
في شهر مارس ، حارب فريق التطوير لدينا الذي يحمل اسم "Hands-Auki" بكل فخر لمدة يومين على المجالات الرقمية في hackathon AI.HACK. في المجموع ، تم اقتراح خمس مهام من شركات مختلفة. ركزنا على مهمة Gazpromneft: التنبؤ بالطلب على الوقود من عملاء B2B. وفقًا للبيانات المجهولة ، كان من الضروري معرفة كيفية التنبؤ بالمقدار الذي سيشتريه عميل معين في المستقبل ، وفقًا لمنطقة شراء الوقود ورقم الوقود ونوع الوقود والسعر والتاريخ ومعرف العميل. التطلع إلى المستقبل - حل فريقنا هذه المشكلة بأعلى دقة. تم تقسيم العملاء إلى ثلاثة قطاعات: كبيرة ومتوسطة وصغيرة. بالإضافة إلى المهمة الرئيسية ، قمنا أيضًا بإعداد توقعات إجمالي الاستهلاك لكل مقطع.
احتوى التفريغ على بيانات عن مشتريات العملاء للفترة من نوفمبر 2016 إلى 15 مارس 2018 (للفترة من 1 يناير 2018 إلى 15 مارس 2018 ، لم تتضمن البيانات الأحجام).
بيانات العينة:
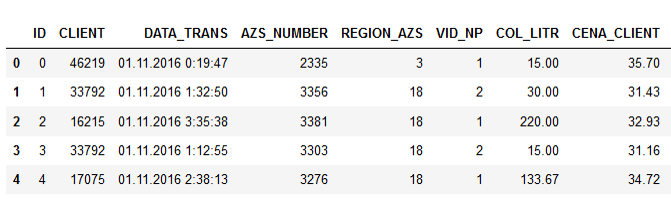
أسماء الأعمدة تتحدث عن نفسها ، أعتقد أنه لا معنى للتفسير.
بالإضافة إلى عينة التدريب ، قدم المنظمون عينة اختبار لمدة ثلاثة أشهر من هذا العام. الأسعار خاصة بالعملاء من الشركات ، مع مراعاة الخصومات المحددة ، والتي تعتمد على استهلاك عميل معين ، على العروض الخاصة ونقاط أخرى.
بعد تلقي البيانات الأولية ، بدأنا ، مثل أي شخص آخر ، في تجربة الطرق الكلاسيكية للتعلم الآلي ، محاولين بناء نموذج مناسب ، للشعور بربط بعض العلامات. حاولنا استخراج ميزات إضافية ، ونماذج انحدار مدمجة (XGBoost ، CatBoost ، وما إلى ذلك).
يشير بيان المشكلة نفسه في البداية إلى أن سعر الوقود يؤثر بطريقة ما على الطلب ، ومن الضروري فهم هذا الاعتماد بشكل أكثر دقة. ولكن عندما بدأنا في تحليل البيانات المقدمة ، رأينا أن الطلب لا يرتبط بالسعر.

ارتباط التوقيع:
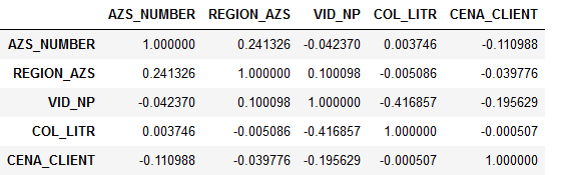
اتضح أن عدد اللترات عمليا لا يعتمد على السعر. تم تفسير هذا منطقيا تماما. يذهب السائق على الطريق السريع ، يحتاج للتزود بالوقود. لديه خيار: إما أن يزود بالوقود في محطة بنزين تتعاون معها الشركة ، أو في محطة أخرى. لكن السائق لا يهتم بمدى تكلفة الوقود - المنظمة تدفع له. لذلك ، ينطفئ ببساطة إلى أقرب محطة وقود ويملأ الخزان.
ومع ذلك ، على الرغم من كل الجهود والنماذج المجربة والمختبرة ، لم يكن من الممكن تحقيق الحد الأدنى المقبول من دقة التنبؤ (خط الأساس) ، الذي تم حسابه باستخدام هذه الصيغة (يعني النسبة المئوية المتساوية الخطأ المطلق):
حاولنا كل الخيارات ، لم ينجح شيء. ثم حدث أن تبصق أحدنا على التعلم الآلي وانتقل إلى الإحصائيات القديمة الجيدة: فقط قم بأخذ متوسط القيمة لنوع الوقود ، والتحقق من الصحة ومعرفة الدقة التي تحصل عليها.
لذا تجاوزنا أولاً قيمة العتبة.
بدأنا نفكر في كيفية تحسين النتيجة. حاولنا أن نأخذ القيم المتوسطة حسب مجموعات العملاء وأنواع الوقود والمناطق وأرقام محطات الوقود. كانت المشكلة في بيانات الاختبار أن حوالي 30٪ من معرّفات العملاء التي كانت في عينة التدريب كانت مفقودة. أي ظهر عملاء جدد في الاختبار. كان هذا خطأ لم يتحقق منه المنظمون. ولكن كان علينا حل المشكلة بأنفسنا. لم نكن نعرف استهلاك عملاء جدد ، وبالتالي لم نتمكن من وضع توقعات لهم. وهنا ساعد التعلم الآلي.
في المرحلة الأولى ، تم ملء البيانات الناقصة بالقيمة المتوسطة أو المتوسطة للعينة بأكملها. ثم طرحت الفكرة: لماذا لا تنشئ ملفات تعريف عملاء جديدة بناءً على البيانات الموجودة؟ لدينا تخفيضات حسب المنطقة ، وعدد العملاء الذين يشترون الوقود هناك ، وبأي تواتر ، وأنواع. قمنا بتجميع العملاء الحاليين ، وقمنا بتجميع ملفات تعريف محددة لمناطق مختلفة ، وقمنا بتدريب XGBoost عليهم ، والتي "أكملت" ملفات تعريف العملاء الجدد.
هذا سمح لنا باقتحام المركز الأول. لا تزال هناك ثلاث ساعات متبقية قبل تلخيص النتائج. لقد سررنا وبدأنا في حل مشكلة المكافأة - التنبؤ حسب القطاعات لمدة ثلاثة أشهر مقدمًا.
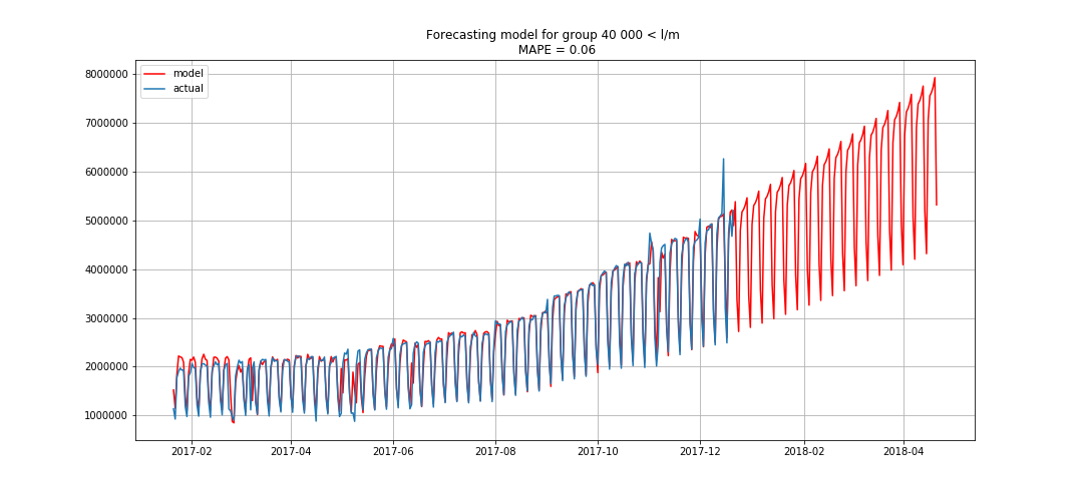
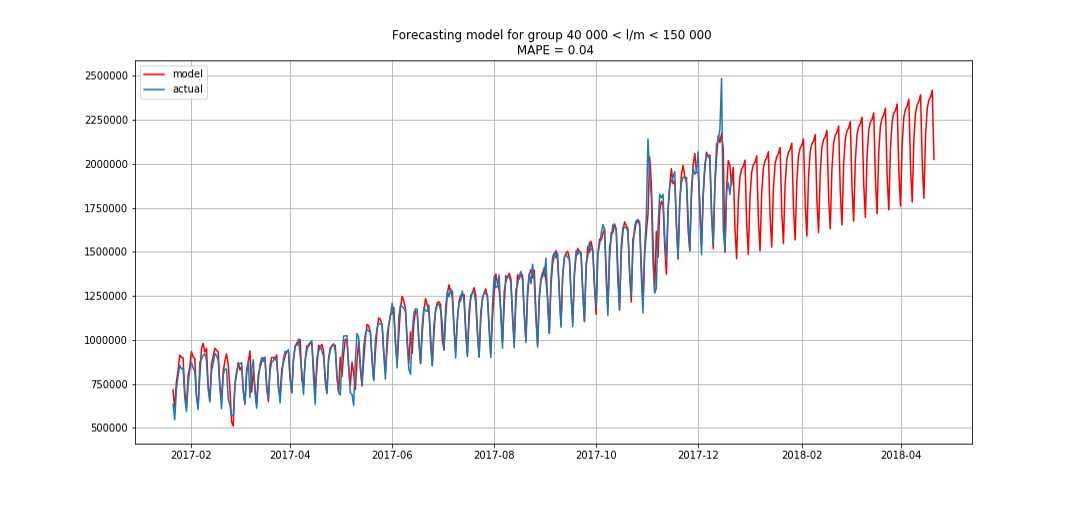
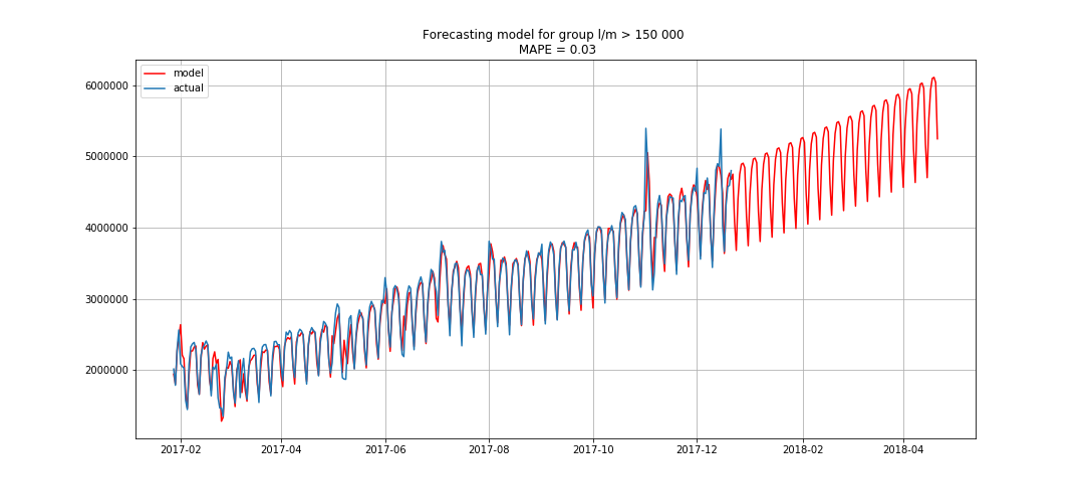
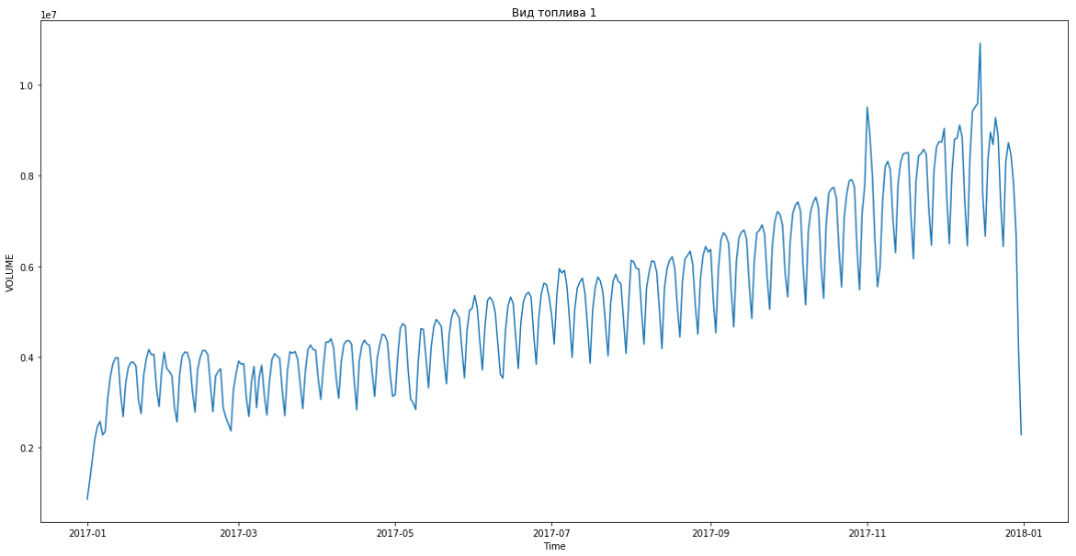
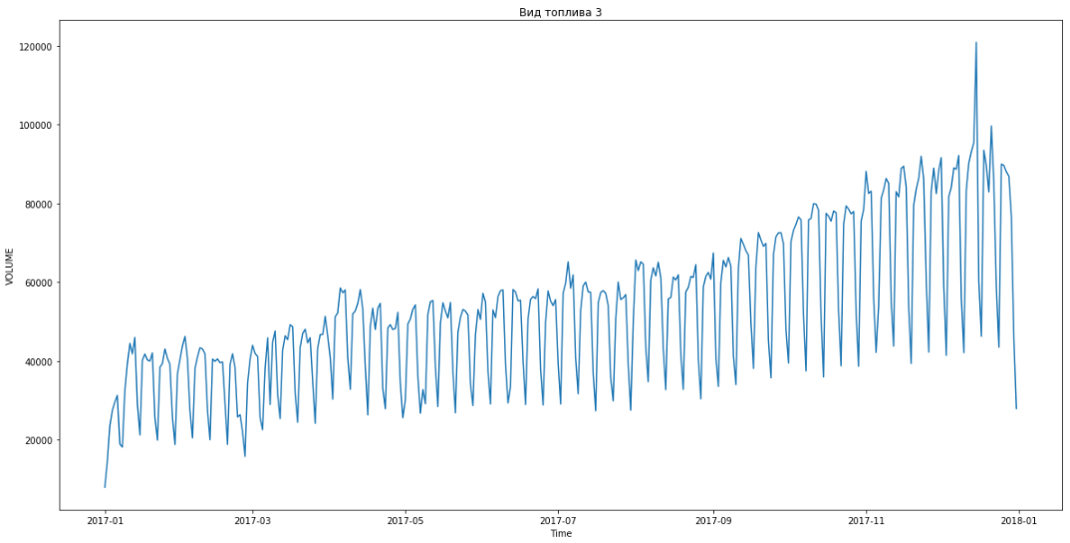
يظهر الأزرق بيانات حقيقية ، باللون الأحمر. تراوحت نسبة الخطأ من 3٪ إلى 6٪. يمكن حسابها بدقة أكبر ، على سبيل المثال ، مع مراعاة القمم الموسمية والعطلات.
أثناء قيامنا بذلك ، بدأ فريق واحد في اللحاق بنا ، مما أدى إلى تحسين نتيجتنا كل 15-20 دقيقة. نحن أيضًا بدأنا في الجلبة وقررنا أن نفعل شيئًا في حالة اللحاق بنا.
بدأوا في صنع نموذج آخر بالتوازي ، والذي صنف الإحصائيات حسب درجة أهميتها ، وكانت دقتها أقل قليلاً من الأولى. وعندما هزمنا المنافسون ، حاولنا الجمع بين كلا النموذجين. أعطانا هذا زيادة طفيفة في المقياس - حتى 37.24671٪ ، ونتيجة لذلك ، استعادنا مكاننا الأول وأبقناه حتى النهاية.
من أجل الفوز ، حصل فريقنا Ruki-Auki على شهادة 100 ألف روبل ، والشرف ، والاحترام و ... المليء بتقدير الذات ، وذهبت إلى السبا! ؛)
فريق تطوير النظم البيئية النفاثة