مرحبًا اسمي سيرجي ، أعمل كبير المهندسين في سبرتخ. لقد عملت في مجال تكنولوجيا المعلومات منذ حوالي 10 سنوات ، 6 منها تعمل في قواعد البيانات وعمليات ETL و DWH وكل ما يتعلق بالبيانات. في هذه المقالة سأتحدث عن Vertica - DBMS التحليلي والعمودي حقًا الذي يضغط بكفاءة ، يخزن ، يقدم البيانات بسرعة وهو رائع كحل كبير للبيانات.

معلومات عامة
بدأت البيانات الضخمة في التطور في العقد الأول من القرن الحادي والعشرين ، وكانت هناك حاجة إلى محركات يمكنها هضمها بالكامل. ردا على ذلك ، ظهر عدد من DBMS العمودي المقصود لهذا الغرض - بما في ذلك Vertica.
لا تقوم Vertica بتخزين بياناتها في أعمدة فحسب ، بل تقوم بتخزينها بشكل عقلاني بدرجة عالية من الضغط ، ولكنها أيضًا تقوم بجدولة الاستعلامات بكفاءة وتعطي البيانات بسرعة. ستستهلك المعلومات ، التي في DBMS صغيرة الحجم الكلاسيكية حوالي 1 تيرابايت من مساحة القرص ، على Vertica حوالي 200-300 غيغابايت ، وبالتالي نحصل على توفيرات جيدة على الأقراص.
تم تصميم Vertica في الأصل على شكل عمود DBMS. تحاول القواعد الأخرى ببساطة محاكاة آليات الأعمدة المختلفة ، لكنها لا تنجح دائمًا لأن المحرك لا يزال مصممًا لمعالجة السلاسل. كقاعدة ، يقوم المقلدون ببساطة بنقل الجدول ثم معالجته بآلية الخط المعتادة.
Vertica تتحمل الأخطاء ، ولا تحتوي على عقدة تحكم - جميع العقد متساوية. إذا كانت هناك مشاكل مع أحد الخوادم في المجموعة ، فسوف نستمر في تلقي البيانات. في كثير من الأحيان ، يعد تلقي البيانات في الوقت المحدد أمرًا بالغ الأهمية للعملاء من رجال الأعمال ، خاصة في الوقت الذي يتم فيه إغلاق التقارير وتحتاج إلى تقديم المعلومات إلى السلطات المالية.
مجالات التطبيق
Vertica هي في المقام الأول مستودع بيانات تحليلي. لا يجب أن تكتب لها في معاملات صغيرة ، لا يجب أن تثبتها في أي موقع ، إلخ. يجب اعتبار Vertica نوعًا من طبقة الدُفعة ، حيث يجدر غمر البيانات في حزم كبيرة. إذا لزم الأمر ، فإن Vertica جاهزة لإعطاء هذه البيانات بسرعة كبيرة - يتم الانتهاء من الاستفسارات لملايين الخطوط في ثوانٍ.
أين يمكن أن يكون هذا مفيدًا؟ خذ ، على سبيل المثال ، شركة اتصالات. يمكن استخدام Vertica فيه للتحليلات الجغرافية ، وتطوير الشبكة ، وإدارة الجودة ، والتسويق المستهدف ، ودراسة المعلومات من مراكز الاتصال ، وإدارة تدفقات العملاء الخارجة ، وحلول مكافحة الاحتيال / مكافحة البريد الإلكتروني العشوائي.

في قطاعات الأعمال الأخرى ، كل شيء متشابه - التحليلات الموثوق بها في الوقت المناسب مهمة لتحقيق الربح. في التجارة ، على سبيل المثال ، يحاول الجميع تخصيص العملاء بطريقة أو بأخرى ، وتوزيع بطاقات الخصم لذلك ، وجمع البيانات عن مكان ، وماذا ومتى اشترى شخص ، وما إلى ذلك. من خلال تحليل مجموعة من المعلومات من جميع هذه القنوات ، يمكننا مقارنتها ، وبناء النماذج واتخاذ القرارات التي تؤدي إلى نمو الأرباح.
حد الدخول
اليوم ، يحتاج أي صاحب عمل إلى محلل لفهم ماهية SQL. إذا كنت تعرف ANSI SQL ، فيمكن أن يطلق عليك اسم مستخدم Vertica الواثق. إذا كان بإمكانك بناء نماذج في Python و R ، فأنت مجرد "مدلك" للبيانات. إذا كنت تتقن Linux ولديك معرفة أساسية بإدارة Vertica ، فيمكنك العمل كمسؤول. بشكل عام ، عتبة الدخول في Vertica منخفضة ، ولكن ، بالطبع ، لا يمكن العثور على جميع الفروق الدقيقة إلا عن طريق حشو اليد أثناء العملية.
هندسة الأجهزة
ضع في اعتبارك Vertica على مستوى الكتلة. يوفر نظام إدارة قواعد البيانات (DBMS) هذا معالجة بيانات متوازية بشكل كبير (MPP) في بنية حوسبة موزعة - "لا شيء مشترك" - حيث ، من حيث المبدأ ، أي عقدة جاهزة لالتقاط وظائف أي عقدة أخرى. الخصائص الرئيسية:
- ليس هناك نقطة واحدة للفشل
- كل عقدة مستقلة ومستقلة ،
- لا توجد نقطة اتصال واحدة للنظام بأكمله ،
- تتكرر عقد البنية التحتية ،
- يتم نسخ البيانات الموجودة على عقد الكتلة تلقائيًا.
تتدرج الكتلة خطيا دون أي مشاكل. نحن ببساطة نضع الخوادم في الرف ونربطها من خلال واجهة رسومية. بالإضافة إلى الخوادم التسلسلية ، يمكن النشر على الأجهزة الافتراضية. ما الذي يمكن تحقيقه مع التمديد؟
- يزيد حجم البيانات الجديدة
- زيادة عبء العمل الأقصى
- تحسين المرونة. كلما زاد عدد العقد في المجموعة ، قل احتمال فشل المجموعة بسبب الفشل ، وبالتالي ، كلما اقتربنا من ضمان التوفر على مدار الساعة طوال أيام الأسبوع.
ولكن هناك بعض الأشياء التي يجب مراعاتها. بشكل دوري ، يجب إزالة العقد من المجموعة للصيانة. حالة أخرى شائعة إلى حد ما في المؤسسات الكبيرة هي أن الخوادم خارج الضمان والانتقال من بيئة إنتاجية إلى نوع من بيئة الاختبار. ويحل محلها محل جديد يخضع لضمانة الشركة المصنعة. بناءً على نتائج كل هذه العمليات ، فإن إعادة التوازن ضرورية. هذه عملية حيث يتم إعادة توزيع البيانات بين العقد - وبالتالي ، يتم إعادة توزيع عبء العمل. هذه عملية تستهلك الكثير من الموارد ، وفي المجموعات التي تحتوي على كمية كبيرة من البيانات ، يمكن أن تقلل الأداء بشكل كبير. لتجنب ذلك ، تحتاج إلى تحديد نافذة الخدمة - الوقت الذي يكون فيه الحمل ضئيلًا ، وفي هذه الحالة لن يلاحظه المستخدمون.
الإسقاطات
لفهم كيفية تخزين البيانات في Vertica ، تحتاج إلى التعامل مع أحد المفاهيم الأساسية - الإسقاط.
الوحدات المنطقية لتخزين المعلومات هي الرسوم البيانية والجداول ووجهات النظر. الوحدات المادية هي إسقاطات. تأتي الإسقاطات في عدة أنواع:
- الفائق
- إسقاطات خاصة بطلبات البحث
- التوقعات الإجمالية
عند إنشاء أي جدول ، يتم إنشاء
إسقاط فائق تلقائيًا يحتوي على جميع أعمدة جدولنا. إذا كنت بحاجة إلى تسريع أي من العمليات المنتظمة ، فيمكننا إنشاء
إسقاط خاص
موجه نحو الاستعلام يحتوي على ، على سبيل المثال ، 3 من أصل 10 أعمدة.
النوع الثالث مخصص أيضًا للتسريع -
الإسقاطات المجمعة . لن أخوض في فئاتهم الفرعية - هذا ليس مثيرًا للاهتمام. أريد أن أحذرك على الفور أنه ليس من المفيد حل مشكلاتك باستمرار مع تنفيذ الاستعلام من خلال إنشاء توقعات جديدة. في النهاية ، ستبدأ الكتلة في التباطؤ.
عند إنشاء الإسقاطات ، نحتاج إلى تقييم ما إذا كانت استعلاماتنا تحتوي على ما يكفي من المشاريع الفائقة. إذا كنا لا نزال نرغب في التجربة ، فإننا نضيف إسقاطًا جديدًا واحدًا بدقة. إذا ظهرت مشاكل ، سيكون من الأسهل العثور على السبب الجذري. للجداول الكبيرة ، قم بإنشاء إسقاط مجزأ. وهي مقسمة إلى أجزاء يتم توزيعها عبر عدة عقد ، مما يزيد من تحمل الخطأ ويقلل الحمل على عقدة واحدة. إذا كانت الأجهزة اللوحية صغيرة ، فمن الأفضل عمل إسقاطات غير مجزأة. يتم نسخها بالكامل إلى كل عقدة ، وبالتالي يزداد الأداء. سأحجز: من حيث Vertica ، فإن جدول "صغير" حوالي 1 مليون صف.
التسامح مع الخطأ
يتم تطبيق التسامح مع الخطأ في Vertica باستخدام آلية السلامة K. إنه بسيط للغاية من حيث الوصف ، ولكنه معقد من حيث العمل على مستوى المحرك. يمكن التحكم فيه باستخدام معلمة K-Safety - يمكن أن يكون له قيمة 0 أو 1 أو 2. تحدد هذه المعلمة عدد نسخ بيانات الإسقاط المجزأة.
تسمى نسخ الإسقاطات إسقاط الأصدقاء. حاولت ترجمة هذه العبارة من خلال مترجم Yandex واتضح شيئًا مثل "الإسقاط الجانبي". عرضت جوجل خيارات وأكثر إثارة للاهتمام. عادة ، تسمى هذه التوقعات بالشريك أو الجوار ، وفقًا للغرض الوظيفي. هذه إسقاطات يتم تخزينها ببساطة على العقد المجاورة وبالتالي محفوظة. لا تحتوي الإسقاطات غير المجزأة على إسقاطات الأصدقاء - يتم نسخها بالكامل.
كيف يعمل؟ خذ بعين الاعتبار مجموعة من خمسة آلات. دعوا K-safety يساوي 1.

العقد مُرقّمة ، وتحت تحتها إسقاطات شريك مكتوبة يتم تخزينها عليها. افترض أن لدينا عقدة واحدة غير متصلة. ماذا سيحدث؟

تحتوي العقدة 1 على إسقاط سهل للعقدة 2. وبالتالي ، سيزداد الحمل على العقدة 1 ، لكن الكتلة لن تتوقف عن العمل. والآن هذا الوضع:
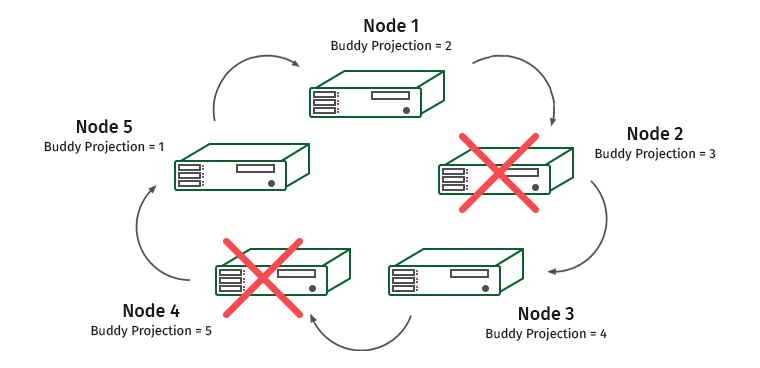
تحتوي العقدة 3 على إسقاط العقدة 4 ، وسيتم تحميل العقدتين 1 و 3 بشكل زائد.
نحن نعقد المهمة. K-Safety = 2 ، قم بتعطيل عقدتين متجاورتين.
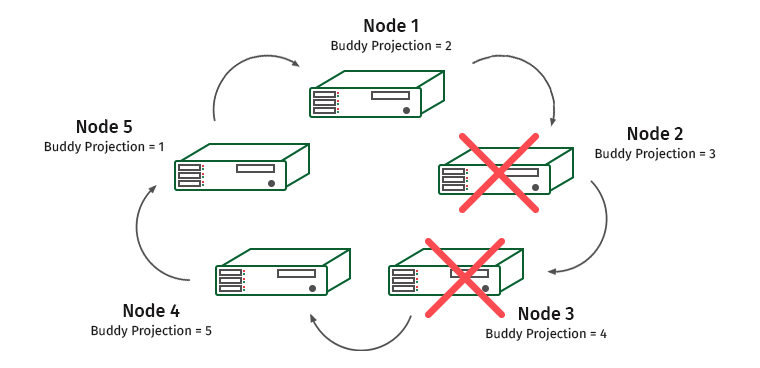
هنا سيتم تحميل العقدتين 1 و 4 بشكل زائد (العقدة 2 تحتوي على إسقاط العقدة 1 ، والعقدة 3 تحتوي على إسقاط العقدة 4).
في مثل هذه الحالات ، يتعرف محرك النظام على أن إحدى العقد لا تستجيب ، ويتم نقل الحمل إلى العقدة المجاورة. سيتم استخدامه حتى يتم استعادة العقدة مرة أخرى. بمجرد حدوث ذلك ، يتم إعادة توزيع الحمل والبيانات مرة أخرى. بمجرد أن نفقد أكثر من نصف الكتلة أو العُقد التي تحتوي على جميع نسخ بعض البيانات ، فإن الكتلة تستيقظ.
تخزين البيانات المنطقية
تحتوي Vertica على مناطق تخزين محسنة للكتابة ، ومناطق محسنة للقراءة ، وآلية Tuple Mover التي تسمح بتدفق البيانات من الأول إلى الثاني.
عند استخدام عمليات COPY و INSERT و UPDATE ، فإننا ننتهي تلقائيًا في WOS (كتابة المحسّن المحسن) ، وهي منطقة لا يتم فيها تحسين البيانات للقراءة وفرزها إلا عند طلبها ، وتخزينها دون ضغط أو فهرسة. إذا كانت أحجام البيانات كبيرة جدًا بالنسبة لمنطقة WOS ، فاستخدم العبارة DIRECT الإضافية ، فيجب كتابتها على الفور إلى ROS. خلاف ذلك ، فإن WOS ستكون ممتلئة وسوف نتحطم.
بعد انتهاء الوقت المحدد في الإعدادات ، تتدفق البيانات من WOS إلى ROS (اقرأ القراءة المحسنة) - وهي بنية محسنة وموجهة للقراءة لتخزين القرص. تقوم ROS بتخزين معظم البيانات ، وهنا يتم فرزها وضغطها. تنقسم بيانات ROS إلى حاويات تخزين. الحاوية هي مجموعة من الخطوط التي تم إنشاؤها بواسطة مشغلي الترجمة (COPY DIRECT) ، ويتم تخزينها في مجموعة محددة من الملفات.
بغض النظر عن مكان كتابة البيانات - في WOS أو في ROS - فهي متاحة على الفور. لكن القراءة من WOS أبطأ لأن البيانات ليست مجمعة هناك.

Tuple Mover هي أداة تنظيف تؤدي عمليتين:
- Moveout - ضغط البيانات وفرزها في WOS ، ونقلها إلى ROS وإنشاء حاويات جديدة لها في ROS.
- دمج - تجتاحنا عندما نستخدم DIRECT. لا يمكننا دائمًا تحميل الكثير من المعلومات للحصول على حاويات ROS كبيرة. لذلك ، فإنه يجمع بشكل دوري بين حاويات ROS الصغيرة في حاويات أكبر ، وينظف البيانات المحددة للحذف ، أثناء العمل في الخلفية (وفقًا للوقت المحدد في التكوين).
ما هي فوائد تخزين العمود؟
إذا قرأنا الأسطر ، على سبيل المثال ، لتنفيذ أمر
SELECT 1,11,15 from table1
سيتعين علينا قراءة الجدول بأكمله. هذه كمية ضخمة من المعلومات. في هذه الحالة ، يكون نهج العمود أكثر ربحية. يسمح لك بحساب الأعمدة الثلاثة فقط التي نحتاجها ، مما يوفر الذاكرة والوقت.

تخصيص الموارد
لتجنب المشاكل ، يحتاج المستخدم إلى أن يكون محدودًا قليلاً. هناك دائمًا فرصة أن يكتب المستخدم طلبًا كثيفًا يلتهم جميع الموارد. بشكل افتراضي ، تحتل Vertica جزءًا كبيرًا من المنطقة العامة ، بالإضافة إلى ذلك ، يتم تمييز مناطق منفصلة لـ Tuple Mover و WOS وعمليات النظام (الاسترداد ، وما إلى ذلك).
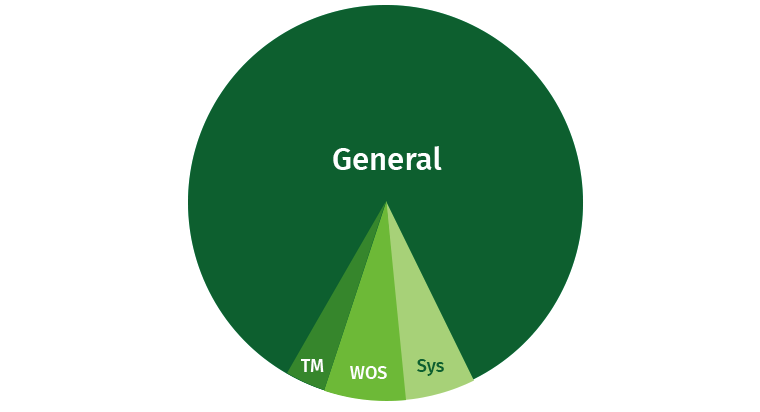
دعونا نحاول مشاركة هذه الموارد. نقوم بإنشاء مناطق للكُتّاب والقراء والاستعلامات البطيئة ذات الأولوية المنخفضة.

إذا نظرنا إلى جداول النظام التي يتم تخزين مواردنا فيها - تجمعات الموارد - فسوف نرى العديد من المعلمات التي يمكنك من خلالها ضبط كل شيء بدقة أكبر. في البداية ، لا يجب أن تخوض في ذلك ، فمن الأفضل أن تقصر نفسك على قطع الذاكرة لبعض المهام. عندما تكتسب الخبرة وتكون متأكدًا بنسبة 100 ٪ من أنك تفعل كل شيء بشكل صحيح ، سيكون من الممكن التجربة.
تتضمن الإعدادات الرفيعة أولوية التنفيذ وجلسات تنافسية ومقدار الذاكرة المخصصة. حتى مع المعالجات يمكننا إصلاح شيء ما. للعمل باستخدام هذه الإعدادات ، أنت بحاجة إلى ثقة كاملة في صحة أفعالك ، لذا من الأفضل الحصول على دعم الشركة ولديك الحق في ارتكاب خطأ.
فيما يلي مثال على طلب يمكنك من خلاله رؤية إعدادات التجمع العام:
dbadmin => select * FROM resource_pools WHERE NAME = 'general';
-[ RECORD 1 ]------------+---------------
pool_id | 45035996273721212
name | general
is_internal | t
memorysize |
maxmemorysize | 30G
executionparallelism | AUTO
priority | 0
runtimepriority | MEDIUM
runtimeprioritythreshold | 2
queuetimeout | 0:05
plannedconcurrency | 10
maxconcurrency | 20
runtimecap |
singleinitiator | f
cpuaffinityset |
cpuaffinitymode | ANY
cascadeto |ANSI SQL وميزات أخرى
- تسمح لك Vertica بالكتابة في SQL-99 - يتم دعم جميع الوظائف.
- تتمتع Verica بقدرات تحليلية رائعة - حتى أدوات التعلم الآلي مضمنة
- يمكن لـ Vertica فهرسة النصوص
- تقوم Vertica بمعالجة البيانات شبه المنظمة
التكامل
تم دمج Vertica ، مثل جميع الأدوات الحالية ، بجدية مع الأنظمة الأخرى. قادرة على العمل بشكل جيد مع HDFS (Hadoop). في الإصدارات السابقة ، كان بإمكان Vertica تنزيل البيانات فقط من HDFS بتنسيقات معينة ، ولكن الآن يمكنها القيام بكل شيء ، وتعمل مع جميع التنسيقات ، على سبيل المثال ، ORC و Parquet. يمكنه حتى إرفاق الملفات كجداول خارجية وتخزين بياناتها في حاويات ROS مباشرة على HDFS. في الإصدار الثامن من Vertica ، تم إجراء تحسين كبير لسرعة العمل مع HDFS ، كتالوج البيانات الوصفية وتحليل هذه التنسيقات. يمكنك بناء مجموعة Vertica مباشرة على كتلة Hadoop.
بدءًا من الإصدار 7.2 ، يمكن أن تعمل Vertica مع Apache Kafka - إذا احتاج شخص إلى وسيط رسائل.
لدى Vertica 8 الدعم الكامل لـ Spark. من الممكن نسخ البيانات من Spark إلى Vertica والعكس صحيح.
الخلاصة
Vertica هو خيار جيد للعمل مع البيانات الضخمة التي لا تتطلب الكثير من معرفة الإدخال. هذا DBMS لديه قدرات تحليلية واسعة. من السلبيات - هذا الحل ليس مفتوح المصدر ، ولكن يمكنك محاولة النشر مجانًا بحد أقصى 1 تيرابايت وثلاث عقد - وهذا يكفي لفهم ما إذا كنت بحاجة إلى Vertica أم لا.