تستخدم جميع أنظمة الإشراف الحديثة إما
التعهيد الجماعي أو التعلم الآلي الذي أصبح بالفعل كلاسيكيًا. في تدريب ML التالي في ياندكس ، تحدث كونستانتين كوتيك وإيجور غاليتسكي وأليكسي نوسكوف عن مشاركتهم في المسابقة من أجل التعرف الجماعي على التعليقات المسيئة. أقيمت المسابقة على منصة Kaggle.
- مرحبا بالجميع! اسمي كونستانتين كوتيك ، وأنا عالم بيانات في شركة Button of Life وطالب في قسم الفيزياء وكلية الدراسات العليا في جامعة موسكو الحكومية.
اليوم ، سيخبرك زملاؤنا ، إيغور غاليتسكي وأليكسي نوسكوف ، عن مسابقة تحدي تصنيف التعليقات السامة ، التي احتل فيها فريق DecisionGuys المركز العاشر بين 4551 فريقًا.
قد يكون من الصعب إجراء مناقشة عبر الإنترنت للمواضيع التي تهمنا. غالبًا ما تجبر الإهانات والعدوان والمضايقة التي تحدث عبر الإنترنت العديد من الأشخاص على التخلي عن البحث عن الآراء المناسبة المختلفة حول القضايا التي تهمهم ، لرفض التعبير عن أنفسهم.
تكافح العديد من الأنظمة الأساسية للتواصل بشكل فعال عبر الإنترنت ، ولكن هذا غالبًا ما يؤدي إلى إغلاق العديد من المجتمعات لتعليقات المستخدمين.
يعمل فريق بحث واحد من Google وشركة أخرى على أدوات للمساعدة في تحسين المناقشة عبر الإنترنت.
من الحيل التي يركزون عليها استكشاف السلوكيات السلبية عبر الإنترنت مثل التعليقات السامة. يمكن أن تكون هذه التعليقات مسيئة أو غير محترمة أو يمكن أن تجبر المستخدم على ترك المناقشة.

حتى الآن ، طورت هذه المجموعة واجهة برمجة تطبيقات عامة يمكنها تحديد درجة سمية التعليق ، لكن نماذجها الحالية لا تزال ترتكب أخطاء. وفي هذه المسابقة ، تم تحدينا ، نحن Kegglers ، لبناء نموذج كان قادرًا على تحديد التعليقات التي تحتوي على التهديدات والكراهية والإهانات وما شابه ذلك. وبشكل مثالي ، كان هذا النموذج مطلوبًا ليكون أفضل من النموذج الحالي لواجهة برمجة التطبيقات الخاصة بهم.
لدينا مهمة معالجة النص: لتحديد التعليقات ثم تصنيفها. كعينات تدريب واختبار ، تم تقديم التعليقات من صفحات مناقشة ويكيبيديا. كان هناك حوالي 160 ألف تعليق في القطار ، 154 ألفًا في الاختبار.

تم وضع علامة على عينة التدريب على النحو التالي. يحتوي كل تعليق على ستة ملصقات. تأخذ العلامات القيمة 1 إذا كان التعليق يحتوي على هذا النوع من السمية ، 0 خلاف ذلك. وقد تكون جميع التسميات صفرًا ، وهي حالة تعليق كافية. أو قد يكون تعليق واحد يحتوي على عدة أنواع من السمية ، على الفور تهديد وفحش.
نظرًا لحقيقة أننا على الهواء ، لا يمكنني عرض أمثلة محددة لهذه الفئات. فيما يتعلق بعينة الاختبار ، كان من الضروري لكل تعليق للتنبؤ باحتمالية كل نوع من السمية.
مقياس الجودة هو ROC AUC الذي تم حسابه في المتوسط على أنواع السمية ، أي المتوسط الحسابي لـ ROC AUC لكل فئة على حدة.
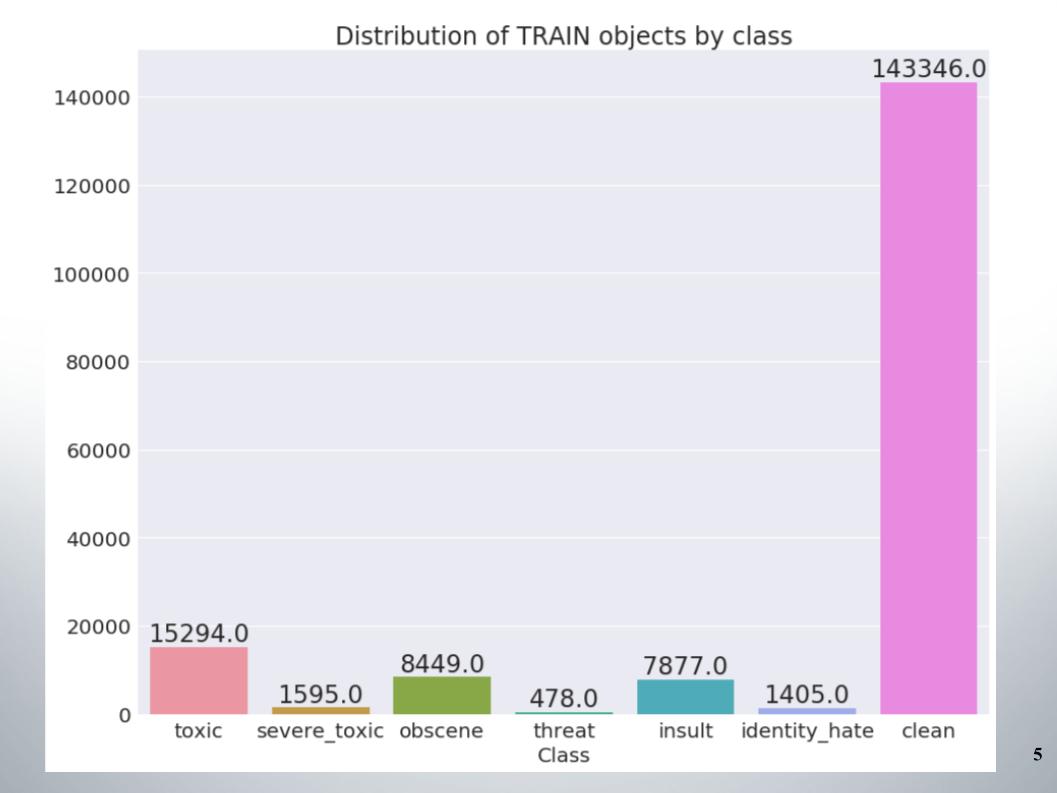
هنا توزيع الأشياء حسب الفئات في مجموعة التدريب. يمكن ملاحظة أن البيانات غير متوازنة للغاية. يجب أن أقول على الفور أن فريقنا سجل نقاطًا على عينة من الأساليب للعمل مع البيانات غير المتوازنة ، على سبيل المثال ، الإفراط أو الاختزال.

عند بناء النموذج ، استخدمت معالجة بيانات على مرحلتين. المرحلة الأولى هي المعالجة الأساسية للبيانات ، وهذه هي تحويلات العرض على الشريحة ، وهذا يؤدي إلى جعل النص صغيرًا وحذف الروابط وعناوين IP والأرقام وعلامات الترقيم.

بالنسبة لجميع النماذج ، تم استخدام معالجة البيانات الأساسية هذه. في المرحلة الثانية ، تم تنفيذ المعالجة المسبقة الجزئية للبيانات - استبدال الرموز التعبيرية بالكلمات المقابلة ، وفك تشفير الاختصارات ، وتصحيح الأخطاء الإملائية في اللغة البذيئة ، وإحضار الأنواع المختلفة من الحصائر إلى نفس الشكل ، وكذلك حذف الصور. في بعض التعليقات ، تمت الإشارة إلى روابط للصور ، قمنا ببساطة بإزالتها.
لكل من النماذج ، تم استخدام المعالجة الجزئية للبيانات وعناصرها المختلفة. تم كل هذا من أجل النماذج الأساسية لتقليل الارتباط المتبادل بين النماذج الأساسية عند بناء المزيد من التكوين.
دعنا ننتقل إلى الجزء الأكثر إثارة للاهتمام - بناء نموذج.
تخليت على الفور عن أسلوب الحقيبة التقليدية للكلمات. يرجع ذلك إلى حقيقة أن كل كلمة في هذا النهج هي سمة منفصلة. هذا النهج لا يأخذ في الاعتبار ترتيب الكلمات العام ؛ من المفترض أن الكلمات مستقلة. في هذا النهج ، يحدث توليد النص بحيث يكون هناك بعض التوزيع في الكلمات ، ويتم اختيار كلمة بشكل عشوائي من هذا التوزيع وإدراجها في النص.
بالطبع ، هناك عمليات توليد أكثر تعقيدًا ، لكن الجوهر لا يتغير - هذا النهج لا يأخذ في الاعتبار ترتيب الكلمات العام. يمكنك الذهاب إلى إنغرامز ، ولكن ترتيب الكلمات فقط سيؤخذ بعين الاعتبار هناك ، وليس عامًا. لذلك ، فهمت أيضًا زملائي في الفريق أنهم بحاجة إلى استخدام شيء أكثر ذكاءً.
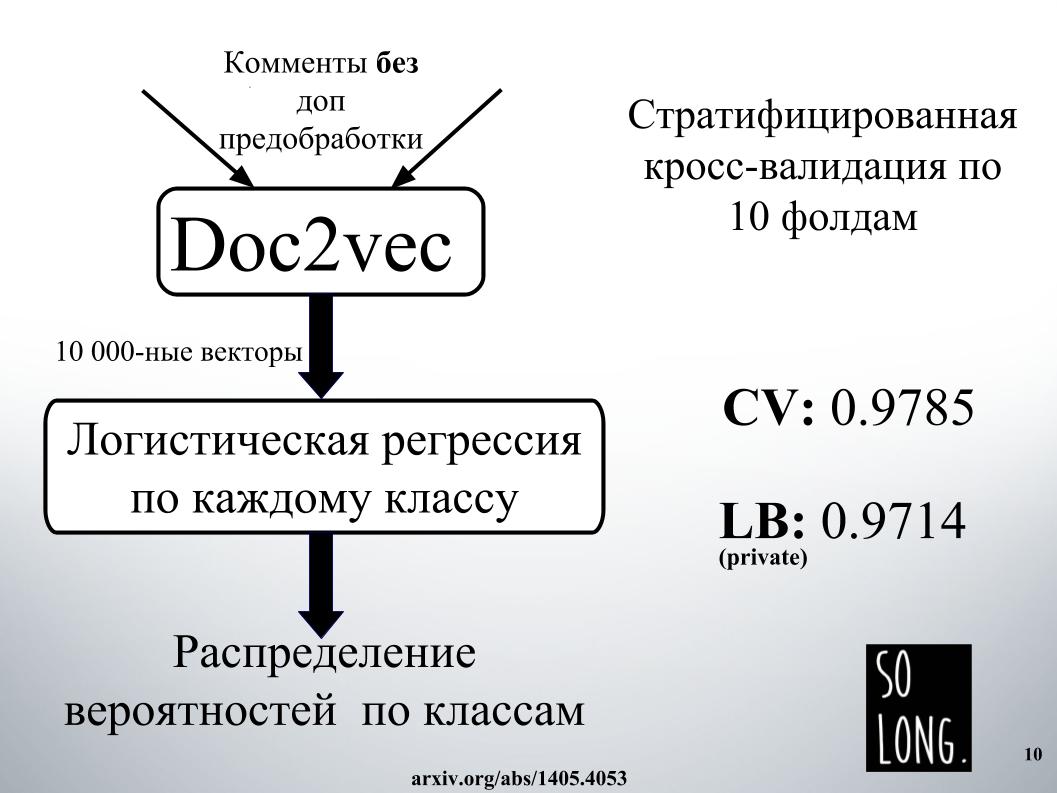
أول شيء ذكي حدث لي هو استخدام تمثيل متجه باستخدام Doc2vec. هذا هو Word2vec بالإضافة إلى ناقل يأخذ في الاعتبار تفرد مستند معين. في المقالة الأصلية ، يسمى هذا المتجه باسم فقرة المعرف.
ثم ، وفقًا لهذا التمثيل المتجه ، تم دراسة الانحدار اللوجستي ، حيث تم تمثيل كل وثيقة بمتجه 10000 الأبعاد. تم إجراء تقييم الجودة من خلال التحقق المتقاطع لعشرة أضعاف ، وتم تقسيمه إلى طبقات ، ومن المهم ملاحظة أنه تم دراسة الانحدار اللوجستي لكل فئة ، وتم حل ست مشكلات تصنيف بشكل منفصل. وفي النهاية ، كانت النتيجة توزيع احتمالي حسب الفئة.
تم تدريب الانحدار اللوجستي لفترة طويلة جدا. أنا عموما لا تتناسب مع ذاكرة الوصول العشوائي. في مرافق إيغور ، أمضوا يومًا في مكان ما للحصول على النتيجة ، مثل الشريحة. لهذا السبب ، رفضنا على الفور استخدام Doc2vec بسبب التوقعات العالية ، على الرغم من أنه يمكن تحسينه بمقدار 1000 إذا تم إجراء تعليق مع معالجة إضافية للبيانات.

الأكثر ذكاءً الذي استخدمناه نحن والمنافسون الآخرون كانت شبكات عصبية متكررة. يتلقون كلمات بالتتابع عند المدخل ، ويحدثون حالتها المخفية بعد كل كلمة. استخدمنا أنا وإيجور شبكة GRU المتكررة لتضمين كلمة fastText ، وهي خاصة في أنها تحل العديد من مشاكل التصنيف الثنائية المستقلة. توقع وجود أو عدم وجود كلمة السياق بشكل مستقل.
أجرينا أيضًا تقييمًا للجودة على التحقق المتبادل لعشرة أضعاف ، ولم يتم تقسيمه هنا ، وهنا تم الحصول على توزيع الاحتمالية على الفور بواسطة الفصل. لم يتم حل كل مشكلة تصنيف ثنائي بشكل منفصل ، ولكن تم إنشاء ناقل سداسي الأبعاد على الفور. كانت واحدة من أفضل الموديلات الفردية.
تسأل ، ما سر النجاح؟
كان يتألف من المزج ، وكان هناك الكثير منه ، مع التراص ، والشبكات في النهج. يجب أن يتم تصوير نهج التواصل على شكل رسم بياني موجه.
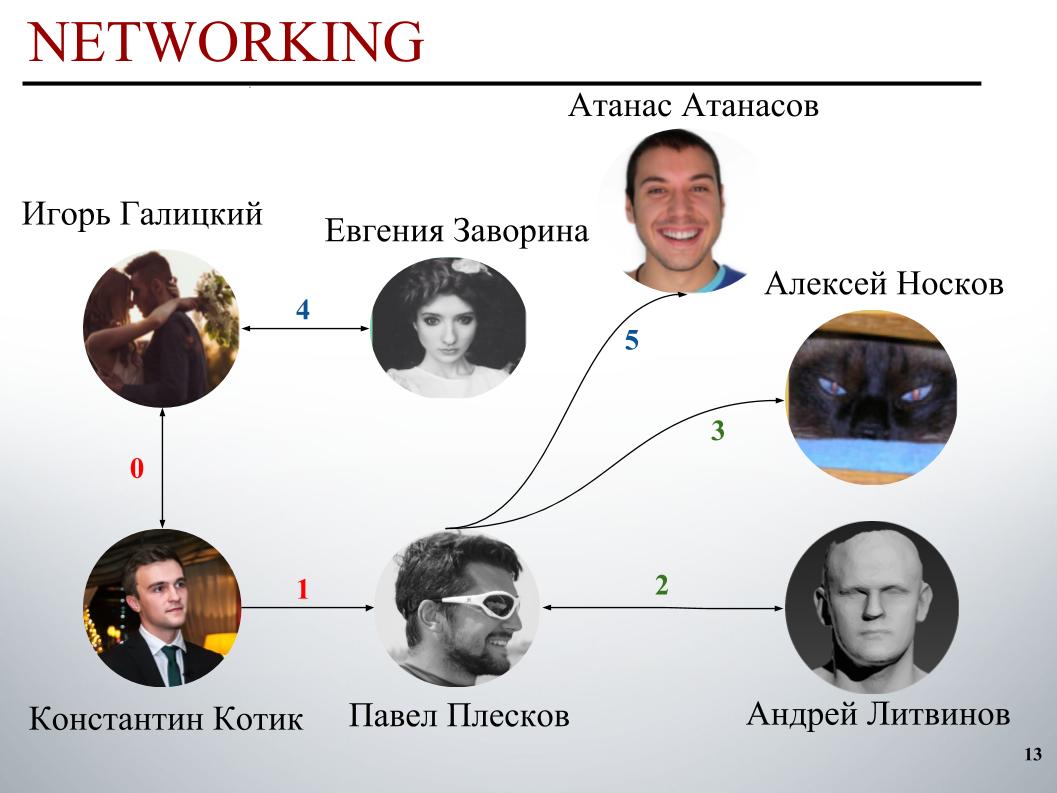
في بداية المسابقة ، كان فريق DecisionGuys يتألف من شخصين. ثم عبر بافيل بليسكوف في قناة ODS Slack عن رغبته في التعاون مع شخص من أفضل 200 لاعب. في ذلك الوقت كنا في مكان ما في المركز 157 ، وبافل بليسكوف في المركز 154 ، في مكان ما في الحي. لاحظ إيغور رغبته في الانضمام ، ودعته إلى الفريق. ثم انضم إلينا أندري ليتفينوف ، ثم دعا بافيل Grandmaster Alexei Noskov إلى فريقنا. إيغور - يوجين. وكان الشريك الأخير لفريقنا هو البلغاري أتاناس أتاناسوف ، وكان ذلك نتيجة فرقة دولية بشرية.
الآن سيخبر إيغور غاليتسكي كيف قام بتدريس اللغة ، بمزيد من التفصيل ، سيتحدث عن أفكار ونهج بافل بليسكوف وأندريه ليتفينوف وأتاناس أتاناسوف.
إيجور جاليتسكي:
- أنا عالم بيانات في Epoch8 ، وسأتحدث عن معظم البنيات التي استخدمناها.
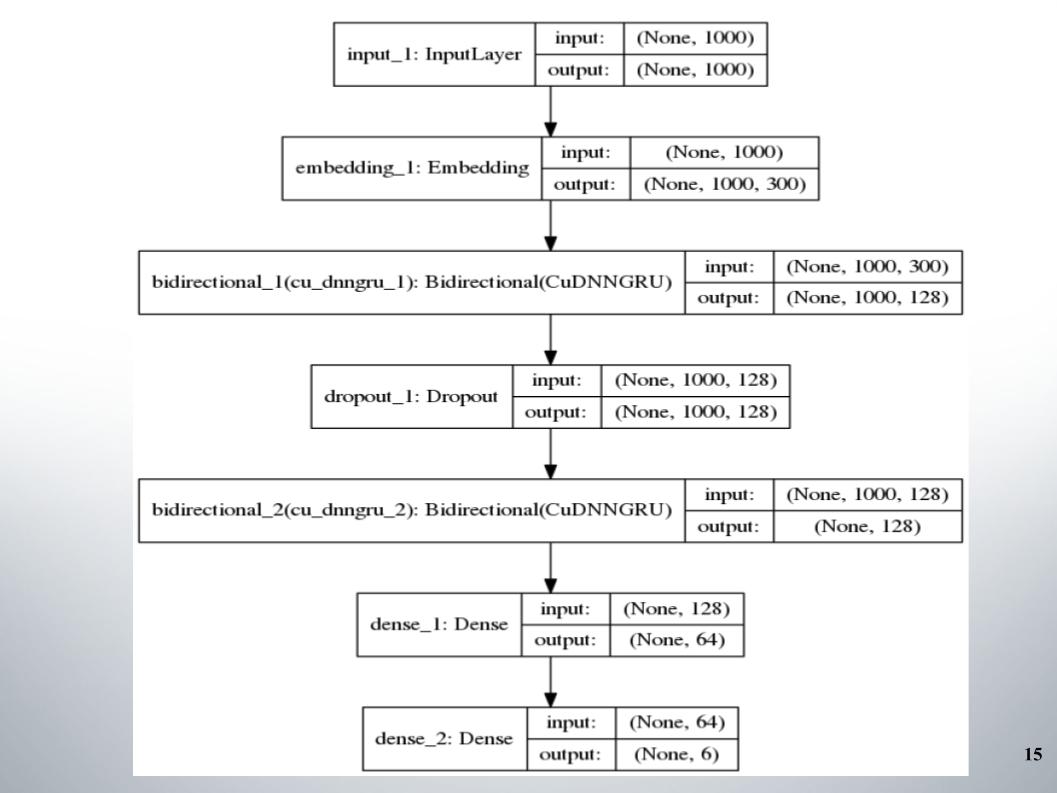
بدأ كل شيء مع التوجية الاتجاهية القياسية مع طبقتين ، استخدمتها جميع الفرق تقريبًا ، واستخدمت fastText ، وهي وظيفة التنشيط EL ، كالتضمين.
لا يوجد شيء خاص للقول ، هندسة بسيطة ، بدون زخرفة. لماذا أعطتنا مثل هذه النتائج الجيدة التي بقينا بها في قائمة أفضل 150 لبعض الوقت؟ كان لدينا معالجة جيدة للنص. كان من الضروري المضي قدما.
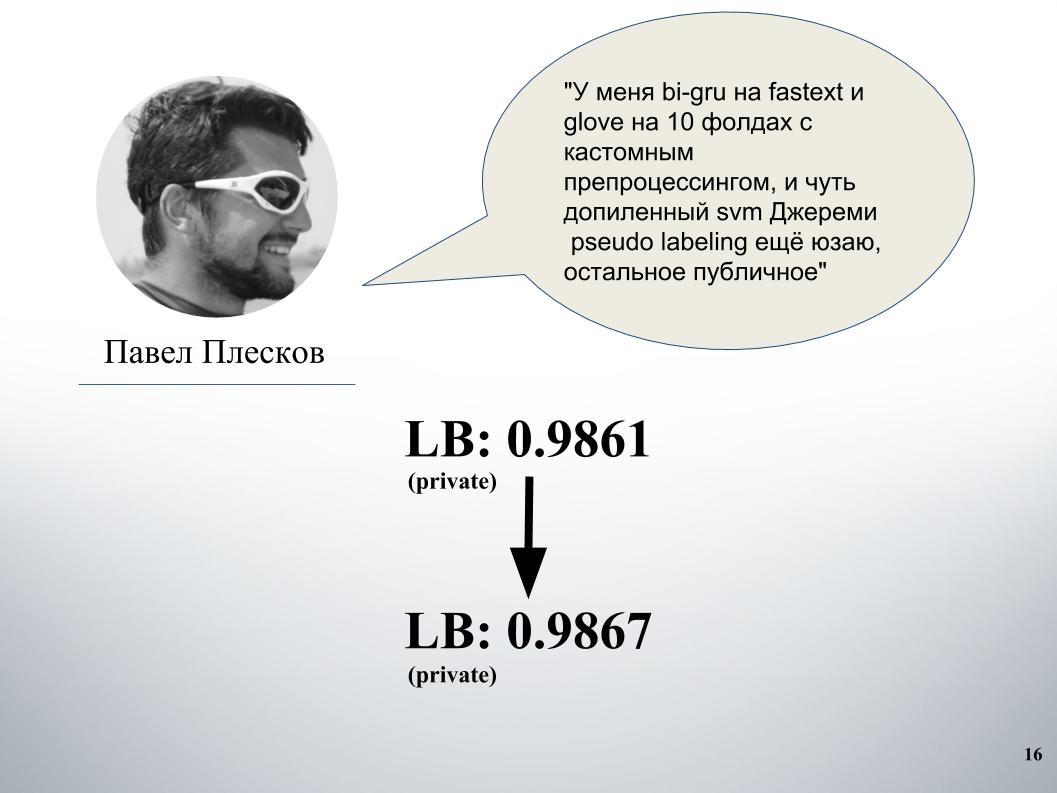
كان لدى بول منهجه الخاص. بعد المزج مع بلدنا ، أعطى هذا زيادة كبيرة. قبل ذلك ، كان لدينا مزيج جرو ونموذج على Doc2vec ، أعطت 61 رطل.
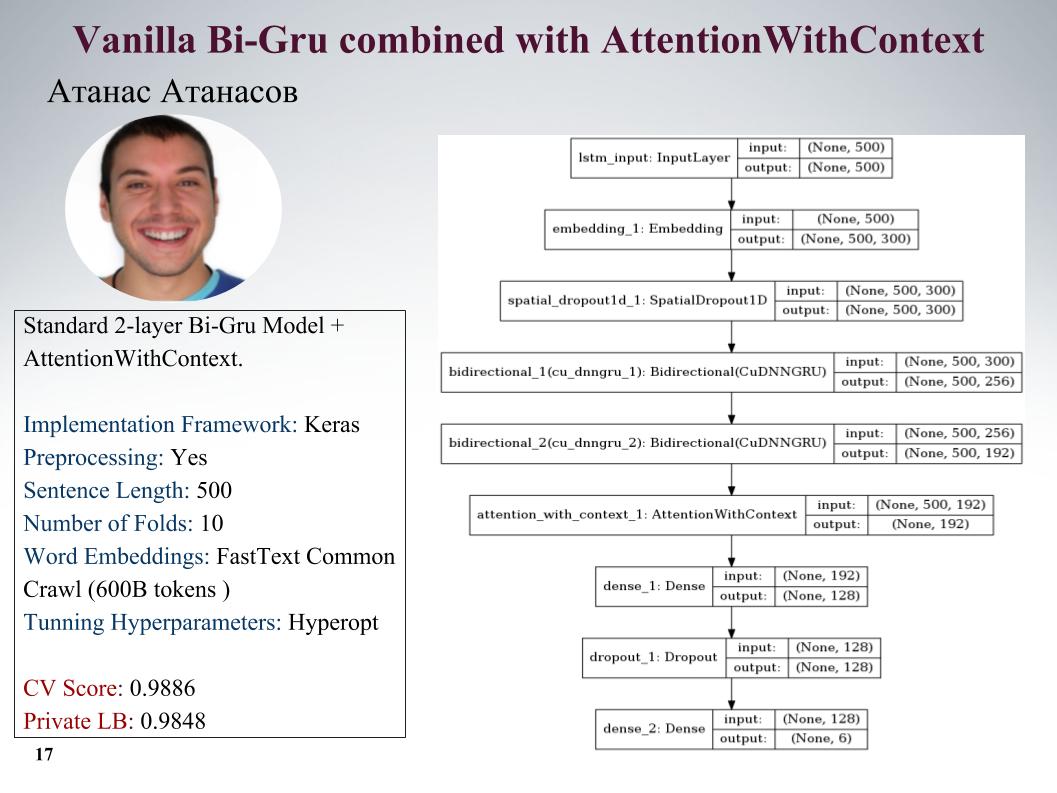
سأخبرك عن نهج Atanas Atanasov ، فهو متحمس مباشرة لأي مقالات جديدة. هنا جرو مع الاهتمام ، جميع المعلمات على الشريحة. كان لديه الكثير من المقاربات الرائعة حقًا ، ولكن حتى اللحظة الأخيرة استخدم معالجة مسبقة له ، وتم تسوية كل الأرباح. السرعة على الشريحة.
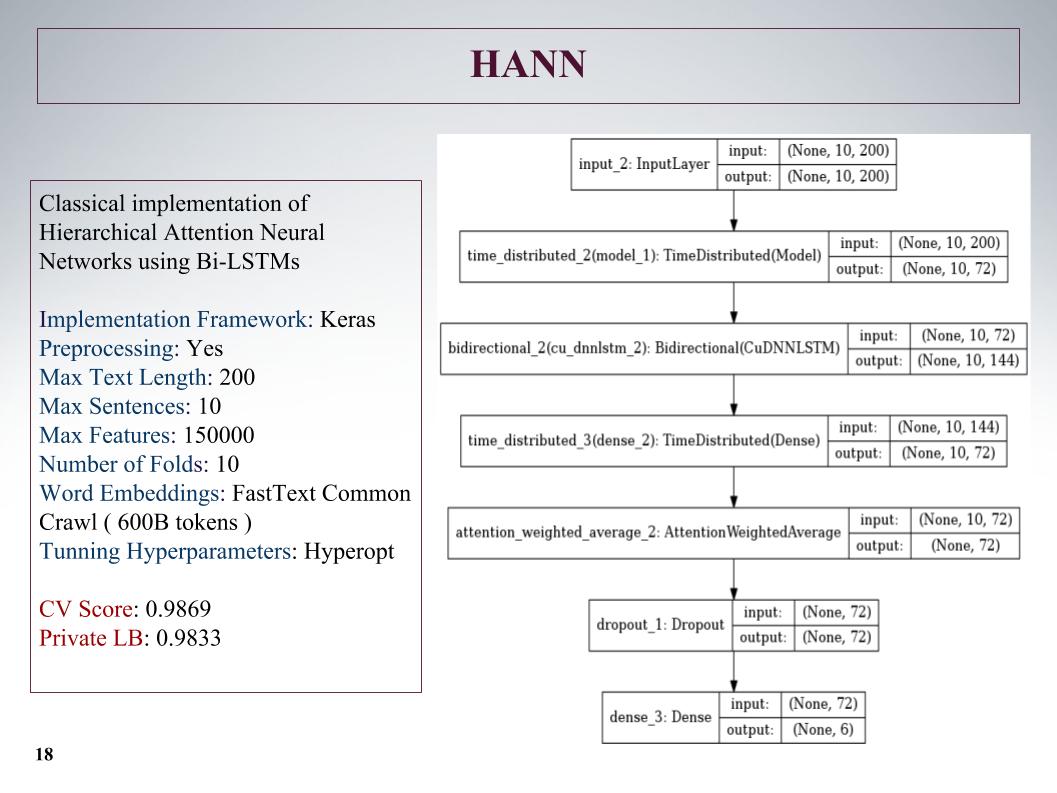
ثم كان هناك اهتمام هرمي ، فقد أظهر نتائج أسوأ ، حيث كان في البداية شبكة لتصنيف المستندات التي تتكون من جمل. لقد أفسد الأمر ، لكن النهج ليس صعبًا.
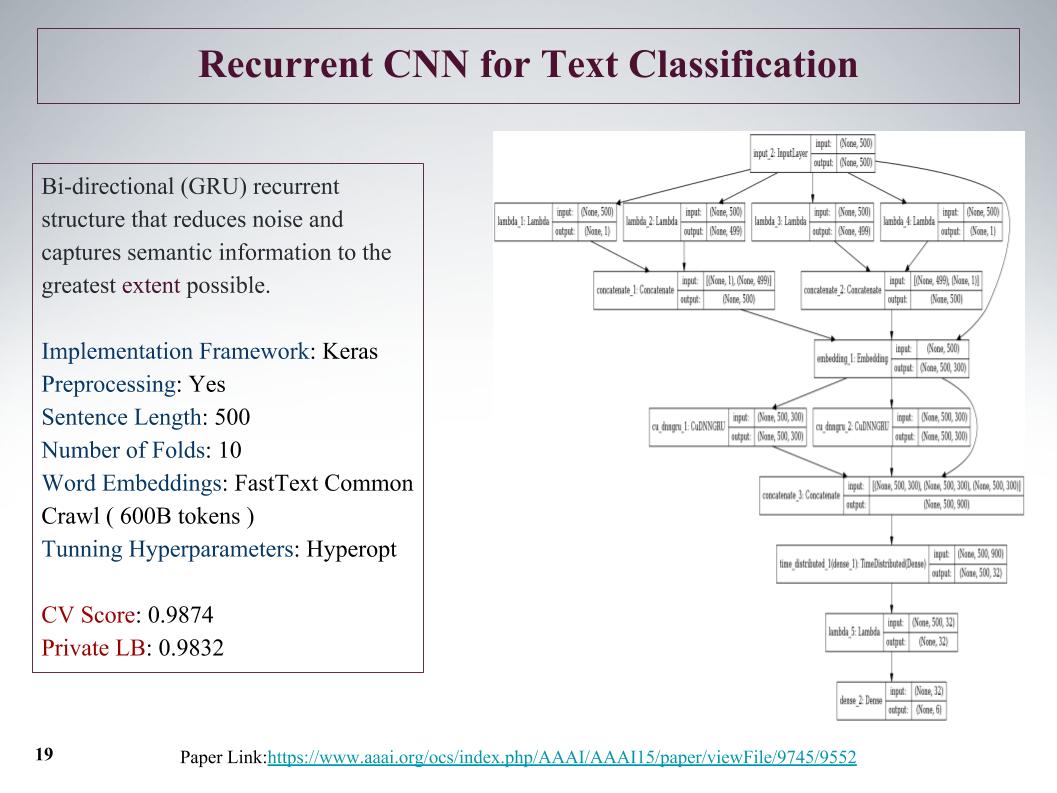
كان هناك نهج مثير للاهتمام ، يمكننا في البداية الحصول على ميزات من العرض من البداية ومن النهاية. بمساعدة الالتفاف ، الطبقات التلافيفية ، نحصل بشكل منفصل على ميزات على يسار ويمين الشجرة. هذا من بداية الجملة ونهايتها ، ثم يتم دمجها وتشغيلها مرة أخرى من خلال gru.

أيضا Bi-GRU مع كتلة الانتباه. أظهر هذا هو واحد من أفضل في القطاع الخاص كانت شبكة عميقة إلى حد ما ، وأظهرت نتائج جيدة.

النهج التالي هو تسليط الضوء على الميزات قدر الإمكان؟ بعد طبقة الشبكة المتكررة ، نقوم بعمل ثلاث طبقات متوازية أخرى من الالتواء. وهنا لم نأخذ جملًا طويلة ، قطعناها إلى 250 ، ولكن بسبب ثلاث لفات ، أعطى هذا نتيجة جيدة.

كانت الشبكة الأعمق. كما قال أتاناس ، أراد فقط تعليم شيء كبير ومثير للاهتمام. شبكة تلافيفية عادية تعلمت من ميزات النص ، والنتائج ليست خاصة.

هذا نهج جديد مثير للاهتمام إلى حد ما ، في عام 2017 كان هناك مقال حول هذا الموضوع ، تم استخدامه لـ ImageNet ، وهناك سمح لنا بتحسين النتيجة السابقة بنسبة 25 ٪. ميزتها الرئيسية هي أن طبقة صغيرة يتم إطلاقها بالتوازي مع الكتلة التلافيفية ، التي تعلم الأوزان لكل الالتفاف في هذه الكتلة. أعطت طريقة رائعة للغاية ، على الرغم من قطع الجمل.
المشكلة هي أن الحد الأقصى لطول الجمل في هذه المهام بلغ 1500 كلمة ، وكانت هناك تعليقات كبيرة جدًا. كان لدى الفرق الأخرى أيضًا أفكار حول كيفية اللحاق بهذا العرض الكبير ، وكيفية العثور عليه ، لأن كل شيء ليس مدفوعًا للغاية. وقال الكثير أنه في نهاية الجملة كان هناك INFA مهم جدا. لسوء الحظ ، في جميع هذه الأساليب ، لم يؤخذ هذا في الاعتبار ، لأنه تم أخذ البداية. ربما هذا سيعطي زيادة أخرى.

هنا هي بنية AC-BLSTM. خلاصة القول هي أنه إذا كان التقسيم السفلي إلى قسمين ، بالإضافة إلى الانتباه ، يسحب بذكاء ، ولكن في موازاة ذلك ، لا يزال هناك أمر طبيعي ، وهذا كله يتم تجسيده. أيضا نتائج جيدة.

وأتناس حديقة حيواناته الكاملة من النماذج ، ثم كان مزيجًا رائعًا. بالإضافة إلى النماذج نفسها ، أضفت بعض الميزات النصية ، عادةً الطول ، عدد الأحرف الكبيرة ، عدد الكلمات السيئة ، عدد الأحرف ، كل ذلك أضاف. التحقق المتبادل من خمسة أضعاف ، وحصل على نتائج ممتازة على LB 0.9867 الخاص.
والنهج الثاني ، درس بتضمين مختلف ، لكن النتائج كانت أسوأ. استخدم الجميع في الغالب fastText.
كنت أرغب في التحدث عن نهج زميلنا الآخر ، أندريه ، مع لقب Laol في ODS. لقد قام بتدريس الكثير من النوى العامة ، وشربها كما لو كان خارج نفسه ، وقد حقق هذا نتائج رائعة جدًا. لا يمكنك أن تفعل كل هذا ، ولكن فقط خذ حفنة من النوى العامة المختلفة ، حتى على tf-idf ، هناك كل أنواع المحسنين.
كان لديه أحد أفضل الأساليب ، حيث بقينا معه لفترة طويلة في أفضل 15 ، حتى انضم إلينا أليكسي وأتاناس ، ودمج المزج والتكديس لكل هذا. وأيضًا لحظة رائعة جدًا ، كما أفهمها ، لم تستخدم أي من الفرق ، ثم صنعنا أيضًا ميزات من نتائج API للمنظمين. حول هذا أخبر أليكس.
أليكسي نوسكوف:
- مرحبًا. سأخبرك عن النهج الذي استخدمته وكيف أكملناه.

كان كل شيء بسيطًا بما يكفي بالنسبة لي: 10 أضعاف من التحقق المتقاطع ، ونماذج تم تدريبها مسبقًا على ناقلات مختلفة مع معالجة مسبقة مختلفة ، بحيث يكون لديهم المزيد من التنوع في المجموعة ، وزيادة صغيرة ودورتين للتطوير. الأول ، الذي عمل بشكل أساسي في البداية ، درب عددًا معينًا من النماذج ، ونظر في أخطاء التحقق المتبادل ، على الأمثلة التي تقوم بها أخطاء واضحة ، وصحح المعالجة المسبقة بناءً على ذلك ، لأنه أكثر وضوحًا كيفية إصلاحها.
والنهج الثاني ، الذي تم استخدامه أكثر في النهاية ، علم مجموعة من النماذج ، ونظر في الارتباطات ، ووجد كتل النماذج التي ترتبط ارتباطًا ضعيفًا مع بعضها البعض ، وعزز الجزء المكون منها. هذه هي مصفوفة ارتباط التحقق المتبادل بين النماذج الخاصة بي.
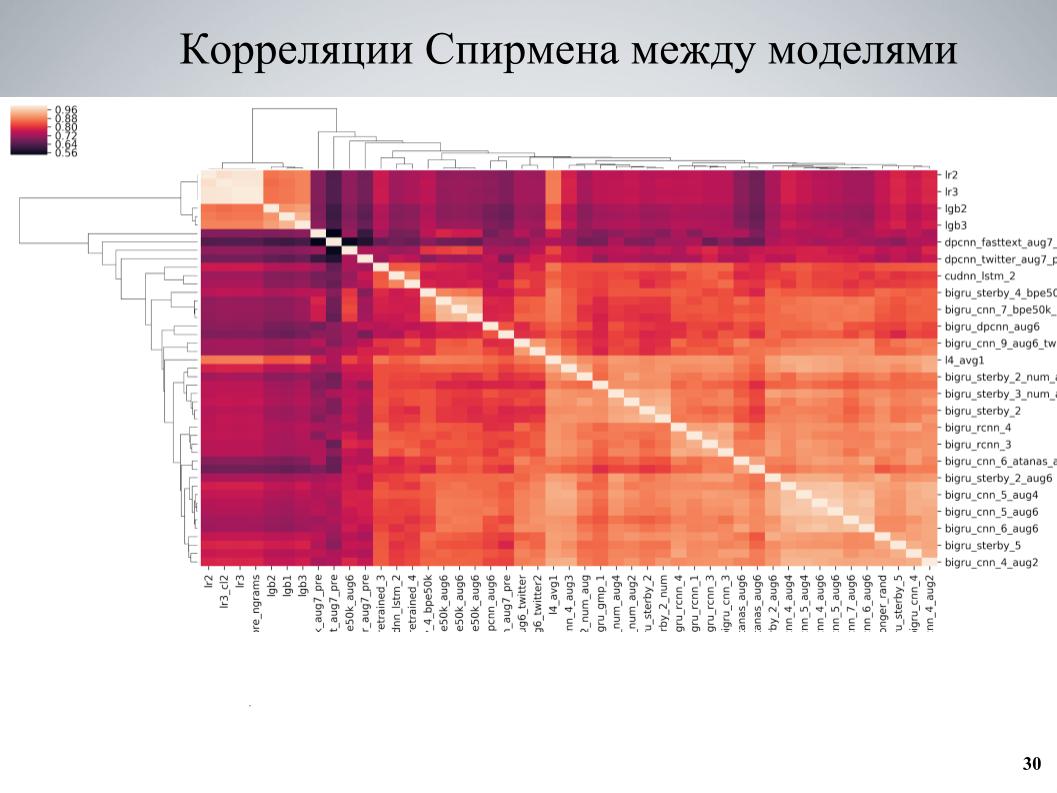
يمكن ملاحظة أنه يحتوي على بنية كتلة في بعض الأماكن ، في حين أن بعض النماذج كانت ذات نوعية جيدة ، وكانت مرتبطة بشكل ضعيف مع الآخرين ، وتم الحصول على نتائج جيدة جدًا عندما أخذت هذه النماذج كأساس ، علمتهم العديد من الاختلافات المختلفة التي تختلف باختلاف hyperparameters أو المعالجة المسبقة ، ثم يضاف إلى المجموعة.

لزيادة ، الفكرة التي تم نشرها في المنتدى من قبل بافيل أوستياكوف أشعلت. وهو يتألف من حقيقة أنه يمكننا أخذ تعليق ، وترجمته إلى لغة أخرى ، ثم العودة. نتيجة للترجمة المزدوجة ، يتم الحصول على إعادة صياغة ، ويتم فقدان شيء ما قليلاً ، ولكن بشكل عام يتم الحصول على نص مختلف قليلاً ، والذي يمكن أيضًا تصنيفه وبالتالي توسيع مجموعة البيانات.
والنهج الثاني ، الذي لم يساعد كثيرًا ، ولكنه ساعد أيضًا ، هو أنه يمكنك محاولة أخذ تعليقين تعسفيين ، عادة ليسا طويلين ، لصقهما وتأخذ كتصنيف على الهدف مجموعة من التسميات أو القليل من الملل حيث لا يوجد سوى واحد من أنها تحتوي على تسمية.
نجح هذان النهجان بشكل جيد إذا لم يتم تطبيقهما مسبقًا على مجموعة المجموعة بالكامل ، ولكن لتغيير مجموعة الأمثلة التي يجب أن يتم تطبيقها على التعزيز في كل عصر. في كل عصر في عملية تشكيل الدفعة ، نختار ، على سبيل المثال ، 30٪ من الأمثلة التي يتم تشغيلها من خلال الترجمات. بدلاً من ذلك ، في وقت ما ، في مكان ما بالتوازي يكمن بالفعل في الذاكرة ، نختار ببساطة الإصدار للترجمة بناءً عليه ، ونضيفه إلى المجموعة أثناء التدريب.

كان الاختلاف المثير للاهتمام هو النماذج التي تم تدريبها في BPE. هناك SentencePiece - Google tokenizer الذي يسمح لك بالانقسام إلى رموز مميزة لن يكون فيها UNK على الإطلاق. قاموس محدود يتم فيه تقسيم أي سلسلة إلى بعض الرموز. إذا كان عدد الكلمات في النص الحقيقي أكبر من الحجم المستهدف للقاموس ، فإنها تبدأ في الانقسام إلى أجزاء أصغر ، ويتم الحصول على نهج وسيط بين مستوى الحرف ونماذج مستوى الكلمة.
يتم استخدام خوارزميتين رئيسيتين للبناء هناك: BPE و Unigram. بالنسبة إلى خوارزمية BPE ، كان من السهل العثور على التضمين قبل العلامات التجارية في الشبكة ، ومع بعض المفردات الثابتة - كان لدي فقط مفردات 50 ألف جيدة - يمكنني أيضًا تدريب النماذج التي أعطت جيدًا جدًا (غير مسموع - تقريبًا Ed.) ، أسوأ قليلاً ، من المعتاد على fastText ، لكنهم كانوا مرتبطين بشكل ضعيف جدًا مع جميع الآخرين وأعطوا دفعة جيدة.
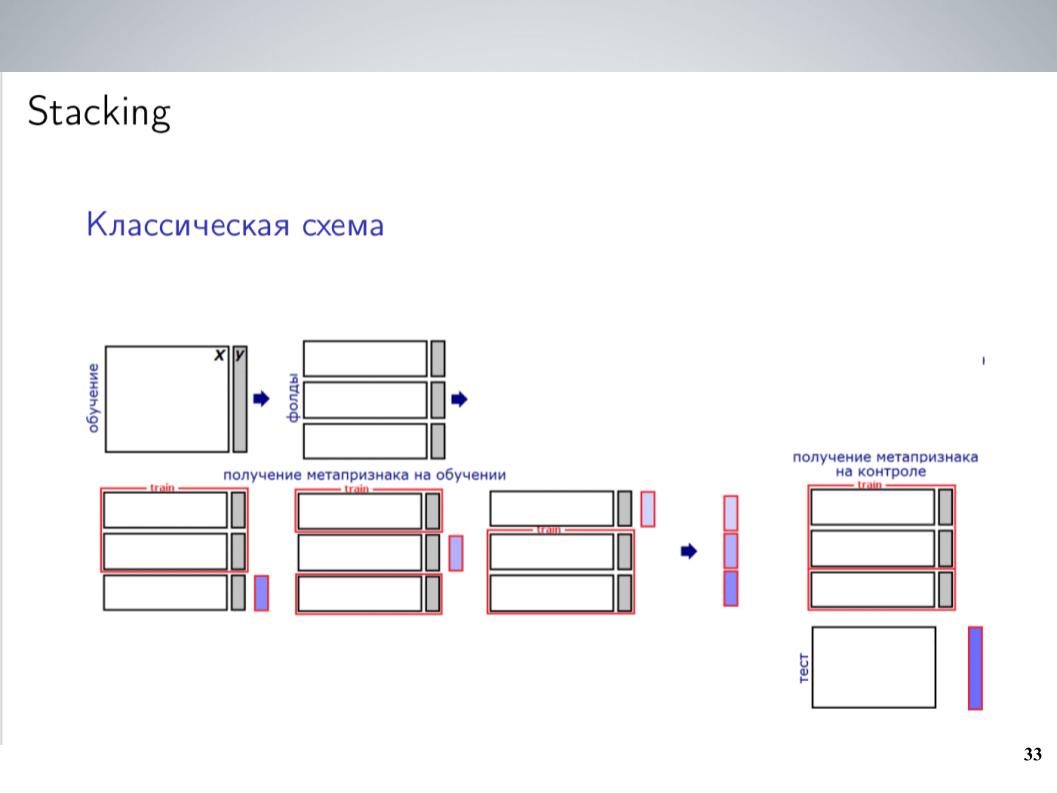
هذا مخطط تكديس كلاسيكي. كقاعدة عامة ، بالنسبة للجزء الأكبر من المسابقة ، قبل الجمع ، كنت ببساطة أمزج جميع نماذجي بدون أوزان. أعطى هذا أفضل النتائج. ولكن بعد الاندماج ، تمكنت من الحصول على مخطط أكثر تعقيدًا قليلاً ، والذي أعطى في النهاية دفعة جيدة.

كان لدي عدد كبير من النماذج. هل ترميهم جميعًا في نوع مكدس؟ لم يكن يعمل بشكل جيد للغاية ، فقد أعاد تدريبه ، ولكن نظرًا لأن النماذج كانت مجموعات مرتبطة ارتباطًا وثيقًا ، فقد قمت ببساطة بتوحيدها في هذه المجموعات ، وفي كل مجموعة قمت بمتوسط واستلمت 5-7 مجموعات من النماذج المتشابهة جدًا ، والتي من بينها ميزات استخدم المستوى التالي القيم المتوسطة. لقد دربت LightGBM على هذا ، وأصدرت 20 عملية إطلاق مع عينات مختلفة ، وحمّلت بعض الوظائف الوصفية المشابهة لما فعله Atanas ، وفي النهاية بدأ العمل أخيرًا ، مما أعطى بعض الدفعة على المتوسط البسيط.

الأهم من ذلك كله ، أضفت واجهة برمجة التطبيقات التي وجدها أندريه والتي تحتوي على مجموعة مماثلة من التسميات. قام المنظمون ببناء نماذج لهم في البداية. نظرًا لأنه كان مختلفًا في الأصل ، لم يستخدمه المشاركون ، كان من المستحيل مقارنته ببساطة مع تلك التي كنا بحاجة إلى التنبؤ بها. ولكن إذا ألقت نفسها في تكديس يعمل بشكل جيد كميزة تعريفية ، فستعطي دفعة رائعة ، خاصة في فئة TOXIC ، والتي ، على ما يبدو ، كانت الأكثر صعوبة على لوحة الصدارة ، وسمحت لنا بالقفز إلى عدة أماكن في النهاية ، حرفيا في اليوم الأخير .

نظرًا لأننا اكتشفنا أن التراص وواجهة برمجة التطبيقات يعملان بشكل جيد للغاية بالنسبة لنا ، قبل عمليات الإرسال النهائية ، لم يكن لدينا شك كبير في كيفية نقل هذا إلى خاص. لقد عملت بشكل جيد بشكل مريب ، لذلك اخترنا إرسالين وفقًا للمبدأ التالي: الأول - مزيج من النماذج بدون واجهة برمجة تطبيقات تم استلامها قبل ذلك ، بالإضافة إلى التراص مع الميتافيزيقيا من واجهة برمجة التطبيقات. هنا اتضح 0.9880 في الأماكن العامة و 0.9874 في القطاع الخاص. هنا علاماتي مشوشة.

والثاني هو مزيج من النماذج بدون واجهة برمجة تطبيقات ، بدون استخدام التراص وبدون استخدام LightGBM ، لأنه كانت هناك مخاوف من أن يكون هذا نوعًا من إعادة التدريب الطفيف للجمهور ، ويمكننا أن نطير مع ذلك. حدث ذلك ، لم يطيروا ، ونتيجة لذلك ، ونتيجة لـ 0.9876 على انفراد ، حصلنا على المركز العاشر. هذا كل شيء.