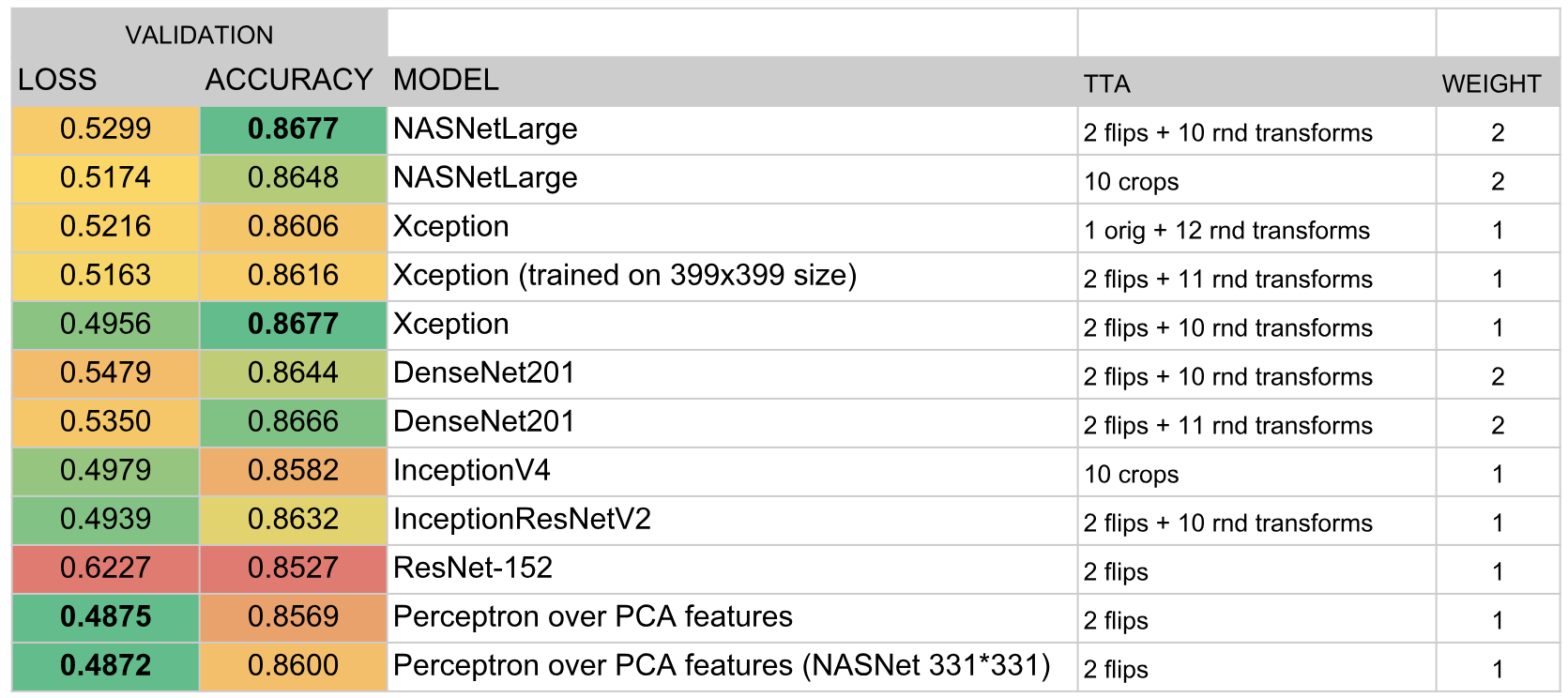
النتائج
وبحسب نتائج المسابقة احتلنا المركز الثالث. يبدو لي أن مفتاح النجاح هو الاختيار الناجح لخوارزمية المجموعة والوقت
الضخم الذي
استثمرته أنا وأنا
mtrtido في تدريب عدد كبير من النماذج.
